
7 Mitów o sztucznej inteligencji
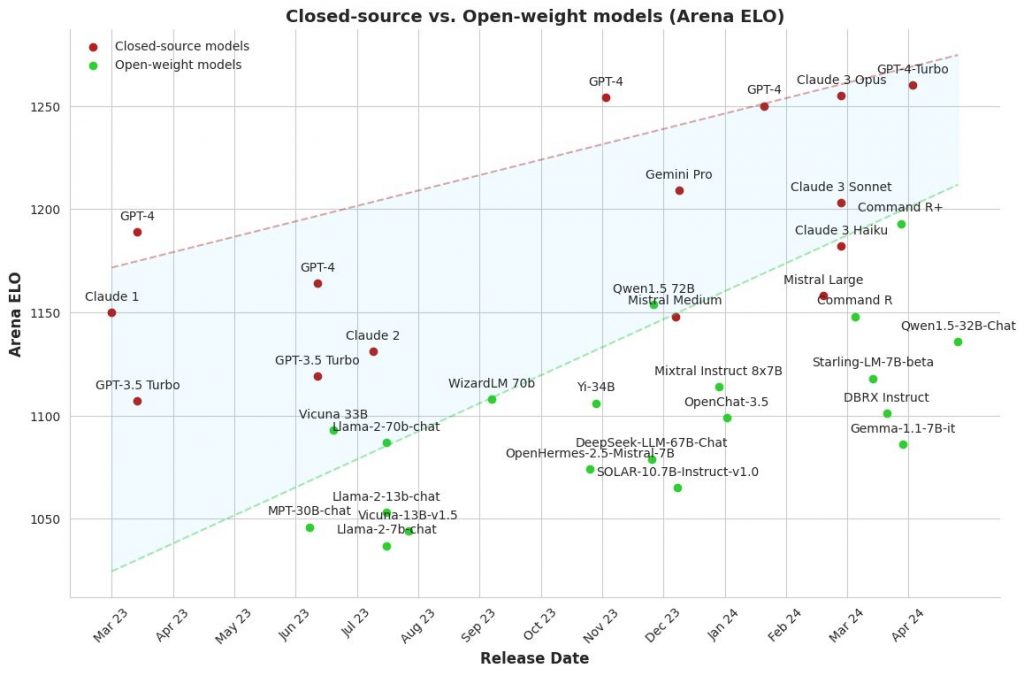
Wprowadzenie
Cześć! Nazywam się Vladimir Alekseichenko i witam Cię w podcaście „Biznes Myśli” – Twoim sprawdzonym źródle informacji na temat sztucznej inteligencji. Jako praktyk z wieloletnim doświadczeniem we wdrażaniu modeli machine learningu w celu generowania zysków, chcę wraz z gośćmi zgłębiać tajniki AI i ML. Będziemy rozmawiać o tym, co jest ważne i jakie możliwości oraz korzyści te technologie mogą przynieść Tobie lub Twojej firmie.
Podcast powstaje przy wsparciu założonej przeze mnie spółki DataWorkshop, zajmującej się praktycznym uczeniem maszynowym. Jeśli potrzebujesz wytrenować modele, wdrożyć je, skonsultować pomysły, a może nauczyć się robić to samodzielnie lub przeszkolić zespół – jesteśmy właściwym adresem. Zaufało nam już wiele osób, duże firmy i liderzy tacy jak Leroy, mBank czy Orange.
Pamiętaj – świat zmieni się szybciej, niż myślisz. Zaczynamy!
Powrót do mitów o AI
W dzisiejszym, 122. odcinku podcastu, powrócimy do tematu mitów związanych ze sztuczną inteligencją. Już w kwietniu 2019, w 55. odcinku, omawiałem 10 najpopularniejszych mitów. Sprawdziłem je przed nagraniem – nadal są aktualne, choć o niektórych można podyskutować. Oto one w skrócie:
- Sztuczna inteligencja jest zła.
- AI jest tylko dla dużych graczy.
- Sztuczna inteligencja to gotowy przepis na sukces.
- Algorytmy są ważniejsze niż dane (ten mit jest dziś jeszcze bardziej aktualny).
- Mamy lub nie mamy danych.
- Prototyp równa się rozwiązaniu do wdrożenia (do tego wrócę, wyjaśniając jak to wygląda w obecnym kontekście).
- AI = roboty.
- Sztuczna inteligencja to kura znosząca złote jajka (tę analogię też przypomnę, ale w nieco innym ujęciu).
- AI jest twórcą (to może budzić dyskusje, ale wyjaśniam tam swoje intencje).
- Sztuczna inteligencja jest uczciwa.
Jeśli chcesz usłyszeć więcej, sięgnij po 55. odcinek w wersji audio lub tekstowej na stronie.
Mity o LLM
Dzisiaj jednak skupię się przede wszystkim na mitach związanych z LLM (Large Language Models), bo tych nawarstwiło się ostatnio sporo. W minionym miesiącu aktywnie uczestniczyłem w różnych wydarzeniach, meetupach i konferencjach – jako słuchacz i prelegent. Mimo że jestem raczej introwertykiem, starałem się rozmawiać z ludźmi, by lepiej zrozumieć, jak myślą o tych tematach.
To normalne, że możemy się mylić, bo nie każdy ma czas, by dogłębnie śledzić, co się faktycznie dzieje. Źródła, z których czerpiemy wiedzę, bywają mniej sprawdzone niż Biznesowe Myśli, więc łatwo o nieporozumienia.
Udało mi się wychwycić pewne powtarzające się wzorce myślenia, o których chciałbym dziś porozmawiać i je wyjaśnić. Choć nie wyczerpują one wszystkich mitów wartych omówienia, skupię się na siedmiu najważniejszych.
Mit 1: Tylko ChatGPT się liczy
Jeśli interesujesz się choć trochę tematami LLM i AI, to zapewne wiesz, że istnieją również inne modele poza ChatGPT.
Jeśli interesujesz się choć trochę tematami LLM i AI, to zapewne wiesz, że istnieją również inne modele poza ChatGPT. Jednak wiele osób kojarzy przede wszystkim ChatGPT jako jedyny model do LLM, albo nawet nie wiedzą do końca, czym jest LLM, czyli duży model językowy, tylko bardziej odnoszą się do AI.
Jeżeli popatrzysz na takie narzędzia jak np. Google Trends, zauważysz bardzo ciekawą korelację. Po wpisaniu modeli takich jak ChatGPT, Claude od Anthropic, Gemini od Google czy Llama od Facebooka, widać wyraźnie, że ChatGPT zajął prawie 100% rynku, jeżeli chodzi o rozpoznawalność.
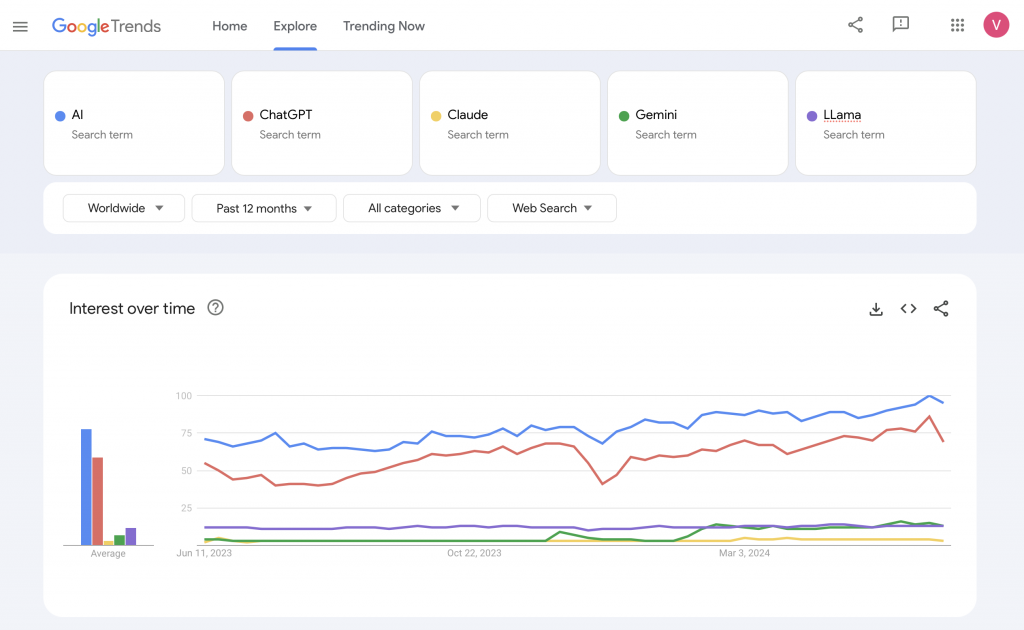
Co więcej, trendy dla haseł „AI” i „ChatGPT” również wykazują zauważalne podobieństwo. Prawie idealne, równoległe falowanie na wykresach. Choć utożsamianie ChatGPT z AI może być niebezpieczne, bo to na pewno nie jest tożsame, da się to w pewnym sensie wyjaśnić. Większość osób zaczęła na nowo myśleć o sztucznej inteligencji właśnie po pojawieniu się słynnej wersji 3.5 ChatGPT.
