
Lokalne modele AI: Twoje dane, Twoje zasady

Wprowadzenie do lokalnych modeli językowych
Zaczynamy, ale pamiętaj przed tym, że świat zmieni się szybciej niż myślisz. Już w poprzednich odcinkach podcastu wspomniałem wiele o tak zwanych dużych modelach językowych, czyli LLM, ChatGPT i podobnych. Mówiłem też o tym, jakie są potencjalne pułapki, problemy, na co należy uważać. Mam nadzieję, że już widać, że faktycznie takie modele LLM mogą być użyteczne dla ciebie i twojej firmy, ale trzeba umieć je wykorzystać.
Z drugiej strony jest też szereg różnych ograniczeń i innych ryzyk. Zauważyłem również, że osoby, które są mniej techniczne, potrzebują wsparcia w zrozumieniu, w jaki sposób można wykorzystać takie modele LLM w praktyce. Nie tylko słyszeć o tym, że gdzieś jest fajny supermodel, który coś potrafi zrobić, ale jak ty możesz ten model faktycznie wykorzystać, jakie są opcje i czym się różnią.
W szczególności, jeśli skupimy się na tematach związanych z lokalnym modelem językowym. Tutaj jest też szereg różnych haseł, które chciałbym wyjaśnić i wytłumaczyć, na czym polega ta różnica. Między innymi chciałbym osiągnąć dzisiaj to, że jak pojawi się na przykład jakiś kolejny model, powiedzmy Bard wersja druga, to będziesz wiedział, w jaki sposób można go wykorzystać u siebie lokalnie, tak żeby nie tylko o tym słyszeć, ale też mieć kontrolę nad tym modelem.
O czym będzie?
Będę mówić najwięcej o LLM-ach, czyli pracy z tekstem, ale nie tylko. Głównie chcę się skupić na pojęciu lokalnego modelu językowego, ale przygotowałem też w notatkach inne tematy. Na przykład chciałbym poruszyć wątek self-hosted LLM, czyli samodzielnie hostowanych modeli. Jest też takie pojęcie jak
PC AI, czyli komputer i AI. Porozmawiamy też o open-source LLM i open-weight LLM. O tym już trochę mówiłem, ale rozszerzę ten wątek albo takie pojęcie jak offline language model, czyli praca offline z modelem, lub pojęcie, które zaczyna się pojawiać, tzw. small LLM, czyli małe modele językowe. Wyjaśnię, na czym to polega i dlaczego jest to wartościowe. Następnie wspomnę o szeregu narzędzi, które mogą być przydatne dla ciebie. Dlatego warto wysłuchać do końca, aby faktycznie z tego skorzystać.
Oczywiście w ramach podcastu nie jestem w stanie krok po kroku cię wprowadzić i pokazać, jakich narzędzi używać. Na to będą inne formaty, na przykład moje szkolenia albo webinary. Warto je obserwować. Natomiast to, co już będzie wartościowe dla ciebie, to przynajmniej zrozumiesz strukturę. Będę się starał mówić maksymalnie zrozumiale, aby wszystko było jasne i przejrzyste.
Zrozumiesz wady i zalety tego czy innego rozwiązania. Spróbuję też uporządkować narzędzia, o których będę mówić, aby było zrozumiałe, które narzędzie jest prostsze w użyciu, ale daje mniej kontroli nad tym, co dzieje się pod spodem. I w drugą stronę – które narzędzie jest bardziej techniczne, wymaga większej konfiguracji, ale daje większą kontrolę. Przy czym te narzędzia też mogą współpracować ze sobą.
Oczywiście porozmawiamy wprost o korzyściach, zarówno prywatnych dla Ciebie, jak i biznesowych, dlaczego warto o tym w ogóle myśleć. Zacznijmy od początku.
Załóżmy, że mamy taki model LLM, który już jest wytrenowany. Wspomniałem o tym na przykład w podcaście 120, „Sztuczna inteligencja pod własnym dachem”. Dlaczego to jest ważne, dlaczego zwykle wymaga dużych zasobów i ciężko jest to zrobić pojedynczej osobie. Zwykle za tym stoi jakaś większa organizacja albo wprost państwo.

Jak wykorzystać gotowy model LLM/AI?
I załóżmy, że taki model już jest wytrenowany. Jakie masz opcje, aby taki model wykorzystać? Czyli utylizować. Model jest wytrenowany i chcesz z tym modelem w ten czy inny sposób porozmawiać, albo w jakiś inny sposób go wykorzystać. Jakie są opcje?
Otóż zacznijmy od samego początku. Najprostszy i najbardziej znany przypadek to jest ChatGPT w takim sensie, że wchodzisz na stronę internetową, wpisujesz ten adres i możesz już rozmawiać. Właściwie jak pojawiło się ChatGPT 3.5, to wtedy pełna rewolucja nastąpiła na świecie, no i też pewne rzeczy zaczęły się troszkę zniekształcać.
Z jednej strony fajne, że te tematy poszły w masę, ale z drugiej strony też ten przekaz często był niepoprawny, ale na razie zostawmy to na boku, czyli to, co wtedy masz, to wchodzisz sobie na stronę, wpisujesz pytanie i dostajesz odpowiedź. W tym przypadku w ogóle nie przejmujesz się niczym, jeżeli chodzi o infrastrukturę, na której to jest uruchomione, jaki tam serwer, jakie tam są karty GPU. Tym w ogóle się nie przejmujesz, wysyłasz, rozmawiasz. I to jest takie najprostsze i faktycznie bardzo wygodne czasem, bo wtedy po prostu wchodzisz na stronę internetową i rozmawiasz.
Natomiast z punktu widzenia integracji z prawdziwym biznesem, no to już niekoniecznie jest proste, tak technicznie, ale też zawiera mnóstwo problemów, w szczególności dla firm. W regulaminach OpenAI, bo są różne regulaminy, teraz mówimy o tym regulaminie na dostępnym narzędziu na stronie internetowej, no to tam są pewne takie nie do końca zrozumiałe rzeczy, co jest możliwe z punktu widzenia biznesu, jak on je chroni.
Opowiem Ci o badaniu Cyberhaven (jednej firmy amerykańskiej), która zbadała różne firmy pod tym kątem, jak często pracownicy firmy wrzucają poufne dane do takiego ChatGPT. Okazało się, że dość często. Zresztą oni zbadali, wtedy kiedy czytałem ten artykuł, 1,6 miliona użytkowników. No i było tam dość sporo incydentów, czyli sytuacji, kiedy dane poufne, które były tajemnicą handlową, takim know-how konkretnej firmy, mogły trafić do ChatGPT, no i wiadomo, OpenAI w ten moment zaczęło te dane posiadać. Czy oni to gdzieś tam udostępniają, czy nie, to już tam można się wczytać razem z prawnikiem, co to znaczy.
Z głośnych spraw, kiedy pracownik z Samsunga opublikował, z tego co pamiętam, to był kawałek kodu, który był taki strzeżony, bo tam chciał pewnie coś naprawić, no i to wyszło. I później między innymi Samsung i wiele innych firm zaczęli to blokować.
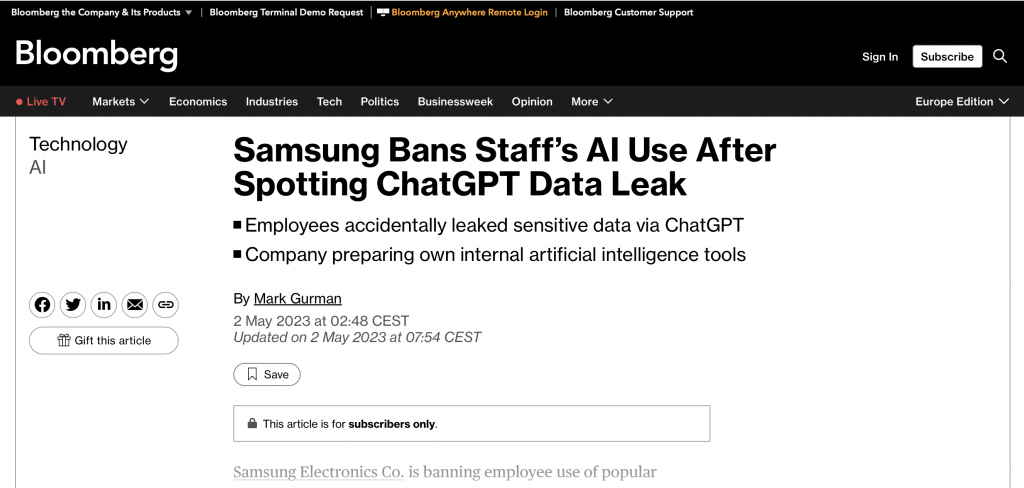
Korzystając z prostych narzędzi online do przetwarzania danych, należy pamiętać, że informacje te są przesyłane do zewnętrznych firm. Stwarza to szereg potencjalnych problemów.
