

Podsumowanie roku 2019

Okres świąteczny jest czasem, kiedy warto zrobić podsumowanie roku, a także przemyśleć kolejne kroki i odpowiednio przygotować się na nowy rok.
3 urodziny Biznes Myśli
Jak możesz już wiedzieć, 14 marca 2020 roku podcast Biznes Myśli będzie obchodzić swoje 3 urodziny! Z tej okazji spotkamy się, aby się poznać osobiście – poznasz mnie, ja poznam Ciebie, poznasz także innych słuchaczy oraz gości podcastu. Zaproszenie już powinno być w Twojej skrzynce mailowej (jeśli jesteś zapisany do newslettera), więc gorąco zapraszam do rejestracji i przyjazdu do Krakowa całą rodziną 🙂
Szczegóły pojawią się wkrótce, ale już teraz mogę zdradzić, że w planie jest duża doza networkingu oraz dyskusje o tym, jak sprawić, by ten podcast był dla Ciebie jeszcze bardziej wartościowy. Nie zabraknie także inspiracji, dlatego już teraz zapisz się na listę gości i zarezerwuj czas w kalendarzu.
Bilety możesz zdobyć tutaj 🙂
Czas zastanowić się, co przyniósł rok 2019
Podsumujmy rok, a właściwie nawet nieco dłuższy okres. Nie tak dawno pojawił się raport Artificial Intelligence Index 2019, który warto przeczytać, bo jest tam wiele ciekawych informacji. Materiał ten zbiera, zestawia, destyluje i wizualizuje dane dotyczące sztucznej inteligencji.
Jego misją jest przedstawienie obiektywnych, rygorystycznie sprawdzonych danych decydentom politycznym, badaczom, kierownictwu, dziennikarzom i opinii publicznej, aby rozwinąć wiedzę i intuicję dotyczącą złożonej dziedziny sztucznej inteligencji. Co roku bardziej rozbudowany raport stara się zawierać dane na temat rozwoju sztucznej inteligencji na całym świecie.
Jest to lektura na 291 stron, więc brzmi to jak całkiem ciekawy plan na Święta :). Jeśli jednak masz inne plany niż czytać raport (bo tak też może być), to pomogę Ci trochę z wyciąganiem wniosków.
Rozkwit badań AI
W latach 1998–2018 udział publikacji AI we wszystkich publikacjach na całym świecie wzrósł trzykrotnie stanowiąc finalnie 3% recenzowanych czasopism i 9% opublikowanych publikacji konferencyjnych.
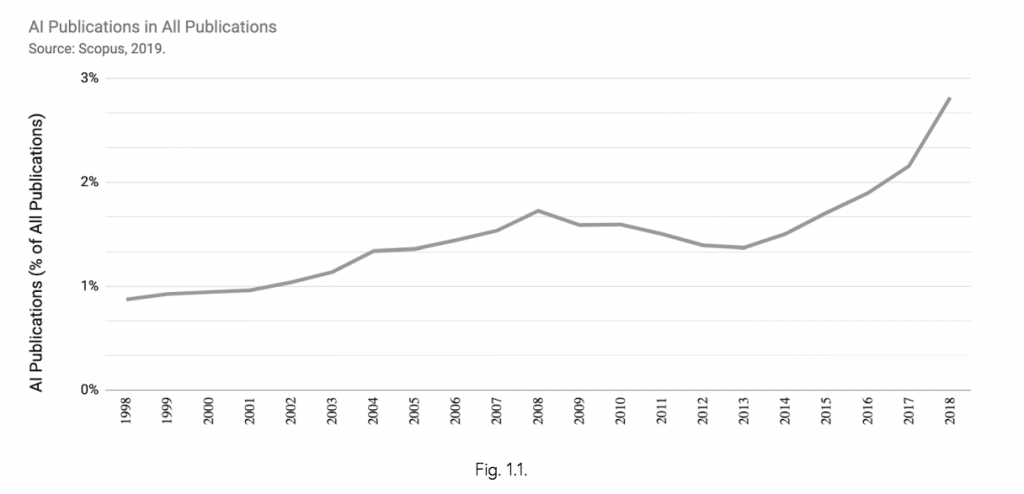
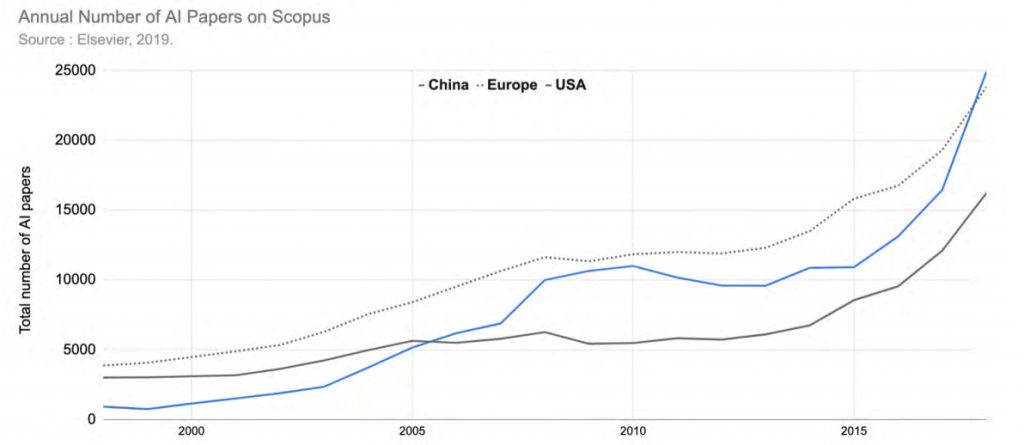
Warto zwrócić uwagę na to, które kraje się aktywowały. Jak pewnie łatwo jest się domyślić na pierwszym miejscu znajdują się Chiny. Na ten temat nagrywałem osobny odcinek – 23: czy Chiny stają się nowym centrum świata? Znajdziesz tam więcej informacji o tym, z czego to wynika i jak na poziomie państwa jest wspierany rozwój tak zwanej sztucznej inteligencji oraz jakie są ambicje.
W raporcie porównywane są Chiny, Stany Zjednoczone oraz Europa. W każdym z tych rejonów zauważalny jest przyrost publikacji w roku 2018 w porównaniu z poprzednimi latami. Na przykład w Chinach w 2017 roku opublikowano 16,5 tys. prac, natomiast rok później już 24,9 tys. W Stanach Zjednoczonych różnica to wzrost z 12,1 tys. w 2017 r. do 16,2 tys. rok później.
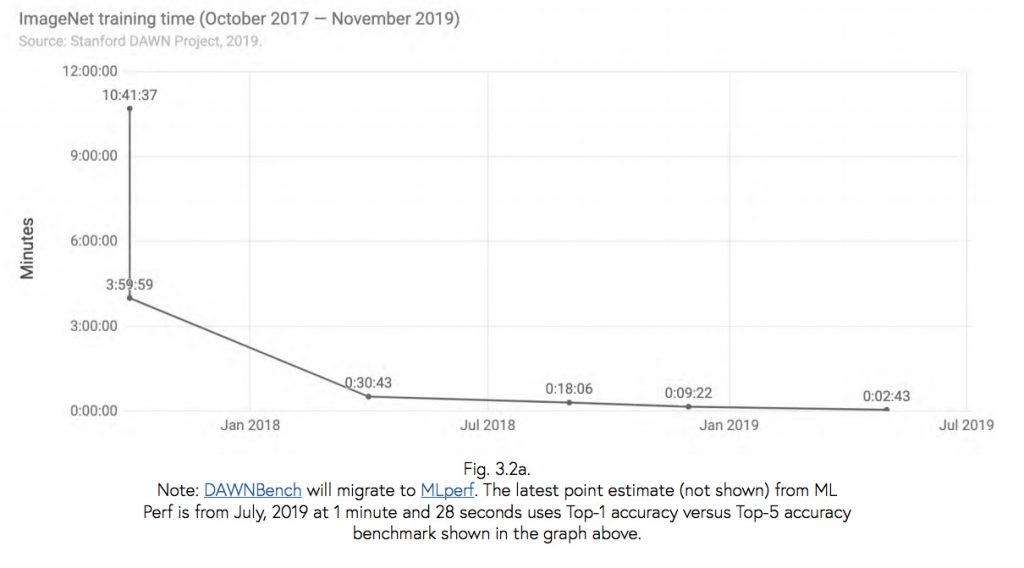
Uczenie modeli staje się coraz szybsze i tańsze. Badania niewiele wnoszą wartości, jeśli nie udało się wytrenować prawdziwych modeli, więc ten punkt jest bardzo istotny. Zespół AI Index zauważył, że czas potrzebny na uczenie modelu na popularnym zbiorze danych (ImageNet) spadł z około trzech godzin w październiku 2017 roku do zaledwie 88 sekund w lipcu 2019 roku. Spadły również koszty: z tysięcy dolarów do dwucyfrowych kwot.
