
Sztuczna inteligencja zmienia szukanie odpowiedzi

Wprowadzenie
Vladimir: Cześć Piotrek, powiedz trochę więcej o sobie, czym się zajmujesz, gdzie mieszkasz?
Piotr: Cześć, ja się nazywam Piotr Rybak, mieszkam w Warszawie i zajmuję się szeroko pojętym rozumieniem języka, tak zwanym Natural Language Processing (NLP). W tym się specjalizuję, ale też zajmuję się przy okazji całym nurtem uczenia maszynowego, trochę wizją komputerową, kiedyś też analizami sygnałów – bardzo różnymi rzeczami. Co się trafiało, tym też się zajmowałem.
Natomiast główny mój fokus to jest właśnie rozumienie języka, przetwarzanie języka, budowanie tak naprawdę produktów, które wykorzystują w jakiś sposób ten komponent uczenia maszynowego, żeby rozumieć język.
Ciekawa książka
Vladimir: Właśnie, o tym dzisiaj porozmawiamy. Masz bardzo fajne doświadczenie, takie bardzo praktyczne, takie sobie najbardziej lubię. Ale tak na rozgrzewkę, powiedz, jaką fajną książkę ostatnio przeczytałeś i dlaczego warto ją przeczytać?
Piotr: To jest bardzo problematyczne pytanie. Szczerze, nie wiem. Chyba od wielu lat nie czytam już książek. Jakoś mam wrażenie, że książki przestały być dobrym medium, jeżeli chodzi o naukę, o przekazywanie wiedzy.
Kiedyś rzeczywiście dużo czytałem – bardzo dużo beletrystyki, potem też jakichś podręczników i tak dalej. Ale w sumie mam wrażenie, że w tej chwili cała branża rozwija się na tyle szybko i to zarówno, jeżeli chodzi o jakieś uczenie maszynowe, ale nie wiem – budowanie produktów czy cokolwiek innego, startupów – to się wszystko rozwija na tyle szybko, że najwięcej informacji jest na Twitterze, na Discordach. Gdzieś ludzie napiszą jakiś losowy komentarz i tam jest wiedza. I to trzeba śledzić. Tego na przykład czytam na bieżąco. Polecam przykładowo Hacker News –
Polecam przykładowo Hacker News – to taka super stronka z newsami startupowymi, która ma niesamowite komentarze. Są tam najbardziej znane osoby na świecie, znani startupowcy. Jeżeli jest pytanie o MongoDB i ktoś narzeka, że coś w MongoDB jest beznadziejne, to nagle komentarz pisze twórca MongoDB i odpisuje merytorycznie, że jednak nie masz racji, bo to jest tak i tak. Mam wrażenie, że tam jest aktualnie najwięcej wiedzy i to należy czytać.
Vladimir: Czyli to, co mówisz, to informacja teraz szybko się starzeje, a a propos Hacker News – to też ciekawostka, że ta stronka wygląda jak coś takiego starszego, ale faktycznie zawiera najbardziej świeże rzeczy, plus ta merytoryczność, o której wspomniałeś, tam jest.
Dobrze, słuchaj, to zanurzajmy się w tematy dzisiejszego odcinka. Masz dużo doświadczenia z NLP, w szczególności w tzw. zadaniach zdanie-odpowiedź, czyli question answering. Zwykle jest tak, że ktoś, kto siedzi w tym bardzo długo, zapomina, jak to jest czegoś nie wiedzieć, i mówiąc niby prostymi słowami do kogoś innego, to nie zawsze jest takie oczywiste. I chciałbym, żeby osoba, która w tych tematach nie siedziała, po dzisiejszej naszej rozmowie zrozumiała wiele, a również osoby, które w tym temacie siedzą, też usłyszały przydatne informacje.
Piotr: Jest to dość trudne zadanie, ale myślę, że dam radę.
Czym jest question answering?
Vladimir: Zacznijmy od początku, jeżeli chodzi o właśnie question answering. O co chodzi z tym zagadnieniem, jak możesz to wyjaśnić tak po ludzku, dlaczego to zagadnienie może być pomocne, wartościowe np. dla biznesu?
Piotr: Jeżeli chodzi o question answering, to jest to bardzo, bardzo szeroka dziedzina przetwarzania i rozumienia języka naturalnego. I możemy sobie wyobrazić, dlaczego jest szeroka, podam kilka przykładów.
