
Jak rozmawiać ze sztuczną inteligencją?
Witam Cię w kolejnym odcinku podcastu Biznes Myśli! Nazywam się Vladimir Alekseichenko i na Biznes Myśli zgłębiamy biznesowe mechanizmy, rozkładając na czynniki pierwsze takie zagadnienia jak ludzie, pieniądze, procesy, innowacje i trendy. Jestem praktykiem sztucznej inteligencji, z sukcesami trenującym modele uczenia maszynowego i wdrażającym je w biznesie tak, aby przynosiły realne zyski.

W dzisiejszym odcinku, przygotowanym przy wsparciu DataWorkshop, firmy, którą miałem przyjemność założyć i nadal prowadzę. W czym DataWorkshop może być pomocny dla Ciebie? Praktyczny AI, czyli jak potrzebujesz przeszkolić swój zespół z praktycznego ML, nauczyć się planować i projektować rozwiązania ML we właściwy sposób i ostatecznie też wdrożyć taki model na produkcję, koniecznie skontaktuj się z nami. Zaufali nam tysięcy ludzi w tym duży graczy, takie jak: Orange, MBank, Leroy Merlin i wiele innych.
Uwaga! Już wkrótce ruszamy z szkoleniem, które pomoże rozwinąć umiejętności efektywnej komunikacji z AI. Zachęcam do zapisania się na listę chętnych. To świetna okazja, by zdobyć kompetencje, które staną się niezbędne w niedalekiej przyszłości. Zapisz się dzisiaj.
A ja przechodzę do dzisiejszego odcinka podcastu: jak rozmawiać ze sztuczną inteligencją? Gościem odcinka jest Cezary Kuik, mój były kursant, który od czasu ukończenia szkolenia zrobił ogromny progres i dziś, pracując w dziale ML R&D w Allegro, podejmuje strategiczne decyzje.
Vladimir: Cześć! Dziś porozmawiamy o tym, jak efektywnie komunikować się z AI. Moim gościem jest Cezary Kuik, Product Manager w dziale Machine Learning Research w Allegro. Cezary, przedstaw się proszę naszym słuchaczom.
Cezar: Cześć Vladimir, cześć wszystkim! Bardzo się cieszę, że mogę być częścią tego podcastu. Na co dzień pracuję jako Product Manager w Allegro, w Departamencie Machine Learning Research – to taki zespół, który bada, jak możemy masowo wykorzystać machine learning. Nasza praca często polega na eksplorowaniu tematów, które są jeszcze niepewne, ale ktoś musiał podjąć to ryzyko, więc to właśnie my :). Moja specjalizacja to modele generatywne, takie jak ChatGPT, Gemini oraz inne mniej znane modele, które również mają duży potencjał. Moim zadaniem jest, aby nie tylko podążać za nowinkami technologicznymi, ale przede wszystkim znaleźć dla nich praktyczne i użyteczne zastosowanie.
Vladimir: Zapowiada się super rozmowa, ale na początek, tak jak zwykle, zgodnie z tradycją, powiedz, co ostatnio fajnego przeczytałeś, podziel się z naszym słuchaczem jakąś fajną lekturą.
Cezary: Muszę się z bólem serca przyznać, że nie czytam książek. Ale to nie tak, że w ogóle nie czytam! Wiesz, w dzisiejszych czasach sposób konsumpcji treści się zmienił. Podobnie jak w odcinku z moim kolegą Piotr Rybakiem – on to świetnie wyjaśnia. Mam wrażenie, że czytam bardzo, bardzo dużo, ale po prostu z różnych źródeł w internecie. Od blogów i artykułów naukowych po komentarze na Reddicie czy innych forach. Niestety, nie mam książki do polecenia, ale mogę zasugerować kilka świetnych stron o AI lub publikację np. ostatnio czytałem fantastyczny i trochę prowokacyjny artykuł o tym, dlaczego RAG-i nie będą działały w korporacjach, ale to temat na inną okazję.

Tu możesz poczytać więcej: https://arxiv.org/pdf/2406.04369
Vladimir: Temat RAG-ów pewnie jeszcze poruszymy, jeśli starczy nam czasu. Teraz jednak przejdźmy do sedna naszej rozmowy. Jak rozmawiać ze sztuczną inteligencją? Jakie są twoje myśli na ten temat? Zacznijmy od ogólnych uwag, a potem zanurzymy się w szczegóły.
Cezar: Ja się bardzo cieszę w ogóle, że właśnie tak ująłeś ten temat, że w ogóle zahaczyłeś o to słowo „rozmowy”, bo to jest taka drobnostka, może wręcz purystyczna językowo, ale mam wrażenie, że zapominamy czasami, że modele generatywne to są modele konwersacyjne, to znaczy wymagają one rozmawiania po prostu z nimi. Bo mam czasami takie (oczywiście subiektywne) odczucie, że jednak trochę zapominamy o naszej roli. Po prostu oczekujemy, że napiszemy tego prompta, napiszemy polecenie, zlecimy modelowi jakieś zadanie i model się po prostu wszystkiego domyśli.
W dobrej rozmowie jednak chodzi o to, żeby nie tylko słuchać, mówić, ale też mówić w taki sposób, aby dobrze przekazać jakieś nasze przemyślenia, oczekiwania. Jakby dobra komunikacja jest wtedy, kiedy obie strony się rozumieją, a nie tylko ta jedna, więc myślę, że dla wielu ludzi to jeszcze jest coś, co może być dla nich zaskakujące, że nie ma jeszcze takiego zrozumienia, że:
Z modelami się nie pracuje po prostu wydając im polecenia, z modelami się powinno pracować przez rozmowę z nimi, taką rozmowę, którą rozumieją obie strony.
Vladimir: Możesz mieć rację, że często traktujemy „sztuczną inteligencję” jako coś „martwego”, jakby była tylko jakimś pudłem, które sobie leży w kącie i posiada pełną wiedzę. Tymczasem kluczowe jest, by umieć się z nią dogadać. Dzisiaj o tym właśnie porozmawiamy. Najpierw jednak skupmy się na szerokim kontekście, aby wprowadzić wszystkie pojęcia, którymi będziemy się posługiwać. Krótko i na temat omówimy najważniejsze kwestie, o których warto wiedzieć, jeśli chcemy zacząć stosować generatywne modele u siebie.
Cezar: Mam taką intuicję, że zawsze jak wchodzisz do jakiegoś nowego świata, nawet niekoniecznie w technologii, po prostu, jak wchodzisz w obszar, którego nie znasz, to bardzo fajnie po grach widać. W grach zawsze masz taki tutorial, który ci tłumaczy trochę świat, w którym lądujesz i myślę, że dobrze dla tej rozmowy by było, gdybyśmy właśnie w ramach takiego tutorialu po prostu skupili się może na kilku takich rzeczach. Takie ABC, po prostu kluczowe pojęcia, rzeczy, które warto wiedzieć, aby w ogóle zacząć się poruszać w świecie modeli generatywnych. Zresztą jak ładnie przed rozmową to nazwałeś, operować trochę na takim słowniczku i spróbować go sobie w trakcie tego podcastu stworzyć, a na ten słowniczek mogą się składać takie rzeczy, jak właśnie prompt, tokeny, okno kontekstu.
Jestem przekonany, że jeśli ktoś słucha tego podcastu, to już się z tymi pojęciami prędzej czy później spotka albo już spotkał i dobrze by było, żebyśmy właśnie sobie podczas tej rozmowy ugruntowali te pojęcia i poczuli, że się dobrze w nich czujemy i je rozumiemy. Ale te niuanse są ważne i im lepiej zrozumiemy strukturę, że prompt może być inny i wynik też będzie inny, to to jest ważne, żeby poukładać sobie pięknie w strukturę te pojęcia. Więc czym jest prompt? To w ogóle nie jest wcale takie błahe zadanie, bo na papierze prompt jest czymś prostym. Gdybyśmy chcieli do tego podejść w taki naprawdę łopatologiczny sposób, to moglibyśmy po prostu powiedzieć, że prompt to jest każda wiadomość, każde polecenie, które wysyłamy do modelu generatywnego. Z perspektywy takiego użytkownika, który korzysta z ChatGPT, każda wiadomość, którą wpisujemy w okienko, to jest prompt. Ale przychodząc jakby poziom niżej, to prompt to jest tak naprawdę polecenie, którym musimy wskazać modelowi, jaki rezultat oczekujemy w ramach jego odpowiedzi.
Tutaj tak naprawdę promptem może być znowu nasze pytanie i w ramach rezultatu, którego oczekujemy od modelu, jest odpowiedź na to pytanie, na przykład, „kto strzelił gola w meczu Polska-Walia”. Tutaj oczekujemy, że rezultatem modelu, wynikiem będzie odpowiedź na to pytanie. Promptem może być na przykład instrukcja. Przepis jest jakąś formą instrukcji. Chcemy, żeby model wygenerował przepis na to, jak zrobić tort czekoladowy.
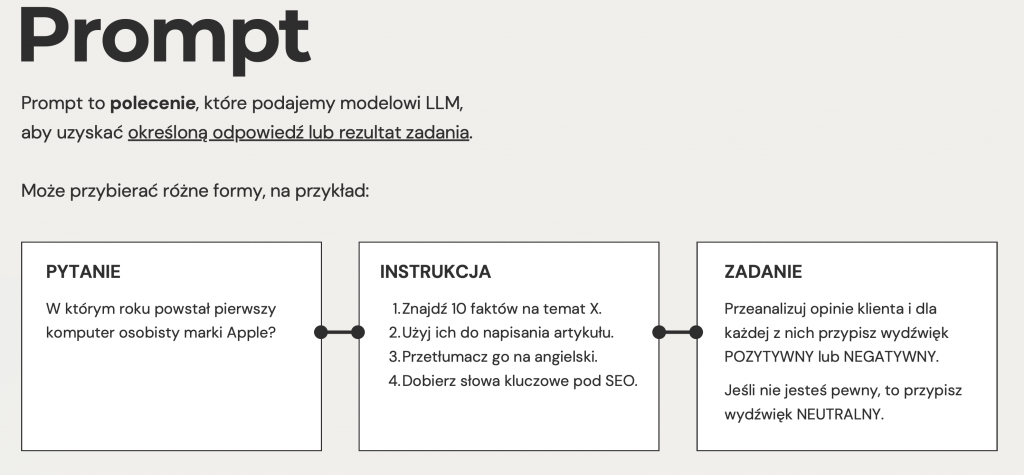
I mógłbym takich przykładów mnożyć, ale na koniec dnia jest to polecenie, które wskazuje, jakiego zadania, jakiego rezultatu oczekujemy od modelu generatywnego. Odpowiedzi na to, co napisaliśmy. Jakbym miał tak bardzo uprościć. Samego prompta moglibyśmy się jeszcze bardziej wgłębić, bo tak naprawdę gdzieś tam już funkcjonuje. Nie wiem, czy ja mogę powiedzieć, że w literaturze, bo to jest takie bardzo naukowe określenie…
Vladimir: W internetach krąży?