Po pierwsze, istnieje ryzyko ujawnienia poufnych informacji. Po drugie, mogą pojawić się kwestie prawne, takie jak naruszenie RODO lub innych regulacji. Wiele instytucji, szczególnie finansowych, zakazało swoim pracownikom korzystania z narzędzi takich jak ChatGPT ze względu na te obawy.
Przykładowo, wprowadzanie danych osobowych do takich systemów jest nie tylko nieetyczne, ale często również zabronione. Z tego powodu, korzystanie z tego typu rozwiązań może stwarzać poważne problemy dla firm i osób prywatnych.
Pojawia się pytanie, czy OpenAI można wykorzystać w biznesie lub firmie.
Istnieją trzy główne opcje:
- Standardowa wersja dostępna na stronie OpenAI.
- Wykorzystanie API OpenAI:
- Posiada osobny regulamin Enterprise Privacy, który warto dokładnie przeanalizować, najlepiej z prawnikiem.
- Oferuje więcej praw i gwarancji dla użytkowników.
- Uruchomienie w chmurze Azure:
- Popularna opcja dla firm tworzących wewnętrzne chatboty.
- Microsoft zapewnia, że:
- Nie udostępnia danych innym klientom ani OpenAI.
- Nie wykorzystuje danych do usprawniania modeli OpenAI czy Microsoft.
- Oferuje większe gwarancje bezpieczeństwa danych.

Ta ostatnia opcja (Azure) często zapewnia firmom wystarczający poziom komfortu, choć zawsze warto rozważyć różnice między deklaracjami a praktyką.
Pojawia się pytanie kolejne pytanie, a co jeśli to jest niewystarczające?
W dużych firmach i instytucjach, takich jak banki, często prowadzone są eksperymenty z nowymi narzędziami. Jednak ich wdrożenie na skalę produkcyjną często napotyka na opór ze strony prawników. Spotkania dotyczące tych kwestii bywają burzliwe i zazwyczaj kończą się brakiem zgody na użycie nowych rozwiązań. Mimo pewnych akceptacji, wciąż istnieje wiele niejasności, co rodzi pytanie: co wtedy?
W takiej sytuacji pojawiają się lokalne modele językowe. W praktyce oznacza to, że nie możemy uruchomić lokalnie modeli takich jak OpenAI, szczególnie tych bardziej zaawansowanych (np. GPT-3.5 i nowszych), ponieważ firma nie udostępnia ani kodu, ani wag modelu.
Na szczęście istnieją alternatywy, często określane jako „open weights”. Oznacza to, że choć nie zawsze mamy dostęp do kodu źródłowego modelu, możemy pobrać zbiór wartości (wagi) wygenerowanych podczas treningu. Te pliki, choć duże, pozwalają na uruchomienie modelu lokalnie. Nie zawsze mamy pełny wgląd w proces treningu, ale przynajmniej możemy pobrać i uruchomić sam model.
Otwarte modele LLM na fali: Llama i inne
W 2023 roku, gdy ChatGPT zdominował rynek, otwarte rozwiązania były ograniczone i mniej zaawansowane. Jednak sytuacja szybko się zmieniła. Rodzina modeli Llama, trenowanych przez Meta, znacząco się rozwinęła. Obecnie dostępna jest już trzecia wersja w trzech wariantach, każdy w dwóch wersjach.
Jak wcześniej wyjaśniałem, istnieją modele bazowe i Instruct. Zazwyczaj preferujemy model Instruct, ponieważ umożliwia on konwersację. Trzy warianty różnią się rozmiarem: 8, 70 i ponad 400 miliardów parametrów. Uruchomienie większych modeli lokalnie może być wyzwaniem ze względu na ograniczenia sprzętowe, ale można je uruchomić na potężniejszych maszynach, nad którymi mamy kontrolę.
Tu pojawia się różnica między local LLM, który można uruchomić na zwykłym laptopie, a self-hosted, czyli na większej, kontrolowanej przez nas maszynie. Może ona znajdować się w chmurze lub fizycznie w naszym biurze.
Warto zaznaczyć, że komercyjne modele, takie jak Claude 3.5 od Anthropic, GPT-4.0 czy Gemini od Google, wciąż osiągają lepsze wyniki w różnych benchmarkach. Jednakże modele open-source, jak Llama, szczególnie w największych wersjach, dorównują im jakością. Z pewnością przewyższyły już GPT 3.5, który był przełomowy w momencie swojego debiutu.
Modele otwarte, które możemy samodzielnie uruchomić, mogą być gorsze w ogólnych warunkach oceny, ale często są wystarczające do konkretnych zastosowań biznesowych. Warto pamiętać, że z perspektywy biznesu kluczowe jest rozwiązywanie specyficznych problemów, a nie ogólna wydajność modelu.
Modele te można dostosować i optymalizować pod kątem konkretnych zadań. Jeśli model, który testujemy, jest porównywalny lub lepszy w rozwiązywaniu naszych problemów, może być dla nas odpowiedni, nawet jeśli w innych obszarach działa gorzej.
Warto podkreślić, że modele, które możemy uruchomić na własnych warunkach, są już wystarczająco dobre, by przynosić wartość biznesową. W przypadku specyficznych zastosowań, np. w języku polskim, modele takie jak Bielik (szczególnie w wersji drugiej i kolejnych) mogą działać nawet lepiej niż modele stworzone za granicą.
Uruchomienie modelu LLM lokalnie
Pierwszym krokiem jest określenie, co chcemy uruchomić – w tym przypadku pobrać i uruchomić model. Następnie należy zastanowić się, co oznacza „uruchomienie” i jakie komponenty są do tego potrzebne. Wyróżniamy dwa główne elementy: backend oraz frontend (UI). Istnieją narzędzia, które łączą obie te funkcjonalności.
Warto zrozumieć pewne podstawowe koncepcje, które ułatwią późniejsze zrozumienie działania systemu i dostępnych opcji. Model, który został wytrenowany, to fizyczny plik lub zbiór plików w folderze. Podobnie jak w przypadku innych typów dokumentów, modele można zapisywać w różnych formatach, które mogą się znacząco różnić, mimo że zawierają te same informacje semantyczne.
Wybór formatu zapisu modelu jest istotny, ponieważ różne narzędzia mogą wymagać konkretnych formatów. Po zapisaniu modelu, kolejnym krokiem jest jego pobranie. Popularnym źródłem modeli jest platforma Hugging Face, która stała się swoistym „GitHubem” dla modeli uczenia maszynowego. Hugging Face niedawno dokonał strategicznego przejęcia, aby lepiej zarządzać ogromną ilością danych, którymi dysponuje.
Wiadomo, większe modele, które tam są wrzucone, to powiedzmy nie są takie modele, które chcesz używać na produkcji, ale jest ich przynajmniej jakaś taka setka, może tam kilkaset takich modeli, które gdzieś tam wcześniej czy później mogą być przydatne.
Teraz to, co my robimy, to pobieramy to do siebie, przy czym w różnych narzędziach to można, możesz działać w taki sposób, że po prostu klikasz pobrać i to faktycznie się pobiera i wtedy nawet nie musisz jeszcze się logować na Hugging Face. Jak już to mamy pobrane i to możemy wczytać w ten model, to dalej możemy z tego modelu korzystać na różne sposoby, na przykład takie bardziej techniczne, to gdzieś tam w konsoli. Taka konsola może wyglądać przerażająco dla osób mniej technicznych, możemy już tam rozmawiać ze swoim modelem albo na przykład też możemy wystawiać poprzez API.
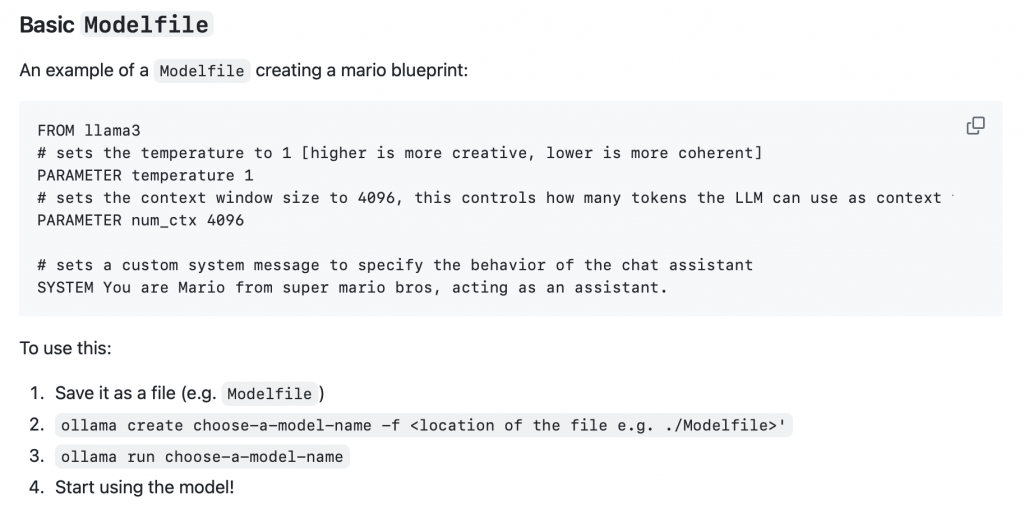
Ollama
Pierwsze narzędzie, które zwykle przychodzi do głowy, to jest tak zwane narzędzie Ollama, które ja osobiście wykorzystuję bardzo często, regularnie, jest piękne, jeżeli chodzi o taką kontrolę i prostotę. Po prostu jak wychodzi jakiś nowy model, to wpisujesz w konsoli na przykład „ollama run” i nazwę modelu, ono sobie, jak go nie masz jeszcze lokalnie, ono sobie pobiera, jak już masz, no to masz, po prostu uruchamiamy w konsoli i już możesz rozmawiać.
