

Uczenie nienadzorowane oczami naukowca z DeepMind

Z tego odcinka dowiesz się:
- Co to jest uczenie nienadzorowane? Poznaj fascynujący świat uczenia nienadzorowanego (unsupervised learning) i dlaczego ma ogromny potencjał w przyszłości.
- Jak dostać się na doktorat na Oxfordzie? Adam Kosiorek, świeżo upieczony doktor z Uniwersytetu Oksfordzkiego, dzieli się radami, jak aplikować na doktorat i dlaczego warto to zrobić.
- Czym jest inteligencja? Odkryj, jak naukowcy, w tym Adam, próbują zrozumieć i zaimplementować inteligencję, oraz dlaczego jest to takie trudne.
- Uczenie nienadzorowane a uczenie nadzorowane. Dowiedz się, dlaczego Adam skupia się na uczeniu nienadzorowanym i jakie są jego przewagi nad uczeniem nadzorowanym.
- Autoenkodery – co to jest i do czego służą? Poznaj definicję autoenkoderów i ich praktyczne zastosowania, takie jak kompresja zdjęć.
- Capsule Networks – nowy sposób na rozpoznawanie obiektów. Odkryj, czym są sieci kapsułkowe (capsule networks) i jak mogą zrewolucjonizować rozpoznawanie obiektów.
- Jak eksperymentować w uczeniu maszynowym? Adam dzieli się swoimi doświadczeniami z eksperymentami w uczeniu maszynowym i opowiada o narzędziu Forge, które stworzył, aby je usprawnić.
Chcesz dowiedzieć się więcej o przyszłości AI i inspirujących badaniach? Przeczytaj cały artykuł!
Uczenie nienadzorowane (unsupervised learning) to dziedzina uczenia maszynowego o ogromnym potencjale, która w bliskiej przyszłości będzie nas coraz bardziej zaskakiwać. O tym właśnie rozmawiałem z Adamem Kosiorkiem, doktorem nauk z Uniwersytetu Oksfordzkiego, który obecnie pracuje w DeepMind.
Cześć Adam. Przedstaw się: kim jesteś, czym się zajmujesz, gdzie mieszkasz?
Nazywam się Adam Kosiorek, jestem z Olsztyna. W tej chwili mieszkam w Londynie. Pracuję jako Research Scientist w Google DeepMind (po polsku – badacz). Pracuję nad sztuczną inteligencją i prowadzę badania w tym zakresie.
Dzisiaj będziemy dużo mówić na temat sztucznej inteligencji oraz Twoich badań i publikacji. Zanim do tego przejdziemy, zdradź, co ostatnio ciekawego przeczytałeś? Niekoniecznie musi to być specjalistyczna publikacja.
Czytać akurat lubię. Jedna z ostatnich książek, która bardzo mi się spodobała to „Sapiens” Yuval Noah Harari. Wydaje mi się, że to bardzo ostatnio popularna pozycja. Opowiada o tym, jak staliśmy się ludźmi ze zwierząt, jak wyewoluowaliśmy od małp i prostszych organizmów, jak znaleźliśmy się tu, gdzie teraz jesteśmy. Opowiada o różnych rewolucjach rolniczych, przemysłowych i religii w naszym życiu, roli technologii i wiele więcej. Naprawdę polecam, aczkolwiek jest to nieco dłuższa lektura.
Obecnie, oprócz tego, że pracujesz w DeepMind, robisz doktorat w Oxford. Jak oceniasz te studia, uczelnię, doświadczenie? Czy ciężko jest się dostać?
Zanim odpowiem, sprostuję jedną kwestię. Mniej więcej 2 tygodnie temu, obroniłem się, więc już nie jestem doktorantem, a świeżo upieczonym doktorem. Natomiast prawda, do tej pory byłem na Oxfordzie. Jak się tam dostać? Odpowiedź może brzmieć banalnie. Należy złożyć aplikację. Aplikacja taka wygląda trochę inaczej na studia na poziomie licencjackim, a trochę inaczej na doktorat. Wydaje mi się, że na doktorat jest dużo łatwiej się dostać, niż na licencjat.
Aplikacja składa się z dwóch elementów:
- List opisujący, czym byśmy chcieli się zajmować, dlaczego właśnie na Oxfordzie, jakie tematy nas interesują itd.
- Druga część tej aplikacji to są referencje od ekspertów w dziedzinie. Najlepiej profesorów, z którymi wcześniej pracowaliśmy, którzy nas znają i dobrze, aby byli dosyć sławni w tej dziedzinie. Najlepiej jest znaleźć możliwości pracy z kimś, kto jest w miarę rozpoznawalny i dać się tej osobie poznać, żeby dostać taką referencję.
Faktycznie, brzmi to w miarę prosto. Czy było warto? Jak to oceniasz to teraz z perspektywy czasu?
Wydaje mi się, że jest warto. Moją drugą najlepszą opcją byłoby zostać na doktoracie na Uniwersytecie Technicznym w Monachium, gdzie zrobiłem swoją magisterkę. Doktorat w Monachium też byłby bardzo dobry, natomiast różnica jest taka, że w Niemczech ludzie często traktują doktoraty jako taką zwykłą pracę, gdzie przychodzą na 09:00, wychodzą o 17:00, nie pracują w weekendy. Natomiast na Oxfordzie jest dużo większa presja, są zazwyczaj przyjmowani bardzo dobrzy ludzie, którzy osiągają bardzo dobre rezultaty.
Poprzez chęć dorównania im wytwarza się presja i ludzie pracują nieco więcej. Niektórym może to nie odpowiadać, natomiast dla mnie jest to coś, czego akurat chciałem i potrzebowałem. Oxford, jeżeli chodzi o machine learning, jest również świetnym miejscem dlatego, że jest tu około 15 grup badawczych na światowym poziomie. Jest mnóstwo ludzi, mnóstwo różnych tematów, nad którymi te grupy pracują, więc jest dosyć duża swoboda pracy. Można też w dosyć łatwy sposób zbudować dobrą siatkę kontaktów z najlepszymi naukowcami na świecie.
