
Praktyczny LLM
A dzisiaj skupimy się na praktycznym LLM. O LLM nagrałem już wiele odcinków, żeby wyjaśnić szerszy kontekst, ale dzisiaj będziemy mówić o tym, czym tak naprawdę jest praktyczny LLM i jakie kroki na Twoim miejscu wykonałbym, żeby faktycznie nauczyć się robić to dobrze. Oczywiście w ramach podcastu będę raczej wymieniać pewną strukturę, a jeśli chodzi o zgłębienie tego, to też powiem, co można zrobić.
Historia ma to do siebie, że lubi zataczać koła. Pewnie słyszałeś o tym. ML-em jako takim zajmuję się już od ponad 10 lat. Pierwsze kursy, które powstały w ramach Data Workshop mają już około 5 lat, może troszkę więcej. Jeśli chodzi o klasyczne uczenie maszynowe, to uczymy tam różnych aspektów, zaczynając od wprowadzenia do ML, szeregi czasowe, prace z tekstem, prace z obrazkami – to wszystko mamy.
Mniej więcej dwa lata temu, pojawił się OpenAI w tym sensie takim sławnym. OpenAI był założony znacznie wcześniej, ale dwa lata temu mniej więcej pojawił się ChatGPT, ten „szef”, który zrobił pewną rewolucję. Chociaż taka ciekawostka, bo też jest takie fajne rozważanie. Żyjemy takim pewnym bąbelkiem i nam się wydaje, przynajmniej mi, że ChatGPT to jest na tyle popularna rzecz, że wszyscy o tym słyszeli i pewnie wszyscy już to próbowali. Otóż okazuje się, że nie. Ostatnio do mnie trafiła taka ciekawa statystyka i też podzielę się z Tobą.
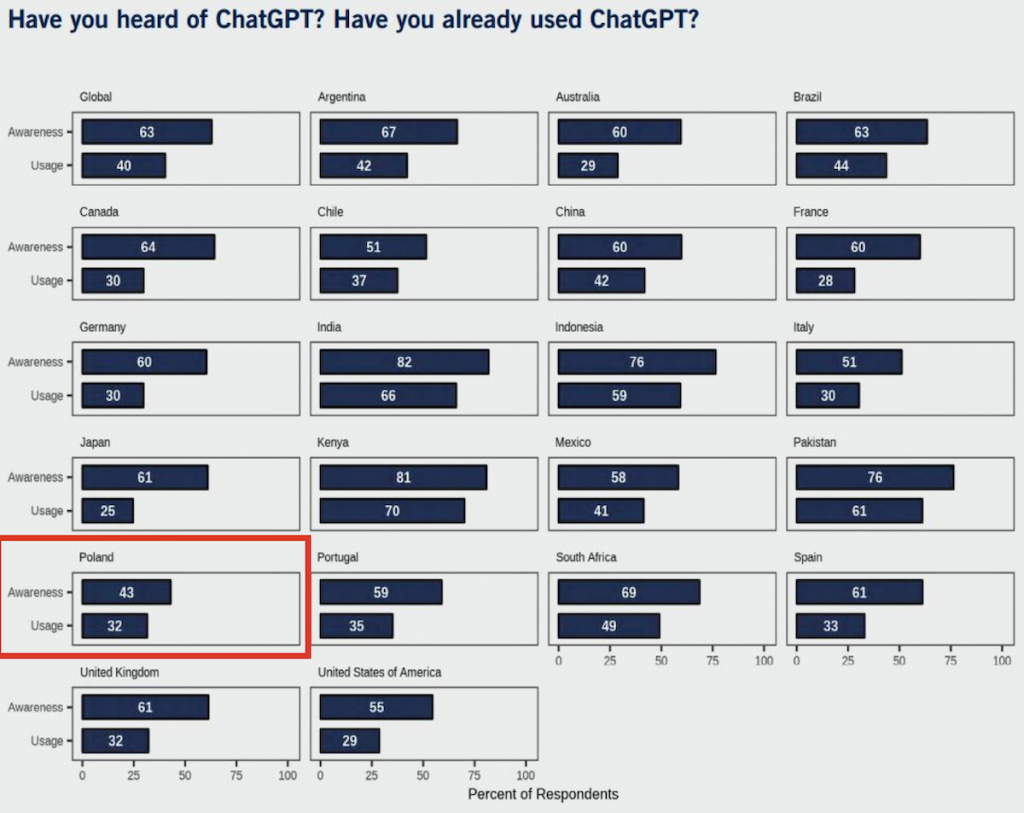
Ta statystyka mówi o tym, na przykład jeśli chodzi wprost o Polskę, że tylko 43% jest świadomych tego, że istnieje ChatGPT, 43%, czyli mniej niż połowa, i tylko 32% używało, z tego co rozumiem, przynajmniej raz. Więc tylko 1/3 używała ChatGPT. W innych krajach wygląda to trochę inaczej, na przykład jeżeli chodzi o świadomość tej technologii, czyli ChatGPT, w Stanach Zjednoczonych to jest 55%, w UK to jest 61%, w Portugalii na przykład 59%, a też taka ciekawostka na temat Afryki. W Kenii to jest 81%, w Południowej Afryce 69% i tak dalej. Więc pod tym względem wygląda to, że w Polsce ChatGPT, nawet ChatGPT, który jest bardzo popularny i słynny, wcale nie jest. Chociaż z drugiej strony tutaj też można by długo rozważać dlaczego, też nie wszyscy mają dostęp do internetu nawet w naszych czasach, więc to jest taka ciekawostka też dla mnie przede wszystkim. Chciałem ci powiedzieć, że jak mówimy, że coś jest popularne, to wcale nie oznacza 100%, ale przynajmniej 1/3 osób w Polsce próbowała ChatGPT. To też pewnie bardzo dużo. Czy jednak mało? Jak myślisz?
