
Sztuczna inteligencja w przemyśle

Przemysł (a tym bardziej przemysł ciężki) żyje swoim własnym życiem. Dość często jest on mocno oderwany, chociażby od świata IT. Oczywiście to zmienia się z czasem. Na przykład, Andrew Ng – ekspert sztucznej inteligencji, który pracował w Google/Baidu, również założył jeden z najbardziej znanych serwisów edukacyjnych – coursera.org. W grudniu 2017, przynajmniej formalnie, rozpoczął nowy projekt o nazwie landing.ai. Celem tego przedsięwzięcia jest wspomaganie przemysłu w wykorzystywaniu mocy uczenia maszynowego.
Ma on już podpisaną umowę o współpracy z FoxConn, która jest największym producentem elektroniki i komponentów komputerowych na świecie. Między innymi, produkuje Macbooki, iPhony, iPody, Xboxy, Kindle, laptopy marek HP i Dell. Mówiąc w skrócie, cała elektronika, którą znamy pod różnymi brandami jest produkowana właśnie przez FoxConn. Mają oni gigantyczne obroty – ok. 150 mld. dolarów. To stanowi ok. jednej trzeciej polskiego PKB.
Osobiście uważam, że w przemyśle, tym bardziej w przemyśle ciężkim, dzięki uczeniu maszynowemu, można wiele zrobić. Wystarczy usprawnić proces o jeden procent i już z tego robią się bardzo duże kwoty. Dość często jest tak, że przemysł jest bardzo zacofany, wtedy można usprawnić proces nawet i o 5% czy 10%. W takiej sytuacji, są to już miliony czy nawet dziesiątki milionów dolarów.
Największy techniczny problem, który dostrzegam – to dane. Zwykle ich nie ma, albo są bardzo źle zbierane. Natomiast, największy strategiczny problem, to dojrzewanie kierownictwa do decyzji, że warto to zastosować. Przy czym, jeśli rozwiązać strategiczny problem, to pierwszy też się rozwiąże (wystarczy trochę czasu, żeby zamontować odpowiednie urządzenia/sensory i zacząć gromadzić dane).
Jeśli jesteś z sektora przemysłu i potrzebujesz pomocy z uczeniem maszynowym, konsultacji jak się do tego przygotować, proszę daj mi znać. Postaram się Ci pomóc.
Dzisiejszym gościem jest Teresa Kurek, która pracuje w Transition Technologies i miała możliwość budować model do optymalizacji pracy młyna węglowego.

Teresa po raz pierwszy brała udział w podcaście i trochę się denerwowała, mam nadzieję, że jej to wybaczysz. Zapraszam do wysłuchania tego odcinka, dowiesz się więcej o problemie, jak i rozwiązaniu, nad którym pracowała Teresa wraz ze swoim zespołem.
Cześć Teresa! Proszę przedstaw się, kim jesteś? Czym się zajmujesz? Gdzie mieszkasz?
Cześć Vladimir, bardzo miło mi Cię poznać. Witam serdecznie wszystkich słuchaczy! Na początku chciałam Ci bardzo podziękować za zaproszenie mnie do tego podcastu, ponieważ będzie to mój debiut. Miałeś tutaj naprawdę wielu wspaniałych gości, bardzo się cieszę, że dołączę do tego wspaniałego grona. Ja nazywam się Teresa Kurek, obecnie mieszkam w Warszawie, gdzie pracuję w dziale badawczo-rozwojowym w firmie Transition Technologies, w tym roku rozpoczęłam też doktorat w trybie wdrożeniowym.
Może krótko powiem co to jest doktorat w trybie wdrożeniowym, bo to jest dość nowa formuła, która pojawiała się właśnie w tym roku, w październiku rozpoczęła się pierwsza edycja. Ideą tego doktoratu było przybliżenie nauki do biznesu, ponieważ doktorant, który rozpoczyna studia zostaje zatrudniony w wybranej przez siebie, bądź też wskazanej przez politechnikę, czy jakąkolwiek inną uczelnie, firmie gdzie na pełny etat wykonuje wskazane przez firmę zadanie, jakiś problem, który musi być innowacyjnym projektem.
Następnie ten problem zostaje wdrożony, to zazwyczaj firma definiuje gdzie ma on zostać wdrożony. Taki doktorant otrzymuje dwóch promotorów, pierwszy to promotor naukowy na wydziale, na którym się doktoryzuje. Drugi to promotor pomocniczy z tej firmy – osoba, która pomaga Ci przejść przez ten cały proces. Na koniec Twój problem, który jest problemem rzeczywistym, wdrożonym, jest odpowiedzią na rozwiązanie jakiegoś problemu, jest podstawą Twojego doktoratu. Takie są moje dwie główne aktywności, które zajmują bardzo dużo czasu.
To brzmi bardzo ciekawie, się cieszę, że świat akademicki łączy się z biznesem. Są tutaj pewne wyzwania.
Tak, ja jak tylko dowiedziałam się o takim doktoracie… To była bardzo szybka akcja, bo w maju była rekrutacja, a w czerwcu były już wyniki. Ponieważ do takich firm, które mają działy badawczo-rozwojowe, gdzie zajmujemy się głównie problemami, które są nowe, do których nie mieliśmy jeszcze żadnych podejść. To jest naprawdę świetne rozwiązanie. Ja tutaj akurat byłam pierwsza i pytałam się gdzie, jakie wnioski trzeba składać, żeby tylko móc coś takiego robić.
O firmy i o to co dokładnie robicie jeszcze zapytam, ale teraz pytanie: co ostatnio czytałaś?
Może troszkę Cię zaskoczę bo nie będzie to nic branżowego. Nie tak dawno założyłam rodzinę, a ponieważ lubię się doskonalić w dziedzinach, które są dla mnie ważne to czytam teraz książkę „7 nawyków szczęśliwej rodziny„. Jest to książka Steven’a Covey’a.

Pierwszą książką tego autora, którą przeczytałam było „7 nawyków skutecznego działania„, nie wiem czy ją kojarzysz, ale myślę, że wiele osób powinno. Jest to bardzo przydatna książka ucząca podejścia do życia, zwracająca uwagę na wiele istotnych rzeczy, kształtująca charakter, nie tylko ucząca zarządzaniem sobą w czasie, ale ucząca zdrowego podejścia do życia.
Jak się doskonalić w tych elementach, częściach życia, które są dla Ciebie bardzo ważne. Ta książka – „7 nawyków szczęśliwej rodziny” – jest przełożeniem tych nawyków skutecznego działania na rodzinę. Od razu powiem, że nie jest to takie proste. Książkę „7 nawyków skutecznego działania” czytałam rok temu, a obecnie jestem na nawyku trzecim. Dość ciężkie jest to do wdrożenia, ale przynosi bardzo ciekawe rezultaty, więc polecam.
