
RAG w LLM: Dlaczego popularne rozwiązania to droga donikąd?
Cześć, nazywam się Vladimir Alekseichenko i zapraszam Cię do podcastu Biznes Myśli. Jestem praktykiem sztucznej inteligencji z wieloletnim doświadczeniem we wdrażaniu modeli ML, które przynoszą realne zyski.

Ludzie, pieniądze, procesy, innowacje – o tym wszystkim i nie tylko usłyszysz w tym podcaście.
Podcast powstaje przy wsparciu DataWorkshop, firmy, którą założyłem, i gdzie zajmujemy się praktycznym zastosowaniem ML. Zaufali nam już tysiące ludzi oraz znane marki, takie jak Orange, mBank, Leroy Merlin, Polpharma, a także firmy z branży przemysłowej. Uczymy, tłumaczymy i pomagamy wdrażać ML w praktyce. Skontaktuj się z nami na hello@dataworkshop.eu.
Biznes Myśli to sprawdzone źródło wiedzy o sztucznej inteligencji. Pamiętaj, świat zmienia się szybciej, niż myślisz. Zaczynajmy!
Dzisiaj skupię się na ważnym temacie, który nazwałem „RAG w LLM-ach i dlaczego tradycyjne podejście to droga donikąd”.
Brzmi dość kontrowersyjnie, ale to nie było moim celem. Chcę po prostu podzielić się z Tobą rzetelną informacją, tak jak to widzę z mojego własnego doświadczenia i doświadczenia, które mamy w ramach Data Workshop.
Chcę pokazać, jak to wygląda w praktyce i dzięki temu pomóc Ci zaoszczędzić pieniądze, czas, nerwy i wiele innych rzeczy. Jestem pewien, że dojdziesz do tego punktu, jak zaczniesz drążyć temat w praktyce.
Będę mówić o rzeczach dość logicznych, które każdy praktyk wcześniej czy później zrozumie, próbując pojąć ten temat. Pytanie tylko, kiedy i jakim kosztem. Mam nadzieję, że dzięki temu odcinkowi uda Ci się zaoszczędzić i zminimalizować ten czas i inne zasoby. Dzięki temu będziesz w lepszej pozycji względem swojej konkurencji.
O czym konkretnie będę mówić? Albo co się stanie, jak zignorujesz ten odcinek i jakie potencjalne problemy mogą się pojawić w Twoim biznesie? Otóż tych problemów może być wiele. Zaczynając od takich rzeczy, jak transparentność decyzji, czyli zrozumienie albo zinterpretowanie, dlaczego odpowiedź jest taka, a nie inna.
Następnie dokładność odpowiedzi, czyli dlaczego odpowiedź jest taka, a nie inna i czy możemy jej zaufać. Tutaj między innymi pojawia się ten pierwszy problem – przez to, że nie rozumiemy, jak ta odpowiedź powstaje, nie jesteśmy w stanie odróżnić albo zmierzyć tak dokładnie, czy ta odpowiedź w ogóle jest prawidłowa.
Kolejny problem, który się pojawia, to audytowalność naszego rozwiązania, czyli spełnienie pewnych wymogów prawnych, których staje się coraz więcej, szczególnie w Europie. Zaczynając od GDPR, ale też EU AI Act i inne, czyli umiejętność wyjaśnienia, dlaczego to powstało i czy to nadal jest zgodne z wymogami zewnętrznymi.
Mniej oczywisty, ale bolesny dla biznesu problem to koszt – nie tylko implementacji, ale też utrzymania takiego rozwiązania.
Co ciekawe, gdy poszukacie w internecie informacji o RAG, zobaczycie zupełnie inne obietnice – że zwiększa dokładność, transparentność, audytowalność i zmniejsza koszty.

Jak to możliwe, że mówię coś zupełnie przeciwnego?
Proponuję rozdzielić to na dwie kategorie:
- Koncepcyjne rozważania – to, co chcielibyśmy osiągnąć
- Praktyczna implementacja – to, co faktycznie udaje się wdrożyć
Koncepcyjnie RAG może nam dostarczyć tych wszystkich korzyści. Problem polega na tym, że klasyczna implementacja, o której mówi większość źródeł, nie jest w stanie tego zrealizować.
Chcę Ci dziś wyjaśnić, na czym polega problem z klasycznym podejściem do RAG. Nie będę się chować za skomplikowanymi nazwami czy frameworkami – przedstawię to w prosty, logiczny sposób, bazując na moich doświadczeniach i wiedzy zdobytej w DataWorkshop.
Zacznijmy od podstaw – czym jest RAG i dlaczego w ogóle się pojawił?
Mówiąc o modelach LLM (dużych modelach językowych) takich jak ChatGPT, Gemini czy Bard, mamy do czynienia z „systemami”, z którymi możemy prowadzić konwersację. Jednak pojawia się problem, gdy pytamy o coś, czego model nie wie – np. o wewnętrzne procesy firmy czy niszowe informacje z danej branży.
I tu właśnie wkracza RAG. Działa on w taki sposób, że do naszego promptu (instrukcji dla modelu) dodajemy kontekst – dodatkowe informacje, których model sam z siebie nie posiada. Na przykład, jeśli zapytamy model o strukturę naszej organizacji, możemy dołączyć do promptu schemat tej struktury. Model będzie wtedy w stanie zinterpretować te dane i udzielić prawidłowej odpowiedzi.
To prowadzi nas do kilku ważnych wniosków:
- Dobre modele LLM, jak ChatGPT-4, Gemini Pro czy Claude, potrafią wyciągać wnioski z dostarczonego kontekstu, o ile nie jest on zbyt obszerny.
- Kluczowa jest odpowiedzialność za dostarczenie właściwego kontekstu. To od nas zależy, jakie informacje przekażemy modelowi do analizy.
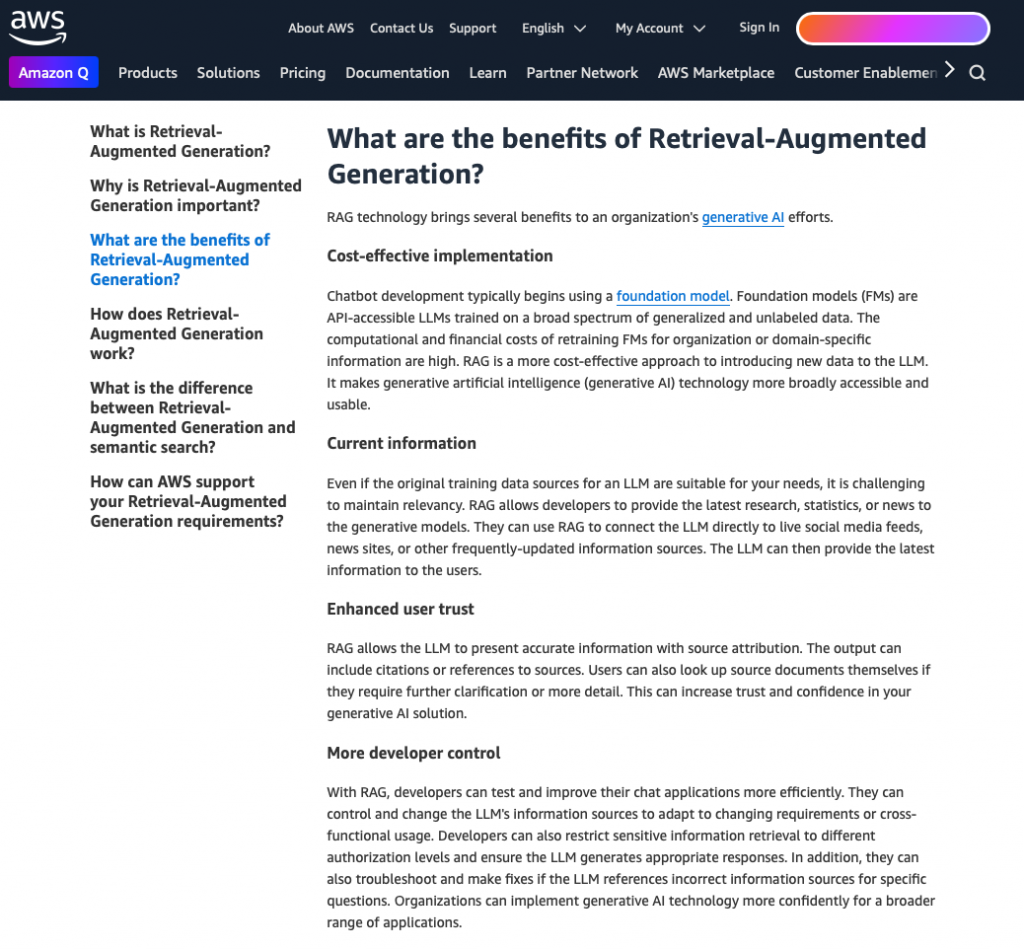
Aby to zobrazować, przeprowadziłem eksperyment. Zapytałem model: „Ile dni urlopu przysługuje pracownikom DataWorkshop? Odpowiedź jako przedział lub NA, jeśli nie wiesz.„
I teraz, jeżeli zapytałem tak w sposób jednoznaczny, bez przekazywania żadnego kontekstu, to ChatGPT-4, bo to na ten moment, jak nagrywałem ten odcinek, był najmocniejszy model, przynajmniej w Hugging Face Leaderboard, odpowiedział NA, czyli jakby nie ma odpowiedzi.
Dobra, to wtedy zrobiłem taki sposób, że będę przekazywać poszczególny kontekst i załóżmy, że ten kontekst będzie polegać na tym, że przekazuję po prostu różne kawałki informacji, które gdzieś tam, załóżmy, znalazłem, na przykład na naszym czacie firmowym albo w bazie wiedzy, na przykład czy takim Jira, czy coś podobnego, albo na przykład jakimś forum takim naszym wewnętrznym, albo jakieś tam pliki PDF, które gdzieś tam mogę znaleźć.