Oczywiście to takie bardzo szybkie i dość wygodne, jeżeli chodzi o prostotę. Też możemy przez Ollama serwować to dalej, czyli na przykład później na poziomie kodu, albo w inny sposób udostępnić sobie poprzez swoje lokalne API i wykorzystywać ten model. Pierwsze narzędzie, o którym warto wspomnieć, to jest Ollama, ale ono w ogóle też przypomina takie podejścia, które znamy na przykład w Dockerze, gdzie możemy sobie tak nawarstwiać różne parametry.
Na przykład możemy sobie stworzyć, możemy odziedziczyć inny model i ustawić swoje parametry, na przykład parametry temperatury, albo tam jakieś systemowe prompty wrzucić, albo jakieś takie podobne rzeczy. Następnie stworzyć taki jakby swój customowy model i później nie musimy na przykład za każdym razem wpisywać ten systemowy prompt, tylko wprost pytając to, co chcemy, dostajemy te wyniki, które chcemy.
Kluczową kwestią, o której należy pamiętać, jest kontrola nad naszymi danymi. Korzystając z narzędzi takich jak ChatGPT czy podobne, wysyłamy nasze informacje do zewnętrznych firm, często zlokalizowanych za granicą, na przykład w Stanach Zjednoczonych. Dane te są fizycznie przesyłane z naszego komputera lub serwera na obce urządzenia.
Takie działanie może budzić wątpliwości z wielu powodów. Nie chodzi tu tylko o chęć ukrycia pewnych informacji, ale także o ochronę tajemnic handlowych czy przestrzeganie różnych regulacji. Dlatego tak istotne jest zachowanie kontroli nad własnymi danymi. Badania wykazują, że wielu pracowników, często nieświadomie, popełnia poważne błędy, udostępniając informacje, które powinny pozostać poufne i dostępne wyłącznie dla personelu firmy.
Kontrola nad modelem LLM
Korzystanie z lokalnych modeli LLM daje nam większą kontrolę nad danymi i samym modelem. Choć dostawcy tacy jak OpenAI czy Anthropic oferują wybór modeli, doświadczenie pokazuje, że ich zachowanie może być nieprzewidywalne.
Zaobserwowano, że modele czasami się „nudzą”, co wpływa na jakość ich pracy. Aby temu zaradzić, stosuje się różne triki, takie jak obiecywanie modelowi „napiwków” w promptach. Jednak efektywność tych metod jest dyskusyjna, a ich długoterminowe konsekwencje niejasne.
Empiryczne doświadczenia wskazują, że nawet przy tych samych parametrach i wybranym modelu, wyniki mogą się różnić. To sprawia, że kontrolowanie modeli LLM staje się trudne i nieprzewidywalne. Osiągnięcie stabilnego stanu jest wyzwaniem, gdyż model może zachowywać się inaczej po pewnym czasie.
Dodatkowo, zaobserwowano różnice w działaniu tego samego modelu w różnych regionach geograficznych, np. w Unii Europejskiej i Stanach Zjednoczonych. Choć można to wyjaśnić, jest to zaskakujące i może powodować problemy w spójności wyników.
Wszystkie te czynniki przyczyniają się do dyskomfortu w pracy z modelami LLM, szczególnie gdy dąży się do uzyskania przewidywalnych i powtarzalnych rezultatów w różnych kontekstach i lokalizacjach (a d tego zwykle dąży się w biznesie, prawda?).
Bo jedna rzecz, której chcemy, oprócz pilnowania naszych danych (co jest bardzo ważne), to kontrola nad modelem. Chcemy mieć kontrolę nad modelem, bo jak już mówiłem ostatnio, zrobić szybki prototyp, który robi efekt „wow”, to jest super, to jest fajna sprawa.
Ale ważną rzeczą, gdy wdrażamy na produkcję, jest nie tylko zrobienie efektu „wow”, ale mieć kontrolę, bo zawsze coś może się zepsuć. I jeżeli ktoś wdraża takie modele na produkcję i bierze za to odpowiedzialność, to jego koszmarem jest to, że coś pominął, coś ważnego zostało przeoczone i coś wyciekło, albo pojawiają się jakieś znaczące błędy.
W DataWorkshop mamy taki standard, że przy wdrażaniu na produkcję jest kontrola nad modelem i wszystko co mu towarzyszy, co się tam dzieje. Zdajemy sobie sprawę, że modele mogą się mylić, ale dążymy do tego, by działo się to w ramach, które sami określimy, a nie w sposób niekontrolowany. Utrata kontroli nad tym procesem może prowadzić do poważnych konsekwencji.
Korzystając z własnych modeli, na przykład w narzędziu Ollama, mamy pełną kontrolę nad ich działaniem. Modele są zamrożone i przechowywane jako niezmienne pliki na dysku, do którego mamy wyłączny dostęp. Przy odpowiednim zabezpieczeniu, nikt inny nie może ich modyfikować.
Dla architekta rozwiązania to bardzo korzystna sytuacja. Daje pewność, że model nie zmieni się niespodziewanie, a przy kopiowaniu między serwerami zachowa swoją integralność. Ta kontrola zapewnia komfort i stabilność w pracy z modelami.
LM Studio
Warto również wspomnieć o narzędziu LM Studio, które jest szczególnie przydatne dla mniej technicznych użytkowników. Jego interfejs graficzny umożliwia łatwe konfigurowanie i natychmiastowe rozpoczęcie czatowania. Dodatkowo, oferuje możliwość udostępnienia modelu jako API.
LM Studio to interesujące narzędzie z wbudowaną wyszukiwarką, które stale się rozwija. Przez dłuższy czas korzystałem z tego oprogramowania i doceniałem jego funkcjonalność. Jednak z czasem zacząłem dostrzegać pewne problematyczne aspekty, szczególnie w kwestii regulaminu i kontroli nad narzędziem.
Jednym z głównych powodów, dla których przestałem używać LM Studio, była możliwość automatycznej modyfikacji oprogramowania bez wiedzy użytkownika. Taka praktyka budzi obawy dotyczące bezpieczeństwa danych, kontroli jakości i potencjalnego wycieku informacji, w tym historii czatów.
W porównaniu do narzędzi takich jak ChatGPT, gdzie użytkownik jest świadomy, że historia jest zapisywana, LM Studio wydawało się mniej transparentne. Wybierając wewnętrzne rozwiązanie firmy, oczekiwałbym większej kontroli nad narzędziem i jego funkcjonowaniem.
Choć istnieje możliwość odcięcia narzędzia od internetu, sam fakt, że firma może wprowadzać niezauważalne zmiany, wydał mi się niepokojący. Jeśli potrzebuję lokalnego lub bardziej kontrolowanego rozwiązania, dlaczego miałbym akceptować takie warunki? To skłoniło mnie do poszukiwania alternatyw, które zapewniają większą przejrzystość i kontrolę nad danymi.
Jan.ai
Alternatywa, która jest w tej chwili mniej znana, a którą bardzo gorąco polecam, to narzędzie nazywające się Jan, dosłownie jan.ai.
I to jest narzędzie, które daje to wszystko, co w sumie jest w LM Studio. Ma bardzo piękny UI, bardziej przyjemny i przejrzysty. Mało tego, tam też można pięknie sobie wrzucić swoje klucze, na przykład do ChatGPT, Anthropica, Mistrala i innych. Czyli de facto możesz wykorzystywać jedno miejsce, jedno źródło do rozmowy.