Faktycznie książka zapowiada się ciekawie, akurat już jestem młodym rodzicem i wiem jak jest bardzo ciężko, mam naprawdę bardzo dużo zaległości i jest to jedna z książek, którą chciałbym przeczytać. Wracając do firmy, o której wspomniałaś, pracujesz w Transition Technologies. Powiedz dokładnie, czym się zajmujecie? Jakie problemy rozwiązujecie? I jak to naprawdę robicie? Jakie są wasze wyzwania operacyjne?

Transition Technologies jest to polska firma, obecnie zatrudnia ponad 1000 osób, więc nie będę mówić o wszystkich jej częściach, ponieważ mamy wiele działów. Generalnie tworzymy systemy IT, w szczególności dla przemysłu, naszą perełką jest energetyka. Sama jestem inżynierem energetykiem. Mocno rozwijamy się teraz też w medycynie.
Jakie rozwiązujemy problemy? To są na przykład optymalizacje. Jednym z bardziej znanych i spektakularnych wyników jakie otrzymujemy to jest optymalizacja spalania. Ten system był inspirowany systemem immunologicznym człowieka, czyli to jest rozwiązanie stricte machine learning.
Duże projekty jakie mamy? Teraz jesteśmy na finiszu dużego projektu – optymalizacja warszawskiej sieci ciepłowniczej. Dla przykładu powiem, że stworzyliśmy około 50 – 60 tysięcy modeli prognostycznych, około 18 tysięcy modeli, które są wejściem do optymalizatora, który ma 10 tysięcy ograniczeń – sporo pracy zostało tam wykonane i wyniki też zapowiadają się ciekawie.
Tworzymy też modele prognostyczne, sama brałam udział w kilku projektach, gdzie je tworzyliśmy. Mamy też mniejsze projekty rozwojowe, mamy dział badawczo-rozwojowy, mamy status placówki badawczo-rozwojowej gdzie staramy się tworzyć nowe rozwiązania. Teraz bardzo mocno skupiamy się na machine learning, data dcience. Mamy naprawdę dość silny zespół zarówno w energetyce, jak i w medycynie.
Wow! Będę dopytywać jeszcze o szczegóły. Powiedziałaś ciekawostkę, że skończyłaś energetykę, z tego co wiem na Politechnice Warszawskiej. Jak to się stało, że zajmujesz się uczeniem maszynowym?
To jest dobre pytanie, ponieważ wydział, który skończyłam to Wydział Mechaniczny Energetyki i Lotnictwa nie było tam praktycznie żadnych zajęć w tym temacie, może poza sieciami neuronowymi.
Akurat miałam to szczęście, że spędziłam rok na wymianie studenckiej w Mołdawii gdzie miałam trochę wolnego czasu i nie za bardzo mogłam się tam rozwijać w kierunku inżyniera energetyka, więc postanowiłam ten czas wykorzystać na samorozwoju. Zaczęłam szukać ciekawych rzeczy, które mogłabym robić.
Przeszukiwałam Internet, znalazłam Coursera i kursy online, gdzie wybrałam takie, które mnie interesowały. Wtedy jeszcze nie wiedziałam, że nazywa się to machine learning czy uczenie maszynowe. Nie wiedziałam, że uczę się modelowania. Po prostu zaczęłam się bawić danymi, wizualizować je, wykorzystywać je do wyciągania sensownych wniosków.
Potem szukając promotora do mojej pracy magisterskiej trafiłam na firmę Transition Technologies, mój obecny szef też wykłada na tym wydziale. Tak to się zaczęło, trochę z ciekawości, trochę z chęci samorozwoju, jestem samoukiem można by rzec.
Bardzo dobrze, uwielbiam samouków, o to też będę dopytywać bo mam podobne podejście i wydaje mi się, że to jest bardzo pragmatyczne podejście do rozwiązywania zadań. Zastanawiam się teraz, jaka jest Twoim zdaniem wartość dodana tego, że masz wiedzę czysto inżynieryjską oraz doświadczenie, które zdobyłaś na studiach?
Projekty, którymi się zajmuję są bardzo mocno powiązane z energetyką. Tak naprawdę to wszystkie one są powiązane jak nie z energetyką to z przemysłem. Tutaj moja wiedza inżynierska ma tę zaletę, że gdy dostaję problem do rozwiązania to już go mniej więcej rozumiem. Nie potrzebuję spędzać czasu nad zrozumieniem go.
Na przykład, gdy waliduję dane to nie tylko potrafię oddzielić outliers czy wyłapać proste zależności, ale ja wiem jak urządzenie działa. Jeżeli to jest jakiś młyn węglowy to ja wiem, że takie wartości, patrząc na dane, wykresy wydawałyby się normalne, to ja wiem, że powinnam je odrzucić bo wtedy działo się tam coś nie tak.
Jestem w stanie to zobaczyć bo wiem mniej więcej jak działa to urządzenie. Myślę, że tu jest bardzo dużo wartość dodana. Zwłaszcza, że proces walidacji danych i przygotowania ich do modelowania to jest 80% sukcesu. Mamy czasem takie projekty, w których współpracujemy z osobami, które są po matematyce i widzę, że moje podejście pozwala mi troszkę lepiej zrozumieć te dane, na przykład tworzyć dodatkowe cechy. Ponieważ wiem, że te dwie cechy są od siebie mocno zależne i być może powinnam stworzyć z nich jakąś jedną.
Dodatkowo, jeszcze to co jest fajnie, tworząc jakiś model dużo łatwiej jest mi ocenić wyniki, bo wiem jak to urządzenie działa. Wiem czy takie wyniki są sensowne czy mogą się zdarzyć takie przypadki jakie dostaje z modelu czy są jakieś wyniki mocno odbiegające. Tu uważam jest duża wartość osoby, która zaczynała od wiedzy inżynierskiej, a dopiero potem przeszła do machine learning.
To jest ciekawe. Zgadzam się, że osoba, która zna się na co najmniej dwóch rozłącznych rzeczach, jak energetyka i machine learning, ma dużą przewagę. Czytałem kiedyś taki artykuł, że edukacja mniej więcej może wyglądać tak jak teraz, ale wszędzie pojawi się + uczenie maszynowe, czyli energetyka + uczenie maszynowe, medycyna + uczenie maszynowe itd.
Generalnie radzenie sobie z danymi. Czasami w pracy zastanawiamy się jaka byłaby lepsza droga. Najpierw zostać energetykiem i potem uczyć się uczenia maszynowego? Czy odwrotnie, najpierw nauczyć się uczenia maszynowego, a potem energetyki? W sumie, nie wiem gdzie mógłby być tutaj złoty środek.
Moim zdaniem, dobrze jest zacząć od wiedzy inżynierskiej. Natomiast mój szef zaczął odwrotnie – on jest informatykiem, dopiero potem uczył się energetyki, a stworzył taki optymalizator oparty na tym, o czym wspominałam, czyli inspirowany system immunologiczny. Jak widać obie drogi są możliwe, aczkolwiek mi moja się podoba.
