

Sztuczna inteligencja i taksówki

Z tego odcinka dowiesz się:
- Jak optymalizacja pomogła firmie iTaxi?
- Jak podnieść atrakcyjność oraz usprawnić działanie firmy wykorzystując uczenie maszynowe oraz sztuczną inteligencję?
- Jak skutecznie optymalizować algorytmy?
- Czy skuteczna automatyzacja może usprawnić workflow?
- Jakie są problemy oraz trudności w odpowiedniej optymalizacji algorytmów?
- Jak wykorzystać podejście symulacyjne do rozwiązywania problemów?
- Co powinno być priorytetem podczas doboru procesów, aby jak najbardziej odzwierciedlały rzeczywistość?
- Jak efektywnie wykorzystywać testy A/B?
- Jak upewnić się, że symulator działa poprawnie oraz jak odpowiednio dobrać jego parametry?
- Czy zastosowanie symulatora w przemyśle innym niż logistyka jest opłacalne?
- Na co należy uważać oraz jakich kosztów się spodziewać podczas wdrażania uczenia maszynowego oraz sztucznej inteligencji do swojej firmy?
- Jak będzie wyglądać postęp technologiczny w ciągu następnych 15 lat?
Jeżeli słuchasz tego odcinka wtedy, kiedy został opublikowany, to zostało Ci jeszcze kilka dni, prawie tydzień do rozpoczęcia konferencji DataWorkshop Club Conf, gdzie bardzo gorąco Cię zapraszam. Mam nadzieję, że jeszcze będą miejsca, i to jest miejsce, gdzie będzie można usłyszeć naprawdę wartościowe, takie życiowe wskazówki, jak należy podchodzić do uczenia maszynowego w naszym życiu, takim życiu realnym.

Również, chciałbym zrobić taki szybki anons, że dwudziestego dziewiątego października startuję z trzecią edycją mojego kursu „Praktyczne uczenie maszynowe” na DataWorkshop. To, jak już powiedziałem jest trzecia edycja. Sto trzydzieści osób wzięło w tym udział. Absolwenci moi pracują w różnych firmach. Znanych i mniej znanych. Myślę, że warto tego spróbować tym bardziej, że wiele osób, czyli moich absolwentów wygłosiło opinię o tym. Ja to wszystko zbiorę i w notatkach to będzie dostępne.
A teraz przechodzimy do tematu, bo dzisiaj jestem z bardzo ciekawą osobą. Nazywa się Tomasz Brzeziński, który pracuje w iTaxi, i dla mnie takie osoby są bardzo inspirujące, interesujące dlatego, że po pierwsze, potrafią myśleć inaczej, ale czasem widzę dwa rodzaje takich ludzi, którzy myślą inaczej. Pierwszy rodzaj to taki, który po prostu się buntuje i mówi: nie, ale za tym nic nie stoi, tylko po prostu się nie zgadza. Taki trochę nastolatek. A drugi rodzaj, który przyciąga moją uwagę to człowiek, który mówi, że można coś zrobić inaczej, i za tym stoją takie twarde, lub jak to się mówi w Polsce, grube argumenty. I to jest super ciekawa rzecz, kiedy wydaje się, że tak się robiło zawsze i przychodzi ktoś i mówi: a zróbmy to inaczej. I tłumaczy dlaczego tak jest. Dobra, już nie przeciągam tego wprowadzenia. Zapraszam do wysłuchania tego odcinka.

Cześć Tomek, przedstaw się: kim jesteś, czym się zajmujesz, gdzie mieszkasz?
Witaj Vladimir. Nazywam się Tomek Brzeziński. Mieszkam w Warszawie. Mam żonę i trójkę dzieci, i tutaj będzie pierwszy wtręt, taki osobisty, ponieważ moja żona dzisiaj akurat ma urodziny, więc wszystkiego najlepszego, a pracuje jako Chief Data Scientist w firmie iTaxi. W firmie która zajmuje się, jest taką niestandardową korporacją taksówkową, a raczej marketplacem dla taksówek, czyli łączy taksówkarzy z klientami. Można zamawiać te taksówki za pośrednictwem aplikacji lub call center.
Co ostatnio czytałeś?
Co ostatnio czytałem? Ja czytam bardzo dużo. Czytam około 60 książek rocznie, chociaż ostatnio po urodzeniu trzeciego dziecka chyba spadło to do około 40, i czytam jednocześnie kilka książek. Tak to jakoś jest, że jedną z reguły mam przy sobie i czytam ją w komunikacji miejskiej, jedna leży przy łóżku, z jedną gdzieś chodzę po domu. I teraz, na przykład czytam też z bardzo różnych dziedzin. Jedna rzecz, to jest taki cykl szwedzkich kryminałów „Saga o Fjällbace”, Camilli Lackberg. Ito jest taka lekka literatura, jeśli kryminały można nazwać lekką.
Druga rzecz jest bardziej analityczna, choć też też popularnonaukowa. To jest taka pozycja o tytule “Piłkomatyka”, napisana przez Sumptera, angielskiego matematyka. I to jest próba analitycznego podejścia do piłki nożnej. Bardzo ożywcze, bardzo ciekawe. Takie podejście, które pokazuje jak na przykład można na różne sposoby próbować wyprognozować, kto w przyszłym sezonie wygra Ligę Mistrzów, jak również, jak można wyjaśnić na poziomie teorii matematycznych, dlaczego do takiego stylu jaki na przykład prezentuje Barcelona, czyli dużo szybkich, krótkich podań, dlaczego akurat taka formacja, jaką stawiają na boisku ma sens.
Trzecia rzecz którą teraz czytam to jest “Wiek krwi” Wołoszańskiego, czyli takie też popularnonaukowe, ale z dziedziny historii, eseje o XX wieku i o wydarzeniach zwrotnych. Także bardzo, bardzo różne gatunki. Ja czytam w zasadzie bardzo wiele różnych gatunków. Omijam może tylko jakieś romansidła i tego typu rzeczy, a oprócz tego chyba nie ma dla mnie żadnych gatunków tabu, i pewnie mniej niż większość specjalistów z tej naszej branży, mniej czytam rzeczy takich stricte technicznych.
W ogóle powiedziałeś kilka ciekawych rzeczy. Wydaje mi się, że dość często słyszę, że niestety nie mamy czasu na książki, bo mamy dzieci. Ty masz trójkę dzieci, czy też, tak jak powiedziałeś czytasz około 40 książek rocznie, więc myślę że to jest taki fajny benchmark dla wielu osób.
Kolejną rzeczą, jaką bym powiedział to, że dla mnie taką inspiracją jest podejście Lecha Kaniuka, który do niedawna był prezesem iTaxi, a wcześniej zakładał PizzaPortal, który jakiś czas temu właśnie zadeklarował, że przeczyta tysiąc książek o biznesie i zaczął czytać książki w momentach, w których do tej pory jakieś inne aktywności kradły mu czas.

I nagle się okazało, że dzięki temu że nie spędza czasu na tych czynnościach, takich które tu nam ukradną pięć minut, to siedem, nagle jest w stanie czytać znacznie więcej niż do tej pory. Ja może nie jestem w tym aż tak konsekwentny, ale mocno mi to zaimponowało. Jest jakąś inspiracją.
Dzięki wielkie za lifehacka. A powiedz czym się zajmujesz w pracy?
Tak mówiąc bardzo ogólnie, optymalizuję algorytmy, a jeszcze bardziej ogólnie, staram się metodami analitycznymi poprawić działanie firmy na bardzo różnych polach biznesowych. Czyli, czasami oznacza to po prostu, że próbuje zautomatyzować jakiś proces, który wcześniej robili ludzie, dzięki czemu mają czas na inne czynności. Czasami kiedy pojawia się jakiś pomysł zmiany strategii, przeliczam jak to wpłynie na opłacalność biznesu, co się może wydarzyć, ale takim najważniejszym elementem jest to, że opiekuję się naszym algorytmem wydawania zleceń taksówkarzom, i staram się tak go przekształcić żeby spełniał nasze cele biznesowe.
