

Możliwe blokery oraz rozwiązania w uczeniu maszynowym

Zbieram coraz więcej informacji zwrotnej i pytań na temat uczenia maszynowego lub blokerów, które powstrzymują przed rozpoczęciem pracy z nim. Zebrałem najbardziej aktualną listę problemów i na nie odpowiedzieć. Zastanawiam się nad najodpowiedniejszą formą.
Może webinar lub kurs online? Pod koniec kwietnia dobiegła końca czwarta edycja kursu “Praktyczne uczenie maszynowe od podstaw” oraz druga edycja “Praktycznego prognozowania szeregów czasowych”. Wkrótce powinienem móc podzielić się z Tobą opiniami uczestników. Daje mi to bardzo dużo satysfakcji, jednakże sam kurs i ogrom przygotowań do niego to spory wysiłek. Troszcząc się o swój poziom entuzjazmu i motywacji (bo właśnie to stale napędza mnie do działania) uznałem, że potrzebna jest inna forma dzielenia się wiedzą.
Tak narodził się pomysł szkoleń stacjonarnych – DataWorkshop Tour. W 2018 roku przeprowadziłem szkolenia w 6 miastach w Polsce, natomiast w tym roku zapraszam wszystkich zainteresowanych do Warszawy.
Zależy mi, aby to nie było jedynie przekazanie informacji o uczeniu maszynowym, lecz także szansa na podzielenie się swoim doświadczeniem oraz umożliwienie uczestnikom zdobycie własnego. Miałem już okazję przeszkolić ponad 800 osób i wciąż uczę się, jaka forma przekazu najlepiej się sprawdza, analizuję, co działa lepiej i wyciągam wnioski. Zauważyłem, że dobrze dobierany jest swego rodzaju konkurs organizowany w trakcie kursu. Lekka doza rywalizacji sprawia, że mocniej angażujemy się w przedsięwzięcie i daje dodatkowej motywacji. W efekcie nierzadko wręcz nie możemy zasnąć głowiąc się nad rozwiązaniem, ponieważ tak mocno zainteresował nas dany problem.
Ludzki mózg znacznie lepiej przyswaja sobie rzeczy, na które się wcześniej przygotowuje. Gdy bierzesz udział w konkursie, angażujesz się w rozwiązanie zadania, przyswojenie i zrozumienie wyniku jest wtedy dla Ciebie znacznie prostsze niż gdybyś po prostu poznał rozwiązanie nie zajmując się nim wcześniej. Gotowe rozwiązania są łatwiejsze do pozyskania, ale trudniejsze do przyswojenia. Dlatego właśnie najlepiej uczymy się poprzez doświadczanie. W związku z tym postanowiłem wprowadzić taki element na DataWorkshop Tour. W wyniku wielu burz mózgów, dyskusji powstała koncepcja dwudniowego wydarzenia, które będzie łączyć klasyczne szkolenie oraz konkurs w formie hackathonu.
Pierwszego dnia będziemy rozmawiać o podstawach uczenia maszynowego, pokażemy wszystko, co należy wiedzieć, aby zacząć z nim swoją przygodę. Drugiego zaś skoczymy na głęboką wodę i podejdziemy do praktycznego rozwiązywania rzeczywistego problemu. Każdy uczestnik będzie miał na zadanie samodzielnie znaleźć rozwiązanie, ale będziemy na miejscu pomagać, gdy pojawią się blokery takie jak nieznajomość języka programowania.
Co jakiś czas będą także prezentowane gotowe części rozwiązania, aby zainspirować do dalszego działania i nie dać się sfrustrować. Z moich obserwacji wynika, że pewien kontrolowany poziom frustracji oraz wyjście ze swojej strefy komfortu wzmagają pragnienie sukcesu i wolę walki, ale kluczowym w tym jest, aby to faktycznie było kontrolowane. W przeciwnym wypadku grozi nam całkowite zniechęcenie do uczenia maszynowego, a przecież nie o to chodzi.
Dlaczego o tym wszystkim mówię? Dwudniowe szkolenie to wciąż mało czasu, żeby przekazać to wszystko czym chciałbym się podzielić w zakresie uczenia maszynowego. Rozważałem, jakie mogę przygotować dodatkowe materiały w łatwo przyswajalnej formie przed szkoleniem i jak je przekazać. Chciałbym w ten sposób pomóc uczestnikom przygotować się do szkolenia i wyrównać poziom wiedzy. Przygotuję notatki, ale zrobię je w taki sposób, aby było wartościowe także dla osób, które nie będą brały udział w szkoleniu, a chcą się rozwijać w tym obszarze.
Na stronie szkolenia zebrałem 10 problemów, z którymi najczęściej spotykają się osoby pracujące z uczeniem maszynowym. Na wszystkie te problemy przedstawione będą rozwiązania podczas szkolenia 30-31 maja w Warszawie. Natomiast część z tych problemów jest taka, że najpierw trzeba poznać, na czym polega problem, żeby móc uświadomić sobie, że również się go ma (lub nie) :). W tym artykule zebrałem 3 najważniejsze problemy.