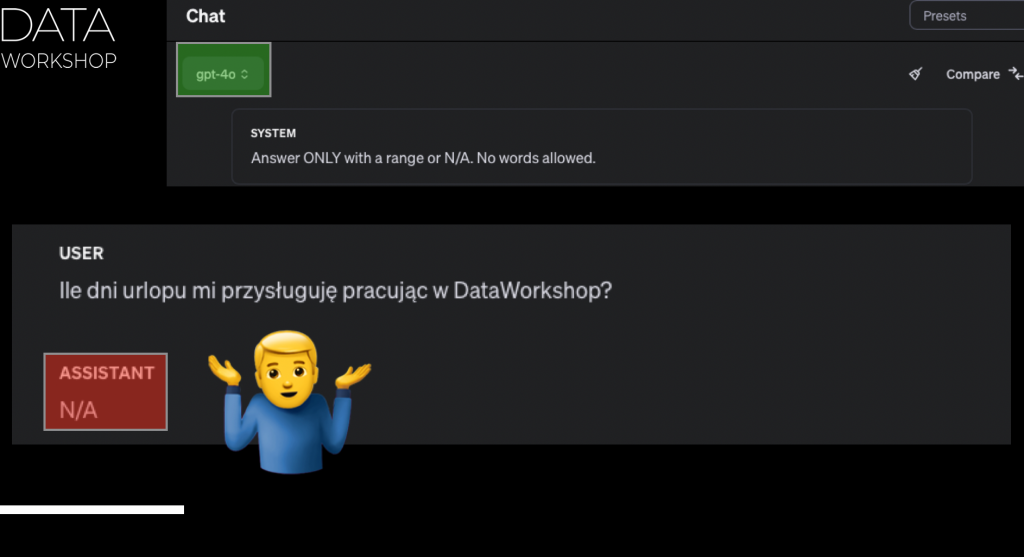
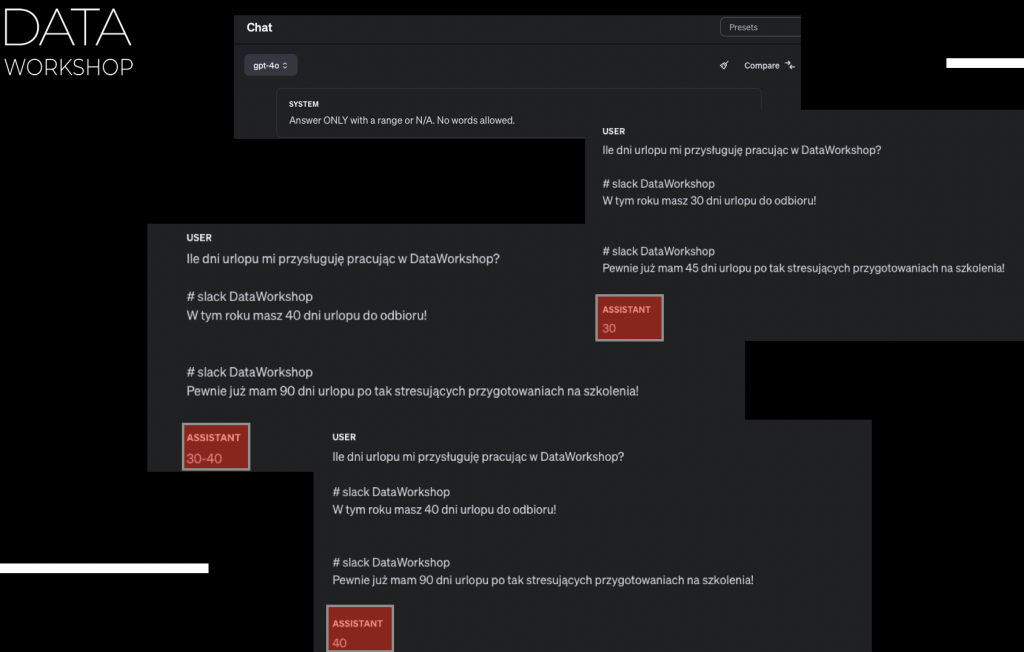
Czyli załóżmy, że mam wiele różnych źródeł informacji i w jakiś sposób sobie to wczytuję i przekazuję takie kawałki informacji, które tam wczytałem, takie różne zdania. I na przykład takie konteksty, które tam mogę przekazać, to będzie tak, na przykład: „Slack Data Workshop: W tym roku masz 40 dni urlopu do odbioru.” To jest takie zdanie, które po prostu mogło tam gdzieś się trafić, czyli mamy Slack, na tym Slacku my sobie rozmawiamy i między innymi ktoś kiedyś w jakimś tam kontekście mógł powiedzieć sobie takie zdanie, że w tym roku masz około 40 dni urlopu do odbioru.
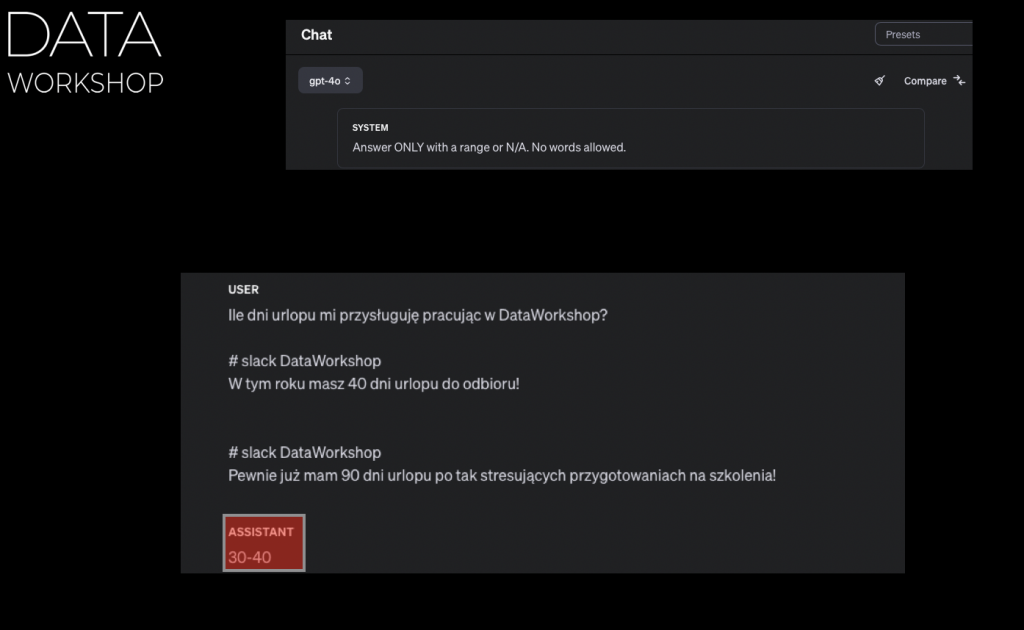
Albo na przykład w innej rozmowie, na przykład w kolejnym wątku, ktoś powiedział w taki sposób, że: „Pewnie już mam 90 dni urlopu, bo tak stresujące jest przygotowanie tego szkolenia.” To jest taka trochę żartobliwa forma wyjaśnienia. Mamy dwie różne odpowiedzi na Slacku, które semantycznie brzmią podobnie, bo dotyczą urlopu. Jedna odpowiedź mówi o 40 dniach, a druga, trochę ironicznie, o 90 dniach. Sens, że chodzi o urlop, jest zachowany. Wtedy nasz model GPT-4, który na ten moment jest najlepszy, odpowie przedziałem albo wartością.
I dostajemy odpowiedź 30 dni, potem uruchamiając to samo, model odpowie 30-40 dni, a przy kolejnym uruchomieniu dostanie też 40. Jak widzisz, w zależności od kontekstu, on odpowiada inaczej. Spróbujmy to zrozumieć tak, żeby było jednoznaczne.
Jeżeli dostarczamy jako kontekst różne kawałki informacji, które semantycznie brzmią podobnie, na przykład dotyczą urlopu w konkretnej firmie, to model wie: „Aha, tutaj jest 30 dni, tu ktoś mówi o 90, tu 40.” Model nie wie, której informacji może bardziej zaufać i wtedy próbuje to jakoś uogólnić. To jest taka wewnętrzna struktura modelu.
Żeby lepiej to zrozumieć, możemy zrobić taki eksperyment. Wyobraź sobie, że zamiast modelu LLM, to Ty jesteś osobą, która dostaje takie zapytania. W tym zapytaniu są poszczególne kawałki informacji i Ty ze swojej strony masz to zinterpretować. Masz odpowiedzieć albo „nie wiem”, albo zwrócić tylko przedział. Taki był nakaz, czyli nie możesz nic dopytać, prawda?
No to co wtedy zrobisz? Przeczytasz jeden komentarz, drugi komentarz, trzeci komentarz i powiesz: „No może od 30 do 40, a może więcej, a może mniej.” Plus trzeba wziąć pod uwagę, że model z góry posiada wiedzę ogólną, ile dni urlopu przysługuje na przykład w Polsce. Bo jak o to zapytasz, to on odpowiada w miarę sensownie, więc też pojawia się pewien konflikt między wiedzą ogólną, którą model posiada, a kontekstem, który dostarczamy, wprowadzającym dodatkowe informacje. I tutaj jest ciekawostka – przez to, że wprowadzamy tę informację, model zakłada, że tym informacjom można zaufać.
To jest ważna rzecz. Model zakłada, że skoro my jako użytkownicy dostarczyliśmy pewien kontekst, pewien tekst, to ta informacja jest sprawdzona i on jako model, patrząc na ten tekst, może temu zaufać. To jest bardzo, bardzo ważne, co teraz powiedziałem.
Model nie weryfikuje, czy to, co wrzuciliśmy, ma sens, czy nie ma sensu. On zakłada, jak takie naiwne dziecko, które potrafi dobrze czytać i łączyć pewne fakty, że każdy z tych faktów, które dostarczyliśmy, był sprawdzony, jest dobrze zweryfikowany i tej informacji można zaufać.
I jedynie, co on zrobi, to popatrzy: „Okej, to jest przedział taki, a to przedział inny” i w jakiś sposób logicznie sobie to przetworzy. Czyli zwróć uwagę, powtórzę to jeszcze raz, bo to jest bardzo kluczowe, żeby to zrozumieć. Później będziemy mówić o tych mechanizmach klasycznych i będzie to też oczywiste, na ile przesunęliśmy tę odpowiedzialność w niewłaściwy sposób.
W tej chwili model zakłada, że my jako użytkownicy wzięliśmy odpowiedzialność na siebie. Sprawdziliśmy, że kontekst, który dostarczamy, naprawdę jest taki, któremu można zaufać. Wtedy on mówi: „Okej, ja ufam, skoro dostarczyliście tę informację, to ja ufam tej informacji i na podstawie tej informacji po prostu odpowiadam najlepiej, jak tylko potrafię.” Jak tam jest informacja sprzeczna, to nie jego problem, po prostu tę informację mu dostarczyliśmy, więc tak to wygląda. I to się sprowadza do tego, że np. ja tam robiłem więcej eksperymentów i dostarczałem różne informacje. Np. później kontynuowałem, że oprócz tej informacji ze Slacka, wrzucałem informację z HR i JIRA, gdzie było napisane: „Każdy pracownik Data Workshop ma od 20 do 26 dni urlopu, ile dokładnie – należy zgłosić się do działu HR i zbadać swoją sytuację.”