Oczywiście możemy się spytać, kiedy była bitwa pod Grunwaldem?
Vladimir: To sobie wyobrażamy jako standardowe odpowiadanie na pytanie. Była wtedy i wtedy. Ale ktoś może zadać pytanie, jak będzie po angielsku „biznes myśli”? Niby to jest question answering, ale tak naprawdę to jest tłumaczenie maszynowe.
Ktoś może zapytać, ile to jest 2+2. Niby to jest question answering, niby ktoś sformułował to jako pytanie, ale tak naprawdę to nie jest pytanie, to jest użycie kalkulatora.
I jakby sam question answering zajmuje się właśnie bardzo, bardzo wieloma rzeczami, bardzo wieloma typami. Ja się zajmuję, w szczególności tutaj podczas tej rozmowy, chyba skupiłem się na takim dosyć ograniczonym rozumieniu question answeringu jako wyszukiwaniu odpowiedzi.
Question answering jako lepszy search
Piotr: Znaczy, założyłbym, że mamy jakąś bazę wiedzy, np. dokumenty w firmie, i teraz mamy użytkownika, który chce się czegoś dowiedzieć, ale zamiast przeszukiwać te dokumenty ręcznie, chciałby zadać pytanie: ile dni urlopu przysługuje pracownikowi, który pracuje tutaj od roku?
To jest konkretna informacja, która najprawdopodobniej jest w jakichś dokumentach kadrowych, HR-owych, tylko zamiast szukać tych informacji ręcznie, ja bym chciał tę informację, tę odpowiedź znaleźć.
I w tym sensie odpowiadanie na pytania to jest tak naprawdę taki trochę lepszy search, trochę lepsza wyszukiwarka. Bo nie tylko znajdujemy dokumenty, w których ta odpowiedź jest, czy jakiś paragraf, w którym ta odpowiedź się znajduje. To jest pierwszy krok, ale drugi krok to jest jeszcze wyciągnięcie tej odpowiedzi i przedstawienie jej w jakiejś takiej bardziej naturalnej formie, czyli po prostu podanie informacji: 20 dni albo 26 dni, zamiast zdania, że tutaj jest dokument.
Przydatność question answeringu
Piotr: Czemu to jest przydatne? To jest analogicznie przydatne, jak Google jest przydatny. Mamy mnóstwo informacji, potrzebujemy informacji. W tym samym sensie po prostu każdy biznes żyje na informacjach w dzisiejszym świecie i tych informacji szuka podczas codziennej pracy.
Co chwilę tak naprawdę zadajemy sobie jakieś pytania, czy jako programiści – jakie argumenty ma dana funkcja, czy jak coś zrobić. Wtedy używamy często tego Google’a, wyszukujemy, znajdujemy taką stronkę Stack Overflow, gdzie ktoś już zadał to pytanie i patrzymy, jaka jest odpowiedź.
Ale oczywiście w każdej innej branży jest dokładnie to samo i niektóre te informacje są publicznie dostępne, jak właśnie w Google, a niektóre oczywiście są zamknięte w ramach naszych organizacji, w ramach naszych firm, bo mamy jakieś procedury, standardy i informacje wewnątrzfirmowe. Też musimy dobrze wyszukiwać te informacje i prezentować je, czy to naszym pracownikom, klientom, czy użytkownikom strony internetowej.
Stack Overflow a ChatGPT
Vladimir: Powiedziałeś, że to jest taka wyszukiwarka, tylko lepsza. Myślę, że Stack Overflow może nam się teraz przydać jako przykład.
Wcześniej, jak ktoś potrzebował napisać kod i coś mu nie działało albo chciał coś nowego stworzyć, to wpisywał zapytanie do Google, trafiał zwykle na Stack Overflow, patrzył na rozwiązania, kopiował, wklejał, coś zmieniał i tak to działało. Był nawet taki żart – Stack Overflow Driven Development.


Natomiast kiedy pojawił się ChatGPT, Stack Overflow zaczął być rzadziej używany.