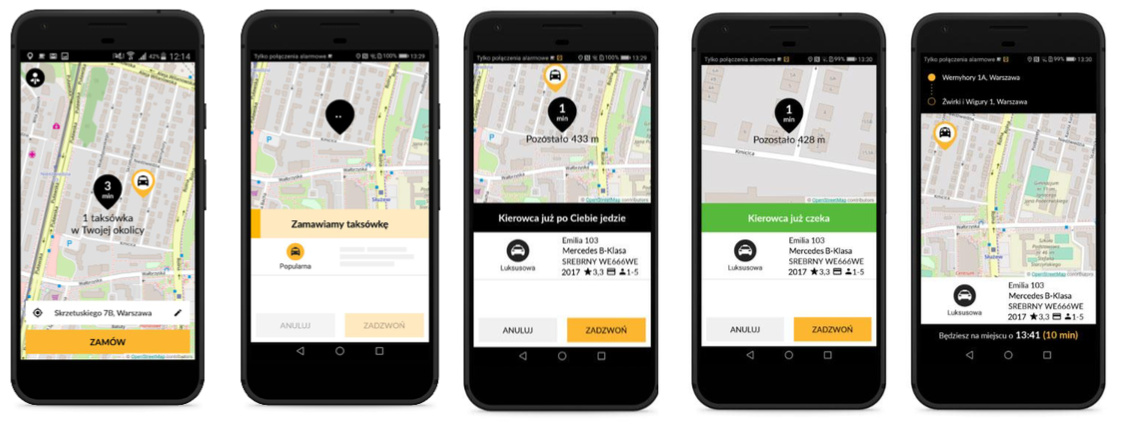
O tym algorytmie dzisiaj porozmawiamy, bo jest właściwie tematem dzisiejszej rozmowy. A powiedz na początek trochę więcej, czym jest iTaxi, i myślę, że w tej chwili mamy na rynku różne nazwy. W głowach wielu osób się to wszystko wymieszało. Jaka jest różnica, i czym na przykład iTaxi różni się od Ubera?
Oczywiście, taki sens ogólny jest ten sam, czyli chcemy przewieźć ludzi w miejsce do którego chcą dotrzeć. Natomiast już dalej są olbrzymie różnice. Przede wszystkim, nasza firma to jest firma zajmująca się przewozami taksówkarskimi. Taksówki w Polsce są tworem koncesjonowanym i są poddane pewnym bardzo ścisłym regulacjom, czyli jest tam określona przez miasto stawka, jaka jest dopuszczalna minimalna i maksymalna. Są pewne zasady, które te taksówki muszą spełniać, a jednocześnie te taksówki mają pewne przywileje, których nie mają inne pojazdy. Na przykład, można przewozić taksówką dziecko bez fotelika, albo mogą te taksówki wjechać w miejsca, w które samochód Ubera, na przykład wjechać nie może.
I to jest taka różnica na poziomie prawno-technicznym, natomiast ona ma bardzo silne przełożenie na biznes. Bo my na przykład nie możemy wprowadzać takich mechanizmów jakie wprowadzał Uber, czyli elastycznie zmieniać ceny nawet z minuty na minutę, ponieważ taryfa musi być wydrukowana na szybie. Zupełnie inna jest nasza filozofia. Uber jest firmą, która stawia na pełną skalowalność, czyli ich biznes, są w stanie, tak naprawdę uruchomić wszędzie na świecie, co w zasadzie robią, natomiast my stawiamy na bardziej, bym powiedział dopieszczony, lokalny biznes, czyli skupiamy się na Polsce.
Przede wszystkim na największych miastach i tam jesteśmy w stanie dostosować naszą politykę tak, żeby uzyskać przewagę konkurencyjną. Druga różnica, taka bardzo duża jest taka, że jesteśmy nastawieni przede wszystkim na obsługę business to business (B2B), czyli zawieramy umowy z firmami na przewóz ich pracowników. Tutaj wypracowaliśmy wiele mechanizmów, które ułatwiają firmą życie, takie jak: jedna faktura na wszystkie przejazdy razy w miesiącu, możliwość ustawiania jakichś limitów dla pracowników, przypisywanie kosztów do określonego projektu, sprawdzanie jakie kursy odbył dany pracownik.
Mnóstwo tego typu mechanizmów, które mają sprawić, że w firmie będzie wygodniej korzystać z tego, co jest bardzo potrzebne i do biznesu, a jednocześnie nie jest ich głównym obszarem działalności. Natomiast, jeśli uruchomisz aplikację Ubera i uruchomisz naszą aplikację, to taka od strony użytkownika zasada działania jest podobna. Jesteś w jakimś miejscu, zamawiasz taksówkę, taksówka do ciebie przyjeżdża, jesteś w stanie w tej aplikacji śledzić trasę, wiesz kiedy taksówka do ciebie przyjedzie, wiesz mniej więcej kiedy dotrzesz do punktu docelowego, masz historię kursów. i tak dalej.
Czyli nie różni się to dramatycznie, natomiast trzeba pamiętać, że Uber przez to, że ten biznes jest nastawiony na takie szybkie skalowanie, nie jest w stanie w tak wysoki sposób jak my dbać o jakość dostarczanej usługi. Nie jest w stanie weryfikować tak precyzyjnie wszystkich kierowców. Oni nie muszą mieć licencji, nie muszą znać miasta. W skrajnych przypadkach mogą nawet nie znać dobrze języka kraju, w którym świadczą te usługi, a u nas są to ludzie którzy mają koncesję taksówkarska, i to jest taka główna różnica.
Z tym ostatnio, jeżeli chodzi o język, to faktycznie, zwłaszcza Warszawie, bo dużo teraz podróżuję po Polsce i w Warszawie czasem się spotyka, że ten samochód jest prowadzony przez osobę z Azji, która w najlepszym przypadku mówi po angielsku, więc potwierdzam, że takie rzeczy się zdarzają. Dobrze!
Skupmy się teraz na tych wyzwaniach, które macie do rozwiązania. Trochę ich jest. Problem optymalizacji algorytmu wydawania zleceń jest dość trudny i o tym właśnie dzisiaj fajnie będzie porozmawiać. Natomiast do czego sprowadza się rozwiązanie tego problemu. Co tak naprawdę chcemy osiągnąć?
No i właśnie, jak tak to sobie określimy, to okazuje się, że problem jest dość prosty. To znaczy, my chcemy żeby pasażer dostał swoją taksówkę jak najszybciej, i żeby ta taksówka w jak największym stopniu spełniała jego oczekiwania. No i my tutaj zwracamy uwagę na takie trzy główne elementy. Pierwszy z nich to jest czas dojazdu, czyli ile czasu minie od momentu kiedy jak kliknę zamawiam taksówkę, do momentu kiedy taksówka pojawi się w żądanym przeze mnie miejscu. Druga kwestia to jest zdolność do zaspokojenia popytu, czyli jak jesteśmy w stanie zminimalizować liczbę takich przypadków, kiedy nie jesteśmy w stanie dostarczyć taksówki. Oczywiście, takie przypadki się zdarzają, jak w każdej korporacji taksówkarskiej, natomiast my bardzo staramy się żeby tych przypadków było jak najmniej. I trzeci element, to jest jakość świadczonej usługi, czyli to żeby taksówka była wygodna, czysta, nowoczesna, żeby taksówkarz był miły, kulturalny.
Stawiamy też bardzo mocno na ekologię i staramy się mieć w naszej flocie jak najwięcej samochodów elektrycznych lub hybrydowych, czyli dbamy o tą jakość, o to żeby te taksówki, które realizują zlecenia były jak najlepsze. I to są te trzy główne parametry, które ja staram się zoptymalizować algorytmem wydawania zleceń.
Okej, to już wiemy co chcemy osiągnąć, ale prawdopodobnie nie jest takie trywialnie. No właśnie. Jakie są wyzwanie w tej optymalizacji?
Oczywiście, to jest bardzo skomplikowany problem i tu jest kilka kwestii. Przede wszystkim, właśnie ja powiedziałem, że optymalizuje trzy rzeczy. Każdy, kto kiedykolwiek optymalizował jakiś proces, od razu powiem: no dobra, ale jak jednocześnie optymalizować trzy rzeczy? I to jest pierwsza kwestia. To jest problem wielokryterialny, jak to mówią specjaliści od badań operacyjnych, czyli mamy nie jeden parametr który chcemy zmaksymalizować, zminimalizować, tylko kilka jednocześnie. I jak to w życiu bywa, z reguły polepszenie jednego wpływa na pogorszenie innego. Druga kwestia, to analityczne sposoby rozwiązywania problemów, zazwyczaj, bardzo często polegają na tym, żeby jakiś problem sprowadzić do problemu liniowego, gdzie już analityka jest dość prosta i komputery potrafią robić to bardzo szybko i bardzo sprawny.