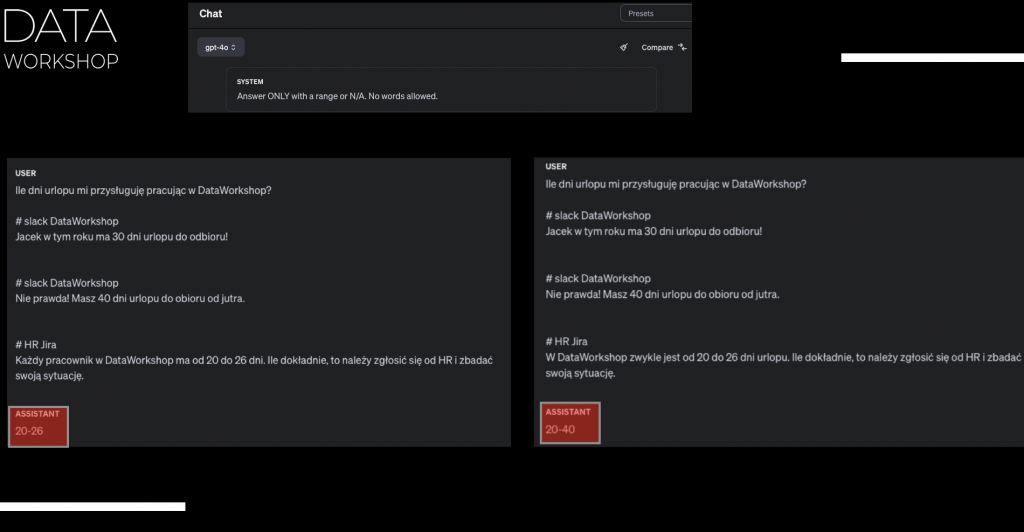
I tutaj co ciekawe, kiedy pojawił się dział HR, to prawdopodobnie model powiedział: „Okej, dobra, według tej informacji brzmi to sensownie, 20 do 26 dni.” Też jest HR, zwykle HR właśnie tym się zajmuje, jeżeli chodzi o te informacje. Więc tym komentarzom, które tu dostarczyliśmy, faktycznie nadał większą wagę to, co tutaj wybrzmiało z HR.
Ale z drugiej strony, jeżeli zaczniemy sobie dalej bardziej podkręcać i eksperymentować, np. dodamy sobie cztery przykłady: Pierwsza wiadomość ze Slacka, gdzie jest napisane: „Jacek w tym roku ma 30 dni urlopu do odbioru.” Druga wiadomość na Slacku była taka: „Czasami mają tylko 2 tygodnie urlopu i to jest bardzo mało.” Trzecia wiadomość: „Nieprawda, masz 40 dni urlopu do odbioru już jutro.” I czwarta wiadomość jest napisana jako HR JIRA: „W Data Workshop zwykle jest od 20 do 26 dni, ile dokładnie to należy się zgłosić do HR i zbadać swoją sytuację.”
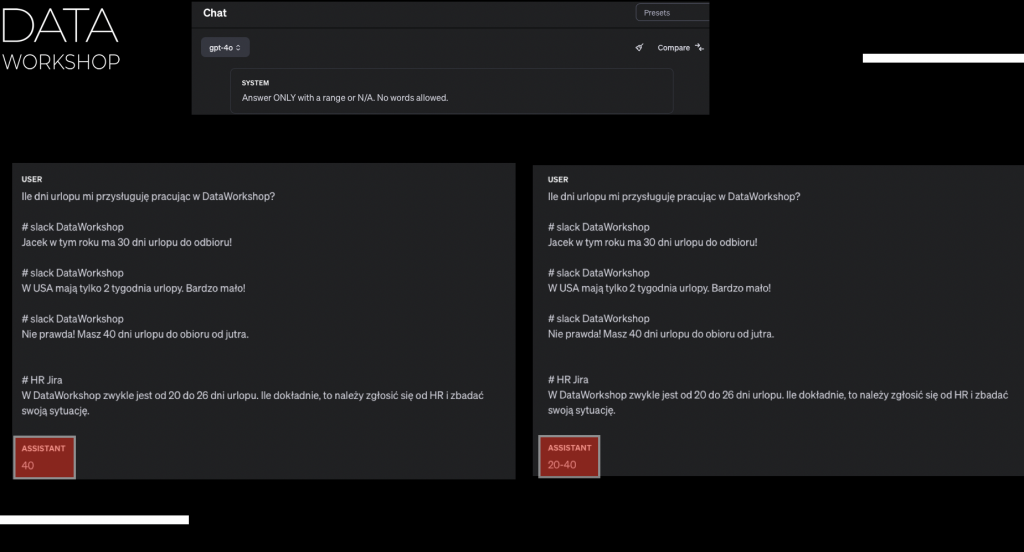
Czyli jak widzisz, dostarczyliśmy różne kawałki tekstu z różnych źródeł. Jest dość duża rozbieżność pomiędzy 30 dni, 2 tygodnie, 40 dni i też HR. I to, co odpowiada model, on nam odpowiedział 40 w tym przypadku. Najciekawsze jest to, że jak odpalisz to kilka razy, to za każdym razem będzie coś innego jeszcze, czyli np. 28, 30.
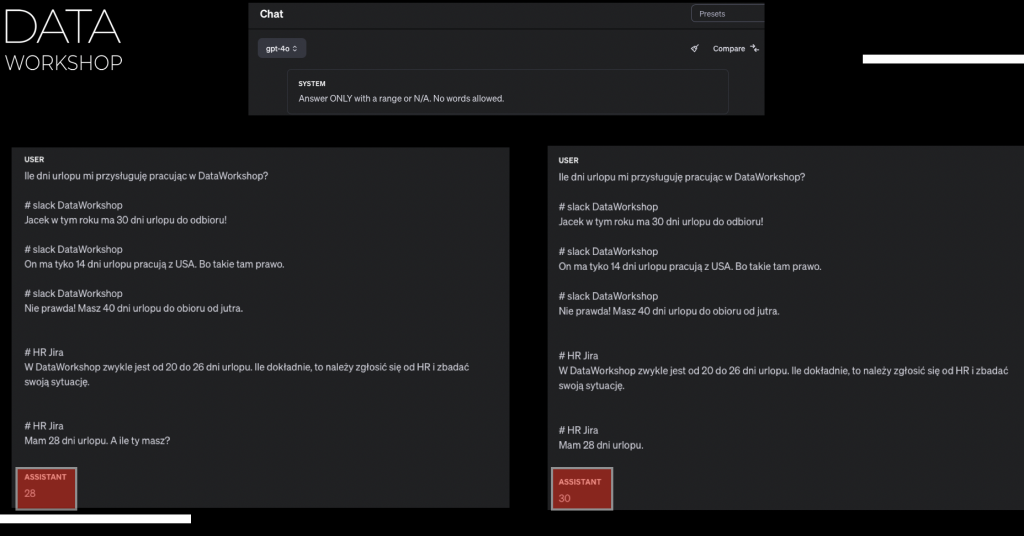
I tu dochodzimy do tego punktu, jeżeli chodzi o dokładność i też transparentność. Zwróć uwagę, my przygotowaliśmy pewien prompt. Ten prompt przekazujemy do modelu najlepszego, który w tej chwili istnieje na świecie, przynajmniej według Areny Leaderboard. Uruchamiamy ten sam prompt wiele razy i dostajemy różne odpowiedzi. Tutaj też uprzedzając, załóżmy, że ustawiamy sobie temperaturę na zero, zamrażamy to i uruchamiamy. I nadal odpowiedź jest inna.
No właśnie, co wtedy? Problem jest taki w tym wszystkim, że LLM sam w sobie ma pewne ograniczenia. I teraz zapewnienie tego, żeby on zwracał Ci tą samą odpowiedź w sposób taki jednoznaczny, transparentny jest nie takie łatwe, niż może się wydawać. Ten cały LLM nie jest taki inteligentny, niż może się wydawać na pierwszy rzut oka.
Największy problem w tym przypadku, jeżeli chodzi o to ograniczenie, polega na tym, że ten kontekst, który my dostarczamy, jeżeli tam dostarczymy sprzeczne informacje, które ciągną w jedną stronę, na przykład 20 dni albo nawet 2 tygodnie, z drugiej strony 90 dni, to model się gubi. Bo którą odpowiedź on ma wybrać? Tak jak powiedziałem przedtem, LLM nie jest w stanie wziąć odpowiedzialności za Ciebie. To jest ważne.
LLM nie jest w stanie wziąć odpowiedzialności za Ciebie i powiedzieć, które z tych faktów są poprawne, a które nie. I to się kończy tym, że on próbuje po prostu zrobić coś. Różnie mu to wychodzi. No i wynik jest taki jaki jest.
Mam nadzieję, że udało się wyjaśnić, na ile jest ważne, jaki kontekst my dostarczamy. A co to ma wspólnego z RAG? No właśnie, bo my cały czas właściwie mówimy o RAG, tylko ja jeszcze nie wytłumaczyłem tej podstawowej fazy.
Zobacz, w RAG-u chodzi o to, że mamy w sumie takie dwie najważniejsze fazy albo dwa najważniejsze kroki. Krok pierwszy, to my w jakiś sposób musimy znaleźć w naszej bazie wiedzy właściwy kontekst, czyli ten kawałek tekstu, który chcemy przekazać. Właśnie o tym teraz rozmawialiśmy, na ile ten krok musi być odpowiedzialny.
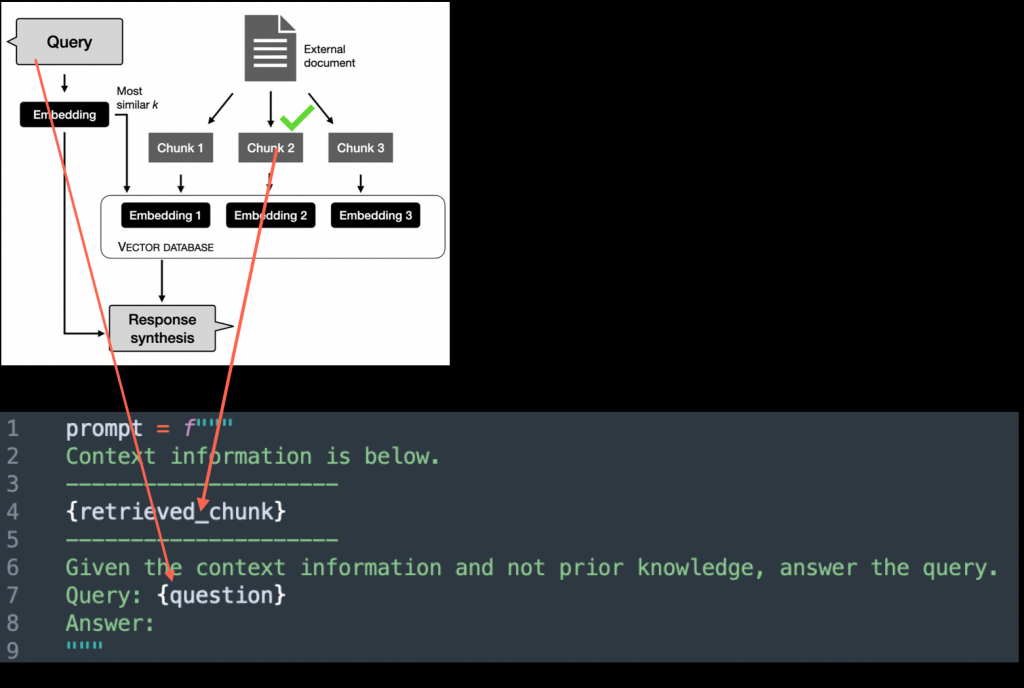
Jak już to przekazaliśmy, to krok drugi jest taki, że na podstawie tego, co przekazaliśmy do naszego prompta, czyli mamy instrukcję z góry, która została ustawiona, plus ten kontekst, na podstawie tego chcemy wygenerować odpowiedź. Czyli mamy dwa kroki.