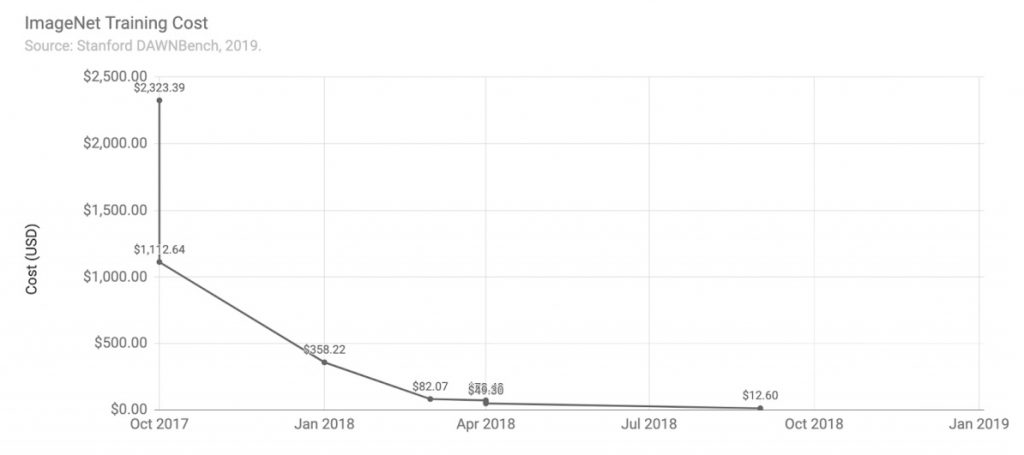
Następny wykres przedstawia koszt trenowania modelu na danych ImageNet mierzony kosztem publicznie dostępnych instancji w chmurze w celu wytrenowania modelu klasyfikacji obrazów TOP5 z dokładnością walidacji co najmniej 93% lub większą.
NLP (natural language processing)
W roku 2018 już były duże postępy w zakresie przetwarzania języka naturalnego w porównaniu z poprzednimi latami, między innym pojawił się BERT, następnie pojawiły się kolejne wersje Microsoft MT-DNN (Multi-Task Deep Neural Networks for Natural Language Understanding), Google XLNet, Facebook RoBERTa.
Jedną z gałęzi NLP jest NLU (Natural Language Understanding), czyli rozumienie języka naturalnego. Tutaj warto zatrzymać się na chwilę, bo w roku 2019 wydarzyło się kilka ciekawych rzeczy.
GLUE
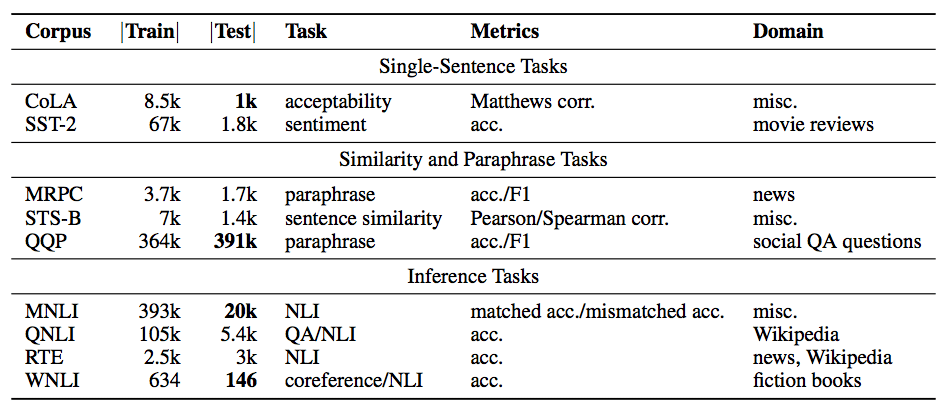
Najpierw trochę kontekstu. Istnieje benchmark o nazwie GLUE benchmark, to jest skrót od General Language Understanding Evaluation benchmark. Benchmark to formalny test, który polegał na tym, że mając różne podejście do rozwiązywania problemu (różne modele), można było w spójny sposób porównywać wyniki. GLUE jest dość ciekawym testem, bo tak naprawdę zawiera w sobie 9 innych. Przed GLUE był szereg różnych testów i zwykle model bardzo dobrze sobie radził z jednym z nich, zamiast tego, żeby uogólnić wiedzę.
Ludzka zdolność do rozumienia języka naturalnego jest ogólna oraz elastyczna. W przeciwieństwie do tego większość modeli NLU powyżej “poziomu słów” (czyli rozumienia znaczenia poszczególnych wyrazów) jest przeznaczona do konkretnego zadania i jest bardzo trudno zastosować ją w innym kontekście. Jeśli dążymy do tworzenia modeli ze zrozumieniem wykraczającym poza wykrywanie powierzchownych korelacji pomiędzy wejściami i wyjściami, to kluczowe jest opracowanie bardziej ujednoliconego modelu, który może nauczyć się wykonywać szereg różnych zadań językowych w różnych domenach.
Stąd potrzebnym stało się przygotowanie modelu, który potrafiłby być dobrym dla różnych zadań i następnie ten model delikatnie dostosowywać pod konkretne potrzeby. Tym samym wynikła naturalna potrzeba do mierzenia jakości takiego modelu, w wyniku czego w maju 2018 roku pojawił się GLUE benchmark. Natomiast już rok później, udało się wytrenować model, który był lepszy pod względem wydajności od ludzi niebędących ekspertami (wcześniej wspomniany model RoBERTa od Facebook czy T5 od Google).
SuperGLUE
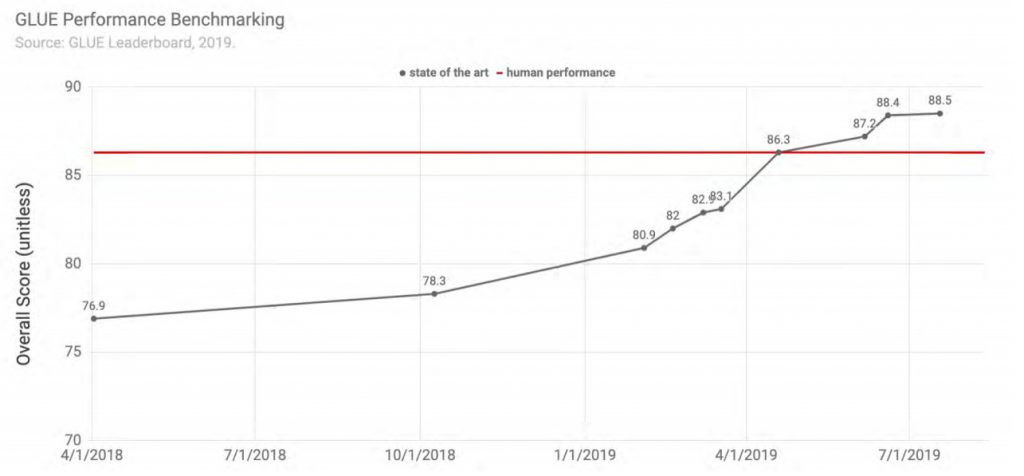
Jak widać postępy rozwoju w NLU w roku 2019 były dość szybkie, więc pojawił się kolejny test o nazwie SuperGLUE, który zawiera nowy zestaw bardziej zróżnicowanych i trudnych do zrozumienia zadań językowych.