Zamknięte i otwarte modele AI
Warto wiedzieć, że poza ChatGPT istnieją też różne inne modele AI. Można je podzielić na zamknięte i otwarte.
Zamknięte modele są udostępniane poprzez API. Oznacza to, że gdzieś w chmurze na cudzym komputerze działa taki model. Wysyłasz do niego zapytanie z tym, co chcesz uzyskać i dostajesz odpowiedź. Nie wiesz jednak, co dokładnie dzieje się w środku z danymi i jak są one przetwarzane. Przykładami zamkniętych modeli są OpenAI (mimo paradoksalnej nazwy bardziej pasowałoby ClosedAI), Anthropic z modelem Claude, Google z Gemini i kilka innych.
Jeśli chodzi o otwarte modele, tutaj mamy więcej możliwości. Jednym z najbardziej znanych jest Llama od Facebooka. Aktualnie najnowsza wersja to Llama 3 dostępna w różnych wersjach – mniejszej 7B i większych, sięgających nawet 400 miliardów parametrów. Inne warte wspomnienia firmy z otwartymi modelami to Mistral czy Cohere.
Mity na temat otwartych modeli AI
Wokół tematu LLM nawarstwiło się kilka mitów, które warto wyjaśnić. Gdy mówimy, że model jest otwarty, nie zawsze oznacza to, że można go swobodnie używać komercyjnie.
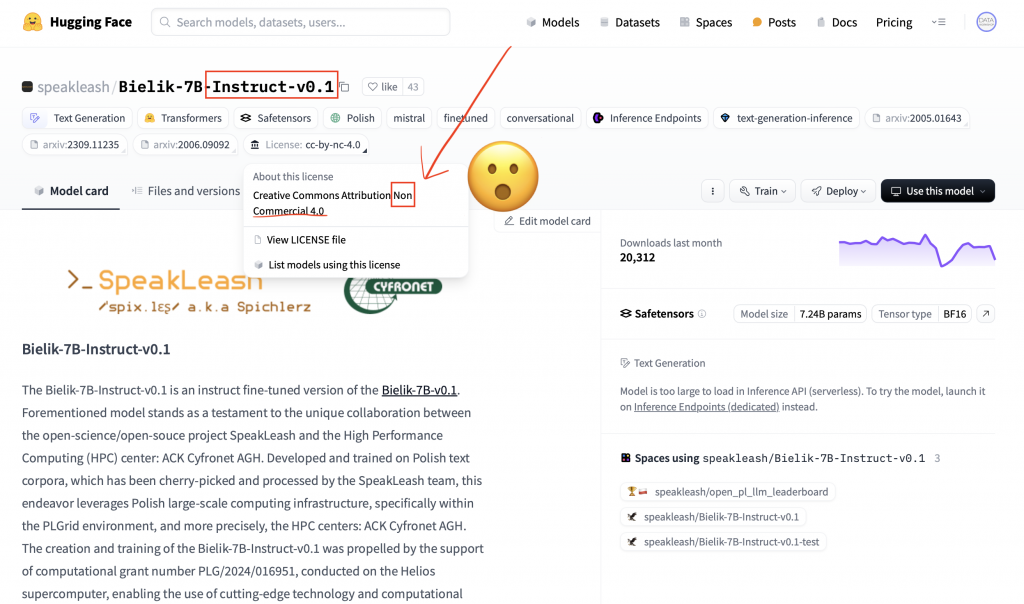
Przykładem jest popularny ostatnio w Polsce model Bielik. Gdy wejdziesz na jego stronę, zobaczysz, że jest on dostępny na licencji Creative Commons, ale z dopiskiem „non-commercial”. Czyli można go używać, trenować na nim, ale nie w celach biznesowych. Twórcy udostępnili go w takiej formie nie tylko ze swojej woli, ale też ze względu na kilka istotnych szczegółów pod spodem.
Podsumowując, warto mieć świadomość różnorodności modeli AI i nie utożsamiać wszystkiego z ChatGPT. Jednocześnie trzeba uważać na pewne niuanse, jak choćby licencje otwartych modeli, które nie zawsze pozwalają na dowolne komercyjne wykorzystanie. Temat LLM i AI ciągle się rozwija, więc na pewno jeszcze nieraz usłyszymy o nowych, ciekawych rozwiązaniach w tym obszarze
Różnorodność modeli AI – niuanse i wyzwania
Aby powstała wersja Instruct modelu językowego, trzeba go wytrenować na zbiorze instrukcji. Część z nich została przygotowana przez zespół Bielika lub w podobny sposób, dzięki czemu można ich używać. Jednak druga część instrukcji została tak stworzona, że nie możemy ich później wykorzystywać komercyjnie.
Na przykład, ChatGPT umożliwia generowanie tekstu, ale jeśli dotrenujesz swój model na podstawie tekstu powstałego z ChatGPT lub Lamy, to masz problem z użyciem komercyjnym. Nie możesz ulepszyć swojego modelu, wykorzystując inne modele, takie jak ChatGPT lub podobne, bo jest to zakazane.
Oczywiście są tu różne strefy – de jure tego robić nie można, de facto, kto to wykryje, ale to zostawiam na własną odpowiedzialność każdego. Więc to ciekawostka – pierwszej wersji instrukcji Bielika nie można wykorzystywać komercyjnie.
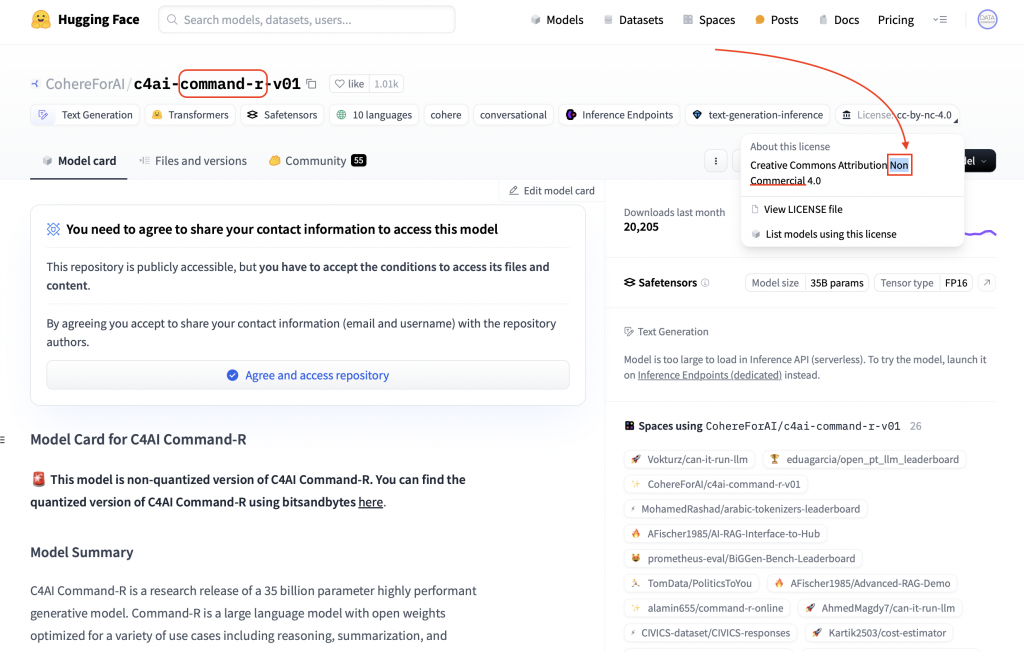
Kolejnym przykładem jest firma Cohera z Kanady, która ma teraz biuro w USA. Wypuścili oni model Command R i Command R+. Ten pierwszy jest całkiem fajny, jeżeli chodzi o reprezentację, wyciąganie tagów, czyli wzbogacenie i wyszukanie informacji. Problem w tym, że udostępnili go do pobrania każdemu, ale znów – nie możemy używać go komercyjnie. Nie znamy też do końca szczegółów, jak ten model został wytrenowany, więc nie możemy za bardzo cokolwiek z nim zrobić.
