

Rozmowa z machine learning engineer z Netguru: obrazowanie hiperspektralne i inne

Sierpień to okres wakacji i odpoczynku. Być może teraz jest czas, kiedy na spokojnie sobie rozważasz, co zrobić dalej, żeby pod koniec roku uznać, że rok 2019 był naprawdę udanym. Rozważ, żeby pojawić się na międzynarodowej konferencji uczenia maszynowego DWCC 2019, która odbędzie się 28 września w Warszawie. Prelegenci są z DeepMind, Facebook, Uber, Stanford itd. Sam jestem aktywnie zaangażowany w organizację tego wydarzenia.
Poświęcam dużo energii i czasu, ale też pokrywam z własnej kieszeni wszystkie koszty. Z punktu widzenia zwykłej kalkulacji biznesowej to nie ma sensu – przynajmniej liczby w Excelu dają do zrozumienia, że to jest zbyt duży koszt. Natomiast gdzieś w środku czuję, że ma to sens, dlatego angażuję się i inspiruję innych do działania. Moim celem jest zrobić naprawdę unikalne wydarzenie. Naszą metryką sukcesu jest usłyszeć “to najlepsza konferencja w tym roku lub nawet najlepsza konferencja, na której byłem.”
W skrócie powiem, że przewidzieliśmy wiele aktywności, aby zaopiekować się i zaangażować uczestników konferencji. Na przykład blok o nazwie AMA – ask me anything, gdzie możesz porozmawiać z prelegentami w bardziej komfortowych warunkach. Z góry ustalona godzina i miejsce, gdzie wybrany prelegent czeka na Ciebie. Dodatkowo zaplanowane będą dyskusyjne obszary i wiele innych rzeczy. Będą także niespodzianki. Wśród organizatorów są osoby twórcze, więc można się spodziewać przeplatania elementów sztuki z uczeniem maszynowym.
Warto być, unikalna okazja… kto wie czy będzie jeszcze taka.
Zaprosiłem w tym artykule do wywiadu Michała Marcinkiewicza. Bardzo ciekawy człowiek, który jest zaangażowany w projekty badawcze związane z uczeniem maszynowym. Michał zrobił na mnie bardzo pozytywne wrażenie. To jest osoba, która znalazła swoje miejsce w życiu i myślę, że jeszcze wiele ciekawych projektów zrealizuje. Zapraszam do lektury.
Cześć Michał, przedstaw się: kim jesteś, czym się zajmujesz, gdzie mieszkasz?
Cześć! Mam na imię Michał. Aktualnie mieszkam w Warszawie i pracuję w Netguru jako machine learning engineer. Zajmuję się wprowadzaniem i rozwojem uczenia maszynowego w naszej firmie. Z wykształcenia jestem fizykiem, studiowałem w Warszawie i we Francji, a teraz wróciłem do Warszawy.
Przyznam się, że jak przygotowywałem odcinek, to bardzo dobrze się bawiłem, w takim pozytywnym sensie, bo ciekawe rzeczy się dzieją i czasem ciężko być na bieżąco ze wszystkimi tematami. Cieszę się, że dzisiaj o tym porozmawiamy. Zanim przejdziemy do meritum, powiedz, co ostatnio interesującego przeczytałeś?
Rozmawiamy teraz o książkach czy o publikacjach z machine learningu?
Raczej o książkach, chociaż o publikacjach możesz wspomnieć, na przykład o jednej wybranej.
Jeżeli chodzi o książki, to aktualnie czytam o historii tworzenia bomby atomowej, autorstwa pana Rhodes’a. Jest to bardzo fajna książka, dosyć długa, ale przyjemna, bo pokazuje właściwie historię, która jest często pomijana, gdy się uczymy historii w szkole, jak właściwie doszło do tego, że bomba atomowa została stworzona. Daje trochę historii o wojnach światowych, jest bardzo dużo fizyki, z którą, jak mówiłem wcześniej, miałem dużo do czynienia i fajnie jest poczytać trochę w życiorysach, o tym, jak to wtedy wszystko się działo.
Mogłem dużo poczytać o tych sławnych fizykach, o prawach których nie tylko słyszałem na studiach, więc bardzo bardzo spodobała mi się ta książka. Polecam wszystkim, nie tylko fizykom, ale także ludziom, którzy mają mało związku z nauką. Jeśli chodzi o publikacje naukowe, to ostatnio uczę się trochę o optymalizacji modeli machine learningowych na telefonach, głównie na iOS, ale też na Androidzie. Studiuję, robię research na temat optymalizacji i wdrożenie modeli, a także kompresji. Chodzi o mobile nety i nie tylko.
Bardzo ciekawe rzeczy. Coraz bardziej nabiera to popularności, jeżeli chodzi o uruchomienie modelu na komórkach. Żeby wyjaśnić nieco kontekst, opowiedz o swojej pracy. Czym się zajmujesz w Netguru?
Mamy obecnie nowo powstały, około roczny, zespół bardzo zdolnych ludzi. Tworzymy razem nasz machine learning division. Ja tam pracuję na stanowisku researchowym i zarządzam małym poddziałem. Cieszę się, że mogę poświęcić praktycznie cały swój czas na research. W związku z tym zajmuję się między innymi wdrażaniem nowych technologii oraz przekazywaniem ich do reszty członków zespołu.
Mamy taką wewnętrzną inicjatywę seminariów, gdzie każdy członek zespołu, który jest chętny, czyta jakiś papier bądź implementuje jakieś rozwiązanie i potem przekazuje je w formie dyskusji reszcie zespołu. Ja zarządzam tym także, pomagam przy tworzeniu oraz oczywiście robię swój własny research. Czasami udaje mi się coś ciekawego znaleźć, napisać z tego papier konferencyjny, wysłać jakiś abstrakt i dalej służę konsultingiem oczywiście w projektach. Jeżeli ktoś ma jakiś problem, chce coś przegadać, to ja jestem na miejscu i służę radą. Taka jest moja pozycja, takie jest moje zadanie w Netguru.
Macie ciekawe podejście do rozwoju i zrozumienia, na czym polega taka twardość dzielenia się wiedzą. Powiedz coś więcej o aplikacji CarLens. Co to jest za aplikacja? Co ona pokazuje? Po co ją stworzyliście?