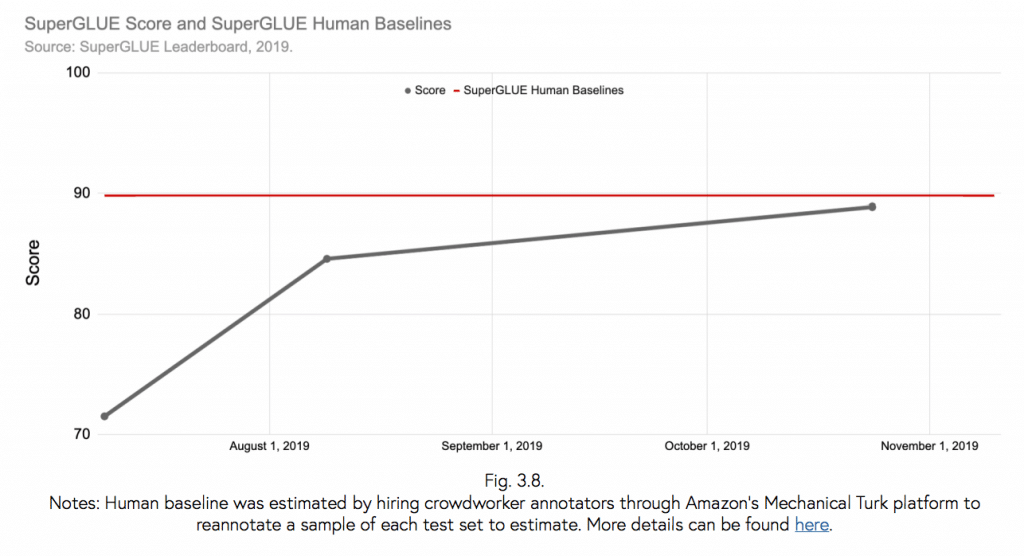
Chociaż i w tym przypadku widać, że już jest bardzo blisko, żeby przekroczyć poziom ludzi (88.9 Google T5 Team vs 89.8 Human Baseline), który został oszacowany na podstawie wyników ludzi w usłudze Amazon Mechanical Turk. To jest taka usługa, gdzie można zlecić wykonanie bardzo prostego, ale rozległego pod kątem ilościowym zadania, które następnie ktoś (z krajów gdzie godzina pracy jest bardzo tania) go wykona. Szacuje się, że w maju 2020 roku model osiągnie poziom 90% lub nawet lepszy (czyli ponad poziom ludzi). Warto sprawdzić za pół roku :).
SQuAD
Kolejne ciekawe osiągnięcie miało miejsce w obszarze odpowiadania na pytania na zbiorze danych SQuAD (The Stanford Question Answering Dataset). Istnieją dwie wersje tego zbioru danych: 1.1 oraz 2.0. W pierwszej wersji było 50 tys. pytań, w drugiej 100 tys.
Działa to na podstawie kontekstu, np. akapitu tekstu z Wikipedii, następnie pojawia się pytanie, na które trzeba odpowiedzieć. Trochę to przypomina zadanie czytania ze zrozumieniem. Jakie są wyniki w tym obszarze?
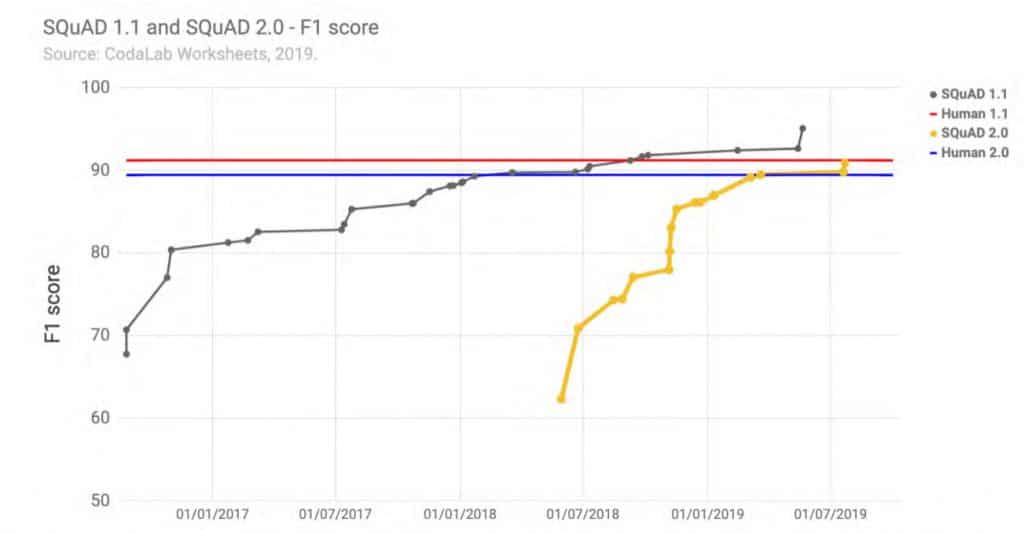
Wynik F1 dla SQuAD1.1 zmienił się z 67% w sierpniu 2016 r. na 95% w maju 2019 roku. Postępy na SQuAD2.0 były jeszcze szybsze: F1 z 62% w maju 2018 do 90% w czerwcu 2019. W obu przypadkach udało się przekroczyć tak zwany human baseline.
Dodam, że wszystkie wyżej wymienione testy dotyczą języka angielskiego, który jest znacznie łatwiejszy niż na przykład język polski. Natomiast to, co udało się osiągnąć w języku angielskim, zwykle po jakimś czasie udaje się przenieść na język polski. Może to zająć trochę więcej czasu, ale to wynika ze specyfiki języka, ale jest jeszcze inne większe wyzwanie – znacznie mniej ludzi jest w to zaangażowanych.
Przy okazji zdradzę, że pracuję nad kursem przetwarzania języka naturalnego. Można się spodziewać nowości w lutym 2020 roku, także zachęcam do śledzenia informacji. Będzie to unikalny autorski kurs, dzięki któremu poznasz te wszystkie zawiłe tematy po ludzku i w taki sposób, żeby można było to zastosować w praktyce rozwiązując konkretne problemy biznesowe. Tych problemów jest naprawdę dużo…
Inwestycja w AI
W skali globalnej, inwestycje w startupy AI kontynuują swój stały wzrost. Z łącznej kwoty 1,3 mld USD zebranej w 2010 r. do ponad 40,4 mld USD w samym 2018 r. (z 37,4 mld USD w 2019 r. według stanu na 4 listopada). Średnia roczna stopa wzrostu wyniosła ponad 48% w latach 2010 – 2018.
