

Uczenie maszynowe, muzyka i logistyka…

W tym odcinku dowiesz się:
- Jak uczenie maszynowe pomogło firmie HelloFresh oraz jakie korzyści przyniosłoby Twojej firmie?
- Na czym polega łańcuch dostaw (ang. Supply Chain Revolution) wykorzystywany przez HelloFresh?
- W jakim stopniu umysł artysty (muzyka) jest powiązany z pracą jako Data Scientist oraz jakie można wynieść z tego korzyści?
- Czy każda osoba jest w stanie rozpocząć przygodę z uczeniem maszynowym?
- Jak jako Data Scientist podchodzić do problemów oraz jak efektywnie sobie z nimi radzić?
- Jaki wpływ będzie miało uczenie maszynowe na logistykę w przyszłości?
- Jakie są mity i legendy związane z uczeniem maszynowym?
- Czym różnią się pojęcia: Machine Learning, AI, Data Science?
- Jaki zabrać się za wdrażanie uczenia maszynowego w firmie z punktu widzenia decydenta?
W momencie, kiedy nagrywam to intro jestem już po konferencji, która odbyła się w sobotę, 13 października w Warszawie. Jeżeli jesteś regularnym słuchaczem, to wiesz, że musiałem włożyć wiele wysiłku i podejść twórczo do organizacji tego wydarzenia. Natrafiłem na wiele różnych przeszkód i ostatecznie organizacja była trudniejsza, niż mogłoby się to wydawać na początku, tym bardziej że świadomie zrezygnowaliśmy ze sponsorów na konferencji, aby jakość prezentacji była jak najwyższa, co wpłynęło fatalnie na aspekt finansowy tego przedsięwzięcia
i stworzyło wiele wątpliwości… Ale za to, po konferencji dostałem tak duży zastrzyk pozytywnej energii, aż byłem zaskoczony. Udało się zorganizować wydarzenie na takim poziomie, że nawet moje optymistyczne oczekiwania były zaniżone. Więcej o konferencji powiem na samym końcu.
29 października rusza praktyczny kurs online na temat uczenia maszynowego, który potrwa 8 tygodni i skończy się tuż przed “gwiazdką”. W trakcie kursu poznasz ze strony praktycznej fundamenty uczenia maszynowego. Będzie mowa o regresji i klasyfikacji (klasycznie uczenie maszynowe). Większość problemów biznesowych można sprowadzić właśnie do tych dwóch aspektów. Podjęty zostanie również temat uczenia głębokiego (w szczególności przetwarzanie obrazów).
Dotychczas odbyły się 2 edycje, w których wzięło udział 130 osób. Moi absolwenci pracują w takich firmach jak Intel, Orange, Allegro, IBM, Microsoft, Nokia, Bayer, Roche, Gemius, Santander Bank. Pracują również na uczelniach – Akademia Górniczo-Hutnicza w Krakowie, Szkoła Główna Handlowa w Warszawie, Politechnika Lubelska, Uniwersytet w Zielonej Górze. Również sporo osób w mniej znanych, ale bardzo ciekawych startupach lub software houseach.
W ciągu roku mają miejsce maksymalnie dwie edycje. Czwarta edycja odbędzie się najwcześniej w marcu lub kwietniu 2019.
Dodatkowo zdradzę jedną rzecz. Konferencja o której wspomniałem na początku i opowiem szczegółowo na końcu, została stworzona z myślą pomocy moim absolwentom. Cały czas staram się o nich myśleć. Są oni ciągle na bieżąco. Nawet po kursie przesyłam aktualizacje o kolejnych edycjach lub innych rzeczach. Postanowiłem, że absolwenci kursu otrzymają zniżkę w wysokości 50% na kolejne konferencje. Mimo tego, że będę musiał za nich dołożyć drugą połowę, to stwierdziłem że takie działania mają sens.
Dobra wiadomość! Zniżka 20% na hasło BM_KURS20
Dzisiejszym gościem jest Adrian Foltyn. Jest to człowiek, który próbuję łączyć muzykę z uczeniem maszynowym. Okazuje się, że obie te dziedziny mają wiele wspólnych cech, i jedni mogą wiele wyciągnąć od drugich. W szczególności, specjaliści od uczenia maszynowego od muzyków. Zapraszam do wysłuchania.
Cześć Adrian, przedstaw się: kim jesteś, czym się zajmujesz, gdzie mieszkasz?
Cześć. Nazywam się Adrian Foltyn. Jestem po części Data Scientistem, po części kompozytorem, po części naukowcem. Mieszkam we Wrocławiu. Pracuje dla dwóch dużych firm, jednej polskiej, jednej zagranicznej – Trans.eu i HelloFresh, i zajmuję się Data Science.
Bardzo ciekawe rzeczy. W szczególności ten temat związany z muzyką.
O tym jeszcze porozmawiamy za chwilę, a teraz: co ostatnio czytałeś?
Ja powiem, że ostatnio dużo czytam głównie artykułów naukowych, ale jeśli już mówimy o większych pozycjach, to zawsze lubię sięgać do klasycznych książek typu: “Elements of Statistical Learning”.

Powiedzmy z bardziej nie Data Science’owych pozycji to uwielbiam Nabokova i ostatnio czytałem “Żar”.
Bardzo ciekawe. Powiedziałeś, że pracujesz właściwie w dwóch firmach, już nie na pełny etat w HelloFresh, to może najpierw opowiedz czym jest HelloFresh. Jaki problem próbuję rozwiązać HelloFresh, a potem jeszcze porozmawiamy jak uczenie maszynowe w tym pomaga, ale najpierw, co HelloFresh próbuje dostarczyć na rynek?
HelloFresh to firma, która została założona już siedem lat temu w Berlinie. To jest dziecko Rocket Internet, i ta firma zajmuje się dostarczaniem klientom, tak zwanych “meal boxów”, czyli można powiedzieć kartonów w których środku mamy wszystkie składniki, które są potrzebne do ugotowania pewnej listy potraw, no i jeszcze dodatkowo te przepisy, które są do tego potrzebne.
Można powiedzieć że to jest inny koncern niż takie zwykłe dostarczanie jedzenia dlatego, że tu bardziej chodzi o to, że HelloFresh robi za ciebie zakupy, dostarcza Ci wszystkie składniki, które są potrzebne do ugotowania potraw w odmierzonych ilościach tak, że nie zostają ci z tego resztki, no i oczywiście podstawia to pod drzwi twojego domu, więc jakby sporo korzyści, których normalnie nie masz przy zamawianiu jedzenia. Oczywiście jest tam też gwarancja jakości, świeżości tego, że te składniki są wyselekcjonowane i dobrane od najlepszych dostawców.
Ten startup w tej chwili funkcjonuje już chyba dwunastu lub trzynastu krajach. Największy rynek, to są Stany, więc to nie tylko Niemcy, oczywiście. W tej chwili już trzy kontynenty w większości Europa, ale też Australia, Stany i Kanada.
