
Naukowiec Computer Vision z DeepMind – Mateusz Malinowski

Gartner opublikowała tak zwany hype cycle 2017, po polsku pewnie to brzmi jako cykl szumu albo cykl dojrzałości technologii. Hype cycle został wymyślony przez Gartner w 1995 roku i składa się z pięciu faz: najpierw pierwsze informacje na temat technologii, druga faza to dużo szumu i wielkie oczekiwania, trzecia faza rozczarowania, bo wykrywają się pewne ograniczenia, czwarta faza naprawa tych ograniczeń i znów oczekiwania. Piąta i ostatnia faza stabilizacja. Mówi się, że wtedy technologia dojrzała i oczekiwania są połączone z możliwościami.
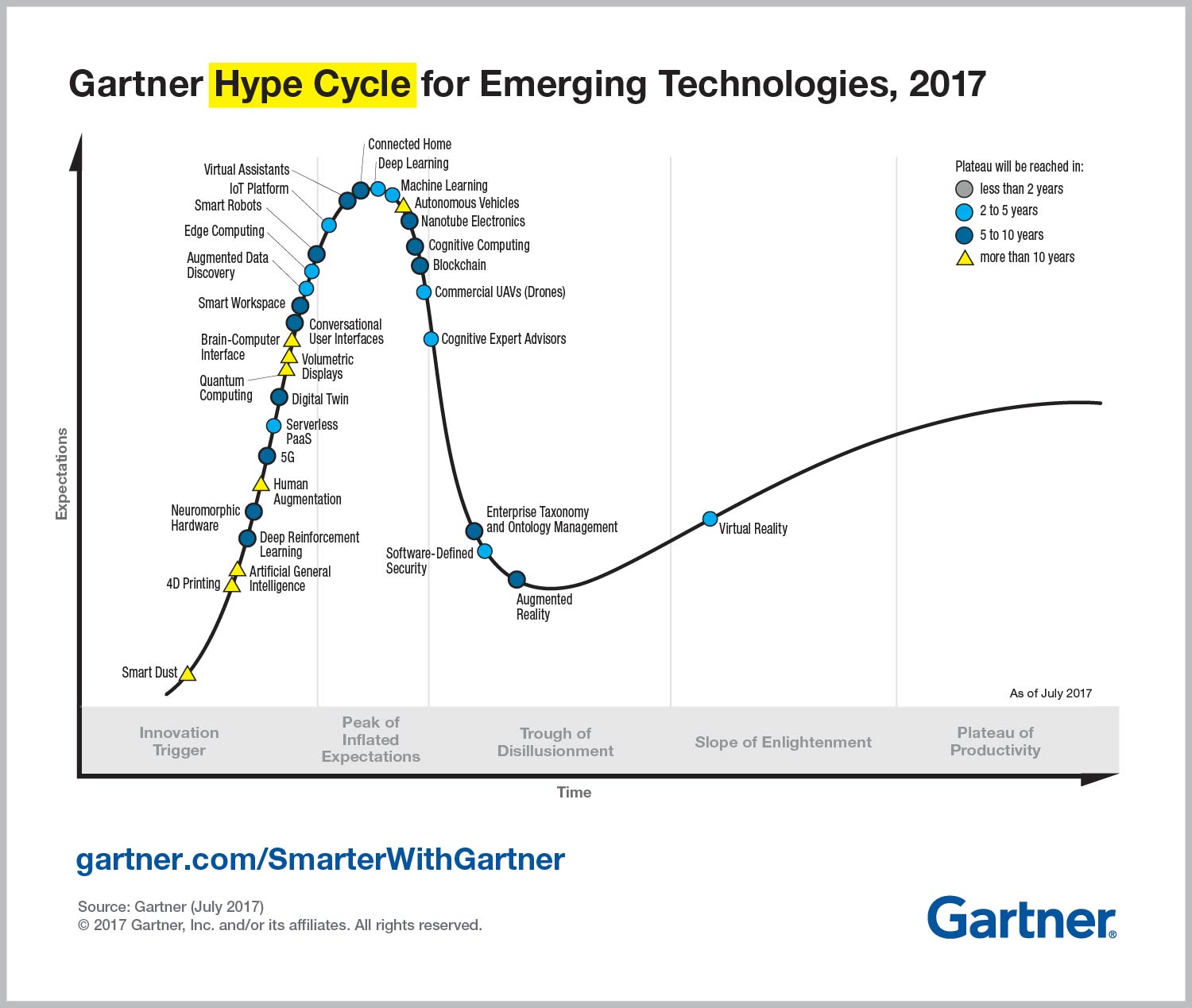
Dla przykładu, na samym początku, czyli w fazie jeden jest tak zwany smartdust, po polsku to zabrzmi jako “inteligentny kurz”. W dużym uproszczeniu, wobraź sobie ziarno piasku, a teraz pomyśl, że tam jest mini-procesor, bateria i sensory. Bateria jest ładowana poprzez słońce lub inne naturalne źródła energie. Takie cząstki mogą robić wiele różnych rzeczy, obserwować otoczenia, mierzyć różne parametry i nawet szpiegować. Stanisław Lem, jeszcze w roku 1964, pisał w “Niezwyciężony” podobną wizję. Teraz o tym mało się mówi, ale wiele się robi w miejscach, o których też mało się mówi :).
Dla przykładu. Pamiętasz o swoich uczuciach kilka czy kilkanaście lat temu, kiedy po raz pierwszy wyszedł w publiczność ekran dotykowy. Wtedy to zrobiło wrażenie. Natomiast jest stosunkowa stara technologia, która już była znana co najmniej w latach 70-tych. ubiegłego stulecia. Podobnie do smartdust jest 4D printing, który też jest w pierwszej fazie. Jednym słowem 4D printing można wytłumaczyć jako – “transformer”. Wyobraź sobie, że został wydrukowany jakiś obiekt, który może transformować w inny obiekt z czasem. To ma wiele obszarów zastosowań w biznesie. Ale temat rzeka, podziel się swoją opinią czy chcesz więcej dowiedzieć się na temat technologii przyszłości jak smartdust lub 4D Printing?
Wracając do cyklu dojrzałości (hype cycle). Zwykle technologia przesuwa się w czasie od lewej strony do prawej, czyli od fazy numer 1 do fazy numer 5. Dla każdej technologii to potrzebuję różną ilość czasu od kilka lat do 10 (czy nawet więcej). Machine learning po raz pierwszy pojawił się w cyklu dojrzałości 3 lata temu (przed tym były tematy powiązane takie jak data science lub bigdata). Przez trzy lata (włączając rok 2017) machine learning jest cały czas jest w fazie numer 2 (czyli dużo szumu). Ciekawostką jest, że 3 lata temu machine learning był bliżej fazy trzeciej niż w roku 2017.
A co to oznacza w praktyce? Kilka wniosków. To, że jesteśmy na etapie, kiedy ilość szumu rośnie. Temat jest bardzo nagrzany i zawiera sporo magii. Kolejny wniosek jest taki, że oczekiwania rosną znacznie szybciej niż biznes jest gotów je wykorzystać. Stąd płynie kolejny wniosek, że po fazie drugiej jest faza trzecia – czyli rozczarowania wynikające z błędnego rozumienia możliwości. Postaram się pomóc Ci przejść z fazy drugiej w fazę trzecią z najmniejszą stratą jak materialną tak i moralną i przygotuję na to osobny odcinek. Już mam kilka pomysłów jak to można zrobić, ale chętnie posłucham Twoje przemyślenia na ten temat.
Naukowiec Computer Vision
Gościem dzisiejszego odcinku jest naukowiec z DeepMind – Mateusz Malinowski. W drugim odcinku podcastu już wspomniałem o turing test, również o tym rozmawialiśmy w innych odcinkach podcastu, np. w 10-ym z Aleksandrą Przegalińską. Natomiast Mateusz kilka lat temu zdefiniował Visual Turing Test, który nabiera coraz większą popularność i ważność.