Nasz problem jest mocno nieliniowy i moim zdaniem niesprowadzalny do liniowego, co może po prostu oznaczać, że ja nie umiem go sprowadzić do liniowego oprócz tego, to optymalne rozwiązanie jest niestabilne w czasie. W tym sensie, że na pewno nie jest tak, że jeśli Ja opracuję idealny algorytm dla godzin szczytu, to on będzie również optymalny dla, na przykład nocy sylwestrowej, czy po prostu godzin porannych. Jest też niestabilny w przestrzeni, to znaczy optymalny algorytm dla Warszawy na pewno nie sprawdzi się na przykład w Trójmieście, gdzie odległości są mniejsze, a problem przejezdności miasta znacznie mniejszy. No i, cała ta optymalizacja do tego jest prowadzona w warunkach niepewności. Czyli my nie mamy, na przykład tak jak w znacznym stopniu ma na przykład poczta albo firma logistyczna, która z góry wie z jakich punktów, do jakich punktów ma danego dnia przewieźć jakieś ładunki, czy to przesyłki, czy jakiś towar, i po prostu może to zoptymalizować jakimiś metodami. Nam się ten popyt pojawia na bieżąco i możemy być nim zaskoczeni. Możemy nagle zobaczyć, że pojawia się trzysta zleceń w jakimś punkcie, gdzie wcześniej te zlecenia się nie pojawiały. Więc, jest to też optymalizacja w warunkach niepewności. No i to są takie główne wyzwania, główne kwestie, które sprawiają, że ten problem jest tak bardzo skomplikowany.
Teraz chcę przejść do symulatora, który właśnie jest rozwiązaniem na jeszcze jedno wyzwanie o którym może warto powiedzieć, bo pamiętam jak rozmawialiśmy. Trudność którą macie, to jest tak, że na przykład wydaje mi się, że można zmienić algorytm w tę stronę albo w drugą stronę, ale niestety żeby to przetestować, to po pierwsze, może się okazać, że ta idea albo hipoteza była błędna, i to oznacza że prawdziwi klienci nie zobaczą taksówki i mogą się wkurzyć i zrezygnować.
Po drugie, to też nie da się tak szybko testować tych różnych pomysłów, bo tych pomysłów jest dużo, a na przetestowanie pomysłu potrzebujemy czasu. Rozwiązaniem na to właśnie byłby symulator. I zastanawiam się tak trochę, jak w ogóle ten pomysł się pojawił? Czy to było takie olśnienie? Czy to była taka naturalna ścieżka? I też myślę, że warto zapytać o odwagę, bo to jest napewno coś innego, niż zwykle się stosuje.
Może zacznijmy od tego, że moja ścieżka zawodowa to już jest dwadzieścia lat i po raz pierwszy stosuje podejście symulacyjne od czasów studiów. I może nawet bym o tym chwileczkę opowiedział, bo to jest bardzo ciekawy przypadek. Kiedy byłem bodajże na trzecim roku studiów, w kole naukowym zaczęliśmy się irytować tym, że w jednym z budynków Szkoły Głównej Handlowej windy działają nieefektywnie.
Tworzą się kolejki, trzeba czekać na tę windę, albo trzeba biec schodami, na przykład na trzynaste piętro, co nie dla każdego jest takie proste. No i, stwierdziliśmy że my ten problem rozwiążemy i powiemy, jak zmienić algorytm poruszania się tych wind. No i, poszliśmy do ówczesnego rektora, który był na szczęście ekonometrykiem i dał nam na to zielone światło. I postanowiliśmy problem rozwiązać.
To oczywiście nie jest tak, że jest jakaś jedna optymalna strategia działania zespołu trzech wind w budynku piętnasto piętrowym, bo gdyby tak było, ona byłaby po prostu wdrożona i nie musielibyśmy jej odkrywać,i oczywiście taka strategia zależy od tego, jaki jest rozkład osób podróżujących pomiędzy każdą parą pięter. Pewnie intuicyjnie wiemy, że najwięcej wsiadań, wysiadań jest na parterze, i tak dalej, i tak dalej.
I można zbudować taki prosty model gdzie, na przykład założymy, że podróże odbywają się wyłącznie na drodze między parterem, którymś piętrem i odwrotnie, czyli zakładamy wtedy że nigdy ludzie nie jeżdżą pomiędzy piętrami, co nie jest prawdą, ale w pewnych przypadkach można te jazdy między piętrami pominąć. Można zrobić mnóstwo innych założeń, a my jako ambitni studenci uznaliśmy, że to byłoby zbyt duże uproszczenie rzeczywistości i chcemy zrobić coś, co na pewno się sprawdzi, no bo właśnie, za chwilę reaktor wdroży nasz algorytm w życie i jeżeli kolejki będą większe, to możemy, co najmniej nasza duma na tym ucierpi.
Stwierdziliśmy, że zbadamy empirycznie ruch w tych windach, czyli to była dość zabawna historia, bo ludzie podróżują z tymi windami mogli spotkać studenta stojącego sobie w tej windzie. Potem zoptymalizowaliśmy nasz sposób zbierania informacji i już mieliśmy krzesełka, na których ten student siedział i notującego czas wejścia każdej osoby do windy. Piętro na którym wsiadł, na którym wysiadł.
Kiedy zebraliśmy dostatecznie dużo danych, oszacowaliśmy rozkłady i zaczęliśmy budować symulator. To była świetna zabawa dla nas jako studentów. Bardzo pouczające doświadczenie, ale co najciekawsze, to to rozwiązanie zostało później wdrożone i rozwiązało problem tych kolejek przed windami. Działało to bardzo długo. Jeszcze kilka lat temu mi ktoś mówił, że rektor wspomniał na zajęciach o tym, że ten algorytm nadal działa. Także, nadal czuję jakąś dumę z tego powodu.
I to był ostatni raz kiedy zastosowałem symulator, bo później problemy z którymi się zderzałem, albo były rozwiązywane analitycznie i wtedy po co budować sam symulator, skoro można to rozwiązać analitycznie, albo były tak skomplikowane, że nie miałem żadnego pomysłu na to jak zbudować ten symulator. Teraz, kiedy przeszedłem do iTaxi, nagle się okazało, że widzę że znowu problem, który jest wręcz stworzony do rozwiązania właśnie metodami symulacyjnymi.
Bo procesy są ściśle określone. My wiemy, jak ten proces wygląda. Pasażer klika, taksówka dostaję zlecenie, przyjmuje lub nie, bo taksówkarz może odmówić jeśli nie przyjmuję zlecenia, idzie do następnego taksówkarza. Ten, który w końcu przyjmie do zlecenie zaczyna się poruszać. Można to zamodelować z jaką prędkością, kiedy dotrze. Później jedzie, gdzieś wysadza pasażera i znowu jest dostępny. To wszystko można opisać takim iteracyjnym symulatorem, gdzie powiedzmy łapiemy takie okna co 15 sekund, aktualizujemy sytuację, no i stwierdziłem, że nie znam lepszej metody na rozwiązanie tego problemu.
A pytałeś też o odwagę. Owszem, zastanawiałem się czy to w ogóle w jakikolwiek sposób zadziała, ale jest problem do rozwiązania. Nie mam innego pomysłu, więc wypróbowuję metody symulacyjne. I tak bardzo często jest, że problem wydaje się znacznie bardziej skomplikowany zanim do niego siądziemy. Bywa też odwrotnie, ale w tym wypadku nagle się okazało, że budowanie tego symulatora nie jest aż tak czasochłonne jak mi się wydawało. Danych z przeszłości mieliśmy bardzo dużo, co pozwoliło bardzo dobrze zweryfikować, które założenia tego symulatora są właściwe, a które trzeba zmienić. No i to była tak naprawdę ta droga, z której jestem zasadzie zadowolony, bo osiągnęliśmy dokładnie to co chcemy. Czyli mamy teraz odzwierciedlenie tego jak działa miasto, tak to nazwijmy, gdzieś w komputerze i jesteśmy w stanie modelować również jakieś nasze nowe pomysły.
Wejdźmy trochę w szczegóły tego symulatora. Powiedziałeś już trochę o założeniach, ale spróbujmy je jeszcze bardziej sprecyzować. Wiem, że to było bardzo pragmatyczne podejście i część założeń wyglądała dość w takim większym uproszczeniu, ale najpierw powiedz kilka słów na temat założeń. Co było przyjęte do tego symulatora?
Generalnie, kiedy budujemy jakiś model, musimy dokonać takich bardzo trudnych wyborów. Które procesy zostaną odzwierciedlone bardzo wiernie, a które zostaną uproszczone lub nawet pominięte. Na przykład, nie jesteśmy w stanie nigdy odwzorować rzeczywistości w stu procentach. Gdybyśmy byli to staje się to znowu rzeczywistością. I my stwierdziliśmy, przy zastanawianiu się jak to zbudować, że pewne uproszczenia mogą zostać wprowadzone. I od takich najprostszych, na przykład założyliśmy, że nie ma czegoś co my nazywamy zleceniem grupowym, czyli że ktoś zamawiał w jeden punkt jednocześnie kilka taksówek.