Pierwszy to jest właśnie retrieval w tym całym RAG, a drugi to jest generacja. No i ten pierwszy krok – wyszukiwarka – właściwie jest najtrudniejszy i najważniejszy. I w takim naiwnym RAG, jak to się robi? Otóż robisz to w taki sposób, że mamy naszą bazę wiedzy, załóżmy, że to jest albo Slack nasz, np. jakiś tam czat, albo np. taka Jira, albo jakieś PDFy.
Bierzemy sobie jakiś modny framework, np. LangChain lub podobny. I tam np. jest taki kawałek kodu, dosłownie kilka linii kodu czasem to jest, że wczytaj wszystkie PDFy i zrób z tego indeks. Co to znaczy w praktyce?
Czyli on bierze sobie, np. mamy taki folder, w którym mamy 100 plików PDF. Więc to, co robi ta biblioteka, to ona wczytuje sobie pierwsze PDFy, parsuje ten PDF, czyli transportuje to, co jest tekstem PDFa jako tekst.
Zwróć uwagę, że to wcale nie jest takie łatwe, bo PDFy, jak pamiętasz, mogą wyglądać różnie. Czasem to zawiera np. takie dwie kolumny, czasem to ma jakąś tabelkę, czasem ma jakiś obrazek.
Więc wyciągnięcie tekstu z PDF to jest osobne wyzwanie, o którym za chwilę też porozmawiam, ale wyciągnąć takie sobie potrafię. Zwykle nie najlepiej. I to jest pierwsza rzecz, czyli wynikiem pierwszej fazy jest to, że parsuje PDF i pojawia się taki jakiś strumień literek.
Chunki – kawałki tekstu
Tam czasem są słowa pokładane, czasem bardziej sensowne, czasem mniej. Jak zwykle mamy tabelkę, to jest pokładane bardzo słabo. I pojawia się ta faza tzw. „chunkow’ania”.
Dlaczego to czątkowanie się pojawia? Bo chodzi o to, że te PDFy mogą być długie np. 50 stron, 150, 1000 itd. Więc to, co zwykle się robi, to, co zwykle się proponuje w tej sytuacji, to dzielimy to na mniejsze porcje np. na tysiąc znaków albo tam dwa tysiące znaków itd.
Czyli innymi słowy mamy np. 100 stron i dzielimy sobie w sposób taki sztuczny, przynajmniej w tym takim naiwnym RAGu, według ilości znaków np. 10 tysięcy albo 1000 znaków.
To jest pierwszy kawałek tekstu, drugi 1000, drugi. I w tym przypadku już pewnie się domyślasz, że pojawi się taka sytuacja, że mamy jakiś paragraf i ten paragraf załóżmy, że ma dwa i pół tysiąca.
Wynikiem takiego podejścia jest to, że obcinamy sobie paragraf na pierwszą część 1000 znaków, potem drugą część 1000 i na końcu 500. De facto mamy takie trzy niezależne kawałki. Możemy właściwie obciąć to gdzieś w pół słowa albo w pół zdania, w dowolne miejsce, bo robimy to w sposób mechaniczny.
Żeby zmniejszyć ryzyko robienia głupich rzeczy, proponuje się zrobić tzw. overlapping, czyli nakładanie się fragmentów. Bierzemy np. 1000 znaków i mówimy: okej, drugi kawałek będzie się zaczynać nie tuż po, tylko z pokryciem np. 50 czy 150 znaków. Chodzi o to, żeby było pewne pokrycie i nie obcinać czegoś ważnego, co jest tuż przed.
Zwykle w tę stronę to idzie – kroimy nasz tekst na plasterki i wrzucamy do bazy. Za chwilę opowiem o tej bazie wektorowej, ale spróbujmy dobrze zrozumieć, o czym teraz mówię, bo to jest ważne.
Wyobraź sobie tabelkę zawierającą różne informacje. Jak przepuścisz ją przez prosty parser, dostaniesz tekst. Ten tekst często jest dość rozrzucony, nie masz pięknie poukładanych wierszy i kolumn, tylko jakieś kawałki informacji. Tracisz strukturę, co już jest pewnym problemem.
Drugi problem, który się pojawia, to że masz rozrzuconą informację z tej tabelki i następnie wychwytujemy jeszcze pewne kawałki, np. piąty wiersz i trochę kolumn, siódmy wiersz itd. W wyniku pojawiają się pewne fragmenty, które wrzucasz do bazy danych, żeby później ich wyszukiwać.
Ale jak wyciągniesz taki kawałek, to tam jest po prostu chaos. To, co opisywałem, to sztuczne krojenie naszej informacji w dość dziwny sposób.
Często robi się na to wszystko overlapping. Ewentualnie później, jak to nie działa, rozszerza się chunk size, czyli rozmiar porcji danych. Byłem świadkiem na konferencji, jak ktoś opowiadał o RAG i mówił, że jak coś nie działa, to zwiększają chunk size z 1000 do 2000 znaków.
W praktyce oznacza to, że wymazujemy całe poprzednie podejście. Jedyne, czym był dumny ten człowiek, to że potrafił szybko wszystko reindeksować. Ale jak na to patrzyłem, to myślałem, że to jest podobne do sytuacji, gdy zamiast wymienić przepaloną żarówkę, ktoś proponuje wyburzyć cały budynek albo osiedle i zbudować nowe. To jest tego typu rozwiązanie.
Czyli jak nie działa jakiś konkretny przypadek, np. mamy 100 przypadków opisanych i widzimy, że 55 nie działa, to wszystko usuwamy, zwiększamy chunk size i lecimy dalej. A później okazuje się, że 5 przypadków, które wcześniej działały, już też nie działają. No to znów wszystko usuwamy i lecimy dalej.
Brzmi to bardzo nieodpowiedzialnie i na pewno nie tędy droga. Jeżeli mamy wpływ w taki bardzo ogólny sposób, że wszystko musimy zniszczyć, wyburzyć i potem jeszcze raz reindeksować, to tu już jest pewien kłopot.
Najważniejszy wniosek, który chcę teraz przekazać, to to, że sposób w jaki wyciągamy kawałki informacji z naszego źródła jest bardzo sztuczny. Wynikiem tego jest to, że rozrywamy pewien sens. Mamy jakiś konkretny akapit, który jest ważny, a my go rozrywamy na 2-3 kawałki i każdy z tych kawałków może być trochę bez sensu, bo jakaś ważna informacja zaczyna się gubić.
Wtedy pojawia się pomysł, żeby jakoś poukładać dodatkowe ścieżki – że tu był kawałek przedtem, tu potem i wyciągamy nie jeden, a więcej fragmentów. Ale nadal gubisz jakąś jednostkę sensu. Zamiast skupić się na tym, że w konkretnym zapytaniu należy przekazać taki a taki kontekst, robisz sztuczne rzeczy, np. zawsze przekazujesz 2-3 dodatkowe kawałki. Czasem to może być trafione, a czasem nie.
De facto próbujemy cały czas jakoś minimalizować ten błąd. A żeby sumienie nas za bardzo nie męczyło, mówimy, że chunk size po prostu jest jaki jest i skupiamy się bardziej na bazie wektorowej.
Bazy wektorowe
O co chodzi z tą bazą wektorową? To jest taka bardziej nowoczesna wyszukiwarka. O wyszukiwarkach mógłbym mówić długo, bo jeszcze zanim embedding stał się tak popularny, pracowałem w General Electric jako architekt i projektowałem system wyszukiwania dla dużych ilości różnorodnych danych – PDFów, obrazków, wykresów itd. Trzeba było to poukładać tak, żeby inżynierowie mogli łatwo znajdować, co robią ich koledzy na innych kontynentach. Wtedy jeszcze nie było embeddingu, ale klasyczne metody całkiem nieźle sobie radziły.
Co jest ważne w tym wszystkim? Kilka rzeczy. Historyczny punkt – w 2021 roku Facebook po raz pierwszy zaproponował to, co teraz nazywamy RAG. I w tym RAG-u faktycznie było użyte to, co nazywamy embeddingiem. Za chwilę powiem, czym jest ten embedding.

Paper: https://arxiv.org/pdf/2005.11401
Teraz ta faza wyszukiwania zwykle tak się przykleiła, że jak mówimy o fazie znalezienia informacji kontekstowej, to mówimy przede wszystkim o embeddingu. Stało się to synonimem. Dlatego chciałem powiedzieć, że tak może być, bo definicja RAG pojawiła się wtedy, ale może warto wymyślić jakąś inną nazwę. Z drugiej strony RAG stał się już bardziej koncepcją niż konkretną implementacją. Dlatego warto też powiedzieć, że wyszukiwać możemy na różne sposoby.
Wyjaśnijmy teraz, o co chodzi z tym wyszukiwaniem z osadzaniem albo reprezentacją wektorową i dlaczego to jest lepsze, ale też jakie ma wady. Wspomniałem już o tym w odcinku o mitach, ale warto powtórzyć i wyjaśnić pewne rzeczy.
Jeśli chodzi o embedding, jest tu kilka ciekawostek. Jak mówimy o reprezentacji tekstu, pomyśl na przykład o słowie „dom”. Jakie masz skojarzenia z domem? Mogą być różne – miejsce stojące na ziemi, można tam spać, każdy chce mieć, mieszka tam rodzina itd. Każdy może mieć swoje skojarzenia i de facto mówimy o szeregu charakterystyk, opisów czy skojarzeń. Każde z tych skojarzeń to będzie konkretna kolumna.
Możemy wymyślić sto pytań, zadając które będziemy w stanie stwierdzić, czy chodzi o dom. Bo dom może być różny – może być dom, mieszkanie, apartament, zamek, chatka, budka. Mimo że to różne rzeczy i słowa, mają też wspólny mianownik. Na przykład chatka i dom mają więcej wspólnego niż wieloryb.
To, co robi osadzenie wektorowe, to próbuje semantycznie znaleźć podobne rzeczy i opisać je w postaci wartości numerycznych w podobny sposób. W praktyce mamy sto wartości numerycznych i jak mamy dom i mieszkanie, to te wartości w poszczególnych kolumnach będą podobne. W niektórych miejscach będą się bardziej różnić, w niektórych mniej, ale wspólnie, jak weźmiesz konkretną metrykę, zobaczysz że te dwa słowa są dla siebie zbliżone.
W ten sposób kodujemy informację semantycznie, czyli sens tego słowa. Możesz zrobić reprezentację wektorową dla pojedynczego słowa, ale też dla kilku słów, zdania, całej książki. I teraz pomyśl – jak masz możliwość zadać 100 pytań dotyczących jednego słowa, to będzie dość precyzyjne. Ale jak masz 100 pytań do scharakteryzowania całej książki, to tracisz więcej informacji przy szerszych tekstach.
W praktyce oznacza to, że istnieje pewna funkcja kompresji. Gdy mamy informację oryginalną, przepuszczamy ją przez ten mechanizm i dostajemy opis numeryczny – np. 100 wartości opisujących dany tekst, książkę czy obrazek. To bardzo fajne i uniwersalne podejście.