Problem 1: Nie wiem, jak podejść do praktycznego problemu za pomocą uczenia maszynowego.
Wyobraź sobie, że poznajesz na lekcji geografii stolice wszystkich krajów i czasem może się wydać, że już można jechać w podróż dookoła świata, ale mając tylko wiedzę o stolicach krajów lub jakieś inne podobne teoretyczne rzeczy. Pytanie jest na ile jesteś w stanie wyruszyć w dalszą podróż niż tylko do Krakowa czy Warszawy posiadając taką informację? Jest dużo praktycznych wyzwań, zaczynając od tego, żeby ogarnąć wszystkie potrzebne wizy, być może szczepienia, jak również sprytne zakupy biletów na samoloty, pociągi czy hotele i zrobić to wszystko w odpowiedniej kolejności. To wszystko wymaga doświadczenia.
Podobnie jest w uczeniu maszynowym, można poznać pewne teoretyczny podstawy, ale tego jest za mało, żeby wyruszyć w prawdziwą podróż. Czy będąc w szkole ucząc się wszelkich informacji o świecie, jego geografii, polityce państw mógłbyś stwierdzić, że jesteś w pełni przygotowany do odbycia podróży dookoła świata? Do takiego przedsięwzięcia potrzebne jest praktyczne doświadczenie, wiedza o tym, jak znaleźć dobre połączenia lotnicze, jak zorganizować dokumenty, zakwaterowanie, co ze sobą zabrać. Takich rzeczy uczymy się poprzez działanie.
Przejdźmy teraz do podwórka uczenia maszynowego. Specjalista od uczenia maszynowego to jest dość egzotyczna rola. Z jednej strony jest to osoba techniczna, bo tworzy modele, zbiera dane i również zwykle pisze kod. Z drugiej strony dla tych osób bardzo ważnym jest umieć myśleć biznesowo. Połączenie obu tych cech w jednym człowieku jest zwykle dużym wyzwaniem. Tutaj oczywiście można rozważać, co jest łatwiejsze: przekształcić osobę biznesową w techniczną czy na odwrót. Zwykle to idzie w takim kierunku, że osoba techniczna doucza się tego, jak działa biznes.
Jak to zwykle bywa, do każdej reguły są wyjątki, podam przykład z mojego doświadczenia. W moim kursie online “praktyczne uczenie maszynowe od podstaw” brał udział prezes dość dużej spółki, ale to raczej wyjątkowa sytuacja. Słowa uznania za tak odpowiedzialne zachowanie dla prezesa. Z jednej strony wiadomo, że prezes tej spółki (raczej) nie będzie pisał kodu na co dzień, bo ma inne obowiązki. Natomiast z drugiej strony, taka wiedza może pomóc znacznie lepiej zrozumieć pewne procesy, a więc może być mu łatwiej stawiać właściwe cele, precyzyjniej interpretować wyniki i radzić sobie z wyzwaniami, których będzie dużo.
Co można poradzić na to, że nie wiesz jak zacząć stosować uczenie maszynowe w praktyce? Proponuję najpierw poczytać i zainspirować się innymi rozwiązaniami. Dość często z technicznego punktu widzenia sporo problemów biznesowych da się sprowadzić do dwóch przypadków: prognozowania wartości ciągłej np. 100, 105, czy 2334 (czyli regresja) lub prognozowania dwóch czy więcej możliwych przypadków np. kupi lub nie kupi (czyli klasyfikacja). Takich technicznych przykładów jest dużo w internecie, co prawda na to trzeba poświęcić swój czas, żeby je znaleźć. Warto też przyznać, że w internecie jeszcze więcej jest szumu, przykładów, które bardziej wprowadzają w błąd. Dlatego uważaj!
Wracając do pytania, możliwym rozwiązaniem braku wiedzy jak zmapować problem biznesowy na problem techniczny, jest inspiracja już gotowymi rozwiązaniami. Ich jest naprawdę dużo (przynajmniej jeśli chodzi o w miarę powtarzalne biznesy), wystarczy tylko umieć je odpowiednio filtrować.
Kolejny problem, z tej rodziny brzmi mniej więcej tak, że już jestem po studiach, książkach czy kursie i nadal nie wiem, jak zabrać się samemu za praktykę. Część osób ma za sobą np. słynny kurs Andrew Ng lub jakiś inny na Coursera, Udemy czy Udacity. W tych kursach jest dużo matematyki, ale potem absolwenci mają proste pytanie: dobrze, mam to zrobione, ale co dalej? Bo nadal nie wiadomo jak to zastosować. To jest podobnie jak przez chwilę pracować w warunkach laboratoryjnych, następnie wyjść do świata rzeczywistego i niby coś tam wiesz, ale jak to zastosować w praktyce?
Często, w szczególności po studiach, w głowach ludzi jest dużo informacji, które ciężko przełożyć na rzeczywistość. Innymi słowy to jest szum, który dość często tylko komplikuje sprawę. To widać bardzo często w życiu. Przeprowadź swój własny test i zapytaj, jak dużo ludzi w Twoim otoczeniu pracuje w zawodzie. A jeśli nawet takich jest wielu, to jak często wykorzystują w pracy wiedzę zdobytą podczas studiów? Czy zajmując się przez te lata czymś innym, mieliby informacje potrzebne do rozwiązywania aktualnych problemów?