Teraz chcę już przejść do ciekawostek jeżeli chodzi o zastosowanie uczania maszynowego na Twoim przykładzie. Zanim zaczniemy omawiać ten technologiczny przykład, to wyjaśnij proszę prostym, zrozumiałym językiem, jaki był problem i jak sobie z nim radziliście wcześniej?
Tutaj wracamy do tematu skąd w ogóle wziął się pomysł, żeby zrobić ze mną podcast, czyli do mojej prezentacji na Warsaw Data Science Meetup. Opowiadałam tam o przypadku, który moim zdaniem jest świetny do pokazania tego jak można wykorzystać uczenie maszynowe w przemyśle. To jest temat bieżącej diagnostyki online młyna węglowego.
Tutaj muszę wspomnieć, że nie robiłam tego projektu od samiutkiego początku, tylko weszłam na początkowym etapie, kiedy już mieliśmy zebrane dane. Aczkolwiek, sama idea rozwiązania została stworzona przez kogoś innego. Natomiast podczas wdrażania optymalizatora na jednym z bloków w elektrowni powiedzieli nam, że „fajny jest ten optymalizator, może zrobilibyście też coś z młynami?
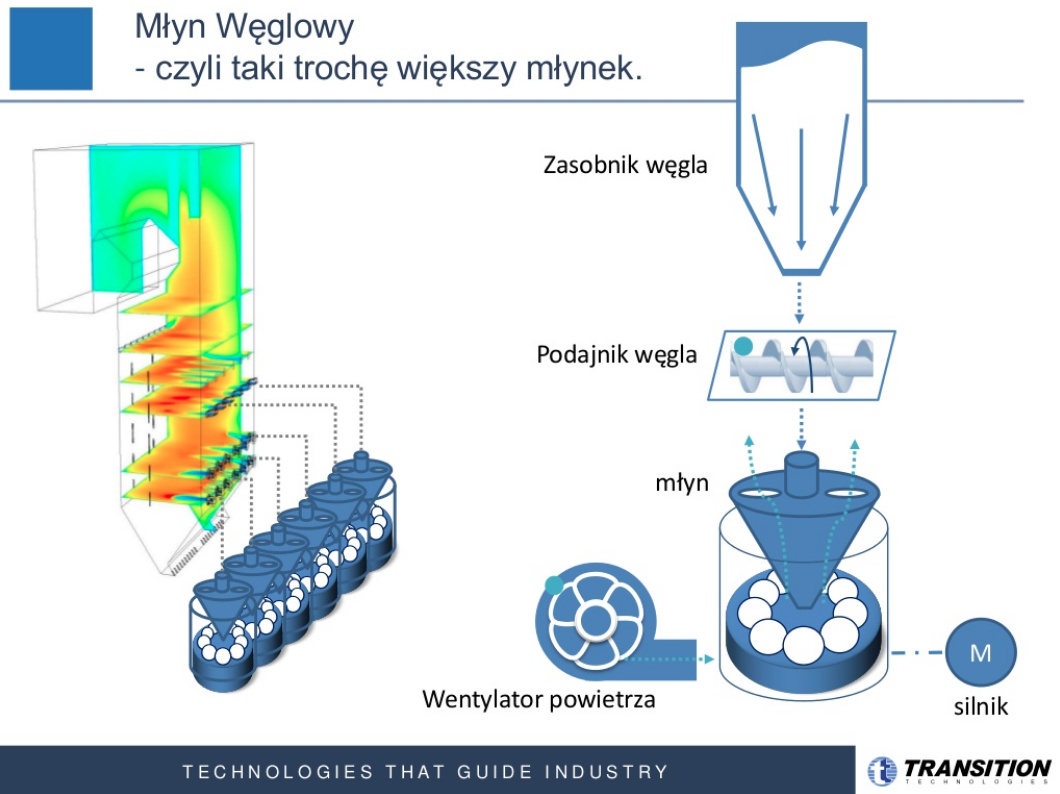
Bo my z nimi mamy taki problem, że mamy ich 5-6 pracujących na raz i musimy je obserwować, a mamy jeszcze szereg innych urządzeń. A chcielibyśmy wiedzieć czy z nimi jest wszystko ok czy nie. Może wpadlibyście na jakieś rozwiązanie?”. W sumie stąd wzięła się idea tego pomysłu. Wcześniej operator patrzył głównie na 2 parametry, ale cały czas musiał mieć je na oku. Jest tutaj 5 pracujących młynów, kocioł, turbina, coś tam jeszcze i pracownik musi to wszystko analizować, a chciałby mieć taki podpowiadacz, który by mu pomógł, żeby czasami mógł on trochę odpocząć i nie patrzeć na te parametry.
Dla osób, które pracują w innych branżach, możesz wyjaśnić czym jest taki młyn? Jak on wygląda jeżeli chodzi o rozmiar i co dzieje się w jego wnętrzu?
Młyn węglowy to urządzenie, które mieli węgiel, ten węgiel, który się podaje jest już wstępnie zmielony, ale on go mieli na pył, miesza z powietrzem i dodaje do kotła, gdzie jest spalany. To jest młynek jak do kawy, gdzie mamy ziarna, które mielimy na pył, tylko jest on zdecydowanie większy, jest 3 razy wyższy od człowieka, w środku ma kule, które mielą węgiel, od spodu podawane jest powietrze.

To wszystko miesza się i następnie jest podawane do kotła, gdzie następnie jest spalane. To jest taka mieszanka paliwowo-powietrzna. Problemy jakie możesz mieć? Na przykład, możesz podać za dużo węgla i wtedy są problemy ze zmieleniem albo możesz nie podać węgla i wtedy też pojawia się problem. To są dwa podstawowe problemy jakie można mieć.
Ten model dokładnie to rozwiązuje?