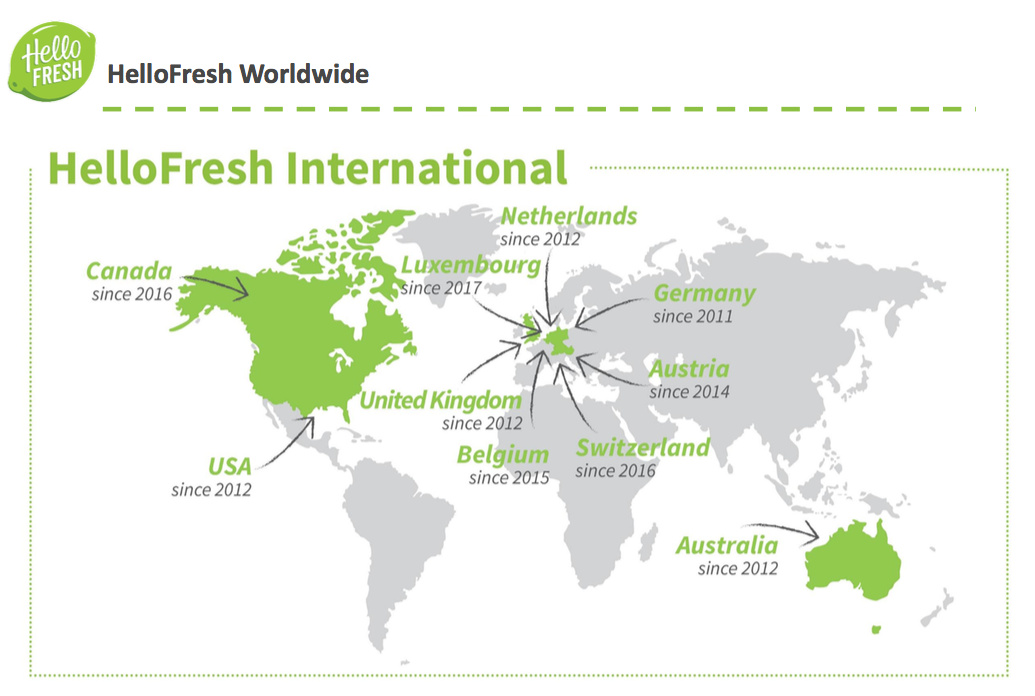
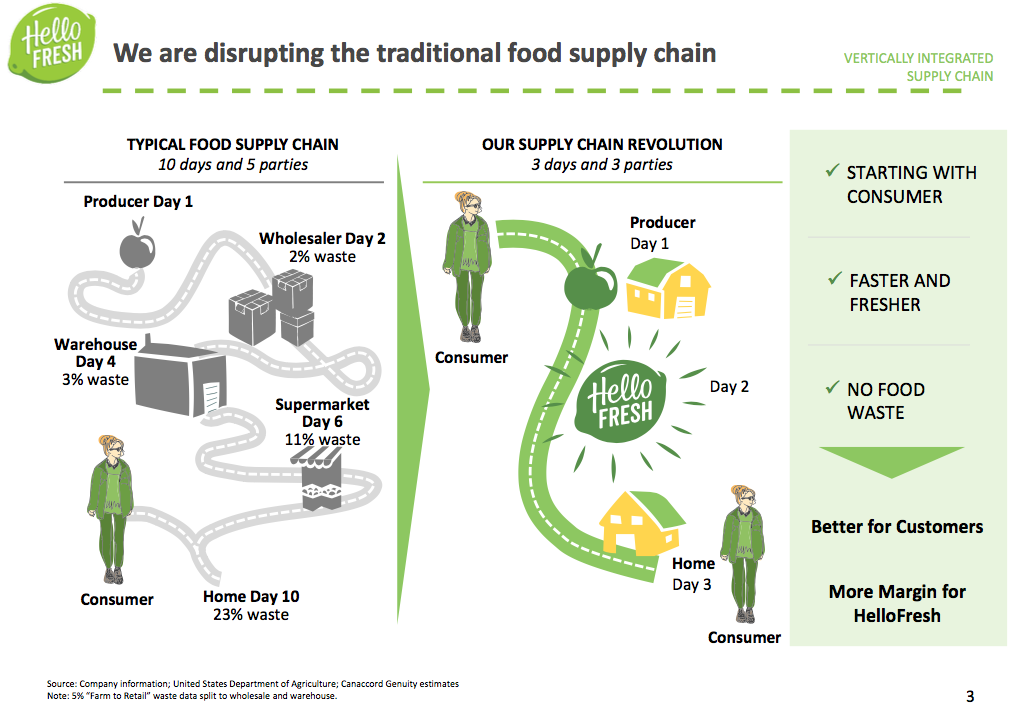
Ta skala jest przerażająca. O tym jeszcze też troszkę porozmawiamy, ale chciałbym teraz żebyś skomentował to hasło. Mówi się, że w HelloFresh powstała pewna rewolucja w łańcuchu dostaw, albo tak zwany “Supply Chain Revolution”, jak po angielsku czasem to nazywają. Czy możesz wyjaśnić na czym to polega?
Chodzi przede wszystkim o to, że w tradycyjnym łańcuchu dostaw pomiędzy producentem żywności, a konsumentem żywności jest wielu pośredników. Mamy pierwszego hurtownika, jakiś magazyn, kolejnego pracownika, który może jakąś flotę transportową, potem sieć supermarketów, albo jakiś inny etap jeszcze. Tak naprawdę tych pośredników pomiędzy konsumentem, a producentem żywności jest bardzo dużo. Natomiast HelloFresh z definicji umawia się z samymi producentami. W związku z tym łańcuch wartości jest skrócony tak naprawdę do jednej firmy. Łatwo się domyślić, że w ten sposób HelloFresh jest w stanie jakby zagarnąć sporą część tej wartości, która jest normalnie dodawana na każdym etapie, i w związku z tym, to jest dobry biznes. Przy czym, konsument nie płaci za to więcej, niż normalnie by płacił.
No właśnie, o to chciałem zapytać. Bo z jednej strony, skoro jest mniej pośredników to znaczy, że to musi kosztować co najmniej tyle samo, albo nawet taniej. Jak to mniej więcej wygląda w kosztach? Czy to jest porównywalne do kosztów ze sklepu, z marketu?
Mogę wam powiedzieć jak to wygląda w Niemczech. Taki box, który zawiera trzy przepisy na trzy potrawy, i wszystkie składniki do trzech potraw dla dwóch osób kosztuje około 40€, więc można sobie policzyć, że wychodzi około 6-7€ na jeden posiłek dla jednej osoby. Biorąc pod uwagę, że to są wyselekcjonowane składniki i dobre rzeczy, to nie jest dużo. I rzeczywiście, gdyby pójść do supermarketu i kupować rzeczy osobno, to mniej byśmy nie zapłacili, a zdarza się, że więcej.