Aplikacja CarLens jest bardzo ciekawą aplikacją. Gdy dołączyłem do firmy akurat projekt był gdzieś w połowie i było bardzo dużo rzeczy do zrobienia, ponieważ mieliśmy pomysł, co chcemy zrobić, natomiast walczyliśmy trochę z implementacją. Musieliśmy rozpoznawać marki samochodów, coś na zasadzie zbierania samochodów na ulicy. W sensie: użytkownik wyciąga telefon, robi zdjęcie i aplikacja sama rozpozna samochód, a następnie dodaje go do historii.
W ten sposób można było kolekcjonować samochody, które się widzi zwykle na ulicy. To był bardzo ciekawy projekt z punktu widzenia rozwoju, ponieważ to był pierwszy (z tego co wiem) machine learningowy projekt Netguru i tak naprawdę nikt do końca nie wiedział, jak mają być takie produkty, projekty prowadzone. Zarówno my, machine learning deweloperzy, jak i software deweloperzy, także kadra zarządzająca aż po C-level executives nie za bardzo wiedzieliśmy, z której strony powinniśmy ugryźć machine learning, jak się za to zabrać i jak dotrzeć się, żeby wszystko dobrze funkcjonowało. Tutaj jeszcze nie mieliśmy żadnych procesów wprowadzonych, więc to nam pomogło zorganizować naszą pracę efektywnie.
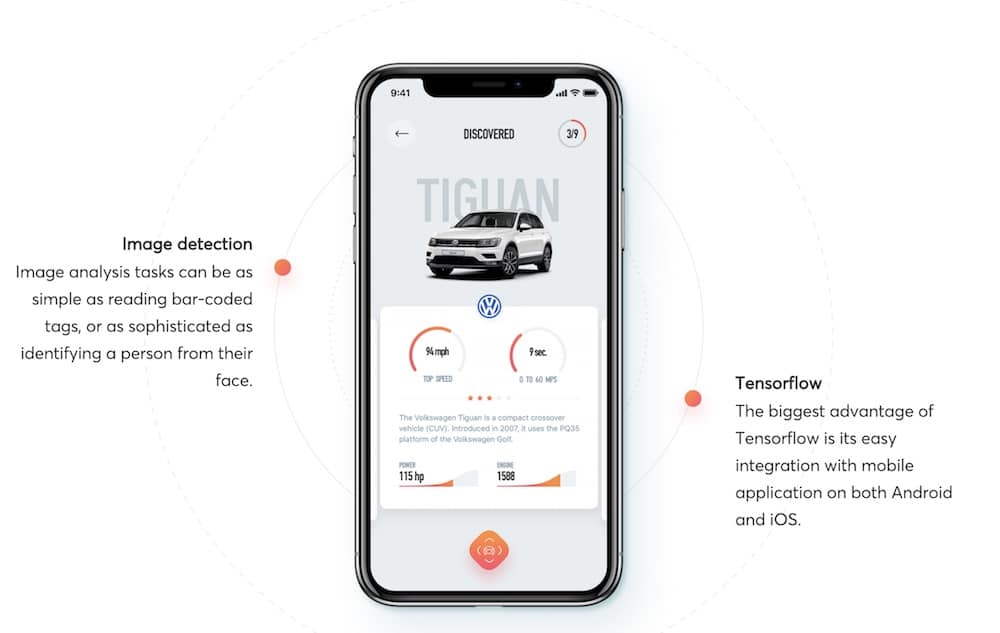
To tyle jeśli chodzi o historię. Sam produkt rozwijał się bardzo ciekawie, ponieważ popełniliśmy dużo błędów, ale także nauczyliśmy się bardzo wiele łącznie z tym, jak naprawdę działa deploy modeli na telefonach, jakie są różnice między Androidem, a iOS (aplikacja jest na obie platformy), jak dane należy zbierać i później analizować, jak wygląda preprocessing na obydwu urządzeniach, bo tutaj też są zupełnie dwa światy.
Także myślę, że najwięcej z tego wynieśliśmy my – machine learning inżynierzy, ponieważ dowiedzieliśmy się, że nie wystarczy po prostu stworzyć model i powiedzieć “okej, nasza praca jest skończona, nic już nie musimy robić, do was teraz należy deweloperzy całe zajęcie”. Także deweloperzy się nauczyli, że machine learning nie jest taki straszny i z nami da się porozmawiać.
Także managerowie dowiedzieli się, że prowadzenie projektów machine learningowych nie jest takie proste i nie należy traktować tego jako zwykłej aplikacji, czyli pisanie feature’ów i robienie dema, co chwilę wprowadzaniem nowych funkcjonalności, bo to po prostu nie działa tak w machine learningu. Myślę, że bardzo wiele się nauczyliśmy tworząc tę aplikację.
Pięknie. Fajnie, że to mówisz. Ze swojego doświadczenia obserwuję następującą sprawę, że dość często ludzie już wiedząc, że uczenie maszynowe bez danych generalnie nie wypali, bo dane są konieczne, to często pomijają kolejny aspekt, że same dane nie wystarczą. Często nawet danych brakuje, ale same dane też nie wystarczą, bo chodzi o kulturę w organizacji.
To, co wy zrobiliście, to jest tak, że na swoim własnym projekcie, który wymyśliliście, zaczęliście budować odpowiednią kulturę i sprawdzać, na ile to się łączy oraz jakie powinny być oczekiwania wobec współpracy w zespołach. Bardzo fajny eksperyment. Cieszy mnie to, że w Polsce są firmy, które podchodzą do tematu w taki sposób. Brzmi bardzo dojrzale i ciekawie. Swoją drogą nie powiedzieliśmy, jak ta aplikacja działa?
Aplikacja przechwytuje obraz z kamery i robi klasyfikację. Na początku klasyfikuje, czy obraz jest samochodem, czy nie. Jeżeli jest samochodem, informacja jest przesyłana wraz ze zdjęciem do kolejnego modelu, który robi finalną klasyfikację modelu. W aplikacji został użyty moduł z augmented reality, czyli ten samochód, który jest w tym momencie klasyfikowany, jest traktowany także w augmented reality. Byliśmy w stanie się nauczyć dwóch technologii na raz. Można powiedzieć, że aplikacja służy do klasyfikacji modeli i marek samochodów, a także do zapamiętywania i kolekcjonowania swojego portfolio samochodów.
Pamiętam, jak mój syn miał 2 lata, to mieliśmy taką tradycję, że jak idziemy po ulicy, to zgadujemy, jaki mija nas samochód. Czasem był taki problem, że zwykle jest logo, ale te starsze samochody czasem miały podniszczone oznaczenia. Syn mnie pytał, co to jest za samochód, a ja nie umiałem odpowiedzieć. Faktycznie więc ta aplikacja mogła być tutaj pomocna, nawet nie tylko mówiąc, co to jest za samochód, a jeszcze tam podpowiadając, jak szybko się rozpędzi do 100 km/h i inne charakterystyki.