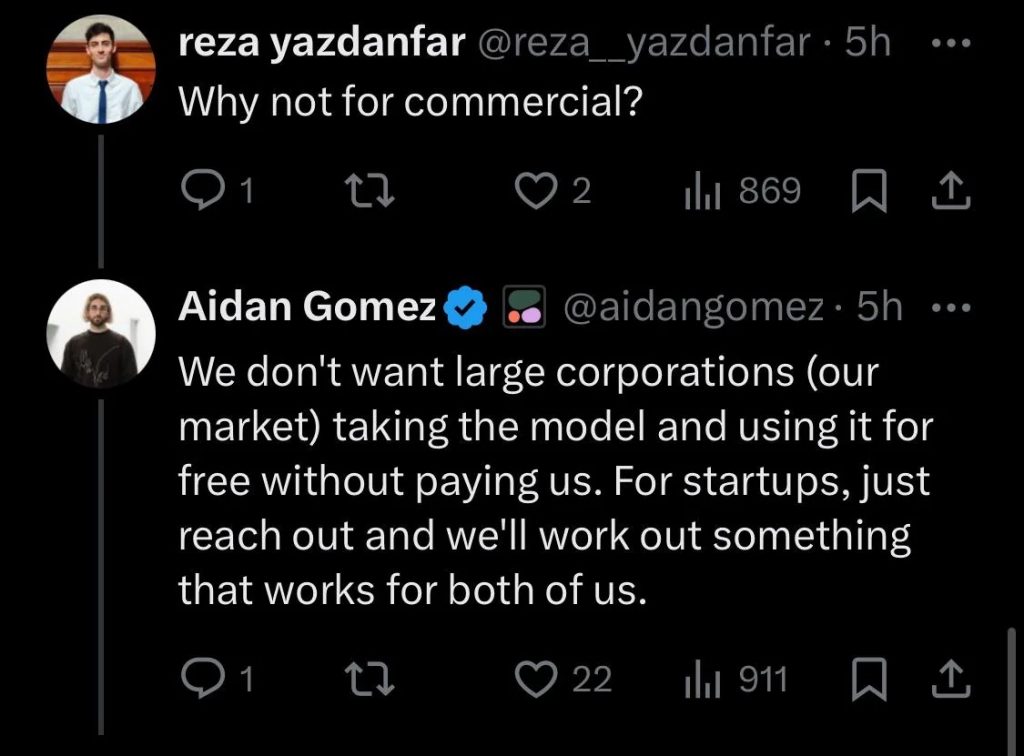
Ciekawostką odnośnie Cohery jest dyskusja na Twitterze, gdzie ktoś zapytał, czemu model jest zamknięty. Odpowiedziano, że chodzi głównie o ograniczenie dużych graczy. Jeśli jesteś małym startupem, możesz do nich napisać i zobaczyć co da się zrobić. Być może umożliwią ci użycie komercyjne.
Llama – najbardziej otwarta, ale z ograniczeniami
Llama jest generalnie najbardziej otwarta ze wszystkich wymienionych rozwiązań. Możemy ją wykorzystywać komercyjnie, chyba że jesteś Google’em lub kimś podobnym. W licencji ciekawie opisano, że jeśli masz więcej niż miliony aktywnych użytkowników, to również nie możesz jej używać. Zrobiono to dla ograniczenia Big Tech’u, ale mniejsze firmy mogą korzystać.
Lama zabrania też wykorzystywania tego modelu do usprawniania innych modeli niż ona sama, co również jest ciekawostką.
Dlatego tą „otwartością” bywa różnie, dlatego uważaj, szczególnie jeśli chodzi o zastosowania komercyjne. Zawsze sprawdzaj, czy konkretny model faktycznie możesz użyć komercyjnie. Nawet jeśli wykryją, że wykorzystujesz model w szarej strefie, zakładamy że chodzi o odpowiedzialność. Zwracaj na to uwagę.
Open source goni trendy
Warto wspomnieć, że open source również próbuje gonić trendy. Na początku, kiedy ruszył ChatGPT, rozwiązania otwarte były bardzo w tyle, z dużą różnicą jakości. Natomiast teraz widzimy, że jeśli chodzi o leaderboardy, open source jest coraz bliżej poziomu modeli zamkniętych, co jest dobrą wiadomością.
Mit 2: LLM i GenAI to coś innego niż ML
Kolejny mit można było nazwać na kilka sposobów, ale ujmijmy to tak: LLM czy generatywna sztuczna inteligencja to coś innego niż machine learning albo uczenie maszynowe. Pewne rzeczy, które zostały opracowane w ML, w szczególności mówimy o wdrażaniu na produkcję, one nadal obowiązują również dla LLM. Nie ma cudów, nie ma magii, to wszystko jest nadal aktualne.
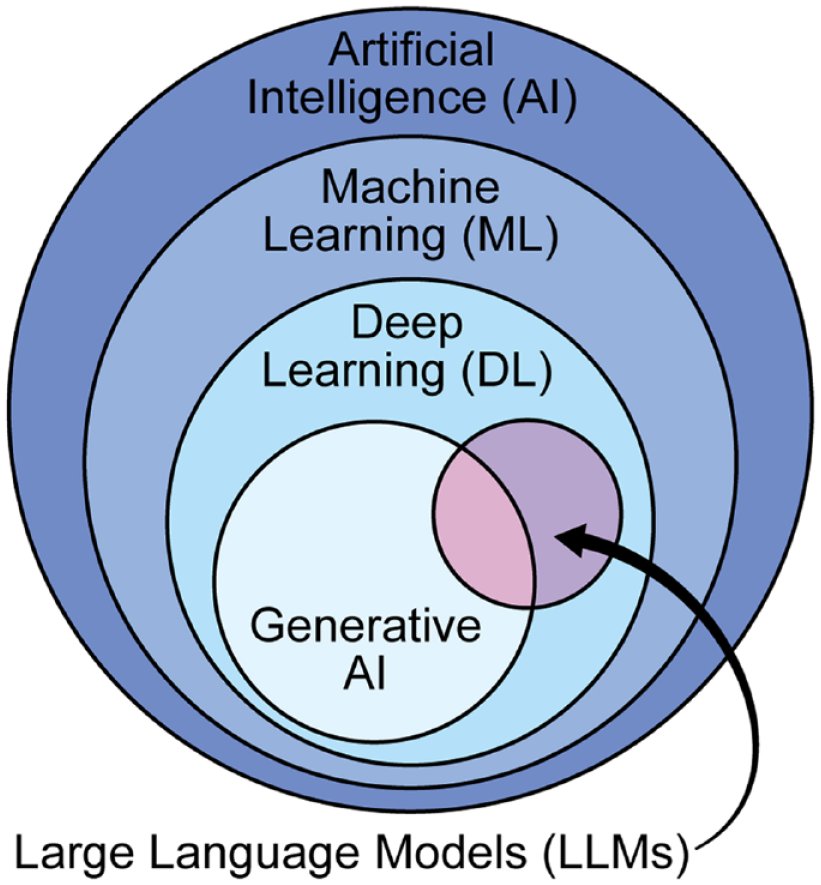
LLM i generatywna AI to część szerszego obszaru machine learningu i sztucznej inteligencji. Wiele podstawowych zasad i technik ML nadal ma zastosowanie w tych nowszych podejściach.
Sztuczna inteligencja (AI) to pojęcie, do którego dążymy. Chodzi o coś, co zachowuje się w inteligentny sposób. Na ten moment najlepszym narzędziem, które przybliża nas w kierunku AI, jest machine learning, czyli uczenie maszynowe.
ML zawiera różne algorytmy i podejścia, w tym klasyczne, które nadal generują najwięcej wartości, ale też takie, które opierają się na sieciach neuronowych. Gdy ML staje się bardziej zaawansowany, mówimy o deep learningu, czyli głębokim uczeniu maszynowym.
Jednym z rodzajów deep learningu są transformers. To właśnie tam pojawia się pojęcie NLP (Natural Language Processing) i LLM (Large Language Models). LLM na ten moment, z małymi wyjątkami, to głównie transformers. Mamy zatem taki ciąg: ML, deep learning, transformers, LLM.
Warto zwrócić uwagę, że nie zawsze LLM równa się GenAI. Nie wszystkie LLM generują treść w postaci rozmowy, jak np. z chatem. Część LLM ma taki cel, a część nie – niektóre mają bardziej cel klasyfikacyjny. Jednak w większości przypadków, gdy mówi się o LLM, chodzi o GenAI, czyli tworzenie i generowanie pewnej wartości.
Wcześniej zdarzały się problemy z odróżnieniem prototypu od rozwiązania gotowego do wdrożenia na produkcję (production-ready). Czasem, gdy w firmie powstawał prototyp, wyglądało to, jakby model był już gotowy do implementacji. To bardzo ryzykowne podejście.
W przypadku LLM ta różnica jeszcze bardziej znacząco wzrosła. Pojawiły się duże wyzwania z odróżnieniem prototypu od rozwiązań, które rzeczywiście nadają się do wdrożenia na produkcję.
Powstanie znanych frameworków, jak LangChain i kilku innych, z jednej strony umożliwia bardzo szybkie i łatwe generowanie prototypów. Czasem wystarczy dosłownie kilka linii kodu – pięć, dziesięć, może pięćdziesiąt – i już mamy działające rozwiązanie, które robi efekt „wow”. Jednak po wdrożeniu takiego rozwiązania można napotkać pewne problemy.
Krzywa Gartnera a LLM
Warto w tym kontekście zwrócić uwagę na tak zwaną krzywą Gartnera. Choć nie zawsze jest ona w pełni spójna, pewne sygnały, które można z niej odczytać, są przydatne.