Brzmi jak środowisko, które po pierwsze da się łatwo zmobilizować, a po drugie ta sieć kontaktów robi potem swoje i naprawdę później te kilka lat w Oxfordzie procentuje.
Na Twoim Twitterze jest takie zdanie: „próbuję zrozumieć, czym jest inteligencja i ją zaimplementować”. Gdzie jesteś teraz, jeżeli chodzi o inteligencję? Na ile udało Ci się zrozumieć, czym ona jest? Jak wyglądają postępy?
Zacznę od tego, że to stwierdzenie jest nieco naciągane. Nie wiem, czy jest chociaż jedna osoba na świecie, która tak naprawdę rozumie, czym jest inteligencja. To pojęcie jest trudne do zdefiniowania. Wydaje mi się, że obecnie posiadane definicje są zbyt szerokie.
Na przykład, niektórzy definiują inteligencję jako umiejętność rozwiązywania wszelkiego rodzaju problemów, bądź umiejętność szybkiego uczenia się rozwiązywania wszelkiego rodzaju problemów. Natomiast jeżeli pomyślimy o problemach wszelkiego rodzaju, jest to niesamowicie duża przestrzeń problemów.
Jeżeli użyjemy tej definicji, okazuje się, że ludzie wcale nie są inteligentni. Możemy zaprojektować bardzo dużo problemów, które są prawie losowe, gdzie są losowe związki pomiędzy różnymi elementami. Okazuje się, że ludzie są bardzo kiepscy w rozwiązywaniu tego typu problemów. Nawet dosyć ciężko jest zawrzeć intuicyjne rozumienie inteligencji w prostej definicji. To jest jeden punkt widzenia.
Z innego zaś rozumiemy na poziomie mechanicznym czy kalkulacyjnym, jak niektóre mechanizmy w mózgu ludzkim i innych zwierząt pracują. Natomiast bardzo często ta wiedza może nam dać pewną inspirację, jak budować system uczenia maszynowego. Zazwyczaj jest ona jednak zbyt mało precyzyjna, żeby naprawdę powiedzieć nam, jak pewne rzeczy powinny funkcjonować. Nawet jeżeli chodzi o intuicję, zazwyczaj dotyczy to bardzo niskopoziomowych podsystemów mózgu.
Mówiąc krótko, tak naprawdę nie wiemy, czym jest inteligencja i jak ją osiągnąć. Natomiast wiemy, jakie podzespoły znajdują się w mózgu i mniej więcej jakie funkcje różne podzespoły pełnią, co daje nam pierwowzór, na którym możemy się wzorować i który możemy próbować zaimplementować.
Twoje badania zwykle skupiają się na uczeniu nienadzorowanym, czyli unsupervised learning. W szczególności działasz sporo z autoenkoderami. Z jednej strony, domyślam się, że ten wybór podyktowany jest tym, że uczenie nadzorowane jest bardziej ograniczone.
Chciałbym usłyszeć Twoją wersję, podziel się swoją motywacją, dlaczego uczenie tylko nienadzorowane? Jeżeli skupiasz się tylko na tym, to jaką przyszłość możesz zaprognozować tej dziedzinie? Jak to się rozwinie w ciągu najbliższych 3-5 lat na podstawie tej wiedzy, którą już teraz posiadasz?
To prawda, że skupiam się głównie na uczeniu nienadzorowanym. Mam może 3 publikacje, które są również o uczeniu nadzorowanym, natomiast na pewno nie jest to główna część mojego badania. Tak, jak zauważyłeś, uczenie nadzorowane ma pewne ograniczenia, które wynikają głównie z tego, że do uczenia nadzorowanego potrzebujemy danych oznaczonych przez człowieka. Czyli potrzebujemy dane zebrane przez różne sensory (np. zdjęcia) i oznaczenia (czyli np. kwadraciki, narysowane na około twarzy, ludzi na tych zdjęciach).
Żeby dostać takie kwadraciki, zazwyczaj potrzebujemy armii ludzi, która będzie takie kwadraciki rysować. Jest to drogi i czasochłonny proces. Za każdym razem kiedy dostaniemy nowe dane, musimy zatrudnić ludzi i zbierać te oznaczenia. Nie możemy np. wykorzystać setki tysięcy godzin filmów dostępnych na YouTube, żeby nauczyć nasz algorytm, ponieważ mimo że posiadamy dane w postaci tych filmów, to nie mamy do nich oznaczeń, co więcej z biegiem czasu często widziane przez algorytm dane zmieniają się.
Np. jeżeli za tydzień mielibyśmy robota, który działa nieustannie i z biegiem czasu zmienia się sceneria, w której ten robot się przemieszcza (np. rozbudowuje się miasto, zmieniają się budynki itd.), to gdyby taki robot korzystał tylko i wyłącznie z uczenia z nauczycielem, to mógłby mieć problem z dostosowaniem się do nowego wizerunku otoczenia.
Natomiast jeżeli taki robot mógłby uczyć się na bieżąco, to mógłby się dostosowywać. Uczenie na bieżąco oznacza, że nie ma oznaczeń wygenerowanych przez człowieka, w związku z tym musimy wykorzystać uczenie nienadzorowane.
Te wspomniane etykiety są także często nieprecyzyjne. Człowiek sam w sobie jest niedeterministyczny. Ta sama osoba potrafi inaczej oznaczyć tę samą ramkę, a tym bardziej jak jest grono rozproszonych ludzi w świecie, to ten input jeszcze bardziej byłby zaszumiony. Zresztą słynny ImageNet też był robiony w taki sposób, że niektóre obrazki były robione po kilka razy, żeby upewnić się, że to jakoś w miarę się pokrywa, ale to też nie było proste zadanie.
Teraz już wiemy, o co chodzi z uczeniem nienadzorowanym i jaka była Twoja motywacja. To chodźmy dalej w kierunku autoenkoderów. Wyjaśnij i podaj klasyczną definicję autoenkodera. Co to jest? Co on robi? Czy mógłbyś podać jakieś przykłady?
Wydaje mi się, że taka ogólna definicja to byłby model, który potrafi skompresować dane i później dokonać ich dekompresji.