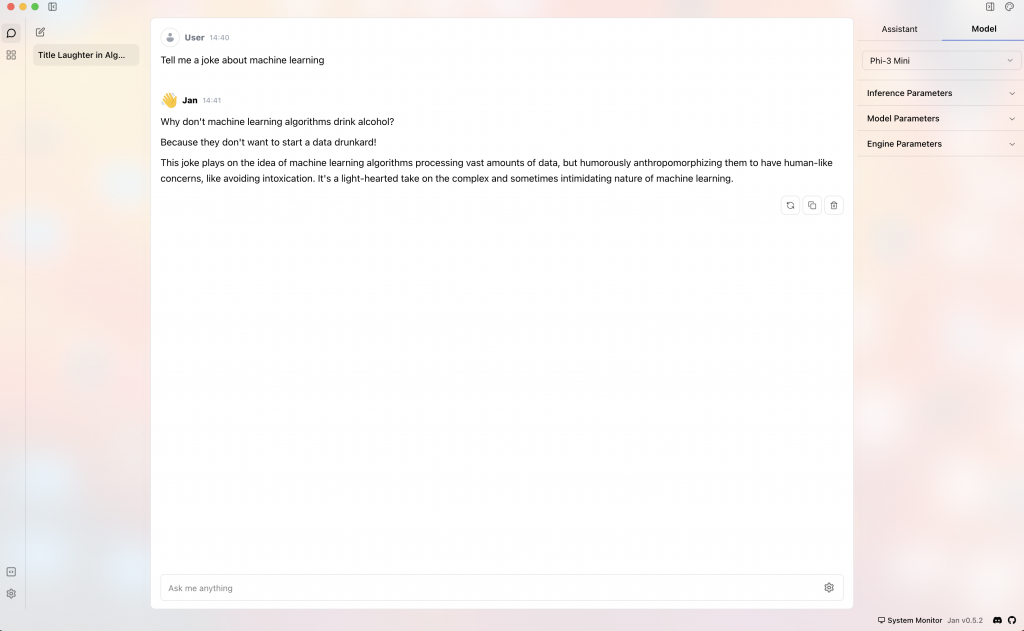
Możesz rozmawiać wprost lokalnie, czyli z modelami, które masz na swoim dysku i w 100% kontrolujesz, albo rozmawiać z modelami zewnętrznymi. To jest wygodne. Wiadomo, trzeba wypracować pewne techniki, aby nie mylić, z kim rozmawiasz, ale sam interfejs jest bardzo piękny i wygodny. Możesz też zobaczyć, który model w danej chwili jest wybrany.
Też co jest fajne, to można z jednej strony wchodzić w szczegóły i ustawiać różne parametry, ale domyślnie to jest schowane. To znaczy, jeśli jesteś mniej zaawansowanym użytkownikiem, to tego nie potrzebujesz i widzisz tylko zwykłe okienko, w którym wpisujesz różne rzeczy. Też na przykład Jan umożliwia udostępnienie API, które później też możemy w ten czy inny sposób wykorzystywać.
Zresztą to narzędzie mocno jest inspirowane przez takie podejście open-source, z prywatnością na pierwszym miejscu, albo lokalnym uruchomieniem na pierwszym miejscu. Albo też takie pojęcie jak offline uruchomienie, czyli te modele, pomijając modele zewnętrzne, ale te, które masz lokalnie, potrafią działać lokalnie.
I to też jest wygodne. Zresztą to nie chodzi tylko o to, że masz pewne tajemnicze dane, tylko jak masz to lokalne, to działa u Ciebie. To znaczy, jak działasz na swoim laptopie, pod warunkiem, że ten model tam się zmieści, to danych nigdzie nie wysyłasz. Więc to jest szybsza odpowiedź, jeżeli chodzi o działanie.
Dostępność ChatGPT
Też na przykład to, co dzieje się w ChatGPT – zresztą możesz sobie zobaczyć na stronie statusu dostępność ChatGPT – to są takie sytuacje, kiedy ChatGPT przez kilka godzin albo więcej jest niedostępny, i nic z tym nie zrobisz. Po prostu przez moment nie możesz z tym pracować, szczególnie gdy pojawiły się jakieś nowe wydania.
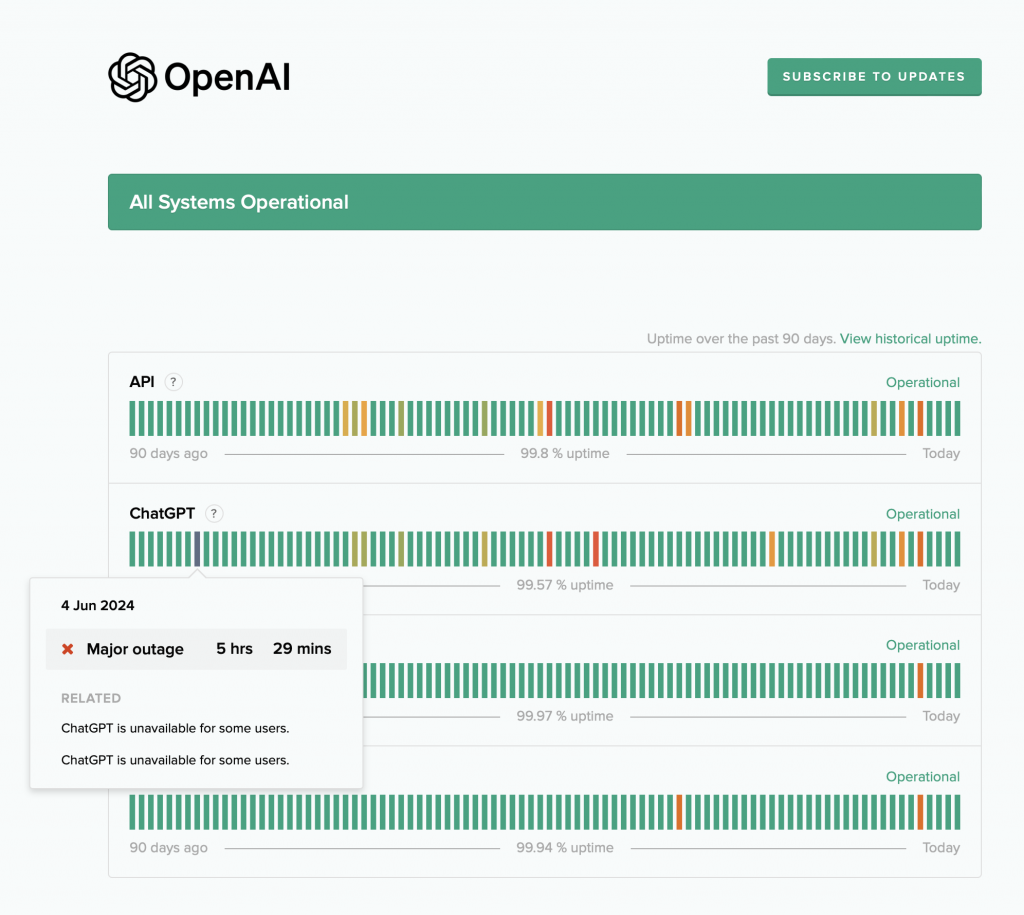
W tym przypadku nie masz tego problemu, może działać. Albo na przykład jesteś gdzieś, gdzie jest słaby zasięg albo w ogóle go nie ma. Na przykład jak ja latam samolotami, to lubię popracować, bo to jest jakiś taki fajny stan umysłu i skupienia. No i działam sobie. W ogóle nie przejmuję się tym, że w tej chwili nie mam łącza. Uruchamiam sobie. Jest to bardzo wygodne. To jest taki komfort, kiedy na przykład wychodzisz gdzieś do parku albo jeszcze gdzieś, to i tak masz dostęp do tego, co chcesz zrobić, uruchamiasz i to masz. Więc tak zwane offline modele są czymś fajnym.
Ja też powiedziałem, które modele można uruchomić na laptopie, bo faktycznie nie wszystkie modele da się uruchomić z różnych powodów. Jeden powód to, że po prostu fizycznie możesz się nie zmieścić w pamięci, a drugi powód, że to może być też bardzo wolne.
SLM – Small language model
I to wszystko zrodziło ten trend, który nazywa się właśnie small language model, czyli małe modele językowe. Jeden z takich modeli, który stał się dość popularny, opracowany przez Microsoft, nazywa się Phi.
Teraz jak nagrywam ten podcast, to już jest dostępny Phi 3.5. Bardzo fajny model. Ja sobie go ostatnio potestowałem. Pięknie działa. To jest model taki dość lekki.