Cezar: Tak, w internetach krąży. To jest dużo lepsze określenie. Ale fakt faktem, że czasami w internecie można się natknąć na takie naprawdę świetne checklisty z kilkoma elementami, które powinien zawierać dobry prompt. Zresztą często są one zatytułowane „Z czego powinien składać się idealny prompt?”. Zazwyczaj wyróżnia się sześć takich elementów.
Przede wszystkim jest to cel, zadanie, po angielsku mówi się na to „task”. To najważniejsza część prompta, ta, która jasno komunikuje modelowi, czego od niego oczekujemy. Następnie jest kontekst, czyli jeżeli model już wie, czego potrzebujemy, warto dodać kontekst w prompcie, czyli po co właściwie tego potrzebujemy.
No bo okej, mogę dać modelowi zadanie w stylu „wygeneruj mi jakieś teksty” – na przykład „wygeneruj mi opis jakiegoś zwierzęcia” albo „wygeneruj mi raport biznesowy”. Ale po co? Czy to jest raport, który ma być podsumowaniem dla kogoś, kto nic nie wie o projekcie, czy dla ekspertów, którzy potrzebują szczegółowej wiedzy? Zawsze jest to pytanie: robię coś, ale po co?
Następnie pojawia się kolejny element – przykłady. Ja to bardzo często, jak tłumaczę osobom tak bardzo od zera, to podaję to na przykładzie diety. Taki bardzo prosty prompt. „Twoim zadaniem jest tworzenie diety, diety po prostu. Diety samej w sobie, czyli listy posiłków tego, co mam jeść.” Po co jest ta dieta? Kontekstem jest tutaj to, że ja w ramach tej diety chcę się odchudzić. Czyli jest to dla modelu ważna informacja, no bo wiesz, że generując treść takiej diety, powinien ją tworzyć przede wszystkim dla takich osób i z takich posiłków, których celem jest zrzucenie wagi.
I tutaj często właśnie, jako przykład elementu, wrzucam właśnie w diecie posiłki, których nie chcielibyśmy w diecie. No bo jeżeli napiszemy po prostu do ChatGPT na przykład, „wygeneruj mi dietę odchudzającą”, no to on po prostu wygeneruje jakieś najpopularniejsze dania, które są popularne w internecie. No i przecież taki model nie wie, że ja na przykład osobiście nie lubię ryb, nie lubię owoców czy jeszcze coś… więc jeżeli ja mu w tym prompcie nie wskażę takich przykładów, takich elementów, że ja nie chcę, żeby w tej diecie były dania rybne, owocowe, no to on tego nie będzie wiedział, no i nie będzie wiedział, żeby tego nie używać.
Kolejną rzeczą w prompcie, którą bardzo często się powinno wskazywać, warto wskazywać, jest na przykład ton wypowiedzi. To jest taka może niezbyt intuicyjna rzecz, no ale są takie teksty, gdzie ten ton wypowiedzi ma olbrzymie znaczenie. Na przykład ja pisząc posta.
Na bloga, posta marketingowego, no to ten ton dobrze by było, żeby był na przykład sprzedażowy, pozytywny. Jeżeli na przykład każę wygenerować modelowi tekst, nie wiem, prawniczy albo tekst naukowy, no to ten ton musi być bardziej neutralny, obiektywny. Tam w tekście naukowym zwłaszcza nie powinno być takiej tendencyjności, tak? Powinno być bardzo obiektywne, neutralne.
Kolejna rzecz, ona jest najbardziej nieintuicyjna, mi się wydaje w promptowaniu, to jest tak zwana persona, czyli persona to jest taka sytuacja, kiedy my w prompcie zamieszczamy taką krótką instrukcję o tym, w jaką rolę ma się wcielić model. To często jest napisane w taki sposób, że nie wiem, jesteś tłumaczem języka angielskiego o poziomie specjalizacji tam, nie wiem, C1.
Ja nie wiem, czy to jest najlepsze wytłumaczenie persony, ale lubię zawsze wyjaśniać to w taki sposób, że dla mnie trochę persona jest taką kotwicą tematyczną, że jeżeli ja powiem, napiszę w prompcie, że model jest personą tłumacza, no to dla modelu jest to pewien sygnał, że on nie ma korzystać ze wszystkiego, co widział w trakcie nauki, tylko, że dla niego większy priorytet powinny mieć informacje dane, które są jakkolwiek związane w ogóle z tłumaczeniami i że to jest gdzieś tam jego cel pierwotny. Czyli podsumujmy sobie, mamy cel, mamy kontekst, czyli po co jest to zadanie, które chcemy zlecić modelowi. Mamy przykłady, jak to zadanie wykonywać. Przykłady pozytywne albo negatywne. Mamy personę, czyli zakotwiczenie tematyczne dla modelu.
Mamy ton wypowiedzi i było coś jeszcze.
Vladimir: Format?
Cezar: Format, tak. To jest, no właśnie, taka drobnostka, no ale myślę, że każdy, kto trochę rozmawiał z czatem GPT, to może odnieść wrażenie, że jak się zada pytanie czatu GPT, no to on odpisuje po prostu książką, tak?
Przykład praktyczny. Ja bardzo często wykorzystuję czata GPT, żeby generować jakiś kod w Pythonie do analizy danych. I jest to męczące, kiedy się iteruje taki kod, żeby zamiast kodu dostawać jeszcze takie wielkie wytłumaczenie.
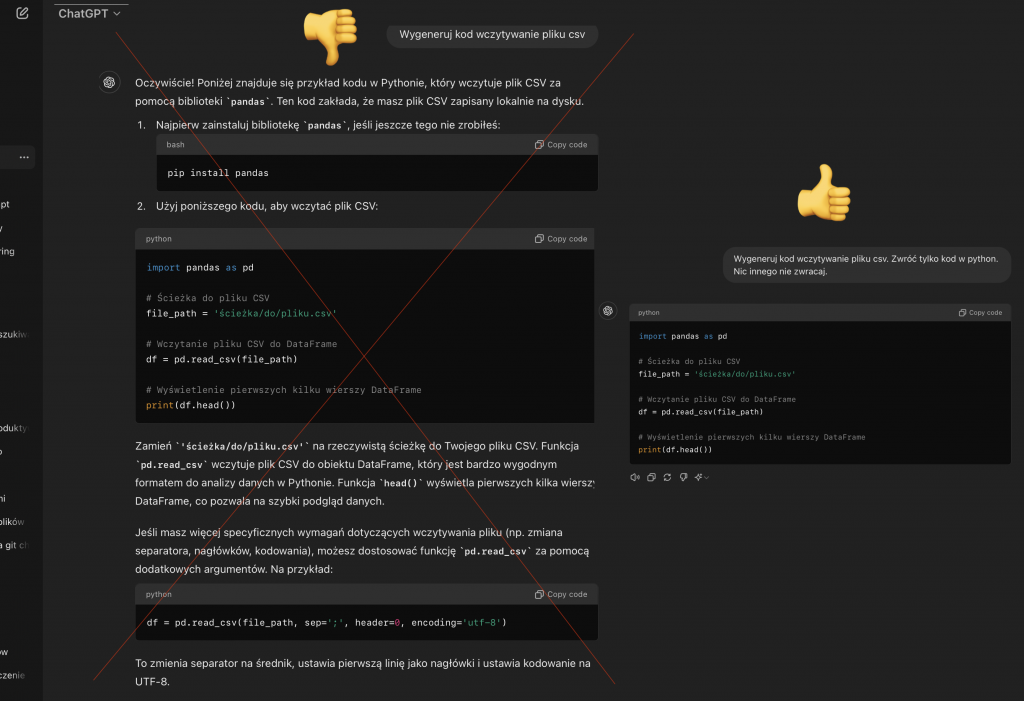
Ja jako model wygenerowałem ten kod po to, żeby, ja mu wtedy zawsze właśnie wskazuję w prompcie, że twoim zadaniem, jesteś asystentem, który pomaga mi generować kod do analizy danych. Jeśli chodzi o format odpowiedzi, to masz generować tylko i wyłącznie kod. Nie chcę jakby tych wszystkich ozdobników dookoła, chcę, by on mi zwracał tylko kod, bo dzięki temu szybciej iteruję. Mogę wrzucić kolejny kod, kolejną jego wersję i w ten sposób szybciej dojść do czegoś, co działa. I też część elementów warto zawsze zawierać w prompcie.
I ostatnia rzecz, mam nadzieję, że tu jeszcze jest to, można się na tym nadążyć. To nie jest takie ważne, żeby te sześć elementów zawsze w prompcie umieszczać. Dołączymy dla słuchaczy taki materiał źródłowy, taką prostą infografikę, która właśnie pokazuje, że nie każdy element z tych promptów jest zawsze tak samo ważny. I jako przykład podam rzecz najważniejszą i najmniej ważną. Najważniejsze w prompcie jest zawsze określenie zadania.
Na pierwszym miejscu jest określenia zadania (task). To jest tak ważne, że większość modeli, jeżeli nie opiszecie jasno, czego od nich oczekujecie, to po prostu Was zatrzymają i poproszą o doprecyzowanie tej części prompta. Najmniej ważna część to jest na przykład właśnie ton wypowiedzi. W większości przypadków on nie ma żadnego znaczenia. Nie musicie mówić modelowi, że na przykład generując kod powinien być pozytywny, negatywny, neutralny. No tutaj w większości wypadków nie będzie to miało znaczenia. I co jest najważniejsze i najlepsze (dobra wiadomość!)? Nie trzeba się tak bardzo tym przejmować, bo im się więcej promptuje, no to się właśnie zaczyna po prostu mieć intuicyjne wyczucie, że ten element jest ważny, ten mniej i nawet nie musimy już myśleć o tym, którego z tych elementów kiedy używać.
Vladimir: Zawsze mam wyzwanie, gdy zadaję pytanie, a odpowiedź jest trochę dłuższa. W mojej głowie pojawiają się wtedy kolejne wątki do zbadania. Trudno jest zdecydować, z którego wątku zacząć. Myślę, że kluczowa refleksja, którą chciałbym podkreślić przed zadaniem kolejnego pytania, to fakt, że z jednej strony prompt to coś prostego—pytamy model o coś konkretnego. Cała sztuka polega jednak na tym, by zrobić to dobrze. To podobnie jak z ludzką komunikacją; niby możemy zadać pytanie wprost, ale wyrażanie myśli w sposób zrozumiały jest trudniejsze, niż się wydaje. Chyba każdy, kto kiedykolwiek próbował wytłumaczyć coś skomplikowanego, wie, jak wielkim wyzwaniem bywa przekazanie dokładnie tego, co ma się na myśli.