Pamiętam, jak kilka lat temu po raz pierwszy poznałem to podejście reprezentacji wektorowej. Byłem mega zachwycony. To był super język, wcześniej niedostępny, dzięki któremu możemy różne informacje i sygnały – obrazki, dźwięk, wideo itd. – przekazywać w uniwersalny sposób i poszukiwać podobnych rzeczy.
Na przykład mamy tekst, audio i obrazek, gdzie wszędzie jest dom – ktoś powiedział słowo „dom”, narysował dom, a w tekście jest napisane „dom”. Możemy te rzeczy porównywać i faktycznie je znaleźć. To robi efekt wow i pokazuje, że wcześniej tego nie potrafiliśmy zrobić. Klasyczna wyszukiwarka opierała się bardziej na słowach kluczowych i różnych indeksach odwróconych.
To faktycznie robi wrażenie, ale ma też swoje wady. Ważne jest, żeby zrozumieć, jakie to ma wady i zalety. Jeżeli pójdziemy tylko i wyłącznie w tę stronę, że najpierw pokroimy nasz tekst źródłowy na kawałki, stracimy pewien kontekst, bo kroimy to w sposób sztuczny. Następnie, jeśli ten kawałek jest trochę większy, wrzucamy go do funkcji, która zrobi nam reprezentację wektorową albo osadzenie, i to wszystko wstępnie zapisujemy do bazy wektorowej.
Z jednej strony może to sprawiać wrażenie, że mamy super nowoczesną wyszukiwarkę i bardziej zaawansowane rzeczy. Ale trzeba pamiętać o ograniczeniach tego podejścia i nie traktować go jako jedynego słusznego rozwiązania.
Później, gdy użytkownik o coś pyta, bierzemy jego pytanie, przepuszczamy przez reprezentację wektorową, dostajemy wektory, potem poszukujemy podobnej odpowiedzi, wyciągamy 5, 10 czy 50 różnych kawałków, wrzucamy to do kontekstu i dostajemy odpowiedź. Zwróćcie uwagę, co tu się dzieje, jeśli chodzi o niepożądane wyniki.
Przez to, że pytanie użytkownika najpierw konwertujemy do reprezentacji wektorowej i później wyciągamy to, co jest podobne, pojawia się pewien element niespójności. Ten element niespójności polega na tym, że im szerszy jest kontekst, o który pytamy, tym trudniej jest go precyzyjnie reprezentować w postaci ciągu znaków.
Wybieramy na przykład 100, 1000 lub inną liczbę wymiarów, w zależności od modelu. Każdy wymiar lub kolumna coś reprezentuje, ale zwykle nie wiemy semantycznie, co oznacza wartość w konkretnej kolumnie. Wiemy tylko, że jeśli mamy dwa kawałki tekstu, w których te kolumny zawierają podobne wartości, to przynajmniej w tym aspekcie te kawałki tekstu są podobne.
Jeśli we wszystkich kolumnach mamy podobne wartości, to możemy uznać, że to jest o tym samym. Wracając do przykładu z pytaniem o urlop, pokazałem mechanicznie, jak wrzucanie różnych informacji do GPT (najlepszego modelu w momencie nagrywania) wpływa na jakość i na ile możemy wprowadzić model w błąd, wrzucając konfliktujące informacje.
We wszystkich tych kawałkach, które wrzuciłem, było coś na temat urlopu. Ale czy było to powiedziane ironicznie, czy bardziej dokładnie, to już model osadzenia (embedding) tego nie rozróżnia. Model poszukuje podobnych semantycznie rzeczy, czyli jeśli mamy kawałek tekstu, który mówi o urlopie, to nam pasuje i to wrzucamy.
Oczywiście, wiele osób propagujących to klasyczne podejście powie, że to tylko naiwny RAG (Retrieval-Augmented Generation) i że istnieją bardziej skomplikowane rozwiązania. Na przykład, gdy mamy dodatkowy model, który najpierw wyciąga podobne kawałki tekstu, a później nowy model z tych 50 kawałków wybiera np. 5 kawałków.
Ten dodatkowy model ma zdecydować, który kawałek zasługuje na to, aby przekazać do naszego RAG-a. To brzmi sensownie, bo mamy mechanizm, który bierze odpowiedzialność za to, aby przekazać do modelu językowego (LLM) informacje, które zasługują na zaufanie. I to faktycznie potrafi czasem działać lepiej.
Ale fundamentalnie popełniliśmy błąd, i to, co teraz robimy, to troszkę bardziej podkręcamy ten koreczek. Mamy wiele różnych problemów, trochę je zmniejszyliśmy, potem wprowadzamy kolejny mechanizm i jest ich trochę mniej, i tak dalej. Natomiast sytuacja, do której to wszystko doprowadza, jest taka, że tych elementów, które próbują naprawić fundamentalne błędy założone na początku, jest coraz więcej.
Jak zobaczysz najbardziej nowoczesne rozwiązanie RAG, to zobaczysz takie, nazwijmy to, prawdziwe potwory informatyczne, gdzie jest wpięte wiele modeli. Ja jako architekt, patrząc na to, myślę: „Ojejku, jak to jest możliwe?”.
Mogę powiedzieć taką historię. Pamiętam, kiedy w 2008 roku po raz pierwszy zacząłem pracować jako programista w komercyjnych projektach.
To było moje pierwsze doświadczenie i wtedy widziałem świat w taki sposób, że im bardziej skomplikowane rozwiązania, im więcej nowoczesnych rzeczy, tym lepiej. Bo niby się wykazuję, że jestem taki inteligentny, że jestem w stanie się pokazać, że mogę zastosować najbardziej nowoczesne rzeczy, że nie brakuje mi umysłu czy inteligencji. Żeby wziąć to i wrzucić, i jeszcze odpowiedzialności, i śmiałości, żeby to wrzucić na produkcję.
Ale z czasem, kiedy zacząłem się rozwijać i być odpowiedzialnym za swoje rozwiązanie, które wdrażam na produkcję, na przykład w roli też architekta, to zaczynasz myśleć zupełnie inaczej. Po prostu rozumiesz, że wszystkie elementy, które masz w swojej architekturze, one wszystkie mogą się zepsuć, i zwykle się zepsują. Jednak to, co robisz, to maksymalnie wszystko upraszczasz. Jak czegoś nie potrzebujesz, to nie potrzebujesz tego.
Po prostu musisz to w taki sposób zrobić, żeby maksymalnie uprościć swoje rozwiązanie. Teraz, co to znaczy w praktyce? Jest takie stwierdzenie, że idealny kod to jest brak kodu. Tylko jest taki problem, że to nie działa. Ale to jest taki kierunek, gdzie chcemy dążyć, czyli chcemy tworzyć takie rozwiązanie, które jest na tyle proste, na ile się da, tak to tam chcemy być. I na pewno nie chcemy tworzyć rozwiązania, które cały czas coś dokładamy, dokładamy, dokładamy, a teraz trochę lepiej, trochę ten problem, który mamy, trochę z tej strony podkręcimy.
Bo jeżeli na koniec dostajemy taki statek kosmiczny, w którym właściwie wszystko na raz może się zepsuć, i chcesz mieć kontrolę nad tym, żeby zapewnić te wszystkie rzeczy, o których powiedziałem, właśnie ta transparentność, audytowalność, przewidywalność i tak dalej, no to to mija się z celem.
Dobra, to spróbuję jeszcze podsumować to, co powiedziałem, żeby to stało się jednoznaczne i zrozumiałe. W klasycznym podejściu RAG zwykle używamy reprezentacji wektorowej po to, żeby później wyszukiwać podobne kawałki.
Te kawałki wrzucamy do bazy wektorowej i wtedy, kiedy pojawią się zapytania, to te zapytania też konwertujemy do reprezentacji wektorowej. Później poszukujemy podobnych rzeczy, które mamy, wyciągamy te podobne rzeczy, ewentualnie robimy taki tzw. „re-rank”, czyli wybieramy z tych pięćdziesięciu albo pięćset rzeczy, wybieramy na przykład pięć albo tam dziesięć, takie, które niby zasługują na naszą uwagę.
I to przekazujemy już do naszego programu. Wtedy ignorujemy odpowiedź. I teraz wspomnijmy sobie taki sposób: jeżeli w sposób sztuczny dzielimy nasze dane na kawałki, w których rozrywamy pewną strukturę, czyli mamy jakiś pewien paragraf albo jakąś tabelkę, i następnie w sposób sztuczny to rozrywamy, czyli de facto posiadamy jakieś takie szczątki informacji.
Na przykład mamy jakąś tam kolumnę, czasem mamy wartość, czasem nie mamy, no bo ekspresujemy sobie takie PDF, to tak to mniej więcej wygląda, to co będzie wtedy? I nawet jak wrzucimy jakiś super zaawansowany model, który wybierze z tych pięćdziesięciu, pięćdziesięciu, pięć najlepszych, to wcale nam nie gwarantuje, że to w ogóle ma sens.
Bo nawet w tych pięciu albo w tym top jeden nadal może być bzdurna informacja. Bo wracając do samego początku, co chciałem dostarczyć, taki bardzo ważny wniosek, bardzo ważna informacja, to, co dostarczamy do prompta, model później nie krytykuje, czyli maksymalnie próbuje zaufać temu, co dostarczyliśmy.
Czyli de facto odpowiedzialność, jaką musimy wziąć za siebie, to ten kontakt, który dostarczamy, naprawdę musi być dobry. I tu dochodzimy do sedna rozwiązania, oczywiście znów coś bardziej tutaj z klasycznego rozwiązania, jak możesz powiedzieć, a czekaj, czekaj, tak naprawdę jeszcze oprócz tego sztucznego podziału możemy zrobić tak zwany bardziej semantyczny podział.
Na przykład zatrudnić jakiś inny model, który podzieli nam na przykład na kapity, albo na jakieś takie różne kawałki i faktycznie to już trochę lepiej, faktycznie to w tym przypadku to brzmi trochę lepiej, ale znów problem jest taki, co to oznacza lepiej? No bo w tym przypadku być może, być może ten mechanizm pozwoli nam na to, żeby jak mamy na przykład taki problem, taki PDF i mamy różne kolumny.
No to wtedy faktycznie na przykład on będzie w stanie, w stanie scalić na przykład jeden paragraf do jednego, albo jakąś tam mamy tabelkę, no to złączyć tą tabelkę, żeby to była jedna wspólna tabelka, albo jak na przykład mamy taką tabelkę na dwie strony, no to zrozumieć, że to jest tabelka na dwie strony i faktycznie też to scalić. I faktycznie, jeżeli pójdziemy w tą stronę, to jesteśmy już w znacznie lepszej sytuacji, niż to, co było przedtem.
Bo robimy przynajmniej już bardziej sensowną rzecz, co jest najważniejsze, faktycznie robimy to w taki sposób, żeby dane, które przechowujemy w naszej bazie decylowej, były w takiej postaci, jak to powinno być. Ale nadal przez to, że robimy to w sposób taki dość ślepy, bo co to znaczy zatrudnić taki model? No to możemy coś mu tam wyjaśnić, ale tak naprawdę ten sam PDF możemy podzielić na różne sposoby.