I teraz, kiedy to się pojawiło, ja pamiętam te czasy, kiedy zacząłem to przeglądać, to z jednej strony jako osoba, która dawno się zajmuje ML-em, poczułem się, jakbym pewne rzeczy zrozumiał. To znaczy, zrozumiałem, wiedziałem, że tam pod spodem są na przykład transformery, no tu mam osobny kurs, na którym uczę, jak to działa. Wiedziałem, jak ten model był trenowany, ale z drugiej strony jest takie coś, kiedy gromadzi się pewna masa krytyczna i z jednej strony ty możesz rozumieć pewne rzeczy, jak to było przygotowane, ale z drugiej strony rozumiesz, że coś się zmieniło. Nastąpił tak zwany kwantowy przeskok, albo jakkolwiek to nie nazwać, czyli przeskoczyliśmy z jednego poziomu na drugi poziom. W ogóle rozwój ma to do siebie, że lubi przeskakiwać z punktu do punktu. Rozwój nigdy nie jest taki ciągły, to jest takie właśnie skakanie.
I teraz jest ten moment, kiedy to się w miarę już stabilizuje, być może jakiś moment będzie kolejne skakanie, ale to, co jest ważne. Ja pamiętam wtedy, rozważałem o tym, myślałem, próbowałem, myślę, o, to jest ciekawe, trzeba znacznie lepiej poznać naturę tego zjawiska, żeby zacząć eksperymentować, no i też wdrażać. I pomyślałem wtedy, nie będę teraz robić coś na szybko, na przykład na szybko zrobić jakiś kurs o, nie wiem, o Langchain, bo on to w miarę szybko się pojawił. Chociaż miałem taki na początku pomysł, że jak uczyłem się tej biblioteki, to pomyślałem, dobra, nauczę też innych, jak to używać. Ale wycofałem się z tego pomysłu, bo z praktycznego punktu widzenia nie są ważne narzędzia. Ważne jest to, żeby zrozumieć, co jest ważne, co jest pierwotne, co jest fundamentem. Potem są rzeczy drugorzędne i tak dalej.
I w tym czasie, właściwie to mniej więcej już dwa lata minęły, w tym czasie przeprowadziłem wiele różnych eksperymentów. Też w ramach Data Workshop pracowaliśmy z innymi firmami, pomagaliśmy, konsultowaliśmy, pewne rzeczy wdrażaliśmy. Chociażby na przykład teraz prowadzę w takiej aktywnej fazie z nami trzy projekty, chociaż też jest kilka innych, takich mniej aktywnych, takie powiedzmy w przygotowawczej fazie. Więc tych projektów troszkę się wydarzyło. A ostatnio sobie próbowałem tak zliczyć, to jest trochę taka techniczna rzecz, ale tak sobie wyobrażać mniej więcej ile ja osobiście zrobiłem API call do takich różnych modeli, tych zamkniętych czy tych otwartych. I tak wyszło dużo. Ja myślę, że, bo akurat tego nie mierzyłem jednoznacznie, ale tak sobie rozważając na różne sposoby, ile by to mogło być, to na pewno było w dziesiątkach tysięcy, ja myślę, że nawet bardziej w setkach tysięcy takie różne API call. I też warto zrozumieć, że to nie chodzi tylko o to, że napisałem jeden prompt i to kręciło się w kółko, tylko właśnie faktycznie sprawdzałem różne rzeczy.
Dlaczego to mówię? I teraz doszedłem do tego punktu, że w mojej głowie pewna struktura się utworzyła. To znaczy, wytworzyły się takie pewne kamienie milowe, na których warto się oprzeć, jeżeli mówimy o LLM na produkcji, takim praktycznym LLM, który potrafi pewne rzeczy zrobić, zrozumieć, jakie to ma ograniczenia i jakie to ma możliwości. Dla biznesu to jest bardzo ważne. Bo dla biznesu z jednej strony oczywiście prototypy gdzieś tam są po drodze, ale prototypy nigdy nie są celem. Dlaczego w ogóle prototypy są ważne dla biznesu? No bo biznes się uczy na błędach, prawda?
W sumie wszystko jedno, okazuje się, że pewna ścieżka jest wadliwa i nie tędy droga. Czyli na przykład jak pojawia się pewien prototyp, a później ciężko jest go rozwijać i utrzymywać, to dochodzi do bardzo prostego wniosku – nie tędy droga. W takim razie którędy? Teraz tworzenie mniejszych kroków i sprawdzanie pewnych możliwości to jest fajne, ale oczekuje się domyślnie, biznes oczekuje, że jak mamy ten mniejszy krok, to później możemy go rozwijać dalej. Tylko problem polega na tym, że w elementach, które są w szczególności bardzo widoczne, w odróżnieniu na przykład od klasycznego programowania, kiedy mamy taką sytuację, że zrobienie pewnego prototypu, które robi wrażenie, jest znacznie łatwiejsze, ale później rozwijanie tego i wdrażanie na produkcję, aby mieć na tym kontrolę, zaufanie, audytowalność, staje się bardzo trudne albo prawie niemożliwe. Czyli totalnie to przekreśla. Wtedy jest taki niesmak i właśnie to poczucie biznesu, że chyba to nie działa. I ta falia się zaczyna. To akurat dobrze. Teraz wyjaśnię dlaczego. Ta falia się zaczyna, że w tej chwili biznes pomału zaczyna docierać te sygnały, informacje, że aha, halo, halo, ten cały szum informacji, ten cały marketing, który się kręci wokół LLM, to chyba jednak nie tędy droga. Zresztą krzywe Gartnera to można zawsze zobaczyć, jak ta falia rosła w 2023 roku.