Swoją drogą śmialiśmy przed startem, że ja po takich promptowaniach znacznie lepiej też zacząłem komunikować się z ludźmi, bo to tak wrzuciło pewną strukturę i zmusza na przykład określić cel, instrukcję i to jest takie fajne, przez to, że możesz iterować z takim czatem GPT wiele razy swoją umiejętność, bo dostajesz nie to, co chcesz i próbujesz jeszcze raz i jeszcze raz… i tam nie ma emocji (nikt na Ciebie nie obraża się, nie masz poczucie winy lub inne podobne emocji, więc trenujesz tak długo jak masz tylko ochotę i najlepiej robić to regularnie), to możesz go tak podkręcać, podkręcać i w końcu się uczysz, jak lepiej zadawać pytania (ChatGPT i potem okazuje się też i ludzi). Poprawa komunikacji z ludźmi to jest takie trochę taka wartość uboczna, to nie było zaplanowane, żeby czat GPT uczył ludzi komunikować się i wyrazić swoje myśli, ale fajnie to wyszło :).
Powiedz, co chciałeś dodać?
Cezar: Ja właśnie tak będę się starał unikać dłuższych wypowiedzi w trakcie tej rozmowy, choć już się przyłapałem na tym, że trochę za bardzo rozłożyłem ten prompt na czynniki pierwsze. Pomyślałem sobie, że jest jedna prosta rzecz, która stanowi istotę całego wyzwania związanego z promptingiem. Powiedz mi, czy znasz mit o królu Midasie?
Vladimir: Tak, no, wspominałem o nim w podcastie (4 odcinek w 2017 roku). Ale to było jakiś czas temu, więc możesz przypomnieć.
Cezary: Historia króla Midasa ma na celu przypomnieć nam, jak ważne jest ostrożne formułowanie życzeń. Król Midas pragnął, aby wszystko, czego dotknie, zamieniało się w złoto. To było jego życzenie, jego prośba, jego prompt (mówiąc językiem ChatGPT i podobnych), ale nie przewidział negatywnych konsekwencji. Każdy przedmiot, każda rzecz, której dotknął, zamieniała się w złoto, włącznie z jedzeniem i napojami. W efekcie Midas umarł z głodu i pragnienia, ponieważ nie mógł nic dotknąć bez natychmiastowej zamiany w złoto. Oczywiście takie streszczenie jest uproszczeniem, ale dobrze ilustruje, że odpowiednie formułowanie oczekiwań jest kluczowe. W kontekście promptowania, zasada jest jasna: im precyzyjniej opiszesz, czego chcesz, tym większa szansa, że dokładnie to otrzymasz. Prosta zasada, ale bardzo istotna.
Vladimir: Umiejętność promptowania sama w sobie jest sztuką, ale wrócimy do tego za chwilę. Teraz porozmawiajmy o tokenach. Z jednej strony są one techniczne, więc może się wydawać, że przeciętna osoba nie musi się tym przejmować. Jednak istnieje kilka powodów, dla których warto zrozumieć tokeny, nawet na podstawowym poziomie. Skupmy się na praktycznej stronie tego zagadnienia — jako użytkownik nie musisz znać wszystkich technicznych szczegółów, ale są pewne kwestie, na które warto zwrócić uwagę.
Cezar: Tokeny są dużo łatwiejsze do zrozumienia, gdy się je widzi, a nie tylko o nich słucha. Istnieje świetne narzędzie od OpenAI, nazywane tokenizerem, które pozwala wrzucić swój tekst i zobaczyć, jak jest on podzielony na tokeny. To wygląda jak kolorowe klocki, co naprawdę pomaga w zrozumieniu, o co chodzi.
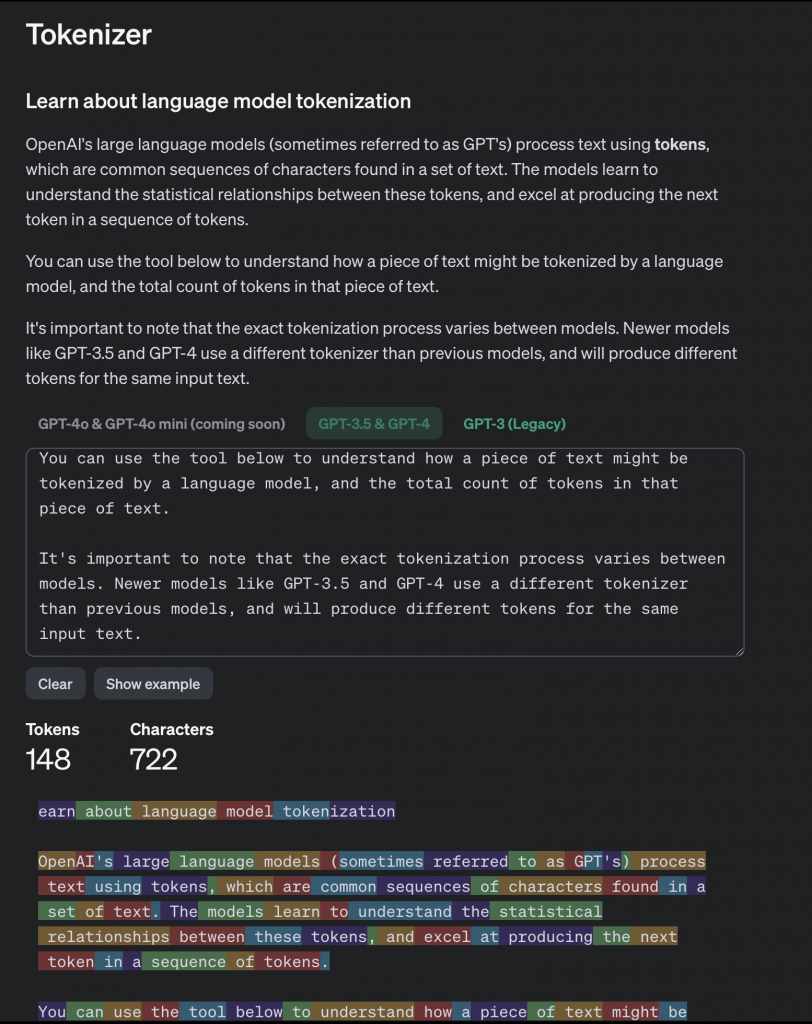
Ale żeby nie wchodzić zbyt głęboko, co do zasady jest tak, że modele nie operują naszym językiem, nie operują literami, słowami, wyrażeniami. To my możemy do nich mówić naszym językiem, ale modele, żeby rozumieć to, co do nich piszemy, muszą tłumaczyć sobie nasze słowa, zdania, wyrażenia na coś, co one rozumieją, czyli na tak zwane tokeny.
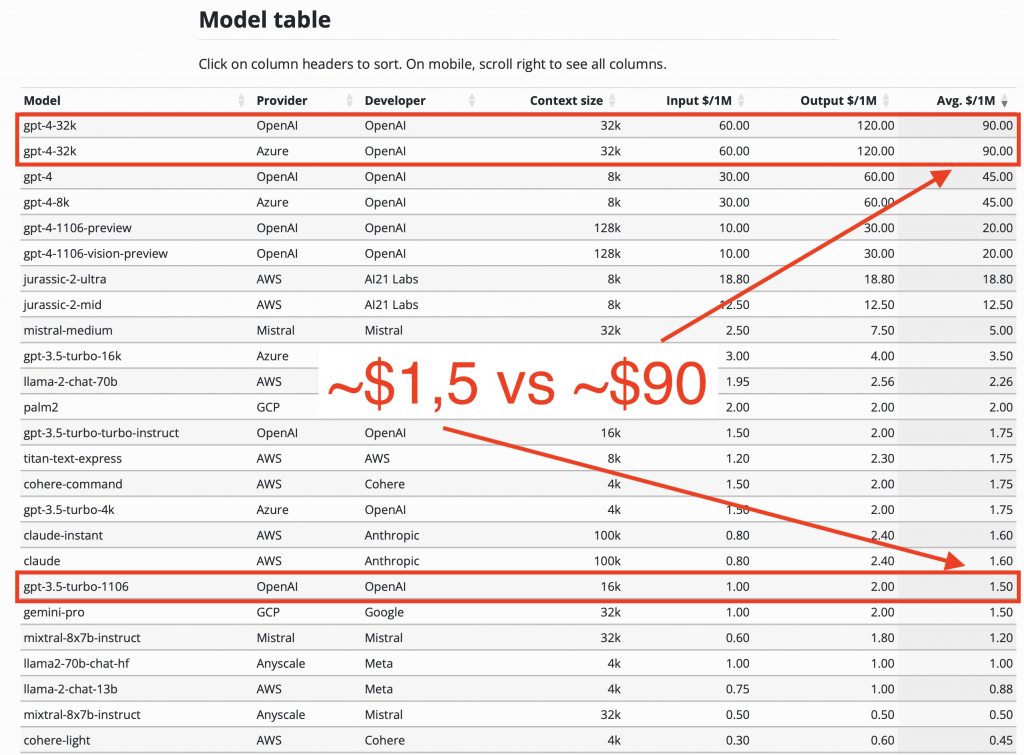
Tokeny to są pewien format, na który sobie tłumaczą nasz język modele. I tokeny są o tyle istotne z takiej biznesowej perspektywy, bo tak naprawdę tokeny decydują o bardzo ważnej rzeczy – ile my właściwie zapłacimy za tę rozmowę z tym modelem. Firmy, które mają modele, jak OpenAI, Microsoft czy Google, rozliczają się właśnie po tokenach. Za każde tysiąc tokenów, które model wykorzysta, my płacimy konkretne pieniądze. Czasami są to ułamki setne centa, a czasami konkretne centy.
Jest to bardzo ważne, bo musimy rozumieć, że to, ile tokenów zużyjemy, bezpośrednio wpłynie na to, ile po prostu wydamy fizycznie pieniędzy na wykorzystanie tego modelu. Pojawiły się pieniądze, więc to na pewno jest ważne dla osób decyzyjnych. I tutaj to, co ważne jest, że jak my piszemy tę treść, liczba tokenów zależy od procesu tokenizacji. Tokenizer to mechanizm, który właśnie dzieli to, co było jako tekst, na tokeny. Różne tokenizery mają różne słowniki, czyli bardziej rozbudowane potrafią zjednoczyć nie tylko pojedyncze literki, ale nawet kawałki słów.