Właśnie takie mieliśmy zaimplementowane funkcjonalności i z tym się wiąże ciekawa historia. Na początku mieliśmy 5 czy 4 marki – od tego chcieliśmy zacząć i na tym rozbudowywać. Na tyle było to fajnie, że na początku mieliśmy trochę danych z internetu, a następnie chcieliśmy potestować na bardziej realnych danych, czyli zrobionych telefonami.
Zwołaliśmy Netguru Help i wszyscy użytkownicy, wszyscy pracownicy Netguru, którzy byli chętni (a było ich dosyć sporo) zrobili po prostu zdjęcia tych marek i modeli, których szukaliśmy i potem na tyle było fajnie, że wszyscy się śmiali, że w tym momencie już akurat wszyscy wiemy, jakie te nasze 4 marki są i wszędzie je widzą. Była taka chwila, tydzień obsesji na temat starych modeli samochodów.
Fajna sprawa. Proszę, wyjaśnij, czym są obrazy MRI mózgu i po co one są robione, jak to wygląda fizycznie?
Obrazy MRI, po polsku obrazy z rezonansów magnetycznych są to obrazy, które są wykonywane między innymi w szpitalach, bądź w jednostkach medycznych. Pacjent jest wprowadzany do maszyny, która bezinwazyjne jest w stanie zobrazować, co tak dokładnie znajduje się wewnątrz naszej czaszki i wykryć pewne zmiany, bądź nieregularności bez potrzeby operacji. Jest to bardzo przydatna metoda do diagnostyki i analizy, czy się choroba pojawia, rozwija.
Druga rzecz: wyjaśnij, czym jest farmakokinetyka i też jakieś przykłady podaj.
To jest bardzo ciekawa dziedzina, która ma już sporo lat, ale tak naprawdę nie jest bardzo szeroko rozwijana. Oryginalnie obrazy MRI były wykonywane statycznie z kontrastem bądź bez. Pewnie kontrast był wprowadzony niedługo później. Otóż gdy podamy pacjentowi kontrast, jest on zaprogramowany tak, aby podświetlać na obrazach rejony mózgu w których znajduje się na przykład nowotwór. W tym momencie patrząc na zdjęcie widzimy dokładnie, gdzie znajdują się podejrzane tkanki.
Początkowo było to tak zrobione, że faktycznie były to obrazy statyczne, czyli widzieliśmy w danym momencie, czy w konkretnym miejscu jest nowotwór i nic więcej nie byliśmy w stanie zrobić. Wraz z rozwojem technologii zarówno rezonansów, kontrastów, jak i całej medycyny byliśmy w stanie robić zdjęcia dużo częściej i tak naprawdę śledzić jak kontrast, jego wysycenie, czyli podanego pacjentowi płynu zmienia się w czasie. Rezonans magnetyczny pokazuje różnice w budowie mózgu.
Akurat jest to szczęście, że mózg jest symetryczny, ma prawą i lewą półkulę. Wszystkie nieregularności można porównać z drugą półkulą, więc są bardzo łatwo rozróżnialne. Podając kontrast jesteśmy w stanie prześledzić, jak bardzo on się przyczepia do tkanek, jak długo zostaje w nich, jak szybko jest wypłukiwany z mózgu. Tkanki, które są w pewien sposób zmienione przez nowotwór, w zależności od tego jak bardzo postępuje choroba, inaczej reagują z kontrastem i gdy będziemy w stanie śledzić te zmiany, będziemy mogli bardziej precyzyjnie wykryć stadium choroby, tworzyć prognozy na przyszłość oraz dostosowywać ewentualną terapię.
Miałem pewne doświadczenie związane z kontrastem. Moja żona zajmuje się kwiatami i gdy chce zmienić ich kolor, to może wstawić je do pewnego płynu, który sprawi, że staną się na przykład niebieskie lub fioletowe.
Jak tłumaczyłeś pojęcie kontrastu, to powiedzmy, że mózg zachowuje się podobnie. Co prawda tam są pewne ograniczenia, nie wszystko można wstrzyknąć, ale sprowadza się to do tego, że próbujemy “podkręcić” pewne sposoby percepcji. Widzimy lepiej, jak zachowują się niektóre tkanki, bo wprowadzamy pewne substancje. Ty nazywasz to kontrastem, bardziej medycznie, ale tak po “ludzku” kolory pomagają nam lepiej znaleźć pewne nieregularności.
Tak jest.
A teraz idąc dalej, jak uczenie maszynowe może być pomocne w tych obszarach?
Kontynuując dodam jeszcze, że śledząc zmiany kontrastu, tej substancji w mózgu, która reaguje w pewien sposób z nowotworem, jesteśmy w stanie użyć konkretnych modeli matematycznych pozwalających znaleźć pewne markery dodatkowe. Są to liczby, które pomagają lekarzom ocenić sytuację. Gdy robimy morfologię krwi, mamy podane wartości różnych parametrów w liczbach i dzięki temu lekarze są w stanie ocenić, czy z nami jest wszystko okej, czy coś powinniśmy zmienić.
Byliśmy w stanie teraz nie tylko spojrzeć na obraz rezonansu i powiedzieć “okej to wygląda dla mnie dobrze, a to wygląda dla mnie źle”, ale otrzymać pewne liczby, które jesteśmy w stanie porównać nie tylko między różnymi czasami tego samego pacjenta, ale między innymi pacjentami i w ten sposób zbudować na przyszłość bazę danych standardowych wartości dla różnych stadium choroby. Mówię “na przyszłość, bo nie wiem, czy w tym momencie taka baza danych istnieje.
Deep learning bardzo pomaga w aplikacji obrazowania MRI, a także analizy farmakokinetycznej, ponieważ obraz rezonansu dalej jest obrazem, a mam nadzieję, że większość słuchaczy wie, że machine learning i deep learning mają bardzo szerokie zastosowanie w analizie obrazu. Chodzi tutaj między innymi o zastosowanie sieci konwolucyjnych, które pozwala na bardzo dokładną i przede wszystkim powtarzalną analizę obrazu. Dzięki temu jesteśmy w stanie nauczyć sieć neuronową rozpoznawania zmian nowotworowych i dalej możemy wykorzystać informacje otrzymane z sieci do dalszego post processingu, czyli jako input do modelowania farmakokinetycznego.