Kompresja to według mnie dobre skojarzenie. Mamy w tym przypadku dwa czynniki. Wiele osób nie miało styczności z autoenkoderami, ale pewnie każdy używał zipa albo inny kompresora danych – czyli wtedy, kiedy pakujemy dany plik w jakąś taką postać “pomiędzy”. To jest nadal plik, ale nie ten oryginalny i zajmuje troszkę mniej miejsca. Później jakiś inny program albo funkcjonalność tego samego programu to odczytuje. Gdzie taki autoenkoder może być użyteczny?
Prostym i dosyć powszechnym przykładem jest np. kompresja zdjęć. Dzisiaj jednym z najpopularniejszych formatów jest .jpg, który jest skompresowanym zdjęciem. Jest to kompresja stratna, która nie zawiera wszystkich informacji, natomiast zdekompresowane zdjęcie wygląda bardzo podobnie do tego przed kompresją.
Jpg jest standardem ręcznie zaprojektowanym, co zajęło wiele lat. Ma jakieś właściwości, jeżeli chodzi o kompresję, natomiast okazuje się, że dzisiejsze autoenkodery wykorzystujące najnowsze osiągnięcia z uczenia maszynowego, potrafią nauczyć się kompresować zdjęcia dużo lepiej niż .jpg, w przeciągu minut, co może spowodować zaoszczędzenie olbrzymiej ilości danych (np. przy przesyłaniu zdjęć przez Internet).
To bardzo fajny przykład. Google też to próbuje stosować, kiedy się wysyła mniejsze zdjęcie i komórka, która pobrała to zdjęcie, potrafi to zdjęcie rekonstruować. W ten sposób to funkcjonuje i faktycznie nie trzeba przesyłać dużych plików. Przy czym po otworzeniu zdjęcia wygląda ono bardzo podobnie do oryginalnego i nie ma za bardzo tej straty. Myślę, że też fajnie wspomnieć o przypadkach związanych z tym, że możemy zaszumić sobie to zdjęcie i potem otworzyć takie, które nie jest zaszumione.
Albo np. przypadki związane z nakładaniem, coś jest na tym zdjęciu wycięte i później można to odtworzyć. Co prawda, to też ma negatywne skutki. Było dość głośno na ten temat, kiedy nagle się okazało, że wszystkie znaki wodne można wyeliminować – to, co potrafi autoenkoder zrobić, czyli odszumić od „niepotrzebnych” rzeczy.
Więc teraz, jak ktoś myśli, że dodając znak wodny do zdjęcia może spać spokojnie, to już te czasy niestety minęły. To się wszystko rozwija, więc trzeba to robić bardziej dynamicznie, niż tylko poprzez dodanie statycznego znaku wodnego.
Podsumowując, jeżeli chodzi o autoenkoder, mamy kawałek tej sieci na wejściu np. zdjęcie, które jest pobierane i robimy wszystko, żeby zredukować wymiary. Zostaje jakiś powiedzmy wektor. Później jest inny kawałek sieci, który próbuje z tego wektora odtworzyć zdjęcie oryginalne.
Ale teraz przejdźmy do tego, nad czym pracujesz więcej, czyli variational autoenkoders (VAE). Wyjaśnij, dlaczego VAE używasz najczęściej? Na czym polega różnica od klasycznego autoenkodera?
Główną różnicą jest to, że autoenkoder wariacyjny jest to model stochastyczny. Zazwyczaj zwykłe autoenkodery są deterministyczne tzn., że mamy coś na wejściu (np. zaszumiony obrazek), później mamy reprezentację tego zaszumionego obrazka na wejściu, który jest wektorem uzyskanym w sposób deterministyczny i później staramy się zrekonstruować z tego wektora odszumiony obrazek, bądź zaszumiony (w zależności od aplikacji).
Jednym z problemów w tym autoenkoderze jest to, że jest tylko jedno poprawne rozwiązanie, czy też istnieje tylko jeden rodzaj poprawnej rekonstrukcji. Nie możemy zawrzeć w tym naszym wektorze, który reprezentuje to zdjęcie, niepewności związanej z tym obrazkiem czy z rekonstrukcją.
Natomiast autoenkoder wariacyjny to model stochastyczny, gdzie ten wektor, który jest reprezentacją naszego obrazka, jest zaszumiony. Dodajemy do niego pewien szum, co pozwala nam zakodować pewną niepewność. Dzięki temu jeden konkretny wektor pozwala nam zrekonstruować wiele różnych wariantów tego obrazka, który mieliśmy na wejściu.
Na tym polega nasz świat. Jak spróbujemy powtórzyć to samo działanie i np. jeżeli komuś przygotujemy przepis i powiemy: „Słuchaj, ja całe życie robiłem tak i tak, więc rób te same kroki, a osiągniesz to samo”, to zwykle tak nie działa, bo życie zawsze gdzieś nas zaskoczy. Tak tylko dodam, że jak mówisz „stochastyczne”, to myślę, że dla osób, które nie są w tej terminologii obeznane, to pewnie słowo „losowy” będzie bardziej zrozumiałe.
Sprowadzamy się do tego, że w tym przypadku przepuszczając przez ten nasz model np. zdjęcie, to w klasycznym autoenkoderze dostajemy ten sam wynik (jeżeli model już jest wytrenowany), a w przypadku autoenkodera wariacyjnego przepuszczając za każdym razem model, wynik może być nieco inny. Czy to jest tak, że też mamy parametry, które umożliwiają ten rozrzut wyników, żeby można było ten model jakoś ograniczyć? Na tym właśnie polega trenowanie tego modelu, że dobieramy te parametry, prawda?
Tak, oba modele zazwyczaj są to dwie sieci neuronowe. Jeżeli chodzi o implementację, to różnica sprowadza się do tego, że w autoenkoderze, enkoder jest jedną siecią neuronową, która daje nam ten wektor będący reprezentacją obrazka na wejściu.
Natomiast w autoenkoderze wariacyjnym, enkoder daje nam nie jeden wektor, ale rozkład prawdopodobieństwa na przestrzeni różnych wektorów, które mogą opisywać bądź reprezentować obrazek na wejściu.