DeepMind i AlphaGo
Kilka słów o DeepMind. To jest brytyjska firma zajmująca się sztuczną inteligencją założona w roku 2010. Która za 4 lata została przyjęta przez Google za 500 mln. dolarów. Firma stała się bardzo znana ze swoich osiągnięć gry w Go. DeepMind zaimplementował gracza o nazwie AlphaGo i bardzo głośnie po wygranej Lee Sedola w marcu 2016.
Lee Sedol w roku 2003 zwiększył swój ranking z 4 danu do 9 danu (najwyższy). Nie ma jednego rankingu gry w Go, ale zgodnie z jednym z nich na moment gry Lee Sedol zajmował 4-tą pozycję w świecie. Już w tym roku, czyli w maju 2017 odbyła się gra Ke Jie. To jest Chińczyk, który ma teraz 20 lat i który zajmuje pozycję numer 1 przez ostatnie trzy lata. Ale AlphaGo wygrało Kei Jie. Po tym wydarzeniu CEO DeepMind, Demis Hassabis powiedział, że AlphaGo może teraz wyjść na emeryturę, bo cel został osiągnięty, a zespół, który nad tym pracował będzie robił inne projekty.
Wyzwania sztucznej inteligencji
AlphaGo naprawdę zrobiło ogromne wrażenie i już wydaje się, że sztuczna inteligencja staje się coraz bardziej mocniejsza. A w tym czasie nadal są problemy które dla sztucznej inteligencji są bardzo trudne. Między innymi znane jako paradoks Moraveca. Jak mówił jeszcze Marvin Minsky:

Generalnie, najmniej jesteśmy świadomi tych rzeczy, które nasze umysły robią najlepiej. Jesteśmy bardziej świadomi prostych procesów, które nie działają dobrze, niż złożonych procesów, które działają bezbłędnie.
No właśnie i taki jeden z przykładów, gdzie sztuczna inteligencja wygląda albo wyglądała bardzo słabo to rozumienie relacji. Prosty przykład. Jest stół gdzie stoi szklanka wody, kubek i talerz. Każdy z nich ma położenie, materiał, z którego zbudowany i kształt.
Załóżmy talerz stoi za kubkiem. Jeżeli zapytam dziecko, które ma kilka lat lub mniej: “Co jest za kubkiem?”. Odpowiedź będzie — talerz. Dla nas to zadanie brzmi absurdalnie proste, ale jest bardzo trudne dla maszyny. Rozumienie, takich rzeczy przez maszyny jest koniecznie dla zbudowanie mocnej sztucznej inteligencji i dlatego między innymi DeepMind pracuję nad tym. Mateusz to jeden z naukowców, który pracuje nad tym problem. Zapytałem go, czy nadal to jest wyzwaniem i jakie są postępy. Mateusz powiedział:
Można powiedzieć, że było wyzwaniem. W celu takiego relacyjnego wnioskowania przez maszyny, stworzyliśmy moduł, który nazwaliśmy Relation Networks. Jest to sieć neuronowa, która rozważa dwa obiekty na obrazie, porównuje te obiekty ze sobą za pomocą kilku warstwowej sieci neuronowej, a następnie agreguje wszystkie te reprezentacje takich par w celu stworzenia jednej reprezentacji globalnej całego obrazu. Za pomocą tak zbudowanej sieci neuronowej otrzymaliśmy wyniki, które są w zasadzie lepsze niż ludzkie odpowiedzi.
Więcej o tym i innych tematach dowiesz się w naszej rozmowie.
Na samym końcu również powiem, jak możesz dostać bezpłatnie bilet na konferencję zorganizowaną przez Google. Google organizuję trzy konferencji GDD w roku, pierwsza, jak zwykle odbywa się w stanach (już była), druga w Europie (tym razem w Krakowie) i trzecia w Azji. Konferencja odbędzie się 5 i 6 września (oryginalny koszt biletu jest 250 dolarów).
Zapraszam do wysłuchania…
Cześć Mateusz, przedstaw się kim jesteś i co studiowałeś, gdzie pracujesz, gdzie mieszkasz?
Cześć Vladimir, nazywam się Mateusz Malinowski. Obecnie jestem naukowcem w DeepMind i pracuję nad uczeniem maszynowym, a w szczególności nad tak zwanym widzeniem maszynowym (po ang. computer vision). DeepMind jest placówka nukową, która jest związana z Google i która stała się słynna między innymi za sprawę wygraną w Go. Obecnie mieszkam w Londynie, studiowałem informatykę na Uniwersytecie Wrocławskim, ukończył magisterskie studia z informatyki na Uniwersytecie Saarlandskim w Niemczech, doktorat obroniłem z widzenia maszynowego w Instytucie Maxa Plancka.

Myślę że DeepMind faktycznie jest znaną firmą, o którą wiele razy wspominałem w podcaście i nie tylko. Jeszcze porozmawiamy o tym później. Co ciekawego ostatnio przeczytałeś i dlaczego to jest warte polecenia?
Przyznam szczerze, że głównie czytałem fachową literaturę. Aczkolwiek z tych artykułów, które ostatnio przeczytałem i które są w miarę przystępne, zaciekawiła mnie seria artykułów na trochę prowokujący temat “Czy neuronaukowcy potrafią zrozumieć mikroprocesorów” (Could a Neuroscientist Understand a Microprocessor? oraz Neuroscience Needs Behavior: Correcting a Reductionist Bias).
Zaciekawiły mnie głównie ze względu na to, że od pewnego czasu męczy mnie to, w jaki sposób powinniśmy podejść do budowania inteligentnych maszyn. Czy powinniśmy zastosować podejście redukcjonistyczne, gdzie tworzymy zrozumiały dla nas jakiś mały element, a potem te rzeczy skalujemy.
Czy może lepiej jest podejść od całkowicie odwrotnej strony, zastanowić się nad klasą problemów do rozwiązania, w pewnym sensie opisać czego oczekujemy od takiej inteligentnej maszyny w formie funkcjonalnej, a potem stworzyć metodę, która rozwiązuje tą klasę problemów.
O sztucznej inteligencji jest bardzo dużo mitów, dodatkowa jeszcze dziennikarze dolewają oliwy do ognia, można wspomnieć chociaż komentarz, o tym że Facebook wyłącza AI. Jesteś naukowcem, osobą która wie jak to jest z własnego doświadczenie. Mam nadzieje, że uda się nam trochę odczarować mity i pokazać praktyczne osiągnięcie oraz wyzwania. Najpierw co to jest tak zwana sztuczna inteligencja?
Czyli zaczynamy od podstaw. To prawda, że niektóre dziennikarze zamiast informować społeczeństwo, niepotrzebnie zaogniają sytuację poprzez takie interpretacje. Co do Twojego pytania, dla mnie sztuczna inteligencja jest dyscypliną, którą zadaniem jest stworzenie maszyn, będących na co najmniej ludzkim kognitywnym poziomie.
Oznacza to, że takie maszyny muszą organizować oraz interpretować różne nieustrukturyzowane sygnały i takie sygnały jak, na przykład, język, wizja na co najmniej ludzkim poziomie. Następnie, mając te sygnały, maszyny powinne w jakiś tam sposób reagować na nie i podejmować decyzje, biorąc pod uwagę sygnały wizyjne oraz językowe.
Teraz może będę miał trudność, jeżeli chodzi o terminologię, ale chcę zapytać o tak zwany Symbolic AI i Sub-Symbolic AI. Proszę wyjaśnij na przykładach co to jest i na czym polega różnica? Jakie mają wady i zalety?
Symboliczne AI i Subsymboliczne AI, to są dwa z pozoru odmienne podejścia do tworzenia, budowania inteligentnych maszyn. Historycznie rzecz biorąc symboliczne AI dominowało. A głównym produktem symbolicznego podejścia do AI są tak zwane systemy eksperckie. Symboliczne AI bazuje na hypotezie, że inteligencja to głównie przetwarzanie symboli.
W praktyce, osoba (nazwijmy tą osobę inżynierem AI) tworzy zbiór wiedzy, a także zbiór reguł, który przetwarzają tą wiedze na nową wiedzę. Tutaj dobrym przykładem jest sylogizm logiczny. Jeżeli wszyscy ludzi są śmiertelni (to jest nasza właśnie wiedza), Vladimir jest człowiekiem (to znów jest nasza wiedza), to Vladimir jest śmiertelny i to jest nasza nowa wedydukowana, albo stworzona na podstawie jakiś reguł, wiedza.