OK, to brzmi ciekawie. Też myślę, że skoro mniej czasu potrzebują na to, żeby dostarczyć dane produkty, to jest duża szansa, że będą bardziej świeże.
W szczególności te produkty, które szybko się psują.
Tak jest. To jest jedna z kluczowych korzyści. Oczywiście, te świeże produkty generują też wyzwania, bo trzeba tak zamawiać żeby trafiać z zamówieniami odpowiedni poziom popytu. Tutaj się ujawnia już pierwszy temat dla Data Science.
No właśnie, skoro już jesteśmy przy wyzwaniach, to w szczególności przy wyzwaniach, które mogą być rozwiązane przy pomocy uczenia maszynowego, to proszę, wspomnij przynajmniej kilka zastosowań, gdzie uczenie maszynowe jest korzystne w tym przypadku.
W takim biznesie bardzo ważna jest zarówno strona kosztowa, jak i strona przychodowa. Kiedy mówi się o startupach, najczęściej mówi się o tym, jak te startupy mogą zoptymalizować swoje strategie marketingowe, więc ta strona przychodowa jakby, czy generowanie leadów, generowanie potem konwersji, to jest to na czym się często skupiają firmy technologiczne. Natomiast HelloFresh ma część problemów rzeczywiście z tej działki, ale część ma też z takiej tradycyjnej działki można powiedzieć, którą mają normalne normalne sieci handlowe, czyli bardzo ważne jest też strona kosztowa, optymalizacja pod względem zamówień, czyli przewidywanie popytu, i również optymalizacja kosztów marketingu.
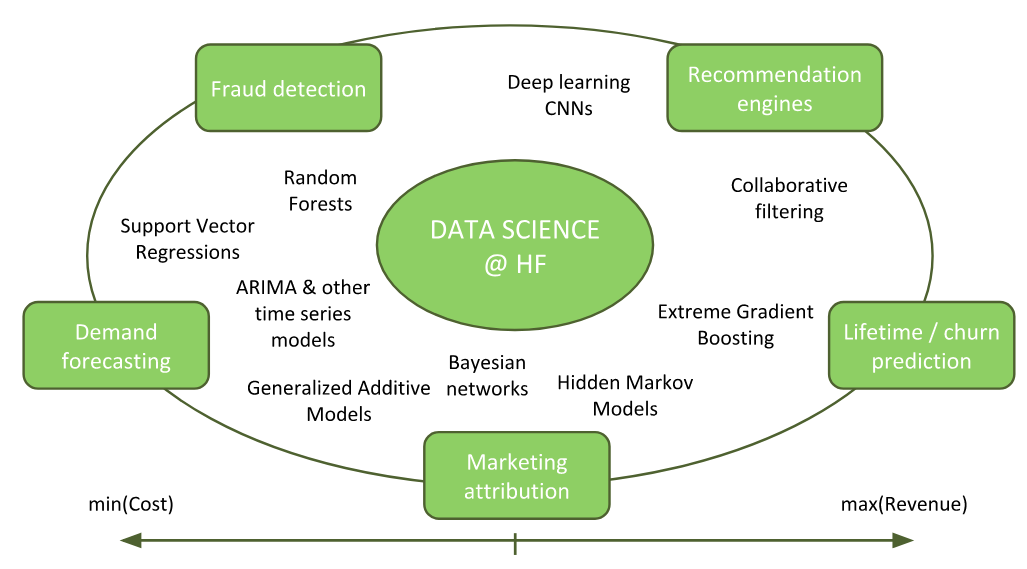
Można się domyślić, że HelloFresh działa w ten sposób, że w wielu kanałach się reklamuje i optymalna strategia jak ten fundusze, które są przeznaczone na marketing jest jak najbardziej pożądana. Więc to jest strona kosztowa, natomiast jest oczywiście też strona przychodowa tam, gdzie mówimy o maksymalizacji retencji, maksymalizacji pozyskania jak najlepszych klientów, o personalizacji, to jest bardzo ważne, czyli silnikach rekomendacyjnych. To są te elementy, gdzie Data Science wchodzi i ma istotny wpływ na P&L, czyli rachunek zysków i strat.
Podobno HelloFresh bardzo szybko rośnie, o czym wspomniałeś już na samym początku. Z tego co wiem to, rynek Stanach Zjednoczonych pewnie jest jednym z największych, ale też są inne rynki. Zastanawiam się teraz, na ile w tym przypadku technologia, a w szczególności uczenie maszynowe jest kluczowym elementem tego sukcesu. Wiem, że te kilka rzeczy pewnie się łączą, ale pytam o to dlatego, żeby przekazać też innym decydentom firm, jak często uczenie maszynowe może być tą przewagą konkurencyjną. Podziel się swoim zdaniem na ten temat.
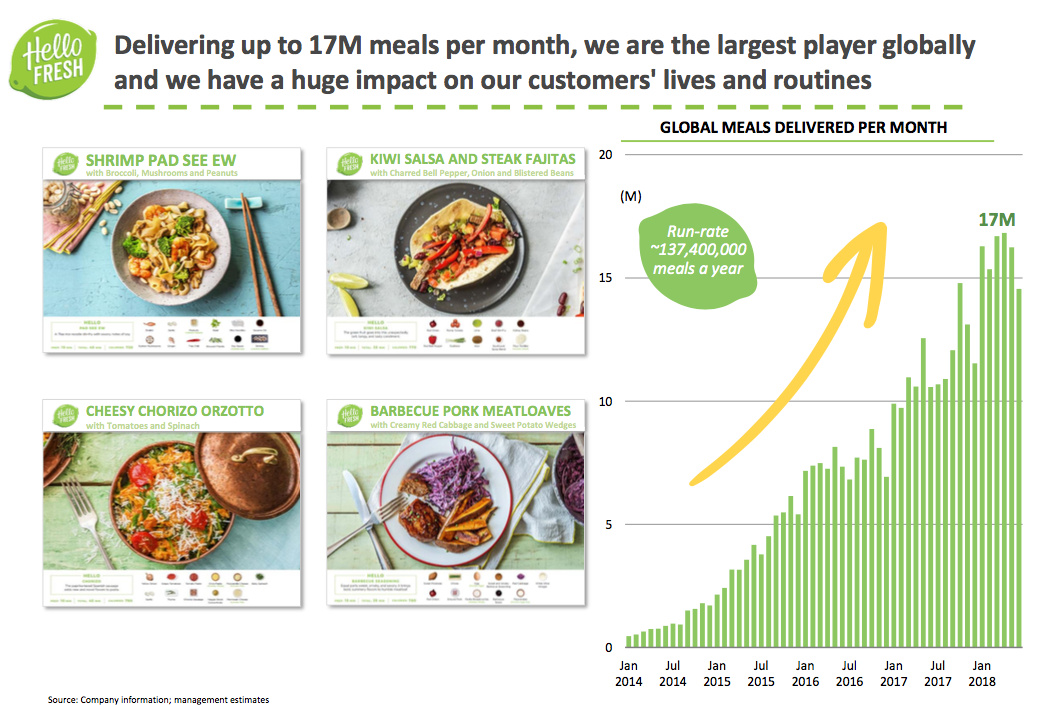
Tak, to widać choćby w takich sytuacjach, kiedy coś jest robione, na przykład intuicyjnie, a później wchodzi Data Science i mówi: dobrze, my zrobimy wam model, który wam to zoptymalizuje, w związku z tym wydacie mniej, a dostaniecie więcej w wyniku. Przykład: bardzo ważnym kanałem pozyskania nowych klientów są tak zwane referral, czyli to, jak aktualni klienci polecają nas kolejnym klientom. Oczywiście, są wydawane przy tej okazji vouchery na zniżkowe pierwsze boxy, i jest pytanie którym z naszych aktualnych klientów wydać te vouchery, żeby to była jak najbardziej opłacalna inwestycja, czyli inaczej mówiąc żeby ci klienci, którzy zostaną poleceni czy przyjdą do nas z polecenia jak najdłużej z nami zostali.