W najprostszym przypadku ten rozkład jest tu po prostu wielowymiarowym rozkładem gaussowskim. Wtedy implementacja polega na tym, że ten enkoder daje nam wektor średni i kowariancję. Kowariancja jest w tym przypadku zazwyczaj macierzą diagonalną, więc możemy ją wyrazić jako wektor. Czyli enkoder daje nam te dwa wektory, dzięki czemu możemy uzyskać ten rozkład gaussowski, z którego próbki później opisują nam to, co mamy na wejściu (czyli ten obrazek).
Ponieważ w tych próbkach jest niezerowa wariancja, możemy zrekonstruować nasz obrazek na wiele różnych sposobów, rekonstruując różne próbki z tego rozkładu prawdopodobieństwa.
Jak mawiali mądrzy ludzie: umiejętność rozpoznawania obiektów i zrozumienia relacji pomiędzy tymi obiektami jest kamieniem węgielnym ludzkiej inteligencji. Spróbujmy najpierw zrozumieć, co to oznacza w praktyce. Ważność rozpoznania obiektów i relacji – dlaczego akurat to jest taki ważny element? Jak to się robi, jeżeli chodzi o uczenie nadzorowane? Większość elementów się skupia na ten moment, używając supervised learning, w szczególności jeżeli mówimy o zastosowaniu w praktyce, bo ta gałąź nienadzorowana dopiero się rozkręca.
My jako ludzie, ale także inne istoty (ożywione i nieożywione), musimy cały czas poruszać się w swoim środowisku i musimy nieustannie wchodzić z nim w interakcje. Wchodzenie w interakcje ze środowiskiem zazwyczaj polega na wchodzeniu w interakcje z różnymi obiektami w tym środowisku. Możemy to zrobić bezpośrednio, gdzie sami wchodzimy w interakcję z tymi obiektami (np. dotykamy ich, przesuwamy) bądź możemy używać do tego narzędzi.
Użycie narzędzi jest to używanie innych obiektów do manipulowania otoczeniem. Żeby to było możliwe i żeby tak naprawdę życie było możliwe, musimy zrozumieć, co znajduje się w naszym otoczeniu. Musimy być w stanie wykryć obiekty, opisać je. Nie musi to być świadome, natomiast musimy wiedzieć, jakie właściwości mają różne obiekty oraz jakie są relacje między nimi.
Na przykład: znamy prawa fizyki i wiemy, że jak coś zrzucimy ze stołu, to spadnie na ziemię, ale z drugiej strony oznacza to, że ten stół podpiera ten przedmiot, który na nim stoi. Używając relacji tego typu, możemy wykorzystywać obiekty w naszym otoczeniu jako narzędzia. Wtedy widząc np. banana wiszącego na drzewie, możemy wziąć krzesło bądź kamień, postawić go pod drzewem, wspiąć się i zerwać tego banana.
A propos tych relacji, chciałem moją obserwację dotyczącą tego, jak się uczymy. Obserwując najpierw synka teraz już bardziej córkę (która ma ponad roczek), zauważyłem, jak uczy się małe dziecko. Najpierw jest w miarę czysta karta i później np. jak moja córka upadła i uderzyła się o łóżko, to trochę ją zabolało.
Teraz jak próbuje położyć się na bok, to wie, że to może zaboleć, zamyka oczy i robi to bardziej delikatnie. Nauczyła się w ten sposób, że to boli. My jako ludzie bardzo często poznajemy ten świat poprzez eksperymenty. Część z nich faktycznie musimy dokonać swoimi rękoma, a części się po prostu domyślamy. Znajdując pewne analogie i wzorce, nie musimy całego świata spróbować, żeby go poznać.
Nie poznamy go w całości, ale przynajmniej takie podstawowe rzeczy, które zdają się bardzo trywialne dla osoby dorosłej. Nie musimy ich wszystkich spróbować. Wiemy, że jak włożymy dwa palce do kontaktu, to kopnie nas prąd, a nie wszyscy to sprawdzili. To jest ciekawa rzecz, jak my jako ludzie uczymy się, jak wyciągamy te relacje. Nie mówię, że to jest kierunek, żeby zdefiniować inteligencję, ale to są powiązane punkt.
Obecne modele, w szczególności związane z uczeniem nadzorowanym, zupełnie nie rozumieją tej relacji. Potrafią jeszcze wykrywać w taki sposób statystyczny, że na danym zdjęciu jest coś (kot, pies itd.), ale nie potrafią zrozumieć, że kot będzie uciekał za chwilę, bo tutaj jest także pies.
W tym przypadku to bym powiedział, że to zależy od danych, jakich używamy do trenowania. Natomiast wydaje mi się, że to, co chciałeś powiedzieć to to, że dzisiejsze algorytmy uczą się wykrywać nie tyle związki przyczynowo-skutkowe, co zależności statystyczne. Dzisiaj to właśnie wykrywanie związków przyczynowo-skutkowych jest bardzo aktywnym obszarem badań. Bardzo wiele publikacji powstaje właśnie w tej dziedzinie.
W 2016 r. naukowcy z DeepMind opublikowali pracę o tzw. AIR (Attend-Infer-Repeat), która przykuła Twoją uwagę. Zresztą też napisałeś potem swoją własną implementację tego algorytmu, który jest dostępny na GitHubie. Później to na tyle Cię zainspirowało, że napisałeś swoją publikację z tzw. sequential. Wyjaśnij troszkę bardziej kontekst – czym jest AIR? Jakie ma wady?
AIR reprezentuje bardzo dużą część moich zainteresowań sztuczną inteligencją i inteligencją jako taką. AIR jest to stochastyczny model, który potrafi opisać różne obrazki, różną ilością zmiennych. Oznacza to, że jeżeli mamy bardzo prosty obrazek np. jabłko na stole, możemy taki obrazek opisać tylko jedną zmienną, która w tym przypadku będzie opisywała to jabłko. Natomiast jeżeli mamy bardziej skomplikowaną scenę, możemy użyć większej ilości zmiennych, gdzie każda z nich będzie opisywała inny element tej sceny.
Jest to fajne, ponieważ pozwala nam to skompresować zdjęcia do rozmiaru, który odpowiada ilości elementów na tym zdjęciu, czyli bardziej skomplikowane zdjęcie, będzie opisane większą ilością zmiennych. Inną równie ciekawą rzeczą jest to, że każda zmienna będzie opisywała inny przedmiot na tym zdjęciu. Jest to ciekawe dlatego, że AIR jest elementem, który uczy się bez nauczyciela.