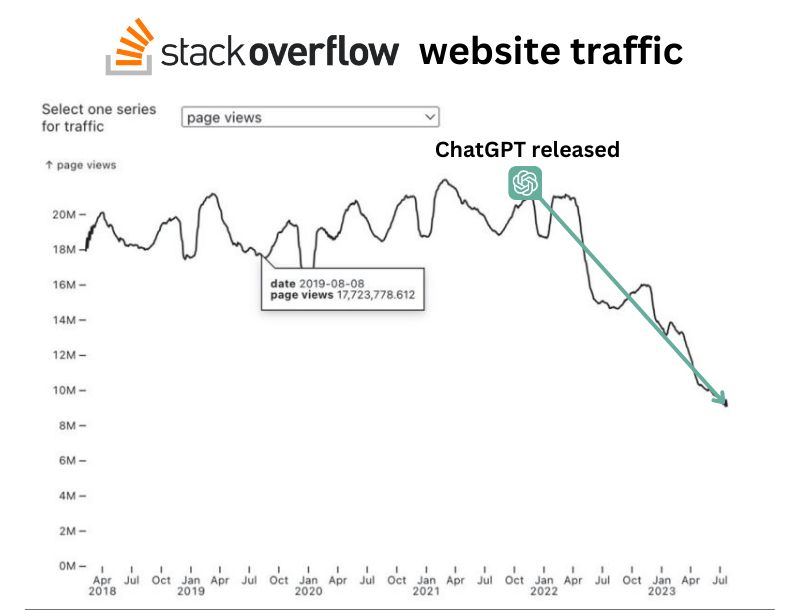
Zresztą, jak teraz nagrywamy, to już jest oficjalny news – ChatGPT, czyli OpenAI, zaczyna formalnie współpracować ze Stack Overflow. Wcześniej były tylko pogłoski, że parsują sobie te dane, a teraz to już formalna współpraca. Pojawiały się nawet śmieszne propozycje nazw, jak GPT Overflow, ale oficjalnie nazywa się to Overflow AI.

Idea polega na tym, że teraz już nie musisz najpierw szukać w Google, analizować semantycznie wyników, tylko od razu wpisujesz, co chcesz i dostajesz odpowiedź. Wszystko sprowadza się do tego, że jako ludzie szybciej uzyskujemy potrzebne informacje.
Ograniczenia ChatGPT
Vladimir: Chociaż trzeba przyznać, że nie zawsze to działa. Wczoraj miałem wyzwanie z Kubernetesem, bo po kolejnej aktualizacji rozsypały mi się rzeczy. Kopiowałem błędy wszędzie – do Bardy, ChatGPT, Perplexity, Llamy – coś podpowiadały, ale ostatecznie musiałem sam pogrzebać głębiej w logach i rozwiązać problem. Choć czasem faktycznie pomaga.
Podsumowując, teraz mamy mniej kroków i zwykle, choć nie zawsze, dostajemy precyzyjną odpowiedź na swoje pytania, prawda?
Piotr: Tak, to jest założenie. Znaczy założenie jest takie, że odpowiedź gdzieś jest, przynajmniej w tym rozumieniu question answeringu, którym ja się zajmuję i który dla mnie jest obecnie najbardziej rozwiązaną częścią tego zagadnienia.
Chodzi o to, że gdzieś w bazie dokumentów jest odpowiedź i chcemy ją wyciągnąć w dobrej formie. W przypadku tego błędu z Kubernetesem, być może nikt nigdy nie rozwiązał tego problemu, w sensie nie ma tej informacji w żadnym dokumencie – nikt nie zadał tego pytania na Stack Overflow, nie ma tego w dokumentacji ani w zgłoszeniach na GitHubie. Więc to jest coś, co jest nierozwiązywalne w takim standardowym question answeringu.
Prawdopodobnie obecnie w ogóle nie jest to sensownie rozwiązywalne. Można liczyć, że kolejna wersja ChatGPT przeanalizuje kod źródłowy Kubernetes i wymyśli, z czego może wynikać błąd, ale jeszcze nie jesteśmy na tym etapie.
To, co działa dobrze, to znalezienie informacji, która już gdzieś jest i być może przetworzenie jej w bardziej zrozumiały sposób, tak żeby łatwiej nam było to przeczytać.
Vladimir: Masz rację, bo to była świeża aktualizacja, więc dopiero te błędy zaczęły się pojawiać i ludzie próbują to rozwiązać i gdzieś zgłosić. Dopiero później informacja będzie gdzieś zarejestrowana.
Paradoks odpowiedzialności za rozwiązywanie problemów
Vladimir: Tylko problem polega na tym, że ty jako osoba, która jesteś odpowiedzialna za to, musisz to rozwiązać. Więc to jest taki trochę paradoksalny stan, gdzie nadal człowiek nie ma wymówki, że nie ma jeszcze informacji, jak to rozwiązać, tylko musi coś sobie z tym zrobić.
