

Sztuczna inteligencja i bezpieczeństwo

Czy wiesz, że zgodnie z raportem Capgemini, ponad połowa osób decyzyjnych w tematach bezpieczeństwa twierdzi, że analitycy cyberbezpieczeństwa są zbyt przytłoczeni bieżącymi zadaniami, na skutek czego 23% zidentyfikowanych incydentów nie jest skutecznie zbadanych?
Jak sobie z tym radzić? To bardzo zły znak, że analitycy odpowiadający za bezpieczeństwo firm nie są w stanie przetworzyć 100% znalezionych zagrożeń z odpowiednim zrozumieniem. Lekarstwem na ten problem może być właśnie sztuczna inteligencja.
W tym samym raporcie można znaleźć informację, że 48% badanych szacuje, że budżety na AI w cyberbezpieczeństwie wzrosną średnio o 29% w 2020 roku. Warto zauważyć, że taki wzrost nie jest naturalnym zjawiskiem, lecz wskazuje na to, że dostrzeżono, jak ważna jest stabilizacja w tym obszarze.
Spotkanie społeczności BiznesMyśli
Nim przejdę do głównego tematu, mam ważne ogłoszenie. 14 marca 2020 roku podcast BiznesMyśli będzie świętował 3 lata swojej działalności. Przez ten czas wydarzyło się wiele ciekawych rzeczy. Biblioteka podcastów liczy już 70 odcinków, w których wzięło udział bardzo dużo ciekawych gości, co zaowocowało ponad 160 tys. pobraniami.
Utwierdza mnie to w przekonaniu, że treści, które przygotowujemy w ramach BiznesMyśli są dla Ciebie ciekawe i wartościowe. Jeśli słuchasz podcastu regularnie, to już dużo wiesz na temat uczenia maszynowego. Poznałeś też mnie bardzo dobrze i teraz nadszedł moment, żebym to ja poznał lepiej Ciebie, prawda?
Jakiś czas temu zasugerowałem, że może warto spotkać się z okazji urodzin podcastu i prosiłem słuchaczy o wypełnienie ankiety. Bardzo Ci dziękuję, jeśli tam też jest Twój głos. Większość wybrała dzień spotkania w weekend. To akurat dobrze składa się, bo 14 marca to sobota.
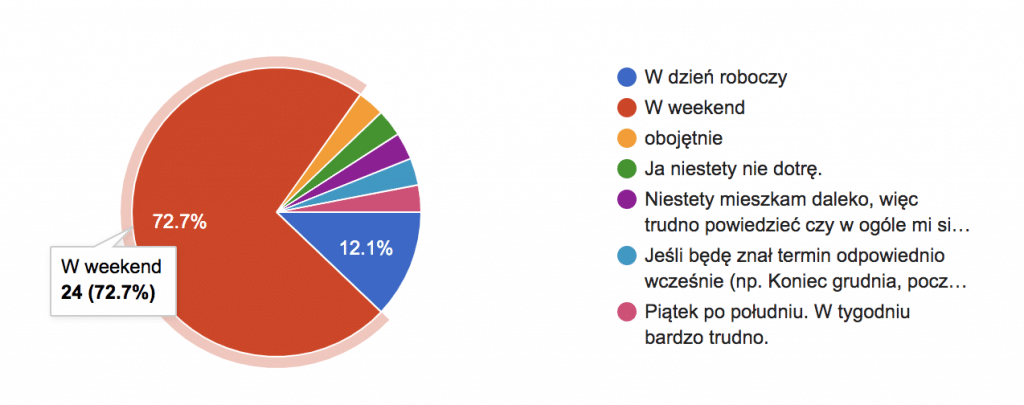
Tym samym zapraszam Cię na unikalne, pierwsze spotkanie BiznesMyśli. Odbędzie się ono w Krakowie w sobotę, 14 marca 2020r. Już mamy zarezerwowaną salę dla 50 osób. Natomiast, żeby dać równe szanse każdemu sprzedaż biletów ruszy 16 grudnia o 20:00. Zapisz się na newsletter, żeby dostać e-mail z przypomnieniem i linkiem do sklepu.