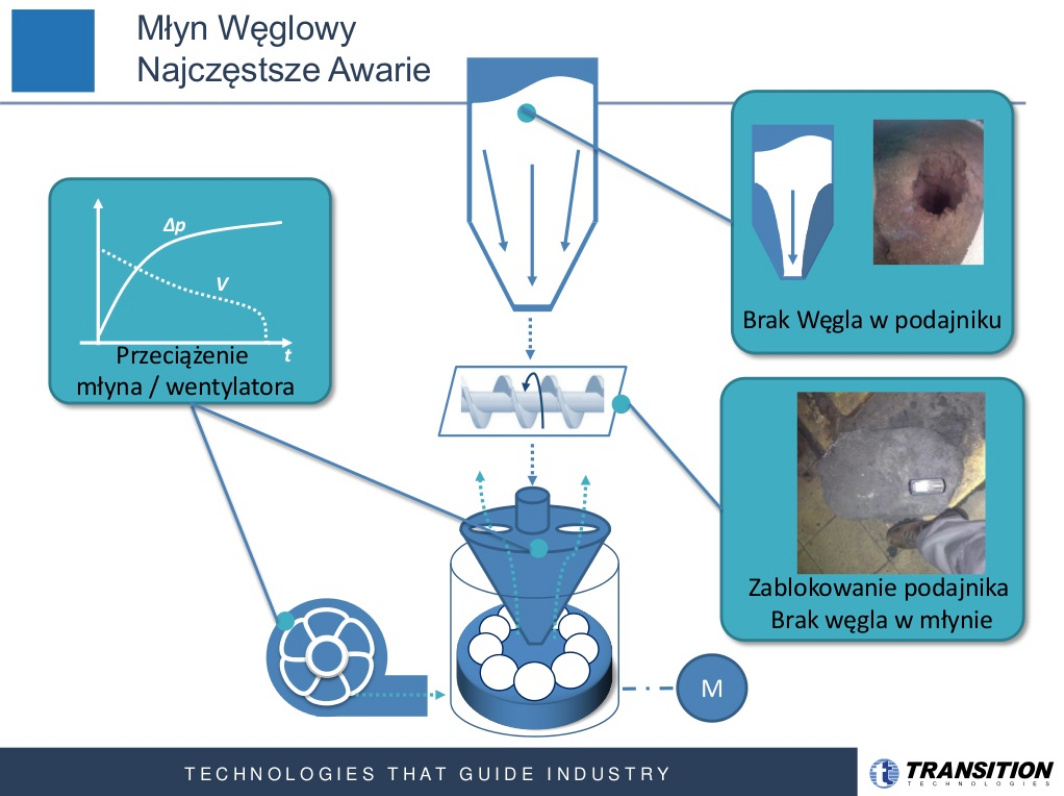
Aby rozwiązać ten problem, postanowiliśmy trochę skopiować to co robią operatorzy. Oni mimo, że mają mierzonych około 30 parametrów, które mogą obserwować, to patrzą tylko na dwa. My wzięliśmy te parametry i stworzyliśmy ich modele. Wykorzystaliśmy ideę digital twin, gdzie tworzymy cyfrowy odpowiednik pomiaru urządzenia. Stworzyliśmy cyfrowy odpowiednik pomiaru, stworzyliśmy dwa modele i patrząc na różnicę w czasie rzeczywistym, na jej podstawie generujemy sygnał diagnostyczny, który mówi o tym, jak pracuje młyn. Określa on czy jest to praca normalna czy jest może jakaś anomalia, czy może jest to jakiś stan, który zaraz doprowadzi do awarii. Tak naprawdę generujemy trzy stany i wysyłamy te informacje do operatora. Jeżeli generujemy sygnał mówiący, że jest to sytuacja prowadząca do awarii to wysyłamy też taki dodatkowy sygnał do operatora na specjalnym wyświetlaczu. Dostaje on informację, że jest to młyn ten i ten, spójrz na niego bo może coś tam się dzieje.
A na czym polega ta anomalia? Na przykład, za dużo węgla to będzie anomalia?
Tak, na przykład, gdy dodaje się za dużo węgla, to już jest anomalia, bo wtedy podajemy za mało paliwa do kotła. Gdy już nie dajemy rady mielić to paliwo nie jest wypluwane do kotła. Albo nie podajemy wcale przez co młyn może się zapalić, ponieważ podawane powietrze jest bardzo gorące albo coś się zalepia. Można sobie wyobrazić taki młynek, tylko na większą skalę i tam oczywiście różne rzeczy mogą się dziać.
Rozumiem. Czy to rozwiązanie już zostało wdrożone, jak to mówi się w IT, na produkcję? Czy jeszcze jest to prototyp?
Takie pilotażowe wdrożenie mieliśmy w elektrowni. Wdrażaliśmy to dla jednego młyna, to była właśnie moja praca magisterska. Tam pokazywaliśmy to operatorom, zostało to zainstalowane i to już od jakiegoś czasu działa. Możemy obserwować w czasie bieżącym jak to wygląda, aczkolwiek komercyjnego wdrożenia jeszcze nie mieliśmy.
Mamy już rozmowy z inną elektrownią, żeby wdrożyć to na całym zespole młynowym i ewentualnie może rozszerzyć o jakieś dodatkowe rzeczy. Sami mamy już wiele pomysłów jak dalej rozwijać ten produkt, więc mamy szerokie pole do popisu.
Myślę, że warto powiedzieć na konkretach, jakie są korzyści tego rozwiązania? Jak wy to zmierzyliście? Czy to jest teoretyczne, czy zmierzyliście to w praktyce?
Uważam, że takie wdrożenie byłoby bardzo sensowne. Jeżeli nie wyłapiemy jakiejś awarii to wtedy wypada nam młyn, czyli nie podaje on już paliwa do kotła, generujemy mniej mocy co jest stratą pieniężną dla elektrowni.
Każde nieplanowane wypadnięcie młyna to jest strata pieniężna, którą jesteśmy w stanie przeliczyć, ale akurat tutaj nie chcę podawać konkretów. Jeżeli młyn źle działa i daje mniej paliwa niż powinien, a nam się wydaje, że działa prawidłowo, to proces spalania przebiega nieoptymalnie i efektywność przemiany jest mniejsza, co również generuje straty.
Wiadomo, że straty to strata pieniędzy. Tutaj da się to przeliczyć liczbowo, ale nie chciałabym podawać konkretów póki nie mamy wdrożenia produkcyjnego. Największą wartością jest to, że gdy wypada młyn, czego ty nie wyłapiesz, to masz spadek na mocy, a często elektrownia jest zobligowana, żeby generować jakąś moc w danym momencie.
Myślę, że tak jak mówisz, gdy wypada młyn to osoby, które się na tym znają mogą łatwo wyliczyć jakie są straty. Wydaje mi się, że te straty są ogromne.
Możesz sobie to tak wyobrazić, po nitce do kłębka. Młyn to jest pierwszy element w procesie, gdy on wypada to dzieje się już coś w drugim elemencie, a to się już propaguje na cały proces. Powinniśmy zaczynać od tych początków. Uważam, że to jest ważne w tym przypadku.
Tak, to prawda. Jak najbardziej to popieram, bardziej chodziło mi o to, żeby zmierzyć to na liczbach. Ze swojego doświadczenia wiem, że gdy rozmawiasz z ludźmi biznesu lub z zarządem, to jeden argument, że to jest ważne, ale drugi argument to zaoszczędzenia miliona złotych. Ten drugi bardziej przemawia.
Zapytam teraz może mniej biznesowo, ale bardziej technicznie. Jakie miałaś wyzwania podczas realizacji, w sumie jakie mieliście wyzwania, bo powiedziałaś, że było kilka osób zaangażowanych i ile zajęła wam czasu ta cała realizacja?