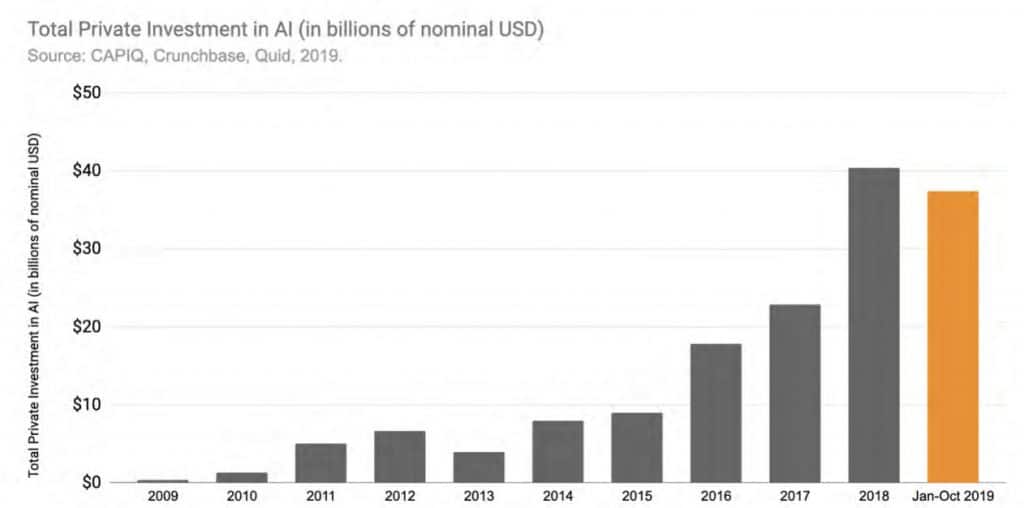
Stale wzrasta również liczba zakładanych firm działających w obszarze AI. Od poniżej 1000 w roku 2014 do ponad 3000 w roku 2018 (czyli trzy razy więcej w 4 lata).
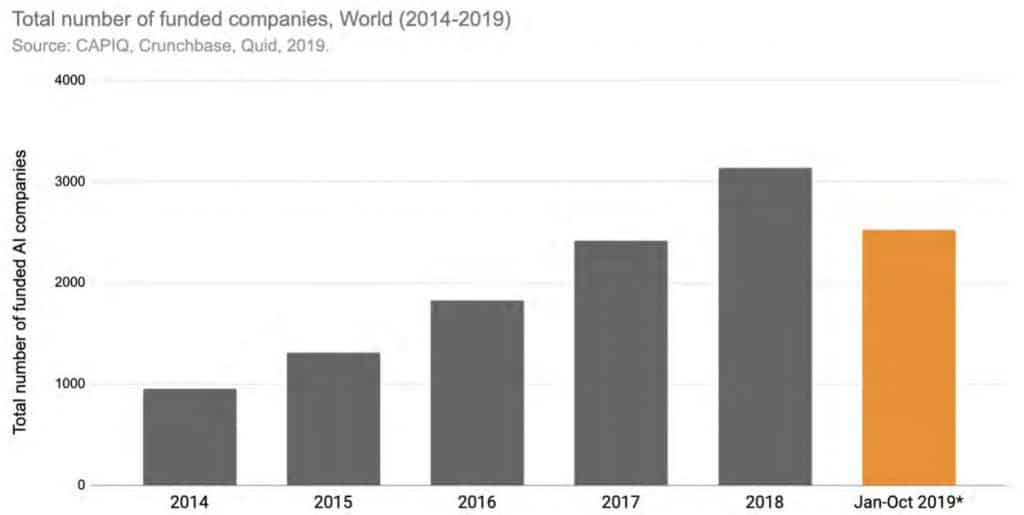
Większość startupów finansowanych z prywatnych inwestycji zakłada się w Stanach Zjednoczonych, na drugim miejscu są Chiny i na trzecim miejscu (ale bardzo daleko od pierwszych dwóch) Wielka Brytania.
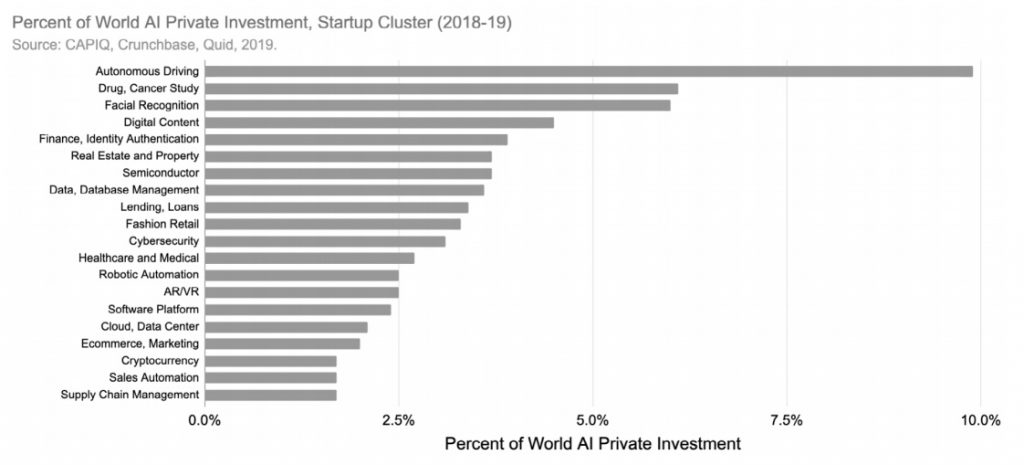
Który dokładnie obszar AI jest najbardziej popularny? Na pierwszym miejscu są samochody autonomiczne 9,9% (7,7 mld USD), następnie badanie leków i walka z rakiem 6,1% (4,7 mld USD) i na trzecim miejscu rozpoznawanie twarzy 6,1% (4,7 mld USD).
Uwaga: Wykres przedstawia sumę wszystkich prywatnych inwestycji w AI w okresie od stycznia 2018 roku do października 2019 roku.
Edukacja
Przede wszystkim warto zauważyć trend, że wiedza stała się łatwiej dostępna dzięki kursom online zaczynając od gigantów Coursera czy Udacity. Liczba studentów, którzy zapisują się na kurs, mierzona jest w nawet milionach, chociaż ilość zwykle wpływa negatywnie na jakość.
Będąc przy tym temacie warto wspomnieć o moich autorskich kursach internetowych na DataWorkshop. To jest jedyny projekt w Polsce na taką skalę. Na ten moment dostępne są trzy kursy online, a kolejny już w trakcie przygotowywania.
Mam dla Ciebie w tym miejscu prezent – kupując kurs do końca 2019 roku, masz zniżkę 30%. To coś więcej niż tylko kurs, bo skupia się na tym, żeby maksymalnie przyspieszyć Twój rozwój. To także więcej niż online, bo organizujemy regularne spotkania absolwentów, na których dzieje się wiele wartościowych rzeczy. Ludzie poznają się, robią wspólne projekty, znajdują pracę. Kolejny zlot absolwentów odbędzie się 15 lutego 2020 w Krakowie. Zobacz, jak było na poprzednim zlocie.
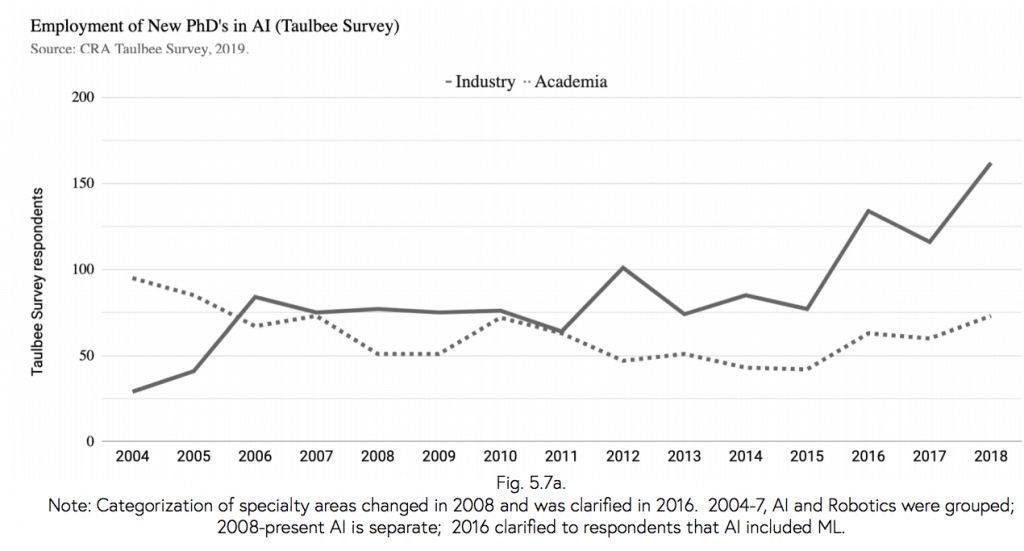
Wracając do raportu. AI jest najbardziej popularnym obszarem specjalizacji CS PhD. W 2018 roku ponad 21% absolwentów studiów doktoranckich z zakresu informatyki specjalizowało się w AI/ML.