Żeby opisać różne przedmioty różnymi zmiennymi, AIR musi nauczyć się wykrywać te przedmioty, wyizolować je z tego zdjęcia i opisać. Co ciekawe, w odróżnieniu od innych modeli, które wykrywają obiekty, AIR opisuje obiekt, nie tylko opisując jego położenie na zdjęciu (czyli współrzędne x, y i rozmiary), ale również daje nam wektor, który opisuje bardzo dokładnie wygląd tego obiektu.
Tego typu reprezentacja (tzn. reprezentacja zdjęcia złożona z wielu zmiennych, opisujących różne elementy na nim), pozwala nam wnioskować relacje pomiędzy obiektami na tym zdjęciu i odpowiadać na często dosyć skomplikowane pytania (o to zdjęcie, o przedmioty na nim).
Brzmi to ciekawie, prawie tak, jakby działa się jakaś magia, że nie mówimy modelowi, co jest na tym zdjęciu, a on sam potrafi się domyślić, zbadać lokalizację tych przedmiotów, a przy okazji reprezentację wektorową. Innymi słowy – jak mam zdjęcie, a którym jest stół, na nim klocki, to on jest w stanie wychwycić te poszczególne klocki i je przenieść, bo może robić różne manipulacje matematyczne, również geometryczne. Prawda?
Tak, to prawda. Niestety ten model ma też sporo wad. Jedną z nich jest to, że ten model działa tylko na bardzo prostych zdjęciach, reprezentujących bardzo proste sceny np. obiekty leżące na stole, cyferki na czarnym tle. Niestety on nie działa z bardziej skomplikowanymi scenami. Natomiast w tej chwili są już publikacje, które prezentują rozszerzenia tego modelu, które są w stanie działać na dosyć skomplikowanych scenach.
Jest też trochę problemów technicznych z jego implementacją. Sam model zawiera wiele komponentów. Trudnością techniczną jest to, że różna ilość zmiennych do opisu różnych wejść (czy obrazków) oznacza, że musimy podjąć decyzję w pewnym momencie, ile tych zmiennych ma być.
Decyzja ta jest związana z pracą z dyskretnym rozkładem prawdopodobieństwa. Obliczanie gradientów pochodnych w rozkładach dyskretnych jest dosyć trudne i wymaga dużej ilości plików. Da się to zrobić, natomiast trenowanie takich modeli jest dużo droższe i niestety te modele nie skalują się tak dobrze do dużych danych.
Powiedziałeś też o kolejnych publikacjach, które te wady częściowo naprawiają. Skupmy się teraz na Twojej publikacji, czyli SQAIR (Sequential Attend, Infer, Repeat). Co udało się osiągnąć? Co udało się naprawić z tej poprzedniej inspiracji, jeśli chodzi o pierwotny model AIR?
Po pierwsze AIR jest modelem, który działa na poszczególnych zdjęciach. Jeżeli użyjemy AIR do opisania zdjęcia kilkoma zmiennymi, dostaniemy zmienne, opisujące różne obiekty. Wszystko fajnie, ale teraz jeżeli mamy wideo i zastosujemy ten model do następnej klatki tego filmu, chcielibyśmy mieć zmienne, które znowu opisują te same obiekty i faktycznie AIR może nam to dać. Niestety nie będziemy mieli żadnego prostego sposobu, żeby powiązać zmienne z jednej klatki do zmiennych z następnej.
Nie będziemy wiedzieli, które zmienne przyporządkować do tego samego obiektu. Jeżeli interesuje nas jakiś konkretny obiekt i chcemy wiedzieć, gdzie on się znajduje, jak się porusza, jak się zachowuje, jakie ma relacje w stosunku do innych obiektów widocznych na filmie, niestety AIR nie będzie nam w stanie tego dać.
Po drugie ponieważ AIR pracuje ze zdjęciami, rozkład tego zdjęcia na różne obiekty jest niejednoznaczny, tzn. jeżeli mamy skomplikowany obiekt (nawet człowieka), AIR może rozbić go np. na nogi i tors, ale też może rozbić człowieka na pół, gdzie jedna zmienna będzie opisywała jedną nogę i jedną rękę, a druga będzie opisywała drugą nogę i drugą rękę.
To dlatego że ten rozkład jest dokonywany tylko i wyłącznie na podstawie pikseli, na podstawie jednego zdjęcia. Jeżeli mielibyśmy algorytm, który działa bezpośrednio na video, moglibyśmy wziąć pod uwagę, które części zdjęcia poruszają się razem, a które nie. Biorąc to pod uwagę, moglibyśmy zaklasyfikować człowieka jako jeden obiekt i wtedy reprezentować go, używając tylko jednej zmiennej, która faktycznie wyrazi, jak ten obiekt zmienia się w czasie na różnych klatkach video.
W SQAIR również dostajemy zmienne, które opisują ten sam obiekt w różnych punktach czasu. Możemy tego użyć do śledzenia obiektów.
Co udało nam się osiągnąć? Udało nam się to zastosować do wideo nagranych na kampusie uniwersyteckim, gdzie nauczyliśmy się wykrywać i śledzić ludzi. Udało nam się zrobić to bez nadzoru człowieka, co do tej pory nie było możliwe.

Tam jeszcze jest jedna rzecz, o której nie wspomniałeś, a mnie to też zaciekawiło w tej publikacji. Mam na myśli przewidywanie, czyli z jednej strony obserwowanie tych zmian w czasie rzeczywistym (że jakiś obiekt się porusza), ale również prognozowanie co będzie dalej. Czyli człowiek jest tam gdzie jest, ale za chwilę pójdzie w zupełnie inną stronę.
Tak, możemy również przewidywać przyszłość. Co ciekawe, ponieważ jest to model stochastyczny (czyli losowy), możemy przybliżyć wiele różnych przyszłości. Dzięki temu, możemy przewidzieć różne rozwiązania. Może to być bardzo istotne, np. w przypadku samojeżdżących samochodów, które muszą podejmować decyzje konserwatywne tak, żeby np. nie wpaść na pieszego. W takim przypadku, jeżeli możemy przewidzieć różne ścieżki, którymi pieszy może się poruszać w przyszłości, możemy mieć samochód, który będzie bardzo bezpieczny.