Oczywiście, swego czasu była za tym po prostu pewna intuicyjna strategia, ale weszło Data Science. Zbudowało kilka modeli dla referali na różnych etapach cyklu życia klienta, no i te wzrosty są zauważalne, to znaczy to są liczby pomiędzy 5 a 25% więcej klientów, którzy zostają dłużej z firmą przez dłużej powiedzmy, rozumiemy więcej niż pięć tygodni.
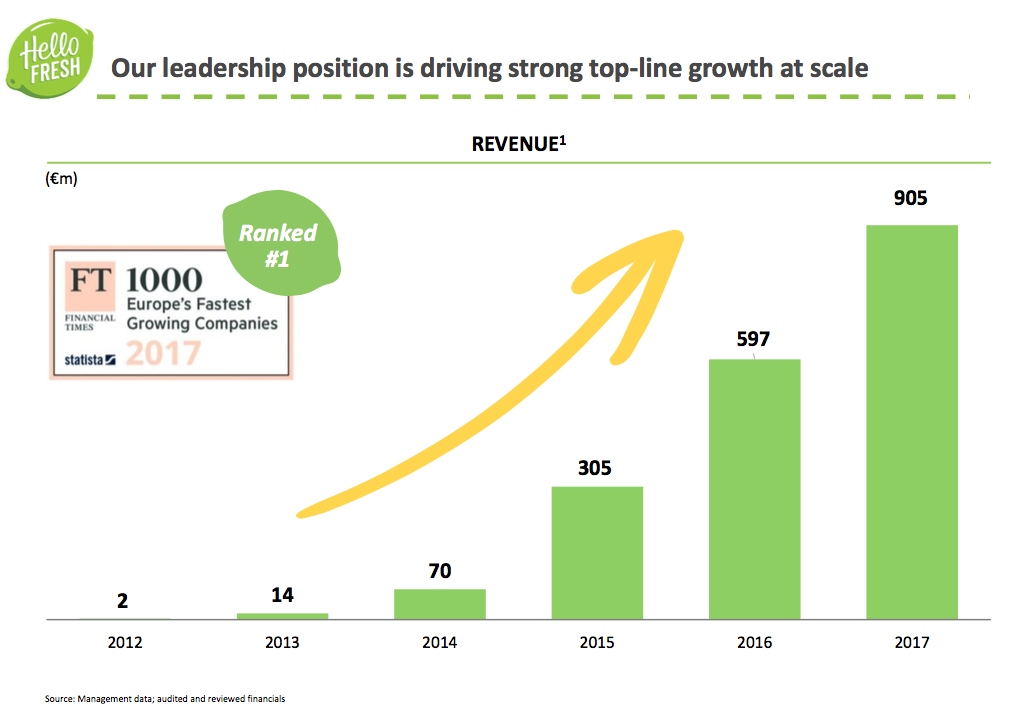
Trzeba powiedzieć, że to ma bardzo konkretny wpływ potem na przychody. Z kolei, jeśli mówimy o przewidywaniu popytu, to jest case powiedzmy częściowo machine learningowy, częściowo statystyczny, bo tutaj trzeba po prostu znaleźć jak najlepszy model. Tu ciekawostka jest taka, czym opowiada czasem na konferencjach, że klasyczne metody związane z szeregami czasowymi nie działają kompletnie na te szeregi czasowe, które są w HelloFreszu i tam trzeba było budować takie modele ensemble’owe, które korzystają z technik regresyjnych, ale bardzo różnych technik rekreacyjnych i to dawało naprawdę bardzo dobrze radę do tego stopnia, że udało się zmniejszyć błędy około pięc punktów procentowych. To są olbrzymie pieniądze jak sobie pomyśleć o skali działania, bo HelloFresh w skali całego świata, już teraz można powiedzieć, czyli trzech kontynentów to są setki tysięcy boksów, które są wysyłane co tydzień do klientów.
Tak, jak myśli się o skali, to wtedy zupełnie inne liczby wychodzą. Pozwolę teraz sobie zmienić temat. Na początku powiedziałeś, że jesteś związany z muzyką i teraz troszkę ten temat pociągniemy dalej. Dla mnie osobiście jest to dość inspirujące, bo wydaje mi się, że bardzo fajne jest, kiedy mózg potrafi się odnaleźć w różnych dziedzinach, chociaż podobno próbujesz te dziedziny łączyć. No właśnie, spróbujmy o tym porozmawiać. A powiedz może najpierw o Twoich zainteresowaniach z muzyką i co Ciebie łączy z muzyką?
Tak naprawdę edukacja dlatego, że ja skończyłem zarówno studia ekonomiczne w kierunku metod ilościowych i marketingu, ale też akademię muzyczną na kierunku kompozycja. I oczywiście ta historia jakby też zainspirowała mnie do myślenia o tym, jakie są podobieństwa pomiędzy pracą Data Scientista i kompozytora. Wbrew pozorom to mamy dość sporo podobnych obszarów, bo oba te zawody starają się, czy ludzie w tych zawodach starają się kształtować taki abstrakcyjny materiał, czyli dane albo dźwięki muzyczne. W obu przypadkach produkujemy pewien zestaw instrukcji, czyli taki kod albo dla wykonawcy albo dla maszyny i oba te zadania są właściwie dość mocno nieprzewidywalne. W tym sensie, że wcale nie jest łatwo ująć proces dochodzenia do rozwiązania Data Sciencowego, lub proces dochodzenia do ciekawego utworu muzycznego w jakiś ustrukturyzowany proces. Dlatego zastanawiałem się, czy coś ciekawego mogliby się Data Scientiści nauczyć czegoś od kompozytorów, w końcu muzyka była pisana przez ludzkość przez wieki, a Data Science to jednak taka dość nowa dziedzina.