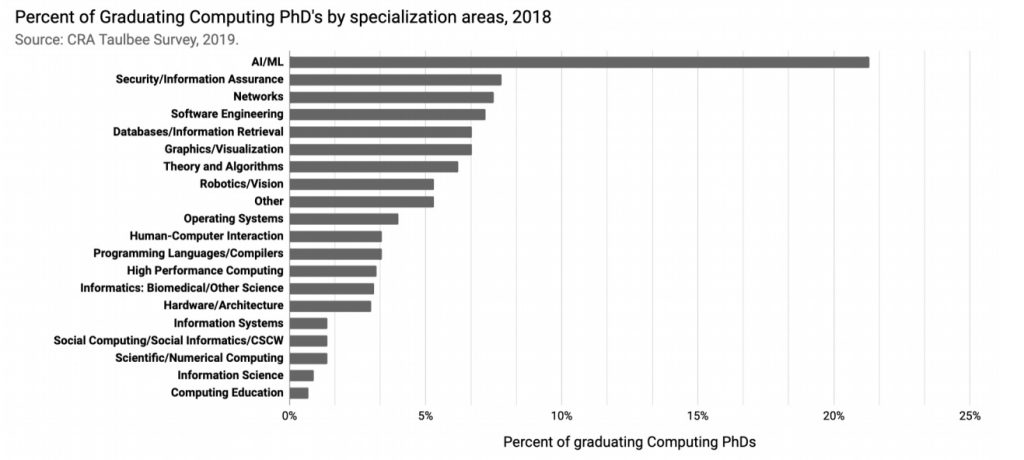
Doktorat w AI stał się modny, dlatego że dzięki temu tytułowi można pozyskać lepszą ofertę pracy z większym wynagrodzeniem. To jest argument, który słyszałem od wielu osób na żywo. Osobiście nie mam takich aspiracji, aby pozyskać ten dyplom (przynajmniej na razie tak wyczuwam), bo ostatecznie to tylko tytuł, a doświadczenie zdobywa się poprzez praktykę.
Tym bardziej pozyskanie PhD w ML/AI w Polsce dość często jest dużą męką, wynikającą z kwalifikacji kadry na uczelniach. Dziedzina ML/AI jest zbyt dynamiczna, ciężko tylko wykorzystywać wiedzę zdobytą 20 czy 50 lat temu i być na czasie teraz. Chociaż warto przyznać, że zrobienie doktoratu na przykład na Stanfordzie brzmi bardzo ciekawie (też networking bardzo dobry).
Zgodnie z raportem proporcja nowych doktorów działających w branży jest trzykrotnie większa w 2018 roku niż 2004. Związane jest to z tym, że dużo osób decyduje się na studia doktoranckie jedynie dla dyplomu, który bywa dźwignią w karierze i wcale nie planuje wiązać swojej przyszłość ze światem akademickim. Prosta i pragmatyczna decyzja.
Raport przedstawia wiele ciekawych wniosków, dlatego zapraszam do jego pełnej lektury. Jeśli będziesz mieć pytania czy po prostu chcesz podyskutować, to porozmawiajmy 🙂
Wspomnę jeszcze o kilku rozwiązaniach, które pojawiły się 2019 roku, o których warto wiedzieć, bo to jest kolejny postęp w rozwoju AI.
Pluribus
W trzecim odcinku podcastu wspomniałem o Libratus, czyli rozwiązaniu, które w 2017 roku potrafiło pokazać, jak dobrze gra w pokera. System pokonał kilku mocnych zawodników. Tylko wtedy była to gra jeden na jeden. W lipcu 2019 pojawił się ciekawy artykuł na Facebooku o nowym rozwiązaniu. Kolejną wersję Libratus nazwano Pluribus. W tym przypadku już chodziło o grę 6 uczestników, np. 5 ludzi i jeden Pluribus, może być też na odwrót. Pluribus wygrał z wszystkimi, chociaż warto przyznać, że również grali tam bardzo dobrzy gracze.
Cytując Jasona Lesa, profesjonalnego pokerzystę:
“To jest absolutny mistrz blefowania. Powiedziałbym, że jest o wiele skuteczniejszy niż większość ludzi. I to właśnie sprawia, że tak trudno jest z nim grać. Zawsze jesteś w sytuacji, w której AI wywiera na Ciebie dużo presji.”
Natomiast teraz zwrócę uwagę na kilka ważnych rzeczy. Naukowcy potrzebowali superkomputerów kosztem setek tysięcy dolarów i budżetu w wysokości miliona dolarów na opracowanie i testowanie Libratusa (czyli poprzedniego rozwiązania), za to Pluribus został uruchomiony na komputerze o dwóch 14-rdzeniowych procesorach oraz mniej niż 512 GB pamięci RAM, a cały budżet wyniósł mniej niż 150 dolarów.