Założyliśmy, że zawsze każde zlecenie to jest dokładnie jedna taksówka. Założyliśmy. że nie ma zleceń terminowych, czyli takich że ja, na przykład teraz zamawiam taksówkę na jutro na 9:00 rano. Czyli, że wszystkie zlecenia to są zlecenia na już. Czyli chodzi o to, żeby dostarczyć tam taksówkę jak najszybciej. Założyliśmy też że pasażer bez powodu nie zmienia swoich decyzji. To znaczy, on może stwierdzić: “ja rezygnuję z taksówki, bo jest zbyt duży czas dojazdu”, i to jak najbardziej zamodelowaliśmy, natomiast założyliśmy, że nie jest tak, że zamawia taksówkę, taksówka jedzie i to jest dla niego czas oczekiwania dopuszczalny, ale mam z tego rezygnuje, co jest oczywiście uproszczeniem rzeczywistości.
No i teraz, to są te takie prostsze uproszczenia, ale założyliśmy też, że wszystkie taksówki mają tą samą charakterystykę prędkości. Czyli oczywiście prędkość taksówki jest inna w centrum miasta, a inna na obrzeżach, ale każda taksówka w centrum porusza się z tą samą prędkością, i z tą samą prędkością co inne, porusza się na obrzeżach. No to jeszcze da się przełknąć. I ostatnie założenie które jest najbardziej takie drastyczne, to ja przyjąłem, że taksówki będą się poruszać po liniach prostych. I to oczywiście w żaden sposób nie odzwierciedla rzeczywistości, natomiast tutaj mój tok myślenia był taki: metryka miejska.
Nie to, co w badaniach operacyjnych nazywa się metryką miejską, ale taka rzeczywista metryka miejska, czyli czas lub odległość jaką potrzebuje taksówka do przejechania z jednego punktu do drugiego po drogach zgodnie z przepisami, da się przekształcić na właśnie taką klasyczną euklidesową metrykę, czyli poruszanie się po linii prostej bez obciążenia w żadną stronę. Oczywiście, my zakładamy wtedy znacznie krótszą drogę, więc musimy to zrekompensować odpowiednią korektą prędkości taksówek.
No i oczywiście bałem się bardzo jak to założenie, czy to założenie nie jest zbyt upraszczające i czy nie nie wpłynie na to, że to co dostaniemy symulatorze kompletnie nie będzie odzwierciedlało rzeczywistości, więc bardzo starannie, na takich wąskich przypadkach sprawdzałem czy wyniki otrzymane przy takiej metodzie są znacząco różne, a przede wszystkim sprawdziłem czy odległość w linii prostej, czyli ta którą ja będę stosował jest bardzo ściśle skorelowana z czasem dojazdu. Bo jeśli jest bardzo ściśle skorelowane z czasem dojazdu, takim rzeczywistym, historycznym, to oznacza, że ja manipulując właśnie prędkością jestem w stanie zasymulować ten rzeczywisty czas dojazdu, który by taksówka miała, gdyby jechała po normalnych drogach.
I to było takie najostrzejsze założenie, ale są też rzeczy o których stwierdziliśmy, że musimy odwzorować bardzo wiele. Pewne zjawiska mają określone rozkłady, na przykład rozkład zleceń, pojawiania się zleceń jest specyficzny i w czasie i przestrzeni, czyli więcej zleceń pojawia się w szczycie i również w przestrzeni.
Jest to dość charakterystyczne ponieważ, na przykład rano więcej zleceń pojawia się na obrzeżach miasta, a po południu więcej zleceń pojawia się w centrum, bo ludzie jadą do pracy z reguły z obrzeży do centrum i wracają z pracy z centrum na obrzeża. No i oczywiście te rozkłady musiały być powiązane, czyli rozkład zlecenie w czasie i w przestrzeni musiał być powiązany. No i, to trzeba było odwzorować bardzo wiernie. Ja pewnie za chwilę bym chciał opowiedzieć o tym jak to robiliśmy, jakimi metodami. Inne takie rzeczy, które chcieliśmy bardzo wiernie odwzorować, to rozkład dostępności taksówkarzy.
Nie można założyć, że każdy taksówkach pracuje równo osiem godzin. Jedni z nich pracując dziennie dwie godziny, inni osiem, jedni pracują dwa dni w tygodniu, inni siedem. My dajemy taksówkarzem w tej kwestii pełną dowolność. Kolejna z tej strony rozkład cierpliwości pasażerów. Nie można stwierdzić, że jeżeli czas dojazdu będzie trwał powyżej ośmiu minut, to zawsze pasażer zrezygnuje z dojazdu. Dla części pasażerów to jest czas dopuszczalny, dla części jest absolutnie niedopuszczalny. W związku z tym musieliśmy zamodelować ten rozkład cierpliwości dla każdego pasażera niezależnie.
To, co założyliśmy również to, że poszczególne miasta mają zupełnie inne charakterystyki, czyli nie będziemy zakładać że to co sprawdza się dla Warszawy sprawdzi się też dla innych miast i modelujemy każde miasto oddzielnie. Założyliśmy również, że przejezdność miasta, czyli tak naprawdę w naszym przypadku prędkość poruszania się taksówki zmienia się w czasie, czyli jest inna w szczycie, inna w nocy. No i jest niejednorodne w przestrzeni. Inaczej jeździ się w centrum, inaczej jeździ się na obrzeżach. No i, takie bardzo ważne założenie przy wszelkich symulacjach, że kiedy podejmujemy decyzje w danym momencie, nie mamy wiedzy o przyszłości. To jest dość oczywiste, ale często analitycy starają się iść na skróty i stwierdzić: ja to mam cały popyt z całego dnia i teraz znajdę taką funkcję, która zoptymalizuje zaspokojenie tego popytu, a natomiast nie musimy mieć taką funkcję, która mając informacje o godzinie 9:20, podejmie optymalną decyzję, a potem dowie się co się zdarzyło o godzinie 9:21 i podejmie kolejną decyzję.
No i oczywiście, to już takie bardzo oczywiste. Stwierdziliśmy, że każda z czynności musi trwać określony czas. Zamówienie taksówki, przyjęcie zlecenia przez taksówkarza, czas dojazdu, wsiadanie pasażera, i tak dalej. Każda z tych czynności trwa i ten czas należy w symulator wpisać. Jeśli chodzi o to, co zrobić z tymi rozkładami. No tak jak opowiadałem o tych windach, tam sobie szacowaliśmy te rozkłady siedząc z tych windach i notując. Tutaj byłem w trochę lepszej sytuacji, bo danych historycznych mieliśmy mnóstwo, ale oczywiście, zwłaszcza w takiej firmie która tak dynamicznie się rozwija jak nasza, nie można przenieść tak jeden do jednego przeszłości na przyszłość, ta przyszłość jest po prostu znacznie bardziej intensywna.
Jest znacznie więcej zleceń z dnia na dzień. No i, uznałem, że najlepszym podejściem będzie zastosowanie metody Monte Carlo do budowy większości z tych rozkładów. Dla tych którzy nie wiedzą, metoda Monte Carlo jest wymyślona przez polskiego matematyka Stanisława Ulama. To ten matematyk, który jest wywodzi się ze szkoły lwowskiej, i między innymi pracował nad bombą atomową w czasie II Wojny Światowej.
I ta metoda służy znajdowaniu właśnie rozwiązania takiego problemu, który jest za trudny na rozwiązanie analityczne. I to rozwiązanie znajdujemy przez wielokrotne powtarzanie eksperymentu, które polega na losowaniu według pewnego rozkładu prawdopodobieństwa. Przykładowo, możemy sobie wyobrazić, że chcemy oszacować powierzchnię jakiegoś obszaru o bardzo nieregularnych kształtach, na przykład powiedzmy, że chcemy oszacować powierzchnię jeziora. Metoda Monte Carlo w takim przypadku dałaby takie rozwiązanie: utwórz sobie kwadrat o znanej ci długości boku, takich że całe to jezioro będzie wewnątrz kwadratu. Następnie wielokrotnie losuj z takiego klasycznego rozkładu jednostajnego, punkty należące do tego kwadratu.
Część punktów będzie na powierzchni jeziora, część nie. Jeśli podzielisz liczbę punktów które należą do jeziora przez liczbę wszystkich punktów, otrzymasz oszacowanie tego, jaką część kwadratu zajmuje jezioro, a ponieważ powierzchnię kwadratu znasz, daje ci to też oszacowanie powierzchni jeziora. Bardzo proste i eleganckie. Oczywiście trzeba dokonać tych losowań bardzo dużo, ale bardzo fajne do szacowania, na przykład właśnie powierzchni, jeśli ktoś tak, jak ja strasznie nie lubi całkować, to świetnie nadaje się też do obliczania pola pod wykresem.