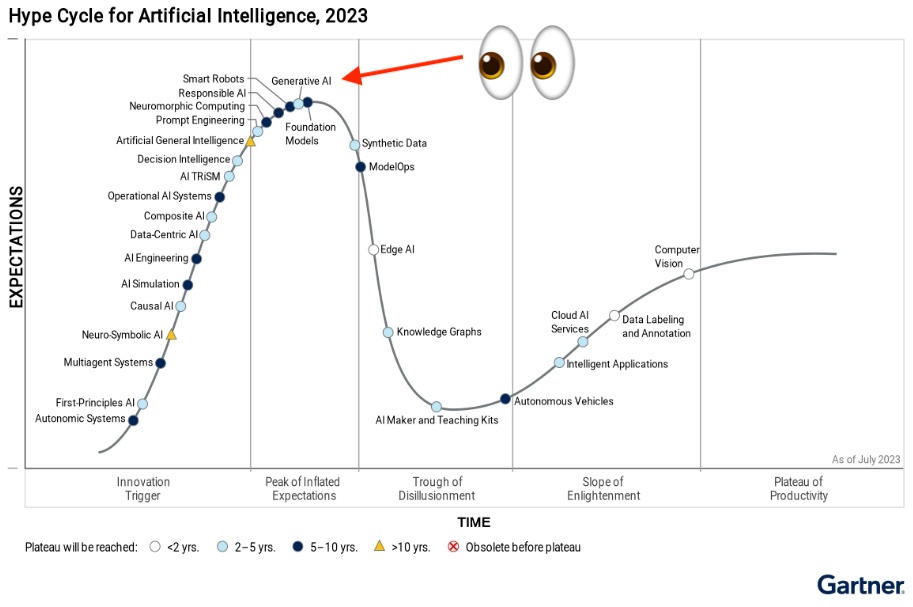
Patrząc na najnowszą krzywą z 2023 roku, widać, że LLM znajduje się na jej szczycie. Jak to bywa w życiu, nie ma rzeczy idealnych, są różne odcienie szarości. Mimo to sygnał informacyjny płynący z krzywej Gartnera jest wartościowy i warto go wziąć pod uwagę, myśląc o implementacji LLM w swojej organizacji.
Niedługo będziemy świadkami zjawiska, gdy pojawi się wiele informacji sugerujących, że LLM nie działa zgodnie z oczekiwaniami i jest znacznie gorsze niż się wydawało. Źródłem problemu jest między innymi fakt, że dużo łatwiej jest zrobić prototyp niż przygotować stabilne rozwiązanie gotowe do wdrożenia.
W dzisiejszych czasach niemal każdy może zrobić prototyp LLM, który robi wrażenie. Natomiast przygotowanie aplikacji, którą można bezpiecznie wdrożyć na produkcję tak, by biznes na tym nie tracił, to zupełnie inna para kaloszy. Występuje tu prawdziwa przepaść między prototypem a rozwiązaniem produkcyjnym.
Problem ten nie jest nowy, ale w przypadku LLM i szerzej pojętej AI urósł do niespotykanych wcześniej rozmiarów. Warto mieć to na uwadze planując wykorzystanie tej technologii w swojej organizacji. Nie daj się zwieść łatwości, z jaką da się dziś stworzyć atrakcyjny prototyp. Droga do stabilnego rozwiązania biznesowego jest dużo dłuższa i bardziej wymagająca.
Mit 3: Halucynacja to bug
Czym jest halucynacja w kontekście AI? Formalnie rzecz biorąc, mamy z nią do czynienia, gdy LLM tworzy odpowiedź inną niż oczekiwana. Temat ten został już dość dobrze zbadany, powstało wiele publikacji naukowych i innych materiałów, które pozwalają zrozumieć ciekawe źródła tego problemu.
Najważniejsza myśl, którą chciałbym Ci przekazać, to mechanika tego zjawiska. Halucynacja to nie jest bug. Owszem, to niepożądane zjawisko, kiedy nasz model tworzy rzeczy, na których biznes może stracić, ale spróbujmy zrozumieć tę mechanikę, bo dzięki temu będziesz lepiej tym zarządzać.
Aby lepiej to zrozumieć, przytoczę pewną analogię. Wyobraź sobie farmera, który miał kurę. Zauważył on, że ta kura ma dwie części: przednią, która je ziarenka generując koszty, oraz tylną, która znosi jajka przynosząc zyski. Farmer pomyślał – co by tu zrobić, żeby pozbyć się tej przedniej części i zostawić tylko tylną? Idealnie, prawda? Problem w tym, że tak się nie da. Bez przedniej części, nie będzie też tylnej. To prawo natury.
Podobnie jest z LLM. Ta halucynacja to nie bug, to sposób działania modelu. LLM cały czas marzy, fantazjuje. Za każdym razem, gdy dajemy mu konkretne zadanie, on zaczyna marzyć. Kiedy trafia w to, czego oczekujemy, cieszymy się. Ale gdy zwraca coś innego, pojawia się problem – przynajmniej dla nas. Zaczynamy narzekać, choć to nie jest wina LLM. Jeśli wyeliminujemy element marzenia, równie dobrze możemy w ogóle z niego nie korzystać.
Zupełnie inną kwestią jest zastanowić się, skoro to jest wbudowane w rdzeń mechanizmu funkcjonowania LLM, co możemy zrobić? Jak tym zarządzać?
Kolejna analogia, szczególnie przydatna jeśli masz doświadczenie w zarządzaniu ludźmi twórczymi – jeśli zaczniesz ich za bardzo ograniczać, narzucać regulaminy i procedury, to albo uciekną, albo przestaną „znosić złote jajka”. Jako mądry menadżer dajesz im przestrzeń do odnalezienia się, ale tak konfigurujesz środowisko, by móc tym zarządzać. Wiesz, że taka osoba może czasem spaść w niepożądane, niebezpieczne ścieżki. Myślę, że ktoś zarządzający takimi ludźmi doskonale to rozumie.

Podobnie jest z LLM i generowaniem treści. Pewne rzeczy upraszczam i robię to świadomie, ale jeśli pomyślisz w ten sposób, łatwiej będzie Ci zrozumieć, jak zarządzać niepożądanym zjawiskiem generowania przez model rzeczy wadliwych, niepotrzebnych, a jednocześnie skorzystać z tej części, która niesie nasze „złote jajka”.
Polecam myśleć w ten sposób, zamiast tylko narzekać na to, że model halucynuje. Tym da się zarządzać, choć jest to temat szerszy i nie da się go w pełni wyjaśnić w kilku zdaniach. Chciałem jednak zwrócić uwagę, że halucynacje modelu nie są błędem (bugiem), a raczej wynikają z tego, jak model działa pod spodem.
Zarządzanie AI i generowaniem treści można porównać do zarządzania twórczymi ludźmi. Kluczem jest znalezienie równowagi między dawaniem przestrzeni a konfigurowaniem środowiska, by móc tym zarządzać. Dzięki takiemu podejściu możemy czerpać korzyści z potencjału LLM, jednocześnie minimalizując niepożądane efekty.
Mit 4: Duże okna kontekstowe „robią robotę”
Wiele firm, takich jak Google, chwali się coraz większymi oknami kontekstowymi w swoich modelach języka, sięgającymi nawet milionów tokenów. Może to prowadzić do mylnego przekonania, że wystarczy po prostu wrzucić do modelu wszystkie dane firmy, a on sam znajdzie potrzebne informacje bez konieczności wykorzystywania innych systemów. Niestety, nie jest to takie proste.
Przede wszystkim, wysyłanie całej bazy danych za każdym razem, gdy potrzebujemy znaleźć konkretną odpowiedź, brzmi dziwnie z technicznego punktu widzenia. To tak, jakbyśmy za każdym razem, gdy potrzebujemy jednej książki, musieli przeglądać wszystkie książki w bibliotece po kolei. Nawet gdybyśmy byli w stanie zrobić to szybko, takie rozwiązanie wydaje się bardzo nieefektywne.
Co więcej, samo rozumienie tekstu przez model może stanowić wyzwanie, nawet przy bardzo długich oknach kontekstowych. Istnieją różne testy, takie jak „poszukiwanie igły w stogu siana”, które pokazują, że im dłuższe okienko, tym gorsze wyniki w znajdowaniu poszukiwanych informacji. Sytuacja pogarsza się jeszcze bardziej, gdy tych „igieł” jest więcej i są umieszczone w różnych miejscach, a my chcemy nie tylko je znaleźć, ale również zadać pytania na ich temat.
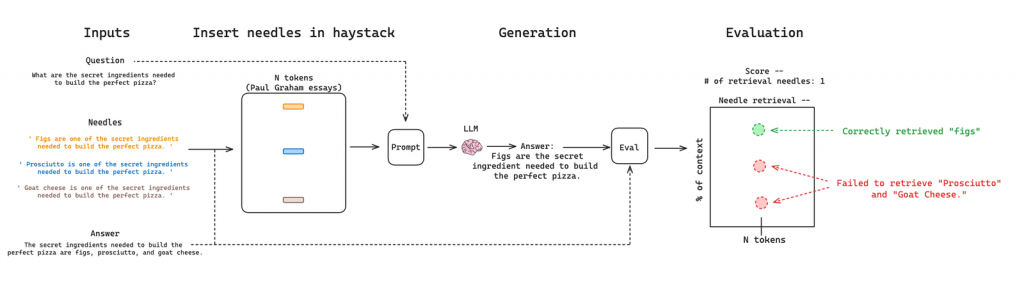
Wraz z rozszerzaniem się okienek kontekstowych, ludzie zaczęli dostrzegać te problemy i przeprowadzać dodatkowe testy. Wyniki jasno pokazują, że samo zwiększanie rozmiaru okna nie rozwiązuje wszystkich wyzwań związanych z wyszukiwaniem informacji przez modele LLM.