Dla języka polskiego, angielski tokenizer będzie dzielił słowa na mniejsze kawałki, co skutkuje większą liczbą tokenów. To przekłada się bezpośrednio na koszty. Dodatkowo, każdy model kosztuje różnie. Tysiąc tokenów w jednym modelu i tysiąc tokenów w drugim modelu może kosztować znacząco różną wartość, nawet do stu razy więcej.
Na przykład, różnice w cenach między GPT-3.5 i GPT-4 były znaczące. Potem pojawiła się wersja turbo, która stała się tańsza. Te kwestie cenników i estymacji finansowych są biznesowo bardzo ciekawym wątkiem. Pracując w Allegro, nie przykładam zbyt dużej wagi do wyceny modelu, bo muszę zawsze w projekcie biznesowym pokazać to w bardzo prostej tabelce. Ujmuję to w jednostkach użycia, czyli po prostu ile razy fizycznie użyję modelu.
Na przykład, deklaruję, że użyję modelu GPT-4 10 tysięcy razy i zapłacę za to określoną kwotę. Dlaczego mówię, że to jest kontrowersyjne? Nie przykładam do tej wyceny aż tak dużej wagi, bo tak naprawdę co kwartał możemy przyjąć, że jeśli dzisiaj wyceniamy, że użycie modelu będzie nas kosztowało tyle, to możemy z dużą dozą prawdopodobieństwa założyć, że za rok będzie to już o połowę taniej. Te cenniki po prostu ulegają degradacji, bo z każdym kolejnym treningiem modelu spada jego cena.
Dzisiaj ChatGPT 3.5 turbo jest już wielokrotnie tańszy niż wcześniej. Te cenniki to już są dziesiąte tysięczne ułamki centa, więc ciężko to nawet wyrazić w liczbach. Moim zdaniem, kluczowym problemem, na który trzeba sobie odpowiedzieć, jest to, jaką wartość biznesową przynosi nam dany model. Nie chodzi o to, że jeden model jest droższy czy tańszy. Nikt ci nie zabroni używać modelu, który kosztuje 10 tysięcy dolarów dziennie, ale pytanie brzmi, jaką to wartość biznesową ci przynosi.
Wewnętrzny Asystent AI w Allegro
W Allegro, gdzie musiałem odpowiedzieć sobie na pytanie, czy bardziej mi zależy w modelu na tym, żeby był tani w użyciu, czy jednak zapłacić trochę więcej, a żeby było to jakościowe. Pierwszym była sumaryzacja. Mamy wewnętrznego asystenta w Allegro i stworzyliśmy dla niego dedykowaną funkcję, gdzie nasi pracownicy mogą wrzucać swoje dokumenty służbowe i prosić model, aby wykonał podsumowanie. Zamiast czytać 20-stronicowy dokument, chcesz dostać 10-20 zdań, które dają tę samą wiedzę.
Musieliśmy zdecydować, czy chcemy wykorzystać ChatGPT 3.5 turbo, czy GPT-4. ChatGPT 3.5 turbo był bardzo szybki i tani, ale jakość podsumowań była średnia. GPT-4 dawał lepsze wyniki, ale był znacznie droższy. Musieliśmy więc rozważyć, czy chcemy wykonywać zadanie szybko i tanio, czy wolniej, drożej, ale jakościowo.
Zaczęliśmy analizować, ile średnio stron ma typowy dokument służbowy w Allegro. Wyszło nam, że około 10 stron, więc ustaliliśmy limit 50 stron na dokument, co powinno pokryć 80% przypadków zgodnie z zasadą Pareto. Dzięki temu mogliśmy oszacować maksymalne koszty, nawet gdyby pracownicy zaczęli intensywnie korzystać z tej funkcji.
Reasumując, zawsze trzeba rozważyć, czy chcemy coś zrobić szybko i tanio, ale w dużej ilości, czy mniej, ale drożej i jakościowo. To jest wybór, który masz.
Vladimir: Jak wspomniałem w poprzednim odcinku, kluczowe jest porównanie modeli pod kątem ich efektywności w rozwiązywaniu danego problemu. Ważnym elementem tej analizy jest również uwzględnienie kosztów; warto mieć obok kolumnę z kosztami, ponieważ tego rodzaju dane mają istotny wpływ na nasze decyzje. Weźmy na przykład modele GPT-3.5 i GPT-4. Zazwyczaj GPT-4 wypada lepiej, ale zdarzają się sytuacje, gdzie droższy model radzi sobie gorzej. Jest to szczególnie trudne, kiedy ponosimy wyższe koszty, a otrzymujemy gorsze rezultaty.
Twój wybór, dotycząc tego, czy płacić mniej i akceptować niższą jakość, czy zdecydować się na wyższe koszty dla lepszego efektu, jest interesujący. Czasami tańsze rozwiązanie jest wystarczająco dobre. Z drugiej strony, bywa, że potrzebujemy najwyższej jakości, co skłania nas do ponoszenia wyższych kosztów.
Przechodząc do tematu tokenów i zamykając ten wątek, warto pamiętać, że oprócz jednoznacznych metryk, jak zdolność modelu oceniana przez zewnętrzne leaderboardy, warto mieć własne, wewnętrzne metryki w firmie. Pozwolą one lepiej ocenić, czy dany model faktycznie miał pozytywny wpływ na nasze działanie. Na początku może być trudno to stwierdzić, ale z czasem, gdy napotkamy bardziej konkretne problemy, można stworzyć własne leaderboardy i metryki.
W kontekście tokenów ważne jest zrozumienie ich wkładu w rozwiązanie problemu oraz kosztów z tym związanych. Mnożąc te dwa czynniki, można uzyskać pewne pojęcie o ekonomii rozwiązania, co pozwala podejmować bardziej świadome decyzje.
Cezar: Zainspirowałeś mnie, bo powiedziałeś, że ludzie faktycznie zwracają głównie uwagę na wymiar rezultatu. Widać to często na LinkedInie – ludzie poświęcają dużo uwagi temu, jak dobry jest wynik zwracany przez model.
A kwestie tokenów można zamknąć w trójkącie: koszt, czas odpowiedzi i rezultat tej odpowiedzi. Wszyscy zazwyczaj skupiają się na rezultacie. Przez to, że nie biorą pod uwagę kwestii kosztu i czasu, są bardzo niemile zaskoczeni. Nagle okazuje się, że użycie ChatGPT-4, który według nich daje najlepsze wyniki, trwa 10 sekund. A wyobrażasz sobie na przykład czekać 10 sekund na coś na Allegro?
W tym czasie jesteś w stanie zalogować się do innego sklepu, znaleźć inny produkt i go kupić. Okazuje się, że parametry, które nie są oczywiste, też mają znaczenie. Jeśli tokenów jest dużo, model potrzebuje więcej czasu na odpowiedź. Więcej tokenów oznacza wyższy koszt, a często, żeby uzyskać lepszą odpowiedź, musimy dodać większy kontekst, czyli zużyć więcej tokenów. Moim zdaniem to jest trochę jak z trójkątem – nie da się zrobić tanio, szybko i dobrze jednocześnie.
Zawsze, gdy chcesz postawić na któryś z tych trzech parametrów – szybszą odpowiedź modelu, niższy koszt lub lepszą jakość odpowiedzi – to któryś z pozostałych parametrów musi ucierpieć. Tak można te tokeny zamknąć w tym trójkącie.
Vladimir: Pięknie to ująłeś. Chciałbym nawiązać do tego, co wcześniej powiedziałeś o spadku cen. Słowo „degradacja” często ma negatywne konotacje, ale tutaj jest to pozytywne zjawisko, bo oznacza obniżkę cen. To bardzo optymistyczna perspektywa. Wracając do metafory trójkąta – im bardziej to wszystko nabiera tempa, tym bardziej ulega optymalizacji. Trudno jest obecnie zaspokoić wszystkie trzy parametry jednocześnie, ale jeśli porównamy sytuację dzisiaj i za rok, zobaczymy zupełnie inne układy.
Warto zauważyć, że to, co jest dostępne dzisiaj, za rok będzie jeszcze korzystniejsze, choć wciąż będą istnieć różne kompromisy. Te kompromisy charakteryzują się dużą dynamiką w kontekście tego, co jest możliwe tutaj i teraz.
Cezar: Dokładnie tak.
Vladimir: Dobra, na tę chwilę zamykamy temat tokenów. Mam nadzieję, że omówiliśmy kluczowe kwestie. Teraz przejdźmy do kolejnego tematu, który jest powiązany z tokenami – czyli okienek kontekstowych. Porozmawiamy o długości tych okienek, co warto o nich wiedzieć i dlaczego są takie istotne.
Cezar: Tak, nawet pokusiłbym się o stworzenie takiego łańcuszka. Wiemy już, że jest prompt, czyli polecenie, sposób komunikacji z modelem. Żeby model zrozumiał nasze prompty, musi nasze wiadomości przetworzyć na tokeny, które rozumie. Teraz pojawia się okno kontekstowe, które najprościej wyjaśnić w ten sposób, że wyznacza nam, jak duże prompty możemy wysyłać do modeli generatywnych.