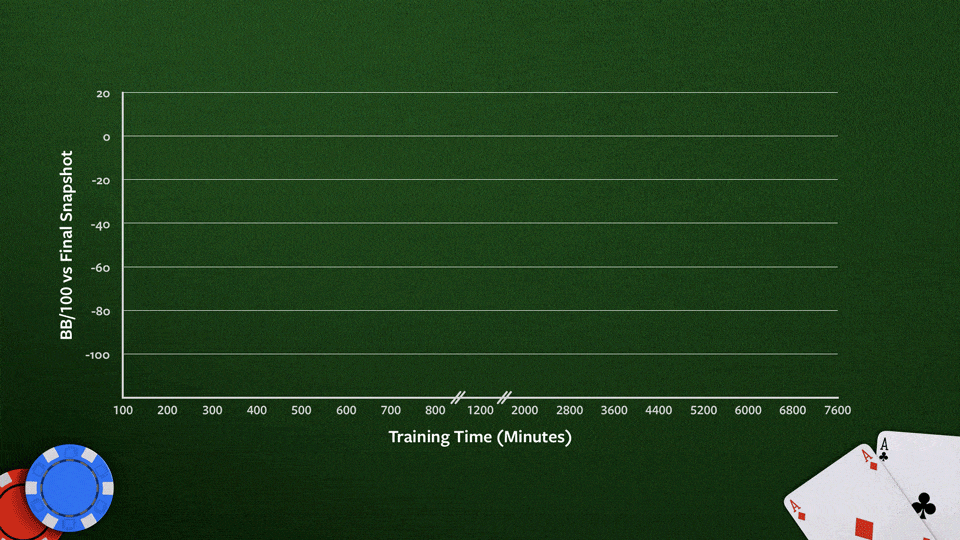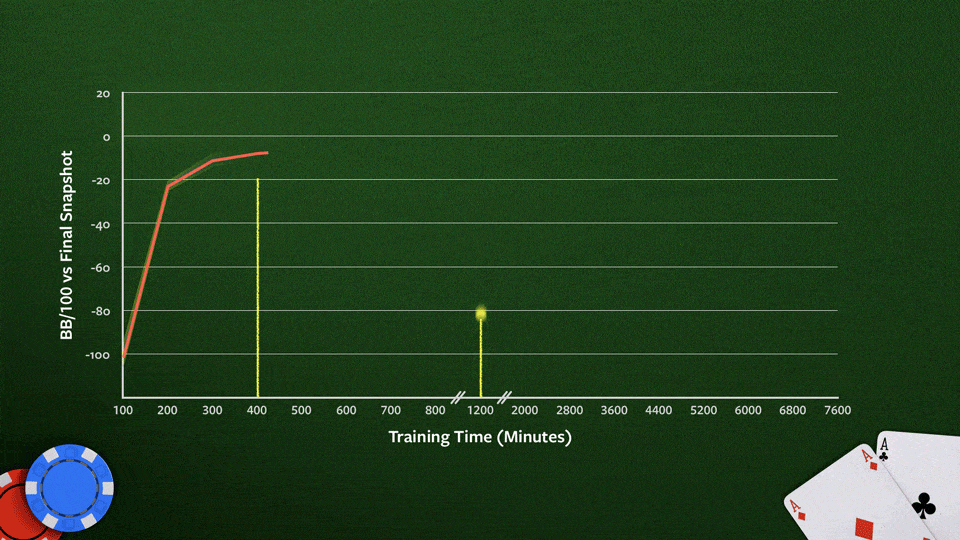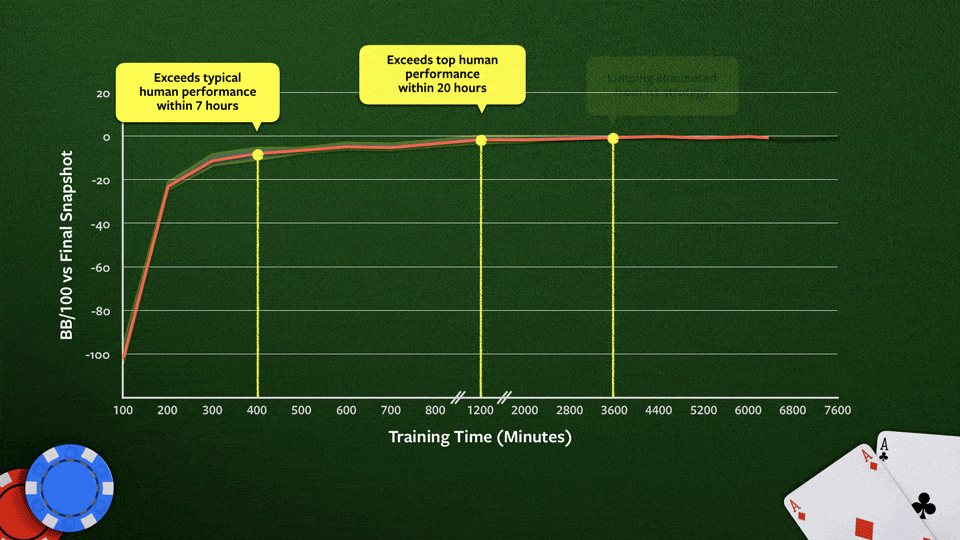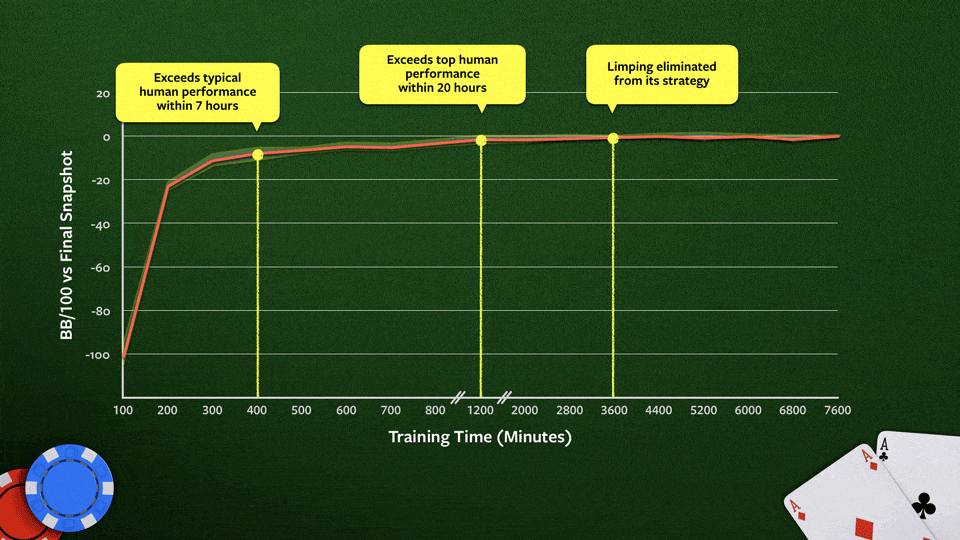
Takie rozwiązanie robi wrażenie… Zresztą podobnie jak AlphaZero (gdzie zero oznacza zero wiedzy wprost podanej od człowieka). AlphaZero nie miało żadnych reguł, uczyło się poprzez doświadczenie. Zaczynając od losowych kroków bardzo szybko wyciągało wnioski, co działa, a co nie. Osiągnięcie poziomu tak zwanego superhuman, czyli lepiej niż człowiek w zależności od złożoności gry zajęło 9 godzin dla szachów, 12 godzin dla shogi (czyli Japońskich szachów) oraz 13 dni dla Go.
Dla osób, które już szukają publicznie dostępnego kodu, jest informacja od autorów, że Pluribus nigdy nie będzie publicznie dostępny.