Krzywa Gartnera
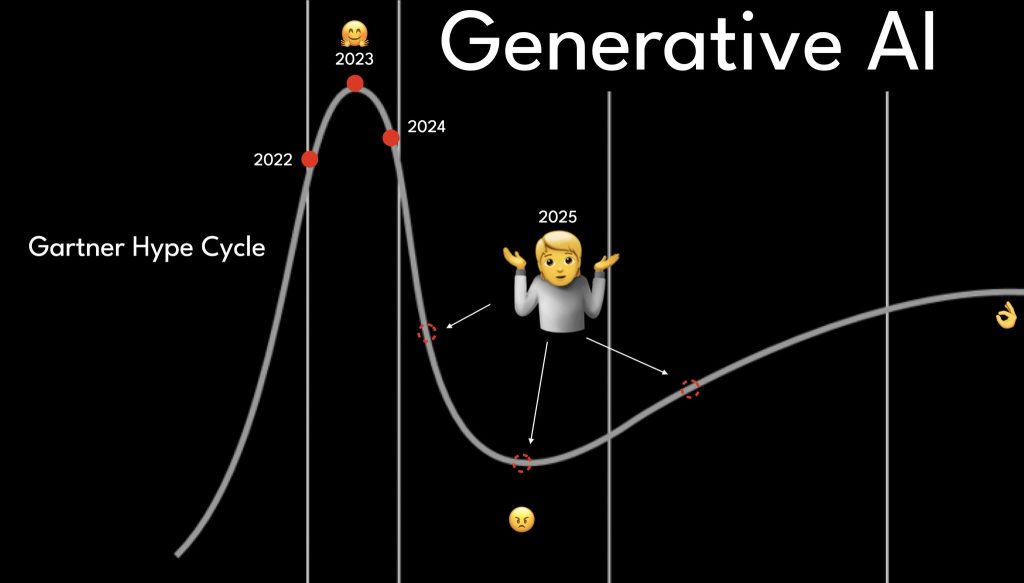
Pisałem post na LinkedIn, gdzie próbowałem zadać pytania, żeby zgadnąć, w którym miejscu będziemy na przykład w 2025 roku, jeżeli chodzi o tę falę rozczarowań z GenAI? To też kolejna myśl, która przychodzi do głowy, że mamy takie coś jak świat programowania, świat programistyczny. I tam też były pewne rzeczy, które stabilizowały się z czasem, to znaczy w praktyce. Te pierwsze programy, które zaczęły się pojawiać, w szczególności ta faza pomiędzy tym, kiedy robili to powiedzmy takie uczelnie i kiedy w latach dziewięćdziesiątych, tak początku dwutysięcznych, to się rozlało, język PHP i podobne stały się bardziej popularne i prawie każdy student, uczeń mógł też to tworzyć. Wytworzyło się mnóstwo kodu, któremu nie do końca było zaufania. I później była taka turbulencja i to się tak stabilizowało, nawarstwiało się, stabilizowało i w tym czasie możemy uznać, że w świecie IT pewne rzeczy się wypracowały.
Tam nadal są różne turbulencje, ale pewne rzeczy się ustabilizowały. W świecie ML było podobnie. Potem to zaczęło się troszkę stabilizować, inspirując się tym, co posiada klasyczne programowanie, na przykład wciągając takie elementy jak Continuous Integration, wersjonowanie kodu, testowanie kodu i podobne. W świecie LLM właśnie ta turbulencja dopiero się zaczyna. Co to znaczy w praktyce? Właśnie najpierw była ta faza, rzućmy się i coś poróbmy, jakieś różne dziwne rzeczy, które sprawiają, że to może mieć sens. No i później okazuje się, że ciężko jest z tym zarządzać. To jest nieprzewidywalne, temu nie da się zaufać, a skoro nie da się zaufać, to kto będzie to używać? No i teraz wchodzi ta kolejna faza, do której się cieszę, bo dla mnie zawsze było bliskie, zawsze dla mnie znajdowało się takie podejście, kiedy chcemy zrobić to solidnie, chcemy zrobić to porządnie, chcemy to tak poukładać, żeby to się opierało na pewne słupy, takie pewne fundamenty, którym da się zarządzać, da się kontrolować, da się wprowadzać zmiany, rozszerzyć. To jest właśnie taki świat, który mnie bardzo rezonuje, bardzo mi się podoba.
Dobra praktyki w programowaniu
Pamiętam czasy, kiedy przed (moim) ML-em, kiedy zajmowałem się tylko programowaniem i tworzyłem też architekturę, bardzo starałem się szerzyć takie dobre praktyki w programowaniu, między innymi na przykład takie rzeczy, które nazywały się wtedy design by contract, żeby tam pewne rzeczy wprowadzać na początku, na końcu. Jakby nie wchodząc teraz w szczegóły, ale generalnie biorąc teraz mam takie wrażenie, że tamte praktyki, które wtedy szerzyłem w roli w takim świecie bardziej programistycznym, trzeba teraz wnieść do świata ML-owego, oczywiście adaptując do tej natury, która jest w świecie ML-owym i wtedy faktycznie wytworzyć tę wartość do danych.
Idąc do dzisiejszego odcinka, ja w ogóle przygotowałem kilka rzeczy, które chciałem z tobą się podzielić i generalnie rzecz biorąc, pomyślałem tak: postaram się dzisiaj odpowiedzieć na pytanie, co bym ja zrobił na twoim miejscu, jakbym chciał zacząć wdrażać praktyczne ML-owe rozwiązania na produkcję, czyli w taki praktyczny sposób, czyli w sposób, który rozwiązuje konkretne problemy, jakie by to były kroki, tak bardziej konceptualne. Również też ja ostatnio zbierałem pytania osób, które właśnie chcą to zrobić i ciekawiło mnie taką bardzo prostą rzecz, a właściwie co martwi ludzi, co jest ważne, co w tej chwili jest największym wyzwaniem, czym sobie nie do końca mogą poradzić i gdzie jest potencjalna rzecz, którą mogę podpowiedzieć i pomóc.
Bo to zawsze jest tak, że jak tymi rzeczami się zajmujesz, pewne rzeczy są prostsze, bardziej przewidywalne, ale z drugiej strony nie zawsze zdajesz sobie sprawę, który konkretny aspekt w tym całym gąszczu jest bardziej trudniejszy. I przy tym, jak zacznę omawiać taką pełną strukturę, to ja proponuję zrobić tu dwie rzeczy. Po pierwsze to sobie zrobiłem takie notatki, żeby takie pierwsze ostrzeżenie na początek albo disclaimer. Obecnie jest takie popularne podejście no-code, kiedy w ogóle nie piszesz kodu, tylko klik, klik, klik i już dostajesz rozwiązanie.
I to nie zawsze musi być związane z ML-em, to może być nawet coś innego, ale bardziej chodzi o to, że od razu powiem, jak do tego się odnoszę, bo też jest ważne, żeby dalej tego punktu nie dotykać. Ja osobiście nie wierzę w tak zwany no-code. Dlaczego nie wierzę? Przeżywałem to wiele razy. Jeszcze przed światem ML, takim bardziej biznesowym ML, kiedy byłem bardziej programistą, też pracowałem z jedną firmą, która właśnie takie narzędzia tworzyła. Pamiętam, jak bardziej szedłem do świata ML, to też się wytwarzało takie różne studia, takie no-code, takie zresztą nawet w chmurach, tak po bardziej popularnych, na przykład ML Studio, takie było w Azure. Kiedy tworzyłeś takie różne chmurki albo takie węzły, klik, klik, tam coś przypływa i wszystko jest pięknie.