Cała realizacja zajęła nam około 5 miesięcy. Tak naprawdę od samego pomysłu do wdrożenia i patrzenia na ekran, gdzie już system działał. Dla mnie to doświadczenie było o tyle ciekawe, że to był mój pierwszy prawdziwy projekt branżowy, zaczynałam wtedy pracę, bardzo dużo się tam uczyłam.
Byłam samoukiem i tutaj rozwijałam się na wszystkich możliwych frontach, głównie uczenie maszynowe. Spotkałam się też z tym, gdy byłam na elektrowni… Przychodzi do pana młoda dziewczyna i mówi, że ma taki soft, który będzie mu podpowiadał i mówił kiedy młyn pracuje nieprawidłowo, a kiedy prawidłowo.
Przy starszych operatorach spotykałam się z pewną niepewnością, jednak to czego ludzie się boją w uczeniu maszynowym to, że będziemy im zabierać pracę, że tworzymy systemy, które będą inteligentne, będą w stanie nas zastąpić przez co ja nie będę miał pracy. Trochę to odczułam, chociaż młodsi operatorzy byli pozytywnie nastawieni i pomagali mi to testować.
Tak naprawdę, miałam wyzwania na dwóch polach. Pierwsze to było wykorzystanie w jak najlepszy sposób wiedzy teoretycznej, bo wcześniej nie wykonywałam żadnego rzeczywistego modelu, który potem już wdrożyłam na prawdziwym obiekcie, który działa i funkcjonuje.
Po drugie, to jednak nastawienie związane z uczeniem maszynowym, które w Polsce, a w szczególności w przemyśle, jest dość nową rzeczą, jeżeli mówimy o diagnostyce czy utrzymaniu predykcyjnym. Na takich dwóch płaszczyznach dla mnie to było nowe. Dzięki temu nabrałam doświadczenia i trochę lepiej sobie teraz z tym radzę.
Zastanawiam się teraz nad kolejnym pytaniem, bo nie ukrywajmy świat dużego przemysłu jest trochę oderwany od IT, nie wspominając o uczeniu maszynowym. Zastanawiam się jak to się stało, że uczenie maszynowe przeniknęło tam i zaczęliście go używać.
Czy miałaś jakieś wsparcie od kierownictwa? Czy oni Cię inspirowali czy jednak była to taka inicjatywa z dołu? Jak to było?
Akurat ten projekt – diagnostyka młyna – to była inicjatywa naszej firmy, jako działu badawczo-rozwojowego. Firma zdecydowała się wyłożyć środki, żeby stworzyć taki produkt i dalej to rozwijać, abyśmy później mogli jeszcze bardziej iść w ten temat.
Często jest tak, że jeżeli chcemy stworzyć jakieś nowe rzeczy, na przykład teraz mamy projekt, w którym tworzymy moduł, który szacuje ryzyko wystąpienia awarii na odcinkach rur ciepłowniczych dla sieci ciepłowniczej, często robimy to przy pomocy grantów unijnych. Wtedy szukamy konsorcjum bo można znaleźć ciekawe projekty i wykorzystać nasze pomysły. Tam nie trzeba mieć żadnych doświadczeń czy wdrożeń.
Często też są fundusze z NCBR-u, które można wykorzystać, trzeba zawiązać wtedy konsorcjum. Wiele mamy takich projektów, że jeżeli chcemy się rozwijać w jakim kierunku to szukamy grantów czy funduszy. W ten sposób też jesteśmy w stanie wprowadzać nowe produkty albo inwestując swoje środki. W przypadku młynów to były swoje środki, aczkolwiek mamy dużo takich projektów, gdzie mamy zawiązane konsorcja i korzystamy z dostępnych grantów.
Rozumiem, wydaje mi się, że tutaj nie chodzi o to jak to z finansować, chociaż to też wiadomo może być wyzwanie. Załóżmy, że teraz słucha nas osoba związana z przemysłem, która pracuje w fabryce lub mniej informatycznym miejscu. Ma ona świetny pomysł jak coś można usprawnić, na przykład jakieś czujniki na podstawie, których można robić różne predykcje, kiedy coś się popsuje itd.
Taka osoba chce to zrobić, natomiast jak pójdzie teraz do swojego szefa, zwłaszcza jeśli przełożony jest starszą osobą, to prawdopodobnie go nie zrozumie. Jakie masz porady dla takiej osoby? W jaki sposób można pokazać tę wartość, nawet jeżeli pracujesz w obszarze mniej informatycznym?
Myślę, że wtedy trzeba spędzić nad tym trochę czasu i pokazać pierwsze podejście. Trochę wbić się w temat i chociaż trochę pokazać co można zrobić. Myślę, że takim czysto teoretycznym mówieniem, że tu są takie rozwiązania i my też możemy zrobić coś takiego to może trochę przekonasz, ale osobie sceptycznej musisz chociaż trochę pokazać, że faktycznie jesteś w stanie to zrobić, posiadać jakiś model, pierwsze bazowe rozwiązanie.
Jednak trzeba mieć z czym pójść, żeby to nie była sama idea. Oczywiście trzeba mieć ją w głowie, sprawdzić jakie są rozwiązania, ale mieć też coś w zanadrzu, pokazać, że mogę to zrobić tak, zobacz już zrobiłem to i to, teraz gdybym pociągnął temat to chciałbym sprawdzić to rozwiązanie. Już zacząłem, mam wstępne wyniki, zobacz, że faktycznie dobrze to wygląda.
Często dobrze jest mieć jakiś research, pokazać, że tutaj zrobili to w ten sposób, może my też byśmy mogli? Najlepiej pokazać, że konkurencja coś takiego ma, to myślę, że może to być punkt zapalny, który sprawi, żeby też spróbujemy.
Ostatni punkt jest dość mocnym argumentem i mam wrażenie, że w tej chwili wszyscy czekają, żeby to pierwsza konkurencja gdzieś tam wyszła, a potem wszyscy próbują dogonić to co uciekło do przodu…
Wiem, że również działasz w tematach związanych z medycyną, w sumie wspomniałaś już o tym. Podziel się proszę tym trochę więcej, jakie projekty robisz? Jakie problemy próbujecie rozwiązać? Być może już coś rozwiązaliście?
Sama akurat nie zajmuje się projektami związanymi z medycyną, aczkolwiek mój dział badawczo-rozwojowy ma bardzo mocny team w tym temacie. Myślę, że tu mogłabym wspomnieć o dwóch rzeczach.
Pierwsza, stworzyliśmy takie narzędzie MedStream Designer, jest to narzędzie, które zbiera dane ze szpitala lub placówki medycznej w jednej bazie danych. Myślę, że wszyscy są sobie w stanie wyobrazić, że gdy idziesz do szpitala to jeden lekarz ma swoje zapiski, drugi lekarz swoje, wyniki z laboratorium są jeszcze gdzieś indziej, a wyniki z drugiego laboratorium w jeszcze innym miejscu.