Mam tam sporo przemyślenia, które kiedyś nawet zamknąłem w prezentacji na konferencję, ale generalnie zamyka się to w takich kilku tematach:
- pierwszy to planowanie,
- drugi to jak pisać, żeby pisać efektywnie,
- trzeci to jak przechowywać i walidować to co mam,
- i czwarty to jak dostarczyć wyniki.
Wbrew pozorom to jest bardzo wiele paraleli na które można wskazać. Mnie na przykład bardzo zainteresowała taka rzecz, że wybiorę teraz trochę z tego co swego czasu poskładałem. Jest taka rzecz jak wartość planowania. Ja widziałem wielu Data Scientistów, którzy lubią się jakby zagłębić w temat od razu, bez planowania, trochę tak jakby taka wena twórcza ich dopadła, i zaczynają eksplorować bez planów. To się często kończy tak, że po paru dniach, dobrze jeśli po paru godzinach, ale niestety czasem po paru dniach trafiają na taki problem, którego nie są w stanie przeskoczyć i dopiero wtedy orientują się: :ale tak naprawdę to mocno od biegłem od od tego co chciałem osiągnąć”. I to jest rzeczywiście coś to widziałem zarówno u Data Scientistów, jak i kompozytorów.
Jest inny ciekawy temat pod tytułem: Co to znaczy, że coś zostało już napisane, albo czy warto sprawdzać czy coś już zostało napisane. Większość mówi Data Scientistów mówi: No tak, to tak naprawdę już większość rzeczy które ja potrzebuję na pewno jest, istnieje i wtedy starczy to dobrze znaleźć gdzieś na GitHubie.Tak, to prawda, ale założenie, że na pewno to gdzieś jest nie zawsze się sprawdza. Ja w ostatnich dwunastu miesiącach sam napisałem dwa algorytmy “from scratch”, jak to się mówi.
Jeden do wybierania cech w uogólnionych modelach addytywnych, a drugi do oceniania wpływu poszczególnych zmiennych losowych lasach. I tu nie mówimy o tym, co się nazywa ważność zmiennych – variable importance, ale właśnie o kontrybucji tak zwanej, czyli jakby czymś co się sumuje do całkowitej wartości zmiennej objaśnianej. I jest ileś kolejnych tematów. Tak się zastanawiam, czy coś by z tych z tych obszarów jest szczególnie ciekawe. Planowanie, pisanie, walidacja czy dostarczanie wyniku. O czym mógł bym jeszcze opowiedzieć?
Szczerze mówiąc, mnie zaintrygowała ta część, gdzie opowiadałeś, że jak i specjalista od ML’a, albo Data Scientist, jak i osoby które tworzą muzykę dość często robią to, ale jak zapytasz, czy możesz to opisać jako proces, to zwykle Ci ludzie mają problem. To tak trochę brzmi, że to jakaś intuicja, podświadomość jest wtedy zaangażowana. I zastanawiam się, jak fajnie by to było ugryźć, a z drugiej strony jak podałeś te cztery kroki to w pewnym sensie chyba próbujesz na te pytania odpowiedzieć w sposób bardziej procesowy. Dlatego fajnie by było podać może jakiś prosty przykład i przejść przez te cztery kroki i zobaczymy co z tego wyjdzie.
W tych czterech krokach o których mówię, ja się koncentruję bardziej na tym, na co zwrócić uwagę. Nie tyle na tym, że tutaj buduje jakieś takie ramki, jakiś framework, którym należałoby się kierować. Bardziej, na co by warto było zwrócić uwagę, na przykład tam, gdzie mówimy o pisaniu. Są takie proste rzeczy, które naprawdę wiedzą o kompozytorzy, a Data Scientiści nie zawsze. Kompozytorzy, na przykład wiedzą doskonale, że należy się w twórczy sposób ograniczyć. To znaczy, że najlepiej nie rzucać tysiąc pomysłów, albo modeli na jeden problem, tylko wybrać sobie to w jakim obszarze będziemy działali i w tym obszarze spróbować napisać coś najlepszego.
Druga ciekawa rzecz, to też typowo kompozytorska mądrość można powiedzieć, to jest to, że kompozytorzy też lubią pisać takimi flowami, to tak podobnie jest z Data Scientistami. Widzę, że jak dobrze mi idzie, to chce pisać dalej i jak najszybciej dojść do wyniku, jak najszybciej skończyć. To dobrze działa, ale jeżeli nie jesteśmy pewni czy skończymy w tej iteracji, można powiedzieć, to często jest tak, że w którymś momencie utkniemy. Nie wiemy co dalej, a wtedy bywa tak, że już jesteśmy tak zmęczeni, że naprawdę nie wiemy co zrobić dalej.
W związku z tym, taka dobra mądrość do wykorzystania jest taka, że warto przerwać czasem wtedy, kiedy idzie dobrze, a nie wtedy kiedy się utknęło. Po to żeby następnego dnia kiedy się znowu usiądzie do tego samego problemu, można było normalnie podjąć to w tym miejscu w którym szło dobrze. Wbrew pozorom to naprawdę działa. Ja to kilka razy stosowałem i to może nie jest oczywiste, ale bardzo mi to pomogło, bo wiedząc że czegoś nie skończę danego dnia, przerywałem to w takim punkcie w którym mogłem łatwo to podjąć następnego dnia, a nie w takim punkcie w którym coś zakończyłem i nie wiedziałem co zrobić dalej. Jest kilka innych tematów oczywiście, jeżeli mówimy o walidacji to z kolei i przechowywaniu, to jest kwestia oczywiście kontroli wersji.
To nie jest żadne odkrycie, że Data Scientiści powinni stosować kontrolę wersji. To jest ten jeden moment, kiedy kiedy mówię, że kompozytorzy mogliby się czegoś od Data Scientistów nauczyć, bo wiem jak dużo ludzi cierpiała z tego powodu, że coś uciekło z tego co pisali. Natomiast poza tym jeśli mówimy o tym, czego Data Scientist mógłbym nauczyć się od kompozytora, to choćby to, że kompozytorzy mają taki dobry zwyczaj tego, że siadają ze sobą, młodszy ze starszym i pokazują sobie co napisali, i jakby przeprowadzają tego starszego przez to, co napisali. Czyli taki można powiedzieć code review.
Nie zawsze na to starcza czasu. Przy typowej pracy Data Scientista ja uważam, że jest w tym wielka wartość i warto to robić. I ostatnia rzecz, która jest ważna przy rezultatach. Jest takie przekonanie, że zwłaszcza po stronie biznesu, że Data Science bardzo łatwo wpada w pułapkę tego, że wchodzi na przykład za głęboko w jakiś problem i zaczyna podchodzić do niego naukowo, a my chcemy tak naprawdę rozwiązanie, czy odpowiedź taką 80/20. Więc prawda jest bardziej złożona dla mnie dlatego, że ja uważam, że zarówno Data Science, jak i muzyka nie cierpią 80/20. Natomiast to, co jest ważne to żeby przejrzyście komunikować się z tymi którzy oczekują na naszą pracę, czyli z interesariuszami i mówić im: dobrze, jeśli chcecie mieć dobre rozwiązanie to potrzebuje mieć więcej niż 20% czasu na osiągnięcie tego rezultatu. To jest później oczywiście decyzja ich i Twoja, jako Data Scientista, jak ważymy koszty tego, że coś będzie później versus tego, że coś co dowieziemy będzie niższej jakości.