Ale to zawsze się kończy w ten sam sposób. W jaki? Zrobić piękny prototyp jest fajnie – kilka węzłów, coś się kopiuje, odczytujemy dane, robimy piękny wykres, super. Ale biznes z natury się zmienia i potrzebuje elastyczności. Istnieje pewnie bardzo mało biznesów na tym świecie, które przez sto lat mogły sobie pozwolić na to, aby mieć twarde i jednoznaczne reguły, które nigdy się nie zmieniają. Być może znasz takie przykłady – podziel się swoją wiedzą w komentarzach. Dotyczy to raczej organizacji państwowych niż zwykłych firm. Natomiast typowy biznes działa w taki sposób, że świat zmienia się szybciej niż myślisz, a biznes musi się adaptować. Co to oznacza w praktyce? To, co wspiera biznes, musi być elastyczne.
I to zwykle kończyło się tym, że oprócz standardowych węzłów, pojawiał się węzeł customowy, w który można było wrzucić kawałek kodu. Ten kod oczywiście można byłoby tam umieścić, ale pojawia się pytanie – po co mi to narzędzie, jeżeli wrzucanie tego kodu znacząco komplikuje mi życie? Bo ten kod to nie tylko sam kod. Trzeba go wersjonować, debugować, testować, gdzieś zapisywać, mieć wgląd w to, jaki kod aktualnie posiadam, kto go zmienił, jak go zmienił, co dokładnie zmienił, kto napisał jakiś komentarz. Jeśli chodzi o oprogramowanie, wytworzyły się pewne praktyki i standardy, jak to można zrobić. Kiedy wrzucamy to jako kawałek kodu, kawałek tekstu dosłownie, totalnie tracimy kontrolę nad tym. To jest bardzo niefajna sytuacja i bardzo nie chcielibyśmy tam być. Dlatego, podsumowując, ja osobiście nie wierzę w no-code. Owszem, można robić fajne prototypy, ale według mnie nie tędy droga.
Z drugiej strony warto też dodać inną rzecz. Patrząc na ludzi z biznesu, czasem faktycznie mogą mieć wrażenie, że nie potrafią przeczytać kodu lub go zinterpretować. I faktycznie są trudności z czytaniem długiego kodu. Natomiast z mojego osobistego doświadczenia, kiedy przekazuje się biznesowi pewną prostą strukturę w postaci kodu, na przykład Pythona, i tłumaczy, że tutaj jest nazwa pliku, który chcesz użyć, tutaj parametry, na co masz wpływ – to całkiem fajnie się odnajdują. Ludzie z biznesu też całkiem dobrze radzą sobie na przykład z Excelem, więc ja osobiście nie dostrzegałem jakichś dużych problemów. Według mnie nawet ludzie z biznesu, mając taką prostą strukturę w postaci kodu, poczują tę elastyczność, którą mogą wykorzystać, aby osiągnąć cele ważne dla biznesu.
Druga ważna rzecz to fakt, że czasem kod może być dłuższy – powiedzmy 10, 15 czy 50 linii – i ktoś, kto nie zajmuje się tym na co dzień, może się w tym pogubić. Ale teraz żyjemy w świecie, w którym mamy dostęp do modeli LLM (Large Language Models). Możesz po prostu wrzucić kawałek kodu do pierwszego lepszego modelu LLM i poprosić o zmianę czegoś, dodanie czegoś lub cokolwiek innego. Pojawi się nowy kawałek kodu. Można zapytać, czy nie łatwiej byłoby poklikać. Być może na szybko byłoby łatwiej. Natomiast jeśli mówimy o rozwiązaniach, którym chcemy zaufać, które mają być stabilne i tak dalej, to jednak lepiej iść w stronę kodu. Zawsze może być taki kompromis, że jedna osoba koduje, a druga wykorzystuje. Nie mówię, że ludzie z biznesu mają zawsze pisać kod. Natomiast mam wrażenie, że często występują ekstremalne sytuacje, gdzie uważa się, że ludzie z biznesu nie potrafią zmienić kilku linii kodu, i dlatego tworzy się narzędzie, które znacząco ogranicza biznes. Według mnie to jest nieefektywne przede wszystkim dla biznesu.
Kończąc moje rozważania, dochodzę do wniosku, że żyjemy w czasach, kiedy tworzenie kodu stało się jeszcze prostsze niż kiedykolwiek, a będąc na poziomie kodu, jesteś zdecydowanie bardziej elastyczny i możesz osiągnąć znacznie więcej rzeczy.
Dobrze, a teraz jeszcze jedno kluczowe założenie w ramach rozumienia całego świata LLM. LLM, jak już mówiłem w poprzednich odcinkach podcastu, to nadal ML, czyli machine learning. Myślenie specjalisty od ML jest inne niż myślenie, powiedzmy, osoby z IT, takiej jak programista, inżynier czy menedżer. Dlaczego jest inne? Obserwuję teraz dużą różnicę, gdy osoby, które potrafią użyć konkretnej biblioteki, dołączyły do świata LLM rok temu czy dwa lata temu. Z jednej strony mają poczucie, że już pewne rzeczy potrafią wykorzystać, ale tracą tę subtelną, choć bardzo istotną granicę, że ML działa inaczej. Chodzi o to, że ML to przede wszystkim jest temat nieprzewidywalności. W ML – i to warto zapamiętać – zawsze popełnia się błędy. Nie ma ani jednego ML, który nie popełnia błędów. ML to zawsze zarządzanie niepewnością.
W praktyce oznacza to, że każdy model, który wdrożysz na produkcję, również popełnia błędy. Pytanie tylko, kiedy i jak duże. Oczywiście zawsze możemy zadać sobie pytanie, o ile błąd kosztuje znacząco, i wtedy pracujemy nad tym, żeby maksymalnie go zminimalizować. To będzie kosztować nas więcej wysiłku, który musimy włożyć w zarządzanie i minimalizowanie tego błędu. Albo możemy pójść w drugą stronę, w zależności od problemu. Natomiast ML zawsze popełnia błędy, to jest ważne. LLM jest częścią ML. Więc oczekiwania, że LLM będzie jednoznacznie przewidywalny, to jest popełnianie fundamentalnego błędu, które polega na tym, że jakby odklejamy się od rzeczywistości. Rzeczywistość jest taka, że LLM, podobnie jak ML, będzie nieprzewidywalny – to jest jego natura i tym trzeba zarządzać.