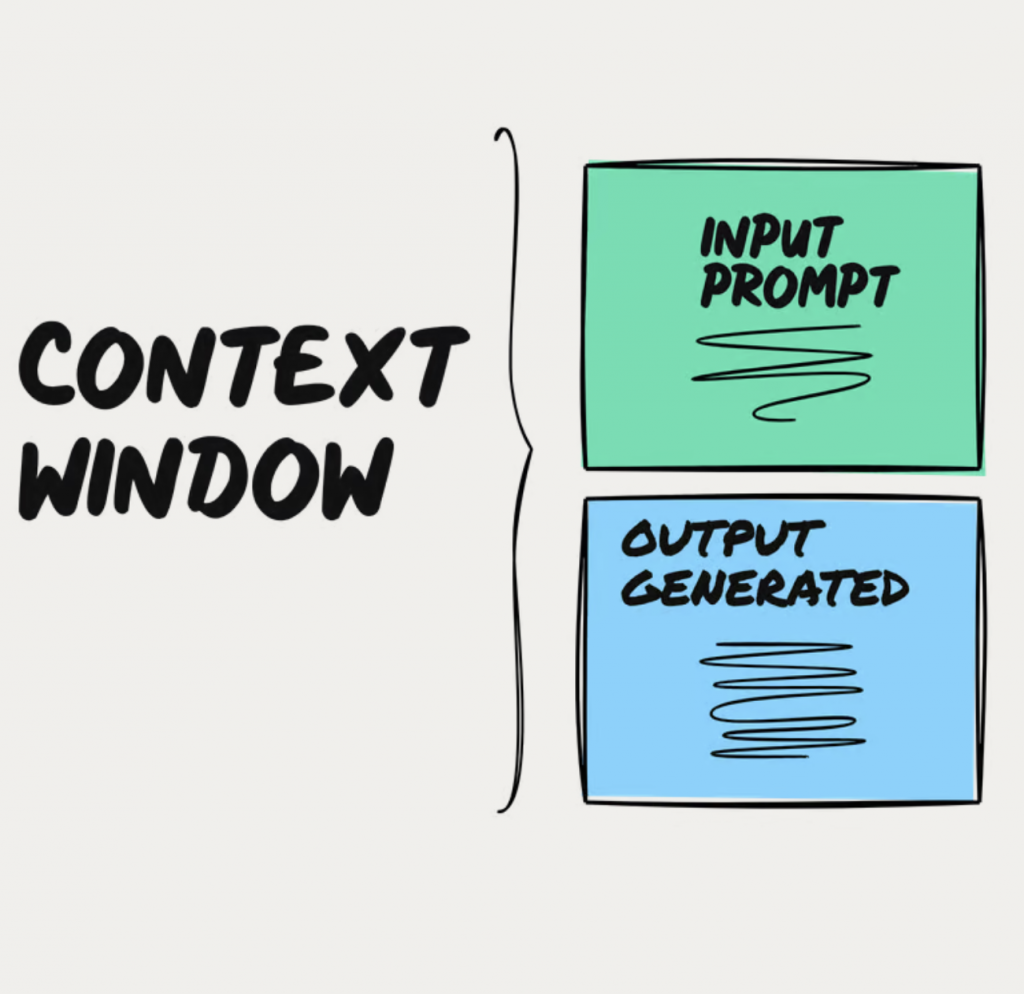
Okna kontekstowe są najczęściej wyrażone w ilości tokenów, które możemy umieścić w ramach jednego prompta. Ludzie mogą usłyszeć bardzo duże liczby, np. że okno kontekstowe wynosi 32 tysiące tokenów, 128 tysięcy tokenów, a nawet takie giganty jak Gemini od Google, gdzie mamy tych tokenów chyba nawet 2 miliony.
Co do zasady, tokeny mówią nam, jak duże prompty możemy jednorazowo wysłać do modelu generatywnego. I więcej nie znaczy znowu lepiej. Mieliśmy taką rozmowę jeszcze przed nagraniem, bo można ulec pewnemu mylnemu wrażeniu, że im większe okno kontekstowe, tym lepiej, co nie jest prawdą.
Jest pewne zjawisko w prompt engineeringu, które zresztą można bardzo łatwo sobie wyobrazić, bo jako ludzie też mamy ten problem. Jest to zjawisko, które zostało potwierdzone naukowo, że im dłuższego prompta wyślemy, tym jesteśmy bardziej narażeni na to, że model zacznie gubić to, co jest w naszym promptcie.
Co ciekawe, im dłuższy prompt, tym silniej można zaobserwować zjawisko, że model bardzo dobrze koncentruje się na tym, co było na początku i na końcu prompta, ale nie do końca już pamięta, co było w środku. Ludzie działają dokładnie tak samo – gdy czytamy długie teksty, pamiętamy, co było na początku i na końcu, ale trudno nam zapamiętać to, co jest w środku.

Z oknem kontekstowym jest dokładnie tak samo. Co ciekawe, Google opublikował taki podręcznik, chyba 101 dobrych praktyk, jak dobrze promptować.
I to jeszcze bym zamknął takim przykładem, który właśnie mieliśmy przed wejściem online. Musimy mieć świadomość, że te wszystkie firmy, które zarabiają na modelach generatywnych, stosują te same triki marketingowe, co inne branże. Na przykład Google teraz bardzo często podkreśla, że ich modele mają właśnie milion tokenów.
I teraz co to znaczy dla zwykłego użytkownika? Czy dla zwykłego użytkownika milion tokenów to jest dobrze czy źle? Moim zdaniem dla zwykłego użytkownika takiego jak ty czy ja nie ma to absolutnie żadnego znaczenia, bo dla większości użytkowników wystarczy tak naprawdę okno kontekstowe, które jest 10 razy mniejsze, na przykład ma 100 tysięcy tokenów.
To jest trochę jak z elektroniką. Bardzo często komputery sprzedaje się w ten sam sposób, że nasz komputer ma tam, powiedzmy, „2 tysiące” gigabajtów RAM-u. Ja nawet, widzisz, nie wiem do końca jak działa RAM, może wstyd się trochę przyznawać, ale prawda jest taka, że większości ludzi oglądających YouTube’a wystarcza tam, nie wiem, znaczniej mniej gigabajtów RAM-u.
Vladimir: My jesteśmy bombardowani ogromnymi liczbami, które mają robić wrażenie. W rzeczywistości jednak, w praktycznym zastosowaniu, potrzebujemy jedynie niewielkiej części tych danych. Cały trik polega na tym, że ludzie mają tendencję do myślenia: „Dobra, zapłacę więcej za większą liczbę, bo większe na pewno znaczy lepsze”. Ale w rzeczywistości, często te dodatkowe zasoby są wręcz niepotrzebne.
Co więcej, nawet jeśli byśmy próbowali to wykorzystać, często okazuje się to nieefektywne. Problem polega na tym, że większość osób nie zdaje sobie sprawy z tej nieefektywności i po prostu akceptuje te ogromne liczby jako coś wartościowego, mimo że faktycznie tego nawet nie potrzebujemy.
Jak mówiłeś, to tak sobie myślę, że fajnie byłoby zostawić jakąś praktyczną wskazówkę. Porozmawialiśmy o tokenach i ich kosztach, o prędkości, o oknie kontekstowym i jego długości. Przytoczyłeś również przykład z Allegro, który analizowaliście. Może spróbujmy teraz oszacować, ile to wszystko będzie kosztować?
Cezar: Wyobraźmy sobie, że jest ktoś, kto nas słucha, teraz myśli: „A ile będzie kosztować mój problem, jak w ogóle się za to zabrać?”. Wiadomo, że to można zrobić różnie, ale przynajmniej rząd wielkości – czy to jest koszt 10 dolarów, czy 10 tysięcy dolarów dziennie? Jak do tego się zabrać, jakieś takie proste porady, przynajmniej taki punkt zaczepienia, jak do tego tematu podejść?
Znaczy, to jest trudne pytanie, bo wydaje mi się, że tutaj nie tyle jest… Tu nawet nie tyle trzeba, oczywiście trzeba rozumieć, czym są tokeny, że są jakieś cenniki, ale moim zdaniem, żeby odpowiedzieć na to pytanie, to tak naprawdę trzeba zacząć od czegoś innego i zrozumieć proces biznesowy, który my chcemy zaopiekować, po prostu wykorzystaniem modelu generatywnego.
No to jeśli mogę na swoim przykładzie, wydaje mi się, że on jest dość prosty. O właśnie, pracujemy w Allegro. Pracujemy nad takim udogodnieniem dla klientów, którym ma być streszczenie opinii.
To znaczy, że czasami niektóre produkty mają tych opinii na przykład kilka tysięcy, no i z jednej strony opinie są bardzo ważną rzeczą dla kupującego, na ich podstawie często podejmujemy główną decyzję zakupową, ale też nie każdy chce czytać tysiąc opinii.
No i problem biznesowy był taki: czy możemy stworzyć taką jedną opinię na podstawie tysiąca opinii, która da ci dokładnie tę samą wiedzę albo bardzo podobną wiedzę, jaką byś miał, gdybyś przeczytał właśnie wszystkie opinie. Czyli tworzymy jedną super opinię, która jest streszczeniem wszystkich opinii.
No i tutaj właśnie pojawiło się pytanie, ile to będzie kosztowało, no i tu musiałem sobie to rozparcelować w taki sposób. Jak mój proces biznesowy tu wyglądał? Wiem, że mam produkt i wiem, że ten produkt ma na przykład tysiąc opinii. Więc wiem, że jeżeli chcę dla jednego produktu stworzyć taką super opinię, no to muszę wrzucić tysiąc opinii do modelu generatywnego.
Skoro już wiem, ile chcę wrzucić opinii, czyli wiem, ile tekstu chcę wrzucić, no to mogę zacząć liczyć koszty. Więc skoro już wiem, że mam tysiąc opinii, no to kolejne pytanie, ile średnio znaków ma każda opinia? No i wiesz, tam mi wyszło, że średnia opinia na przykład ma, nie wiem, 200 znaków.
No to 200 znaków razy tysiąc opinii, no to już tam mamy 200 tysięcy znaków. No i teraz proste już tutaj wykorzystanie jakichś kalkulatorów na ile tokenów zazwyczaj się średnio przekłada 200 tysięcy znaków.
No i wyszedł mi bardzo prosty koszt, że stworzenie super opinii dla jednego produktu kosztuje tam, nie wiem, 2 zł. No a że produktów mamy już 100 tysięcy, no to cały projekt będzie kosztował nas na przykład tam ileś set tysięcy złotych.
Zobacz, że ja tak naprawdę niewiele tutaj mówiłem o tokenach w ogóle, czy o modelu generatywnym, ja jeszcze bardziej upraszczając musiałem zrozumieć, jak w ramach procesu biznesowego, jaki tekst i ile tekstu i jak często chcę go po prostu przetworzyć. Zwykła matematyka prosta polegająca na tym, ile ja słów chcę wrzucić do modelu i za ile mnie po prostu te słowa ta firma szarżuje. I to wszystko.