Teraz dotykam jeszcze ciekawszego tematu. Zawsze jest dużo ludzi, którzy teoretycznie wiedzą, jak coś zrobić lepiej, natomiast z drugiej strony dość często te osoby są jeszcze w znacznie gorszej sytuacji (jak finansowej tak i mentalnej). Zawsze mnie to ciekawiło, jak to może być, jeśli ta osoba, która tak dobrze rozumie jak powinno się robić, to czemu tak słabo radzi sobie w swoim własnym życiu. Jak myślisz, dlaczego jest tak, że jest dużo osób, które mają informacje, jak działa ten czy inny proces, nadal są tam gdzie są (czyli posiadanie tej informacji jest mało wartościowe dla nich)?
Wróćmy do uczenia maszynowego. Mając do wyboru dwie opcji: zgłębić jak działa matematyka pod spodem tego czy innego modelu lub nauczyć się zadawać właściwe pytania, który problem należy rozwiązać, to w mojej opinii lepiej pójść w kierunku rozwiązywania właściwych problemów, nawet jeśli robić to mniej optymalnie. Można to powiedzieć nawet w ten sposób, lepiej rozwiązać wartościowy problem na trójeczkę, niż bezwartościowy problem na piąteczkę. Dlatego jeśli celem osoby jest rozwiązywanie problemów, lepiej najpierw nauczyć się identyfikować te problemy i następnie w miarę możliwości pogłębiać coraz bardziej zaawansowane techniki jak dany problem można rozwiązać.
Jeśli wziąć zawodowca, np. boksera i kogoś, kto wychował się w tzw. “złej dzielnicy” i musiał codziennie wracać późno w nocy do domu po pracy, to który z nich lepiej poradzi sobie w życiu? To zależy. Np. jeśli to będzie idealny pojedynek wg pewnych reguł, to zawodowy bokser pewnie z łatwością sobie poradzi. Natomiast jeśli to będzie przykład z prawdziwego życia, to już niekoniecznie, bo ten kolega nauczony życiem może być po prostu bardziej skuteczny. Dlaczego? Bo może lepiej adaptować się do rzeczywistości. Np. może użyć gazu pieprzowego lub paralizatora, czy zastosować coś mniej oczekiwanego np. uderzyć poniżej pasa czy ugryźć przeciwnika, czyli coś co w normalnym boksie jest zakazane więc zawodowiec nie pomyślałby, żeby takie ruchy wykonać.
Jak to wszystko łączy się z zastosowaniem uczenia maszynowego w biznesie? Sztuką jest szybko adaptować się do rzeczywistości. Nawet niektórzy w ten sposób właśnie definiują inteligencję – na ile człowiek może szybko zorientować się, gdzie jest i odpowiednio wybrać następny skuteczny krok. Czasem ten krok jest bardzo daleki od idealnego akademickiego rozwiązania. Jest natomiast wystarczająco dobry, żeby przynieść wartość przy tych wszystkich ograniczeniach jakie są, a ograniczeń zwykle jest bardzo dużo, takich jak brak czasu, brak kompetencji w zespole, brak odpowiedniej kultury w organizacji i oczywiście ograniczony budżet.
Są pewne techniki, narzędzia, które warto poznać i wykorzystać do rozwoju. Oczywiście, czym bardziej skomplikowane problemy, tym lepiej trzeba rozumieć też część akademicką, natomiast moje doświadczenie pokazuje, na ile istotne jest poznawanie świata na własnej skórze przeprowadzając eksperymenty empiryczne i tylko w drugim kroku czytając pewne teorie czy prawa akademickie. Wtedy świat poznaje się bardziej kompleksowo, nie fragmentarycznie. Lepiej zaczyna się wyczuwać kontekst, a także lepiej rozumie się pewne ograniczenia. Nie zawsze wiesz czemu, ale wiesz, że dany model mniej nadaje się do wybranego problemu. Takie wyczucie jest złotem i głównie zdobywa się poprzez rozwiązywanie konkretnych przypadków.
Dlatego na szkoleniu (na tym co będzie w Warszawie, ale też i innych) staram się stworzyć pewne środowisko, które bardziej przypomina rzeczywiste warunki. Na przykład, trzeba sobie poradzić z tym, że dane będą “brudne”. Będa pewne braki, duplikaty lub bzdurne wartości. Mało tego, zawsze można zastanawiać się, jak sobie poradzić z brakiem, ale prawda jest taka, że czasem trzeba zrobić jakiś prosty krok, np. dla wszystkich brakujących wartości wstawić wartość “brakująca wartość” i może się okazać, że to jest wystarczające dobre rozwiązanie.
Dodatkowo ważnym elementem w procesie uczenia maszynowego jest tworzenie nowych cech, ten proces nazywa się feature engineering. Dość często może on odgrywać kluczową rolę co do jakości modelu, nawet bardziej znaczącą niż który model zastosować. Temat jest skomplikowany i mało poznany akademicko, dlatego często jest pomijany. To jest przykład, kiedy mówi się, że w tym jest więcej sztuki niż nauki. Innymi słowy to jest pewna umiejętność adaptacji i zadawania właściwych pytań w konkretnym przypadku.