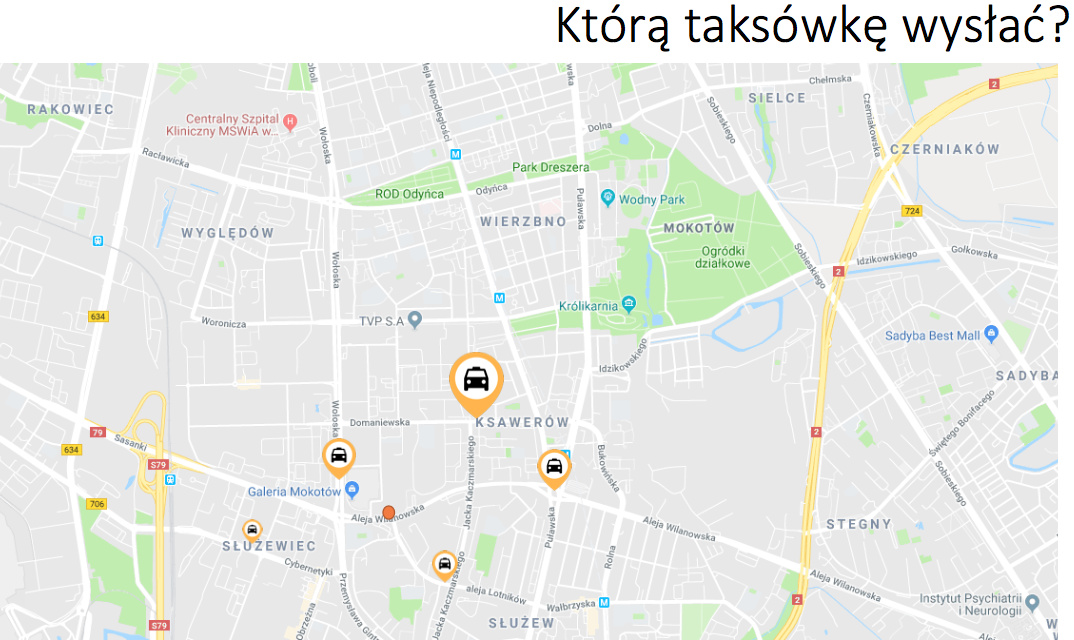
No i ja tej metody użyłem do szacowania rozkładów prawdopodobieństw do mojego symulatora. I na przykład, żeby zamodelować popyt, wziąłem z odpowiedniego okresu z przeszłości wszystkie zlecenia klientów. Jeśli chciałbym, na przykład zrobić symulator dla dnia w którym spodziewam się dwustu zleceń, to po prostu z przeszłości, z dni podobnych losowałem dwieście zleceń i brałem wszystkie cechy tych zleceń, czyli jaka była charakterystyka tego pasażera, gdzie dokładnie to zlecenie się pojawiło, jaki był adres docelowy, o której godzinie, i tak dalej. Podobnie szacowałem inne rozkłady, na nawet nie szacowałem tylko symulowałem te rozkłady. No i następnie trzeba było zbudować symulator. Gdyby go zwizualizować, co zresztą zrobiłem i w tym symulatorze jest taka opcja żeby podejrzeć jak, w którejś iteracji wyglądało miasto, to wyglądałoby to tak, że powiedzmy na mapie Warszawy są rozmieszczone taksówki. No i pojawia się zlecenie. I zlecenie jest przydzielane jednej z taksówek przez najważniejszą funkcję w tym algorytmie, bo to ją optymalizujemy.
Następnie, w następnej iteracji taksówka rusza w stronę klienta. Mogą się pojawić kolejne zlecenia, mogą się pojawić kolejne taksówki, bo właśnie jakiś taksówkarz zaczął pracę, mogą niektóre taksówki zniknąć, bo jakieś taksówkarz skończył pracę, może się pojawić jakieś inne zdarzenie. Mogą się zmienić, na przykład prędkości. Następnie, kolejna iteracja. Wybrana nasza taksówka dojedzie w pewnym momencie do pasażera, potem razem z nim pojedzie do adresu docelowego, wysadzi pasażera i znowu zmieni status na dostępny i będzie gotowa przyjąć kolejne zlecenie. I tak symuluję cały dzień. Do tego, oczywiście właśnie dochodzą takie kwestie jak: koniec pracy taksówkarzy, taksówkarze odrzucają zlecenia, bo uważają że dojazd zajmie im za długo, pasażer nie chce tyle czekać, i wiele innych kwestii. No i potem już jest kwestia tylko przeprowadzenia bardzo wielu symulacji.
Sprawdzenie, czy nie mamy niestabilności, czyli czy wyniki poszczególnych symulacji nie są bardzo rozbieżne, bo jeśli tak, to albo problem jest chaotyczny, bo tak też może się zdarzyć. Na szczęście w naszym przypadku tak nie było.
I generalnie modelowanie chaosu nie jest dobrym pomysłem, albo jeśli ta rozbieżność jest duża, to może to wskazywać, że symulator ma jakieś elementy niestabilne i trzeba je znaleźć, i poprawić. Następnie, kiedy widzimy, że stabilność jest uśrednieniem wyników z tych wielu symulacji, znalezienie najlepszych parametrów, no i mamy coś, o czym wierzymy, że najlepiej działa w symulatorze, no i teraz musimy sprawdzić czy również będzie najlepiej działało w rzeczywistości. Tu dochodzimy do właśnie sprawdzenia w rzeczywistości. Robiliśmy to przez klasyczne testy A/B, czyli dla części zleceń stosowaliśmy nowe wymyślone w symulatorze funkcje, dla części zostawiliśmy stare i sprawdzaliśmy, czy rzeczywiście poprawa jest taka, jakiej się spodziewamy. Tak to z grubsza wyglądało.
Powiedziałeś wiele ciekawych rzeczy, ale zastanawiam się teraz nad tym, kiedy mamy symulatory i mamy tą rzeczywistość, i jedno jest pewne, że to nie jest to samo, natomiast może być bardzo zbliżone. I powiedziałeś, już na końcu, że przy pomocy testów A/B sprawdzaliście na ile to jest akceptowalne. Zastanawiam się teraz nad taką rzeczą. A co jeżeli znajdziesz informację, że symulator działa inaczej, czyli zakłamuję tą rzeczywistość. Co robicie wtedy?
Skąd, na przykład wiecie, to znaczy, według mnie wtedy jest pewność w jednym, że symulator działa inaczej, ale ten symulator posiada bardzo dużo różnych parametrów. Skąd wiecie, że w tym przypadku trzeba zmienić takie parametry, albo takie założenie, albo inne założenie. Bo tych założeń jednak trochę przyjęliście. To już na poziomie intuicji się dzieje? Czy macie jakieś inne metody do tego? Powiedz coś więcej.
Tu dotknąłeś bardzo ciekawej rzeczy. Rzeczywiście, to jest największy problem. I tak: w pierwszym etapie, po prostu starałem się odwzorować naszą przeszłość. Czyli, w symulatorze obowiązującą funkcją była ta, która jest, była dotychczas w rzeczywistości wprowadzona. Brałem sobie jakiś rzeczywisty dzień z przeszłości i sprawdzałem, czy wyniki w symulatorze oddają ten dzień, tak jeden do jednego. Najpierw na poziomie bardzo ogólnym. Czy, na przykład czy średnia czasu dojazdu mediana czasu dojazdu były podobne do rzeczywistości. Czy podobny procent zleceń nie został obsłużony. Potem schodziłem głębiej. Czy na przykład z grubsza te same zlecenia zostały zrealizowane, czy na przykład nie było tak, że symulator dobrze zachowywał się w godzinach szczytu, a zupełnie nie odzwierciedla rzeczywistości w nocy. Oczywiście, to nie jest tak że wymagam od symulatora żeby zrobił to wszystko jeden do jednego, tak jak to się działo w rzeczywistości, i pewne odstępstwa są dopuszczalne, bo jest to symulator, natomiast jeśli system zachodzącym zupełnie inaczej, to było wiadomo że ten symulator dobrze nie działa. No i na tym taka wstępna kalibracja na przyszłości, kiedy jeszcze w ogóle nie testujemy nowych hipotez, to był ten pierwszy etap.
Wizualizowałem to na mapach i patrzyłem, czy układ, czy to co widzę na tej mapie zachowuje się logicznie. Jeśli nie, to starałem się to zmienić. Później kiedy już robiliśmy testy A/B, w zasadzie procedura była bardzo podobna, natomiast badałem też stabilność systemu ze względu na poszczególne parametry. Czyli jeżeli sprawdzałem co się stanie jeżeli lekko lub bardziej zmienię jakiś parametr, czy to mocno wpływa na wynik, czy nie. Jeśli ta wrażliwość na dany parametr jest niewielka, to prawdopodobnie nie ma w ogóle sensu grzebać przy tym konkretnym parametrze, a on nie jest tak istotny dla wyniku. jeśli jest bardzo duża, to trzeba się temu przyjrzeć, popatrzeć na jakieś poszczególne przypadki. I tak to wyglądało, czyli dużo takiego przyglądania się i próbowania, dopasowania tego symulatora do rzeczywistości w taki sposób żeby było jak najbliżej, ale nie takiego jak często analitycy starają się, czyli tak, znajdę coś co minimalizuje jakiś średni błąd, czyli tylko coś, co jak najlepiej oddaje rzeczywistość w taki sposób czysto fizyczny.