No właśnie, to już jest bardziej rzeczywiste, że ten świat może mieć wiele scenariuszy i ważne jest, aby umiejętnie się przygotować przynajmniej do części z nich. Uwiarygodni to rozwiązanie na większą skalę.
Zmienię temat i przybliżę się do Twojej ostatniej publikacji (przynajmniej z tych, które są publicznie dostępne, bo nie wiem nad czym jeszcze pracujesz teraz). W roku 2017 Hinton wraz ze swoim zespołem przedstawił światu tzw. capsule networks. Hinton jest słynny z tego, że bardzo mocno krytykuje CNN, czyli sieci konwolucyjne argumentując, że to ma swoje ograniczenia.
Akurat te argumenty, których używa, faktycznie przemawiają do mnie. Ciężko to nazwać inteligencją, to bardziej na poziomie statystyki. Zgaduje pewne rzeczy i dość często trafia. Teraz proszę wyjaśnij, czym są capsule networks. Do czego mogą być przydatne? Czy to działa?
Zacznę od ostatniego pytania, czy to działa? Nie, niestety nie, ale cel jest godny podziwu i być może pewnego dnia zaczną działać. Capsule networks (po polsku byłaby to sieć kapsułkowa) mógłbym przedstawić z kilku punktów widzenia. Jeden z ciekawszych jest ten, że sieci neuronowe w tej chwili działają na podstawie poszczególnych neuronów.
Każdy neuron jest to wartość skalarna, czyli po prostu jedna liczba. Natomiast w capsule networks, jeden neuron jest małym wektorem, który opisuje jakiś obiekt bądź jakąś abstrakcję.
Wróćmy na chwilę do CNN. Convolutional Neural Network działa, ponieważ to, co mamy na wejściu, nie zależy od translacji, tego co dajemy na wejściu. Jeżeli mamy np. zdjęcie i zastosujemy CNN na nim, to jeżeli przesuniemy to zdjęcie, przesunie się również wyjście. Po angielsku mówimy, że CNN są translation equivalent, gdzie translation jest jednym z wielu stopni swobody, w stosunku do których zmiany chcielibyśmy modelować w ten sposób.
Inne stopnie swobody tego typu, to jest np. skala, czyli powiększanie, zmniejszanie obiektów bądź rotacja, czyli obserwator monitoruje przedmiot z innego punktu widzenia itd. CNN tego niestety nie robią, choć ostatnio pojawiają się publikacje, które dają tego typu możliwości. Natomiast są one bardzo skomplikowane matematycznie.
Główną ideą capsule networks jest to, że obiekt, skomplikowany przedmiot jest złożony z części. Relacje geometryczne pomiędzy tym obiektem a jego częściami, są niezależne od punktu widzenia obserwatora. Jeżeli powiedzmy, moja ręka jest przesunięta w jakiś sposób względem mojego środka ciężkości, to to przesunięcie nie zależy od tego, z którego punktu ktoś na mnie patrzy.
Jest to prawdą, tylko jeżeli weźmiemy pod uwagę geometrię trójwymiarową. Nie jest to natomiast prawda, jeżeli mówimy o dwuwymiarowych projekcjach, czyli zdjęciu. Jeżeli przyjmiemy to założenie, że obiekt składa się z części i te relacje między obiektami a częściami obiektu nie zależą od pozycji obserwatora i jeżeli założymy, że części i ich pozycje są łatwiejsze do wykrycia niż całe skomplikowane obiekty, to mogąc wykryć te części na zdjęciu, powinniśmy być w stanie użyć informacji o tych częściach do wykrycia obiektu, z których te części się składają.
Jest to dosyć skomplikowane i nie wiem, czy jestem w stanie to wyrazić w kilku zdaniach.
Gdzieś tam pojawia się też ten element interpretacji, że rozkładamy sobie na czynniki pierwsze albo na jakieś mniejsze części i coś tam z tym robimy, pojawiają się wektory, które próbują te części opisywać. Pewien kontekst z tego wybrzmiał.
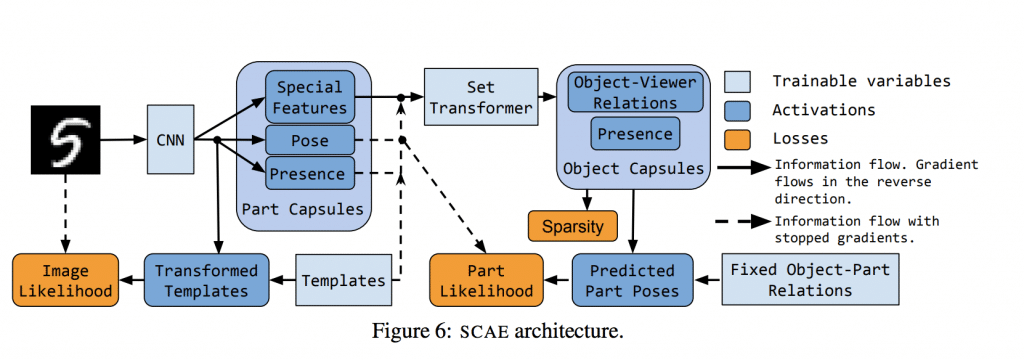
Dążę do tego, że pojawiła się Twoja najnowsza publikacja o nazwie „Stacked Capsule Autoencoders”, w której również Hinton brał udział (albo przynajmniej jest wpisany jako jeden z współautorów). Powiedz trochę więcej, co fajnego udało się osiągnąć tym razem?
Wydaje mi się, że pomysł kapsułek jest nieco zbyt skomplikowany, żeby mógł działać. Natomiast to, co mnie zainteresowało to to, że kapsułki wykorzystują tzw. routing, czyli mamy części i obiekty. Części powinny w pewnym sensie zagłosować na niektóre obiekty. Powoduje to, że potrzebujemy znaleźć ścieżkę, którą informacje powinny popłynąć w takiej sieci neuronowej. Jest to podobne do modelu, który ostatnio stał się popularny w przetwarzaniu języka naturalnego – transformer.