Często gdy chcemy przeprowadzić jakieś badanie, wyciągnąć wnioski na podstawie leczenia, sprawdzić czy dany lek się sprawdził czy nie to musimy biegać to tu, to tam, żeby zebrać te dane – to narzędzie pozwala nam zebrać to w jedno. Co więcej, to nie jest tylko do zbierania danych, to pozwala na przeszukiwanie wszystkich rekordów, wyszukiwanie zależności czasowych, zależności przyczynowo-skutkowych.
To jest narzędzie, które bardzo podoba się naukowcom, bo pozwala na przeszukanie szerszej bazy danych i wyłapanie dodatkowych rzeczy. Nie musisz już pół roku chodzić, żeby zbierać dane, a masz je tutaj na wyciągnięcie ręki. Jestem ogromną fanką tego narzędzia. Z takich tematów bardziej uczenia maszynowego. Teraz bierzemy udział w bardzo dużym projekcie, zawiązało się bardzo duże konsorcjum, między innymi z USA, Finlandii, Belgii no i my.
Naszą odpowiedzialnością jako TT jest przeprowadzenie statystycznej analizy. Ponieważ projekt polega na tym, aby stworzyć narzędzie, które pozwoli na wczesne wykrywanie padaczki u noworodków. Pierwszy etap polega na sprawdzeniu leczenia prewencyjnego, czyli jeżeli wykonamy jakieś badanie EEG i na jego podstawie możemy znaleźć jakieś symptomy mówiące, że ten dzieciaczek może prawdopodobnie mieć padaczkę.
To możemy albo go zacząć leczyć wcześniej albo czekać aż faktycznie wystąpią objawy tej padaczki, wystąpi atak i wtedy dopiero możemy podać leki. W pierwszym etapie sprawdzamy czy leczenie prewencyjne faktycznie przynosi efekty.
W drugim etapie będziemy analizować dane genetyczne. To jest naprawdę bardzo duża ilość danych. Dla pacjentów liczonych w dziesiątkach, załóżmy około setki, to jest około 30 terabajtów danych. Czyli bardzo dużo danych genetycznych, które trzeba przeanalizować. Będziemy szukali takich sekwencji czy markerów na podstawie, których będziemy mogli wnioskować o to, że u tego dzieciaczka może wystąpić w przyszłości padaczka.
Docelowo narzędzie jakie chcielibyśmy stworzyć to jest taki algorytm uczenia maszynowego, który jeżeli na wejściu dostanie skan EEG to będzie w stanie zapalić lampkę osobie, która wykonuje badanie, żeby zwróciła szczególną uwagę, bo tutaj widać te symptomy. Obecnie te wszystkie czynności, o których mówiłam są wykonywane tylko i wyłącznie przez człowieka. Jest to bardzo duży projekt rozpisany na kilka lat.
Teraz jesteśmy dopiero w pierwszym etapie. Bardzo ostrożnie trzeba to wszystko robić. My jesteśmy odpowiedzialni za część machine learning, dużo odpowiedzialność przed nami, ale też dużo ciekawych rzeczy.
To co powiedziałaś brzmi bardzo ciekawie, ale z drugiej strony jest to bardzo odpowiedzialne. W tej chwili ten kawałek oprogramowania, uczenie maszynowe, decyduje o tym…
To jest strasznie odpowiedzialne, ponieważ musisz patrzeć na naprawdę każdy krok. Nie możesz się pomylić w żadnej walidacji danych, ponieważ te wyniki, które będziesz generować będą oddziaływać na życie tych dzieciaczków. Jak stworzysz coś naprawdę świetnego, co naprawdę będzie w stanie wykrywać to świetnie, ale jak się pomylisz to…
Masz tutaj bardzo duże poczucie, że wykonujesz coś co ma wpływ na życie innych dzieci, na to czy wykryjesz u nich padaczkę, czy będziesz w stanie im pomóc w tym młodymi wieku. To są takie projekty, które po pierwsze są bardzo odpowiedzialne, a po drugie bardzo satysfakcjonujące.
Trzeba do tego działania podchodzić bardzo ostrożnie. Ale z drugiej strony jak już odpowiednio dobrze się to zrobi i sprawdzi to może przynosić korzyści. Tak jak powiedziałaś, w takiej chwili robi się to manualnie, o ile w ogóle się to robi, bo tych lekarzy pewnie nie jest zbyt wielu.
Po drugie, trzeba też bardzo dobrze dokumentować takie projekty. Jak tworzysz jakiś algorytm to możesz mieć tylko jakiś wynik i w porządku, wszystko działa. Ale tutaj, ktoś na pewno będzie chciał do tego wrócić i zobaczyć jak to wszystko wyglądało.
Tutaj dochodzi ten aspekt, że musisz wszystko bardzo skrupulatnie zapisywać: gdzie były jakie wyniki, na podstawie czego jakie wnioski, na podstawie jakich danych, co tutaj zmieniałeś, a co nie. Naprawdę dużo do zrobienia.
W ogóle takie dokumentacje i prowadzenie różnych logów dla mniej formalnych projektów jest bardzo ważne, bo w ten sposób możemy przywołać to co robiliśmy dzień czy tydzień temu.
W szczególności, gdy tworzymy całą serię modeli. Patrzysz na wyniki poszczególnych modeli, a jak nie pamiętasz z jakich danych model był trenowany, to jest bardzo ciężkie. To prawda, że w każdym projekcie trzeba zapisywać sobie takie pomocnicze informacje. Moim zdaniem, w szczególności w modelowaniu, gdzie musisz mieć zestaw cech wejściowych, które wprowadziłeś i też jakie parametry wykorzystałeś do zbudowania modelu.
Z drugiej strony, jeżeli chodzi o takie bardziej formalne projekty, bo tak się złożyło, że miałem trochę z takimi styczność. Tam szczerze mówiąc, często jest dużo biurokracji i to też potrafi zabić projekt. Dobrze mieć jakiś złoty środek, bo jeżeli będzie za dużo reguł, to w pewnym momencie w ogóle już nie ma tego badania, a są tylko inne rzeczy z nim nie związane. Na to też trzeba czasem uważać. Wiadomo, że projekt jest bardzo odpowiedzialny, więc trzeba to zrównoważyć.
Zapytam teraz o Twój własny rozwój, tak jak powiedziałaś jesteś samoukiem, jeśli chodzi o uczenie maszynowe, masz też pewne sukcesy na swoim koncie, z czego oczywiście można się cieszyć. Podpowiedz proszę osobom czy firmom, które dopiero zaczynają, na co należy zwracać szczególną uwagę, żeby też odnieść sukcesy w uczeniu maszynowym?
Powiedziałabym, że nie należy oczekiwać zbyt wiele na początku. Wydaje mi się, że ludzie często gdy myślą o uczeniu maszynowym, to wyobrażają sobie naprawdę zaawansowane algorytmy opakowane w jakiś piękny GUI, gdzie mamy rekurencyjne sieci neuronowe i mamy jeszcze inne ciężkie rzeczy do zaimplementowania i już mamy wyniki.