Jak dużo ludzi w Twoim otoczeniu interesuje się uczeniem maszynowym? Czy chcesz poznać osoby, które mają podobne zainteresowania do Ciebie i też słuchają podcastu BiznesMyśli? Być może chcesz poznać personalnie część gości z podcastu? Na tym spotkaniu będzie nawet coś więcej…
Zdradzę Ci tajemnicę: ostatnio mieliśmy gorącą dyskusję w zespole i próbowaliśmy odpowiedzieć na pytanie: co dalej? Czy warto rozwijać podcast? Jak to pogodzić z tym, że jestem dość zajęty oraz moją mocną stroną jest część merytoryczna, a nie cała otoczka, która jest równie potrzebna, a jednocześnie mocno angażująca?
Zdecydowaliśmy dalej się rozwijać, bo dzieją się fajne rzeczy i warto po prostu inwestować energię, czas i po prostu środki w tak wartościowe działania. Na dzień dzisiejszy w produkcję odcinków jest zaangażowanych 5 osób. Natomiast ogarnięcie całego procesu w tak zwanym międzyczasie staje się wyzwaniem. Stąd decyzja – zatrudnić redaktora naczelnego podcastu, rolą którego jest uporządkować cały proces i jeszcze bardziej podnieść jakość.
W tym momencie BiznesMyśli traktujemy jak prawdziwą redakcję, oczywiście dopiero zaczynamy materializować pomysły, więc daj nam trochę czasu, żeby zobaczyć te zmiany.
Wracając do spotkania na żywo, czyli 14 marca. To będzie moment, w którym będzie można wpłynąć na to, jak dalej będzie rozwijał się podcast. Chociaż, mówiąc “podcast”, to trochę za mało, ponieważ już planujemy zrobić coś więcej… ale pierwsi o tym dowiedzą się uczestnicy marcowego spotkania.
Wiem, że każdy jest zajęty, też ciągle z tym walczę, ale Twoja obecność będzie dla mnie podziękowaniem i powiedzeniem, że to, co udało się zrobić z podcastem przez ten czas, jest wartościowe dla Ciebie. Dla jasności dodam, też tam będę przez cały czas, po to, żeby lepiej Cię poznać.
Zapraszam też osoby spoza Krakowa na weekend, jest tu co robić 🙂
Webinarium “Jak sobie radzić z feature engineering?”
W czwartek 12 grudnia o 19:00 odbędzie się bezpłatne webinarium na temat “jak sobie radzić z feature engineering?”. Webinarium jest skierowane do osób, które chcą poznać machine learning od strony praktyczno-technicznej. Jeśli to przemawia do Ciebie – zapraszam.
Sztuczna inteligencja i bezpieczeństwo
Teraz wracamy do głównego tematu odcinka, mianowicie bezpieczeństwa oraz tak zwanej sztucznej inteligencji. W ramach spółki DataWorkshop, której jestem założycielem i prezesem, pomagamy firmom wdrażać uczenie maszynowe we właściwy sposób. Podczas jednej z ostatnich konsultacji rozmawialiśmy o bezpieczeństwie i to mnie zainspirowało, żeby strukturyzować różne kawałki mojej wiedzy i dzielić się tym z Tobą.
Przy okazji dodam, że bardzo chętnie angażujemy się w projekty, w których trzeba walczyć ze złem lub niesprawiedliwością. Osobiście cieszę się jak dziecko, kiedy świat staje się chociażby odrobinkę lepszy, bardziej sprawiedliwy.
W tym artykule omówię trzy logiczne obszary związane z bezpieczeństwem:
- Cyberbezpieczeństwo
- Ataki na modele uczenia maszynowego
- Anonimowe dane i bezpieczeństwo
O każdym z tych wątków można napisać osobny tekst, ale tutaj chciałbym wprowadzić Cię w ten temat, a w przyszłości rozwinąć poszczególne zagadnienia głębiej.
Zachęcam również do zapoznania się z 36 odcinkiem, w którym Hubert Rachwalski, CEO Nethone, opowiadał o tym, co robią w Nethone i o wykrywaniu oszustw.
Cyberbezpieczeństwo
Jak podaje CEO Cisco (Chuck Robbins, w ubiegłym roku Cisco zablokowało siedem trylionów zagrożeń, czyli 20 miliardów zagrożeń dziennie w imieniu swoich klientów (oznacza to ponad 200 ataków na sekundę). Ta liczba jest za duża, żeby w nią uwierzyć, ale podaję linki, skąd pochodzi ta informacja. Robi to wrażenie.