I teraz ten mindset, tak to się modnie mówi, albo ten sposób myślenia, trzeba tak przedstawić, aby wziąć pod uwagę naturę tego naszego komponentu, bo LLM to jest takie narzędzie właściwie, nie? Z drugiej strony zacząć to wykorzystywać w taki sposób, abyśmy mogli z tego czerpać wartość. To jest ważne złożenie.
No i dobra, i teraz taki prosty algorytm, jeżeli chodzi o to, co ja bym zrobił na twoim miejscu, gdybym chciał podejść do tematu LLM w sposób praktyczny. Też potem poczytam różne pytania, które tutaj zebrałem. Zresztą te pytania można było na początek przeczytać, bo to też pomaga pobudzić taką pełną wyobraźnię. Pytania, które zbieram od różnych osób w ramach społeczności Data Workshop, partnerów, i ludzie tutaj piszą, z czym mają na przykład największe doświadczenie. Takich kilka, było tam sporo tych tematów, ale zebrałem takich kilka przykładowych, jeżeli chodzi o grupy, żeby też wyczuć i też być może zrezonuje to z twoją perspektywą.
Więc tak, to co ludzie do mnie pisali. Czyli jakie były największe wyzwania na ten moment związane z LLM? To tak: brak świadomości, jakie są realne możliwości do osiągnięcia z wykorzystaniem LLM. Kolejne: odpowiednie dobranie narzędzia do projektu. Albo kolejne takie: Zrozumienie, o co w tym wszystkim chodzi od środka, samo pisanie promptów mnie już nie bawi. Właśnie to jest ten moment, kiedy pewne rzeczy się ustabilizowały, już ta magia pomału osiada i chcemy twardo stąpać po ziemi i wykorzystywać tę technologię.
Kolejna rzecz: jestem zakłopotany mnogością różnych rozwiązań i dynamiką rozwoju tej technologii. Ciężko się zdecydować, jak ją wybrać w przyszłych projektach. To bardziej takie już na temat pewnych decyzji na poziomie zespołu, firmy. I teraz takich kilka konkretnych pytań. Widać, że osoba jest bardziej zaawansowana. Jak zapewnić, że generowana odpowiedź przez LLM będzie wiarygodna i powtarzalna? Ponieważ na jej podstawie będę podejmować bardzo ważne decyzje inwestycyjne.
Jak wygląda mapa wiedzy? Mapa wiedzy to jest temat, który ja już wspomniałem. O tym chcę uczyć. To jest taka pewna koncepcja. Będę o tym szczegółowo rozmawiać. Widzę, że ta osoba już słyszała o tym albo w odcinku podcastu, albo też czasem wspominałem w moim newsletterze regularnie o tym. Więc jak wygląda mapa wiedzy i jak w praktyce ją zastosować zamiast RAG z embeddingiem, aby zwiększyć ROI lub precyzję odpowiedzi z LLM? Jakie mechanizmy wprowadzić, aby od samego początku ładowania danych, sprawdzenia ich poprawności i jakości do samego końca wygenerowania odpowiedzi, renderowania jej na UI, wykorzystywania przez użytkownika, kontrolować transformację danych?
Kontrolować, ważne słowo, kontrolować transformację danych i zrozumieć, co ma wpływ na generowanie odpowiedzi przez LLM. Czy obecnie możemy i warto budować rozwiązania wieloagentowe? Super pytanie, że to wybrzmiało, czy nadal ta technologia jest niedojrzała i w praktyce jakie odpowiedzialne zadania można powierzyć LLM i agentom. Super, że to wybrzmiało, bo teraz kolejny trend, który się podnosi, podobnie jak dwa lata temu to były takie tematy związane z ChatGPT, to teraz te agenty po prostu stają się coraz bardziej popularne.
Mam takie wrażenie, że znowu historia zatacza koło i pewne rzeczy, które wytworzyły się związane z Langchain, to teraz się kopiują w kierunku agentów. Trochę do tego się odniosę, w skrócie powiem w ten sposób, że popularne biblioteki, które teraz promują agenty, są super fajne, jeżeli chodzi o zrobienie efektu wow i prototypu. Natomiast ja osobiście większości tych popularnych frameworków i bibliotek, które tam są, nie wdrażam na produkcję. Nie dlatego, że biblioteki to w ogóle trutkarze na rzeczy. Przede wszystkim te biblioteki nie skupiają się na rzeczach najważniejszych i jeżeli na tym się nie skupisz, to samo to się nie zrobi. Z czym są te rzeczy najważniejsze? Będę dzisiaj jeszcze mówić, więc tutaj słuchaj dalej.
Tak, jeszcze kilka kolejnych punktów, nie będę czytać wszystkich, bo tam jest kilkaset pewnie wszystkich odpowiedzi, ale wytworzę kontekst, taki kontekst, żeby za chwilę też było lepiej zrozumiała ta struktura, o której będę mówić. Zrozumienie zasad, które sprawiają, że dany model LLM jest lepszy od drugiego i wyjaśnienie, dlaczego tak się dzieje. Wykorzystanie LLM-ów w najlepszych dla nich miejscach, aby nie strzelać do wróbli armatą. Czy i kiedy warto poświęcać czas na LLM-owe eksperymenty, np. prompting i podobne, jakie modele użyć, do jakich zadań najlepiej się spiszą, retrieval, classification, a może przygotowanie zbiorów treningowych dla innych modeli. Zwróć uwagę, to jest bardzo fajne też pytanie, że LLM być może nie wszędzie jest ważne, być może da się użyć starszych, prostszych modeli i w tej interakcji to będzie lepsze.