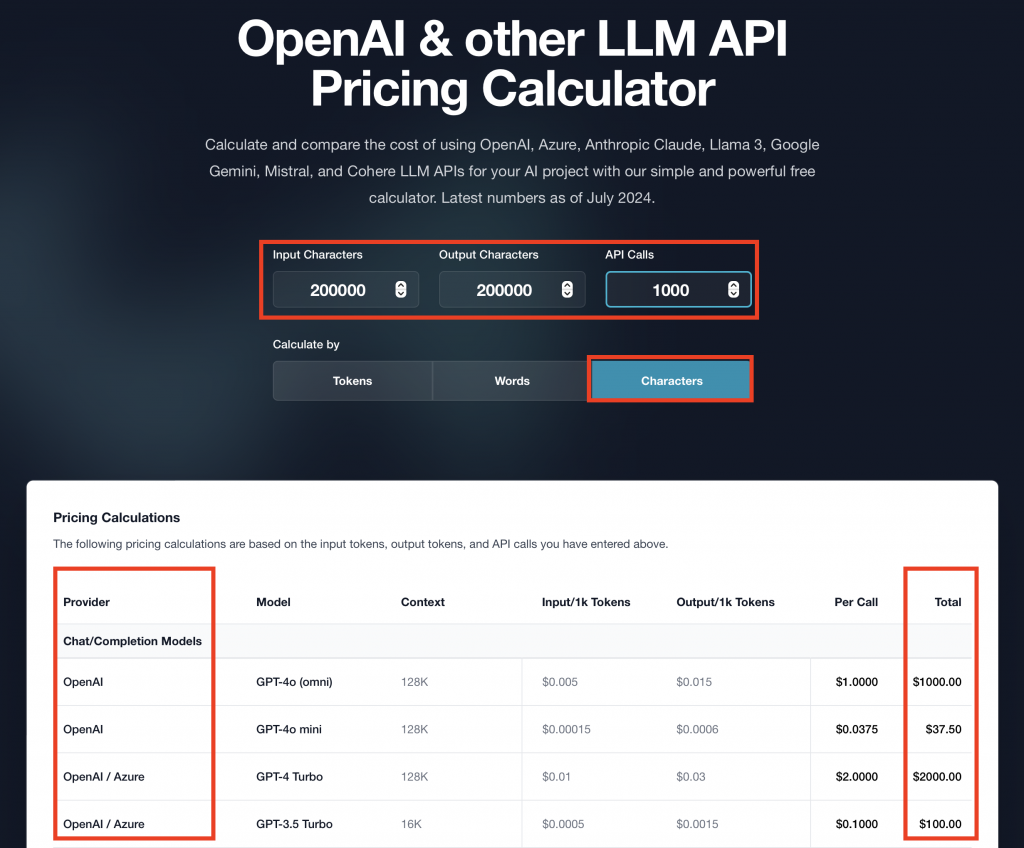
Vladimir: Tak to wygląda w trzech prostych krokach. Pierwszy – analizujemy proces biznesowy. Przyglądamy się dokładnie, co chcemy osiągnąć i jak to obecnie funkcjonuje. Drugi krok – liczymy wszystko, nawet na poziomie znaków. Sprawdzamy, ile dokładnie będzie potrzebnych zasobów. Trzeci krok – sięgamy po pierwszy lepszy kalkulator. Wpisujemy nasze parametry oraz założenia i otrzymujemy przynajmniej szacunkowy przedział kosztów.
Jeśli kalkulator poda nam, ile to będzie kosztować, warto znowu wrócić do tych trzech kluczowych wartości, o których dziś mówiliśmy. Dobrze jest oszacować także czas trwania projektu. Czy zajmie to dwa dni, czy dwa miesiące – taka estymacja również jest bardzo przydatna.
Cezar: Tak, to prawda. Kalkulatora do tego niestety nie ma. Na szczęście, zależność jest bardzo prosta: im więcej tokenów wrzucimy do modelu, tym dłużej trwa odpowiedź. Nie ma tu innych zmiennych. To jest najprostsza forma zależności, ale może się wydawać nieco bardziej złożona.
Ta zależność ma jednak duże znaczenie biznesowe. Decyduje o tym, czy chcemy przetwarzać dane online, czy offline. Na przykład, jeśli chcemy uzyskać wysokiej jakości podsumowania, nie będziemy ich generować na żywo. Wszystko będzie przetwarzane offline, a na stronie umieścimy już gotowy tekst.
Gdyby klient miał czekać na podsumowanie opinii w czasie rzeczywistym, trwałoby to kilka, kilkanaście, a może nawet kilkadziesiąt sekund, bo mówimy tu o tysiącach opinii do podsumowania w jednym raporcie.
Vladimir: No i właśnie. Chciałbym zapytać o więcej przykładów takich konkretnych use case’ów, ale myślę, że zanim do tego przejdziemy, warto porozmawiać jeszcze o parametrach modeli, szczególnie o temperaturze. To jest jeden z tematów, który często umyka, a fajnie byłoby to wyjaśnić z perspektywy użytkownika. Wiadomo, że technicznie działa to jeszcze inaczej, pojawiają się różne rozkłady i tak dalej, ale z punktu widzenia użytkownika – jaka jest mechanika tego parametru, na co on wpływa i dlaczego warto go rozumieć? Poruszmy, jaki to ma wpływ z perspektywy użytkownika.
Cezar: Ja zawsze mam takie poczucie, że jak dochodzi do parametrów, jeszcze tak, mamy prompta, mamy tokeny, mamy okno kontekstowe, to to są jeszcze takie rzeczy, które jest w stanie każdy nawet intuicyjnie zrozumieć. I wydaje mi się, że parametry to jest ta granica, gdzie się zaczyna robić trochę trudniej. I ja w ogóle w takiej sytuacji nawet nie staram się tworzyć jakiejś definicji parametrów.
Ja zawsze tutaj podaję przykład DJ-a i konsoli. W sensie, jeśli chcemy zrozumieć, czym są parametry i dlaczego parametry są ważne z perspektywy tego, jak działa model, jak zwraca wyniki, to właśnie trzeba sobie trochę wyobrazić, że ja jako użytkownik jestem DJ-em, a model jest konsolą DJ-ską, która właśnie ma parametry, czyli te pokrętła, suwaki.
I dobry DJ wie, jak ustawić te suwaki, kontrolki, czyli parametry, po to, żeby uzyskać co? Jak najlepszą jakość brzmienia dźwięku. No i na przykład jak mamy ML inżynierów, no to oni właśnie wiedzą, jakie parametry ustawić, żeby modele zwracały jak najlepsze wyniki. I prawda jest taka, że tych parametrów jest bardzo dużo, ale jesteśmy tak naprawdę w stanie wyróżnić takie 2-3 parametry, które są nazwijmy takimi topowymi, najważniejszymi parametrami.
I ja zawsze też mówię, że moim zdaniem to nie jest istotne rozumieć z perspektywy użytkownika biznesowego, że nie wiem, że temperatura 0,3 to jest to, a to nie ma znaczenia. Moim zdaniem dużo lepiej jest rozumieć, co to znaczy biznesowo, że parametr jest wysoko, albo nisko.
I w ogóle zacznijmy od temperatury, bo wydaje mi się, że to jest taki najlepszy przykład. Temperatura jest w ogóle chyba takim najbardziej znanym parametrem i też parametrem, który jest mylnie rozumiany. Bo zauważyłem, że bardzo często jak inni tłumaczą, czym jest temperatura, to mówią, że to jest taki parametr, który wpływa na to, jak bardzo model jest kreatywny.
I to moim zdaniem jest pułapka, bo jak ja rozumiem kreatywność, no to myślę sobie, że ja tym parametrem mogę decydować, jak bardzo inteligentny jest model. No bo inteligentny człowiek to jest człowiek kreatywny. A to nie jest to. Ja zawsze mówię, że o temperaturze można sobie trochę myśleć, jak człowiek ma temperaturę, jak ma gorączkę.
Jak masz wysoką temperaturę, to co się zaczyna dziać z twoim językiem? Zaczynasz mówić bez sensu, prawda? Wysoka temperatura, po prostu majaczysz, mówisz rzeczy, które nikt nic nie rozumie. Jak masz niską temperaturę i jesteś zdrowy, no to mówisz z sensem składnie. I dokładnie tak jest z modelem.
W modelach generatywnych parametr temperatury odpowiada za to, jak bardzo losowe słowa będzie generował model. Jeżeli ustawimy temperaturę najwyżej, jak się da, no to model będzie wypluwał z siebie słowa, które są totalnie losowe, które nie tworzą spójnej całości. Jeżeli ustawimy temperaturę nisko, to te teksty będą właśnie bardzo generyczne.
I właśnie mówię, znowu, nie ma sensu wchodzić w to, kiedy warto ustawić temperaturę 0,1, 0,2, 0,5. To są inżynierskie rzeczy. Ja zawsze uważam, że warto zrozumieć, jakie są przykłady biznesowe ustawiania tego parametru, tej temperatury wysoko i nisko. Czyli znowu, kiedy mi biznesowo opłacałoby się ustawić na przykład niską temperaturę.
Jeżeli na przykład chcę generować kod z modelem generatywnym, albo generować instrukcję, to ja wtedy na przykład wolałbym tę temperaturę ustawić nisko. Dlaczego? No bo wtedy te słowa będą bardzo powtarzalne, bardzo generyczne, czyli coś, co jest pozytywną cechą w kontekście kodu czy instrukcji.
Ale już na przykład, gdybym chciał generować treść na artykuł, na bloga, albo napisać bajkę, albo post reklamowy, to już bym tę temperaturę ustawił wysoko. No bo tutaj ta wysoka losowość generowanego tekstu daje mi co? Większe szanse, że ten tekst będzie niegeneryczny. Będzie bardziej oryginalny, bo będzie napisany w inny niż typowy sposób.
Jeśli rozumiemy, co to właśnie znaczy wysoko nisko, to to nam absolutnie wystarczy. Innym bardzo fajnym parametrem jest tak zwany topP. I znowu, ja bardzo lubię jako przykład podawać, że topP to jest trochę de facto parametr, który decyduje o tym, jak elokwentny jest model.
No bo topP tak naprawdę decyduje o tym, jak, z jak dużego zbioru słów model będzie generował, będzie wybierał słowa, które będzie generował. I znowu, kiedy nam, takie proste pytanie biznesowe, kiedy nam się opłaca, żeby model był elokwentny, a kiedy nie? Wrócę do tej instrukcji, bo to jest bardzo fajny przykład. Dobre instrukcje to są takie, które zrozumieją wszyscy.
Nieważne, czy to jest profesor po studiach, albo ktoś, kto nawet nie skończył podstawówki. Dobrą instrukcję powinni zrozumieć absolutnie wszyscy. I znowu, tutaj, jakbym chciał mieć model do generowania instrukcji, to parametr topP ustawiłbym nisko, bo on wtedy używa najbardziej powszechnych, najbardziej prawdopodobnych słów, czyli takich, które prawdopodobnie zrozumie większość.
Ale gdybym był dziennikarzem, który pisze reportaż do gazety, no to już tutaj bym ten parametr ustawił wysoko, no bo dobry jednak reportaż powinien mieć trochę synonimów, trochę bogactwa językowego, tak? No i tak mógłbym w kółko, jest jeszcze kilka innych parametrów, ale szczerze, wydaje mi się, że topP i temperatura na ten moment, to są takie dobre, żeby je rozumieć, zwłaszcza, że jeśli pozwolisz, ostatnią rzecz powiem.
Prawda jest taka, że na przykład użytkownik biznesowy praktycznie się nigdy z tymi parametrami nie spotyka. W sensie, jak wchodzisz na przykład na ChatGPT albo Gemini’a, to nie masz tam czegoś, żadnych suwaków, żadnych parametrów, prawda? Ale na przykład osoby, które się z tym prędzej czy później spotkają, to są inżynierowie oprogramowania.
No bo każdy deweloper w ciągu najbliższych kilku lat, przynajmniej raz będzie miał taką sytuację, że w pracy prawdopodobnie będzie musiał się połączyć z modelem generatywnym, na przykład z GPT przez API. Na przykład w API w ramach zapytania, nie tylko wpisujesz prompta, ale właśnie się pokazuje. Musisz podać takie pola, jak temperatura topP i wtedy się zaczyna.