I nie ma czegoś takiego jak super uniwersalne rozwiązanie, to znaczy nie jesteś w stanie zrobić jedno podejście, które będzie pasowało dla wszystkich firm. Co to znaczy w praktyce? Nie jesteś w stanie wziąć po prostu taki model, który w jakiś tam sposób mu wyjaśni, że podziel tam na jakieś takie sprawy, jakieś semantyczne kawałki i to będzie zawsze pasować.
W praktyce to oznacza to, co u nas zwykle dla warsztatów się sprawdza. Zaczynamy w ogóle od drugiej strony. I tutaj właśnie zaczyna się różnica pomiędzy tym, jak się robi to klasycznie i jak to się powinno robić. I z tego co ja dostrzegam coraz więcej osób, praktyków przynajmniej, to dostrzegają. I ja myślę, że to stanie się standardem, tylko pewnie mija trochę czasu.
Otóż ważna myśl taka, którą próbuję dostać. To, co zwykle robimy, to jest tak. Nie zaczynamy od tego, że po prostu wciągamy sobie dane, jakoś tam kroimy na kawałki, jakieś tam wrzucamy do jakiejś bazy wektorowej i długo się kłócimy, która baza wektorowa jest lepsza. Totalnie bez sensu, nie tędy droga. Robimy w ten sposób. Próbujemy zrozumieć, a co chcemy właściwie osiągnąć. Jaki jest problem biznesowy.
I to brzmi bardzo oczywiste. I tak chyba wszyscy robią, przynajmniej w teorii, ale w praktyce niekoniecznie. I teraz w zależności od tego, że wiemy, co chcemy osiągnąć, kolejnym krokiem, który robimy jest takie: no dobra, to załóżmy, że robię teraz to człowiek. To jak on to zrobi? Załóżmy, że mamy taki konkretny bank, przykład z życia wzięty.
W tym banku jest taki departament do audytowalności, czyli chodzi o to, że jest wiele różnych takich wymogów prawnych, jakieś PDF i nie tylko. I coś się zmienia, jakiś przepis się zmienia i ten dział musi zapewnić, że wszystkie inne przepisy są zgodne z tym, co wymaga się przez prawa. I to, co tam było w oczekiwaniach, to było tak, że no to zróbcie tam coś, żeby to po prostu w jakiś sposób to sprawdziło.
No dobra, no może i zrobimy, tylko pytanie jest takie: co to znaczy w praktyce? I to, co robimy w tej sytuacji, to mówimy: a co robi człowiek? No człowiek bierze na przykład konkretny przepis, który wyszedł od państwa, albo kto tam to wydaje, i tam jest napisane pewne wytyczne. Okej, a co dalej robi? No czyta sobie po kolei. Okej, a dalej co? No bierze sobie te wszystkie dokumenty, które ma sprawdzić.
No dobra, a dalej co robi? No porównuje sobie poszczególne kawałki z tym, czy to jest nadal zgodne i tak dalej. Czyli innymi słowy to wszystko się sprawdza jeżeli rozumiemy, co z czym chcemy porównać, w jakich sytuacjach chcemy coś zmienić, a w jakich sytuacjach nic nie chcemy zmienić. Ale to oznacza, że de facto próbujemy maksymalnie zrozumieć, jak wygląda ten proces.
Największy wysiłek, który tu wkładam, to żeby zrozumieć proces krok po kroku i rozpisać sobie, co dokładnie ma się wydarzyć, aby ten problem był rozwiązany przez człowieka. I później to, co się zmienia de facto, to ja z góry wiem, jaki kontakt chcę dostarczyć, co z czym chcę porównać, jaki wynik jest możliwy, kiedy to jest wadliwe, kiedy niewadliwe, żeby tam ewentualnie zrobić jakieś double-checki.
I wtedy pojawi się struktura, jak powinienem przechowywać dane, jeżeli chodzi o te rzeczy, dokumenty, które sprawdzam, dane, które przychodzą z zewnątrz, w jaki sposób chcę to podzielić. To nie jest tylko kwestia per paragraf albo jak dalej. To właśnie różnie może być. To może być takie drzewko, to może być jakoś inaczej poukładane.
I mając ten kontekst biznesowy, jak to powinno być dalej używane, to ja układam sobie struktury. I zwróć uwagę, że ten ciężar odpowiedzialności który poświęcam na rozwiązanie, on skupia się nie na bazie wektorowej, nie na tym, jaki chunk wybrać. W ogóle tej chunki w ogóle nie palę, co może być, do kosza wszystkie. To jest najlepsze, co można zrobić.
Skupiam się przede wszystkim na tym, jak chcę utrzymać struktury moich danych, czy tam jest potrzebna aktualizacja. Jeżeli tak, to w jaki sposób nie będą dopływać, jak tę strukturę utrzymywać. Kolejna rzecz, czy te embeddinki, czy wektory będą potrzebne, to jest nie zawsze konieczne. Może być tak, że będą potrzebne, może być tak, że nie będą potrzebne.
Jednak to, co przy wektorach jest przydatne, bo faktycznie potrafią wychwytywać takie rzeczy, które nie potrafię wychwytywać w klasycznej wyszukiwarce, ale to wcale nie eliminuje klasycznej wyszukiwarki. To jest bardzo ważne, żeby to zrozumieć, że klasyczne wyszukiwarki nadal są potrzebne, bo potrafią wychwytywać te kluczowe słowa, które według takiej wyszukiwarki, powiedzmy, sztucznej inteligencji, bo tak czasem się nazywa, czyli interpretacji wektorowej, potrafią tu pomylić.
I w niektórych przypadkach, na przykład mówimy o prawach, finansach i podobnych, konkretne słowo na tyle jest czasem istotne, że to wszystko albo się obróci do góry nogami, albo czarne, albo białe. Ale z punktu widzenia embeddingu to może być podobne. I okazuje się, że ważne, że to jest podobne, dlatego wkładamy w taką dużą pułapkę.
Spróbuję podsumować to, co powiedziałem, żeby to było zrozumiałe. Bo jeżeli ja chcę zrobić rozwiązanie, które jest maksymalnie transparentne, czyli jestem w stanie zbadać, w jaki sposób dostaję odpowiedź, czyli jakie informacje są brane pod uwagę, jak się wyciąga kontekst, dlaczego jest ten błąd, też mogę zrobić…
Kiedy robię to bez większego zrozumienia, popełniam fundamentalny błąd. Jeżeli na przykład mam pewne problemy fundamentalne, gdy pokroiłem mój tekst na plasterki, wrzuciłem do jakiejś super nowoczesnej bazy, robiłem wiele różnych modeli, które próbują te plasterki wyciągnąć najlepsze, to popełniłem po prostu fundamentalny błąd. Wynikiem tego błędu jest to, że mogę cały czas dokładać jeszcze bardziej nowoczesne modele, jakieś super modne struktury. To wszystko się komplikuje, staje się takim statkiem kosmicznym w kwadracie i tak dalej, ale ostatecznie ten koszt też rośnie.
Koszt utrzymywania tego, koszt zrozumienia, kiedy jest jakiś błąd, dlaczego ten błąd tam się pojawił – to wszystko zaczyna przerażać i ostatecznie to się może skończyć tym, że ten AI nie działa. A nie działa nie tyle, że AI, tylko niewłaściwe zastosowanie.
Use case – sprawozdania finansowe
Ja jeszcze powiem taki przykład, który przy okazji właśnie robiłem w moim szkoleniu, bo to myślę, że taki fajny też na koniec. Zrobiłem taki eksperyment, żeby to też najbardziej przemawiało. Na przykład zabrałem sobie dane, właściwie sprawozdania finansowe. Najpierw znalazłem takich 200 największych firm w Polsce, wybrałem 7 PDFów. Na przykład tam trafiły dane z Enea, Orlen, PGE, PKO, PZU, Tauron.
I jak się domyślasz, to fajne w ogóle ćwiczenie. Zabrałem te sprawozdania, które z jednej strony mają pewną strukturę, bo są pewne wymogi, jakie informacje tam powinny się znaleźć. Z drugiej strony, jak takie informacje będziesz poszukiwać w Internecie, a to jest publiczna informacja, każdy może sobie to znaleźć, no to zobaczy, że te PDFy wyglądają po prostu inaczej. Czasem te tabelki wyglądają w taki sposób, czasem inaczej, jakieś obrazki się pojawiają, ta treść też w różny sposób się układa.
I to, co ja zrobiłem, to użyłem jakichś tam, w tym przypadku użyłem LlamaIndex. Przy tym mówiłem, nie polecam, nie polecam LangChain na produkcję. Coraz więcej osób to dostrzega, ale niestety nie tak szybko, i te koszty błędu, które będą coraz większe, będą boleć. I wtedy stanie się to oczywiste. Nadal widzę, że sporo osób używało LangChain na produkcję, bo tak się zaczęło, ale to wcale nie znaczy, że tak powinno być.
Ja użyłem też inny framework, żeby pokazać jako przykład, albo antywzorzec właściwie. W tym przypadku to był LlamaIndex. To, co zrobiłem, to użyłem taką bibliotekę, która nazywa się Simple Directory Reader. Czyli przekazałem tam ścieżkę do folderu, w którym są te moje PDFy. Wczytałem, bardzo szybko się wczytałem, za minutkę, i już miałem te wszystkie dokumenty.
I to, co dalej robiłem, na przykład zadałem sobie takie pytanie: „Podaj listę nazw firm, dla których posiadasz sprawozdanie finansowe. Jako wynik pokaż listę. Jak nie wiesz, to powiedz, że nie wiesz. Nie zwracaj nic innego.” Taki prompt przekazałem. Czyli zbudowałem sobie PDFy, które miałem, zabrałem PDFy, te PDFy przepuściłem przez te biblioteki modne, wytworzyły się pewne wektory, albo te osadzenia wektorowe, i wrzuciłem sobie to do jakiejś bazy wektorowej.
I niby wszystko miało być dobrze. I sobie testuję, i na przykład uruchamiam to po raz pierwszy, ten sam prompt, on mi zwraca, że ma PGE i KGHM, super, bo takie firmy też były. Uruchamiam to samo, i jeszcze raz to mi zwraca to samo, plus jeszcze PZU. Uruchamiam po raz kolejny, to zwraca już zamiast PZU, inaczej to napisała, Powszechny Zakład Ubezpieczeń, Spółka Akcyjna, i PKO, i tak dalej. Czyli de facto, każdym razem dostawałem coś innego.
No dobra, zacząłem dostawać kolejną rzecz. Na przykład pisuję sobie: „Jaki jest przychód ze sprzedaży w PGE w 2024 roku w złotówkach?” Czyli pytanie takie bardzo konkretne, konkretna firma, konkretna informacja, konkretny rok, i też, że to ma być w złotówkach. Dlaczego w złotówkach? Bo zauważyłem, że czasem podaje się w euro, więc jednoznacznie sobie podałem. Więc to jedno pytanie takie mam, odpowiedź dostawałem w miarę szybko, tam dwie sekundy, coś takiego.