Obraz kojarzy się przede wszystkim z tym, że mamy trzy kanały (RGB), ale ich może być więcej. W ciągu kilku ostatnich dekad obrazowanie hiperspektralne nabierało coraz większego znaczenia i ma zastosowanie w różnych obszarach. Zacznijmy od początku. Czym jest obrazowanie hiperspektralne (ang. hyperspectral imaging), jaki ma cel i gdzie może być przydatne?
Obrazowanie hiperspektralne jest bardzo ciekawą dziedziną, która łączy wiele mniejszych, takich jak technologie kosmiczne, optyka czy spektroskopia. Polega ona na tym, że jesteśmy w stanie robić zdjęcia świata, ale także innych światów. Wszyscy wiemy, że istnieje takie coś jak Google Maps, które pozwala na oglądanie zdjęć z satelity. Mam nadzieję, że większość z nas patrzyła na swój dom z satelity, bądź z samolotu. Tak jak wspomniałeś, te zdjęcia na Google Maps są zwykle w trzech kanałach – czerwony, niebieski, zielony, ale to nie jest wszystko, co jesteśmy w stanie osiągnąć za pomocą dzisiejszej technologii. Możemy obserwować ziemię w różnych pasmach elektromagnetycznych, nie tylko w świetle widzialnym, ale także w świetle podczerwonym bądź ultrafioletowym.
Są takie sensory, które potrafią obserwować ziemię, odbierać światło w wielu kanałach, zarówno w świetle widzialnym, jak i podczerwonym, co pozwala na dużo dokładniejszą analiz, ponieważ część rzeczy jest niewidocznych w świetle widzialnym, ale są bardzo dobrze widoczne w świetle podczerwonym. W kamerach podczerwonych, które widzą ciepło, jest obrazowanie termalne, gdzie często całe tło jest niebieskie, a człowiek na przykład czerwono-żółty, w zależności od tego czy jest cieplej, czy zimniej. To także jest część pasma elektromagnetycznego, które jesteśmy w stanie obrazować i nakładając na przykład właśnie takie obrazowanie termalne na widzialne uzyskujemy dużo więcej informacji o materiale bądź przestrzeni.
My, jako ludzie jesteśmy bardzo ograniczeni co do tego, co widzimy. To jest jakiś wąski zakres możliwości, który dostaliśmy, ale mogliśmy widzieć znacznie więcej. Niektóre zwierzęta, ptaki widzą więcej niż my. Wprowadzając kolejne pasma, to na początku nawet nie jesteśmy w stanie sobie uświadomić, że rzeczy, które wydawały się niemożliwe, w tej chwili stają się całkiem osiągalne.
Istnieje takie pojęcie “przekleństwo wymiarowości” (ang. curse of dimensionality). W szczególności to pojęcie ma duże wyzwanie w sytuacji, kiedy mamy dużo dość rzadkich danych. Pozwolę właśnie, żebyś wyjaśnił, co to jest i dlaczego to również występuje w obrazowaniach hiperspektralnych.
Bardzo dobre pytanie. Klątwa wymiarowości jest spowodowana naszymi ograniczeniami pod względem hardware’u. Gdybyśmy mieli nieograniczone możliwości i nieograniczone zasoby do obliczeń, klątwa wymiarowości nie byłaby taka straszna. Natomiast wszyscy, którzy zajmują się machine learningiem, przede wszystkim deep learningiem, muszą zmierzyć się z tym, że możliwości ich sprzętu nie są nieograniczone i istnieje pewien zasób informacji, który w jednej chwili komputer może przetworzyć.
Problem polega na tym, że z reguły większe sieci neuronowe są w stanie lepiej analizować dane i tworzyć lepsze predykcje, natomiast jeżeli użyjemy większych sieci neuronowych, to powstaje problem z treningiem. Wszystko musi się zmieścić w pamięci karty, a w momencie analizy danych zwłaszcza wielowymiarowych, które pochodzą z obrazów hiperspektralnych, musimy brać pod uwagę, że te dane po pierwsze są olbrzymie na starcie, a gdy chcemy trenować model czyli znaleźć lepsze reprezentacje danych, to te wymiary ulegają zwiększeniu o bardzo duży czynnik i musimy używać bardzo sprytnych metod, które pozwalają uzyskać bardzo dobre wyniki jednocześnie zachowując i utrzymując ograniczenia, które nakłada na nas sprzęt.
Obrazowanie hiperspektralne oryginalnie ma wbudowaną dużą ilość danych. Nawet jedno zdjęcie nie tylko ma 3 kanały, tak jak mówiliśmy wcześniej, tylko może ich mieć 10, 20, 100, 200. Wtedy to już nie jest zwykły obraz, jaki zwykle sobie wyobrażamy, tylko to jest raczej kostka danych. Możemy mieć zdjęcie na przykład 200×200 pikseli, które ma 200 kanałów. Więc to jest kostka 200 na 200 na 200 i ona sama w sobie już stanowi bardzo dużą ilość informacji. Jeżeli chcemy przetworzyć taką informację, musimy być w stanie dobrze zarządzać naszą pamięcią, naszym zasobami. W przeciwnym wypadku nie będziemy w stanie nic z tym zrobić.
Właśnie tu przy okazji warto doprecyzować, od którego poziomu zaczyna się hiperspektralność. Ile kanałów to już “hiper”?
To jest bardzo płynna granica i tak naprawdę każdy uważa, jak chce. Moje osobiste zdanie jest takie, że gdy wyjdziemy ponad 20, to już mówimy o hiper. Jest dużo urządzeń, które obrazują na przykład w szesnastu lub mniej. Na przykład (z tego co pamiętam) “Sentinel” ma mniej niż 20 kanałów i jest nazywany multispectral, więc ja swoją granicę przyjąłem na 20, ale są różne zdania. Może być 50, może być odrobinę więcej.
Nawet 20 już robi wrażenie. Czasem jesteśmy w stanie bardzo łatwo sobie wyobrazić, co to znaczy trzy wymiary, dwa wymiary, ale już cztery, siedem, dwadzieścia wymiarów to jest bardzo ciężkie do zwizualizowania. Podobnie czuję się tutaj, kiedy próbujesz sobie uświadomić, co to oznacza 20 kanałów, które do Ciebie docierają to “wow!” i normalny człowiek tego nie powinien procesować w swojej głowie.
Tak wyszło to ograniczenie do trzech wymiarów, ale bardziej abstrakcyjna wyobraźnia jest bardzo przydatna w machine learningu i nie tylko oczywiście.