Sposób, który najbardziej się u mnie sprawdza, to pokazanie najpierw sposobu myślenia zamiast próby uogólnienia, następnie wrzucanie na głęboką wodę, kiedy człowiek ma samodzielnie, inspirując przykładami, wymyślić cechy. Tutaj warto przyznać, że to jest też talent. Z drugiej strony, też jak widać, jeśli odpowiednio popracować nad tym, to tę umiejętność po prostu można zdobyć, należy włożyć odpowiedni wysiłek we właściwe miejsce.
Problem 2. Nie wiem, jak interpretować wynik modelu.
Interpretowalność modelu jest ważna z kilku powodów.
Zanim przejdę do szczegółów, zwrócę uwagę na to, że są co najmniej dwa wymiary, które często wrzuca się do jednego worka. Ostatnio rozmawiając w sprawie pewnego projektu z jednym z największych banków między innymi dotknęliśmy tematy interpretowalności i to od razu brzmi jak synonim akceptacji przez regulator (np. w Polsce to KNF). Warto jednak to odróżniać, dlatego że interpretowalność z punktu widzenia biznesowego, czyli pewność że jak puścisz ten model na produkcję, to ryzyko jest kontrolowane, to warunek konieczny, bo inaczej można zmarnować bardzo dużo zasobów i co gorzej, też mogą być różne tragiczne skutki.
Natomiast interpretowalność, której wymaga regulator, czasem przypomina sztukę dla sztuki. Oczywiście teraz nie chodzi o to, że regulator to jest wielkie zło, wbrew pozorom taki regulator musi istnieć przynajmniej przy obecnej świadomości ludzi. Być może kiedyś, kiedy każdy przypomni sobie, że jest człowiekiem, to wtedy będzie łatwiej. Mała dygresja. Jak myślisz, czy człowiek jest w stanie świadomie zrobić krzywdę innemu człowiekowi? Mówiąc świadomie mam na myśli to, że przed tym jak to zrobi, przeprowadzi w swojej głowie eksperyment, czyli stanie na miejscu tej osoby, której chce zrobić krzywdę i przeżyje tę samą sytuację, ale od innej strony, jako ofiara. Jak myślisz, ile osób po takim eksperymencie, nadal zrobiłoby coś złego?
Wracając do regulatora, myślę, że jednym z największych wyzwań, które ma regulator to metryka sukcesu. Przede wszystkim liczą się rzeczy na papierach, to przyciąga ludzi z odpowiednimi umiejętnościami, którzy bardziej znają się na prawie i umiejętnym prowadzeniu papierów. Tylko prawo w tej chwili jest mocno do tyłu, jeśli chodzi o nowe technologie, polecam chociażby artykuł “prawo i sztuczna inteligencja”. Jak mówi się “papier jest cierpliwy i wszystko przyjmie”, czyli w tabelkach na papierzy może zgadzać się, ale czy o to chodziło z punktu widzenia normalnego człowieka?
Pomyśl, czy sposób działania państwa nie przypomina Ci zasad działania korporacji, tylko bez konkurencji, czyli taki monopol? Przeprowadź w głowie eksperyment: we wszystkich urzędach zaczynają obowiązywać zwykłe reguły rynku, czyli swojego klienta należy szanować. Jak dużo urzędów przetrwa w takiej uczciwej konkurencji? Nawet jeśli przetrwają, jak będzie wyglądało działanie takiego urzędu po tym eksperymencie? Na przykład, przychodzisz do urzędu, żeby załatwić pewną sprawę i słyszysz: “Drogi kliencie, żeby zaoszczędzić Twój czas, już wszystko zrobiliśmy za Ciebie, zostało załatwionych 5 rzeczy i jeszcze 2 są w trakcie, ale też będą załatwione, jak to się stanie dostaniesz mail z potwierdzeniem. Nie martw się. Tylko proszę regularnie płać podatki i my zajmiemy się resztą”. Czy jest możliwe, że kiedyś tak będzie?
Domykając temat z regulatorem i interpretowalnością modelu. Są pewne obszary, w szczególności na rynkach finansowych, w których regulator bardzo mocno trzyma kontrolę, co oczywiście ma pewne konsekwencje we wdrażaniu uczenia maszynowego. Natomiast warto zrozumieć, że po pierwsze mówiąc o interpretowalności, to w tym przypadku jest więcej pracy dla prawników (niż dla inżynierów), a po drugie to również się zmienia. Regulator próbuje dostosować się do zmian, być może wolniej niż oczekuje się, bo pamiętaj że tam “obowiązują” inne prawa niż w startupie :).