Ten problem nie dotyczy tylko USA, w Polsce też dzieje się sporo. Jedna z najbardziej gorących spraw, to morele.net. Urząd Ochrony Danych Osobowych nałożył karę 2,8 mln zł na internetowy sklep Morele.net. Ma to związek z atakiem hakerskim i wyciekiem danych klientów w październiku 2018 roku. Łącznie wyciekło 2,2 mln kont użytkowników. Sytuacja jest dość głośna, bo część osób apeluje, że takimi karami Urząd Ochrony Danych Osobowych motywuje hakerów do działania.
W pewnym sensie jest to kozioł ofiarny, dzięki czemu wiele firm uszczelnia swoje procedury z obawy przed karą. Niestety hakerzy nadal mogą wykraść dane, ale jak to bywa w urzędach, liczą się prawidłowe papierki, a nie realne działania.
Popatrzmy na świat oczami hakera. Oczywiście wielki biznes to smaczny kąsek, bo tam są duże pieniądze, ale jednocześnie są tak zwykle większe zasoby IT i większość luk jest zamknięta. Szanse na osiągnięcie czegoś cennego są niewielkie.
Zupełnie inna historia to średnie i małe firmy. Kompetencje pełnoetatowych specjalistów tam często pozostawiają wiele do życzenia. W rezultacie mamy nie tylko drobne luki w systemie, ale wręcz otwarte drzwi dla atakujących. Jeśli akurat prowadzisz firmę, w której nie ma zatrudnionego na cały etat zespołu bezpieczeństwa, to warto zatrzymać się na chwilę i zastanowić się jak i kiedy podjąć właściwe działania.
Zapraszam Cię do obejrzenia prezentacji “czy AI to srebrna kula w cyberbezpieczeństwie?”. Pierwsza połowa tej prezentacji to wprowadzenie kontekstu, czym jest tak zwana sztuczna inteligencja, ale potem są podawane przykłady użycia w firmie. Żeby zaoszczędzić Twój czas, opowiem o trzech przytoczonych w prezentacji przykładach.
Campaign Hunting
W tym przypadku chodziło o wykrywanie grup oszustw. Na przykład, ta sama grupa czy osoba ma tendencje się powtarzać tworząc np. złośliwy URL. Robi to w taki sposób, że w różnych miejscach można znaleźć pewne podobne elementy. Na skutek tego można próbować zautomatyzować mechaniczny proces i zrozumieć pewne atrybuty (ciągle nowe), które wpływają na to, że to działanie jest złośliwe.
Na skutek tej inicjatywy udało się zwiększyć jakość o 10%, czyli to, co wcześniej nie było wykrywane, udało się wykryć.
Huntress
W tym projekcie chodziło o to, że osoby, które próbują znaleźć dziury w systemie, nie piszą całego kodu od zera, zwykle wykorzystują gotowe komponenty i za tym stoi już pewna logika. Idea jest taka, żeby w środowisku testowym lub tak zwanej piaskownicy (sandbox) próbować przesuszać różnego rodzaju sztuczny lub mniej sztuczny ruch, żeby pewne rzeczy się wydarzyły i pojawiły się wzorce, na których model będzie mógł się nauczyć i następnie skutecznie wykrywać podejrzane ruchy na serwerach produkcyjnych.
W ten sposób udało się wykryć dodatkowe 13% procent zagrożeń.
CADET
Tak zwany Context Aware DETection. Jak oglądałem tę prezentację, to było pierwsze, o czym pomyślałem. Wiem, jak skuteczna jest analiza całego kontekstu i na ile dobre to wyniki może dawać. Używamy teraz regularnie takiego podejścia dla naszych klientów (o ile mają odpowiednie dane), bo wyniki zaskakują swoją jakością.
W tym przypadku był analizowany cały kontekst, np. jak powstał link, dokąd prowadził, jak zachował się użytkownik, czy gdzieś pod drodze był sms itd. Każdy proces wymaga od nas innych czynności, a każdy z nas może to robić inaczej. O tym nie było mówione w prezentacji, ale już czuć drzemiący w tym potencjał. Na przykład analizując taki kontekst można stwierdzić, w jakim stopniu dana osoba jest podatna na oszustwa. Ostatecznie w bezpieczeństwie najsłabszym ogniwem zawsze jest człowiek.
Inny przykład – PetSmart, popularny amerykański sklep zoologiczny, zaoszczędził $12 milionów wykorzystując AI do wykrywania oszustw. We współpracy z Kount, PetSmart wdrożył rozwiązanie, które bada miliony transakcji i ich wyniki. Inteligentny system określa legalność każdej transakcji porównując ją ze wszystkimi innymi przeprowadzonymi transakcjami. Wykryte fałszywe zamówienia są anulowane, co oszczędza pieniądze firmy bez szkody dla marki.