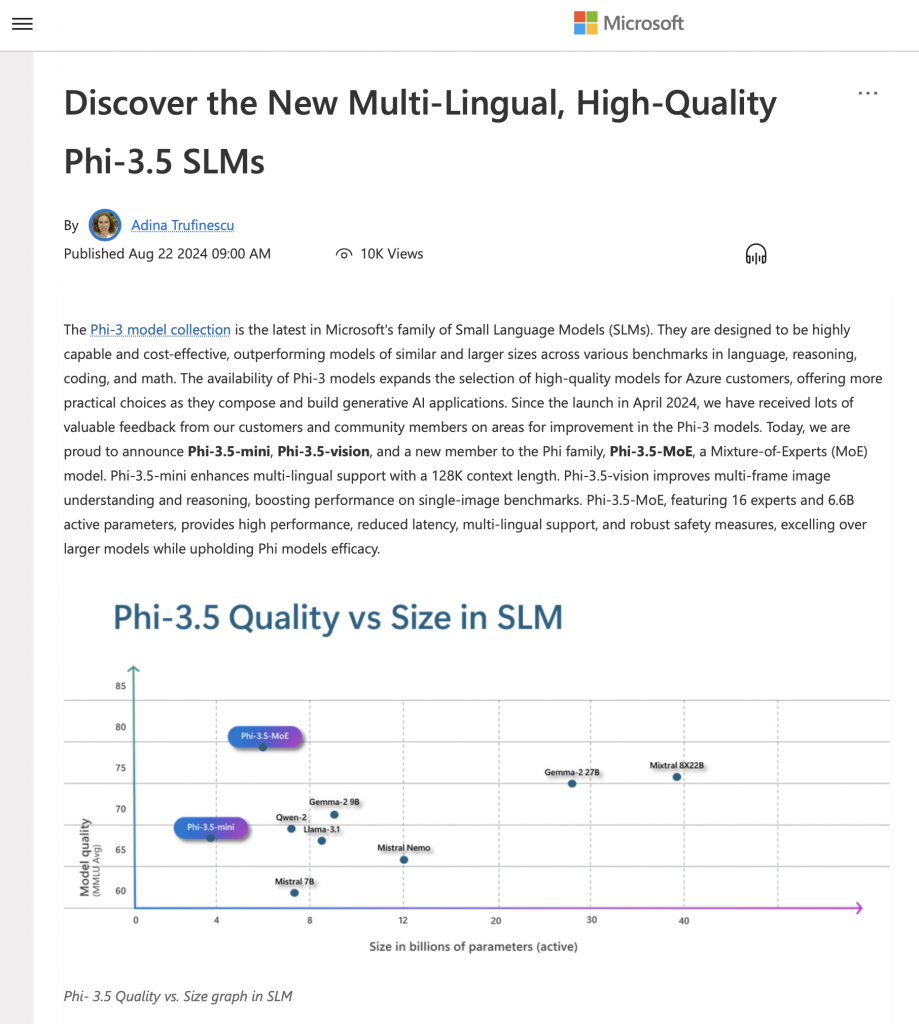
Benchmark pokazuje, że ten model, który ma dwa z kawałkiem miliarda parametrów, potrafi przebić na przykład Llama, która ma tam około ośmiu. Więc pod tym względem to wygląda całkiem dobrze.
Chociaż tam trzeba uważać, bo pamiętam w poprzednich wersjach Phi, o czym wspomniałem w poprzednich odcinkach podcastu, były takie tak zwane przecieki, kiedy te modele były trenowane wprost też na benchmarkach i tu trzeba zwracać uwagę, czy przypadkiem ten model nie pokazuje dobrych wyników tylko na benchmarkach, ale poza tym ma pewne wady.
Natomiast ten trend małych modeli językowych faktycznie się rozpędza. Tak jak powiedziałem, rodzina modeli Phi, tu trzeba zwrócić uwagę, też są takie modele od LLaMA, tym mniejsze, Mistrala i jeszcze kilka innych, ale na przykład te chyba trzy to są takie najważniejsze, na które warto zwrócić swoją uwagę, aby to uruchomić.
Teraz pojawia się też pytanie, a co jeżeli zrobić, jak mamy model większy, który się nie mieści do pamięci, na przykład 70 miliardów parametrów, a tym bardziej 400. Tutaj oczywiście są pewne też techniki. Dziś ja o tym nie będę mówić, tylko na razie wspomnę, że takie coś jest jak kwantyzacja.
Czym jest kwantyzacja?
To fizycznie oznacza, że po prostu zmniejszamy ilość informacji, które posiadamy w naszym modelu. Dzięki temu po prostu potrzebujemy mniej pamięci, żeby taki model uruchomić. To jest fajne, ale zwykle też tracimy na jakości. O kwantyzacji trzeba porozmawiać troszkę więcej i osobno, nie chciałem za bardzo tego tematu spłycać.
W skrócie chodzi o to, że to jest kompromis, że skoro zmniejszamy model, to oznacza, że coś tracimy, ale też tracimy pewnie na jakości. Chociaż tam czasem są takie ciekawostki, różne badania, gdzie w pewnych przypadkach badałem, to nie zawsze jest tak, że zawsze tracimy na jakości. Są czasem paradoksalne sytuacje, ale zwykle domyślnie faktycznie tracimy na jakości, ale nadal to może być wystarczająco dobre, żeby taki model posiadać i uruchomić, i wykorzystywać w praktyce.
Audytowalność rozwiązania
Jeszcze chciałem dzisiaj, oprócz tego, że porozmawialiśmy o takich rzeczach, że mamy kontrolę nad danymi, czyli to fajnie mieć tą władzę, mamy kontrolę nad modelem. Kolejna rzecz, którą też możemy osiągnąć uruchamiając model lokalny, to łatwiej nam będzie spełniać takie warunki, które nam są narzucane poprzez regulacje, na przykład GDPR, albo chociażby amerykański standard, albo chociażby już słynny EU AI Act, który będzie pomału tutaj wkraczał nie tylko de jure, ale też de facto, bo tamten zegarek już się liczy i od stycznia pewne rzeczy będą z stycznia 2025 roku będą obowiązywać.
Kiedy my mamy kontrolę nad tym, jak dane nasze przepływają, jaki model wykorzystujemy, kto konkretnie ma i kiedy tam dostęp, co dokładnie się dzieje z tymi dostępami, z tym procesowaniem itd., to wszystko powoduje, że nam będzie łatwiej kontrolować również prawnie takie tematy.
Self-hosted LLM
Tutaj oczywiście warto sobie postawić taką kreskę, jeżeli chodzi o kontrolowanie, że możemy to uruchamiać na laptopie i dzisiaj w sumie bardziej o tym chciałem mówić, za chwilę jeszcze powiem o kilku narzędziach, ale też możemy uruchamiać to na tak zwanych warunkach self-host, czyli sami hostujemy to na naszym komputerze, do którego mamy kontrolę.
O self-hosted będę mówić pewnie w osobnym odcinku podcastu albo w jakimś innym formacie, bo tam są fajne szczegóły. Zresztą też mam zamiar wystąpić na jednej konferencji, gdzie będę mówić wprost o inferencji modeli.
Natomiast dzisiaj chciałem bardziej mówić o takim lokalnym uruchomieniu modeli, bo to też jest możliwe i może się okazać, że to wcale nie jest aż tak skomplikowane, nawet jak nie jesteś osobą techniczną. Już powiedziałem o Ollama, powiedziałem też o LM Studio, powiedziałem też o alternatywie ewentualnej LM Studio i Jan AI.
llama.cpp
Też jest takie narzędzie, które nazywa się llama.cpp. To jest w ogóle ciekawe narzędzie. Ono jest bardziej takie back-endowe. To jest narzędzie, które jest napisane w języku C++, albo C plus plus, jak tam kto lubi wymawiać.
To jest ciekawy człowiek, który mieszka sobie w Bułgarii, dobrze się zna na języku C++, nie jest ML-owcem, ale przez to, że sobie pewne rzeczy gdzieś tam nauczył, jeżeli chodzi o formaty i tak dalej, to był w stanie przygotować takie rozwiązania. To jest piękna historia pod kontekstem One Man Team, kiedy my żyjemy w czasach, kiedy faktycznie jeden człowiek może być takim bohaterem, który potrafi zrobić coś, co później wykorzystuje wiele osób.
Zresztą jak wejdziesz sobie na GitHub, czyli gdzie ten kod jest przyszykowany, no to widzimy tam, jak to nagrywałem, to było ponad 60 tysięcy tak zwanych gwiazdek. Dlaczego na to zwracam uwagę? To nie chodzi o to, że to jakiś tam prestiż, chociaż to też, ale bardziej chodzi o to, że ja osobiście stosuję ten filtr, kiedy mamy mnóstwo różnych informacji i kiedy próbuję zrozumieć, czy coś ma sens, czy to zasługuje na moją uwagę, żeby ja to zbadał osobiście, no bo ilość narzędzi, które powstaje jest znacznie, znacznie szersza niż to, co możesz zbadać osobiście, a ja wolę sprawdzać rzeczy osobiście, przynajmniej te, które zasługują na tę uwagę.