Tak naprawdę to powinno zaczynać się po nitce do kłębka. Zaczynamy od podstaw i dopiero potem się rozwijamy. Ja sama nie jestem super wyszkolona w tych wszystkich algorytmach. Wiem, które jak działają, ale nie wszystkie w praktyce wykorzystywałam. Myślę, że bardzo ważne jest, żeby iść po kolei, zacząć od podstaw i dopiero później się rozwijać i uzyskiwać bardziej zaawansowaną wiedzę.
Wtedy gdy się ją ma to pewnie dojdzie się do bardzo zaawansowanych algorytmów, żeby nie chcieć za dużo na początku. To wszystko przyjdzie z czasem, tylko trzeba do tego powoli dojść. Przynajmniej ja tak miałam i myślę, że to jest bardzo dobre podejście.
Czyli małymi kroczkami i do przodu?
Tak, zdecydowanie.
A jakie rozwiązania ze świata uczenia maszynowego, albo tak zwanej sztucznej inteligencji, zaskoczyły Cię?
Tu powrócę do poprzedniego pytania gdzie mówiłam, że nie należy zaczynać od bardzo zaawansowanych algorytmów i powrócę też do tematu młynów węglowych. Gdy rozwijałam się w temacie uczenia maszynowego to wyobrażałam sobie, że te wszystkie bardziej zaawansowane modele zawsze się lepiej sprawdzają i dają super wyniki. Jak już skończyłam model liniowy to koniecznie chciałam przejść do modeli z sieciami neuronowymi, porównać to z wynikami pracy kolegi, który robił modele na podstawie fizycznych zależności, gdzie dobierał współczynniki, wykorzystując uczenie maszynowe.
Wydawało mi się, że taka prosta regresja liniowa nie będzie w stanie dać takich sensownych wyników. A faktycznie proste rozwiązania często mogą rozwiązać dużą część problemów. Model liniowy okazał się równie skuteczny jak model sieci neuronowych czy model fizykalny, który opisywał prawdziwe zależności i miał w swoich równaniach wyznaczane różniczki.
To co mnie najbardziej zaskoczyło to, że skomplikowane rozwiązania nie zawsze dają najlepsze rezultaty. Tak naprawdę, to co należy powiedzieć to, że im coś jest prostszego tym lepiej, łatwiej to zaimplementować i wykorzystać. To było moje pierwsze światełko, że nie zawsze to co skomplikowane i co wydaje się wszystkim, że teraz tego tyle się robi i raczej powinniśmy to wykorzystać, to nie we wszystkich problemach koniecznie musi być zaimplementowane. Co prawda lepiej to wtedy brzmi, ale jednak lepiej keep it simple.
Chciałem to powiedzieć, że w informatyce jest na to skrót „KISS” – keep it simple, :). Tak to jest, że najprostsze rozwiązania zwykle działają. Po pierwsze działa to stabilnie, a po drugie może być wystarczająco dobrze.
Prowadzę warsztaty o praktycznym uczeniu maszynowym i powtarzam, że jeżeli uda się rozwiązać problem wykorzystując prostsze narzędzia, to nie ma co komplikować i wybierać trudniejszych, no bo po co? Już mamy rozwiązanie i może być ono wystarczająco dobre. Słowa „wystarczające dobre” są bardzo ważne.
Dokładnie, nawet jeżeli to rozwiązanie nie będzie tak samo dobre, ale tylko nieznacznie gorsze to często w optymalizacji tak jest. Wykorzystujemy modele, które są nieznacznie gorsze, np. od jakiś nieliniowych, tylko po to, że później dużo łatwiej jest nam to wykorzystać. Jakieś drobne pogorszenie jakości wcale nie musi oznaczać, że nie będzie to działało tak jakbyśmy tego chcieli.
Zapytam teraz trochę o naszą przyszłość. Jak myślisz, jak uczenie maszynowe potrafi zmienić nasze życie za 5-10 lat? To może być pytanie globalne, ale możesz też to odnieść do obszaru swojej pracy.
Nie wiem czy jesteś zaznajomiony z takim pojęciem jak „rewolucja przemysłowa 4.0„? Myślę, że tutaj będziemy szli bardziej w tym kierunku. Po pierwsze, wszechstronna cyfryzacja. Obecnie w wielu dziedzinach, w szczególności w przemyśle, mamy problem z danymi, bo nie są one jeszcze zbierane albo nie są zbyt dobrze zbierane. Nie mamy takiej uwagi na to, że potrzebujemy zbierać te dane.
Dopiero teraz dostajemy tę świadomość, że faktycznie na podstawie danych faktycznie jesteśmy w stanie zrobić bardzo dużo. A po drugie, przetwarzanie tych danych. Będziemy przetwarzać te dane w czasie rzeczywistym, prawdopodobnie, raczej prawie na 100%, w chmurze. Będziemy mieć centralne ośrodki i dynamika przetwarzania tych danych będzie bardzo szybka. Myślę, że będzie to już rzędu milisekund. Będziemy na bieżąco wykorzystywać informacje z bardzo wielu pól.
Jak mówiłam o MedStream Designer, który łączy dane z tych wszystkich źródeł, od lekarzy, laboratoriów itd. Myślę, że tak samo tutaj, tylko na większą skalę. Na przykład, będziemy mieć zespół kilku fabryk, które będą połączone w jedno i w czasie rzeczywistym będziemy przekazywać te dane i wykorzystywać je do zwiększania efektywności pracy i myślę, że w tę stronę to idzie.
Plus, oczywiście, rzeczywistość rozszerzona gdzie będziemy te dane wykorzystywać. Pod spodem będzie jakiś dobry silnik uczenia maszynowego, który będzie pozwalał nam na efektywniejsze zarządzanie procesem i osiąganie znacznie lepszych wyników i zapobieganie awariom. Dużo się teraz mówi o predykcji w maintenance, nawet w kontekście tych młynów.
Myślisz, że w Polsce też to nastąpi na większą skalę, w perspektywie najbliższych 5-10 lat? Czy to bardziej światowy trend?
Może nie 5, ale 10 myślę, że tak. Nasza firma Transition ma też biuro w Łodzi, które zajmuje się stricte rozszerzoną rzeczywistością. Coraz więcej firm jest otwartych na takie rozwiązania i coraz więcej mamy tutaj wdrożeń. Mówię tutaj o wdrożeniach w Polsce, czyli dla fabryki Fiata lub firm kosmetycznych. Myślę, że to jest kwestia kilku lat, nie są to żadne mrzonki.
Nie do końca jeszcze to widzimy bo to jest przemysł, osoby, które nie mają z nim styczności nie do końca wiedzą co się tam dzieje, widzą tylko produkt końcowy. Ja jestem zdania, że idziemy w tym kierunku.