Jest sporo wyzwań, które stoją przed tworzeniem takich systemów, przede wszystkim skalowalność oraz pewna tolerancja na błędy. Na przykład, ciężko jest zebrać całą wiedzę świata w postacie formalnej, w takiej postaci która byłaby zrozumiała dla maszyny, podobnie ciężko jest stworzyć wszystkie reguły na których świat się opiera. Nasza wiedza, dotycząca wszystkich reguł jakimi człowiek się posługuje w języku angielskim, jest w najlepszym wypadku nie pewna, a być może nawet troszeczkę błędna.
Sytuacja jest dużo gorsza z mniej popularnymi oraz mniej zbadanymi językami, takimi jak na przykład język polski. Idąc dalej tym torem zapytajmy się czym jest kod, w jaki sposób formalnie opisać taki obiekt, jakim jest kod i tak dalej. To nie jest taka prosta sprawa. Ostatecznie, oprócz zgromadzenia oraz sformalizowania całej wiedzy, przetwarzanie symboliczne zgromadzonej wiedzy także jest ciężkim, wymagającym procesem z perspektywy obliczeń. Jeżeli chodzi o tolerancje, to te systemy mają często problemy, na przykład, jeżeli podana wiedza jest błędna.
Z drugiej strony subsymboliczne AI nastawia się raczej na takie rozmowy, bym powiedział, miękkie oraz bardziej indukcyjne. Tutaj przykładem są metody statystyczne oraz coraz bardziej popularne sieci neuronowe, a szczególnie głębokie uczenie maszynowe czyli deep learning. Z grubsza, szczególnie metody uczenia maszynowego polegają na stworzeniu ogromnych danych treningowych, mogą to być obrazki z oznaczoną kategorią.
Na przykład, obrazek, który przedstawia kota razem z kategorią że to jest kot, obrazek przedstawiający psa z kategorią że to jest pies. Następnie uczymy takie maszyny na podstawie takich danych treningowych. Może brzmi to trochę magicznie, ale cały ten proces ostatecznie można formalnie i ładnie opisać za pomocą matematyki. Można także myśleć, że takie systemy uczą się pewnych wzorców za pomocą których potrafią rozwiązywać problemy, które tym systemem zadaliśmy.
W pewnym sensie subsymboliczne AI jest przeciwieństwem tego symbolicznego AI i wiele z tych problemów, które wcześniej wymieniłem, tutaj nie istnieją. Pojawiają się za to nowe problemy, taki jak, na przykład, potrzeba zbudowania odpowiednich zbiorów treningowych. Tę modele też ciężej się interpretuje co jest dosyć oczywiste, ponieważ w symbolicznych metodach same wymyśliliśmy reguły, wobec tego wiemy czym te reguły są, co one znaczą.
Oba nurty można obrazowo podzielić ze względu na reprezentacje myśli. Symboliczne AI sądzi, że myśl ma reprezentacje symboliczną. Z drugiej strony, szczególnie nutr głębokiego uczenia maszynowego, sądzi że myśl jest wektorem aktywacji sztucznych neuronów. Jeżeli chodzi o przyszłość AI, to osobiście nie wierze, że systemy symboliczne były tu przyszłością.
Pewnie w zawęrzonych i dobrze zrozumiałych dziedzinach, takich jak, na przykład, pomóc przy naprawie komputera czy pomóc w naprawie samochodu, mogą się sprawdzać, ale wątpię żeby takie systemy uogolniały – skalowały się na świat w którym żyjemy. Widzę więcej nadziei w systemach subsymbolicznych, tak jak głębokie uczenie maszynowe, które ostatnio stało się bardzo popularne lub w systemach mieszanych, które łączą zalety obu podejść do AI.
Dałeś szerszą odpowiedź, fajnie. Chciałem tylko dodać o pierwszym przypadku Symbolic AI, problem który pamiętam, który jeszcze w latach 60h się pojawił – tak zwana eksplozja reguł, czyli tych reguł stało się tak dużo, i z każdym krokiem robiło się coraz więcej, przy czym nawet dla dla bardzo prostych problemów. Ale jak powiedziałeś, przyszłość leży gdzieś na wykorzystaniu Sub-symbolic i jednak trochę Symbolic AI.
Jesteś bardzo mocno zaangażowany w tak zwany “Machine perception”, “Computer Vision” i w szczególności “Visual Recognition” oraz “Visual Question Answering”? Będziemy dzisiaj zgłębiać ten temat, tylko zaczniemy od wyjaśnienia na prostych przykładach co to jest?
Machine perception – to jest dyscyplina, której zadaniem jest stworzenie maszyn, które interpretują i organizują docierające sygnały, jak, na przykład, dźwiękowe czy też wizyjne.
Computer vision czyli widzenie maszynowe – to jest dyscyplina, której celem jest stworzenie maszyn, które widzą świat w taki sposób jaki my widzimy, czyli trochę podobnie do machine perception, bo też chodzi o budowę maszyn które organizują i interpretują sygnały, ale są to sygnały głównie wizyjne.
Visual recognition – to jest podkategoria computer vision i sprowadza się w zasadzie do kategoryzacji obiektów ze zdjęć, na przykład, klasyfikacja zdjęć.

Visual Question Answering – to jest całkiem niedawno przedstawiona pod-dziedzina computer vision, która została najpierw zapoczątkowana przez Visual Turing Test podczas mojej pracy doktorskiej. Celem jest zbudowanie maszyn, które odpowiadają na pytania dotyczące świata wizyjnego, jak, na przykład, o to co się znajduje na obrazku lub o to co się znajduje na video.

Computer vision nie jest tak naprawdę nowym tematem. Już w latach 60-tych na MIT były pierwsze próby pracować z rozpoznawaniem obiektów na zdjęciu. To był stosunkowo prosty przypadek związany z rozpoznawaniem geometrii, a przede wszystkim krawędzi w 3D obiektach… Natomiast prawdziwy rozkwit computer vision nastąpił 5 lat temu. No właśnie co takiego się stało 2012 roku?
Tak, sporo się zmieniło między latami 60-mi i 2012 rokiem, jeżeli chodzi o computer vision. Tak jak powiedziałeś, w latach 60h eksperymenty były prowadzone na obrazach o stosunkowo małej złożoności, głównie to były idealne figury geometryczne z bardzo prostą semantyką. Przez semantykę tutaj mam na myśli że było kilka kategorii, takie jak stożki, szcześciany i tak dalej, i te kategorie są łatwe do odróżnienia.
Obecnie, w dzisiejszych czasach, prowadzimy eksperymenty na prawdziwych obrazach, czyli takich obrazach, które można zobaczyć na Facebooku, Flickerze i tak dalej. Tutaj złożoność takich obrazów jest znacznie większa i samo odseparowanie obiektów od tła jest większym wyzwaniem. Semantyka tych obrazów jest dużo bardziej skomplikowana, jest dużo więcej obiektów na takim obrazie, mamy dużo więcej kategorii. Samo pytanie czym jest obiekt jest także skomplikowane.
Na przykład, czy traktować człowieka jako całość, czy to jest kompozycja z jakichś części prostszych typu nogi, ręce i tak dalej, czy może człowiek czy ogólnie obiekty są bardziej zdefiniowane przez kontekst, przez otoczenie czy może to wszystko na raz. To jest dużo bardziej skomplikowany problem niż te problemy, które badaliśmy w latach 60h. I tak jak wspomniałeś, w latach 60h można było stworzyć systemy regułowe, które rozpoznawały to co się dzieje na obrazach, a w dzisiejszych czasach na prawdziwych obrazach to jest zajęcie bardzo ciężkie i prawdopodobnie nie możemy się zdawać na systemy regułowe.