Warto mieć to na uwadze, planując wykorzystanie tej technologii w swojej organizacji. Nie dajmy się zwieść pozornej łatwości i pamiętajmy, że stworzenie efektywnego systemu wymaga przemyślanego podejścia, a nie tylko polegania na coraz większych oknach kontekstowych
Poznaj BABIlong – test, który pomoże ocenić efektywność modeli językowych
Wśród testów oceniających modele językowe warto zwrócić uwagę na mniej znany, ale ciekawie zaprojektowany BABILong. Jego nazwa nawiązuje do dłuższych okien kontekstowych (long), które są istotnym elementem tego testu. Znajdziesz w nim przykłady, które pozwalają lepiej zrozumieć możliwości i ograniczenia współczesnych modeli AI.
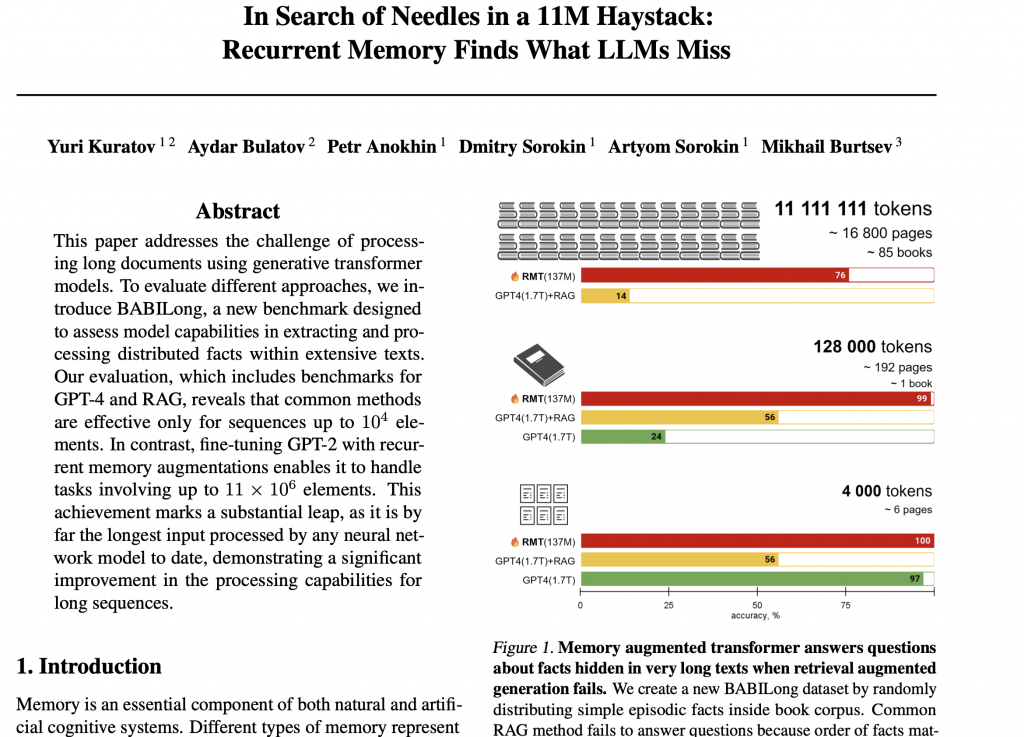
Nie daj się zwieść pozorom – większe okno kontekstowe to nie zawsze lepszy model
Ostatnio pojawił się model reklamowany jako tańszy i lepszy od GPT-4. Osobiście nie polecam go, ponieważ przy dłuższych oknach kontekstowych szybciej zaczyna mieć problemy z rozumieniem treści. Teoretycznie przyjmuje on okna o długości 128 tysięcy tokenów, ale w praktyce już po przekroczeniu 2 tysięcy tokenów jego skuteczność spada.
Podobnie jest w przypadku innych modeli, takich jak GPT-4, Gemini czy Claude. Mimo deklarowanej możliwości przetwarzania nawet 128 tysięcy tokenów, ich efektywna wartość zazwyczaj nie przekracza 16 tysięcy. Mit o tym, że większe okna kontekstowe rozwiązują wszystkie problemy i pozwalają modelowi lepiej znajdować i przetwarzać informacje, nie znajduje potwierdzenia w rzeczywistości.
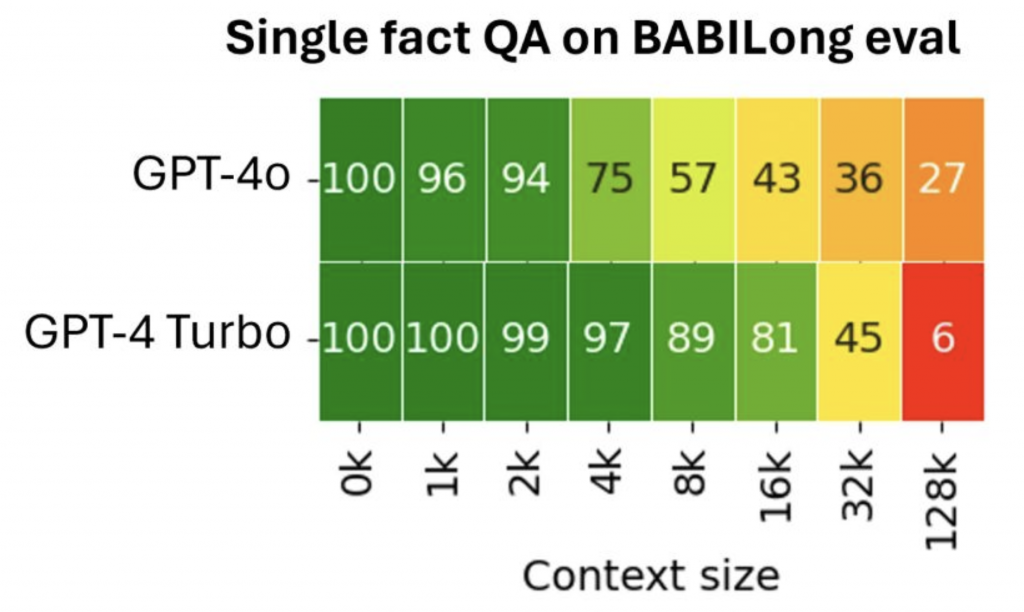
Obiecana a efektywna długość okna kontekstowego – czym się różnią?
Warto rozróżnić pojęcia obiecanej i efektywnej długości okna kontekstowego. Ta pierwsza odnosi się do długości promptu, czyli tekstu, który wysyłamy do modelu. Możemy przesłać nawet całą książkę, o ile zmieścimy się w limicie tokenów (dla uproszczenia można przyjąć, że token to mniej więcej jedno słowo).
Efektywna długość okna kontekstowego to natomiast maksymalna ilość tokenów, jaką model jest w stanie przetworzyć bez utraty jakości. Obecnie wynosi ona około kilku tysięcy tokenów – dla GPT-4 to 2-4 tysiące, a dla GPT-4 Turbo około 16 tysięcy. Przekroczenie tych wartości skutkuje pomijaniem przez model istotnych faktów i informacji.
Nie zapominaj o ograniczeniach rozmiaru danych wyjściowych
Nawet jeśli model posiada ogromne okno kontekstowe, pamiętaj, że zawiera ono zarówno dane wejściowe (input), jak i wyjściowe (output). Ich rozmiary sumują się, choć różne modele podchodzą do tego inaczej. W przypadku GPT łączna wielkość danych wejściowych i wyjściowych mieści się w oknie kontekstowym, ale output zawsze jest mniejszy od inputu.
Przy zadaniach typu streszczenie, gdzie na wejściu mamy dużo treści, a na wyjściu oczekujemy niewielkiej ilości tokenów (np. 2-4 tysiące), nie ma problemu. Gorzej, gdy input i output powinny być porównywalne, jak przy tłumaczeniu czy sprawdzaniu artykułu. Wtedy ograniczenia rozmiaru danych wyjściowych wpływają też na maksymalny rozmiar danych wejściowych.

Duże okno kontekstowe nie zawsze działa tak dobrze, jak byśmy chcieli. Warto sprawdzać, jaka jest maksymalna długość tekstu, który model może wygenerować na wyjściu. Jeśli w Twoim zadaniu input i output powinny być podobnej wielkości, może to stanowić problem.
Z drugiej strony, przy poleceniach typu „przygotuj artykuł” czy „wygeneruj sprawozdanie”, gdzie na wejściu mamy niewiele treści, a na wyjściu oczekujemy obszerniejszego tekstu, obecne ograniczenia nie będą aż tak dokuczliwe. Pamiętaj jednak, że na ten moment generowanie całych książek przez AI wciąż pozostaje wyzwaniem. Typowy output to zwykle 2-4 tysiące tokenów.