W jaki sposób wyliczono $12 milionów oszczędności? Śledząc oszustów internetowych w 2017 r. PetSmart mógł anulować prawie 4 miliony fałszywych zamówień. Koszt składa się z kilku komponentów: niepotrzebnego zaangażowania pracowników, kosztów wysyłki, kosztu towarów, obciążeń zwrotnych, opłat i grzywien, które mogą przełożyć się na $3-3,50 za każdego dolara w nieuczciwych opłatach, co daje łączną roczną kwotę około $12 milionów.
Jak widać, potencjał jest duży. Muszę w tym miejscu podkreślić, że ekspert od bezpieczeństwa nadal jest bardzo potrzebny. Problem jest w tym, że ekspertów trudno skalować (jest duży deficyt na rynku), więc machine learning może być bardzo dobrym asystentem i wsparciem w tej nierównej walce.
Trenowanie modeli machine learning
Przejdźmy do kolejnego obszaru,czyli potencjalnych zagrożeń w uczeniu maszynowym.
Model jest naiwny i wszystkiemu wierzy, ponieważ uczy się dosłownie na tych danych, które dostał. Jeśli w tych danych były pewne problemy, np. anomalia czy stereotypy społeczne, to model potraktuje to jako to, co istnieje i dopasuje się do rzeczywistości. Stąd pojawia się szereg problemów i te wszystkie tak zwane “biasy”, np. błąd poznawczy.
Zaburzone dane
Teraz mówiłem o przypadku, kiedy model uczył się na danych. Dane są brudne (bo tak zwykle jest), ale nikt świadomie nie próbował wprowadzić modelu w błąd. Teraz pomyśl inaczej. Co jeśli ktoś, chce oszukać Twój model w ten czy inny sposób i zaczyna generować sztuczne dane? Robi to, żeby zaburzyć rozumienie.
Jakiś czas temu robiłem projekt o wykrywaniu oszustw dla amerykańskiej firmy związanej z ubezpieczeniami. Zrobiłem wtedy projekt pilotażowy i udało się znaleźć kilka ciekawych rzeczy. Po pierwsze czynniki, które wpływały na to, że dana sprawa jest oszustwem czy nie, okazały się inne niż zakładano. Na przykład bardzo mocno wpływała na to ocena osoby, która zgłaszała szkodę. Gdyby analizować głębiej, można było znaleźć zależności, które wskazywały na podobieństwa między zgłaszającymi osobami i stwierdzić, że tworzą grupy czy wręcz organizacje.
Druga rzecz to jakość modelu. Wynik był całkiem dobry – ponad 90% precyzji. Natomiast, jak to zwykle bywa, gdy zaczynasz drążyć temat, to pojawia się szereg pytań. W jaki sposób w bazie pojawia się informacja, że dana sprawa jest oszustwem? Odpowiedź: to jest praca manualna odpowiednich ludzi (rozsianych po Stanach). To już brzmi mało stabilnie, bo ludzie nawet z procedurami działają różnie (pytanie tylko jak bardzo różnie).
Kolejna rzecz, która jest jeszcze ważniejsza, to przy takim podejściu nie ma żadnej gwarancji, że to było oszustwo, bo tak naprawdę to są jedynie wykryte oszustwa przez manualne procedury, pozostaje pytanie jak dużo zostało pominięte? Wtedy zaproponowałem eksperyment, żeby sprawdzić sprawy, które przed tym nie były oznaczone jako oszustwo, ale model z dużym stopniem pewności twierdzi, że są. Nie znam wyniku, bo tej informacji już nie dostałem, ale myślę, że w ten sposób udało się wykryć kolejną warstwę przypadków, które wcześnie były ignorowane.
Dlatego jest tak ważne uważać na dane, na których model się trenuje, uświadamiać sobie, w jaki sposób te dane powstały. Kto był zaangażowany w ten proces? Czym się kierował (wiedza, motywacja itd.)? Model traktuje dane na poważnie, beż żadnego filtru krytycznego. Są pewne triki, jak można z tym walczyć i wykrywać pewną niespójność w danych, ale to temat na inną okazję.