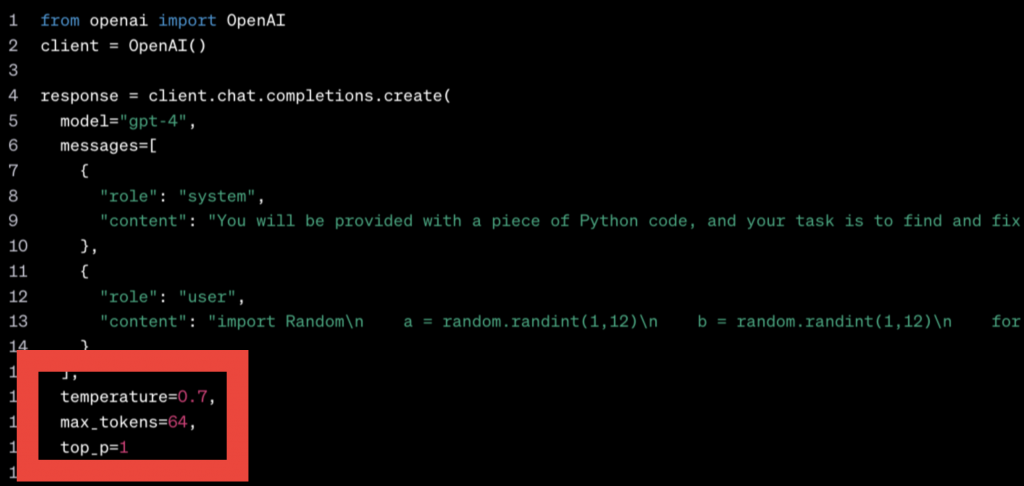
Co to znaczy? Tam są jakieś cyferki. Jezu, jak ja mam te cyferki ustawić? I tu właśnie warto wtedy rozumieć, że po prostu co to znaczy wysoko, co to znaczy nisko. Nie bez wchodzenia w szczegóły, że 0,8, 0,9 to nie ma tak naprawdę biznesowo większego znaczenia.
Vladimir: Uważam, że ta analogia jest świetna! Jeśli mówimy o odczuwaniu temperatury, to zakładamy, że punkt 0 to 36,6 stopni, a wszystko, co dalej. Często jest tak, że niektórzy ludzie w ogóle nie czytają na ten temat, a potem, gdy już coś usłyszą, myślą o 1 i 0 i zaczynają się gubić – czy 0 to tutaj, czy tam? Zawsze to wprowadza zamieszanie. A teraz, jeśli mamy punkt odniesienia, że normalna temperatura to 0, to jest to jasne. Potem może ona jedynie rosnąć, a im wyżej, tym mniej przewidywalne, czym to się skończy. Ta analogia bardzo dobrze zostaje w pamięci, więc dzięki za nią!
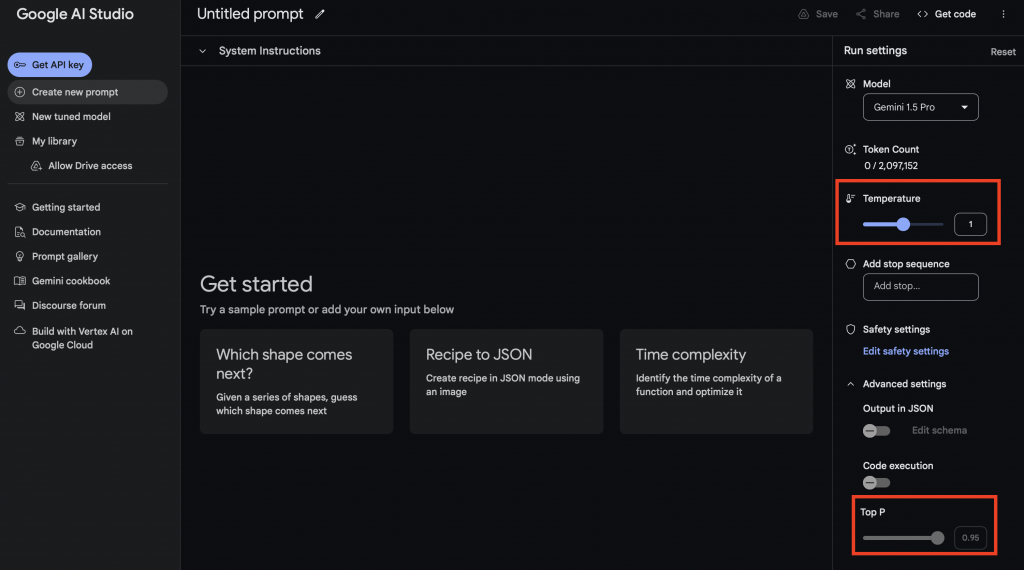
Co do interfejsu, to faktycznie jest interesujące. ChatGPT i Gemini standardowo nie mają tych suwaków, ale na przykład AI Studio czy Workbench od Anthropica mają dostępne opcje. Wystarczy czasem kliknąć ustawienia i można je sobie dostosować.
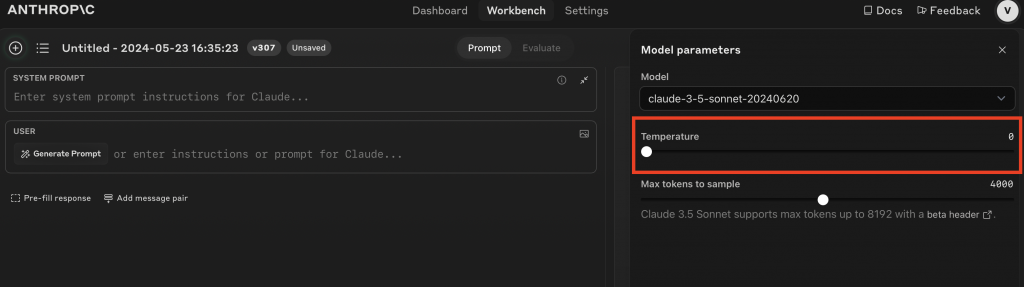
Ale to nasuwa mi myśl, że faktycznie te interfejsy też będą różne. Wcześniej było tak, że mieliśmy świat techniczny i nietechniczny, a teraz tych odcieni szarości staje się coraz więcej. Według mnie, nawet dla osób nietechnicznych warto, żeby zrozumiały te proste parametry, bo to w sumie prosta mechanika. Gdy opanujesz te podstawy, masz większą kontrolę, co wpływa na biznes w prosty sposób. Dlatego ważne jest, aby wykorzystywać takie podstawowe parametry, takie proste suwaczki.
To jest podobnie jak w samochodzie – pełno tam wiedzy technicznej, ale są podstawowe rzeczy, które warto znać, jak lepiej hamować, gdzie są pedały itp.
Jeszcze chciałbym zdążyć, bo nam powoli czas się kończy. Nie wszystko na dzisiaj, a na koniec będzie jeszcze niespodzianka. Chciałbym porozmawiać trochę więcej o use case’ach. Z jednej strony wydaje się, że ta generatywna AI krąży wokół nas, wszyscy oczekują, że świat się zmieni – i faktycznie tak będzie. Fajnie jednak mieć konkretne przykłady, gdzie możemy to zastosować. Wiedza o promptowaniu i konkretne przykłady, nawet bez wchodzenia głęboko w tematy generatywnej AI, mogą być już teraz bardzo przydatne.
Wymieńmy sobie kilka najciekawszych przykładów na początek, żeby dać inspirację osobom, które nas słuchają. Chciałbym, żeby pomyślały: „O, to może być przydatne u mnie. To nie jest jakaś abstrakcja; ja też mogę to zrobić, przynajmniej jako prototyp.”
Cezar: Znaczy to jest w ogóle trudne pytanie, bo zauważyłem, że internet wpada w pułapkę pytania, do czego mogę użyć generatywnej AI. Bo zauważyłem, że wszyscy w sumie mówią o na przykład generowaniu tekstu, że podają takie pięć zastosowań, które po prostu widać, że kopiują wszyscy po sobie.
Ja Ci wyślę po podcaście, żebyśmy tu załączyli dla słuchaczy, taki fajny artykuł z Harvard Business Review, gdzie badacze w ogóle przeskrolowali cały internet i zebrali 100 takich zastosowań, o których piszą ludzie, od takich biznesowych, po analizę Excela, po takie bardziej prywatne, w stylu pisania bajek.

Wracając do Twojego pytania, ja jakbym miał dzisiaj naprawdę wybrać kilka takich case’ów, które moim zdaniem mogą być bardzo uniwersalne i praktyczne, to ja zawsze mówię, ta pierwsza rzecz, o której mówię i na mnie ona robi jak dotąd największe wrażenie, to ta zdolność modeli do zamieniania nieustrukturyzowanych danych w dane ustrukturyzowane.
To brzmi poważnie, ale chodzi o coś bardzo prostego. Ja na przykład w pracy bardzo często wykorzystuję model generatywny do tego, żeby stworzyć dużo lepsze notatki. To jest niby taka, wiesz, taka niby pierdoła, ale ja w trakcie spotkania mam do wyboru, że albo mogę być bardzo na spotkaniu obecny i nie notować, albo mogę bardzo dokładnie notować, ale przez to się bardziej skupiam na notowaniu, niż na uczestnictwie w spotkaniu.
I bardzo często robię po prostu tak, że jeśli coś notuję w trakcie spotkania, to staram się tylko pisać słowa kluczowe. Takie, żeby one faktycznie dobrze mówiły, o co było na spotkaniu, ale nie martwię się całą tam, wiesz, otoczką. I wrzucam to następnie do modelu generatywnego po spotkaniu i proszę, żeby on stworzył z tego bardziej pełną notatkę, która dostarcza trochę więcej kontekstu i publikuję to potem już w formie jakiegoś dokumentu, do którego można wrócić.
Inną bardzo fajną rzeczą, która też się wiąże z tą zdolnością modeli do formatowania, w ogóle do transformowania rzeczy. Wiesz, ja jestem product managerem i mimo, że znam się na machine learningu, to nie jest tak, że rozumiem wszystko, a ja bardzo nie lubię nie rozumieć, co do mnie mówią inżynierowie. I bardzo często robię tak, że na przykład, jeżeli oni mi dostarczają jakąś dokumentację albo piszą wiadomości, których nie rozumiem, bardzo techniczne, to lubię je wrzucać do ChatGPT Allegro. Na początku tego nie wiedziałem, ale ucząc się, wydobywając tę wiedzę, bo model mi podpowiadał te rozwiązania, sam iterowałem tego swojego prompta. Dostęp do wiedzy, której nie mamy, jest tutaj najlepszy. Ja też bardzo często lubię w promptcie pisać, żeby na przykład model wcielił się w prezesa Allegro, bo my jako product managerowie…
Wiem, że to brzmi infantylnie, ale naprawdę jest to super biznesowa rzecz :). My jako product managerowie musimy nasze pomysły na takich one-pagerach opisywać – po co coś robimy, ile to będzie kosztowało, jak na przykład przyniesie wartość biznesową.