Brzmi to ciekawie. Czy dużo właśnie też intuicji, empirycznego sprawdzania, dużo eksperymentowania. A powiedz coś więcej o metrykach sukcesu. Jakie je macie, i jak symulatory pomogły je sprawdzić.
Tak jak wcześniej mówiłem, my tak naprawdę mamy trzy kwestie, które chcemy optymalizować, więc do każdej z nich trzeba było dopasować metrykę sukcesu. Pierwsza kwestia, to czas dojazdu, i tutaj dla mnie naturalną kwestią była po prostu mediana czasu dojazdu. Mediana, nie średnia, bo chciałem mieć wskaźnik który jest odporny na outlayery. Mediana jest, średnia absolutnie nie. Druga kwestia to jak wiele zleceń jesteśmy w stanie obsłużyć prawidłowo i to jest wskaźnik, który my nazywamy reliability ratio, czyli tak naprawdę stosunek zleceń obsłużonych do całego popytu który się pojawił, i trzecia kwestia to jakość dostarczanych taksówek.
I tutaj, ponieważ każdy z naszych taksówkarzy ma przyznawany scoring, który może się zmieniać w czasie, w zależności od tego jak jest oceniany przez klientów, jak my oceniamy jego pracę, więc jako tę metrykę tej jakości przyjąłem średni scoring, ale średnia nie po taksówkarzach, bo to jest stałe tylko po wydawanych zleceniach. Czyli, wysoki średni scoring oznacza, że zlecenie idą głównie do tych lepszych w sensie scoringu taksówkarzy. I to były trzy metryki.
No i, co się udało mam zrobić? Ja przyjąłem takie pierwsze założenie, jakoś trzeba sobie radzić z problemami wielokryterialnymi. Albo można stworzyć jakiś syntetyczny wskaźnik, który zawiera wiele kryteriów, albo przyjąć jakieś założenie. Nasze podejście było takie, że uważamy że jakość naszych kierowców obecnie jest odpowiednia, czyli warunkiem brzegowym jest nie pogorszenie średniego scoringu, natomiast walczymy o zmniejszenie czasu dojazdu i zwiększenie efektywności zaspokajania popytu i oba te czynniki są na równym poziomie.
I co osiągnęliśmy, w jakim punkcie jesteśmy teraz? Teraz jesteśmy w takim punkcie, że w stosunku do tego co było przed symulatorem, średni scoring podrósł o 0,4 %, a mediana czasu dojazdu spadła o 4,5% natomiast wydawanych zleceń wzrosła o 3%. I co to oznacza? To nie są jakieś bardzo duże wartości, natomiast choćby ten ostatni wskaźnik mówi tyle, że firma z samych tych poprawek w algorytmie zarabiała o 3% więcej.
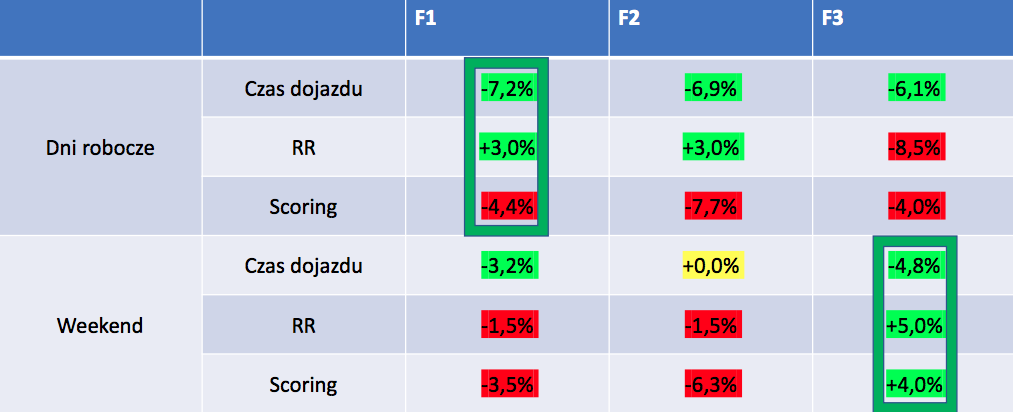
Widać, że wynik jest trochę lepszy. To tak sumarycznie rzecz biorąc. Natomiast nie ma dużego przyrostu, jakiego biznes zwykle oczekuje, ale wiem że masz plany znacznie bardziej ambitne. Powiedz coś więcej. Co chciałbyś osiągnąć dzięki temu symulatorowi.
Może najpierw, ponieważ to pytanie, dlaczego tak mało wszyscy zdają mi dość regularnie, więc może najpierw właśnie wyjaśnię dlaczego, dlaczego tak mało. A może najpierw nawet zacznę od czegoś innego. Jeszcze dwa miesiące temu te wzrosty były kilkunastoprocentowe, natomiast teraz ta różnica spadła i ma to pewne takie bardzo logiczne przyczyny.
Było znacznie lepiej, ale nasza sytuacja jako firmy znacząco się zmieniła. Nasza firma niedawno wygrała przetargi na obsługę Dworca Centralnego i Dworca Zachodniego w Warszawie oraz lotniska Chopina, co spowodowało kompletną zmianę sytuacji. Mamy zupełnie inną strukturę zleceń, niż mieliśmy jeszcze jakiś czas temu i nagle się okazało, że ja muszę się z tym rozwiązaniem cofnąć, bo to co było optymalne przed tą zmianą popytu przestaje być optymalne teraz. I to jest jeden z takich powodów. Drugi powód to tak naprawdę taki pierwotny powód dla którego te wzrosty nie są takie duże. Zanim zacząłem w nim grzebać, mieliśmy już całkiem dobry algorytm.
Naprawdę bardzo skutecznie wydający zlecenia. Więc tutaj ta przestrzeń do poprawy oczywiście jest, ale nie jest taka, jaka byłaby gdybyśmy na przykład mieli algorytm taki klasyczny, zachłanny, czyli wysyła zawsze najbliższą taksówkę. No i trzeci powód dla którego ten przyrost nie jest taki duży. Testowanie tego, co wyjdzie w symulatorze w takich klasycznych A/B testach musi trwać. My musimy pamiętać, że testujemy na żywym organizmie i jeśli by się zdarzyło tak właśnie, o czym wcześniej ty mówiłeś, że taksówkarz, że nasz symulator pokazał że to będzie dobrze działało, natomiast rzeczywistość tego nie odzwierciedla, to stracilibyśmy klientów, stracilibyśmy pewnie taksówkarzy, którzy nie dostawali by zleceń i ogólnie miałoby to bardzo zły impact na nasz biznes, w związku z tym musimy te testy robić powoli i ostrożnie, więc testowanie musi trwać.
Dlatego ten proces optymalizacji nie idzie tak szybko, jak ja bym chciał, ciągle się nie zatrzymujemy. Pytałeś też o to, do czego dążymy. No, ja mam takie założenie, że w ciągu roku jest jak najbardziej realne i do tego dążę. Chcę skrócić czas dojazdu o 15% i zmniejszyć liczbę niewydanych zleceń o 20%. To jest, absolutnie widzę że jest że jest w zasięgu, Wymaga trochę zmiany podejścia i jeszcze większego skomplikowania symulacji, bo my właśnie rozpoczynamy pracę nad takim mechanizmem dynamicznym, który ma się dostosowywać, i można powiedzieć tutaj, że inteligentnie, czyli wreszcie padł buzzword sztuczna inteligencja, do obecnych warunków.