Widzenie komputerowe
Inny problem związany jest z widzeniem komputerowym (ang. computer vision). Wyobraź sobie, że masz model, który daje bardzo dobry wynik, np. rozpoznaje, że dany obiekt to znak drogowy, banan lub coś innego. Wystarczy nakleić przylepkę na ten obiekt lub obok i wynik z prognozowania modelu może nagle stać się zupełnie inny.
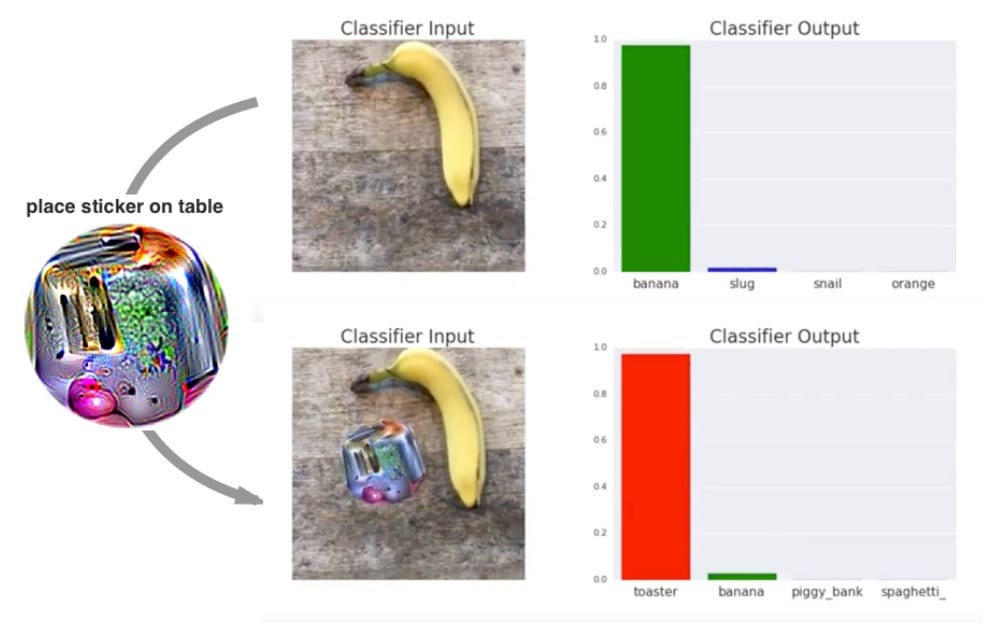
Najciekawsze jest to, że na tej przylepce zwykle jest coś bardzo abstrakcyjnego.

Źródło: artykuł Adversarial Patch

To jest problem i to dość złożony, bo nie da się tak łatwo tego obejść. To jest w pewnym sensie hackowanie neuronów sieci wiedząc, gdzie mają słabe miejsca i przy pomocy innych sieci tworzenie takich kształtów, które wpłyną na wynik.
Są też inne publikacje na ten temat, np. zespołu Google Brain, który ten wątek kontynuuje, więc jeśli dla Ciebie to jest ciekawe, to zapraszam do dalszej lektury.
Już wiesz, że model jest bardzo czuły na dane, na których się uczy i można go oszukać podając odpowiednio przygotowane dane na wejściu. Model nie ma krytycznego myślenia.
Kopiowanie modelu
Wyobraźmy sobie, że mamy gotowy model. Ten model jest wdrożony i jest tajemnicą naszego przedsiębiorstwa. Wszystko jest tak zrobione, że ciężko sam model będzie skraść. Nasz system jest bardzo szczelny i zespół nad tym czuwa. Czy to oznacza, że można spać spokojnie? Okazuje się, że można częściowo lub nawet więcej skopiować model, nie kopiując fizycznie oryginału. Jak?
Już podaję Ci przykład. Załóżmy, że masz wytrenowany bardzo dobrej jakości model, o którym Twoja konkurencja może tylko marzyć. Zainwestowałeś w to cały majątek i cieszysz się, że masz takie fajne rozwiązanie. W momencie, w którym umożliwiasz innym korzystanie z tego modelu (może to być Twoją usługą), pojawia się co najmniej jedno niebezpieczeństwo.
Osoba, która zaczyna wysyłać dużą ilość zapytań i dostaje odpowiedzi z Twojego modelu, może na podstawie tych danych wytrenować nowy model, który będzie zachowywał się podobnie. Stąd trzeba pomyśleć, jak można zapobiec tego typu atakom.