I często się zastanawiam, czy mój dokument na przykład ma jakieś braki. Wtedy piszę takiego prompta, że „jesteś prezesem dużej platformy e-commerce”, wrzucam mu mój dokument i każę mu zadać pięć challenge’ujących pytań wobec tego mojego pomysłu.
I dostaję takie pytania, których faktycznie ja bym sobie nie zadał, nie zauważył. W ten sposób podnoszę wartość dokumentu, zbierając informacje, które mogą go na przykład obronić albo dostarczyć treść, której wcześniej nie było.
Nie wiem, czy się takich zastosowań spodziewałeś, ale… Bardzo fajne, bardzo praktyczne. Myślę, że wiele osób może też z tego skorzystać. Jedynie trzeba uważać, bo jak mówiłeś, używacie wewnętrzną instancję. Tak, więc to jest… Trochę… Bo nie wrzucajmy danych prywatnych na publiczną instancję, bo nie wiadomo, co tam się wydarzy.
Vladimir: Wiesz co, taka ciekawa rzecz… Pamiętam czasy, kiedy pojawiły się telefony komórkowe i wtedy mówiło się, że to jest jakby przedłużenie naszej ręki. Jak się zostawiło komórkę w domu, to stanowiło problem. Słuchając ciebie, mam wrażenie, że teraz te technologie, które używasz, to są jak osobisty asystent, który jest przedłużeniem ciebie.
Obecnie cały ten przepływ pracy, który wykonujesz codziennie, jest już wspierany przez narzędzia takie jak ChatGPT czy Claude, albo inne modele językowe. I rozmowa z tzw. sztuczną inteligencją na co dzień nie jest już czymś wyjątkowym, tylko stała się nieodzownym elementem naszej codzienności, prawda?
Cezar: Znaczy ja już sobie nie wyobrażam pracy bez w ogóle modeli generatywnych. To jest zawsze, jak człowiek już dozna pewnego poziomu wygody, no to jest mu ciężko wrócić do tego, co było wcześniej. Zwłaszcza, że ilość po prostu możliwości… Ja do tej analizy danych wracam. Wiesz, ja gdybym miał się… Ja nigdy inaczej, ja nie wiem, ile czasu bym musiał poświęcić, żeby osiągnąć taki poziom używania Pythona, który zdobyłem z ChatGPT.
Bo po prostu musiałem dobrze formułować, czego oczekuję, że potrzebuję funkcji, która mi na przykład z tego Excela wydobędzie 10 najbardziej popularnych pozycji, następnie zamieni mi to na słupki, nie? I ja wiesz, jakbym miał sam szukać, jak się taki kod pisze, ja bym to zrobił, ale bym to robił pewnie kilka dni. A tutaj miałem to w 5 minut i mogłem bardzo szybko po prostu sprawdzić, czy to działa.
No… Dzisiaj tak naprawdę mam bardzo dużą wiedzę o analizie danych w Pythonie, więc to też moim zdaniem trochę… Bo to jest trochę mit, że jak korzystamy z modeli generatywnych, to one sprawiają, że człowiek przestaje myśleć. No właśnie nie, ja się tyle nauczyłem w trakcie, no bo też uczyłem się ewaluować.
Przepraszam za taką trochę specjalistyczną wstawkę, ale powiedziałem o tej bibliotece Seaborn. Dlaczego w ogóle ja odkryłem Seaborna? No bo model generatywny, jeżeli nie podajesz mu jakich…
Jeśli ty nie wiesz, jaka jest najlepsza strategia na rozwiązanie problemu, no to model generatywny zaproponuje ci taką, która według niego jest najlepsza, a według niego najlepsza jest zawsze ta najbardziej popularna w internecie na przykład i jak się domyślasz, on mi sugerował zawsze matplotlib – to jest taka najpopularniejsza biblioteka do generowania wykresów. I co się stało? Mi się one nie podobały i zapytałem, czy mógłby wygenerować mi wykresy w kolorze pastelowym. Powiedział mi, że matplotlib nie ma kolorów pastelowych, ale ma właśnie biblioteka Seaborn. I tak się nauczyłem właśnie, że istnieje biblioteka Seaborn. I od zawsze teraz dodaję o tym informację do prompta.
I po prostu zmierzam do tego, że to nie jest jednostronna relacja. To, że model sugeruje mi rozwiązania, których ja nie znałem, no i ja muszę siłą rzeczy je wypróbować, no to ja się też bardzo, bardzo dużo uczę. I bardzo uważam, że to jest ważne, żeby to zrozumieć, że jeśli pracownik dzisiaj korzysta z modeli generatywnych, to on nawet nie widzi od razu tego, ile on się dodatkowych rzeczy nauczy, których normalnie nie miałby czasu się nauczyć, albo nawet by nie wiedział, że się może ich nauczyć. To jest niesamowite.
Vladimir: No właśnie, dochodzimy do kluczowego momentu. Miałem inspirację – zaraz to wyjaśnię. Chodzi o to, że rozmowa z asystentem opartym na sztucznej inteligencji przestaje być domeną wyłącznie techników czy entuzjastów technologii. Coraz bardziej staje się to codziennością.
Patrząc w przeszłość, zauważamy, że kiedyś w CV dominowała znajomość Excela czy podobnych narzędzi. Teraz pojawia się potrzeba umiejętności komunikowania się ze sztuczną inteligencją. Może to być nazwane różnie, na przykład „prompt engineering” – nie ma znaczenia, jak to nazwiemy, ważne, co kryje się pod tym pojęciem.
Rzeczywiście, jesteśmy na etapie, gdy ta umiejętność staje się coraz bardziej popularna. Inspiracja przyszła, gdy dogłębniej poznaliśmy ten temat. Pomyślałem wtedy: „To jest świetne! To, co robisz, jest fantastyczne, bo używasz tego na co dzień, ale również pokazujesz, jak to działa w praktyce.”
Zaprosiłem wtedy Ciebie do przygotowania szkolenia, które, według mnie, będzie bardzo wartościowe. Tak więc, na razie pozostawiamy szczegóły na później. Chcemy tylko zapowiedzieć, że połączyliśmy siły, aby stworzyć coś wartościowego dla ludzi. To szkolenie będzie czymś naprawdę wyjątkowym. Co o tym myślisz, chcesz coś dodać?
Cezar: Wiesz co, Vladimir, nie mogę się z jedną rzeczą zgodzić, którą powiedziałeś, bo powiedziałeś, że może to będzie wartościowe, ale w sensie to nie chodzi teraz o żadne gadanie marketingowe, w sensie, no bo ja tak sobie myślę, powiedziałeś o tym prompt engineeringu, ja w ogóle mam takie wrażenie, że dzisiaj nie jest istotne to, czy ty wiesz, że istnieje model X, Y albo Z.
Jest to dobra wiedza, nie mówię, żeby tego nie śledzić, ale zauważ, że bez względu na to, czy mówimy o modelach od Google’a, od OpenAI’a, czy nawet, nieważne, czy mówimy o modelach, asystentach, nieważne o jakiej tak naprawdę mówisz interpretacji, interfejsie tego AI’a, to wszystkie łączy to, że musisz z nimi promptować, w sensie, to nie jest już kwestia, czy to będzie umiejętność moim zdaniem, to po prostu będzie uniwersalna, po prostu na to, tego się nie da po prostu moim zdaniem podważyć, bo niektórzy mówią, że są takie głosy. Niektórzy twierdzą, że promptowanie nie będzie aż tak potrzebne, bo na przykład GPT-5 będzie już tak wszystko wiedział, że te prompty nie będą takie istotne. I ok, prawdopodobnie będzie tak, że nie będziemy musieli robić tego promptowania tak bardzo dokładnego.
Ale nie zmieni się to, że to cały czas będzie rozmowa i będziesz musiał umieć rozmawiać i dobrze się komunikować z modelami generatywnymi. Tak jak kiedyś pakiet Office to był po prostu moim zdaniem standard – nie dało się bez tego dostać pracy biurowej, no to prompt engineering będzie dokładnie tym samym.
Nie wierzę szczerze powiedziawszy w to, że będą prompt engineerzy. Ja jakbym miał dzisiaj obstawiać, uważam, że nie będzie takich stanowisk na dłuższą metę.
Ale prompt engineering w takim rozumieniu, że to jest jak pakiet Office w czasach AI, to już tak. To dzięki stąd karykty, bo ja faktycznie czasem tak troszkę skromnie pewnie myślę i wypowiadam się.
Dlatego powiedzmy to na głos: to będzie bardzo potrzebna, wartościowa umiejętność, która nie będzie opcjonalna, tylko konieczna. Pytanie tylko, czy nauczysz się z opóźnieniem i będziesz mieć z tego powodu stres, czy jednak zrobisz to na spokojnie.
Przy czym ważna też taka myśl, którą trzeba zapamiętać, bo taka szkoła gdzieś tam się też narodziła, że bardziej próbuje się przekazać takie szablony. To na pewno nie o to chodzi. Szablony na pewno nie działają jak w życiu. Szablony są wygodniejsze, bo tam klik, klik i coś tam masz, ale to jest natalne bezsensu, bo to się zmienia wszystko.
Trzeba złapać mechanizmy i zrozumieć, jaka jest idea, jak to połączyć w taki sposób, jak te warstwy, które wymienialiśmy, żeby to dawało faktycznie wartość. Tak, zwłaszcza że z szablonami to w ogóle jest taka pułapka, że nawet jeśli stworzysz super prompta i zadziała on doskonale, to na innych danych ten sam prompt może dać zupełnie inne wyniki. Nie zawsze lepsze, często nawet gorsze. Więc i tak na koniec dnia warto rozumieć, jak się tworzy dobry prompt, bo to po prostu daje ci największą elastyczność i pewność, że jesteś w stanie stworzyć coś, co działa.
Vladimir: Dziękuję, Cezary, za te cenne wskazówki i inspirującą rozmowę. Dla wszystkich zainteresowanych pogłębieniem wiedzy w tym temacie – już wkrótce ruszamy z szkoleniem, które pomoże rozwinąć umiejętności efektywnej komunikacji z AI. Zachęcam do zapisania się na listę chętnych. To świetna okazja, by zdobyć kompetencje, które staną się niezbędne w niedalekiej przyszłości.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