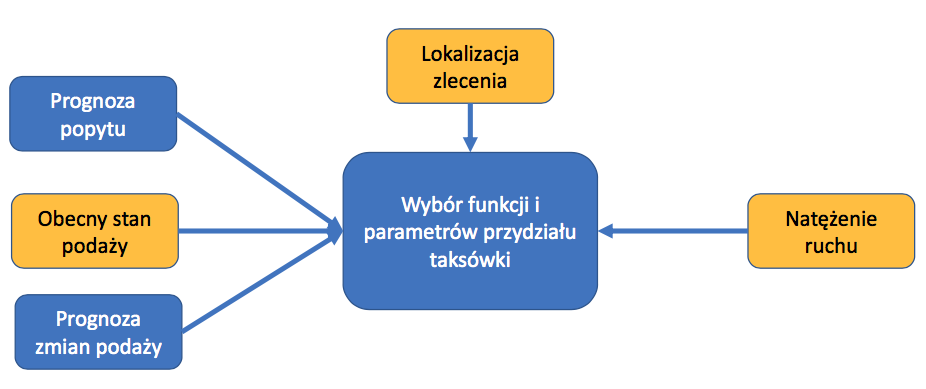
Czyli do tego, ile jest dostępnych taksówek, jaka jest intensywność zleceń, jaka jest przejezdność miasta, czyli na przykładzie: jeśli my mamy wieczór, po mieście się dobrze jeździ, mamy sporo wolnych taksówek, to pewnie optymalnym rozwiązaniem jest wysłać klientowi lepszy samochód, nawet jeżeli poczeka na niego siedem minut zamiast sześciu. Klient wtedy będzie bardziej zadowolony. Natomiast w szczycie, kiedy miasto jest sparaliżowane, wolimy nie kombinować tylko po prostu wysłać najbliższą taksówkę, bo różnica w czasie dojazdu będzie dość dużo. No i oczywiście tutaj nie chodzi o mechaniczne stwierdzenie, że szczyt jest codziennie, od poniedziałku do piątku między 7:30 a 9:30, tylko żeby system sam na podstawie stanu popytu, podaży i przejezdności rozpoznawał, jaką funkcję w danym momencie należy zastosować. Czyli, żeby była taka real time’owa optymalizacja parametrów tego algorytmu, i tutaj widzę bardzo duży potencjał wzrostowy.
Zmienię teraz trochę temat, bo wydaje mi się że to jest pytanie bardzo ważne dla osób które nas słuchają. Jak myślisz, w jakich biznesach zupełnie z innej branży nie związanej z taksówkami, zastosowanie symulatora może się opłacać?
Może w ten sposób. Wszędzie tam, gdzie mamy do czynienia z fizycznymi zjawiskami. Najbliżej tego naszego biznesu jest cała logistyka, czyli wszędzie tam gdzie przewozimy towary, lub ludzi z miejsca na miejsce. Jak najbardziej metody symulacyjne są szeroko aplikowalne. Wszelkie procesy produkcyjne. Tam też możemy możemy to optymalizować przez symulowanie co się stanie jeśli na przykład zmienimy układ taśmy produkcyjnej w taki i taki sposób.
A może bardziej szeroko w tej starej i ekonometrii która miała swój podział zanim ekonometria zmieniła się w machine learning, a potem sztuczną inteligencję, mieliśmy taki olbrzymi dział, który się nazywał badania operacyjne. I w zasadzie tam, gdzie kiedyś stosowano badania operacyjne, tam często najlepszym podejściem będzie właśnie symulacja.
Myślę że teraz nas może słuchać osoba, która zbiera rozważa: fajnie brzmi mnie ten symulator, być może ja muszę go zastosować w praktyce, tylko pytanie: jak dużo inwestycji to potrzebuję, jak duże zasoby, ile czasu to zajmie. Powiedz tak trochę więcej w liczbach, ile osób realizowało ten symulator i ile czasowo tak mniej więcej to zajęło.
Mhm, i tutaj pewnie Cię zdziwię, bo my jesteśmy dość małą firmą, więc ten symulator budowałem w zasadzie sam. Konsultując z kilkoma osobami, ale większość tej takiej pracy to jednak była praca samodzielna. Zbudowałem ten symulator przez czas około trzech miesięcy, ale ponieważ mam też mnóstwo innych zadań w firmie, więc mogę powiedzieć, że taki realny czas to było pewnie koło trzydziestu dni roboczych. Do stworzenia i takiej wstępnej kalibracji. Czyli takiego momentu, gdzie mam symulator który dobrze odzwierciedla przeszłość, czyli wiem że dla tej funkcji która była wcześniej działa dobrze. No i później, można już go zacząć używać i wtedy praca nad nim jest już ciągła, czyli szukam jakiegoś rozwiązania wprowadzam testy A/B, sprawdzam wyniki, koryguje symulator i tak dalej, i tak dalej, no i to oczywiście może trwać w nieskończoność. Ale te trzydzieści dni jednej osoby w zupełności wystarczyło żeby zbudować ten symulator.
To brzmi bardzo ciekawie, tym bardziej, że jak w sumie kiedyś wspomniałeś na naszej rozmowie jeszcze przed podcastem, że uważasz ten symulator za takie know-how dla firmy, i że to jest dość mocna przewaga konkurencyjna. I to po raz kolejny potwierdza, że niekoniecznie zawsze chodzi tylko o ilość ludzi zatrudnionych, czy jakieś tam większe zasoby umiejętności, i tak dalej.
Chodzi o to, żeby mieć dobry pomysł i zrozumienie problemu, do czego tak naprawdę dążymy. I właśnie stąd też trochę chcę dodać kolejne pytanie. Trochę bardziej uogólnione, ale dla osób powiedzmy decyzyjnych, które mogą nas teraz słuchać. Jakich porad możesz udzielić, jeżeli ktoś zastanawia się nad rozpoczęciem używania uczenia maszynowego, lub tak zwanej sztucznej inteligencji? Na co należy uważać, i jak to robi tak zwaną głową?
Ja najpierw może powiem czego nie radzę robić. Widzę taki ogólny trend rynkowy, który bym tak nazwał: zrób sobie sam Data Science. Czyli, powstaje coraz więcej oprogramowania, które umożliwia włożenie jakichś danych, określenie jaki ma być efekt i naciśnięcie naciśnięcie guzika i ten software sam wybierze model, sam przeliczy, stworzy prognozę, klasyfikację, czy jakiś inny wynik i gotowe. Nie potrzebujesz żadnego Data Scientist’a żeby sobie samemu zrobić machine learning. Nie musisz mieć żadnego pojęcia o tym, jak działa ta metoda którą właśnie zastosowałeś.
I to jest pewnie bardzo kuszący scenariusz dla wielu osób, które nie chcą wydawać pieniędzy na zatrudnienie analityka. Tak naprawdę software mimo, że też nie jest tani, to będzie zawsze tańszy od analityka. Natomiast ja bym to porównał do takiego samodzielnego zrobienia sobie w domu instalacji elektrycznej. To jest niby proste, prawda? Trzeba kable przeciągnąć od źródła energii, do miejsc gdzie są potrzebne. I może nawet wielu z nas by się to udało, a od czasu do czasu ktoś będzie miał zwarcie, pożar i to wszystko spłonie. Podobnie jest moim zdaniem przy stosowaniu takich czarnych skrzynek.
Menedżer, który sobie pójdzie na tą łatwiejszą drogę, ryzykuje takim pożarem. To oprogramowanie może mu podpowiedzieć coś, co jest bardzo dobrze dopasowane do danych użytych do tworzenia modelu, ale kompletnie nie odzwierciedla przyszłości. No i nastąpi katastrofa. Ja nie mam zbyt dużych złudzeń. Ten trend będzie się pogłębiał. Coraz łatwiej będzie zrobić skomplikowaną analitykę przez osoby które nie do końca rozumieją co w tej czarnej skrzynce się dzieje.
Natomiast, wierzę też w to, że dopóki nie będziemy mieli takiej prawdziwej sztucznej inteligencji, to jeszcze bardzo długo lepszym wyborem będzie zatrudnić dobrego analityka, niż kupić software z wielkim czerwonym przyciskiem zrób segmentację, na przykład. I też trzeba pamiętać, że jeśli ktoś wam pokazuje tego typu system, który tak pięknie robi analitykę, to zazwyczaj realne case biznesowe są znacznie bardziej skomplikowane, niż te akademickie przykłady. Takim klasycznym akademickim przykładem jest zbiór Iris, który świetnie się nadaje do pokazywanie, jak na przykład działa algorytm k-średnich, czyli jak pogrupować, posegmentować pewne obserwacje na oddzielne klasy, ale kompletnie na tym zbiorze nie pokażemy co się może zdarzyć jeśli zastosujemy algorytm k-średnich, jeśli poszczególne zbiory na które mamy segmentować są w rzeczywistości niewypukłe.
I albo jeżeli wiemy, że mamy posegmentować na dwa segmenty, ale te dwa segmenty są mocno nierówne, na przykład jeden stanowi tylko 1% obserwacji.
I wtedy takie metody jak algorytm k-średnich, który świetnie działa na spreparowanych danych, praktycznie może nie zadziałać. Wtedy człowiek, który nie rozumie idei tych metod jest bezradny. No i, tak sobie pogadałem, pogadałem można to sprowadzić do prostej rady – zatrudnieniajcie specjalistów od tej dziedziny. Nie liczcie na to, że dobrze zrobiony automat zastąpi analityka. Te oprogramowania są bardzo przydatne, ale właśnie dla analityków. One mogą zwiększyć efektywność analityka, bo on będzie w stanie używając tych oprogramowanie pracować znacznie szybciej, ale nie zastąpią go. To trochę takie, ja wierzę w to, że dobra siekiera zwiększa efektywność drwala i dobre oprogramowanie pomaga data scientist’owi, ale sama siekiera drzewa nie zetnie.