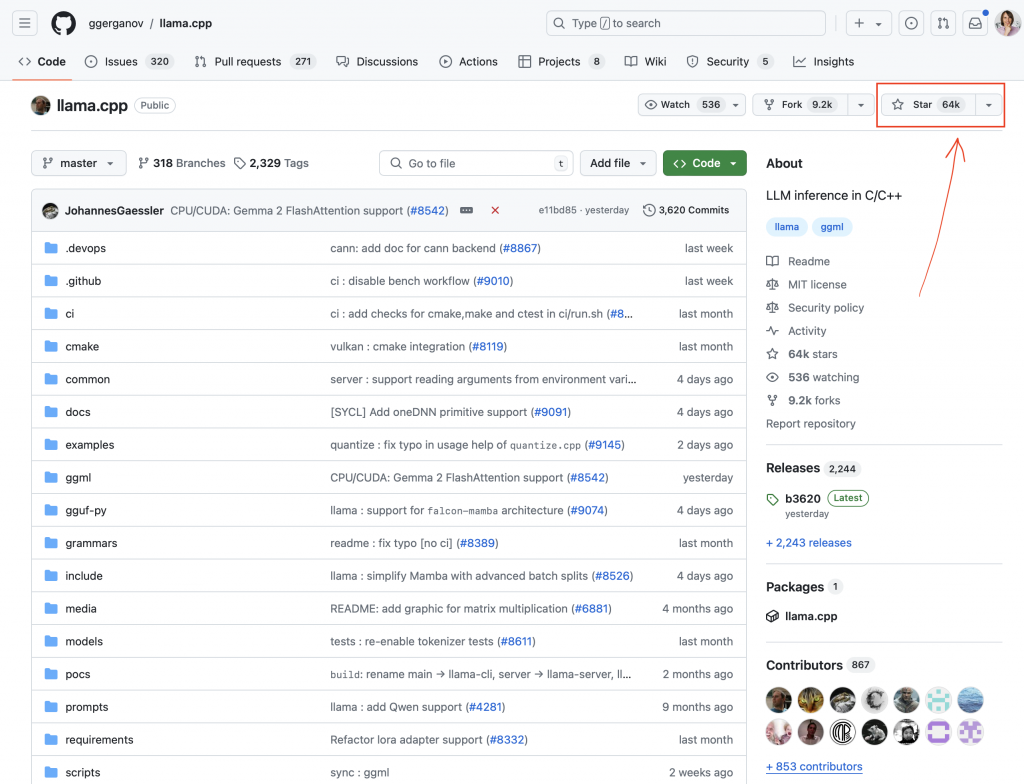
I tutaj masz tą liczbę ponad 60 tysięcy gwiazdek, to jest dość duże, więc to jest taki jeden z filtrów, który Ci pokazuje, że społeczność docenia. I to narzędzie oczywiście jest takie bardziej techniczne i to, co ono umożliwia, to po prostu uruchamiać ten model w konsoli, czyli pobierasz sobie model, uruchamiasz go, tam oczywiście trzeba spełnić warunek w odpowiednim formacie, ale na szczęście w GitHubie też są różne konwertery, które mogą ci pozwolić to zrobić.
OpenWebUI
I później, jak to uruchomisz, to możesz potem też udostępnić poprzez API, żeby później wykorzystać to na przykład w jakimś tam frontendzie. Jeszcze o jednym może teraz, bo wspomniałem o backendach, albo wspólnych narzędziach, ale jest takie też bardziej ta druga końcówka, kiedy mamy sam UI, ale nie ma backendu, ten UI może gdzieś się podpiąć. I na przykład jest takie narzędzie, jak nazywa się OpenWebUI, albo też jest LibreChat.
Open WebUI chyba jest jeden z najbardziej popularnych. To działa w taki sposób, że uruchamiasz go, to wizualnie nawet z miary przypomina ChatGPT i później się integrujesz z backendem. Albo to może być Ollama pod spodem, o którym wcześniej wspomniałem, albo to może być też LM Studio, albo jakieś inne, na przykład API.
Na przykład z Jana możesz sobie udostępnić API, która jest kompatybilna, czyli jakby wygląda podobnie, jakby dosłownie ten URL i te różne parametry, jak to udostępnia ChatGPT, to de facto stało się takim pewnym standardem.
I w ten sposób się integrujesz, czyli masz tak zwany backend, masz frontend, frontend rozmawia z backendem, no i ty wtedy jesteś w stanie zutylizować to rozwiązanie. Na przykład, jeżeli mówimy o takim rozwiązaniu prywatnym, albo też wewnątrz firmy, czyli wewnątrz tej strefy, która jest dostępna wewnątrz firmy, to takie OpenWeb UI może być przydatne.
Jeszcze dzisiaj chciałbym wspomnieć, bo teraz mówiłem o narzędziach związanych bardziej z tekstem, czyli mamy modele LLM. Wspomniałem takie modele, które są dostępne jak Phi, albo LLAMA, albo Mistral, można to pobrać. Później wykorzystując takie narzędzia jak Ollama, LM Studio, Jan, albo llama.cpp, możemy to wykorzystać w ten czy inny sposób w terminalu, albo podpinając bardziej piękniejsze UI.
Zewnętrzne, albo takie, które już jest dostępne w narzędziach, na przykład ten Jan, o którym wspomniałem, to od razu jest dostępne w narzędziach, albo też jest takie narzędzie Anything LLM, na przykład jest jeszcze kilka innych. Natomiast oprócz pracy z tekstem, mamy też inny rodzaj informacji, na przykład audio.
whisper.cpp
I ja z audio osobiście dużo pracuję, bo na przykład jak nagrywam podcast, to dostaję właśnie audio, i później z tym audio robię różne rzeczy. I jedna rzecz, która powstaje, to jest transkrypt, czyli mam dźwięk, na przykład mówię teraz po polsku, i tą transkrypcję potem konwertuję w postaci tekstu. I tutaj użyłem narzędzia whisper.cpp.
To jest narzędzie, które właśnie autor ten sam, który napisał llama.cpp, stworzył. Natomiast sam algorytm był wymyślony oczywiście przez bardziej zaawansowane firmy, w tym przypadku to było OpenAI. Na szczęście OpenAI udostępniło to rozwiązanie.

Zresztą Whisper jest dostępny poprzez API, czyli możesz wrzucić do OpenAI swój plik taki zewnętrzny, czyli wrzucasz tam, ono przetwarza, dostajesz transkrypcję.
I znów zmieniając historię to, że i tak musisz wrzucić tam plik, musisz mieć dostęp do internetu, to chwilę też trwa, masz mniejszą kontrolę, nie możesz sobie uruchamiać na poszczególnych tam jakichś elementach. Więc dla mnie osobiście to, że mogę to uruchomić na swoich własnych zasadach, na przykład na laptopie, kiedy na przykład nie lecę w samolocie, nadal mogę sobie pracować i działać, daje duży komfort.
Tym bardziej, że na przykład taka konwersja dużego odcinka, godzina, trwa nie tak długo, to bardziej w dziesiątkach minut, albo nawet trochę mniej. Taki krótszy filmik, to będzie jeszcze oczywiście szybciej. Uruchamiam to na przykład na tym laptopie, na moim Mac. Wiadomo, to różna moc komputerowa może dawać różne wyniki.
Warto się pokazać, że to nie jest tak, że czekam tydzień, żeby zrobić transkrypcję tego audio. Też jeżeli chodzi o jakość, tam są różne dostępne modele, ja wykorzystuję ten model Large w wersji trzeciej, i to daje całkiem dobrą jakość, jeżeli chodzi o wyniki. Ja pewnie o tej transkrypcji zrobię coś jeszcze.
Pokażę pewnie o tym więcej, czy to szkolenie, czy webinar, pomyślę jak to zrobić, bo kilka takich ciekawostek gdzieś tam czasem się nauczyłem, tak bardziej empirycznie. Tak jak powiedziałem, że staram się łapać wszystkie sygnały, które słyszę dookoła, ale są takie rzeczy, które osobiście sprawdzam, bo wtedy człowiek lepiej czuje, co to daje, jakie daje to możliwości.
GPT-4 All
Jak widzisz, że oprócz tekstu, to możemy pracować też z audio, ale również oprócz tekstu i audio, możemy też na przykład pracować z obrazkami. I tutaj na przykład takie modele, które są dostępne, znaczy narzędzia właściwie, GPT-4 All, to tam między innymi mamy takie modele, które już, zresztą to jest pobierane automatycznie, jak to zbieramy, pobieramy to narzędzie, do pracy z obrazkami.
Na przykład możemy sobie ten obrazek opisać, sobie z tym obrazkiem i następnie też porobić różne rzeczy. No na przykład, gdzie to może być przydatne? Załóżmy, że mamy strumień informacji i musimy sobie monitorować, czy to jest zgodne z naszymi przepisami, które mamy w firmie. Na przykład, czy tam ktoś nie wrzuca jakieś dziwne zdjęcia, zakazane zdjęcia, takie rzeczy, które tam nie powinny być.