A skoro pytasz o rok 2012, to w tym roku nastąpił przełom w rozpoznawaniu obiektów na obrazach. W największym ówcześnie konkursie na najlepszy system rozpoznający obiekty na obrazach tak zwane ImageNet, pewna metoda, która bazowała na konwolucyjnych sieciach neuronowych (po ang. convolutional networks) zdeklasowała pozostałe systemy o jakieś 10% i wygrała. I następujące rzeczy się zmieniły, tak to można podsumować.
Przeszliśmy od metod symbolicznych do metod subsymbolicznych, a dokładniej przeszliśmy do metod głębokiego uczenia maszynowego. Wytrenowaliśmy wspomniane metody na dużo większych zbiorach danych treningowych. Pojawianie się takich zbiorów treningowych jak właśnie ImageNet, który zbiera bardzo dużo obrazków jest kluczowe, żeby wytrenować maszyny, które rozpoznają obiekty na obrazach.
Rozwój sprzętu do gier komputerowych czyli karty graficzne także się przyczyniły rozwojowi AI. W szczególności umożliwiły one wytrenowanie głębokich sieci neuronowych na dużych zbiorach treningowych o których wspomniałem.
Technicznie jest to spowodowane tym, że sieci neuronowe dobrze się opisuje za pomocą operacji macierzowych, a te z kolei są także bardzo ważne w grach komputerowych, a za tym te operacje zostały dobrze zoptymalizowane w karty graficzne i przez to także są wykorzystywane do trenowania głębokich sieci neuronowych.
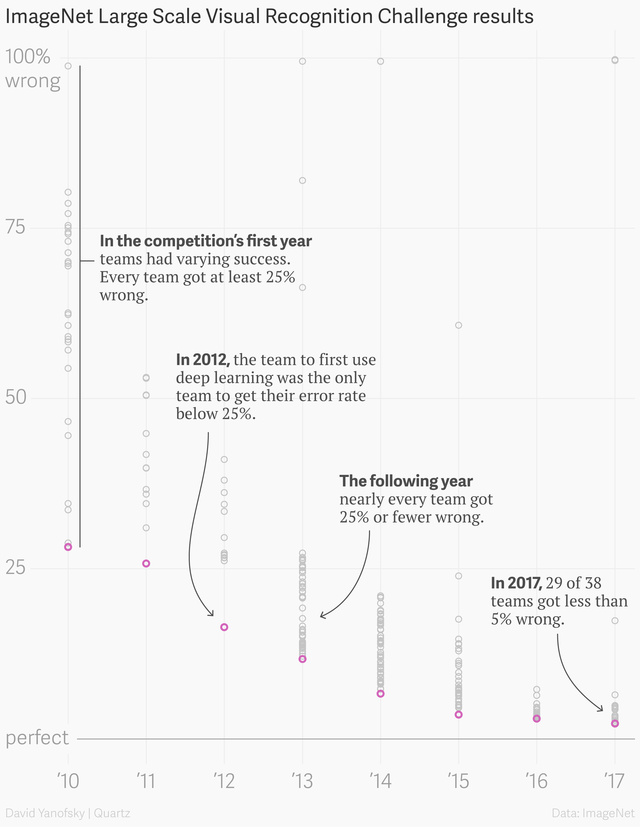
Zapytałem już o computer vision. Nieco podsumowując, wracają do konkursu ImageNet, czyli konkurs gdzie algorytm próbuje klasyfikować obiekty które są na zdjęciu. Ludzi robią to z dokładnością 95% innymi słowami błąd jest 5%.
Pokażę teraz dynamikę rozwoju. W roku 2010 (kiedy konkurs rozpoczął się) każdy z uczestników uzyskał wynik ponad 25% błędu, za 2 lata w słynnym roku 2012 najlepszy wynik był (AlexNet) już był 16%, trzy lata później, czyli 2015 udało się osiągnąć trochę mniej niż 5% (3.57% top 5 error) a w 2017 już 29 z 38 drużyn miał wynik mniej niż 5%. Postępy są gigantyczne. Powtórzę, że algorytm robię to lepiej niż ludzi (dla pewnych kategorii).
Pytanie analogiczne, ale będzie dotyczyło innego obszaru. A jak wyglądają postępy z przetwarzaniem i rozumieniem tekstu (NLP/NLU)?
Jeżeli chodzi o przetwarzanie języka naturalnego, to z tą dziedziną jestem dużo mniej zaznajomiony, więc nie mogę to tak ładnie podsumować. Ale z grubsza mogę powiedzieć , że obecnie wielu problemów z przetwarzania tekstu daje się rozwiązać za pomocą głębokiego uczenia maszynowego czyli za pomocą głębokich sieci neuronowych.
W pewnym sensie to jest bardzo fajne, bo, jak widzisz, podobne metody, które są stworzone do przetwarzania lub klasyfikacji obrazów także nadają się do przetwarzania lub klasyfikacji tekstu. Mamy w pewnym sensie unifikacje, czyli korzystamy z podobnych metod do rozwiązywania z pozoru odmiennych problemów.
Wracając do tematy, to tak zrbusza, ostatnio takie metody jak word2vec albo rekurencyjne sieci neuronowe, takie jak LSTM udowodniają swoją pozycję przy rozwiązywaniu pewnych problemów z przetwarzania języka naturalnego. Działają one bardzo dobrze na poziomie słów lub krótszych zdań. Te metody, a szczególnie rekurencyjne sieci neuronowe także wykorzystywałem w swojej prace doktorskiej.
O Turing Test już wspomniałem kilka razy w poprzednich odcinkach, ale proszę wyjaśnij czym jestem Visual Turing Test, jaki jest sens tego (albo inaczej, jakie jest zastosowanie, jakie potencjalnie problemy to może rozwiązać) i na koniec jaki jest postęp (zgodnie z estymacją kiedy będzie zaliczony)?
O tym mogę długo opowiadać. Visual Turing Test to jest problem, który zaproponowałem razem z moim opiekunem w czasie swojego pobytu na studiach doktorskich w Instytucie Maxa Plancka. Jest to problem, w którym maszyna dostaje zbiór pytań w języku naturalnym na temat danego obrazu. To mogą być pytania w stylu “ile jest krzeseł przy stole” albo “jaki przedmiot leży w kącie tego pokoju”.
Następnie maszyna, która dostaje takie pytanie, musi odpowiedzieć na nię, a my automatycznie sprawdzamy poprawność udzielonej odpowiedzi. Podsumowując można powiedzieć, że Visual Turing Test jest o tworzeniu takich maszyn, które jednocześnie rozumieją język naturalny, oraz widzenie (na przykład, rozumieją obrazy, zdjęcia, wideo). A to rozumienie mierzymy w sposób automatyczny przez porównanie otrzymanej odpowiedzi do odpowiedzi oczekiwanej.
Podczas pracy doktorskiej, nie tylko zaproponowałem taki test i opisałem kierunek jego rozwoju, także zaproponowałem konkretny zbiór danych DAQUAR, stworzyłem pierwsze metody, które odpowiadają na pytania o obrazy, jedną będącą połączeniem takiego symbolicznego AI z uczeniem maszynowym, a druga metoda, która już należy do nurtu subsymbolicznego (a dokładniej do głębokiego uczenia maszynowego).

Także zaproponowałem kilka metryk, które automatycznie sprawdzają jakość otrzymanych odpowiedzi. Problem okazał się z jednej strony bardzo trudny, a z drugiej – ciekawy, do tego stopnia, że wiele innych uniwersytetów, a także firm potwierdziły ten pomysł i kontynuują badania w tym kierunku.
Chciałbym opowiedzieć również o początkach Visual Turing Test, bo to jest dosyć istotne do zrozumienia. Problem ten powstał częściowo ze względu na moje niezadowolenie z postępów w tak zwanym image captioningu, gdzie zadaniem maszyny jest opisanie obrazu. Dużym problemem w image captioningu jest automatyczna ewaluacja (ocenianie jakości działania modelu) opisów wyprodukowanych przez maszynę.