Bardzo dobra analogia. To jeszcze na koniec zadam pytanie trochę bardziej takie globalne, bardzo ciekawy jestem co na to powiesz. Jak myślisz, jak przyszłość nas, czyli ludzi może wyglądać za, powiedzmy tak piętnaście lat, żeby trochę dalej niż pięć. Bo postęp technologii naprawdę jest coraz bardziej szybszy, coraz bardziej odważne i coraz bardziej się wdrażają w rzeczywistość. Czy masz jakieś przemyślenia na ten temat? Jeżeli tak, to podziel się tym.
Powiedziałbym tak. To znaczy, w takim krótkim okresie, bo piętnaście lat, to ja wiem że technologia bardzo przyspiesza, ale dla mnie to ciągle jest krótki okres. Na pewno wydarzy się to, że maszyny będą lepiej rozpoznawały obraz i mowę, będą lepiej rozpoznawały kontekst, będziemy mieli coraz więcej interfejsów dźwiękowych, botów, tego co jeszcze niedawno było kompletnie poza zasięgiem. Czyli będziemy w stanie dobrze zautomatyzować te czynności, które są mechanicznie powtarzalne.
Pewnie o krok dalej, jak się zastanowimy to też jest mechanizm dość powtarzalny mechanicznie, ale samochody autonomiczne ułatwią nam życie. Mnóstwo innych procesów będzie uproszczonych i zoptymalizowanych. To będzie miało społeczne konsekwencje, bo wiele zawodów może stracić rację bytu, albo stać się rzadkimi. I to takich bardzo różnych, jak kontroler lotów, bo automat może to robić równie dobrze jak człowiek. Zawiadowca stacji, co jest jakby podobnym, ale też kontroler biletów w komunikacji miejskiej może być zastąpiony przez automat, albo inny sposób pobierania automatycznie opłaty za transport.
Na pewno wykrywanie mnóstwa chorób przez automaty może sprawić, że będziemy żyć dłużej i będziemy rzadziej chorować. Natomiast ja myślę, że zaczniemy się w pewnym momencie, dawać jeśli już się nie boimy, do czego to wszystko doprowadzi. Ja też mam takie obawy, bo mam taką teorię, że właśnie rozwój sztucznej inteligencji doprowadzi do zagłady ludzkości. To znaczy, to nie jest tylko moja teoria, bo już w dziewiętnastym wieku niejaki Butler wymyślił coś takiego, że ludzie stworzą sztuczną inteligencję, która niszczy ludzkość.
Później ten koncept pięknie powtórzył Frank Herbert w swojej twoim cyklu “Diuna”. To jest cykl science fiction. Dla tych, którzy nie czytali, zachęcam. To lata sześćdziesiąte ubiegłego wieku, ale nadal bardzo ciekawe i bardzo dużo można znaleźć analogii do tego w jaki sposób świat się przekształca. Tam, u Herberta ludzie w pewnym momencie zniszczyli wszelkie maszyny myślącę i w ten sposób uniknąć samo zakłady i nałożyli bardzo twardy zakaz na budowanie jakichkolwiek maszyn myślących.
Ja myślę, że my z jakiegoś powodu przyjmujemy trochę nieuprawnione założenie, że ta sztuczna inteligencja którą my w końcu rzeczywiście wyhodujemy, będzie miała dobre zamiary wobec nas. No bo przecież mają stworzyliśmy. Ale w zasadzie nie widzę powodu dla którego miałoby tak być. Dla którego nie miałaby mieć takiej klasycznej powiedzmy, mentalności dzikusa z epoki kamienia łupanego, który będzie tylko patrzył jak tej ludzkości dać po głowie maczugą i przestać się nią przejmować. Więc zastanawiam się nad tym, czy idziemy w dobrym kierunku, chociaż, jakby nie można absolutnie negować tego, że teraz w krótkim okresie wszelki rozwój tych metod, które ogólnie nazywamy sztuczną inteligencją ułatwia nam życie i będzie ułatwiał jeszcze przez jakiś czas.
Bardzo ciekawa odpowiedź. Dziękuję Ci za to. I też bardzo dziękuję za to, że znalazłeś czas, żeby porozmawiać dzisiaj i powiedzieć wiele ciekawych wskazówek. Myślę, że dla wielu osób to będzie bardzo wartościowe, w szczególności w tych przypadkach, gdzie takie standardowe rozwiązanie albo ciężko zastosować, albo w ogóle się nie da, to taki symulator może być inspiracją, więc bardzo Tomek Ci dziękuję za Twój czas.
Tomek: Dziękuję również.
Nagrywam już ten odcinek, kiedy DataWorkshop Tour się skończył. To była bardzo ciekawa przygoda. Dość mocno wyczerpująca. Spotkałem wielu słuchaczy BiznesMyśli, co mnie bardzo cieszy. Czasem czułem się mniej komfortowo dlatego, że wiem, że mój głos dla osoby, która mnie słucha jest bardzo znany, a odwrotnie niekoniecznie, ale wydaje mi się, że przeprowadziliśmy bardzo fajne dyskusje. Też z przyjemnością pytałem: dlaczego słuchasz, czego ciekawego się dowiedziałeś. Dla osób, które nie wiedzą o co chodzi z tym Tour’em, w skrócie powiem, że we wrześniu, przez cały wrzesień, pierwszego września zaczęliśmy, dwudziestego dziewiątego września skończyliśmy. Jeździliśmy po całej Polsce. Odwiedziliśmy sześć miast.






Ponad dwieście trzydzieści osób wzięło udział w tych szkoleniach. To były takie jednodniowe szkolenia. Wprowadzenie do uczenia maszynowego. Bardzo dużo różnych firm, też znanych i mniej znanych wzięło udział. Też było trochę takiego przemieszczania się po Polsce uczestników, bo czasem na przykład ludzie dojeżdżali z Łodzi do Warszawy, to jest takie naturalne. Ale czasem było tak, że zabrakło miejsc na przykład w Krakowie, to ktoś dojeżdżał z Krakowa do Wrocławia, albo z Wrocławia do Poznania. Więc było ciekawie.

To był bardzo ciekawy eksperyment, który mnie osobiście wiele nauczył, i też mogę od razu powiedzieć, na ile ludzie, mimo tego, że mieszkają w jednym kraju, jak oni się różnią. I to we wszystkim. Zaczynając od takich prostych rzeczy, jak jedzenie. Może to nie jest aż takie proste, ale powiedzmy. Też w jaki sposób pochłaniają wiedzę, jak bardzo są otwarci na wyzwania, na ile są bardziej poukładani procesowo, i odwrotnie, a taka jeszcze inna rzecz, że nawet nie tylko chodzi o miasta, tylko o to gdzie osoby pracują, na przykład: Warszawa była dla mnie dużą niespodzianką, bo mieliśmy dwa szkolenia. W piątek i w sobotę. W piątek wszystko było kupowane na faktury, w sobotę bardziej na rachunek, czyli osoby fizyczne to kupowały. I te dwie grupy były dość różne, nawet bardzo różne. Więc miałem taki fajny temat do przemyśleń. To jest ciekawe.
Podsumowując, dostałem dużo pytań czy będzie powtórka. Nad tym się zastanawiam. Powiem szczerze, że to było mega wyczerpujące. Ja osiągnąłem ten cel, który chciałem osiągnąć. To wszystko, co było obiecane zostało dostarczone. Feedback jest mega pozytywny. Ale też dla mnie było ważne, żeby zacząć inspirować ludzi, którzy maksymalnie marzą o tym, żeby wybudować swój dom. Myśleć trochę inaczej i widzieć co się dzieje dookoła. Myślę, żę przynajmniej częsciowo udało się ten cel osiągnąć.
No to tyle na dzisiaj. Dziękuję Ci bardzo za Twój czas, za Twoją chęć wysłuchania podcastu BiznesMyśli. Mam taką prośbę jeszcze na koniec. Powiedz co najmniej jednej osobie o istnieniu tego podcastu, i życzę Tobie wszystkiego najlepszego, co tylko może się wydarzyć w Twoim życiu. Cześć! Do usłyszenia!
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.



Jeden Komentarz
Tomasz
A tutaj inny przykład, jak symulacja pozwala na przyspieszenie uczenia maszynowego. https://www.youtube.com/watch?v=txHQoYKaSUk To co w rzeczywistości zajmuje sekundy, w symulacji trwa milisekundy.