To tutaj taki wyproszony flow jest taki, że pierwszy model, który sami kontrolujemy, on konwertuje obrazek na opis tekstowy, to jest pierwszy wynik. Drugi flow, który mamy, to nasz model, który my kontrolujemy i piszemy tam zasady różne, co chcemy sprawdzić, na przykład, czy tam jest ktoś, nie wiem, nagi albo czy tam jest rzecz jakaś zakazana, nie wiem, jakaś broń i tak dalej.
I po prostu stworzymy sobie taką własną politykę, 10, 15, 50 pytań. I następnie też to sprawdzamy, no i potem patrzymy na wynik, czy gdzieś tam wyskoczyła flaga. No, ewentualnie też na końcu może być człowiek, bo tak naprawdę, jak mamy duży strumień i tam, gdzie jest pewne, że jest okej, to przepuszczamy. Tam, gdzie jest niepewność, to po prostu zawsze też może człowiek jeszcze sprawdzić. Dzięki temu znacząco bardziej odciążamy, jeżeli chodzi o ilość rzeczy, które ten człowiek musi sprawdzić. No i takie rozwiązanie możemy po prostu mieć w 100% w swojej kontroli, tak jak powiedziałem przedtem, to jest ta rzecz, na której nam znacząco może zależeć. No to dobrze, to ja już w sumie powiedziałem takie rzeczy najważniejsze.
Spróbuję podsumować, jeżeli chodzi o narzędzia, które wspomniałem i rzeczy, na które warto było zwrócić swoją szczególną uwagę, bo na przykład jeżeli chodzi o modele lokalne, to dość często jest wspomniane na przykład dostęp 24 na 7, albo przyspieszenie, albo też oszczędzanie. I tutaj z jednej strony ja z tym się zgadzam, z drugiej strony niekoniecznie, bo to już zależy od kompetencji, które posiadasz.
Bo faktycznie faktem jest to, że na przykład takie modele, które są udostępniane poprzez OpenAI, czasem są niedostępne. I to jest problem, prawda? Wyobraźmy sobie, że masz core produkt, który jest oparty na tym, żeby wykorzystywać API ChatGPT w ten czy inny sposób. I przez moment, przez godzinę, dwie albo dłużej jest to niedostępne, albo znacząco spowolnione, albo przerywa ci i ty dostajesz cały czas taki fail. To co wtedy?
Znowu kompetencje, które posiadamy, są niewystarczające i może się okazać, że de facto robimy to bardzo nieefektywnie. Ale długofalowo, jeżeli faktycznie budujemy taką kompetencję wewnątrz firmy, wewnątrz naszego zespołu, to długofalowo faktycznie możemy zacząć wygrywać i to na różnych poziomach, zaczynając od optymalizacji poszczególnych architektur.
Tam są takie różne ciekawostki, jakieś cache, można to współdzielić na różne sposoby, różne narzędzia, które to też umożliwiają. To jest jedna historia. Druga historia to lepsze poznanie charakterystyki narzędzi, na przykład jak wykorzystujemy je w dni robocze, to wtedy to działa, a w innych dniach po prostu to wyłączamy.
To też jest ciekawostka, co to znaczy w praktyce. Bo jeżeli to jest nasza karta GPU, to ona po prostu jest wtedy, kiedy jest, a kiedy my potrzebujemy dwa razy więcej kart, to jakby nie mamy, bo jak działamy fizycznie, czyli to jest komputer, który stoi u nas na przykład w budynku czy tam gdzieś. Druga sprawa, jak mamy chmury, to faktycznie z chmurami jest to komfortowo, bo można sobie jakoś tam zrezerwować te karty, włączać, wyłączać. Tam są pewne niuanse, ale tam jest to bardziej elastyczne.
Tam jest pewne wyzwanie pod warunkiem znowu à propos danych, bo te dane gdzieś tam wysyłamy. To trzeba uważać. To być może nie jest równoznaczne z tym, co mówiłem, jeżeli chodzi o wysyłanie wprost przez ChatGPT, ale nadal te dane wysyłamy. Zresztą na przykład to są takie serwisy, które ja sobie jeszcze uwielbiam, jeżeli chodzi o takie szybkie uruchomienia GPU, na przykład takie RunPod lub podobne. To tam faktycznie oni zrobili to na tyle teraz wygodne, kiedy ty potrzebujesz to szybko sobie nawet na poziomie Pythona możesz podnieść maszynę, nawet na takie duże modele jak nie wiem, na przykład Llama 3 – 400 miliardów parametrów.
Szybko uruchamiasz przez moment, kiedy wykorzystujesz to wykorzystujesz, później ją składasz i to generuje ci minimalny koszt. Ale pamiętaj, to zawsze jest tak, że jak jest wygodne, to jest też ryzyko, to zawsze towarzyszy obok siebie. Czyli jak coś się staje bardziej wygodniejsze, jeżeli chodzi o stworzenie pewnych rzeczy, to gdzieś tam może się pojawić ryzyko. W tym przypadku ryzyko polega na tym, że skąd możemy gwarantować, że dane, które tam wysyłamy gdzieś tam właśnie nam nie wyciekną.
Wiadomo, zawsze trzeba patrzeć na to, co nam mówi regulamin, ale też wiemy, że regulamin to jest jedna historia, druga historia to jest egzekucja tego, co tam jest napisane. Więc tutaj mogą pewne pytania się pojawić i to akurat kwestie zostawiam dla ciebie. Teraz bardziej próbuję powiedzieć, że takie rzeczy mogą być.
Jeszcze jeśli chodzi o takie pomysły, które gdzieś mogą wybrzmieć, to większa kontrola nad modelem nie tylko w takim względzie, że jest powtarzalność, ale też na przykład fajne tuningi. O fajnych tuningach ja już mówiłem w osobnym odcinku podcastu z Remigiuszem i tam faktycznie wspomniałem bardziej to podejście, że nie zawsze potrzebujesz fine-tuningu, bo to trzeba umieć zrobić dobrze i to jest zwykle coś innego niż tylko uruchomić go. Czyli kontrolowanie dobrego fine-tuningu wymaga pewnych kompetencji i wysiłku, więc zwykle to nie jest ten przypadek taki powszechny.
Ale faktycznie czasem, jeżeli potrzebujesz taki fine-tuning zrobić, to tym bardziej to jest taki duży komfort, kiedy faktycznie ten model posiadasz u siebie. Bo masz model oryginalny, masz ten, który zmieniłeś, on jest 100% zamrożony, leży tam gdzieś w folderze, który sobie wskazałeś i działa w taki sam sposób, mimo tego, że wszystko dookoła może się zmienić. To jest wygodne, czyli jeżeli faktycznie my potrzebujemy fine-tuningu i mieć na tym kontrolę, robimy to dobrze, wiemy jak to zmierzyć, jak sprawdzić, czy tam faktycznie coś się nie popsuło po drodze, to wtedy ta umiejętność kontrolowania tego naszego modelu tym bardziej nam się sprawdza.
Istnieje wiele przykładów, o których ja sobie jeszcze patrzę z ostrożnością, tak to nazwijmy, kiedy widzę, że na przykład model Llama 3 albo podobny, który był fine-tuningowany i oni przebijają na przykład GPT-4 w różnych jakichś tam kompetencjach. Fajnie, wygodne, tutaj trzeba oczywiście na to uważać, ale faktycznie to jest możliwe, żeby konkretnie pod Twój problem tak zmodyfikować model, żeby ten model działał najlepiej dla Ciebie.
To oczywiście, tak jak powiedziałem, wymaga pewnej kompetencji, nie tylko, żeby zrobić to raz, ale też, żeby później pewnie to powtarzać regularnie, też mieć takie różne, nazwijmy to, bramki jakości, aby się upewnić, że to, że model działa dobrze, to co powinno i też również, że nie zepsuło się to, co nie powinno. Czyli wszystko jest zgodnie z tą jakością, którą oczekujesz. To wszystko da się wypracować i jeżeli faktycznie to jest ta rzecz, która w Twoim przypadku obowiązuje, no to tym bardziej takie modele lokalne LLM mogą być przyjemniejsze pod tym względem, no bo masz kontrolę nad tym.
A kontrola w LLM to jest rzecz, która jest konieczna. To nie jest tylko taka zachcianka, że może być, ale nie musi, ale zwykle kontrola w LLM-ie to jest rzecz, która jest krytyczna z punktu widzenia produkcyjnego. Bo jeżeli tego nie zapewnisz sobie, no to może być pewne wyzwanie, żeby później nie było jakichś takich różnych, niepożądanych zjawisk.