Tutaj pojawia się problem: żeby automatycznie stwierdzić czy maszyna poprawnie opisała obraz, potrzebujemy innej maszyny, która rozumie i opis i obraz. Czyli mamy takie zapętlenie, aby sprawdzić czy maszyna rozumie problem musimy mieć maszynę, która już rozumie problem. W praktyce, oczywiście, korzysta się z jakichś tam heurystyk, ale wyniki ewaluacji nie zawsze są zgodne z naszymi intuicjami, a czasami ciężko się te metody interpretuje. A co byłoby, gdybyśmy zadawali bardziej skomplikowane pytania o to co się znajduje na obrazie, ale w taki sposób, aby dostać w miarę prostą odpowiedź.
Na przykład, jeżeli zadam pytanie “czy po mojej prawej stronie znajduję się szklanka”, z jednej strony wymagasz od systemu by ten zrozumiał obiekt szklanka, by zrozumiał pewne relacje w przestrzeni, by zrozumiał samo pytanie, ale sama odpowiedź jest już bardzo prosta – jest to “tak” albo “nie”. W praktyce okazało się, że ewaluacja nie jest aż taka prosta, ze względu na różne możliwości w interpretacji obrazu lub pytania, ale i tak te problemy są znacznie mniejsze niż w problemie image captioningu.
Kolejnym problemem tych metod, które opisują jest to, że jest im łatwiej oszukiwać, ze względu na to, że nie oczekujemy od takich metod niczego konkretnego, a jest wiele możliwych opisów tego samego obrazu (jedne są bardziej konkretne, inne – bardziej abstrakcyjne), a z dodatkowo pewną tendencją ludzi do antropomorfizacji powodują, że metody opisujące obraz, nie muszą być bardzo precyzyjne. Jeśli takie metody wykryją gdzieś żyrafy i opiszą obraz, jako żyrafa na trawie, to jest to duża szansa, że taki opis jest ostatecznie poprawny.
Te metody mogą opisać obraz bez głębszego rozumienia tego, co się znajduje na obrazie i stworzyłem Visual Turing Test, który podchodzi do podobnego problemu w inny sposób. Bo wiem, by maszyny zrozumiały to co się dzieje wokół w sposób znacznie głębszy niż to jest wymagane od problemów, w których metoda opisuje obrazy, i to jest robione poprzez zadawanie pytań o dane elementy tego obrazu.
Jeszcze z innej strony na taki test można spojrzeć jak na zbiór wielu indywidualnych problemów, nie tylko takich jak klasyfikacja obiektów na obrazie lecz tak jak klasyfikacja czynności, zrozumienie emocji czy też może atrybutowa charakteryzacja obiektów. Każdy taki problem jest sparametryzowany pytaniem. I to, uważam, jest bardzo ważna rzecz, bo wiem, jeżeli myślimy faktycznie o zbudowaniu prawdziwego AI, to musimy pójść w kierunku dywersyfikacji, czyli taka maszyna nie tylko powinna rozwiązać problem A, ale i problem B itd.
Jeszcze z innej strony Visual Turing Test jest odejściem od standardowego paradygmatu widzenia maszynowego, zgodnie z którym maszyny badały zrozumienie sceny zdjęć poprzez detekcje objektów albo segmentację obrazów i to odejście jest na rzecz prostszego w ewaluacji problemu, który nie wymaga specyficznej reprezentacji, takich jak, na przykład, opisanie obiektu prostokąt czy klasyfikacji poszczególnych pikseli. Ewaluacja jest dokonywana na podstawie ostatecznego celu jaki ma maszyna wykonać, czyli w tym wypadku – odpowiedzi na pytanie o obraz.

Jeżeli chodzi o postęp – jest on bardzo duży, biorąc pod uwagę, że ten problem jest całkiem nowy. Przede wszystkim powstało wiele zbiorów danych nasz DAQUAR był pierwszy, najbardziej znaną bazą jest VQA. Wielkość jest na tyle istotna, że obecne metody uczenia maszynowego do efektywnego nauczania wymagają ogromnej liczby danych. Są także inne zbiory danych, takie jak MovieQA gdzie pytania są na temat wideo, i jest taka baza danych syntetyczna CLEVR, którą ostatnio eksperymentowałem w DeepMind.

Jeżeli chodzi o estymacje, to ciężko powiedzieć kiedy rozwiążemy taki problem. Tutaj też warto odizolować sam problem Visual Turing Test od konkretnej bazy danych, która dany problem ukonkretnia. Myślę że Visual Turing Test w najszerszym znaczeniu równoważy z General AI.
Z kolei pewne bazy danych mogą zostać rozwiązane w najbliższej przyszłości. Na przykład, wspomniana baza CLEVR (baza z syntetycznymi obrazami i syntetycznymi pytaniami) została rozwiązana w DeepMind.
Zapytam jeszcze o Turing Test. Alan Turing nie zdefiniował dokładnie co ma nastąpić, żeby powiedzieć że to faktycznie się stało. Teraz jest sporo spekulacji, bo jedni uważają że już udało się osiągnąć Turing Test, drudzy mówią, że udało się przez to że nie został dobrze zdefiniowany i nastolatek z Ukrainy czy inne chatboty, które udają że są inteligentne.
Tak naprawdę tylko bardziej próbują się poruszać w bardzo ograniczonej dziedzinie. Zapytam się właśnie o Visual Turing Test, czy też prawdopodobnie będzie taka spekulacja czy jednak jest to bardziej sformalizowane, bo tego nie do końca zrozumiałem.
Może nie nazwałbym to spekulacją, jest to powiedzmy odkrywanie bazy danych, która jest dobrym odzwierciedleniem tego Visual Turing Test. Może tutaj powtórzę, że na początku, jak tworzyłem test, stworzyłem go z bazą danych DAQUAR i można powiedzieć, że to jest pewna instancja Visual Turing Test. W jednej ze swoich publikacji określiłem mniej więcej co mam na myśli poprzez Visual Turing Test i to jest coś trochę bardziej ogólnego.
W pewnym sensie jasno jest to, że to zależy od innych naukowców czy też innych ludzi, jaka jest konkretna baza danych, która odzwierciedla ten Visual Turing Test, więc pod tym względem jest trochę spekulacji. To co jest dla mnie ważne w odróżnieniu od oryginalnego Turing Testu, zdefiniowanego przez Alana Turinga, jest to, że tutaj bardziej skupiamy się na wizji, na obrazach i przez to ten problem staje się bardziej konkretny od Turing Testu, bo tutaj zadaje konkretne pytania “czym jest ten obiekt” albo “ile mamy obiektów na stole” i td. I nie oczekujmy tutaj abstrakcyjnych odpowiedzi.
Ten problem antropomorfizacji czyli takiego nadawania ludzkiego znaczenia rzeczom, które niekoniecznie mają wiele sensu nie jest tak problematyczny, jak w Teście Turinga. Tak jak wspomniałeś że taki robot może udawać dziecko albo inną osobę i zaczynamy wierzyć w to. Tutaj to wszystko jest bardziej konkretne.
To się cieszę. Warto czasami mieć konkrety, chociaz z drugiej strony, jeżeli chodzi o Turing Test, ten test nie ma już aż tak dużo znaczenia, po prostu warto iść do przodu, niż próbować z kimś dyskutować, albo robić kolejną wojnę czy ktoś wygrał ten test czy nie.
Chodźmy dalej, bo jest jeszcze wiele ciekawych rzeczy. Tylko wspomnę jeszcze o image caption czy podpisy zdjęć. Pamiętam że kilka tygodni czy miesiąc temu czytałem artykuł o ograniczeniach Deep Learning i tam było między innymi zdjęcie, gdzie dziewczynka z szczoteczką stoi i algorytm rozpoznał, że to jest bejsbol. Jeżeli chodzi o geometrie, to przypomina, ale każdy człowiek zrozumie, że to była szczoteczka.

Tak, to prawda, więcej jest takich sytuacji i oni są związane z tym, że sieci neuronowe nie mają głębokiego zrozumienia obrazu i raczej działają na pewnych korelacjach, na pewnych związkach statystycznych. Czasami te metody dają świetne rezultaty i możesz być zaskoczony że dany obrazek został w taki sposób opisany, ale też jest dużo wypadków gdzie opis obrazka jest zupełnie błędny.