Podsumowując, planując wykorzystanie modeli językowych, weź pod uwagę ich realne możliwości i ograniczenia. Dostosuj zadania tak, aby jak najlepiej wykorzystać potencjał AI, jednocześnie mając świadomość obszarów, w których technologia ta wciąż wymaga udoskonalenia. Z odpowiednim podejściem modele językowe mogą stać się cennym wsparciem w wielu dziedzinach.
Mit 5: Dostrajanie modeli językowych (fine-tuning) jest prosty
W świecie AI istnieje wiele nieporozumień dotyczących procesu dostrajania modeli, zwanego z angielska fine-tuningiem. Często słyszy się sformułowania typu „chcemy wytrenować model”, co brzmi konkretnie, ale nie do końca oddaje istotę tego procesu. Warto zatem wyjaśnić, na czym polega fine-tuning i czym różni się od trenowania modelu od podstaw.
W przypadku klasycznego uczenia maszynowego faktycznie trenujemy model od zera. Jednak gdy mówimy o dużych modelach językowych (tzw. LLM – Large Language Models), proces ten przebiega etapowo. Pierwszym, najtrudniejszym i najbardziej wymagającym etapem jest wstępne trenowanie modelu, kiedy przyswaja on ponad 90%, a nawet 99% faktów. Ten etap wymaga wielu różnych GPU i jest niezwykle kosztowny, dlatego nie wszyscy mogą sobie na niego pozwolić.
Kolejnym etapem jest fine-tuning, czyli dostrajanie modelu przy użyciu różnych instrukcji. To właśnie wtedy model uczy się reagować na polecenia i odpowiadać w sposób czatowy. Dostrojenie modelu jest znacznie łatwiejsze i mniej kosztowne niż wstępne trenowanie, dlatego może w nim uczestniczyć więcej osób.
Warto pamiętać, że niektóre instrukcje używane podczas fine-tuningu mogą mieć ograniczenia licencyjne, np. zakaz wykorzystania komercyjnego. Wpływa to na model, który został dostrojony przy ich pomocy. Dlatego ważne jest, aby pierwsze modele powstawały uważnie, najlepiej przy wsparciu większych organizacji lub na poziomie państwa.
Pojawiają się różne pomysły regulacji prawnych dotyczących trenowania modeli AI, np. w Unii Europejskiej czy Kalifornii. Jednak technologii nie da się całkowicie zatrzymać, a regulacje obowiązujące tylko w jednym regionie nie zapobiegną potencjalnym zagrożeniom na poziomie globalnym.
Podsumowując, fine-tuning to ważny etap dostrajania modeli językowych, który różni się od trenowania od podstaw. Warto mieć świadomość tego procesu i związanych z nim wyzwań, aby odpowiedzialnie rozwijać technologię AI z myślą o jej pozytywnym wpływie na nasze życie.
Wyzwania związane z fine-tuningiem modeli językowych
Fine-tuning, czyli dostrajanie już wytrenowanych modeli językowych, może wydawać się prostym i efektywnym rozwiązaniem. Niestety, proces ten niesie ze sobą pewne problemy i ryzyka, o których warto pamiętać.
Jednym z głównych wyzwań jest zjawisko „halucynacji” modelu. Kiedy karmimy go nowymi faktami, o których wcześniej nie miał pojęcia, model zaczyna fantazjować i generować nieprawdziwe informacje. Dzieje się tak, ponieważ próbuje on pogodzić nowy strumień danych z dotychczasową wiedzą, co prowadzi do pewnego rodzaju „pobudzenia”.
Innym problemem jest zapominanie przez model wcześniej poznanych faktów. Choć nie jest to aż tak niebezpieczne jak halucynacje, to jednak oznacza, że fine-tuning nie zawsze przynosi oczekiwane korzyści.
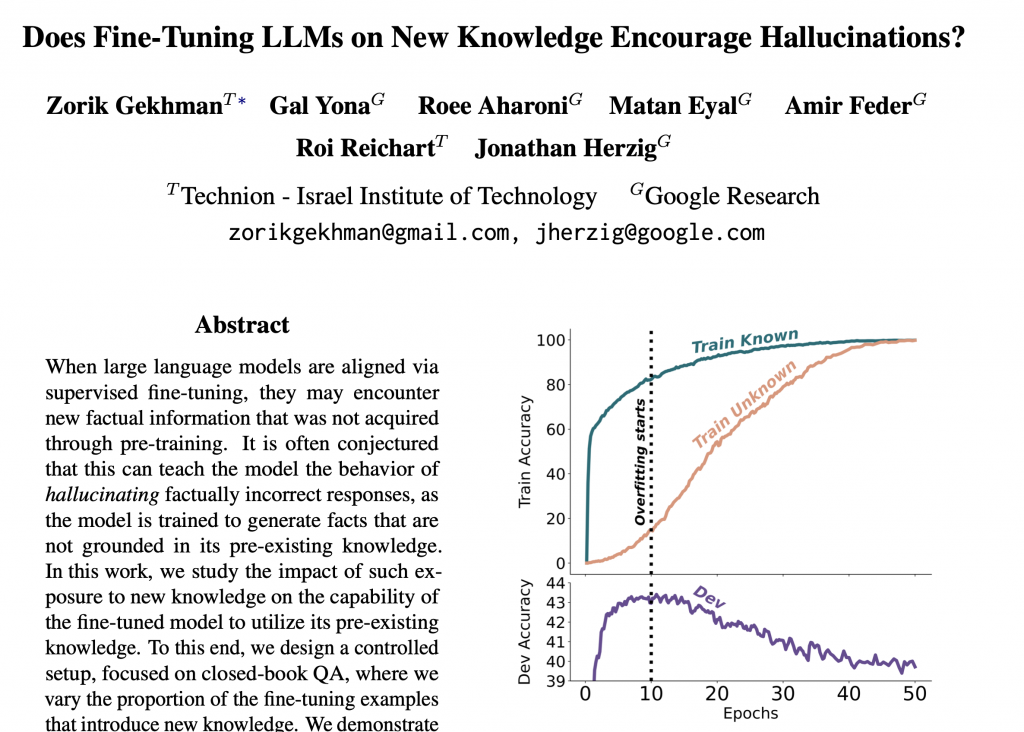
Czy w takim razie powinniśmy całkowicie zrezygnować z dostrajania modeli? Niekoniecznie. Kluczem jest znalezienie odpowiedniej strategii i zachowanie równowagi. Z jednej strony, nie chcemy karmić modelu zupełnie nowymi informacjami, ale z drugiej – uczenie go wyłącznie tego, co już zna, mija się z celem.
Rozwiązaniem może być selekcja faktów, które model zna, ale nie w pełni. Wymaga to jednak zastosowania różnych trików technicznych i znalezienia granicy akceptowalności. Trochę jak w wychowywaniu dziecka – musimy stopniowo poszerzać jego horyzonty, ale jednocześnie dbać o to, by nie zasypywać go nadmiarem bodźców.
Podsumowując, fine-tuning to ważny etap dostrajania modeli językowych, który różni się od trenowania od podstaw. Warto mieć świadomość tego procesu i związanych z nim wyzwań, aby odpowiedzialnie rozwijać technologię AI z myślą o jej pozytywnym wpływie na nasze życie
Porównanie fine-tuningu modeli językowych do wychowania dziecka
Proces dostrajania modeli językowych, zwany fine-tuningiem, można porównać do wychowywania dziecka. Nie mówimy mu dokładnie, co ma robić w każdej sytuacji, ale przekazujemy ogólne wartości, jak uczciwość, pracowitość czy chęć niesienia pomocy. Te wysokopoziomowe wskazówki wpływają później na podejmowane decyzje, choć ostatecznie dziecko samo wybiera swoją drogę, kierując się przekazanymi mu zasadami.
Podobnie jest z modelami językowymi – nie mamy wpływu na wszystkie ich działania, bo jest ich zbyt wiele. Zamiast tego, używamy fine-tuningu jako narzędzia do wysokopoziomowego korygowania modelu. Ważne jednak, by robić to w sposób zrównoważony, bo zmieniając jedno, możemy nieumyślnie zepsuć coś innego. Modele LLM to złożone mechanizmy, w których modyfikacja jednego elementu wpływa na funkcjonowanie całej reszty. Dlatego do fine-tuningu trzeba podchodzić z rozwagą.
Mit 6: Reprezentacja wektorowa (embedding) znajdzie wszystko
Kolejnym ważnym pojęciem w świecie AI jest embedding, czyli reprezentacja wektorowa. Polega ona na opisywaniu bytów, takich jak tekst czy obrazy, za pomocą zbioru wartości numerycznych – wektora. Te wartości niekoniecznie są dla nas zrozumiałe, ale pozwalają modelom opisać i rozróżniać poszczególne elementy, trochę jak w grze, gdzie trzeba zgadywać słowa na podstawie podanych wskazówek.
Reprezentacja wektorowa ma jednak swoje ograniczenia. O ile pojedyncze słowa czy tokeny można precyzyjnie opisać za jej pomocą, to przy dłuższych fragmentach tekstu, jak zdania, akapity czy całe książki, pojawiają się problemy. Pojedyncze słowa giną w morzu innych, przez co ich wpływ na całościową reprezentację jest niewielki. W efekcie, szukając podobnych dokumentów na podstawie embeddingu, możemy otrzymać nie do końca trafne wyniki.