Ja byłem zainteresowany tymi dwoma związkami. Tak się zdarzyło, że akurat byłem na konferencji w Montrealu, gdzie wpadłem na Hintona. Hinton zaprosił mnie na staż do niego do labu. Tak powstało Capsule autoencoders. To, co staraliśmy się osiągnąć, to sieć neuronowa, która byłaby nieco bardziej elastyczna niż oryginalne kapsułki dlatego, że oryginalne kapsułki są bardzo skomplikowane pod względem całej używanej maszynerii.
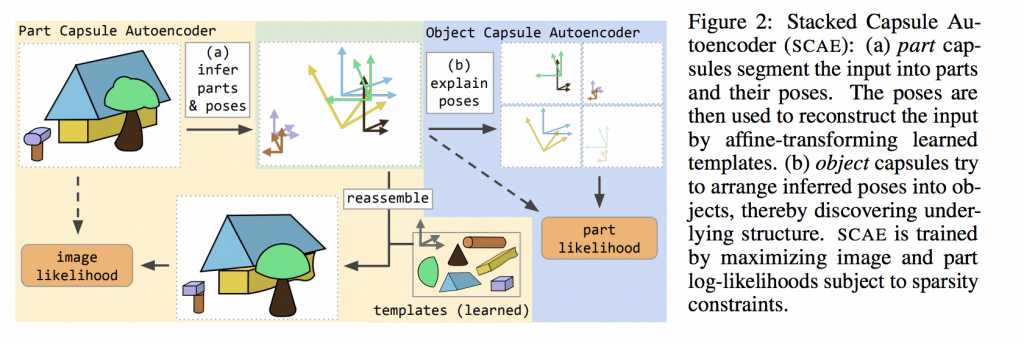
Chcieliśmy mieć model, który pozwoli nam nauczyć się interpretacji wejścia w taki sposób, żeby ta interpretacja dała nam wektory, które przestrzegają pewnych praw. Chcieliśmy mieć takie wektory, które będziemy mogli komponować ze sobą w sposób geometryczny. Trochę tak jak relacje pomiędzy obiektami i ich częściami oraz wektory, które będzie można transformować, używając geometrii trójwymiarowej.
W związku z tym, wzięliśmy sieć neuronową bardzo podobną do kapsułek, natomiast zrobiliśmy ją nieco w drugą stronę.
Kapsułki wcześniej szły od obrazka do wektora prawdopodobieństw przynależności tego obrazka do różnych klas i były wykorzystywane do klasyfikacji obiektów. My zaś odwróciliśmy tę kapsułkę tak, że mogliśmy zacząć od opisu obiektu i mając go, mogliśmy wykorzystać maszynerię podobną do tej, która była w kapsułkach, do wygenerowania obrazka tego obiektu, rozkładając obiekt na różne części i później mapując je bezpośrednio do małych obrazków.
Robiąc to, mogliśmy wziąć tak naprawdę byle jaką sieć neuronową, która mogła się nauczyć reprezentacji oczekiwanych przez nasz dekoder. W związku z tym, otrzymaliśmy model, który uczył się opisywać obrazki bez nauczyciela, gdzie ta reprezentacja, wyuczona przez ten model, przestrzegała zasady geometrii trójwymiarowej.
Zostawiłem sobie na koniec jeszcze dwa pytania praktyczne, które myślę, że będą bardzo przydatne dla osób, które po pierwsze – pracują z uczeniem maszynowym, eksperymentują, a po drugie – zamierzają zbudować wokół tego swoją karierę.
Pierwsze pytanie dotyczy eksperymentów w uczeniu maszynowym, bo tego robisz sporo i zresztą jak wspomniałeś w poście na swoim blogu: z czasem jak się robi takie eksperymenty, to człowiek zaczyna się gubić, bo jest dużo wymiarów zmienności. Tutaj z jednej strony są różne dane, parametry, modele i w tym wszystkim można bardzo łatwo się pogubić.
Są pewne biblioteki, które próbują ten problem rozwiązać, ale też zacząłeś implementować swoją własną o nazwie Forge. Pojawiła się ona jakiś czas temu, ale sprawdzałem, że ostatni update był chyba 2 miesiące temu. Dlaczego w ogóle się zdecydowałeś napisać swoją bibliotekę? Co ona robi lepiej? Czy zamierzasz ją rozwijać dalej? Czy używasz jej we własnych projektach? Komu może być przydatna?
Eksperymenty w uczeniu maszynowym dosyć często przysparzają trudności:
- związanych z zapisywaniem rezultatów generowanych przez eksperymenty,
- zapisywaniem parametrów użytych do przeprowadzenia tych eksperymentów,
- zapisywaniem różnych pośrednich rezultatów z tych eksperymentów,
- zapisywaniem dokładnego stanu kodu, który został użyty do puszczania tych eksperymentów.
To wszystko powoduje, że czasami po tygodniu, czasami po miesiącu regularnego puszczania eksperymentów w nowym projekcie zostajemy ze stosem plików, który jest bardzo ciężki do obsługi, do jakiekolwiek interpretacji i bardzo ciężko się połapać, co jest gdzie oraz jak odtworzyć jakieś rezultaty.
W związku z tym, od kiedy zacząłem swój doktorat, zacząłem budować narzędzia, które pozwalają mi te wszystkie procesy ułatwić, uprzyjemnić. Są to narzędzia, które zacząłem używać ponownie w kolejnych projektach. Natomiast zazwyczaj to używanie ponowne sprowadzało się do tego, że kopiowałem część kodu z poprzedniego projektu do następnego. Niestety nie jest to skalowalne i z każdym projektem tych narzędzi było coraz więcej.
Cały proces zajmował coraz więcej czasu. Powodował, że miałem kilka różnych wersji tych narzędzi itd. W pewnym momencie postanowiłem napisać małą biblioteczkę, nazwałem ją Forge, która zawiera te wszystkie narzędzia.
Niestety nie ma na rynku narzędzia, które byłoby na tyle lekkie, na ile chciałem, a jednocześnie żeby było na tyle elastyczne i pozwalało użytkownikowi zrobić to, co tak naprawdę chce.