Natomiast odpowiedź była różna. Na przykład czasem była taka odpowiedź po angielsku, i tam bardziej było napisane, że w 2023 roku była większa niż przedtem, i tam z jakichś tam powodów. A druga odpowiedź była taka, że wynosiło łącznie 11 milionów złotych, przynajmniej w złotych to podało, ale odpowiedź jest zła. A w trzecim przypadku w ogóle podało, że to jest 318 PLN przez megawatt na godzinę, czyli w ogóle podało nie w złotówkach, tylko podało w jakichś takich jednostkach, no i też wartość, która nie powinna być.
Czyli jak widzisz, zrobiłem nieskomplikowaną rzecz. Wziąłem sobie prostą bibliotekę, klik-klik, dostałem bazę wektorową, zadałem konkretne pytanie, no i odpowiedź jest, jaka jest. I tak naprawdę, jeżeli zaczniesz sobie to obadać, tą stronę, to okazuje się, że to jest w miarę standardowa historia, czym to się kończy. Dlaczego tak jest? Otóż dlatego, że żeby obsłużyć tego typu rozwiązania, to nie mogę sobie pozwolić na to, żeby wziąć tylko PDFy, pokroić to na kawałki, następnie zrobić jakiś tam embedding, jakiś taki losowy embedding.
W przypadku domyślnie embedding zwykle bierze się od OpenAI, który, swoją drogą, nie jest najlepszy w języku polskim, i to się wrzuca gdzieś tam do bazy wektorowej. I jak to zrobię w ten sposób, no to dostaję właśnie takie wyniki nieprzewidywalne. Ale też zwróć uwagę, że jeżeli jesteś użytkownikiem końcowym, i teraz zadajesz konkretne zapytanie, dostajesz odpowiedź, na przykład jakąś tam, i teraz skąd wiesz, że ta odpowiedź jest prawidłowa lub nieprawidłowa? Czy możesz mieć tam zaufanie, czy nie?
I teraz pomyśl w taki sposób: kto chciałby używać takiego rozwiązania, które za każdym razem, zadając to samo pytanie, może dawać coś innego, a właściwie ty nadal nie wiesz, która odpowiedź jest prawidłowa. Czy chciałbyś używać takiego rozwiązania? No oczywiście, że nie, no bo to wprowadza więcej zamieszania i szumu, niż to, co używałeś przedtem. Nie wiem, jak tam było przedtem analizowane, ale nawet jak oczami sobie sprawdzisz te PDFy, to będzie lepszy wynik.
I jakie jest rozwiązanie? No teraz już dochodzimy do tego punktu, który jest najważniejszy, jeżeli chodzi o konceptualne, na czym trzeba się skupić. Dalej będę rozwijać, zobaczymy, czy zdążę wszystko to opowiedzieć w podcastie. Ja próbuję przynajmniej część informacji przekazać, natomiast jak jesteś zainteresowany, to koniecznie się zapisz na moje szkolenie, gdzie krok po kroku o tym tłumaczę.
Największy wysiłek, który tu wkładam, to żeby zrozumieć proces krok po kroku i rozpisać sobie, co dokładnie ma się wydarzyć, aby ten problem był rozwiązany przez człowieka. I później to, co się zmienia de facto, to ja z góry wiem, jaki kontakt chcę dostarczyć, co z czym chcę porównać, jaki wynik jest możliwy, kiedy to jest wadliwe, kiedy niewadliwe, żeby tam ewentualnie zrobić jakieś double-checki.
I wtedy pojawi się struktura, jak powinienem przechowywać dane, jeżeli chodzi o te rzeczy, dokumenty, które sprawdzam, dane, które przychodzą z zewnątrz, w jaki sposób chcę to podzielić. To nie jest tylko kwestia per paragraf albo jak dalej. To właśnie różnie może być. To może być takie drzewko, to może być jakoś inaczej poukładane.
I mając ten kontekst biznesowy, jak to powinno być dalej używane, to ja układam sobie struktury. I zwróć uwagę, że ten ciężar odpowiedzialności który poświęcam na rozwiązanie, on skupia się nie na bazie wektorowej, nie na tym, jaki chunk wybrać. W ogóle tej chunki w ogóle nie palę, co może być, do kosza wszystkie. To jest najlepsze, co można zrobić.
Skupiam się przede wszystkim na tym, jak chcę utrzymać struktury moich danych, czy tam jest potrzebna aktualizacja. Jeżeli tak, to w jaki sposób nie będą dopływać, jak tę strukturę utrzymywać. Kolejna rzecz, czy te embeddinki, czy wektory będą potrzebne, to jest nie zawsze konieczne. Może być tak, że będą potrzebne, może być tak, że nie będą potrzebne.
Jednak to, co przy wektorach jest przydatne, bo faktycznie potrafią wychwytywać takie rzeczy, które nie potrafię wychwytywać w klasycznej wyszukiwarce, ale to wcale nie eliminuje klasycznej wyszukiwarki. To jest bardzo ważne, żeby to zrozumieć, że klasyczne wyszukiwarki nadal są potrzebne, bo potrafią wychwytywać te kluczowe słowa, które według takiej wyszukiwarki, powiedzmy, sztucznej inteligencji, bo tak czasem się nazywa, czyli interpretacji wektorowej, potrafią tu pomylić.
I w niektórych przypadkach, na przykład mówimy o prawach, finansach i podobnych, konkretne słowo na tyle jest czasem istotne, że to wszystko albo się obróci do góry nogami, albo czarne, albo białe. Ale z punktu widzenia embeddingu to może być podobne. I okazuje się, że ważne, że to jest podobne, dlatego wkładamy w taką dużą pułapkę.
Spróbuję podsumować to, co powiedziałem, żeby to było zrozumiałe. Bo jeżeli ja chcę zrobić rozwiązanie, które jest maksymalnie transparentne, czyli jestem w stanie zbadać, w jaki sposób dostaję odpowiedź, czyli jakie informacje są brane pod uwagę, jak się wyciąga kontekst, dlaczego jest ten błąd, też mogę zrobić…
Kiedy robię to bez większego zrozumienia, popełniam fundamentalny błąd. Jeżeli na przykład mam pewne problemy fundamentalne, gdy pokroiłem mój tekst na plasterki, wrzuciłem do jakiejś super nowoczesnej bazy, robiłem wiele różnych modeli, które próbują te plasterki wyciągnąć najlepsze, to popełniłem po prostu fundamentalny błąd. Wynikiem tego błędu jest to, że mogę cały czas dokładać jeszcze bardziej nowoczesne modele, jakieś super modne struktury. To wszystko się komplikuje, staje się takim statkiem kosmicznym w kwadracie i tak dalej, ale ostatecznie ten koszt też rośnie.
Koszt utrzymywania tego, koszt zrozumienia, kiedy jest jakiś błąd, dlaczego ten błąd tam się pojawił – to wszystko zaczyna przerażać i ostatecznie to się może skończyć tym, że ten AI nie działa. A nie działa nie tyle, że AI, tylko niewłaściwe zastosowanie.
Ja jeszcze powiem taki przykład, który przy okazji właśnie robiłem w moim szkoleniu, bo to myślę, że taki fajny też na koniec. Zrobiłem taki eksperyment, żeby to też najbardziej przemawiało. Na przykład zabrałem sobie dane, właściwie sprawozdania finansowe. Najpierw znalazłem takich 200 największych firm w Polsce, wybrałem 7 PDFów. Na przykład tam trafiły dane z Enea, Orlen, PGE, PKO, PZU, Tauron.
I jak się domyślasz, to fajne w ogóle ćwiczenie. Zabrałem te sprawozdania, które z jednej strony mają pewną strukturę, bo są pewne wymogi, jakie informacje tam powinny się znaleźć. Z drugiej strony, jak takie informacje będziesz poszukiwać w Internecie, a to jest publiczna informacja, każdy może sobie to znaleźć, no to zobaczy, że te PDFy wyglądają po prostu inaczej. Czasem te tabelki wyglądają w taki sposób, czasem inaczej, jakieś obrazki się pojawiają, ta treść też w różny sposób się układa.
I to, co ja zrobiłem, to użyłem jakichś tam, w tym przypadku użyłem LlamaIndex. Przy tym mówiłem, nie polecam, nie polecam LangChain na produkcję. Coraz więcej osób to dostrzega, ale niestety nie tak szybko, i te koszty błędu, które będą coraz większe, będą boleć. I wtedy stanie się to oczywiste. Nadal widzę, że sporo osób używało LangChain na produkcję, bo tak się zaczęło, ale to wcale nie znaczy, że tak powinno być.
Ja użyłem też inny framework, żeby pokazać jako przykład, albo antywzorzec właściwie. W tym przypadku to był LlamaIndex. To, co zrobiłem, to użyłem taką bibliotekę, która nazywa się Simple Directory Reader. Czyli przekazałem tam ścieżkę do folderu, w którym są te moje PDFy. Wczytałem, bardzo szybko się wczytałem, za minutkę, i już miałem te wszystkie dokumenty.
I to, co dalej robiłem, na przykład zadałem sobie takie pytanie: „Podaj listę nazw firm, dla których posiadasz sprawozdanie finansowe. Jako wynik pokaż listę. Jak nie wiesz, to powiedz, że nie wiesz. Nie zwracaj nic innego.” Taki prompt przekazałem. Czyli zbudowałem sobie PDFy, które miałem, zabrałem PDFy, te PDFy przepuściłem przez te biblioteki modne, wytworzyły się pewne wektory, albo te osadzenia wektorowe, i wrzuciłem sobie to do jakiejś bazy wektorowej.
I niby wszystko miało być dobrze. I sobie testuję, i na przykład uruchamiam to po raz pierwszy, ten sam prompt, on mi zwraca, że ma PGE i KGHM, super, bo takie firmy też były. Uruchamiam to samo, i jeszcze raz to mi zwraca to samo, plus jeszcze PZU. Uruchamiam po raz kolejny, to zwraca już zamiast PZU, inaczej to napisała, Powszechny Zakład Ubezpieczeń, Spółka Akcyjna, i PKO, i tak dalej. Czyli de facto, każdym razem dostawałem coś innego.
No dobra, zacząłem dostawać kolejną rzecz. Na przykład pisuję sobie: „Jaki jest przychód ze sprzedaży w PGE w 2024 roku w złotówkach?” Czyli pytanie takie bardzo konkretne, konkretna firma, konkretna informacja, konkretny rok, i też, że to ma być w złotówkach. Dlaczego w złotówkach? Bo zauważyłem, że czasem podaje się w euro, więc jednoznacznie sobie podałem. Więc to jedno pytanie takie mam, odpowiedź dostawałem w miarę szybko, tam dwie sekundy, coś takiego.
Natomiast odpowiedź była różna. Na przykład czasem była taka odpowiedź po angielsku, i tam bardziej było napisane, że w 2023 roku była większa niż przedtem, i tam z jakichś tam powodów. A druga odpowiedź była taka, że wynosiło łącznie 11 milionów złotych, przynajmniej w złotych to podało, ale odpowiedź jest zła. A w trzecim przypadku w ogóle podało, że to jest 318 PLN przez megawatt na godzinę, czyli w ogóle podało nie w złotówkach, tylko podało w jakichś takich jednostkach, no i też wartość, która nie powinna być.