Jasne, tylko się cieszyć skoro rozpędza się to też u nas w Polsce. Zapytam jeszcze, bo wiem, że przygotowałaś dla słuchaczy prezent, powiedz proszę co jest w środku.
Dużo mówiliśmy tutaj o moim wystąpieniu na Meetup, o diagnostyce młyna węglowego. Wydaje mi się, że ten podcast jest skierowany do osób, które dopiero rozpoczynają swoją przygodę z uczeniem maszynowym i chciałyby od czegoś zacząć.
Przygotowałam krótki pdf, w którym pokazuję ten proces tworzenia modelu w pięciu kluczowych krokach. Jeżeli ktoś się zastanawia jak wygląda tworzenie takiego rozwiązania, chciałby mieć jakąś podstawę i zobaczyć gdzie wiedza ekspercka faktycznie miała znaczenie to przygotowałam krótki pdf ukazując ten proces od problemu do rozwiązania z zaznaczeniem takich kluczowych etapów.
Dodałam tam kilka pytań, na które musieliśmy sobie w trakcie zadać oraz dodatkowe notatki. Myślę, że dla osób, które chciałyby stworzyć swój produkt albo generalnie stworzyć narzędzie, będzie to bardzo przydatne. Żeby na to spojrzeć wystarczy chwila, a myślę że ma w sobie dużą wartość.
Dziękuję od siebie i od słuchaczy za przygotowanie tego dokumentu. Czego mogę Tobie życzyć?
Najtrudniejsze na koniec. Może ciekawych projektów? Może łatwych egzaminów na doktoracie? Żebym szybciej wdrażała te nawyki, o których czytam w książce.
Życzę Ci dokładnie tego o czym powiedziałaś. Trzymam kciuki, żeby faktycznie to wszystko się udało. I ostatnie pytanie na koniec: jeśli ktoś będzie będzie chciał się z Tobą skontaktować to jak może to zrobić?
Myślę, że najprostszym sposobem będzie znalezienie mnie na LinkedIn – Teresa Kurek, Transition Technologies. Jakby ktoś był bardziej zainteresowany tematyką młynu lub moją prezentacją z Meetup to tam też jest ona dostępna. Myślę, że byłby to najlepszy środek komunikacji. Zresztą my się tak skomunikowaliśmy za pierwszym razem, więc jest to potwierdzone źródło.
Tak, jest sprawdzone, działa. Dziękuję Ci bardzo za rozmowę, za Twój czas i za to, że przynajmniej troszkę powiedziałaś o tym, co dzieje się w świecie przemysłu, a który dla osób spoza tego obszaru jest trochę czarną magią. Jak widać dzieją się tam ciekawe rzeczy i uczenie maszynowe też już tam wkracza.
Bardzo Ci dziękuję Vladimir, bardzo mi było miło być gościem Twojego podcastu.
Ciekawy jestem, jak przemysł zmieni się za jakieś 5-10 lat. Opór do zmian, zwykle istnieje w głowach osób, które kierują – czyli kadra kierownicza. To są ludzie, już w starszym wieku, które naturalnie są bardzo konserwatywne. Akurat, w większości przypadków, to dobrze, no bo jak “szalony nastolatek” zacznie sterować ciężkim przemyślem, to nic ciekawego z tego nie wyniknie. Z drugiej strony, ciężko już jest ignorować ML. Myślę, że największą motywacją do zmian – jak to często bywa – jest konkurencja. Tylko po co czekać kolejne 5-10 lat i potem próbować nadrobić to, co być może będzie trudne do nadrobienia? Co o tym sądzisz?
W międzyczasie, na pewno część osób kojarzy, że prowadzę kurs – praktyczne uczenie maszynowe. Właściwie, wtedy gdy słuchasz tego odcinka, skończyła się pierwsza iteracja tego kursu. W skrócie powiem, że jestem bardzo zadowolony z tego jak wyszedł ten projekt, chociaż jestem również bardzo zmęczony.
Organizacja tego typu przedsięwzięcia na większą skalę jest również męcząca. Myślę o nagraniu osobnego odcinka, w którym opowiem więcej, zaproszę również uczestników, którzy podzielą się swoją opinią (wtedy to będzie bardziej przejrzyste). Dostaję pytania, czy będzie druga iteracja? Już mogę powiedzieć, że tak – będzie! Nawet są już dostępne pakiety z dużą zniżką 25% dla pierwszych dziesięciu osób (promokod: EARLY_BIRDS_25 ).
Teresa wspomniała o prezencie. Osoby, które już są zapisane na newsletter, dostaną go, reszcie polecam się zapisać 😉 Powiem szczerze, że wysyłam newsletter tylko z informacją o nowych odcinkach lub z różnymi prezentami przygotowanymi przeze mnie lub moich gości.
Mam jeszcze dla Ciebie dwa dodatkowe ogłoszenia.
22 lutego odbędzie konferencja Big Data Tech Warsaw. To jest największa konferencja związana z Big Data w Polsce. Pojawią się tam tematy związane z uczeniem maszynowym czy Data Science. Specjalnie dla słuchaczy BiznesMyśli jest zniżka 10%. Wystarczy wpisać promokod: “biznesmysli”, jest on ważny do końca roku 2017.

Druga dobra wiadomość będzie dla studentów, którzy mają napisać pracę magisterską. Politechnika Warszawska i Nethone zorganizowali konkurs na najlepszą pracę magisterską z zakresu Machine Learning i Data Science.

Korzystając z okazji Świąt, bardzo chcę życzyć Ci spokojnych i szczęśliwych świąt. Proszę poświęć trochę czasu, żeby zastanowić się nad tym co dzieje się w świecie. Jak te zmiany mogą wpłynąć na Twoje życie i jak można się do nich przygotować. W każdym zjawisku można zobaczyć dobrą i złą stronę. Sztuczna inteligencja też je ma.
Od nas zależy, w którym kierunku będziemy się rozwijać. Pomyśl o tym. Również chcę Ci bardzo podziękować za Twoje zaufanie i motywację, którą dostaje. Moje życie zmienia się i to dość zauważalnie, po tym jak zacząłem dzielić się wiedzą z szerszym gronem ludzi.
To tyle na dzisiaj. Dziękuję Ci za Twój czas, Twoją energię i życzę wszystkiego dobrego, co tylko może wydarzyć się w Twoim życiu. Cześć!
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.


2 komentarze
Konrad
Bardzo ciekawy odcinek. Skąd można pobrać pdf o którym wspominała Teresa?
Vladimir
Cześć Konrad, dziękuję za Twoją opinię :).
Żeby dostać plik pdf trzeba zapisać się na newsletter (ten mniejszy/pierwszy formularz) to wtedy natychmiast jest wysyłana wiadomość. Do Ciebie wiadomość już poszła przed chwilą :).