To widać też na Visual Turing Test, bo wiele metod, które daje się wykorzystać do opisania obrazów także się daje trochę zmienić i wykorzystać do Visual Turing testu. Przy takich trudniejszych pytaniach, które są wcale nie aż takie trudne, te metody tak dobrze nie działają.
Zgłębię te tematy, bo jak już powiedzieliśmy na początku – pracujesz w DeepMind, ale może warto zaznaczyć, że nie reprezentujesz firmę jako taką, tylko wyrażasz swoją prywatną opinie, ale jednak porozmawiajmy o tym…
Zwycięstwo AlphaGo jest bardzo słynne. To było bardzo duży krok do przodu jeżeli chodzi o możliwości komputera. Ale wiem, że DeepMind robi kolejny duży krok do osiągnięcia tak zwanego General AI.
Algorytmy już całkiem dobrze sobie radzą z wykrywaniem kota czy psa na zdjęciu, ale algorytm nie zdaje sobie sprawę, że pies goni kota (chociaż czasem też była odwrotnie).
Dla człowieka to jest oczywiste. Innymi słowa tak zwanej sztucznej inteligencji po prostu brakuje, jak to czasem mówi się, rozumieniu o życiu, o relacjach (po angielsku common sense knowledge).
Czyli jeszcze raz, na dzień dzisiejsze uczenie maszynowe fantastycznie sobie radzi z wykrywaniem wzorców, ale nie jest w stanie wyjaśnić dlaczego jest tak… nie ma głębszego rozumienia. W dużym uproszczeniu, możemy powiedzieć, że student też może “wykuć” na pamięć materiał i nawet zdać egzamin, ale ta wiedza jest po prostu zbiór reguł w głowie i prawie zero zrozumienia.
Jesteś zaangażowany w jeden z projektów DeepMind, gdzie właśnie próbuję się wyjść na inny poziom sztucznej inteligencji. Proszę wyjaśnij jak podchodzisz do tego tematu w DeepMind. Co już udało się osiągnąć? Również poproszę w miarę prostym, mało technicznym językiem z przykładami.
W DeepMind pracowałem nad relation networks i tak jak wspomniałeś, sieci neuronowe o ile dobrze potrafią rozpoznawać obiekty na obrazach, to z pewnymi rzeczami, takimi jak relacje pomiędzy różnymi obiektami to jest dużo ciężej. Głównym celem tego projektu jest zmiana tego stanu rzeczy.
Już jakiś czas temu chyba wspomniałem o zbiorze CLEVR, który jest zbiorem składającym się z trójek pytanie-odpowiedź-obraz, więc można powiedzieć że to także jest część większego projektu, który został zapoczątkowany przez Visual Turing Test czyli także do niego należy albo Vision Question Answering.
Ale w odróżnieniu od zbioru DAQUAR tutaj mamy syntetyczne pytania oraz syntetyczne obrazy, które się składają z kilku figur geometrycznych. Więc pod tym względem te bazy danych są trochę podobne do baz danych MIT z lat 60-yh, ale CLEVR jest położony głównie na takie relacyjne myślenie, czyli pytania są w stylu “ile jest innych rzeczy, które mają taki sam materiał jak żółty sześcian” itd.
Przepraszam, że Cię przerywam, ale myślę, że warto to trochę rozszerzyć i podać przykład co to znaczy w praktyce, bo mamy stół albo jakąś powierzchnię i tam są różne przedmioty, na przykład, sześcian, stożek, kula i też mają różne kolory. Pytanie jest takie – ile jest przedmiotów tego samego koloru albo czy jest ten sam materiał jak na stożku, prawda?

Tak. Aczkolwiek pytania mogą być znacznie bardziej skomplikowane. Na przykład, ile jest gumowych stożków, które stoją naprzeciwko zielonego sześcianu, który jest po lewej stronie od czerwonej rzeczy.
To jest ciekawe, bo jak mówimy o sztucznej inteligencji, deep learning, to zawsze jest takie zachwycenie, że właśnie wygrała AlphaGo, ale tak jak rozmawialiśmy na początku – jest to wyzwanie z common sense knowledge, albo rozumieniem ogólnym, albo powiązaniem tych relacji i to, co potrafi robić nastolatek albo 5-latek, w tej chwili dla algorytmu nadal jest wyzwaniem albo było wyzwaniem. Powiedz, jakie są postępy?
Można powiedzieć, że było wyzwaniem. W celu takiego relacyjnego wnioskowania przez maszyny, stworzyliśmy moduł, który nazwaliśmy Relation Networks. Jest to sieć neuronowa, która rozważa dwa obiekty na obrazie, porównuje te obiekty ze sobą za pomocą kilku warstwowej sieci neuronowej, a następnie agreguje wszystkie te reprezentacje takich par w celu stworzenia jednej reprezentacji globalnej całego obrazu.
Za pomocą tak zbudowanej sieci neuronowej otrzymaliśmy wyniki, które są w zasadzie lepsze niż ludzkie odpowiedzi. Tutaj muszę zaznaczyć, że wszystko jest na zbiorze danych CLEVR i ten zbiór jest wizyjnie prosty, ma skomplikowane relacje, skomplikowane pytania, ale ta percepcja jest prosta. Ale w każdym bądź razie, nasz system potrafi według metryk odpowiadać lepiej niż ludzie, na tej bazie danych. Dlatego można powiedzieć, że rozwiązaliśmy problem rozumienia relacyjnego, przynajmniej w stosunku bazy danych CLEVR.
To co jeszcze jest ważne. Mimo tego, że powiedziałem, że ten moduł porównuje dwa obiekty, to te obiekty nie muszą jawnie być podane, ta sieć neuronowa sama rozstrzyga czym jest dany obiekt na podstawie danych treningowych. To jest w zasadzie taka sieć neuronowa, gdzie się podaje tylko i wyłącznie obrazy, podaje się skomplikowane pytania, podaje się odpowiedzi (w zbiorze treningowym, oczywiście), i ona na postawie tych trójek zaczyna rozumieć obiekty i zaczyna rozumieć relacje.
To my, jako ludzkość zrobiliśmy kolejny krok w kierunku tak zwanej GAI czyli ogólnej sztucznej inteligencji. Tutaj warto jeszcze dopytać Twoją opinie na temat, jakie są wyzwania na dzień dzisiejszy w uczeniu maszynowym, jakie są największe i które da się pokonać w najbliższe 5 lat?
Jest dużo wyzwań. Myślę, że bardzo ważnym jest to, aby sieci neuronowe zaczęły dobrze sobie radzić w momencie, kiedy nie ma tak dużo danych treningowych. Jak opowiadałem o tym zbiorze danych CLEVR i rozumieniu relacyjnym, to to wszystko dobrze działa, bo mamy dużo zbiorów treningowych. W świecie rzeczywistym ciężko się buduje takie zbiory treningowe, szczególnie na wielką skalę.
Jesteśmy ograniczeni o takie naturalne rzeczy, jak zasoby pieniężne, ludzki, jak czas i tak dalej. I w takich skomplikowanych problemach, jak Visual Turing Test, ciężko jest zbudować takie bazy danych, które by zawierały wszystkie możliwe pytania ze wszystkimi możliwymi odpowiedziami. A my – ludzie, jakoś sobie radzimy, poprzez moze jakąś kompozycję, a być może mamy jakieś inne umiejętności, dzięki którym potrafimy tworzyć nowe zdania i potrafimy rozumieć zdania, albo całe zbiory zdań, które wcześniej nie słyszeliśmy.
I to jest, moim zdaniem, bardzo duże wyzwanie dla sieci neuronowych. Jak zbudować taką sieć neuronową, która jest bardzo silna do rozwiązywania problemów, ale jednocześnie nie wymaga się od niej takiego dużego zbioru treningowego, że ona potrafi na bazie kilku przykładów zrozumieć co się dzieje.
Mogę potwierdzić takim trochę z życia przykładem. Mam małe dziecko i zawsze się fascynuje, jak pokazuje w jednej książce krowę, czy inny obiekt, dosłownie jeden czy dwa razy, a później biorę inna książkę, gdzie ta krowa wygląda zupełnie inaczej i pytam “gdzie jest krowa?”, a on pokazuje prawidłowo.