Teraz przejdźmy do wymiaru interpretowalności bardziej jak inżynierowie niż urzędnicy. Zobacz, na czym polega wyzwanie i dlaczego o tym jest tak głośno. Istnieją słynne modele liniowe (to co przerabialiśmy jeszcze w szkole, zwykłe równanie np. y = 2*x), czyli y rośnie dwukrotnie szybciej niż x. Problem z takim podejściem jest taki, że zazwyczaj otaczają nas problemy, które mają charakter nieliniowy. Zależność czynników ciężko opisać w taki sposób, że zmieniając x, y wzrośnie dwukrotnie.
Co jakiś czasem powtarzam tę frazę, że uczenie maszynowe na tym wygrywa, że potrafi wykrywać zależność mniej oczywiste. Bo inaczej człowiek byłby w stanie w zwykłym Excelu rozwiązać je samodzielnie. Żeby takie zależności wychwycić używa się bardziej złożonych modeli zaczynając od zwykłego drzewa decyzyjnego, lasów losowych i idąc w kierunku sieci neuronowych (uczenia głębokiego).
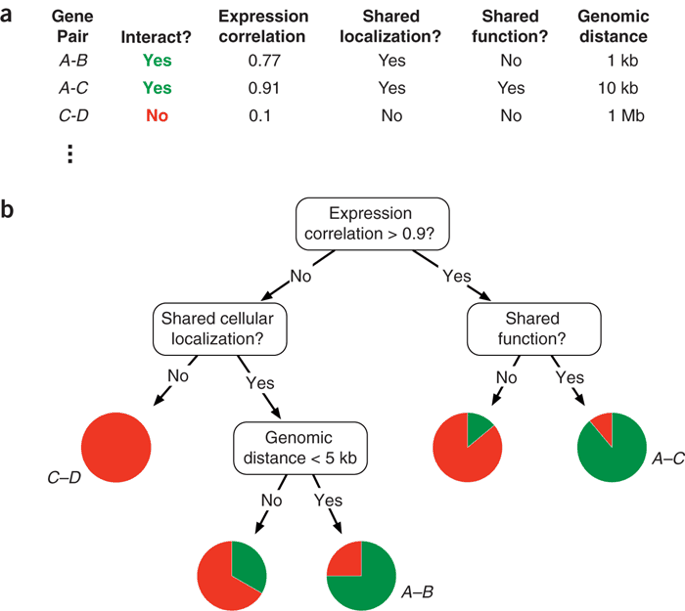
Są różne modele i są różne narzędzia, które pomagają w mniejszym lub większym stopniu je interpretować. Na wyżej wspomnianym szkoleniu przerobimy to w praktyce. Weźmy dla przykładu w miarę prosty model drzewa decyzyjnego, który potrafi wychwytywać pewne mniej oczywiste zależności. Czym jest drzewo decyzyjne? Jest to nic innego jak zbiór pytań. Na przykład chcemy stwierdzić, czy dany klient kupi jakiś produkt.
Możemy sprawdzić, w jakim jest wieku, gdzie mieszka, jakie ma wykształcenie itd. W zależności od odpowiedzi pojawią się kolejne pytania w poszczególnych węzłach aż do ich wyczerpania. Wtedy wystarczy zobaczyć, jaka jest większość obiektów w tym węźle i na podstawie tego zrobić prognozowanie. Jeśli w danym węźle są klienci, którzy zwykle kupują, to ten klient prawdopodobnie też dokona zakupu (można do tego podejść binarnie, czyli kupi/nie kupi lub opierając na prawdopodobieństwie, czyli kupi na 70%).
Warto zwrócić uwagę, że pytanie są dobierane w taki sposób, żeby podzielić dane na mniejsze, ale spójne grupy. Na przykład, tylko klienci, którzy kupują lub nie kupują. Klienci w obrębie tych grup mogą być różni, stąd pojawią się różne ścieżki, żeby je rozbić. Stworzą się segmenty klientów, którzy kupują i takich, którzy tego nie robią.
Czy drzewo decyzyjne to model, który jest interpretowany czy nie? Czy ostatecznie człowiek jest w stanie przeanalizować wszystkie możliwe kombinacje i dostrzec, że wszystko wygląda zdroworozsądkowo, czyli model podejmuje decyzje w sposób przejrzysty? Pytanie tak naprawdę jest podchwytliwe, bo patrząc na przykłady chociażby z książek, w których są tylko dwa lub trzy pytania, to raczej jest wszystko przejrzyste i oczywiste. Natomiast bardziej skomplikowane drzewa decyzyjne, które zwykle trzeba zbudować w praktyce i które mają tysiące czy nawet miliony pytań, to w tym przypadku już jest wyzwanie, żeby załadować wszystkie pytania do głowy, wziąć je jednocześnie pod uwagę i stwierdzić, że nie ma tam żadnej sprzeczności.
Jest tu jeszcze inna trudność polegająca na tym, że model może wychwycić mniej oczywiste, pomocne zależności. Załóżmy, że dla modelu ważna była ostatnia litera w imieniu. Czy może być to ważne dla stwierdzenia czy klient coś kupi? Brzmi dość dziwnie, ale może zadziałać, ponieważ w takim rozróżnieniu kryć się może płeć konsumenta. Mając imię możemy stwierdzić z dużym prawdopodobieństwem, jaka jest płeć i zwykle to jest istotna cecha. Warto dobrze się zastanowić nad najmniejszymi szczegółami, ponieważ ich zbadanie może wskazać na ważne, niezauważalne na pierwszy rzut oka czynniki.