Ten problem wcale nie jest taki trywialny. Jeśli Twój model faktycznie jest bardzo wartościowy, to lepiej nie wystawiać go na zewnątrz lub wprowadzić dodatkową warstwę, która znacząco utrudni wyżej opisane zagrożenie. Takim zabezpieczeniem może być np. konieczność rejestracji – wtedy jest łatwiej ograniczyć liczbę żądań. Warto zastosować pewne ograniczenia przy zakładaniu kont, np. podanie numeru telefonu. Czym bardziej wartościowy jest model, tym większa jest konieczność zabezpieczenia się przed atakami.
Anonimowość danych
Czy wiesz, że żeby zrobić zbiór danych anonimowym, to naprawdę trzeba się postarać? Żyjemy w czasach, kiedy zostawiamy mnóstwo cyfrowych śladów. Uczynienie tylko oczywistych informacji anonimowymi, np. usunięcie imienia, nazwiska czy adresu email już nie jest wystarczające. Opowiem Ci trzy historie, które mogą bardziej Ci wyjaśnić kontekst.
Nowojorskie taksówki
Pierwsza to zbiór danych taksówek z Nowego Jorku. To bardzo ciekawa historia, bo z jednej strony w tym zbiorze danych nie było podanego imienia i nazwiska pasażerów, więc może się wydawać, że ciężko w ten sposób wyciągnąć dane personalne, a jednak…
Dotkniemy teraz świata celebrytów, którzy są śledzeni na każdym kroku. W praktyce to oznacza, że są zdjęcia w internecie, na których widać nr taxi, miejsce oraz kto tam przyjechał (lub odjechał). Na przykład, wpisując do Google “celebrities in taxis in Manhattan in 2013”, można zobaczyć to na przykładzie. W ten sposób te dane stają się bardziej personalne. Można w ten sposób zobaczyć, dokąd pojechała dana osoba, może gdzie mieszka lub gdzie mieszkają jego czy jej bliscy.
Statystyki Netflixa a IMDb
Netflix zorganizował jakiś czas temu konkurs i opublikował dane, które teoretycznie były anonimowe. Faktycznie z tych danych, ciężko było wnioskować cokolwiek więcej. Znów chodzi o zachowanie i powiązania. Istnieje osobny projekt z opiniami o nazwie IMDb. Okazuje się, że ludzie wyrażali swoją opinię po filmie w obu miejscach mniej więcej w tym samym czasie. Natomiast w IMDb już jest więcej informacji o użytkowniku, np. login. Łącząc te dane można już wyciągnąć znacznie więcej informacji m.in. poglądy polityczne lub inne w zależności o treści wypowiedzi.
Aplikacje sportowe
Jeśli biegasz lub jeździsz rowerem, to pewnie kojarzysz aplikację Strava. W roku 2017 opublikowany został anonimowy zbiór danych użytkowników. Wyglądało to dość bezpiecznie, ale coś poszło nie tak. Żołnierze trenują regularnie, żeby mieć odpowiednią kondycję. To jest naturalne.
Natomiast żołnierze z Ameryki są dość nowocześni i używają właśnie podobnych aplikacji jak Strava. Analizując aktywność użytkowników na mapie można znaleźć regularną aktywność w dość ciekawych rejonach, np. Syria czy Afganistan. To, co było tajemnicą, w tak prosty sposób staje się danymi publicznymi. Tutaj możesz znaleźć więcej szczegółów.
Jak widzisz, udostępnienie danych publicznie może stać się nie lada wyzwaniem, chociaż to wcale nie oznacza, że nie warto tego robić. Wbrew pozorom, bardzo cieszę się, że w Polsce dane stają się coraz bardziej publiczne. Dzięki temu nie tylko ekskluzywna grupa ludzi czy firm, może je analizować, ale również każdy, kto chce. To jest dobry trend i warto, żeby się rozwijał, tylko trzeba być bardziej świadomym tego, że czasem coś może pójść nie tak :).
Bezpieczeństwo jest niezwykle ważnym elementem każdego przedsiębiorstwa i dotyczy także uczenia maszynowego. Z każdym nowym rozwiązaniem zawsze wiążą się pewne zagrożenia, na które należy się odpowiednio przygotować. To w Twojej gestii i interesie jest, aby Twój biznes mógł prawidłowo i efektywnie funkcjonować zapobiegając zagrożeniom, których można naturalnie się spodziewać.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.