I też druga rzecz na temat weryfikacji jakości. Tu zresztą jest nawet kontynuacja. W jaki sposób wdrożyć je efektywnie na produkcję i jak zapewnić stabilność rozwiązań offline with human, czyli weryfikację z człowiekiem, versus online, czyli jak wdrożymy to na produkcję, jak upewnić się, że jak to sprawdziliśmy, to faktycznie będzie wystarczające, żeby tym jechać na produkcję. Bardzo fajna sekcja tych pytań. I jeszcze kilka pytań o trochę innych rzeczach. To tak, po pierwsze bezpieczeństwo i kontrola nad danymi. Bez tego nawet nie ma możliwości rozpoczęcia pracy nad modelami, czyli tu się zwraca uwaga na bezpieczeństwo danych. No, dla biznesu to jest ważne. Dla wielu biznesów to jest w ogóle krytyczne, żeby te dane zostały tylko wyłącznie wewnątrz organizacji. Po drugie, stabilność działania i pewność odpowiedzi. Jeżeli modele będą halucynowały, to nikt nie będzie chciał tego używać, no bo nie będzie zaufania.
Po trzecie, sensowne stosowanie. To nie musi być kombajn do wszystkiego. Wystarczy, że będzie potrafić robić jedną rzecz dobrze. Czyli teraz nie chcemy zrobić super uniwersalnego rozwiązania, wystarczy, że będzie jedna. Po czwarte, wdrożenie, czyli jak wdrożyć i monitorować. Pracę modeli i asystenta. No, może do jeszcze jednej rzeczy przytom. Jak minimalizować koszty w zadaniach takich, jak optymalizacja promptów, ubudowanie grafu, entity resolution, graf wiedzy. Jak widzisz tutaj, w tych wyzwaniach, które docierali do mnie jeżeli chodzi o takie praktyczne LLM, wybrzmiają pewne grupy, które warto wziąć pod uwagę, kiedy my wdrażamy.
Ja w ogóle się cieszę, że to pytanie wybrzmiało, bo w mojej głowie podobne struktury były, tylko ja akurat jeszcze potrzebowałem mieć takie pewne potwierdzenie i też pewne struktury, jak ludzie o tym myślą. Też taka ciekawostka. Na przykład było wiele informacji zwrotnych, jak walczyć z halucynacjami. Czyli tutaj ludzie wiedzą, że tak się to nazywa, ale z drugiej strony, jak tam było takie kilka opcji, co chciałby się nauczyć, tam były między nimi struktury, mieć strukturowany input i output, czyli kontrolę na tym, co wpisujemy, co dostajemy, to już trochę mniej, zdecydowanie właściwie mniej osób wybrali ten punkt.
I ciekawostka polega na tym, że halucynacja to jest właśnie co i z tym trzeba walczyć, ale jak, to właśnie to sposób ustrukturyzowany, jeżeli chodzi o ten input i output. To oczywiście jest jedna z opcji, ale ta opcja naprawdę może znacząco wpłynąć na to, jak będziemy radzić sobie z taką niepewnością, nieterminizmem modelu LLM.
Ja od razu też powiem, że LLM z definicji jest nieterministyczny, więc nigdy nie zrobimy tak, żeby mieć stuprocentową kontrolę, ale chcemy w tym kierunku dążyć. No i teraz obiecałem, w jaki sposób ja osobiście popatrzę na twoje miejsce, jeżeli bym teraz dopiero zaczynał. Więc pierwsza rzecz, na którą zwróciłem uwagę, to nauczyć się rozmawiać z LLM poprzez API. Tak jak mówiłem, tutaj mówimy o kawałkach kodu, przy czym ten kod będzie naprawdę bardzo prosty, trywialnie prosty. Tam właściwie będą takie pewne struktury, pewne role. Na przykład są trzy takie najbardziej popularne role, które OpenAI wprowadzili. De facto stało się to standardem i to jest fajne. Takie role to user, assistant, system.
To, co jest ważne, jeżeli chodzi o to zrozumienie, jak rozmawiać, to poznać podstawę, czyli czym jest prompt, jakie są tam role. Dalej też, jak w ogóle wysyłać tego prompta i jakie są najważniejsze modele. Na początek wystarczyło poznać takie trzy rodziny od OpenAI, Anthropic i Gemini Pro od Google. Więc to byłoby fajne też poznać parametry, takie najważniejsze parametry, na co one wpływają i jakie masz takie punkty przesunięcia, żeby wpływać na wynik. Zaczynając od temperatury, jeszcze kilka innych bardziej przydatnych i to właściwie ci już pozwoli wykonywać pewne proste rzeczy, ale nawet tylko jak przerobisz tylko to, to już będzie pewna wartość. Na przykład jak masz różny tekst, to już możesz wyciągać pewną strukturę. Na przykład masz, nie wiem, umowę albo jakieś inne kawałki tekstowe, jakieś prawne dokumenty, albo jakieś wyniki pewne, nie wiem, z Jiry, albo tam jeszcze skądś takie dłuższe, dłuższe komentarze.
Już tylko wykorzystując to będziesz w stanie zrobić naprawdę całkiem fajne rzeczy. Nadal to jest troszkę bardziej sposób nie do końca taki przewidywalny, ale to jest taki krok pierwszy, który ja bym wykonał, czyli nauczyć się rozmawiać z LLM-em, wykorzystując API i poznać te trzy najważniejsze rodziny modeli i te role, które tam są pod spodem i struktura promptu na razie na poziomie tekstu, jak tym zarządzać. Krok drugi to jest taki kontrolowy flow, albo taka struktura na wejściu i struktura na wyjściu. I tutaj jest ciekawa historia. To jest trochę wspomniałem na początku tego podcastu. Jak mówiłem, że przedtem, gdy zajmowałem się ML-em, to dzieliłem się dobrymi praktykami.
Nawet specjalnie znalazłem jedną ze swoich prezentacji, to było ponad 11 lat temu, czy coś takiego, kiedy pisałem, znaczy robiłem taką prezentację kontraktów, design by contract. Kiedy idea polegała na tym, że jak mamy kawałki kodu, to w tym kodzie mamy wejście i wyjście i zakładamy tam takimi warunkami, czyli co musi być spełnione na wejściu, co musi być spełnione na wyjściu, ewentualnie co ma się wydarzyć w środku tej funkcji. I to wszystko było po to, aby upewnić się, że jest taka stabilność, jeżeli chodzi o to nasze oprogramowanie. Zresztą tam między innymi twórcą tego konceptu był Bertrand Meyer i on już stworzył taki język o nazwie Eiffel, jak ta wieża Eiffel. Chociaż ten język powstał wcześniej niż ja się urodziłem, ale między innymi on, ten język nie stał się zbyt popularny, ale między innymi tym językiem się też inspirowali i C# i Java.