Skoro ciężko jest jednoznacznie przeanalizować te wszystkie pytania lub inne sposoby działania modelu, to warto mieć narzędzie, które pomoże lepiej zrozumieć model. Podobnie jak z ludźmi – nie wiemy, co się dzieje w głowie drugiej osoby, ale zastanawiamy się, co sprawia, że ktoś podejmuje taką a nie inną decyzję? Każdy ma pewien zbiór wartości, którymi kieruje się świadomie lub nie. Jakimi wartościami kieruje się model? Dla niego tymi wyznacznikami są tzw. ważne cechy (atrybuty). Są to algorytmy, które stwierdzają, co dla danego drzewa decyzyjnego jest istotne. Należy jednak pamiętać, że i algorytmy są w pewien sposób subiektywne. Podobnie jak każdy człowiek ma swoją prawdę i to jest logiczne, dlatego że ma swój własny algorytm, według którego patrzy na ten świat. W zależności od algorytmu różne cechy są ważne.
Jeśli dana cecha np. wiek często występuje w pytaniach w różnych gałęziach tego drzewa decyzyjnego, to można przyjąć strategię, że ta cecha powinna być ważna, skoro tak często jest potrzebna. To może być złudne. Samo występowanie jakieś cechy nie musi przeświadczać o jej istotności. Podobnie jak w życiu, są ludzi, które często w sposób sztuczna tworzą swoją potrzebność. Podam Ci przykład, jak można sprawdzić. Przeprowadź w głowie takie eksperyment, przypomnij sobie 3 lub nawet 5 osób, które obejmują bardzo wysoką i ważną pozycję w tym życiu. Następnie dodaj jedną losową osobę, czyli taka, które totalnie będzie podejmować decyzje w sposób losowy (np. podrzucając kostkę). Oczywiście będzie ładnie mówić i td, ale strategia będzie losowa, jak myślisz czy da się szybko odróżnić tę losową osobę?
Dlatego stwierdzenie, na ile jest ważna ta osoba, na podstawie tylko częstotliwości wystąpienia w polu widzenia, może być strategią, która dość mocno zniekształca rzeczywistość. Kontynuując tę analogię, zwykle naprawdę ważne osoby, są szeregowymi ludźmi, zwykły Kowalski lub Nowak, na plecach których trzymają się krytyczne procesy.
Weźmiemy przykład z życia, np. masz model, który prognozuje ceny mieszkań i chcemy z jego pomocą sprawdzić ważność cech. Pierwsze trzy pozycje to będzie: powierzchnia mieszkania, ilość pokoi, czy jest winda w budynku. Teraz dodajmy w 100% losową cechę, po prostu dla każdego mieszkania wygenerujemy losową wartość i sprawdźmy, jaka jest ważność tej cechy dla modelu. W tym przypadku ona zajęła czwartą pozycję, wyprzedzając takie kwestie jak taras, garaż, ogródek itd. Dlaczego? Bo właśnie to jest wada klasycznego algorytmu odpowiedzialnego za ważność cech.
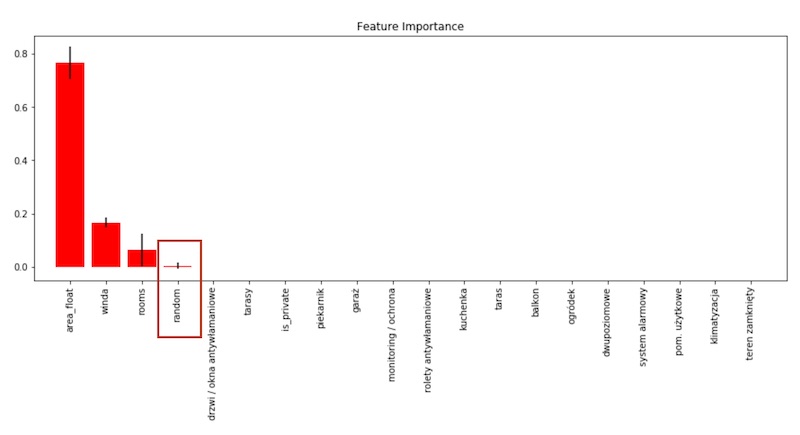
Pomijając szczegóły techniczne dlaczego to się dzieje, jak powinna być reakcja? Czy to oznacza, że domyślne algorytmy ważności cech są absurdalne? Ciężko jest podzielić świat na białe i czarne, jest sporo odcieni szarości. Dokładnie tak jest i w tym przypadku. Należy traktować tę ważność ze świadomością, że to czasem robi bzdurne rzeczy.
Czy są narzędzia, które pomagają rozwiązać wyżej opisany problem? Tak, jest kilka, ale już mniej znanych i dostępnych. Natomiast warto je znać. Jeden z algorytmów, który zastosujemy na szkoleniu wprowadza jedną drobną zmianę badania ważności. Załóżmy, że mamy 5 cech, które bierzemy pod uwagę, takie jak powierzchnia mieszkania, ilość pokoi, obecność tarasu, miejsce parkingowe i na koniec jeszcze jedna cecha w 100% losowa czyli taka, która jest tylko i wyłącznie szumem informacyjnym.