Wyjaśniliśmy sobie trochę kontekst, który był nam potrzebny, aby przejść do segmentacji obrazu hybryd spektralnych (ang. hyperspectral image segmentation). Co to jest, jakie to ma możliwości, gdzie to się stosuje, po co? Cały szereg pytań.
Segmentacja w przeciwieństwie do klasyfikacji jest bardziej niskopoziomowa. Zamiast odpowiedzieć “na pytanie czy na danym rysunku jest obiekt?” (w przypadku klasyfikacji), opowiadamy, czy dany pixel reprezentuje ten obiekt. Czyli finalnie obraz, który próbujemy przetworzyć za pomocą segmentacji, ma przypisaną klasę dla każdego piksela Na przykład mając na obrazie samochód, las i drogę, droga powinna być zaznaczona osobno, samochód osobno i każdy piksel z lasu także osobno.
Obrazowanie hiperspektralne, segmentacja obrazów hiperspektralnych działają dokładnie tak samo. Mamy zdjęcie bądź z samolotu z dużej wysokości, bądź z satelity i próbujemy do każdego piksela dopasować jedną z możliwych klas. W tym momencie istnieją trzy bardzo popularne data sety. Wszystkie zostały zabrane za pomocą urządzenia hiperspektralnego, ale w samolocie z dosyć dużej wysokości.
Na przykład jest “Pavia Data Set” przedstawiający kampus Uniwersytetu w Padwie. Są także dwie sceny ze Stanów Zjednoczonych i ktoś był na tyle dobry dla nas, że posegmentował ten obraz ręcznie, piksel po pikselu dopisując do każdego jedną z około 20 klas.

My, ludzie zajmujący się obrazowaniem hiperspektralnym i segmentowaniem obrazów hiperspektralnych, próbujemy sprawić, aby ten proces był automatyczny, czyli nauczyć sieć, zwykle konwolucyjną (bardzo dobrze sprawują się w takich zadaniach), żeby była w stanie nauczyć się, jakie spektrum powinien posiadać dany piksel, żeby przynależeć do danej klasy. Wspominając o sieciach konwolucyjnych i dlaczego dobrze działają, rozwinę nieco myśl.
Gdy człowiek zaczyna się uczyć o sieciach konwolucyjnych, to sobie wyobraża, że jest filtr, który jest przesuwany krok po kroku po obrazie, tam to się dodaje, coś się tam mnoży, coś tam powstaje. Natomiast warto sobie uświadomić, że filtry to nie są takie zwykłe dwuwymiarowe rzeczy. Zwykle mają trzy wymiary i ten trzeci jest właśnie wymiarem spektralnym, który na początku w zwykłych obrazach ma 3 kanały, ale nic zupełnie nic nie stoi na przeszkodzie, żeby tam ich było 100, bądź 150. Taki filtr jest w stanie nauczyć się korelacji pewnych zależności między różnymi częściami spektrum, żeby bardziej precyzyjnie stwierdzić, co przedstawia otoczenie danego piksela.
Dlaczego sieci konwolucyjne są najbardziej sprawne? Rozumiem, że przede wszystkim chodzi o to, że bardzo łatwo wykorzystać sieci konwolucyjne jako narzędzie, żeby te nasze prognozowania albo w tym przypadku segmentacje wykonać.
Tak, to jest takie naturalne rozwinięcie. Nawet nie trzeba praktycznie nic robić, żeby użyć sieci konwolucyjnej do segmentacji obrazu. Wystarczy zmienić ilość, rozmiar filtra, który jest w pierwszej warstwie, a sieć sobie resztę sama załatwia i to jest super.
W przypadku hiperspektralnego obrazowania, z Twojego doświadczenia, gdzie tu jest największe wyzwanie? W którym kierunku to będzie się rozwijało dalej?
Największe wyzwanie w tym momencie jest takie, że nie ma zbyt dużo danych, które mają przypisane adnotacje. Czyli, że ktoś posegmentował je ręcznie i my jesteśmy w stanie używać ich do treningu naszych sieci. To, mam nadzieję, jest rozwiązywane w tym momencie, bo nie będziemy w stanie trenować sieci bardzo precyzyjnie, jeżeli nie będziemy mieć sporej ilości bardzo dobrze posegmentowanych danych. To jest pierwszy problem. Drugi problem jest taki, że dane zajmują bardzo dużo miejsca. Tak jak mówiłem, jest to kostka danych.
Każdy obraz to jest jedna kostka i trzeba ją po pierwsze przechować, po drugie przetworzyć, po trzecie jeszcze użyć do treningu bądź inferencji, czyli robienia predykcji. To zajmuje bardzo dużo miejsca na dyskach, ale także pochłania dużo zasobów. Natomiast uważam, że bardzo dobrze, że ludzkość próbuje te problemy rozwiązać, ponieważ obrazowanie hiperspektralne ma nieograniczoną ilość zastosowań. Na przykład przy monitorowaniu stanu środowiska, zanieczyszczenia wód, niekoniecznie zanieczyszczenia wywołanego przez człowieka, ale zanieczyszczenie na przykład glonami, bądź innymi algami.
Możemy także monitorować nawadnianie upraw, wykrywać choroby na uprawach, co pozwoli zwiększyć i usystematyzować zbalansowane rolnictwo. Możemy także monitorować inne bardzo ciekawe rzeczy jak aktywność wulkaniczną, ponieważ istnieją gazy, które nie są dostrzegalne w świetle widzialnym, są przezroczyste dla człowieka, natomiast w obrazowaniu hiperspektralnym, przeważnie podczerwonym, jesteśmy w stanie wykryć takie gazy ulatniające się, na przykład z wulkanu i wydać ostrzeżenie dla ludności, bądź nawet poinformować geologów, że tam coś może się dziać i być może będziemy w stanie czegoś nowego się dowiedzieć o aktywności wulkanicznej naszej planety, jakie procesy tam zachodzą. Jest tego bardzo dużo.
Jak wygląda kwestia zastosowania tego na rynku polskim? W czym obrazowanie hiperspektralne może być pomocne?
Do głowy przychodzą mi trzy pomysły. Pierwszy jest rozwinięciem tego, o czym mówiłem wcześniej, że Polska ma bardzo dużo terenów rolnych. Będziemy w stanie monitorować lepiej, jak zachodzą tam procesy wzrostu, ale nie tylko. Na przykład w tym roku była dosyć duża susza i myślę, że monitorowanie hiperspektralne pomogłoby ustalić właśnie nawodnienie różnych upraw i przeciwdziałanie skutkom takim susz.