Tak powstał Forge. Działa z różnymi frameworkami. Forge pozwala zapisać rezultaty, wszystkie zmiany w kodzie, parametry użyte do przeprowadzania danego eksperymentu. Gdy już mamy wytrenowany model, Forge pozwala w bardzo łatwy i przyjemny sposób uruchomić taki model, żeby sprawdzić, jak się zachowuje.
A komu polecasz? Jest to narzędzie dla osób, które zajmują się podobnymi rzeczami, które Ty robisz, czyli badaniami?
Tak, to jest głównie do badań. Wydaje mi się, że tego typu biblioteka w zasadzie nie ma zastosowania w produkcji.
Ciekawy jestem, takiego łańcucha wydarzeń. Najpierw była publikacja AIR stworzona z naukowcami z DeepMind. Zainteresowałeś się tą publikacją, zbadałeś, zaimplementowałeś ten kod, który był w niej pisany. Później pojawił się SQAIR, gdzie ta publikacja była całkiem udana i pojawiła się na konferencji NIPS (czyli już wyżej się nie da “skoczyć”).
Teraz pracujesz w DeepMind i tutaj nasuwają się pewne pytania. Czy ten łańcuch, o którym teraz powiedziałem, ma ciąg wydarzeń przyczynowo-skutkowy? Czyli jedno zdarzenie wpłynęło na drugie? Jeżeli tak, czy to był przypadek losowy, czy to jest jakiś plan, który sobie wymyśliłeś i tak budujesz swoją karierę?
Dlaczego o to pytam? Teraz pewnie też nas czytają młodsze osoby, które są przed wyborami życiowymi typu, czy zrobić doktorat, w jaki sposób się dostać do DeepMind. Być może to będzie podpowiedź dla nich. Jak to było u Ciebie?
Nie ukrywam, że ja DeepMindem zainteresowałem się przynajmniej dwa lata wcześniej, zanim zacząłem swój doktorat w 2016 r. Wydaje mi się, że pierwsze publikacje DeepMind zacząłem czytać w 2013 r. W zasadzie od samego początku moim marzeniem było, żeby dostać się do DeepMind. Głównie dlatego, że publikacje, które DeepMind wtedy wypuszczał, były bardzo bliskie moim zainteresowaniom.
Gdy pojawił się AIR, był on również bardzo bliski moim zainteresowaniom i dlatego chciałem nad nim pracować. Natomiast nie wyobrażałem sobie, że praca nad tym przybliży mnie do DeepMind w jakiś sposób. Jak się okazało, bezpośrednią konsekwencją tego, że zaimplementowałem i wypuściłem tę implementację na moim GitHubie było to, że autor tej publikacji zauważył ją i polecił mnie wewnętrznie na staż.
Dzięki temu, po pierwszym roku mojego doktoratu dostałem się na staż do DeepMind. Owocem stażu była oferta powrotu jako pełnoetatowy Research Scientist. Tak, ciąg przyczynowo-skutkowy jest tutaj bardzo wyraźny.
Nie wiem, czy w tej chwili implementacja publikacji DeepMind jest dobrą drogą dostania pracy w tej firmie. DeepMind się bardzo rozrósł i nie zatrudnia aż tyle osób, ile zatrudniał wcześniej, w związku z czym dostanie się może być trudniejsze.
Natomiast jeżeli ktoś jest zainteresowany publikacjami, bardzo polecam implementację publikacji naukowych od zera, bo uważam, że jest to jeden z najlepszych sposobów uczenia się i zdobywania doświadczenia w tym, jak tego typu projekty tworzyć, jak implementować modele uczenia maszynowego, co jest w nich tak naprawdę ważne. Tylko w ten sposób możesz zobaczyć, jak trudne to czasami może być.
A także jak często nie da się powtórzyć tego, co jest napisane w publikacji. Zresztą Andrew Ng zawsze mówi, że jak chcesz się rozwinąć, to bierz pierwszą lepszą publikację i spróbuj to powtórzyć. Często niestety jest tak, że to nie jest takie łatwe. Wynika to z różnych aspektów. Z jednej strony osobie, która próbuje to powtórzyć, brakuje umiejętności albo to, co jest w publikacji, nie zawsze jest powtarzalne, bo wynik jest w pewien sposób nakręcony.
Z tym, że jest nakręcony, w większości przypadków polega na tym, że autor publikacji uzyskał jakiś wynik przypadkowo. Część z tych modeli działa nieco losowo i niektóre wyniki są po prostu wyższe od innych. Nie przypisywał bym temu chęci oszukiwania, natomiast to też się na pewno zdarza.
Dobrze, że to podkreśliłeś. Tutaj miałem na myśli to, że często problemem jest oszacowanie na ile osiągnięty wynik nie jest przypadkowy. To jest jedno z wyzwań, z którym się mierzymy w uczeniu maszynowym.
Bardzo dziękuję Adamie, że znalazłeś czas, żeby podzielić się swoim doświadczeniem i opowiedzieć o tym, czym się zajmujesz. Życzę Ci, żeby udało Ci się zrozumieć, czym jest inteligencja i ją zaimplementować.
Dziękuję bardzo Vladimir. Trzymaj się w tych dziwnych czasach.
Jeżeli chcesz coś osiągnąć, to naprawdę warto eksperymentować. Adam mówiąc o swojej drodze do DeepMind zaznaczył, że chciał tam się dostać, ale nie do końca wiedział którą ścieżką. Eksperymentował i próbował znaleźć otwarte drzwi, żeby ktoś go zauważył i zaprosił do środka.
Nie zawsze da się ten proces zaplanować w 100%, zwykle w ogóle nie da się go zaplanować. Z drugiej strony, kiedy zaczynasz działać, eksperymentować, to nagle zauważasz, że któreś podejście zaczyna funkcjonować i świat naprawdę potrafi zaskoczyć tym, jak zareaguje na nasze działania.
Życzę Ci dużo zdrowia przede wszystkim, ale również eksperymentuj, próbuj nowych rzeczy po to, żeby znaleźć to, co naprawdę potrafi Cię pozytywnie zaskoczyć.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.