Ale moje zdanie jest generalnie takie, że ja bardzo nie lubię, jak mi ktoś mówi żebym się skoncentrował na 80/20, czyli po prostu dał jakieś rozwiązanie, że lepsze jest jakieś niż żadne. Nie jestem przekonany. Czasem jest tak, że złe rozwiązanie albo słabe rozwiązanie w biznesie może wytworzyć przekonanie, że taka jest natura tego zjawiska i tego już musimy się trzymać. Widziałem to wiele razy, że upublicznianie czy też przekazywanie do biznesu częściowych rozwiązań kończy się źle, po prostu dlatego, że biznes jest bardzo głodny najczęściej tego, żeby coś zobaczyć jeśli chodzi o rozwiązania Data Sciencowe, i potem bardzo trudno jest przekonać ich, że tak naprawdę w kolejnej iteracji jednak zrobimy coś zupełnie innego, bo tamto rozwiązanie było dobre, a oni się już zdążyli do niego przyzwyczaić.
Bardzo ciekawe rzeczy, że tak powiem. Takie praktyczne wskazówki. Ja uważnie słucham też, że chyba ta druga, czy trzecia była w skrajności, tam gdzie opowiadałeś historię, że kończymy projekt, bo przerwałem go nie wtedy, kiedy już nie mamy żadnych pomysłów, tylko wtedy kiedy odwrotnie, mamy dużo pomysł albo przynajmniej więcej niż jeden.
To akurat też chyba jest aspekt psychologiczny związany z tak zwaną prokrastynacją, albo wtedy jak kończysz projekt, kiedy masz pomysły to czujesz taki głód i wtedy jakbym wewnątrz siebie jeszcze bardziej się nakręcał, że chce tam usiąść, coś nadrobić, więc ta energia gdzieś tam rezonuje, masz siły żeby to zrobić. Wydaje mi się, nie wiem czy to jest to koło zbadane, że to działa też w drugą stronę, że jak wiesz że tam ostatnio spróbowałeś wszystkiego, nie masz teraz pomysłu, to jakby to działa w drugą stronę. Jeszcze bardziej czujesz taki brak energii.
Tak, to jest niewątpliwie tak trochę, że jeżeli wiesz, że idzie Ci dobrze i wiesz gdzie masz podjąć swoją pracę, to twój poziom energii od razu startuje z wyższego pułapu. A wtedy kiedy jakby utkniesz, masz taki dead end i nie wiesz co dalej, to podjęcie tej pracy następnego dnia jest bardzo trudne, bo ten poziom energii który potrzebny jest żeby pokonać tę trudność jest znacznie wyższy.
Mówi się, że uczenie maszynowe dotknie każdego obszaru w tym świecie. Trochę mniej, lub trochę więcej, a logistyka jest raczej takim obszarem, dziedziną gdzie uczenie maszynowe może bardzo pomóc. Dlatego chciałbym Ciebie zapytać o takie przypadki użycia, tak zwane use case’y. Być może nawet takie mniej oczywiste, gdzie uczenie maszynowe może pomóc w logistyce, bo wydaje mi się, nawet nie chodzi o Polskę, bo w Polsce na pewno, ale nawet za granicą ten obszar nadal nie do końca dostrzega ten potencjał. Więc proszę, podaj takie przypadki użycia, gdzie ML może być bardzo pomocny w tej branży.
Na pewno jest to optymalizacja planowania przewozu. W szczególności wtedy, kiedy mamy do czynienia z różnymi przewoźnikami, a nawet różnymi metodami, czy też różnymi środkami transportu, bo do mając do wyboru bardzo szeroką paletę i przewoźników, i potem możliwości, jakimi środkami transportu mogę coś przewieźć z punktu A do punktu B, a powiedzmy, że te dwa punkty są oddalone od siebie o tysiące kilometrów, to taka optymalizacja rzeczywiście jest w stanie mieć istotny wpływ na na rachunek zysków i strat. Na po prostu przychody i koszty tego, kto tej optymalizacji dokonuje. To mogą być zarówno firmy, które same przewożą, jak i na przykład spedytorzy, którzy szukają swoich przewoźników, albo szukają w ogóle różnych dróg, jak przewieźć coś z jednego punktu do drugiego.
Może być przykładowo takie zastosowanie, tu się mówi oczywiście o połączeniu z block chainem dlatego, że w sytuacji kiedy potrzebne jest zaufanie, a zaufanie jest oczywiście potrzebne w transporcie, kiedy coś ładuje się w jednym punkcie i ufa się temu przewoźnikowi, że dowiezie to do punktu B, to istotne jest to też, czy jest możliwe utworzenie platformy, na przykład block chainowej z listami przewozowymi, czy innymi dokumentami, które w ten sposób zabezpieczającą transakcje, tak? Też w dużej części chronią przed oszustwami. Ja byłem niedawno na konferencji w Amsterdamie na IoT Forum i muszę powiedzieć, że liczba startupów, które zajmują się już tymi block chainowymi rozwiązaniami także w logistyce i transporcie jest imponująca.
To brzmi ciekawie. Pozwolę teraz jeszcze zmienić temat na takie bardziej porady z Twojej strony. Adrian, masz duże doświadczenie praktyczne i fajnie będzie jeżeli opowiesz, a może nawet trochę uchylisz rąbka tajemnicy, gdyż nie wiem, czy tak często masz okazję o tym opowiedzieć. Co Cię irytuje w obszarze uczenia maszynowego, tak zwanej sztucznej inteligencji, Data Science możemy też pod to podciągnąć. To mogą być jakieś mity, albo coś innego, ale takie rzeczy który Cię irytują.
Jest kilka takich tematów. Ja może wybiorę dwa. Pierwszy dotyczy problemu pojęciowego. To jest takie coś, co widzimy na każdym kroku, mianowicie to, że ludzie którzy patrzą na machine learning, sztuczną inteligencję i powiedzmy Data Science, patrzą na te pojęcia kompletnie wymiennie, tak jakby uważali, że właściwie Machine Learning to to samo, co AI, a to to samo prawie co deep learning. I tak naprawdę, skoro sztuczna inteligencja brzmi najbardziej cool, czy też hype, czy jeszcze inaczej to nazwiemy, to należy jak najczęściej używać tego słowa. I rzeczywiście w wielu biznesowych wpisach, choćby na medium, ale nie tylko, na wystąpieniach, na konferencjach, to pojęcie AI jest straszliwie nadużywane.