Obrazowanie hiperspektralne, ale także zwykłe obrazowanie satelitarne bardzo pomogłoby w zwalczaniu nielegalnych wysypisk śmieci, bo nie jesteśmy w stanie tego ręcznie sprawdzać wszędzie. Zdjęcie z satelity bardzo prosto by ujawniło takie rzeczy. Polska ma także duży problem ze smogiem. Smog, który w dużych ilościach jest widzialny, ale w małych ilościach już nie, jest dosyć łatwo wykrywalny przez obrazowanie hiperspektralne i myślę, że monitorowanie między innymi większych miast bardzo by pomogło nie tylko w walce ze smogiem. Myślę, że powinniśmy dosyć szybko pójść w tę stronę.
Dzięki wielkie za te przykłady. Specjalnie o to zapytałem, chociaż na początku nie planowałem. W trakcie rozmowy wyszło, że to nie jest temat abstrakcyjny. To jest narzędzie, które umożliwia rozwiązywanie praktycznych problemów, które dotykają normalnych ludzi i to na skalę powiedzmy całego kraju. Teraz pozwolę sobie zmienić temat, bo ciekawy jestem Twojej opinii jako praktyka o jednym z tematów. Narzędzia, biblioteki, których używamy, są rozwijane przez większych graczy
Na przykład jeśli chodzi o deep learning, to mamy słynny Tensorflow rozwijany przez Google i PyTorch jako alternatywa rozwijana przez Facebooka. Ciekawostka jest taka, że oni nawzajem konkurują i coraz lepsze się stają te biblioteki. PyThorch wprowadził pewne mechanizmy, więc Tensorflow na to odpowiedział w swojej drugiej edycji, że oni też tak potrafią.
My jako odbiorca końcowy, czyli osoby, które używają tych bibliotek, możemy tylko się cieszyć, bo to się staje coraz lepsze, bezpłatnie dostępne. Czy wszystko jest tak proste? Czy kiedyś się na nas nie odbije? Gdy teraz rozmawiamy, ma miejsce bardzo gorąca dyskusja albo wręcz skandal w pewnym sensie pomiędzy Google i Huawei, bo Huawei w tej chwili nie może używać systemu operacyjnego Android.
Jak to usłyszałem, to pomyślałem, że przecież to jest Open Source, to jest łatwo dostępne. Okazało się, że Huawei w sumie może korzystać z tego systemu, tylko nie może używać usług, które Google tam wprowadza, a bez tych usług Android jest właściwie bezużyteczny. Tak naprawdę z jednej strony to jest dostępne, ale są warstwy ukryte, które wcześniej czy później mogą zablokować działanie. Czy to nie będzie przypadkiem tak, że kiedyś nastąpi moment X i to, co teraz jest łatwo dostępne, bezpłatne, może być anulowane po prostu jednym ruchem. Co o tym myślisz?
Bardzo ciekawy temat. Patrząc na przykład Tensorflow, to niedawno oglądałem bardzo ciekawy film z promocji nowego Tensorflow 2.0, na którym zostało powiedziane, że w tym momencie, jako że Tensorflow jest Open Source, to ma on 1000 albo nawet 2000 aktywnych użytkowników, którzy kontrybuowali w tworzeniu tej aplikacji.
Trzeba pamiętać o tym, że Google jest prywatną firmą i jako taka w pewnym momencie może zdecydować, że przyszedł czas, żeby “zebrać opłatę” i odetnie wszystko. Z tego powodu, że to jest Open Source, może to być trudne, ale jak powiedziałeś, coś, co jest Open Source, da się w pewnym sensie wycofać i jego uniemożliwić używanie. Natomiast myślę, że patrząc aktualnie na strategię Google, która rozwija ten Tensorflow bardzo aktywnie, równocześnie wystawia swoje usługi w postaci API (płatne oczywiście) dla klientów, czyli po pierwsze chce zarobić na machine learningu i deep learningu poprzez swoje usługi, ale także udostępnia dla użytkowników za darmo możliwości rozwoju własnych.
Te dwie rzeczy niejako są sprzeczne, bo po co dawać użytkownikom możliwość zrobienia czegoś samemu, skoro można w pewnym sensie zmusić ich do płacenia? A jednak Google to robi i myślę, że strategia Google nie jest taka, żeby w pewnym momencie to odciąć, choć jest takie prawdopodobieństwo. Musimy natomiast pamiętać, że zarówno PyTorch jak i Tensorflow nie są jedynymi z środkami, na których możemy robić deep learning. 10 lat temu tych frameworków nie było albo były w bardzo wczesnych fazach.
Deep learning był i można go robić także w Numpy. Oczywiście jest to dużo mniej efektywne, dużo trudniejsze i zajmowałoby pewnie tygodnie zamiast paru linijek kodu, żeby cokolwiek zrobić, natomiast dalej jest to bardzo fajnie ćwiczenie dla nowych adeptów machine learningu, żeby właśnie zaprogramować sieć w Numpy, bo daje to dużo do zrozumienia i dalej jest to możliwe. Oczywiście nie uważam, że da się robić machine learning na szeroką skalę używając Numpy, więc pewnie wycofanie popularnych frameworków cofnęło by nas w czasie o 10 lat, natomiast uważam, że prawdopodobieństwo tego jest małe. Trzeba jednak pamiętać, że faktycznie jest szansa, że tak się kiedyś stanie w przyszłości.
Zadam jeszcze jedno pytanie, takie praktyczne. Każda osoba, która próbowała zacząć stosować uczenie maszynowe w praktyce, wie, jak bardzo łatwo jest się poślizgnąć, bo jest bardzo wiele możliwych ścieżek i tylko mała część działa. Czy masz checklistę albo wskazówki, w jaki sposób można osiągnąć ten idealny stan bytu, kiedy poświęcasz 20% czasu, a zyskujesz 80% wartości, a nie na odwrót, jak często to bywa? Być może masz w głowie jakieś sygnały, kiedy na przykład czujesz, że jesteś w sytuacji gdzie już nie warto iść tym tropem, bo to jest błędna ścieżka albo w drugą stronę, że czujesz, że to dobra droga? Czy masz takie wskazówki, którymi podzielisz się z innymi?