Dzieje się tak, bo próbujemy zawrzeć tysiące lub miliony tokenów w postaci zaledwie tysiąca parametrów. To zwykła, ale stratna kompresja danych. Raz zastosowanej reprezentacji wektorowej nie da się już przywrócić do pierwotnej postaci bez utraty informacji.
Embedding to potężne narzędzie, ale nie rozwiązuje wszystkich problemów i ma swoje ograniczenia, szczególnie w przypadku dłuższych tekstów. Warto mieć świadomość jego możliwości i słabości, by efektywnie wykorzystywać reprezentację wektorową w praktyce.
Potęga i ograniczenia reprezentacji wektorowej
Po prostu dostajesz tekst, który konkretne modele próbują w jakiś sposób opisać i w rezultacie otrzymujesz embedding. Kompresja stratna oznacza, że tracimy informację i to jest klucz do tego wszystkiego. To z kolei implikuje, że takie klasyczne wyszukiwarki, które przez dłuższy czas były bardzo potrzebne i popularne, nadal mają sens. Obserwuję, że czasem pojawia się wrażenie, iż embedding wyeliminuje klasyczne wyszukiwanie. To nieprawda, tak to nie powinno działać.
W szczególności, gdy budujemy rozwiązania na produkcję, to nadal posługujemy się też klasyczną wyszukiwarką. Ciekawostką odnośnie rozumienia kwestii związanych z osadzeniem czy reprezentacją wektorową jest to, że kiedy działamy w konkretnej, specyficznej branży, na przykład mamy jakąś dokumentację techniczną z budownictwa, coraz więcej osób rozważa możliwość przyspieszenia pracy nad tą dokumentacją.

W takich dokumentacjach zawsze pojawiają się różne akronimy czy skróty, przykładowo składające się z dwóch, trzech, czterech, pięciu liter. Z punktu widzenia reprezentacji wektorowej, czy tam pojawi się jedna literka więcej, czy mniej, to nie sprawi dużej różnicy. Dla embeddingu, czy w liczbie jest sto tysięcy czy milion, to tylko jeden znak różnicy. Natomiast dla biznesu różnica pomiędzy sto tysięcy a milionem jest gigantyczna.
Potrzeba ostrożności przy używaniu embeddingu
Osadzenie wektorowe daje bardzo fajne możliwości, ale używanie go na wyłączność, w szczególności w specyficznych, technicznych przypadkach, w tym w języku prawnym, z dużym prawdopodobieństwem może prowadzić do problemów. Jest ciekawa publikacja pod tytułem „Embedding is not all you need”, która podkreśla, że osadzenie wektorowe jest fajne, ale to nie jedyne, czego właściwie potrzebujesz.
Warto też wspomnieć o podejściu RAG (Retrieval Augmented Generation), które obecnie obok fine-tuningu jest popularnym podejściem. O wyzwaniach związanych z fine-tuningiem już wspomniałem, podkreślając, że nie przekreślam tej metody, ale przeraża mnie czasem zbyt lekkie podejście do tego procesu. Więcej szacunku powinno się wkładać w fine-tuning. Jeśli chodzi o RAG, zwykle myśli się o używaniu reprezentacji wektorowych do wyciągania poszczególnych fragmentów tekstu. Tutaj chciałem zaznaczyć, że można to robić na różne sposoby.

I taka reprezentacja wektorowa nie zawsze musi być w twoim rozwiązaniu. W szczególności w mojej organizacji, takim bardziej produkcyjnym, to ja mam takie podejście, gdzie można robić to inaczej. To nie zawsze eliminuje reprezentację wektorową, ale to co najmniej daje inny też mechanizm wyszukiwania.
Znaczenie precyzji w wyszukiwaniu informacji
I ta informacja, jeżeli chodzi o takie różne techniczne specyfikacje, gdzie tam to jest ważne, ta informacja, żeby wynaleźć, jest krytyczna. Poszukujesz konkretny akronim, dla ciebie jest ważne, żeby te trzy literki zawierały dosłownie te trzy literki, a nie jedna literka tu czy tam. No bo z punktu widzenia reprezentacji wektorowej, ta jedna literka w tym akronimie to jakby szczegół techniczny, jaka jest różnica. Ale z punktu widzenia odbiorcy, to może być bardzo, bardzo krytyczne.
Mam nadzieję, że to wyjaśnia, że reprezentacja wektorowa jest fajna, osobiście ją lubię, ale też trzeba rozumieć, jakie ona ma ograniczenia i też zalety albo możliwości. I w tym przypadku te ograniczenia zwykle cechują się tym, że jak będziesz używać tylko i wyłącznie reprezentacji wektorowej do wyszukiwania odpowiedzi, które będziesz potem podrzucać do modeli, to jest taka szansa, że będziesz wyszukiwać dużo różnego śmiecia, który niekoniecznie może być wartościowy dla tego biznesu. Oczywiście można powiedzieć tak, że możemy najpierw wyszukiwać mnóstwo i potem jakoś tam kalibrować, to czasem działa.
I tutaj zależy bardziej od biznesu, na ile kosztuje ten błąd, który możemy popełnić. Jeżeli to jest minimalny błąd, powiedzmy to jest jakiś post, który maksymalnie ktoś nie polajkuje, okej. Jak to jest już dokumentacja albo tematy prawne, to tutaj ten błąd może być coraz droższy, coraz większy.
Dlatego, trzeba na to uważać.
Mit 7: AI zastąpi wszystkich ludzi – prawda czy mit?
Temat brzmi kontrowersyjnie: AI zastąpi wszystkich ludzi. W pewnym sensie to mit, a w pewnym to prawda. Warto się nad tym zastanowić.
Dlaczego to prawda? Spójrzmy na to z perspektywy historycznej. Gdybyśmy cofnęli się o 50 czy 100 lat i przeprowadzili ówczesnego człowieka do dzisiejszych czasów, miałby on problem z odnalezieniem się. Można powiedzieć, że w pewnym sensie pozbawiliśmy go pracy. To, co umiał wtedy, teraz już nie jest potrzebne.
Ewolucja zawodów i umiejętności
Przez lata jako ludzie i cywilizacja dostrajaliśmy się do zmian. Robiliśmy swego rodzaju fine-tuning na poziomie naszych umysłów. Obserwowaliśmy, jak zmienia się rynek, czego potrzebuje, i uczyliśmy się nowych rzeczy i umiejętności. Okazuje się, że to, co robimy teraz, jest potrzebne.
Na czym polega więc mit? AI zmienia pewne rzeczy, zachodzą transformacje, ale też pojawiają się nowe obszary, których AI nie będzie w stanie zastąpić.
Kluczowe pytanie brzmi: co się zmieniło w tej zmianie? Ta zmiana już się odbyła. Od setek lat jako cywilizacja ciągle się rozwijamy. Jaka jest różnica między zmianą sprzed 100 lat a tą obecną?
Główna różnica tkwi w prędkości. Kiedyś człowiek miał całe życie na wykonywanie jednego zawodu. Syn czy wnuk robił już coś innego, ale dziadkowie niekoniecznie to rozumieli. Teraz zmiany zachodzą w trakcie życia jednej osoby. Już nie wystarczy tylko obserwować, co robią młodsze pokolenia. Każdy z nas musi zmieniać się w ciągu własnego życia.
Wewnętrzna transformacja
Dla Ciebie oznacza to konieczność wewnętrznej transformacji. Musisz być przygotowany na zachodzące zmiany. Nie ma już opcji, że raz się czegoś nauczysz i koniec nauki. Cokolwiek teraz robisz, Twój obecny zawód ulegnie zmianie. Pytanie tylko, na ile.
Weźmy na przykład tłumaczenie języków. Ten zawód właściwie już prawie zniknął. Nawet Google Translate to już historia. Wystarczy wziąć dobry model LLM i tłumaczy on bardzo dobrze. Można nawet mówić głosem, który jest konwertowany na tekst i z powrotem na mowę. Oczywiście mogą być jeszcze specyficzne przypadki wymagające ludzkiej ręki, ale w masowym rozumieniu zawód tłumacza zanika.
Zawody wymagające kreatywności i złożonego myślenia
Z drugiej strony weźmy zawód prawnika. Tu sprawa jest ciekawsza, bo choć jest dużo treści, które wydają się łatwe do zautomatyzowania, to nie jest takie proste. Prawnicy to w pewnym sensie też „programy”, ale operujące językiem ludzkim, nie programowania. Muszą odnajdywać konteksty, wykonywać twórcze prace, łączyć nieoczywiste kropki. Pewne rzeczy w branży prawnej się zmienią, jak np. wyszukiwanie informacji, ale cała reszta to złożony proces myślowy.
Ostatnio podczas konsultacji w banku osoba z audytu wspominała o wyzwaniu śledzenia nowych rozporządzeń i upewniania się, że reklamy banku są z nimi zgodne. To żmudna praca, ale…## Jak zmienia się świat pod wpływem sztucznej inteligencji?