Czyli jak widzisz, zrobiłem nieskomplikowaną rzecz. Wziąłem sobie prostą bibliotekę, klik-klik, dostałem bazę wektorową, zadałem konkretne pytanie, no i odpowiedź jest, jaka jest. I tak naprawdę, jeżeli zaczniesz sobie to obadać, tą stronę, to okazuje się, że to jest w miarę standardowa historia, czym to się kończy. Dlaczego tak jest? Otóż dlatego, że żeby obsłużyć tego typu rozwiązania, to nie mogę sobie pozwolić na to, żeby wziąć tylko PDFy, pokroić to na kawałki, następnie zrobić jakiś tam embedding, jakiś taki losowy embedding.
W przypadku domyślnie embedding zwykle bierze się od OpenAI, który, swoją drogą, nie jest najlepszy w języku polskim, i to się wrzuca gdzieś tam do bazy wektorowej. I jak to zrobię w ten sposób, no to dostaję właśnie takie wyniki nieprzewidywalne. Ale też zwróć uwagę, że jeżeli jesteś użytkownikiem końcowym, i teraz zadajesz konkretne zapytanie, dostajesz odpowiedź, na przykład jakąś tam, i teraz skąd wiesz, że ta odpowiedź jest prawidłowa lub nieprawidłowa? Czy możesz mieć tam zaufanie, czy nie?
I teraz pomyśl w taki sposób: kto chciałby używać takiego rozwiązania, które za każdym razem, zadając to samo pytanie, może dawać coś innego, a właściwie ty nadal nie wiesz, która odpowiedź jest prawidłowa. Czy chciałbyś używać takiego rozwiązania? No oczywiście, że nie, no bo to wprowadza więcej zamieszania i szumu, niż to, co używałeś przedtem. Nie wiem, jak tam było przedtem analizowane, ale nawet jak oczami sobie sprawdzisz te PDFy, to będzie lepszy wynik.
I jakie jest rozwiązanie? No teraz już dochodzimy do tego punktu, który jest najważniejszy, jeżeli chodzi o konceptualne, na czym trzeba się skupić. Dalej będę rozwijać, zobaczymy, czy zdążę wszystko to opowiedzieć w podcastie. Ja próbuję przynajmniej część informacji przekazać, natomiast jak jesteś zainteresowany, to koniecznie się zapisz na moje szkolenie, gdzie krok po kroku o tym tłumaczę.
Idea najważniejsza, którą chciałem przekazać dzisiaj. Istnieje takie coś jak RAG i RAG faktycznie może rozwiązywać pewne problemy, przynajmniej na poziomie konceptualnym, takie jak zwiększanie transparentności, zwiększanie audytowalności, zmniejszanie kosztów, albo też aktualność danych. To wszystko może być, natomiast problem, który w tej chwili jest, jeżeli chodzi o takie rozwiązania klasyczne, które gdzieś tam się pojawiły jakiś czas temu, ono się skupia nie na właściwych rzeczach.
Takie klasyczne rozwiązania RAG skupiają się na tym, aby jakoś sobie paczankować w głupi sposób nasze dane i tym samym rozerwać tą strukturę. Jak tą strukturę rozrywamy, bo to jest ważne, żeby to zrozumieć, to my tracimy sens, no bo wyrywamy jakiś kawałek tekstu i później ten tekst, oderwany od kontekstu, możemy go znaleźć, ale tylko sam kawałek tego tekstu już nie daje nam rozwiązania.
I dalej oczywiście możemy sobie tam majstrować różne rzeczy, że na przykład wyciągamy nie jeden kawałek, a dwa przed, dwa po, albo coś innego. Ale mam nadzieję, że udało mi się to wytłumaczyć, że jak robimy to w sposób taki sztuczny, taki mechaniczny za bardzo, to czasem to działa, a czasem nie działa. I wtedy, kiedy nie działa to, co robimy, to wszystko usuwamy, cały ten budynek znosimy, albo całą dzielnicę i budujemy od nowa. Ale wtedy okej, działa w tym przypadku, ale już nie działa to, co działało przedtem. I tak sobie w kółeczko się bawimy.
Czyli czuć to, że coś tu śmierdzi, że nie tędy droga, że my nie powinniśmy albo nie chcemy zarządzać tą niepewnością w taki jakiś głupi sposób, kiedy dzielimy sobie, krojemy w sztuczny sposób pewne informacje i potem ewentualnie to usuwamy i jeszcze raz przerabiamy. Oczywiście to podejście takie, które jest bardziej mądrzejsze, kiedy uzupełniamy model LLM, który według nas decyduje, jakie informacje my potrzebujemy i wtedy dzieli na przykład troszkę bardziej sprytniej, ale to też ma pewne wady, no bo skąd ten model LLM wie, co my potrzebujemy.
Jednak nadal ta naturalna inteligencja jest bardzo potrzebna i takie rzeczy jak jakość danych, dane, do których mamy zaufanie, dobrze poukładana struktura tych danych, znów to wygrywa. Znów to jest ta rzecz, która w ML-u się pojawia cały czas, garbage in, garbage out, czyli najwięcej uwagi, którą masz poświęcić na to rozwiązanie, to zrozumieć, jakie problemy konkretnie chcesz rozwiązać, jaki konkretny kontekst będzie potrzebny, żeby to rozwiązać, aby to było nie za duże, a nie za małe, czyli idealne po prostu przerobić to manualnie, krok po kroku.
Masz takie zapytania, żeby na to pytanie odpowiedzieć, to potrzebujesz taki kontekst, ten kontekst się bierze stąd i stąd i czasem to jest jedno zdanie, czasem to są dwa paragrafy na początku i na końcu, czasem to jest jeszcze coś, nie wiem, cała tabelka, ale to jest tak, że to jest dość różnie i z jednej strony to może przerażać, jak ja to zrobię wszystko manualnie, ale no spokojnie, potem to możemy automatyzować, natomiast i tak na początek trzeba zrobić to manualnie i najwięcej czasu należy poświęcić nie na tym, żeby wybrać jaką bazę wektorową, czy jakie tam chunki.
Te chunki do wyrzucenia, nie idziemy tą drogą totalnie, nie polecam. Bardziej chodzi o to, że my jak zrozumiemy, jakie dane my potrzebujemy, żeby tym zarządzać, to wtedy już, mając tą naszą reprezentację tekstu, czy to w bazie danych, czy to w plikach, czy tam jeszcze gdzieś, albo jakaś taka ścieżka, tutaj dochodzimy do czegoś, co nazywam mapą wiedzy. To o tym będę jeszcze mówić, bo to jest krok dalej, bo teraz wprowadzam pojęcie, gdzie jest największy problem, a potem jest krok dalej, jak to można zarządzać. I ta mapa wiedzy to jest taka ścieżka, jak możemy oszczelnić, albo znaleźć poszczególne kawałki. Efekt wow nie należy wdrażać na produkcję, bo ostatecznie możesz więcej stracić.
Myślę, że to byłoby tyle, jeżeli chodzi o dzisiejszy odcinek. Mam nadzieję, że udało mi się wyjaśnić, na czym polega fundamentalny błąd w klasycznym RAG i że dokładanie kolejnych mini-klocków, bo to naprawdę się komplikuje, wcale nie rozwiązuje tego problemu. W klasycznym RAG jest za mała koncentracja na jakości danych i jakiej struktury my potrzebujemy.
Czyli ta odpowiedzialność została zrzucona z człowieka na jakieś algorytmy, i tutaj jest błąd fundamentalny.
To, co ma nastąpić, jeżeli chcesz praktycznie stworzyć rozwiązanie, w którym będziesz mieć zaufanie i poczucie, że to rozwiązanie ma sens, to jest takie, że musisz spędzić więcej czasu używając swojej naturalnej inteligencji, żeby zrozumieć, co ja właściwie chcę osiągnąć, jakie dane będę potrzebować, żeby to osiągnąć i żeby dalej tym lepiej zarządzać.
Zwróć uwagę też, jeśli jeszcze nie poruszyłem w tym wątku, wspomniałem tylko, że te problemy GDPR i podobne mogą być, albo data security, no to w tym przypadku, kiedy ty jednoznacznie zrozumiesz, jakie informacje potrzebujesz, jakie konteksty, z których miejsc, ale tak jakby jednoznacznie. To nie jest tak, że kroisz sobie paragrafami, bo w tym samym dokumencie mogą być informacje, które mogą być publiczne, paragraf pierwszy i piąty, ale ten drugi na przykład już nie może być dostępny publicznie, a tylko dostępny komuś tam.
I tutaj już pojawia się pewna struktura, że aha, dobra, to z jednej strony fajnie sobie umieć znaleźć pewne informacje, ale też trzeba zaraz zaimplementować pewną warstwę, że te informacje na przykład ten ktoś może znaleźć, a ten ktoś drugi nie powinien tego znaleźć, prawda? I wtedy staje się też oczywiste, jak zarządzać tym, żeby audytowalność i inne takie wymogi prawne były nadal spełnione.
No bo jeżeli masz całą bazę, a jeśli lepiej tą całą bazę wrzucamy do jednego kontekstu, no to jest totalne zepsucie wszystkich tych reguł, co nie jest dobrze dla firmy i też dla twoich klientów.
Mam nadzieję, że udało mi się wyjaśnić najważniejsze problemy, najważniejsze wyzwania i też pokazać, jak należy patrzeć na projektowanie takich systemów.
Ja planuję dalej rozwijać ten wątek, i tu na różne sposoby, i w podcaście, ale też obserwuj moje inicjatywy, w tym też szkolenie, zaczynając od promptowania i krok dalej, bo tam będziemy coraz bardziej się zanurzać w zależności od tego, co potrzebujesz, bo czasem potrzebujesz tylko promptowania, czasem potrzebujesz być może RAG, może dalej też mapy wiedzy, a może też i fine-tuningu.
Chociaż na temat fine-tuningu już powiedziałem, że to jest wątek, który w większości przypadków mało komu będzie potrzebny w praktyce, ale są faktycznie przypadki, kiedy to może być przydatne.
Na koniec mam dla ciebie taką prośbę. Aby przygotować taki odcinek, bardzo się staram, układam strukturę, spędzam czas, na przykład dzisiaj nagrywałem to w weekend, bo po prostu w dni robocze też mam wiele innych rzeczy, i robię to po to, żeby podzielić się z tobą moim przemyśleniem, moim doświadczeniem, to, co mi gdzieś tam w środku boli, przekazać to, co ja widzę, i to, co mi wydaje się, że powinno być szersze grono osób powinno to też zobaczyć.
To mam taką prośbę do ciebie: podziel się swoją opinią, swoją myślą, napisz komentarz w zależności od platformy, gdzie to słuchasz, postaw lajka, serduszko, co tam masz pod ręką, i też poleć przynajmniej jednej osobie wysłuchać ten odcinek.
Bo ja na pewno wiem, że taką osobę w swoim otoczeniu posiadasz, i ta osoba będzie ci wdzięczna za to, a ja ci też będę wdzięczny, że pomagasz mi szerzyć wiedzę o tym, jak powinno to się robić w praktyce, żeby faktycznie to działało efektywnie, a nie tylko robiło efekt wow później w razie czarowania.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