Moja rada jest taka dla początkujących, żeby nie starać się robić wszystkiego samemu. W programowaniu cudowne jest to, że nawet jest niezalecane, żeby przysłowiowo wynajdywać koło na nowo. Jest bardzo dużo rozwiązań, które są open source i można ich użyć dla swoich zastosowań, bądź zacząć od czegoś, co działa, żeby mieć tak zwany baseline, czyli pewne rozwiązanie, które może nie jest idealne, ale już działa i wiemy mniej więcej, jak się zachowuje i następnie możemy modyfikować je do swoich potrzeb.
To jest bardzo dobry sposób właśnie dla początkujących, którzy mają ambicję “okej, nauczyłem się tego, więc teraz napiszę od nowa” i są w stanie stracić dzień, tydzień, dwa, miesiąc na szukanie problemów, które są albo bardzo bardzo trudne, albo wręcz odwrotnie bardzo proste, ale na przykład na kursie ich nie było. Polecam wszystkim zaczynać od czegoś co już działa, co jest udostępnione i modyfikować. To się rozciąga trochę dalej nie tylko dla początkujących, ale istnieje bardzo duże parcie na wykorzystanie modeli tak zwanych pre-trained, czyli wytrenowane przez kogoś innego, które także są dopuszczone zwykle jako Open Source, które w pewien sposób są reklamowane jako rozwiązanie na wszystko.
Ja się zgodzę, że bardzo dużo problemów da się rozwiązać używając przetrenowanych modeli, natomiast coś, co jest dobre do wszystkiego, jest dobre do niczego. Czasem trzeba zakasać rękawy i trochę podmienić coś albo zacząć od nowa. Należy o tym pamiętać, że jak chcemy użyć przetrenowanego modelu w naszym rozwiązaniu i widzimy, że nie działa, to nie należy tygodniami próbować zmieniać różne elementy, tylko prawdopodobnie trzeba wypracować inne podejście, bądź całkowicie zacząć od nowa. Także rada dla początkujących i nie tylko jest taka: zacznijcie od czegoś, co działa, ale nie dawajcie 100% wiary w to, bo być może Twój problem jest trudny, bądź zupełnie inny i trzeba by ugryźć to z innej strony.
Dzięki, że o tym powiedziałeś i mam nadzieję, że słuchacze z tego skorzystają. Dzięki wielkie Michale, że znalazłeś czas, żeby się podzielić swoim doświadczeniem. Życzę Ci wszystkiego dobrego. Czuć tę pasję, energię pozytywną, więc trzymam kciuki, żeby wszystko się poukładało, jak sobie tego życzysz.
Dzięki za zaproszenie i miłe słowa. Do usłyszenia.
Teraz przejdziemy do kolejnej opinii absolwenta 4 edycji online kursu “Praktyczne uczenie maszynowe od podstaw” na DataWorkshop. Dawid pracuje w General Electric, w którym ja spędziłem prawie 3 lata, co prawda w innym oddziale. Okazało się nawet, że używa zaawansowanej wyszukiwarki dokumentów (miliony dokumentów, terabajty danych), którą zaprojektowałem jako architekt, wdrażałem na produkcję oraz byłem liderem dla międzynarodowego zespołu, który następnie to utrzymywał. Ciekawy zbieg okoliczności. Dawid dowiedział się o tym tuż przed rozmową.

Cześć Dawid, przedstaw się: kim jesteś, czym się zajmujesz, gdzie mieszkasz?
Cześć Vladimir. Nazywam się Dawid Machalica i w zasadzie od sześciu lat mieszkam w Warszawie. Pracuję w branży energetycznej, dokładnie przy projektowaniu turbin gazowych w firmie General Electric. Na początku to była taka typowa praca inżynierska, natomiast dość szybko zauważyłem, że mnie interesuje programowanie i zacząłem skupiać się na tych obszarach, gdzie mogłem w jakiś sposób zacząć tworzyć programy na zasadzie nakładki na programy inżynierskie, które przyspieszają pracę w tych programach, w których ja wcześniej pracowałem.
Tak więc w taki dość gładki sposób, możemy powiedzieć, przeszedłem z typowej pracy inżynierskiej na ścieżkę software’ową. Obecnie pracuję jako programista C#, dodatkowo od dwóch lat jestem doktorantem na Politechnice Warszawskiej. Swoją pracę realizuję właśnie przy współpracy z firmą General Electric, wcześniej Instytutem Lotnictwa. W czasie własnym prowadzę również bloga dotyczącego produktywności i rozwoju własnej kariery.
Co ostatnio ciekawego przeczytałeś?
To była taka książka, którą jeszcze kilka lat temu w zasadzie z ciekawostek polecił mi mój poprzedni menedżer na ocenie rocznej. Książka nosi nazwę “Esencjalista”. Autor próbuje przekonać nas do idei, że czasami w życiu nie chodzi o to, żeby robić bardzo dużo, być ciągle zestresowanym, zabieganym, ale żeby robić w życiu rzeczy właściwe. Czasem on właśnie porównuje to do takiego bączka, takiej dziecięcej zabawki, która mimo tego, że bardzo szybko czasami się obraca, niby robi bardzo dużo, to ciągle stoi w miejscu.
My możemy tę swoją energię w jakiś sposób ukierunkować, zastanowić się, na czym nam w życiu naprawdę zależy, zrezygnować z rozpraszaczy, które są wokół nas i dzięki temu zdobyć czas na zrobienie czegoś naprawdę fajnego, nauczenia się podstaw uczenia maszynowego, co dla wielu osób wydaje się w pewien sposób niemożliwe. Nawet mając pracę na etacie, czy studia, można wygospodarować na to czas i zdobyć te umiejętności.
Bardzo fajna książka i warto dodać, że robienie rzeczy właściwych raczej nikogo nie dziwi, natomiast cała sztuka polega na tym, żeby sobie uświadomić, co jest właściwe. Człowiek raczej świadomie nie marnuje energii, bo mu się to wszystko wydaje potrzebne. Wiem, że w książce są podane przykłady, jak sobie lepiej uświadomić, które rzeczy są ważniejsze dla Ciebie, a które mniej, więc fajna praktyka.
Lektura tej książki sprawiła, że zacząłem częściej zastanawiać się nad tym, czy to, co robię w danym momencie, jest na pewno tym, co powinienem robić. Czy to, co zacząłem robić, oznacza, że na pewno powinienem to skończyć, czy nie byłoby lepszym rozwiązaniem po prostu zakończyć to, urwać daną rzecz, kurs, cokolwiek niż po prostu brnąć w to i tracić dodatkowy czas. Tak więc widzę tutaj dodatkowy taki zysk.