Sztuczna inteligencja, a w szczególności LLM (Large Language Models), już teraz wywiera znaczący wpływ na naszą rzeczywistość. Wiele rutynowych, żmudnych zadań może zostać zautomatyzowanych, co z jednej strony budzi obawy o miejsca pracy, a z drugiej daje nadzieję na odciążenie ludzi od monotonnych czynności.
Przykładem może być praca w bankowości, gdzie sprawdzanie zgodności reklam z nowymi rozporządzeniami to czasochłonne i mało satysfakcjonujące zajęcie. Jeśli AI przejmie tę część obowiązków, pracownicy będą mogli skupić się na bardziej konceptualnych i kreatywnych zadaniach.
Ograniczenia i możliwości LLM
Mimo imponujących osiągnięć, obecne modele językowe mają swoje ograniczenia. Są świetne w rutynowych zadaniach, ale słabiej radzą sobie z planowaniem i rozumowaniem. Można je postrzegać jako zaawansowane „kalkulatory”, które potrafią zrobić wrażenie, ale nie są jeszcze gotowe do w pełni samodzielnej pracy w obszarach wymagających nieoczywistych decyzji i brania odpowiedzialności.

Oznacza to, że osoby wykonujące bardziej konceptualne zadania, jak prawnicy czy specjaliści od planowania, raczej nie stracą pracy na rzecz AI. Jednak transformacja rynku pracy niewątpliwie przyspiesza i warto być na nią przygotowanym.
Jak odnaleźć się w zmieniającym się świecie?
Kluczem do odnalezienia się w nowej rzeczywistości jest regularne rozwijanie swoich umiejętności i pozbycie się strachu. Panika i obawy nie pomogą, lepiej skupić się na zdobywaniu wiedzy i dostosowywaniu się do zmian.
Warto też spróbować wybiec myślami w przyszłość i zastanowić się, jak będzie wyglądał świat za rok czy dwa. Jeśli uda nam się „dogonić króliczka” i zrozumieć nadchodzące zmiany, łatwiej będzie nam płynnie dostosować się do nowej rzeczywistości, bez ciągłego stresu i poczucia, że nie nadążamy.
Rozwój AI a liczba deweloperów
Ciekawym aspektem rozwoju sztucznej inteligencji jest liczba deweloperów korzystających z jej możliwości. Przykładowo, z API ChatGPT korzysta obecnie około 3 miliony deweloperów. Może się to wydawać dużo, ale biorąc pod uwagę, że na świecie jest prawdopodobnie od 50 do 100 milionów programistów, to wciąż stosunkowo niewielki odsetek.

Można zatem przypuszczać, że jesteśmy dopiero na początku drogi i w najbliższych latach coraz więcej deweloperów będzie sięgać po narzędzia AI w swojej pracy. To z kolei przyspieszy rozwój i adaptację sztucznej inteligencji w różnych dziedzinach życia.
Sztuczna inteligencja zmienia nasz świat w zawrotnym tempie, ale nie musi to budzić strachu. Kluczem jest otwartość na zmiany, chęć ciągłego rozwoju i próba zrozumienia, co przyniesie przyszłość. Jeśli uda nam się wyprzedzić najbardziej dynamiczne zmiany, łatwiej będzie dostosować się do nowej rzeczywistości i czerpać z niej korzyści. Warto pamiętać, że rozwój AI to nie tylko automatyzacja rutynowych zadań, ale też szansa na bardziej kreatywną i satysfakcjonującą pracę dla ludzi
Nie jest za późno na rozwój w świecie sztucznej inteligencji
Choć AI rozwija się w błyskawicznym tempie, to jednak wciąż jeszcze nie przenikła do masowej świadomości. Nawet najbardziej popularny ChatGPT ma 50 milionów użytkowników na świecie, co w skali globalnej populacji nie jest aż tak imponującą liczbą. Co to oznacza dla Ciebie? Jeśli dotychczas nie interesowałeś się tematem sztucznej inteligencji, to wcale nie jesteś na straconej pozycji. Wciąż masz czas, by nadrobić zaległości i przygotować się na nadchodzące zmiany.
Pamiętaj jednak, że bierność w obliczu tak dynamicznego rozwoju technologii może sprawić, że faktycznie zostaniesz w tyle. Kluczem jest ciągłe doskonalenie swoich umiejętności i poszerzanie wiedzy. To już nie jest opcjonalny wybór, a raczej konieczność, którą warto przekazywać kolejnym pokoleniom. Świat zmienia się na naszych oczach i jedynym sposobem, by za nim nadążyć, jest aktywne uczestnictwo w tej transformacji.
Sztuczna inteligencja to szansa na rozwój cywilizacji
Choć łatwo skupiać się na potencjalnych zagrożeniach związanych z AI, warto dostrzec też pozytywne aspekty tej rewolucji technologicznej. Sztuczna inteligencja daje nam narzędzia do szybszego rozwoju jako cywilizacja. To od nas zależy, czy wykorzystamy tę szansę. Oczywiście, każdy z nas ma inne zdolności i możliwości, ale ostatecznie to nasza decyzja, czy chcemy się rozwijać.
Tempo, w jakim aktualizujemy swoją wiedzę, zależy od indywidualnych predyspozycji. Natomiast sam fakt, czy podejmujemy wysiłek, by poznawać nowe rzeczy, leży wyłącznie w naszych rękach. To właśnie te drobne, codzienne wybory będą kształtować naszą przyszłość w świecie zdominowanym przez AI. Wierzę, że podejmiesz właściwą decyzję i nie będziesz biernie czekać na to, co przyniesie los.
Podsumowanie
W ciągu zaledwie kilku minut poruszyliśmy wiele istotnych kwestii związanych ze sztuczną inteligencją. Oto krótkie podsumowanie:
- Na rynku istnieje wiele różnych modeli AI, nie tylko ChatGPT.
- LLM i GenAI to część szerszego obszaru uczenia maszynowego (machine learning), a dobre praktyki z ML mają zastosowanie także w kontekście języków naturalnych.
- Halucynacje generowane przez AI to nie błąd, a inherentna cecha działania modeli językowych.
- Duże okienka kontekstowe brzmią atrakcyjnie, ale wiążą się z szeregiem problemów.
- Dostrajanie modeli AI wymaga ostrożności, by naprawiając jeden problem nie stworzyć wielu nowych.
- Reprezentacje wektorowe mają swoje zalety, ale też ograniczenia, szczególnie w specjalistycznych dziedzinach.
- AI nie tylko zwolni niektórych ludzi, ale też stworzy nowe miejsca pracy. Sama w sobie jest jednak naiwna i ślepa, więc potrzebuje ludzkiego nadzoru.
Mam nadzieję, że te informacje pomogą Ci lepiej zrozumieć złożoność tematu sztucznej inteligencji. Pamiętaj, że kluczem do sukcesu w nowej rzeczywistości jest ciągła nauka i otwartość na zmiany. Przyszłość należy do tych, którzy potrafią dostosować się do dynamicznie zmieniającego się świata.
Doceniajmy nasze możliwości jako ludzie
Jako ludzie często nie doceniamy tego, kim jesteśmy. Jeśli będziemy konkurować z kalkulatorem, to wiadomo, że on wygra, ale człowiek jest w stanie robić znacznie więcej rzeczy niż tylko liczyć. Nasuwa się tutaj pytanie filozoficzne, czy AI, na przykład ten, który obecnie mamy, ma świadomość. Możemy spekulować na ten temat.
W mojej opinii AI, ten model języka, o którym teraz mówimy, nigdy nie będzie miał świadomości, o której mówimy w kontekście człowieka, bo jest to z definicji ograniczone. To podobnie, jakbyś był na dachu drapacza chmur w dużym mieście i obserwował samochody. Patrząc z góry, masz wrażenie, że samochody poruszają się świadomie, jakby były żywymi organizmami. Ale wiesz, że w środku siedzi kierowca. Teraz możesz powiedzieć, że istnieją autonomiczne samochody, ale nie o to chodzi.
Ta świadomość to jest rzecz bardziej głębsza. I tu na koniec zostawię to pytanie: jak ty definiujesz tę świadomość i skąd wiesz, że u ciebie ona jest? To jest ważne pytanie, bo fajnie się zastanawiać, czy LLM ma świadomość. Ale równie istotne jest zapytanie samego siebie, czy ty jesteś świadomy. To jest kluczowa kwestia, którą chciałem ci zostawić do przemyślenia.
Podziel się swoją opinią i zainspiruj innych
Podziel się proszę w wygodny dla ciebie sposób w komentarzach czy w inny możliwy sposób, jak o tym myślisz. Bardzo jestem ciekaw twojej opinii. Poleć proszę też ten odcinek podcastu w dowolny, wygodny sposób, czy tam na jednej platformie, czy w drugiej, jak tam słuchasz. Poleć przynajmniej jednej osobie.
Będę ci za to bardzo wdzięczny i będę się starać dalej dzielić się z tobą wiedzą w najlepszy możliwy sposób, jak potrafię. To tyle na dzisiaj. Dziękuję ci bardzo za wspólnie spędzony czas. Cześć, na razie!
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