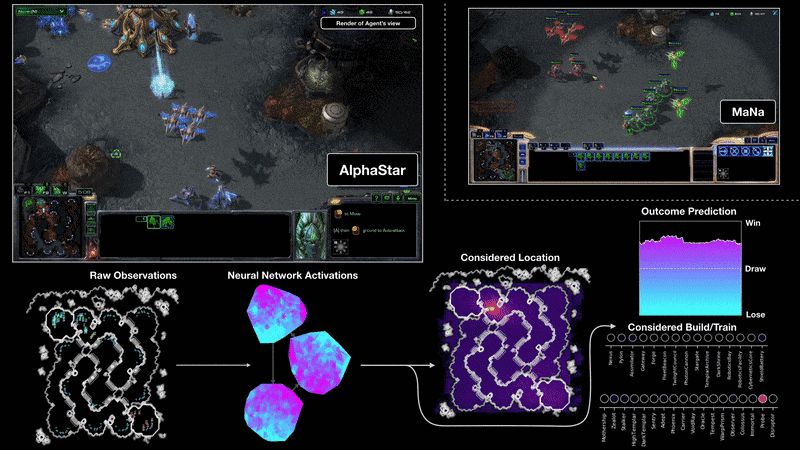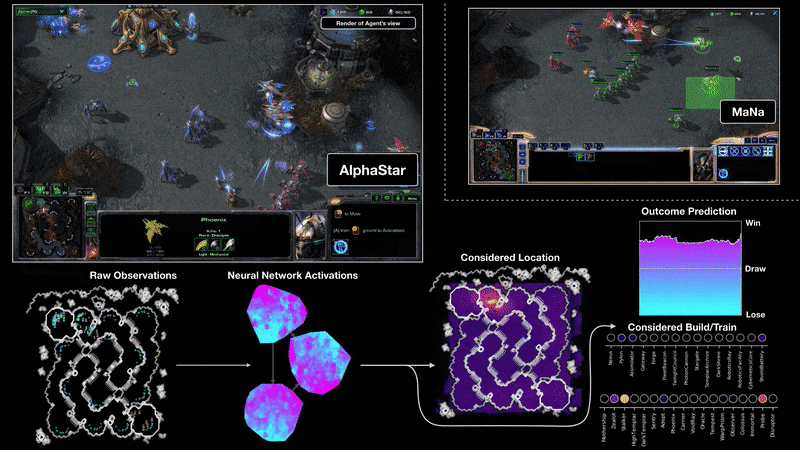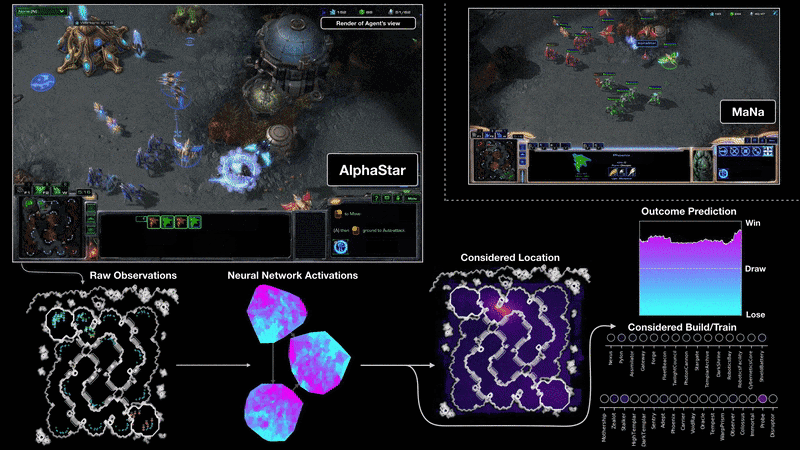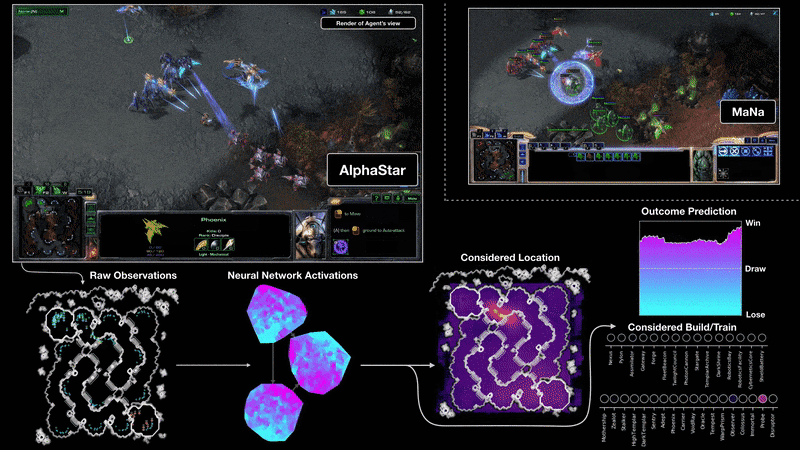
AlphaStar
W roku 2019 pojawił się AlphaStar, czyli bot, który gra w StarCraft. W styczniu 2019 roku, wstępna wersja AlphaStar rzuciła wyzwanie dwóm najlepszym graczom na świecie w StarCraft II, jednej z najbardziej trwałych i popularnych gier strategicznych wszech czasów.
Million sztucznych twarzy
Zebranie danych czasem jest bardzo trudnym zadaniem. W szczególności jeśli mówimy o prywatnych danych takich jak twarz (w szczególności RODO tutaj sprawy komplikuje). Jednym z rozwiązań tego problemu jest generowanie sztucznych zdjęć i właśnie taki projekt został stworzony.
W jego ramach generuje się sztucznie milion twarzy osób, które w rzeczywistości nie istnieją.To jest sztucznych zbiór danych (czyli wygenerowany), który zawiera jeden milion twarzy .
Zbiory danych
Mówiąc o zbiorach danych, warto wspomnieć o projekcie Data Set List, gdzie w łatwy sposób można zobaczyć przeróżne zbiory obecnie dostępnych danych, w kategoriach: computer vision, NLP, Audio, Self-Driving, QA itd.
Znajduje się tam także zakładka z linkami do narzędzi anotation tools. Jeśli masz potrzebę manualnie oznaczyć dane, to warto wiedzieć, jakie są możliwości. Co ważne, wszystkie wymienione tam narzędzia są open-source i mają całkiem fajną licencję, więc można z tego korzystać również w celach komercyjnych.
Mówiąc o open-source warto zwrócić uwagę na to, w jakim stopniu to zmienia rozwój nie tylko machine learning oraz sztucznej inteligencji, ale całego obszaru związanego z komputerami. W tym jest duża potęga i te narzędzia tylko będą nabierać rozpędu z czasem.
Pozwolę sobie też podsumować ten rok także z mojej strony, bo bardzo dużo ciekawych inicjatyw udało się uruchomić.
BiznesMyśli w 2019 roku
Jak już wiesz, podcast w lutym będzie miał 3 lata. W 2019 roku nagraliśmy 23 odcinki, czyli prawie całą dobę nagrań :). Poruszanych było wiele ciekawych tematów. Jeden z najbardziej popularnych odcinków to odcinek 50-ty “Przyszłość naszych dzieci”. Muszę powiedzieć szczerze, że był to także jeden z najtrudniejszych odcinków przede wszystkim pod kątem emocjonalnym. Staram się regularnie myśleć o rzeczach, które nas otaczają, natomiast muszę przyznać, że mam duży dyskomfort mówienia tego na głos.
Dostałem bardzo zróżnicowaną informację zwrotną. Na dzień dzień dzisiejszy, nie jestem pewny, czy będzie kontynuacja podobnych odcinków, bo tak jak powiedziałem, czasem lepiej nie mówić pewnych rzeczy na głos. Mózg człowieka to jest w pewnym sensie hardware (czyli komputer), na którym można zapisywać różne programy. Edukacja i inne sposoby propagandy, zapisują takie programy, które są wygodne np. pod kątem zarządzania masami.
Największy problem pojawia się w tym, że człowiek emocjonalnie przywiązuje się do cudzych poglądów i wtedy jak ktoś zaczyna obalać mity, to po prostu boli… Mam dla Ciebie zadanie domowe. Przypomnij sobie to, do czego lub do kogo jesteś przywiązany, następnie zrób eksperyment, wyobraź sobie, że ktoś krytykuje ten przedmiot lub osobę, to jak wtedy się czujesz?
Spędź trochę więcej czasu i zbadaj źródło tego uczucia i też spróbuj odpowiedzieć, czemu tak jest? Dlaczego zwykłe słowa potrafią wyprowadzić z równowagi? Być może to oznacza brak równowagi wewnątrz, co o tym myślisz?
Oprócz 50 odcinka, popularnymi były również podcasty 10 mitów o sztucznej inteligencji oraz komputery kwantowe i sztuczna inteligencja. Ten drugi odcinek o komputerach kwantowych nagrywałem z Pawłem Gorą, który zamierza pojawić się na urodzinach podcastu Biznes Myśli 14 marca w Krakowie, na który również Ciebie zapraszam.
DataWorkshop w 2019 roku
W roku 2019 sporo działo się także w DataWorkshop. Wyrośliśmy już z działalności jednoosobowej do spółki, czyli już formalnie istnieje DataWorkshop sp. z o.o., której jestem założycielem, inwestorem oraz prezesem. Świadomie napisałem inwestorem, bo to jest strategia, której się trzymamy.
Wpuszczanie osoby z zewnątrz, w szczególności inwestora, może bardzo wywrócić rzeczy do góry nogami i co ważne zmienić tryb myślenia. Inwestorom zależy na tym, żeby zarobić jak najszybciej i to da się zrozumieć, natomiast my mamy inne cele. Mimo tego że ciągle szybko rośniemy (kiedyś na prezentacji wspomniałem o podwajaniu przychodów), to traktujemy to jako efekt uboczny dostarczania wartości dużej liczbie osób.