Bardzo dobre pytanie. Przerobiłeś kurs “Praktyczne uczenie maszynowe” na DataWorkshop. Czy to była właściwa rzecz, którą miałeś zrobić?
Myślę, że z perspektywy czasu jak najbardziej, chociaż przyznam, że przystępując do tego kursu widziałem to jako pewien eksperyment. Z jednej strony forma online mi bardzo odpowiadała, bo jak wspominałem już jestem doktorantem, prowadzę bloga, mam pracę na cały etat, więc to, że mogłem dostosować ten kurs do swoich innych obowiązków, nie musiałem brać w tym momencie urlopu, to jak najbardziej mi odpowiadało.
Natomiast z drugiej strony miałem pewne wątpliwości, jeśli chodzi o jego efektywność. Zastanawiałem się też, czym w zasadzie taki kurs będzie różnił się od kursów, które za kilkanaście, za kilkadziesiąt złotych można znaleźć w internecie. Ostatecznie okazało się, że ten kurs różnił się bardzo, bo z jednej strony mieliśmy dostęp do Slacka, gdzie można było poznać bardzo fajnych ludzi, a z drugiej dochodził element wzajemnej motywacji, że ktoś coś już zrobił, widziałem, że ktoś skończył już jakieś notebook, zrobił jakieś zadanie i to motywowało, żeby systematycznie siadać i realizować ten kurs. Jednocześnie ludzie sami zgłaszali się z problemami i czasami próbując komuś pomóc, samemu próbowałem gdzieś znaleźć odpowiedzi albo zastanowić się przynajmniej nad danym zagadnieniem.
To sprawiało, że automatycznie poświęcałem temu znacznie więcej czasu, niż gdyby to był film na YouTubie, gdzie bym przerobił dokładnie to samo, co autor na wideo i zamknąłbym komputer. Istotny był też konkurs. Podczas kursu, odbyły się dwa konkursy. Lubię rywalizację i to, że widziałem, że pozostałym osobom statystyki idą w górę, to mnie zmotywowało, żeby codziennie siadać, próbować, szlifować zarówno model, jak i uczyć się po prostu dodatkowych rzeczy, starać się jak najwięcej rzeczy z tego wyciągnąć. Przy okazji myślę, że to była doskonała okazja, żeby tę wiedzę usystematyzować, sprawdzić, czy na pewno wszystko dobrze zrozumiałem i mimo, że ostatecznie nie byłem w samej czołówce, to ten konkurs naprawdę mi dużo dał.
Super. Bardzo dziękuję za te wszystkie rzeczy. Jeżeli chodzi o Slacka, tutaj przy okazji nie wiem, czy to jakoś zdradza szczegóły, ale przez to, że na tym kursie mi bardzo zależy, to rozważam, jak sprawić, żeby zwiększyć zaangażowanie, ostatecznie zwiększyć efektywność tego kursu na koniec dnia, żeby człowiek który go przerobił, zdobył tę wiedzę.
Ze Slackiem to zwykle jest tak, że na początku na większość pytań odpowiadałem ja, a później coraz więcej udzielali się inni uczestnicy. Nie przestałam się angażować, tylko specjalnie próbowałem umożliwić innym odpowiedzi na te pytania i tylko wtedy, kiedy było jakieś pytanie, które wisiało przez chwilę troszkę dłuższą i nikt się nie odważył odpowiedzieć, to pomagałem.
To właśnie powoduje, że jak człowiek po raz pierwszy, drugi pomoże komuś i dostanie to magiczne “dzięki”, to zaczyna się dziać coś niezwykłego. To świetnie działa, kiedy człowiek się angażuje, ktoś inny odwdzięczy się, to jeszcze bardziej motywuje, żeby robić kolejne rzeczy i pomagać innym.
Kompletnie się tutaj zgadzam.
Co Cię najbardziej zaskoczyło w kursie?
Myślę, że to, że był duży nacisk na feature engineering, czyli tworzenie i przekształcanie tak, żeby zwiększyć możliwości wykorzystania ich przez algorytmy i poprawić jakość. Ja szczerze powiedziawszy przystępując do tego kursu myślałem, że największy zysk z niego, to będzie, że poznam jakieś nowe modele, nauczę się optymalizować hiperparametry, nauczę się lepiej tworzyć strukturę sieci neuronowej itd.
Oczywiście wiele z tych rzeczy się nauczyłem podczas kursu, natomiast myślę, że największy zysk to było to, że zrozumiałem, że bez odpowiednio oczyszczonych, przygotowanych danych, bez odpowiednich cech zwłaszcza w sektorze takiego klasycznego uczenia maszynowego, czyli jakieś lasy losowe, to tam niewiele można zdziałać i bardzo często oczyszczając dane i odpowiednio je przygotowując, nawet z użyciem dużo słabszego, ale wydajniejszego modelu można osiągnąć dużo lepsze wyniki, niż stosując bardzo skomplikowany model, który długo się uczy i bardzo długo optymalizuje się jego parametry. Wydaje mi się, że to najbardziej mi też w przyszłości w jakichś własnych projektach pomoże.
Dawid, komu polecasz ten kurs?
Myślę, że tutaj byłyby trzy grupy ludzi, którym mógłbym go polecić. Z jednej strony to byłyby wszystkie osoby, które w jakiś sposób mają na co dzień w pracy kontakt z danymi, czyli inżynierowie, managerowie mający zespoły i mający dane na temat tych zespołów, osoby prowadzące własny biznes i chcący zwiększyć jakość zarówno swoich usług, jak i efektywność tego biznesu. Druga grupa to są programiści, którzy chcieliby w jakiś sposób rozwinąć się i zdobyć dodatkowe kompetencje.
Trzecia grupa to są osoby, które nie miały wcześniej do czynienia ani z programowaniem, ani i z danymi natomiast zainteresowało ich samo uczenie maszynowe i mają taką silną motywację, chęć nauczenia się tego. Myślę, że Twój kurs to jest doskonała okazja, żeby w krótkim czasie, bo to są tylko zaledwie 2 miesiące, zarówno zdobyć wiedzę, takie podstawy teoretyczne, jak i również praktyczne umiejętności – w jaki sposób wejść w ten temat, co się z czym je i w którym kierunku w ogóle można iść dalej.
Dziękuję Ci bardzo za Twoją opinię i fajnie, że udało się znaleźć czas, więc dzięki wielkie i do usłyszenia, do zobaczenia.
Dziękuję bardzo za zaproszenie.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