Pewne rzeczy stąd były wzięte. Wiadomo, to była taka inspiracja, to nie były wprost kopiowane. Między innymi kontrakty wprost nie są dostępne i w C# i Java, ale pewne komponenty albo biblioteki zostały tam przygotowane. I też taka ciekawostka, która mi się przypomniała, bo jest taka dokumentacja, która nazywa się „How to Write Correct Programs and Know It” (Jak pisać poprawne programy i wiedzieć o tym), która powstała, właśnie, kiedy powstała, to może powiem na koniec, która napisała właśnie Harland Hills i ja tu tak przygotowałem takie punkty, takie streszczenie, o czym tam było napisane. Teraz ja to przeczytam na szybko, bo to dotyczyło tworzenia dobrego oprogramowania, czyli programu, któremu można będzie zaufać. I tam było tak. Na przykład pierwszy punkt. Znaczy takie streszczenie, które z tego można było powiedzieć. Poprawny kod od początku. To jest naszym celem. Czyli zamiast skupić się na eliminacji błędów podczas debugowania, dąży do pisania kodu, który jest poprawny już w momencie tworzenia.
Programista jest odpowiedzialny za błędy. To jest kolejny punkt. Błędy, które pojawiają się w kodzie nie są samoistne, oni tam się nie pojawiają, to programiści wprowadzają je podczas pisania kodu, dlatego tak ważne jest świadome i precyzyjne programowanie. Kolejny punkt ważny. Nie ma gwarancji absolutnej poprawności. To jest w ogóle też ciekawa rzecz, pod tym względem, że w ML-ach to jest znacznie bardziej jeszcze taki silniejszy problem, że nie ma tej gwarancji, ale nawet w klasycznym programowaniu to jest problem. Więc nie istnieją metody, które dałyby ci stuprocentową pewność, że program jest całkowicie wolny od błędów, nawet formalne dowody poprawności mają swoje ograniczenia.
Budowanie zaufania do kodu w dobie LLM
W dobie rosnącej popularności dużych modeli językowych (LLM) łatwo ulec iluzji, że potrafią one rozwiązać każdy problem za nas. Zamiast ślepo ufać tym narzędziom, powinniśmy skupić się na budowaniu zaufania do kodu, który tworzymy z ich pomocą. Niezwykle ważne jest, aby dokładnie analizować i weryfikować logiczne działanie każdego fragmentu kodu wygenerowanego przez LLM. Nie traktujmy ich jak czarnych skrzynek, których działania nie rozumiemy.
Istotne jest, aby testować działanie programu w różnych scenariuszach, z różnymi danymi wejściowymi. Obserwujmy program w działaniu i reagujmy na ewentualne problemy. Warto stosować techniki programowania strukturalnego, takie jak „dziel i rządź”, aby rozbijać złożone problemy na mniejsze, łatwiejsze do ogarnięcia podproblemy. Weryfikujmy każdy krok i zadawajmy sobie pytania kontrolne podczas pisania kodu, aby upewnić się, że każdy fragment realizuje zamierzoną funkcję.
Pamiętajmy również o precyzji w składni i logice. Unikajmy błędów kompilacji oraz błędów wykonania programu. Chociaż LLM mają inną naturę niż tradycyjne języki programowania, to zasady tworzenia dobrego oprogramowania pozostają aktualne. Jeśli chcemy wdrażać rozwiązania oparte o LLM na produkcję i brać za nie odpowiedzialność, musimy podejść do tematu w sposób przemyślany i ustrukturyzowany.
Struktura i kontrola w pracy z LLM
W przypadku LLM kluczowe znaczenie ma narzucenie struktury na wejście i wyjście danych. Zamiast pisać prompty w sposób nieustrukturyzowany, powinniśmy dążyć do tworzenia precyzyjnych schematów definiujących, jakie dane dostarczamy na wejściu i czego oczekujemy na wyjściu. Dobrym przykładem takiej struktury jest format JSON, który pozwala na jednoznaczne przekazywanie informacji do modelu.
Warto również korzystać z koncepcji „structured output”, spopularyzowanej przez OpenAI. Pozwala ona na uzyskanie wyników od LLM w predefiniowanej strukturze, co ułatwia ich dalsze przetwarzanie. Ważne jest jednak, aby pamiętać, że nawet przy zastosowaniu strukturyzacji, LLM nadal mogą popełniać błędy.
Dlatego niezbędne jest stosowanie walidatorów, które sprawdzą, czy wyniki generowane przez model spełniają nasze oczekiwania. Możemy tu odwołać się do koncepcji „design by contract” znanej z tradycyjnego programowania. Definiując warunki wejścia i wyjścia dla naszego modelu, tworzymy „kontrakt”, którego spełnienie gwarantuje poprawność działania.
W przypadku wykrycia błędu, możemy zastosować mechanizmy automatycznej lub półautomatycznej naprawy. W praktyce okazuje się, że ponowne uruchomienie modelu z tymi samymi danymi często rozwiązuje problem. Dzięki takiemu podejściu możemy zminimalizować liczbę błędów i zwiększyć nasze zaufanie do wyników generowanych przez LLM.
Leaderboardy a rzeczywiste problemy
Leaderboardy, takie jak Arena Leaderboard, pozwalają porównywać różne modele LLM w oparciu o oceny użytkowników. Choć stanowią one cenne źródło informacji, należy pamiętać, że oceniają one modele w sposób uniwersalny, podczas gdy w praktyce mamy do czynienia z konkretnymi problemami.
Dlatego tak ważne jest, aby podczas pracy z LLM skupić się na weryfikacji i walidacji każdego etapu procesu. Zamiast oceniać jedynie końcowy rezultat, powinniśmy sprawdzać poprawność działania poszczególnych komponentów. W przypadku aplikacji typu RAG (Retrieval Augmented Generation) osobno powinniśmy oceniać jakość wyszukiwania kontekstu i dopiero w dalszej kolejności jakość generowanych odpowiedzi.