Ludzie, którzy siedzą bliżej machine learning, deep learning wiedzą doskonale, jakby gdzie sztuczna inteligencja rzeczywiście się zaczyna, i też oczywiście dlaczego to o czym uwielbiają Ci ludzie z biznesu dyskutować, nie znając się na temacie, czyli na przykład, jak daleko jesteśmy od punktu osobliwości, czyli od singularity. Ta dyskusja, tak naprawdę jest jałowa, bo jesteśmy jeszcze bardzo daleko od takiej możliwości w których rzeczywiście sztuczna inteligencja będzie w stanie w dużej części emulować funkcję człowieka, tak?
Na razie jesteśmy w stanie ją nauczyć bardzo konkretnych funkcji, bardzo konkretnych działań w których punktowo jest ona, że tak to spersonifikuje. Jest ona w stanie osiągnąć mistrzostwo i nawet być znacznie skuteczniejsza od człowieka, ale nietrudno się też doszukać takich badań w których mówi się, że na razie to cztero czy pięciolatki są w stanie dużo efektywniej rozpoznawać obrazy, zwłaszcza te obrazy na których coś występuje niestandardowego, niż nawet bardzo dobrze wytrenowany model. A drugie przekonanie w środowisku Data Science to, że w tej dziedzinie najlepsi mogą być wyłącznie ludzie, którzy zrobili doktorat z matematyki czy też z informatyki, i tak naprawdę oni mogą i oni wyłącznie mają taką moc stwarzania tych najlepszych modeli.
Tutaj widziałem już wiele takich osób i żeby nie było wątpliwości znam ludzi z doktoratami z tych dziedzin, którzy świetnie wkomponowali się w biznes i są fenomenalnymi albo Senior Data Scientistami, albo już wręcz liderami zespołów. Ale znam też osoby, które przechodziły do danej firmy i miały jednak bardzo naukowe podejście do tego, co będą robić. I okazywało się też, że ich naukowe podejście miało też taką stronę, że oni kompletnie nie wierzyli temu co już zostało zrobione w danej dziedzinie, w związku z tym powtarzali tę samą drogę dojścia do czegoś, po po czym po trzech miesiącach robili prezentację na której stwierdzali, że nie, z tych danych jednak nie da się nic zrobić, do czego doszedł jego poprzednik, tylko niekoniecznie aż tak naukowymi metodami.
Jest tutaj pewna praca zawsze do wykonania dla lidera zespołu, żeby takie osoby które przychodzą z doktoratami z najlepszych uczelni, zaadoptować ich umiejętności do konkretnych celów. Teraz oczywiście, tutaj trzeba rozróżnić takie dwa przypadki. Jeżeli ktoś przychodzi z uczelni i przez ostatni czas zajmował się głównie tym tematem, którym później zajmuje się w firmie, czyli jakby robi dokładnie to samo. Załóżmy, że zajmował się na doktoracie computer vision i będzie nadal się zajmował computer vision firmie. Tutaj generalnie nie ma kłopotów i najczęściej te osoby wtedy bardzo szybko stają się w biznesie gwiazdami. Natomiast w sytuacji w której jakby ten temat nie był dokładnie zbieżny z tym, co oni teraz będą robić w firmie, to właśnie mogą się zacząć te problemy o których mówiłem. I wtedy trzeba odpowiednio pokierować umiejętnościami tej osoby tak, żeby rzeczywiście ta wartość z tego, że ta osoba ze świetnym oczywiście backgroundem, potrafiła wnieść wartość dodaną do organizmu.
Bardzo fajnie to podsumowałeś, tym bardziej, że miałeś taki praktyczny wgląd. Kontynuujmy ten wątek dalej. Teraz zapytam o porady dla osób, które mają zadecydować, czy warto wdrażać ML, czy nie warto. Jeżeli warto, to jak najlepiej do tego podejść? Co możesz powiedzieć decydentom, jak najlepiej się zabrać do wdrażania uczenia maszynowego w firmie?
Na pewno trzeba podjąć kilka istotnych decyzji. Po pierwsze, warto określić jakie my mamy potrzeby i zainwestować przede wszystkim w to, żeby ludzie biznesu byli w stanie identyfikować w jakich punktach Data Science mogłoby im pomóc. Nie chodzi oczywiście o to, żeby oni znali jakiekolwiek algorytmy. Chodzi o to, żeby, jakby pewnymi heurystykami się posługując, byli w stanie powiedzieć: o! tu jest jakiś temat, który rzeczywiście dział Data Science mógłby nam przybliżyć, albo zbudować model, albo zrobić coś co nam generalnie pomoże. To jest super ważne i ja oczywiście staram się w tych firmach, z którymi współpracuje też do tego dążyć.
Drugi temat to jest potem, jak już z identyfikujemy te potrzebę biznesową, to jest oczywiście decyzja czy robić to samemu, czy skorzystać z dostawcy zewnętrznego, tak zwanego vendora. Tutaj znowu jest ileś częstych nieporozumień, które się biorą z tego, że ludzie dość łatwo jednak wierzą temu, ludzie, to znaczy ludzie biznesu, którzy często są decydentami, wierzą łatwo tym pełnym bajerów prezentacjom różnych dostawców. To nie znaczy, że wszyscy dostawcy mają prezentacje pełne bajerów, ale ja miałem okazję z wieloma współpracować przynajmniej na etapie takiego proof of concept i wiem jakby, gdzie można się spodziewać tych bardziej przechwałek, a gdzie rzeczywiste fakty raczej dominują.
Te nieporozumienia biorą się z tego, że oczywiście ludzie z biznesu nie mają wystarczającej wiedzy, żeby ocenić to rozwiązanie, ale dział Data Science najczęściej ma, dlatego bardzo ważne jest kiedy ocenia się czy zrobić coś samemu, czyli wewnątrz organizacji (in house), czy też dać to zewnętrznemu dostawcy. Bardzo ważne jest, żeby nie tylko robić za ten Business Case, ale też żeby zrobić taki proof of concept z udziałem Data Science. To się bardzo opłaca i dzięki temu, choćby w HelloFresh udało się nam w paru przypadkach udaje nam się zaoszczędzić sporo pieniędzy, a z drugiej strony wybrać właściwych dostawców. Ważne jest żeby, ta skrzynka czarna, którą często oferują dostawcy żeby ona nie była jednak aż tak czarna. Żeby jednak rozumieć trochę co tam w środku działa, bo to pomaga potem podjąć właściwą decyzję.
Dziękuję Ci za te wskazówki. Zadam Ci jeszcze ostatnie pytanie. Jak można Cię znaleźć w sieci?