W tym roku jeszcze bardziej przekonałem się, jak bardzo ważnym jest dbanie o otoczenie, w którym jestem, czasem za szybko ufam ludziom i muszę być ostrożnym. Naiwność sama w sobie jest potężnym narzędziem i tego należy się trzymać (przynajmniej taką mam strategię), natomiast warto zbudować swój lokalny świat w taki sposób, żeby ciężko było przebrnąć osobom, które mogą na tym skorzystać w swoich celach narażając przy tym Ciebie.
Co zrobiliśmy jako DataWorkshop w 2019 roku?
W maju zorganizowaliśmy DataWorkshop Tour. To było dwudniowe szkolenie na żywo w Warszawie.
We wrześniu zorganizowaliśmy konferencję DWCC 2019, na którą udało nam się zaprosić mocnych w swoim obszarze i ciekawych prelegentów z wielu krajów i firm, które rozwijają zaawansowane projekty, np. Facebook, DeepMind, Uber, Huawei itd.
Ta konferencja była też dowodem na to, jak ważne dla nas jest dostarczanie wartości poprzez doświadczenie. Między innymi dlatego zrezygnowaliśmy ze sponsoringu. W wyniku tego sama konferencja była finansowo na dużym minusie. Budżet konferencji był porównywalny do budżetu potrzebnego na zakup mieszkania w Krakowie, z czego ⅓ to jest minus, który trzeba było pokryć z własnych środków.
Było to bolesne… i to z wielu powodów. Bo samo przygotowanie zajęło nam ponad pół roku, nie miałem urlopu i ostatnie miesiące pracowałem prawie po 15 godzin, 7 dni w tygodniu i na koniec jeszcze musiałem pokryć dziurę budżetową z własnych środków. Po raz pierwszy musiałem przeżyć taką sytuację i trochę zajęło czasu, żeby to wszystko przemyśleć i poukładać.
Pytanie, które sobie zadałem – jeśli cofnąć czas, czy zrobiłbym to jeszcze raz? Odpowiedź była twierdząca. To też mówi sporo o mojej motywacji. Mówiąc o roku 2020 na razie mamy inne plany i to czy będzie 3. edycja na dzień dzisiejszy stoi pod dużym znakiem zapytania. Na ten moment widać, że da się dostarczać wartości w bardziej efektywny sposób.
Korona wyzwań
Od marca do października trwała korona wyzwań. To było pięć wyzwań trwających pięć dni. Zaczynało się w poniedziałek i kończyło się w piątek. Codziennie o 5-ej rano było wysyłane zadanie. Ponad 5 tysięcy chętnych zapisało się na ten projekt. Uczestnicy pochodzili z różnych zakątków Polski.
W szczególności cieszy mnie, kiedy ludzie z mniejszych miejscowości znajdowali inspirację i zaczęli wprowadzać zmiany w swoim życiu. Osoby, które mieszkają w dużych miastach, często nie są świadome, że czasem zwykła rutyna małych miejscowości potrafi mocno zniechęcić do działania. Niby internet jest ten sam, ale człowiek nie jest świadomy, co tam można znaleźć. Bardzo cieszę się, że wyzwanie się odbyło i tak dużo wygenerowało pozytywnej energii. Swoją drogą, nadal można zapisać się i będziesz co tydzień dostawać 5 zadań do wykonania. Wyzwanie jest w 100% bezpłatne.
Online kursy
W ciągu roku zrobiliśmy 5 edycji kursów. Dwa razy było powtórzone “praktyczne uczenie maszynowe od podstaw” oraz “prognozowanie szeregów czasowych”, dodatkowo zrobiłem nowy kurs “praktyczne wprowadzenie do Python” specjalnie dla osób, które potrzebują jeszcze łagodniejszego wejścia do uczenia maszynowego (czyli to zwykle są nie-programiści).
Kursy przerobiło już 500 osób, którzy pracują często w znanych dużych firmach lub ciekawych startupach. Ludzi po kursie znajdują pracę jako specjaliści uczenia maszynowego, których miesięczna pensja (nawet juniora) często jest dwukrotnie większa niż cena kursu!
Społeczność i spotkania na żywo
DataWorkshop to już też społeczność zrzeszająca ponad 5 tys. osób. Część z nich, która aktywnie działa głównie na Slacku DW, zorganizowała się lokalnie w kilku miastach, aby spotykać się także na żywo w grupach warsztatowo-projektowych.
Aktualnie regularne spotkanie odbywają się w 11 miastach – w Katowicach, Rzeszowie, Warszawie, Łodzi, Krakowie, Lublinie, Poznaniu, Opolu, Olsztynie, Wrocławiu, Bielsko-Białej. W najbliższym czasie planowane są także spotkania w Trójmieście i Białymstoku. Tempo pracy i cele w poszczególnych miejscach są różne, wszystko zależy od grupy i tego, co chcą razem zrobić.
Idea spotkań na żywo zrodziła się oddolnie. Osoby, które chcą rozwijać się w uczeniu maszynowym spotykają się, aby wspólnie się uczyć i robić projekty, które często są użytecznie społecznie i rozwiązują lokalny problem. Obecnie trwają projekty dotyczące m.in. smogu, rowerów miejskich, predykcji zachowań i poglądów polityków, tworzenia notatek z konwersacji głosowych. Część projektów jeszcze się krystalizuje i jest w fazie planowania.
Wszystkie projekty stworzone w ramach spotkań DW są dostępne publicznie na Githubie.
Każda grupa ma lokalnych koordynatorów, którzy mocno angażują się w to, aby w wymienionych miastach odbywały się warsztaty, zaczynały i kończyły się projekty. Z tego miejsca chciałbym serdecznie podziękować im za zaangażowanie. Adrian Jany, Paweł Dulak, Krzysztof Dudek, Paweł Lubiński, Magdalena Cebula, Adrian Polens, Mariusz Grisgraber, Serhiy Chubyk, Marcin Bukryj, Łukasz Sawaniewski, Dariusz Gross, Arek Klemenko, Mariusz Rokita, Filip Kowalewski i Mirosław Mamczur, Piotr Soszka, Arkadiusz Kondas – ogromnie dziękuję Wam za wkład w rozwój społeczności DW.
Wsparcie firm
W roku 2019 zaczęliśmy spędzać więcej czasu na pomoc firmom we wdrażaniu uczenia maszynowego we właściwy sposób. Forma współpracy była różna: od wstępnych konsultacji, robienia projektów pilotażowych po przeprowadzenie całego procesu kończąc wdrażaniem na produkcję. Współpracujemy z różnymi firmami, nazwy większości jak na razie nie mogę wymienić. To są duże firmy, korporacje takie jak Oracle czy jedna z największych firm energetycznych.
W roku 2020 będziemy kontynuować tę gałąź, czyli wsparcie firm przy zastosowaniu uczenia maszynowego we właściwy sposób. Na ten moment oprócz wiedzy merytorycznej, która zdobywała się latami, też jesteśmy lepiej przygotowani do współpracy z większymi firmami.
I tak już całkiem na koniec…
Gdy nagrywam ten podcast, to trwa już okres świąteczny. Życzę Ci, żebyś w roku 2020 był lepszą wersją siebie w porównaniu z rokiem 2019. To już naprawdę dużo. Życzę też, żeby udało Ci się znaleźć czas na przemyślenia tego, co się dzieje. Dzieje się wiele. Tak naprawdę mimo mądrych słów ludzi, to i tak nie wiadomo, czym to wszystko się skończy.
Osobiście mam szereg obaw, że świat pędzi w bardzo złym kierunku, ale nadal mam nadzieję, że można to jeszcze zmienić. To zależy od nas. Postaraj się spędzić ten rok w taki sposób, żeby wewnątrz Ciebie było poczucie, że ten czas był poświęcony na właściwe rzeczy.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.