Pamiętajmy, że to my definiujemy, co jest dla nas ważne i jakie problemy chcemy rozwiązać. Dlatego warto tworzyć własne leaderboardy, które będą odzwierciedlać specyfikę naszych zastosowań.
Od prototypu do produkcji: Kluczowe kroki wdrażania LLM
Chcąc zbudować funkcjonalne rozwiązanie oparte o LLM, nie wystarczy jedynie stworzyć prototyp. Potrzebne jest podejście systemowe, uwzględniające specyfikę uczenia maszynowego i skalowalność rozwiązania.
Kluczowym elementem jest tworzenie leaderboardów, które pozwolą na automatyczną weryfikację wyników. W uczeniu maszynowym nie ma gotowych recept – sprawdzanie i eksperymentowanie to podstawa. Leaderboardy dają możliwość porównania wyników setek, a nawet tysięcy eksperymentów i wybór najlepszego rozwiązania. Automatyzacja tego procesu jest kluczowa ze względu na skalowalność i eliminację subiektywnych ocen.
Kolejnym krokiem jest wykorzystanie koncepcji RAG (Retrieval Augmented Generation), czyli wzbogacania generowania tekstu o wyszukiwanie informacji. Istotne jest jednak, aby nie ograniczać się jedynie do baz wektorowych. Kluczowe znaczenie ma sposób wyszukiwania, układania i finalnego prezentowania danych. Niewłaściwe chunkowanie tekstu może prowadzić do nieprzewidywalnego zachowania LLM, dlatego warto zadbać o spójność i logiczny podział informacji.
Ciekawym rozwiązaniem jest również wprowadzenie checklist, łączących elementy CoT (Chain of Thought), strukturyzowanego inputu i outputu. Takie podejście pozwala na zadawanie pytań, które stymulują LLM do logicznego myślenia i wyciągania wniosków. Ważne jest, aby pamiętać, że LLM nie jest wszechwiedzący i wymaga odpowiedniego ukierunkowania, podobnie jak w przypadku coachingu.
Kolejnym krokiem jest stworzenie tzw. „mapy wiedzy”, będącej zbiorem procesów opisanych w sposób zrozumiały dla człowieka. W odróżnieniu od często mylonego z nią grafu wiedzy, mapa wiedzy pozwala na łatwe audytowanie, modyfikowanie i nawigowanie po informacjach zarówno przez człowieka, jak i LLM. Należy jednak pamiętać, że samo użycie gotowych rozwiązań do tworzenia grafów wiedzy nie gwarantuje sukcesu – kluczowa jest spójność i wartość merytoryczna tak zbudowanej reprezentacji.
Nie należy zapominać o integracji LLM z klasycznym uczeniem maszynowym (ML). Chociaż LLM zyskują na popularności, klasyczne ML nadal ma wiele do zaoferowania, szczególnie w obszarze analizy danych tabelarycznych. Zamiast postrzegać te dwa podejścia jako konkurencyjne, warto je połączyć. LLM może na przykład etykietować dane dla klasycznego modelu ML, pełnić rolę interfejsu dla klasycznego ML lub tłumaczyć decyzje podjęte przez klasyczny model na zrozumiały dla człowieka język.
Ostatnim elementem układanki są zaawansowane techniki promptowania. Zamiast kosztownego i skomplikowanego fine-tuningu, warto skupić się na optymalizacji promptu. Możliwe jest automatyczne dostosowywanie promptu z wykorzystaniem narzędzi ML, co pozwala na uzyskanie lepszych wyników. Co więcej, takie podejście pozwala na wykorzystanie potencjału zamkniętych modeli LLM (np. od OpenAI) do optymalizacji promptu, bez konieczności udostępniania im wrażliwych danych.
Wdrożenie LLM do produkcji to złożony proces, wymagający przemyślanej strategii i połączenia różnych technik. Kluczem do sukcesu jest zrozumienie zarówno mocnych, jak i słabych stron LLM oraz umiejętne wykorzystanie ich potencjału w połączeniu z innymi narzędziami i technikami.
Jak zapanować nad armią baranów 🙂
Wdrażanie modeli LLM na produkcję to nie lada wyzwanie. Wymaga nie tylko zrozumienia ich możliwości, ale także umiejętności monitorowania, analizy i zarządzania niepewnością.
Kluczowe jest zapewnienie transparentności procesu, czyli możliwość śledzenia poszczególnych kroków działania modelu, analizy zależności i odtwarzania decyzji. Szczególnie ważne staje się to w przypadku wykorzystywania modeli lokalnych, które są niezbędne przy pracy z danymi wrażliwymi.
Chociaż otwarte modele LLM często ustępują wydajnością zamkniętym rozwiązaniom, to ich dynamiczny rozwój pozwala przypuszczać, że z czasem ta różnica będzie się zmniejszać. Warto śledzić te trendy i wybierać rozwiązania najlepiej dopasowane do naszych potrzeb.
Właśnie ta praktyczna wiedza i umiejętność łączenia różnych elementów układanki LLM jest kluczem do sukcesu. Zamiast skupiać się na skomplikowanych technikach fine-tuningu, warto postawić na zrozumienie podstaw, optymalizację promptu i integrację z klasycznym ML.
Takie holistyczne podejście do LLM będzie również podstawą mojego kursu „Praktyczny LLM”, który już wkrótce ujrzy światło dzienne. Chcę w nim przekazać wiedzę i umiejętności niezbędne do efektywnego wykorzystania LLM w praktyce, budując pomost pomiędzy światem programowania a możliwościami, jakie oferują te modele.
Na koniec chciałbym zostawić Cię z pewną analogią, która pomoże zrozumieć, jak skutecznie zarządzać LLM. Napoleon Bonaparte mawiał: „Armia baranów, której przewodzi lew, jest lepsza niż armia lwów prowadzona przez barana.”
LLM to potężne narzędzia, ale bez odpowiedniego lidera, który wyznaczy im cel, strukturę i procesy, pozostaną jedynie chaotyczną siłą. To od Ciebie zależy, czy uda Ci się okiełznać ich potencjał i wykorzystać go do osiągnięcia swoich celów.
Pamiętaj, że dane są kluczowe, proste rozwiązania często bywają najlepsze, a ciągłe uczenie się i adaptacja to podstawa sukcesu w świecie LLM.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.