I dla mnie to jest fascynujące. Jak to jest możliwe, bo pokazałem tylko jeden raz i zupełnie czegoś innego, ale od razu się nauczył. Tutaj widać że mózg człowieka działa znacznie lepiej niż nowoczesne algorytmy, przynajmniej na dzień dzisiejszy.
Tak, dokładnie i na dzień dzisiejszy musiałbyś pokazać 100 instacji żeby sieć neuronowa zrozumiała czym jest krowa.
Teraz przejdźmy do tematów, może trochę etycznych, albo o odpowiedzialności.
Mówi się, że jesteśmy teraz na etapie, kiedy algorytmy rozwiązują coraz bardziej złożony zagadnienia, ale my jako ludzi nie do końca mamy kontrole nad tym co tam się dzieje. W ogólnym sensie tego słowa rozumiemy jak to działa (że jest tam sieć neuronowa i różne funkcję transformujące sygnał). W pewnym sensie, to jest podobnie jak to, że wiemy, że jest Słońca, Ziemia i inne planety. Jest grawitacja i inne prawa fizyki, ale myślę, że każdy fizyk który spędził swoje życie na naukę pod koniec życie mógł stwierdzić, że wiem sporo, ale nadal nie wiem jak to działa w całości.
Jak mówił Arystoteles „Całość jest czymś więcej niż sumą części”. No właśnie jest kilka pytań w tym obszarze.
Najpierw może wyjaśnię dlaczego to jest problemem w mojej opinii. Jeżeli zastanowić się na chwilę, to łatwo stwierdzić też nie mamy kontrolę nad ludźmi z każdym krokiem (i to oczywiście dobrze), czyli nie wiemy dokładnie co Jan Kowalski czy Adam Nowak chce zrobić dzisiaj czy jutro (chociaż, w większości przypadków to jest łatwo przewidzieć, bo ludzi płyną zgodnie z prądem).
Z drugiej strony, mamy odpowiedzialność, jeżeli zrobią coś złego, to na nich będzie czekała kara. Nie powiem, że osobiście podoba mi się taki model relacji, mam inne zasady wewnętrzne. Ale mniejsza o to… chodzi o to, że jest to jakiś mechanizm który reguluję działania innych. W przypadku sztucznej inteligencji. Jaka może być dla niej kara? Brzmi trochę bez sensu :). Dlatego jest potrzebna kontrola, żeby rozumieć każdy jej krok. Czy potrzebna jest taka kontrola wg Ciebie? Bo to brzmi fajnie, że możemy kontrolować, ale to pewnie bardzo ogranicza rozwój. Jaka jest Twoja opinia najpierw jako naukowca?
Tutaj zdecydowanie będzie moja prywatna opinia. Jeżeli chodzi o kwestie rozumienia, szczególnie głębokich modeli uczenia maszynowego, jak głębokie sieci neuronowe, to warto jednak podkreślić dwie rzeczy. Do pewnego stopnia my, jako środowisko, rozumiemy te modele, które tworzymy.
Są oczywiście rzeczy, które słabo rozumiemy i często oni są natury technicznej. Na przykład, intuicyjnie mogłoby się wydawać że taka głęboka sieć neuronowa, która ma ok. 60 mln parametrów, która jest trenowana za pomocą stochastic gradient descent nie powinna dobrze działać, ale praktyka pokazuje na odwrót. Ten mechanizm nie jest do końca całkowicie poznany, brakuje szerszej teorii, która mogłaby zasugerować w jaki sposób budować kolejne modele. W konsekwencji czego, budowanie sieci neuronowych jest zajęciem często empirycznym.
Mamy także do czynienia z innym poziomem rozumienia sieci neuronowych, że nie do konca jestesmy w stanie w jednożnaczy sposób ustalić dlaczego dana konkretna sieć neuronowa podjęła takie a takie decyzje. Jak to się stało, że z obrazka, który przedstawia kolor zielony, ma jeszcze inne kolory i jakieś proste kształty, sieć neuronowa doszła do tego, że to jest obraz przedstawiający kwiat. I w tej ostatniej kwestii pojawia się wiele badań jak akademickich tak i badań, które w jakiś tam sposób związane z firmą. I tutaj jest kilka takich nurtów. Jeden nurt, to wizualizacja.
Sieć neuronowa uczy się rozpoznawać obiekty na obrazie poprzez filtry, które wykrywają pewne wzorce i te filtry do pewnego stopnia można zwizualizować, zinterpretować za wykrycie jakiego wzorca ten filtr odpowiada. I w taki sposób można się dowiedzieć, że w dolnej warstwie sieci neuronowej realizują filtry Gabora i są odpowiedzialne za znajdowanie prostych kształtów. Innym ciekawym nurtem jest zapożyczenie narzędzi z psychologii kognitywnej do tego by badać sieci neuronowej.

I w ten sposób można określić pewne tendencje, która ma sieć neuronowa. Czyli, na przykład, sieć neuronowa kieruje się bardziej kształtem obiektu niż kolorem obiektu do tego żeby rozpoznać dany obiekt.
Są także inne metody które próbują w języku naturalnym wyjaśnić taką sieć neuronową. Żeby to zilustrować, wróćmy do Visual Question Sign zadaje pytanie “co się znajduje po prawej stronie od mojego laptopa”, i taka sieć neuronowa patrzy na obrazek, patrzy czy to pytanie i mi odpowiada na to pytanie, i wtedy się pyta “dlaczego doszła do takich a takich wniosków ” i wówczas ta sieć neuronowa próbuję się wytłumaczyć, tak jak człowiek to robi.
Jak ty mnie zapytasz, dlaczego podjełem taką decyzje, to próbuje ten cały proces decyzyjny Ci przedstawić w postaci języka naturalnego. Tak samo tutaj jest kierunek badań, który próbuje stworzyć sieci neuronowe, które same się wyjaśniają dlaczego doszło do takiego a takiego rozwiązania.
Zapytam Cię jeszcze o jedną poradę, tym razem dla młodszego pokolenia. Którzy teraz są na studiach, albo skończyły je i zastanawiają się co robić dalej. Co możesz im doradzić? Ewentualnie zdradź kilka wskazówek, jak taki młody człowiek może zacząć pracować w DeepMind?
W mojej historii studia doktoranckie były bardzo ważnym okresem w życiu, ogólnie studia były bardzo ważnym okresem w życiu. Myślę, że w czasie studiów warto jest chłonąć wiedzę z wielu różnych dziedzin. Na kierunkach ścisłych także warto nabrać pewnych umiejętności, są to rzeczy, które stają się później ważne, aby móc inspirować, przekonywać inne osoby do pewnych projektów, do pewnych idei.
Myślę, że bardzo ważne jest także aby balansować teorie z praktyką. Z jednej strony teoria jest bardzo istotna, nie zmienia się ona tak często jak inne rzeczy i poprzez nią budujemy pewny warsztat kognitywny, dzięki któremu jesteśmy w stanie zrozumieć inne bardziej konkretne rzeczy.
Z drugiej strony warto wzmacniać tą wiedzę teoretyczną jakąś praktyką lub różnymi eksperymentami w taki sposób, aby ta teoria była bardziej namacalna. Szczególnie jeżeli chodzi o uczenie maszynowe, starałbym każdą wiedzę teoretyczną wzmocnić jakimś argumentem empirycznym, czyli po prostu stworzenie implementacji pewnej rzeczy, która nas interesuje.
Jeżeli chodzi o firmę, to nie skusiłabym się na budowaniu swojego CV pod konkretną firmę. Jak ktoś teraz zaczyna studia, to prawdopodobnie je skończy za jakieś 5 lat, może później, jeżeli zdecyduje się na studia doktoranckie i ten rynek może się zmienić. Ale wydaje mi się że jest ważne by w pewnym okresie swojego życia stać się osobą, która ma unikalne umiejętności, które są także cenione na rynku pracy, i jeżeli tak się stanie, to firmy same zaczną się zgłaszać po taką osobę.