Na razie, mogę powiedzieć że głównie przez LinkedIn, ale jestem na etapie updateowania mojej strony internetowej adrianfoltyn.pl, także wkrótce tam się pojawi nowa treść, która będzie trochę łączyła moje zainteresowania z dziedziny uczenia maszynowego i muzyki. Zresztą mam nadzieję również wreszcie dobić się do tego wyższego stopnia naukowego, na który mam teraz znaleźć czas w najbliższych miesiącach, po to żeby właśnie napisać pracę, która łączy te dwie dziedziny, jeszcze akustykę czy też neurofizjologia. Więc zapraszam tam, ale myślę że tak realnie to zaproszę tam od nowego roku. A na razie zapraszam na Linkedina i tam na pewno można mnie zawsze znaleźć i zadać pytanie, mogę coś rozwinąć o czym mówiłem dzisiaj.
Bardzo dziękuję Adrian za Twój czas, chęć podzielenia się w nieco innym punktem widzenia, czyli łączenia muzyki, Data Science, uczenia maszynowego. Zawsze to jest dla mnie inspirujące, kiedy się łączy różne kropki, a potem okazuje się, że w sumie są one wspólnym mianownikiem, tylko osoba która rozumie przynajmniej jedno i drugie jest w stanie dostrzegać te wspólne części, więc dziękuję, do zobaczenia, do usłyszenia.
Dziękuję bardzo.
Obiecałem, że na końcu opowiem jeszcze trochę więcej na temat konferencji.
Chce się powiedzieć: udało się! Pod koniec kwietnia tego roku wpadłem na pomysł, aby zorganizować dwa duże eventy: DataWorkshop Tour (czyli wyjazd do 6 miast w Polsce ze szkoleniem uczenia maszynowego) oraz zorganizowanie konferencji DataWorkshop Club Conf. Jestem mega z tego zadowolony…
Jednak było to dużym wyzwaniem. W szczególności organizacja konferencji. W trakcie przygotowań zorientowaliśmy się, że sytuacje z konferencjami są w bardzo złym stanie, i to pod kilkoma względami. Mówić w skrócie: jest “dziko”. Każdy dba tylko o swój ogródek. Na przykład, współpraca ze sponsorami według mnie jest mało dojrzała. Sponsorzy chcą promować się w bardzo agresywny sposób, (np. wystawiać swojego prelegenta, który coś sprzedaje) wcale nie przejmując się tym, że to źle wpływa na całokształt. Rozmawialiśmy z wieloma firmami (większość z nich jest znana) i ostatecznie została podjęta decyzja, że zrobimy to inaczej… bez sponsorów! W 100% własnymi siłami. Bardzo prosto się o tym mówi. W zasadzie, każde decyzje przychodzą łatwo. Dopiero potem, kiedy trzeba przejść do działania, jest o wiele trudniej. Okazało się, że byliśmy mocno do tyłu z kosztami. Innymi słowy, na dużym minusie. Marzenia – marzeniami, i będąc o kilkadziesiąt tysięcy do tyłu trzeba to jakoś spłacić.
Pojawił się stres… ale cóż, decyzja podjęta i nadal wierzę, że była ona najlepszą z możliwych. Podjęliśmy próby optymalizacji na wszystkich poziomach, jednocześnie maksymalizując wartość konferencji dla uczestników. Dlatego wydaliśmy dość dużo na catering oraz prezenty, natomiast zminimizliwaliśmy koszty na różnych procesach, a część z nich została zautomatyzowana.
Podam Ci przykład. Było pytanie, kto będzie zapowiadać prelegentów (warto to robić, bo to wpływa na jakość). Była kilka pomysłów, np. podpatrzeć, jak to robią inni, czy może kogoś zatrudnić. Średnio nam się to spodobało, gdyż po pierwsze: trzeba za to zapłacić, a po drugie: jakość takiej usługi też pozostawia wiele do życzenia. Taka osoba nie jest w temacie uczenia maszynowego. Stąd padła decyzja, aby zrobić asystenta, którego nazwaliśmy “Rysiek”. Powstał on przy współpracy z firmą Techmo, którą bardzo gorąco pozdrawiam. Posłuchaj jak brzmi Rysiek :).
Również pomógł nam Karol Majek, razem ze swoim zespołem, który zrobił wyścigi samochodowe pomiędzy ludźmi, a tak zwaną sztuczną inteligencją. Z tego co wiem, to sztuczna inteligencja wygrała. Dziękuję Ci bardzo Karol za wsparcie.
Na jednym z webinarów o efektywnym networkingu, powiedziałem, że jeśli chodzi o organizację konferencji, to finansowo nie jest najlepiej i były przypadki, że niektóre osoby mi trochę pomogły. Bardzo spodobał mi się ten gest. Mimo tego, że osoba mogła skorzystać ze zniżki, to tego nie zrobiła i wysłała do mnie maila z treścią:
“Zakupiłem bilet bez kodu. Potraktuj to jak „kawę”, za Twój czas.”
Ciężko to wyjaśnić. Oczywiście, poczucie wsparcia mentalnego jest dla mnie ważniejsze niż zastrzyk gotówki. Pieniądze i tak gdzieś się rozejdą.
Kolejny temat jaki warto podjąć to studenci, których bardzo staram się wspierać. Szanuję ten okres życiowy, i też wiem, jak duży tam widnieje potencjał. To dlatego zdecydowałem się wprowadzić zniżkę 50% na DataWorkshop Tour. Dotarła do mnie informacja (nawet wiem od kogo), że jeden student z Wrocławia kupił dostęp do transmisji online, ale oglądała ją podobno cała sala studentów. Mimo tego, że z punktu widzenia biznesowego nie brzmi to najlepiej, to mnie osobiście cieszą takie wiadomości, bo to oznacza, że w tym wszystkim jest wartość i kto wie, gdzie w tak zwanym “jutro” będzie ten student.
Na końcu mojej prezentacji wspomniałem o prawie Vladimira, wzorującym się na prawie Moore’a (które mówi, że co dwa lata podwaja się moc obliczeniowa). W prawie Vladimira chodzi o podwojenie przychodów co dwa lata. Pokazałem również slajdy z wykresami z moich PIT’ów. Chodziło o coś innego, niż maksymalizację zysków, bo koszty zwiększają się proporcjonalnie (np. jak dużo pochłonęła ta konferencja). Moim celem jest organizacja coraz bardziej ciekawszych wydarzeń, które ostatecznie pomogą ludziom sprawić, aby ten świat stał się odrobinę lepszym miejscem.
Mimo tego, że sam miałem wątpliwości przed konferencją i pytałem siebie: po co to wszystko robię? Czy to naprawdę jest wartościowe dla innych? To po konferencji przeżyłem tak cudowny stan, który ciężko było mi opisać. Rozmawiając z żoną powiedziałem jej, że mając do wyboru przeżyć ten dzień ponownie lub dostać milion złotych, bez zastanowienia wybrałbym pierwszą opcję. Dzięki takim wydarzeniom czujesz, że życie nabiera sensu. Bardzo Ci życzę przeżywania podobnych uczuć, dzięki czemu staniesz się szczęśliwszą osobą.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.