Wkrótce to byłoby tyle na dzisiaj. Zaraz jeszcze szybko sobie to podsumujemy, to co wybrzmiało. Mam nadzieję, że przynajmniej udało się przedstawić najważniejsze rzeczy, a mianowicie, że jak już model mamy wytrenowany, to oprócz tego, że mamy dostępne opcje, że ktoś za nas ten model uruchamia, udostępni nam tylko możliwość poprzez na przykład taką stronę WWW, żeby my z tym modelem rozmawialiśmy, albo poprzez API, bo tak jest najwygodniej.
Ale najwygodniej nie znaczy zawsze najlepiej, prawda? To również są takie możliwości, że możemy ten model sobie pobrać. No nie wszystkie modele możemy sobie pobrać, ale są takie, które możemy pobrać. Oczywiście warto zawsze czytać sobie licencje, na przykład chociażby wracając do wielu modeli, które są dostępne, oni często mają takie coś, że można ich wykorzystywać, można ich pobrać, ale nie komercyjnie.
Albo żeby wykorzystywać komercyjnie, to należy się zgłosić, no i dostać taką zgodę. Na przykład modele Cohera, o którym wspomniałem, albo chociażby w Polsce model Bielik w wersji pierwszej, tam wprost możesz zobaczyć, że do niekomercyjnego użytku. Ja wiem, że de jure jest jedno, de facto może być drugie, ale zwracam na to twoją uwagę. Więc jak taki model pobierzesz, sprawdzisz sobie licencję, wszystko się zgadza, to wtedy możesz go uruchomić.
Są różne narzędzia, najważniejsze narzędzia, które tutaj dzisiaj wybrzmiały takie weekendowe, to jest Ollama, LM Studio, które ja w tej chwili już mniej wykorzystuję. Na początek bardziej wykorzystywałem, a nie wykorzystuję bardziej z powodu związanego z regulaminem, który dla mnie brzmi trochę tajemniczo. Jak narzędzia tego typu formatu, bardziej przerzuciłem się na taki model, na takie narzędzie, które nazywa się Jan. Jeszcze oprócz tego jest takie narzędzie jak llama.cpp, to jest takie bardziej weekendowe, techniczne narzędzie, ale jest fajne.
Lubię uruchomić, bo to daje też większą kontrolę i rozumienie, co dzieje się pod spodem. Albo też narzędzie podobne do tego samego autora, jeżeli chodzi o taką nakładkę, nazywa się whisper.cpp. To jest narzędzie do robienia na przykład transkrypcji z audio.
Oprócz tego też, że możemy to właśnie weekendowo uruchomić, to czasem są narzędzia, które od razu mają UI albo frontend, że możemy w taki sposób okienkowo wejść w interakcję. Ale są też takie narzędzia wprost, osobne, które skupiają się tylko na UI.
Open Web UI to narzędzie, które po pobraniu i uruchomieniu wymaga skonfigurowania backendu, czyli sposobu, w jaki będziemy wykorzystywać modele. Możesz użyć tych, które wcześniej wspomniałem. Pozwala to na rozmowę z modelami lokalnymi. Jakie to daje korzyści? Powtórzmy to. Przede wszystkim kontrolowanie danych – to ty kontrolujesz, co się dzieje z tymi danymi, jak one przepływają. Wszystko może zostać albo wewnątrz tego komputera, albo wewnątrz twojej organizacji.
W niektórych przypadkach jest to konieczne i krytyczne, zaczynając od tego, żeby wrażliwe informacje handlowe czy ważne fragmenty kodu nie wyciekły na zewnątrz. Również regulacje prawne ograniczają niektóre firmy w zakresie tego, co mogą robić z danymi. Chodzi o to, by nie kopiować czy udostępniać swoich danych, a także lepiej kontrolować dane prywatne, takie jak imię, nazwisko, adres e-mail itp.
Te informacje nie mogą wyciekać na zewnątrz, więc wtedy musisz mieć rozwiązania, nad którymi masz większą kontrolę. Pierwsza korzyść jest więc taka, że jeśli kontrolowanie twoich danych jest dla ciebie konieczne i krytyczne, to powinieneś zwrócić uwagę na tego typu rozwiązania. Druga korzyść jest taka, że jeżeli twoja firma podlega dodatkowym regulacjom, oprócz tych standardowych, na przykład w przypadku organizacji finansowych i podobnych, to tym bardziej powinieneś zainteresować się takimi rozwiązaniami.
Oczywiście, nadal istnieją rozwiązania takie jak model OpenAI w Azure, który, jak już wcześniej wspomniałem, ma pewne wytyczne sugerujące, że nic złego nie robią z danymi. Jednak warto to skonsultować z prawnikiem, czy nadal wszystko się zgadza, bo twoje dane fizycznie gdzieś tam wędrują. Warto się upewnić, czy to ma sens, chociaż trzeba przyznać, że Microsoft postarał się maksymalnie zaznaczyć, że wszystko będzie w porządku. Czy tak będzie, to już zostawiam twojej własnej interpretacji.
Jeśli chodzi o regulacje, modele lokalne mogą być bardzo korzystnym rozwiązaniem. Kolejną korzyścią może być możliwość pracy offline, czyli niezależnie od dostępu do internetu, oraz dostępność 24/7. Chcesz mieć kontrolę nad tym, że model będzie dostępny zawsze, kiedy tego potrzebujesz. Z punktu widzenia biznesu może to być ważne, bo jeśli użytkownik korzysta z twojego produktu opartego na takim rozwiązaniu, chcesz, aby ten produkt był dostępny przez określony SLA, który sobie ustalisz.
Należy sprawdzić, na ile to się zgadza z zewnętrznymi rozwiązaniami. Faktycznie, wykorzystując modele lokalne, możesz sam zarządzać dostępnością. Wymaga to oczywiście pewnych kompetencji, które można pozyskać na rynku, ale wtedy przynajmniej kontrolowanie dostępności jest po twojej stronie. Jak wspomniałem wcześniej, jeśli chodzi o pracę offline, możesz wykorzystać takie modele nawet bez dostępu do internetu.
Warto też wspomnieć o jakości tych modeli. Faktycznie, mniejsze modele, szczególnie te najmniejsze, robią całkiem spore postępy. Wspomniałem już o modelu z rodziny Phi, rozwijanym przez Microsoft. W momencie nagrywania jest to model Phi 3.5. To model, który mimo że jest mały (mniej niż 2 miliardy parametrów), osiąga całkiem dobre wyniki. Potrafi prowadzić rozmowę, generować kod i wykonywać wiele innych ciekawych zadań.
To byłoby tyle, jeśli chodzi o uruchamianie modeli LLM i nie tylko, czy też innych modeli lokalnie u siebie. Chciałbym jeszcze wyjaśnić skrót PC AI na koniec. AI to szersze pojęcie, obejmujące różne technologie sztucznej inteligencji. LLM to praca głównie z tekstem, czyli duże modele językowe. Mogą być też inne modele, na przykład do przetwarzania obrazu (computer vision), wideo, dźwięku itd. AI to taki parasol nad tym wszystkim, a PC AI odnosi się do uruchamiania tych technologii lokalnie na komputerze.
Jak widzisz, te hasła są różne, ale mają pewne wymiary, w których się poruszamy. Gdy to zrozumiesz, łatwiej będzie się w tym wszystkim odnaleźć. Na koniec bardzo chciałbym prosić cię o reakcję – postaw lajka, w zależności od tego, gdzie słuchasz, subskrypcję lub follow, w zależności od platformy, której używasz. Bardzo proszę też o podzielenie się komentarzem – co o tym wszystkim myślisz i, co dla mnie ważne, czy masz już doświadczenie z uruchamianiem i wykorzystywaniem modelu lokalnego, albo czy zamierzasz to zrobić.
Fajnie by było, gdybyś podsumował to, co de facto usłyszałeś w tym odcinku, co było najważniejsze. Ja zawsze staram się przekazać pewne rzeczy i przed nagraniem robię sobie notatki, próbując doprecyzować, co chcę przekazać. Jestem ciekaw, czy faktycznie to, co próbuję przekazać, dotarło do ciebie, bo różnie może to być interpretowane. Te same słowa, inaczej ułożone czy użyte w innej kolejności, a tym bardziej gdy użyje się innych słów, mogą zmienić sens przekazu. Dlatego bardzo proszę, napisz w komentarzu, co wyniosłeś z tego odcinka.
I prośba: poleć proszę ten odcinek przynajmniej jednej osobie, dla której może być interesujący i ciekawy. Dzięki temu poszerzamy zasięg. Dla mnie to też motywacja, aby dalej kontynuować i dzielić się z tobą moim doświadczeniem. To dla mnie frajda, choć znowu udało się znaleźć czas tylko w weekend, bo w dni robocze są inne obowiązki – różne e-maile czy spotkania. Ale staram się utrzymywać regularność, mimo że czasem wymaga to pewnej dyscypliny i napięcia, żeby się wyrobić.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