Osobiście polecam wyjazdy na dobre uczelnie zagraniczne lub do dobrych firm, często zagranicznych, na praktyki. I takie wyjazdy otworzyły mi oczy na pewne dziedziny wiedzy, które wcześniej były mi obce, a stały się kluczowe w mojej karierze.
Także warto uczestniczyć w programach mentorskich, jeżeli takie programy są dla studenta dostępne.
Czyli tak nieco w skrócie mieć otwarte oczy, umysł, być przygotowanym na wyzwania i iść do przodu.
Dokładnie, trzeba być dzielnym, odważnym.
Czego mogę Tobie życzyć?
Zbudowania AI 😉
W takim razie życzę Ci zbudowania AI. A na jakim poziomie, porównywalnym do ludzi czy wyższym?
A myślę, że niekoniecznie musimy myśleć w takich kategoriach. Być może zbudowanie AI, które w jakiś tam sposób jest komplementarne do ludzi czyli uzupełnia nas w jakiś tam sposób.
Czyli taki pomocnik, który robi za nas te rzeczy, które niekoniecznie ludzie lubią robić, a my skupiamy się na najbardziej ciekawych elementach tego życia.
Tak, ale to także pomaga w rzeczach które lubimy robić. Pomaga nam w badaniach naukowych albo w eksploracji kosmosu.
Tam gdzie faktycznie mózg ludzki nie jest najlepszym jak liczenie.
Na przykład. Albo dostęp do wiedzy. To jest tak, że teraz wiedzy jest bardzo dużo, teoretycznie mamy do niej dostęp, ale nie mamy dostępu do tej wiedzy naraz, w jednym momencie. Więc taka sztuczna inteligencja, która ma ten dostęp i potrafi odfiltrować te rzeczy, które dla nas są istotne i w odpowiedni sposób wnioskować. Może nam pozostawić ostateczną decyzje, ale zasugerować pewne rzeczy.
Rozmawialiśmy z Tobą prawie godzinę, ale nadal widać, że sztuczna inteligencja ukrywa w sobie bardzo dużo różnych wątków. Życzę Tobie żeby udało się zrealizować to co planujesz. A jak można z Tobą skontaktować w razie zainteresowania?
Można się ze mną skontaktować tradycyjnie, czyli mailem. Można wysłać maila obecnie na mateuszmalinowskiai [małpka] gmail.com. Jeżeli ktoś jest zainteresowany moimi publikacjami, to można je znaleźć albo na mojej stronie internetowej, albo na Google Scholar czy Linkedin.
Dziękuję, Mateusz bardzo za Twój czas i chęć podzielenia się swoim doświadczeniem.
Także dziękuję za rozmowę.
Duża dawka wiedzy? Być może część poruszonych tematów dla Ciebie była trochę trudna i zawierała skróty czy inne nieznana terminologia.
Mateusz jest pasjonatem swego dzieła, dlatego myślę, że jeszcze wiele dokonań jest jeszcze przed nim. Po naszej rozmowie zastanawiałem się nad tym, o ile my jesteśmy architektami swego losu. Czasem może się wydawać, że pracować w firmie jak DeepMind jest kosmicznie trudno. Na przykładzie z Mateuszem, można zobaczyć, że wystarczy konsekwentnie robić swoje. Dlatego życzę Ci, osiągać swoje cele również skutecznie, jak to robi Mateusz.
Dziękuję za wszystkie informację zwrotne. Przypominam, że możesz kontaktować się ze mną przez dowolny wygodny kanał dla Ciebie: twitter, facebook, linkedin, strona kontaktu na biznesmysli.pl.
Mam dobrą nowość dla Ciebie. W tym roku Google Developers Day Europe będzie zorganizowany w Krakowie 5-6 września. To jest ciekawe wydarzenie dla osób które interesują się technologiami rozwijanymi przez Google. Osobiście bilet kupiłem już kilka misięcy temu (mówię dlatego, żeby pokazać ważność dla mnie tego wydarzenia), ale dzięki współpracy z Google mam do rozdania trzy bilety dla najbardziej chętnych. Przypomnę, że wartość takiego biletu jest 250 dolarów.

Chcesz dostać takie bilet za darmo? A może chcesz się spotkać z ludźmi z Google, które rozwijają innowacyjne produkty (będzie również sporo osób z Doliny Krzemowej)? A możliwie chcesz ze mną porozmawiać osobiście?
- Dołącz się do grupy DataWorkshop na Facebook.
- Udostępnij baner GDD Europe ze swoim komentarzem, dlaczego chcesz pójść na konferencje.
- Zaangażuj również swoich znajomych i może się okażę, że pójdziecie razem.
Masz na to 3 dni. Następnie, w czwartek z rano (31 sierpnia), wybiorę 3 najbardziej wartościowe powody (wg. mojej skromnej opinii) i skontaktuję się z tymi osobami przez wiadomość prywatną i do końca czwartku będę oczekiwał na informację zwrotną od wybranych osób.
Również będę na tym wydarzeniu, więc jeżeli wybierasz się, proszę daj mi o tym znać.
Dziękuję Ci bardzo za Twój czas, Twoją energię i chęć do rozwoju.
Życzę wszystkiego dobrego i do usłyszenia.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.

2 komentarze
Grzechu
Cześć Vladimir,
ostatnio uważnie śledzę Twojego bloga i podcasty. Forma oraz treść, jaką przekazujesz jest świetna i bardzo przyjemnie mi się Ciebie (oraz Twoich gości) słucha i czyta. Bardzo cenię Cię za to, że robisz to wszystko po polsku – to nie lada wyzwanie.
Nie mam jeszcze doświadczenia ze sztuczną inteligencją, machine learning itp., ale niezmiernie mnie to interesuje i szukam informacji na ten temat, aby móc przekuć teorię w praktykę, ponieważ jestem developerem. Natomiast temat wizji komputerowej już od czasów akademickich siedzi mi mocno w głowie, mam masę pomysłów, lecz brak mi czasu i „kopa”, aby coś zacząć i spróbować zrealizować.
Powyższy odcinek bardzo mnie zainteresował – sporo w nim informacji, teorii i przykładów, ale czuje mały niedosyt.
Wyżej przytoczone przykłady są bardzo ogólne i lakoniczne. Brakuje mi tutaj odniesienia do zastosowania w/w technik w praktyce. To znaczy, gdzie w biznesie zostały użyte procesy rozpoznawania przedmiotów lub zwierząt na zdjęciach?
Dla zobrazowania tego o co mi chodzi.
Np. rozpoznawanie źrenic i ich pozycji na obrazie przechwyconym z kamery skierowanej na twarz może zostać wykorzystane i używane przez osoby niepełnosprawne jako kontroler/interface pozwalający korzystać z komputera. Innym przykładem jest (chyba słyszałem to w którymś z Twoich podcastów) analizowanie zdjęcia domu lub mieszkania w celu pomocy przy wycenie nieruchomości przez rzeczoznawcę. Nie mogę tu pominąć oczywiście analizy obrazu w autonomicznych pojazdach.
Dobrze byłoby usłyszeć od doświadczonych osób o już istniejących rozwiązaniach, może nawet dostępnych, przede wszystkim dla osób niepełnosprawnych.
Pozdrawiam,
GD.
Vladimir
Dziękuję Grzehu za komentarz.
Już mam plan nagrać jeden odcinek w którym będzie wzięty konkretny biznes z problemami i jak uczenie maszynowe może pomóc. Będzie to namacalne :).
>Natomiast temat wizji komputerowej już od czasów akademickich siedzi mi mocno w głowie, mam masę pomysłów, lecz brak mi czasu i „kopa”, aby coś zacząć i spróbować zrealizować.
Jeżeli bardzo interesujesz się implementacją (czyli bardzo techniczne rzeczy) to polecam odwiedzić moją inną inicjatywę: dataworkshop.eu i też polecam zapisać się na newsletter. Gdzie co tygodniowa wysyłam 5 najciekawszych rzeczy które przeczytałem o uczeniu maszynowym. Często to są konkretne implementacji lub ciekawostki ze swiatu machinelearning.
A co do kopa, to zapraszam do udziału w warsztacie który rozpoczni się w październiku. Będzie praktyczna wiedza oraz motywacja do działania.