Teraz zróbmy jedną prostą, ale sprytną sztuczkę. Kiedy model już jest wytrenowany, robimy prognozę i dostajemy pewien wynik. Następnie po kolei bierzemy cechę, np. powierzchnia oraz losowa i je mieszamy, czyli dla mieszkania z pierwszego wiersza tabelu przypisujemy wartość z 55, dla mieszkania z drugiego wiersza przypisujemy wartość z 77. Powtórzę jeszcze raz, że robimy to losowo, następnie sprawdzamy, jak takie losowanie wierszy tej cechy wpływa na wynik. Jak łatwo się domyśleć, losowanie wartości dla powierzchni znacząco pogorszy wynik prognozowania. Natomiast losowanie cechy, która już jest losowa zwróci ten sam wynik lub bardzo podobny. Na podstawie tego możemy stwierdzić, na ile ta czy inna cecha jest ważna.
Taka technika rozwiązała jeden problem, natomiast nadal ma swoje wady. Konkretna cecha w zależności od wartości ma różny wpływ na model. Innymi słowy fajnie byłoby mieć dwa wymiary, czyli jak konkretna cecha oraz jej wartość wpływa na model. To już bardziej zaawansowane techniki, ale całkiem wartościowe, żeby stosować je w praktyce i analizować, jak nasz model podejmuje decyzje, jak również wykrywać pewne ograniczenia modelu.
Problem 3: Nie wiem, jak wdraża się model.
To jest kolejny obszar, który jest ignorowany przez środowisko akademickie, książki, czy również kursy (oczywiście w moim to mam, ale to dlatego zwracam na to uwagę). To jest paradoks. Każdy, kto wdraża model na produkcję, wie, na ile to jest skomplikowany i ciężki proces. Z drugiej strony jak zapytasz, w jaki sposób udało się zdobyć to doświadczenie to odpowiedź jest taka: nauka na własnej skórze, popełnianie własnych błędów.
Problem z wdrożeniem jest bardzo szeroki. Czym bardziej skomplikowana firma (np. duży ruch na stronie rzędu miliony wejść dziennie) tym jest trudniej. Natomiast jak zwykle to bywa, są pewne gradacje wtajemniczenia do tematu.
Wdrożenie modelu może zostać przeprowadzone poprzez stworzenie tak zwnaego mikroserwisu i komunikacja z tym serwisem będzie poprzez API. Swoją drogą podobnie funkcjonują usługi udostępniane przez wielkich graczy w tym obszarze, np. Google, Amazon czy Microsoft.
Zrobienie prostego mikroserwisu jest w miarę łatwe, wystarczy tylko poznać kierunek myślenia. Mało tego, później to rozwiązanie można robić coraz bardziej skomplikowanym zdobywając własne doświadczenie lub posługując się doświadczeniem kolegów czy koleżanek, które na tym lepiej się znają. Np. skalowanie mikroserwisu jest stosunkowe proste i to spokojnie mogą zrobić ludzie, którzy wiedzą jak skalować taki mikroserwis, a niekoniecznie wiedzą, jak działa uczenie maszynowe. Innymi słowy, taki mikroserwis jest mostem pomiędzy ludźmi z różnymi umiejętnościami.
Na szkoleniu pokażę praktycznie, jak można zbudować coś więcej niż tylko wytrenowany model, czyli innymi słowy powstanie produkt lub mówiąc bardziej precyzyjnie MVP. W drugi dzień szkolenia zadaniem będzie rozwiązać jeden z dwóch problemów. Pierwszy to prognozowanie kosztu nieruchomości, drugi to prognozowanie kosztów samochodów. Dane są rzeczywiste. Twoim zadaniem będzie po pierwsze wyczyścić dane, wytrenować model, zinterpretować jego wynik, usprawnić dodając kolejne cechy, wytrenować finalną wersję i uwaga, wdrożyć to na umowną produkcję.
Umożliwisz końcowemu użytkownikowi z niego skorzystać używając zwykłej strony internetowej, gdzie będzie mógł posortować mieszkania. W efekcie chodzi o to, by zostawić tylko 50 takich mieszkań, które kosztują znacznie mniej niż powinny i wtedy ekspert od nieruchomości ma nam tylko sprawdzić te 50 ofert manualnie i znaleźć swoją okazję.
Ze względów organizacyjnych nie wszyscy będą mogli wziąć udział w szkoleniu. Miejsc mamy 25, a na moment pisania tego artykułu zajętych jest już 10. Jeśli nie możesz uczestniczyć w szkoleniu, poszukaj samodzielnie informacji o mikroserwisach, o “rest API”, wpisz w wyszukiwarce “machine learning via rest API”. Polecam materiały w języku angielskim, ponieważ jest ich znacznie więcej niż tych po polsku.
Już zamykając temat szkolenia DataWorkshop Tour, które odbędzie się w Warszawie 30-31 maja lub 1 czerwca (ale wtedy jednodniowe). Planując go wziąłem pod uwagę co najmniej 10 problemów, które często słyszę. Część z nich już poruszyłem w tym odcinku.
- Nie wiem, jak interpretować wynik modelu.
- Przerobiłam/em kurs(y), ale nadal nie wiem, jak zabrać się samemu za praktykę.
- Nie wiem, jak model działa „pod spodem”.
- Nie wiem, jak podejść do praktycznego problemu za pomocą ML.
- Nie wiem, na czym polega „czyszczenie danych”.
- Nie wiem, jak tworzyć nowe cechy (ang. feature engineering).
- Mam niespójny obraz tego, jak przebiega proces uczenia maszynowego.
- Nie wiem, jak wdraża się model.
- Nie wiem, które modele działają lepiej i których lepiej używać na produkcji.
- Nie wiem, jak udostępnić model przez API.
Jeśli pojawił się na Twojej drodze któryś z tych problemów, to zbliża się okazja, aby rozwiać wątpliwości, połączyć kropki i przyspieszyć.
Jeszcze trzy istotne informacje na temat szkolenia:
- Odbywa się one tylko raz do roku.
- Z dużym prawdopodobieństwem w następnym roku odbędzie się zagranicą.
- Jak słuchacz i czytelnik BiznesMyśli dostajesz zniżkę 15% do 15 maja 2019 na kod BM_TOUR15. Jeśli rozważasz dołączyć grupą (więcej niż 5 osób), to proszę o kontakt. Dodatkowo jeśli kupujesz jako osoba fizyczna na 1 czerwca, to wtedy również proszę o kontakt, bo dostaniesz zniżkę 23% czyli mniej o VAT (bo to ostatecznie to jest bardziej uczciwe, firma płaci na 23% mniej niż osoba fizyczna).
Osoby, które biorą udział w szkoleniu dostaną jeszcze szereg innych bonusów.
Trochę inny temat, ale pasuje w temacie tego odcinka (w szczególności w ramach pierwszego pytania). Jakiś czas temu miałem okazję rozmawiać z jednym ze słuchaczy BiznesMyśli, absolwentem kursu DataWorkshop. Rozmowa dotyczyła tego, co mogę zrobić, żeby dostarczać dodatkową wartość. Po tej rozmowie i iteracjach kilku pomysłów, pojawiła się koncepcja publikacji serii przypadków użycia maszynowego w biznesie.
Zaczynając do tego, że najpierw tłumaczy się kontekst pewnego biznesu, następnie jakie są potencjalne wyzwania i jak sobie z tym radzić, ewentualnie przykłady z kodem jak można rozwiązać ten czy inny problem używając uczenia maszynowego. Przepuszczając te przykłady przez siebie, już znacznie łatwiej będzie adaptować rozwiązania w różnych kontekstach. Żeby móc zrobić to porządnie, to muszę poświęcić na to dość dużo czasu. Zanim więc do tego przejdę, chciałbym się dowiedzieć, czy to będzie dla Ciebie wartościowe?
Efektywnym kryterium sprawdzenia, czy jest to wartościowe, jest gotowość zapłacenia za to (w tej chwilę myślę nad możliwościami, np. model subskrypcji 100 zł miesięcznie i dostajesz jeden “use case” miesięcznie). Dodatkowo można będzie wpływać na to, jaki będzie kolejny use case. O ile to jest etyczny biznes (wg mojej miary), dla mnie jest wszystko jedno, który przypadek przerobić. Proszę daj znać, jeśli dla Ciebie to jest interesujące, bo ilość inicjatyw, które chodzą mi po głowie to znacznie więcej, niż mogę zrealizować. Dlatego muszę wybierać, Twoja informacja zwrotna pomoże mnie lepiej ułożyć priorytety.
Na koniec jeszcze jedna wiadomość, która może Cię zaciekawić.
13 maja ruszyło trzecie bezpłatne wyzwanie w ramach inicjatywy korona wyzwań uczenia maszynowego. To jest inicjatywa, która małym wysiłkiem umożliwia Ci poczuć, że Ty też możesz nauczyć się uczenia maszynowego! Tym razem będzie wprowadzenie do samochodów autonomicznych. Nauczysz samochód poruszać się autonomicznie w symulatorze.

Swoją drogą, teraz robię eksperymenty i ostatnio więcej publikuję tekstów- monologów, niż wywiadów z gośćmi. Mam nadal w planach zapraszać ekspertów :). Tylko próbuję lepiej wyczuć, które odcinki są bardziej wartościowe dla Ciebie. Dlatego bardzo Cię proszę, podziel się ze mną swoimi wrażeniami. Na ile odcinki, które tworzę są wartościowe dla Ciebie? Bo w tym biegu czasem jest to bardzo trudne utrzymać rytm. Piszę ten tekst późno w nocy, może już trochę przesadzam? Dlatego pytam o Twoją opinię. Jeśli to jest mało wartościowe, to muszę coś zmienić.
Życzę Ci wszystkiego dobrego i do kolejnego przeczytania.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