Piotr: Jak o tym pomyślimy, to takie sytuacje nie zdarzają się aż tak często. Raczej to, co widzimy, jak mamy kanał supportowy w firmie i komuś nie działa, nie ma dostępu do jakiejś usługi. Rzadko kiedy jest sytuacja, w której on jest akurat tą pierwszą osobą w firmie, która ma ten problem.
To raczej jest tak, że już 50 innych osób napisało, że ma z tym problem i tylko człowiek z tego wsparcia IT musi po raz kolejny, 50. raz napisać „trzeba założyć ticket tutaj i tutaj”. Tak samo tutaj z tym błędem Kubernetesa, pewnie kolejne 50 osób już nie musi tego rozwiązywać samemu, tylko wystarczy, że znajdzie już to pierwsze rozwiązanie.
Rozwiązywanie powtarzających się problemów dzięki technologii
Vladimir: Właśnie, teraz dochodzimy do wniosku nr 1.
Osoba decyzyjna, osoba, która buduje takie systemy, już wie co najmniej jedną rzecz – że jeżeli chcemy rozwiązać problem, który regularnie się powtarza, to obecnie technologie pozwalają robić to całkiem dobrze.
Za chwilę też o tym porozmawiamy jak, ale mówimy, co jest możliwe.
Open domain vs closed domain w question answering
Vladimir: I teraz połączmy to z takim stwierdzeniem jak open domain, bo często pojawia się właśnie question answering w kontekście open domain albo closed domain. Gdzie jest ta definicja i jaka jest granica? Czy teraz, mówiąc o takiej wewnętrznej wyszukiwarce w firmie, to jest open domain czy to już nie do końca? Jak to definiujesz dla siebie?
Piotr: To jest trudne pytanie. Wydaje mi się, że tak jak wiele prób postawienia granicy, to zależy. Dla mnie to jest raczej kwestia historyczna względem tego, jak kiedyś się rozwiązywało systemy question answering.
To było raczej tak, że mamy jakiś dokument i zadajemy do tego dokumentu pytanie. To bym nazwał taki closed domain, to się teraz raczej nazywa reading comprehension, a open domain to jest na zasadzie, że mamy tę bazę wiedzy bardzo, bardzo dużą. Na tyle dużą, że możemy rzucić tam, w cudzysłowie, dowolne dokumenty, dowolnie dużo dokumentów, ale mamy tę bazę wiedzy.
Teraz możemy zadawać dowolne pytania o tę bazę wiedzy i w tym sensie jest to open domain. Oczywiście, też założenie jest takie, że to jest rzeczywiście open domain w znaczeniu, że to mogą być dokumenty czy to prawnicze, czy jakieś lekarskie, czy techniczne i tak dalej.
I to ma trochę znaczenie, ale raczej powiedziałbym, że rozróżnienie jest takie, czy mamy dużo tych dokumentów, czy to jest jeden dokument.
Vladimir: Dobrze. Spróbujmy teraz zrobić taki punkt odniesienia na temat technicznych możliwości, jeżeli chodzi właśnie o „open„, „nie open„, question answering, czyli pytania, odpowiedzi.
Skuteczność systemów AI w zadaniach question answering
Vladimir: Czyli nawet uprośćmy sobie zdanie, załóżmy, że mówimy o angielskim, za chwilę też porozmawiamy o języku polskim. Gdzie jesteśmy teraz? Są różne benchmarki, ale chciałbym, żebyśmy to jakoś oszacowali bardziej tak po ludzku. Załóżmy, że jest ocena od 0 do 10 – 0 totalnie nie umiemy, 10 idealnie trafiamy zawsze w to, co trzeba. Załóżmy, że tych dokumentów jest nieskończenie wiele i znajdujemy dokładnie to, co trzeba, prosto, idealnie. Gdzie jesteśmy teraz? Przynajmniej może subiektywnie, to jest trochę, ale spróbujmy to oszacować, żeby osoba, która nie zna tych benchmarków po nazwach, była w stanie odnieść, co w tej chwili już jest możliwe.
Piotr: Ja bym powiedział, że to jest 9, 9,5. Jest to w miarę rozwiązany problem, a przynajmniej rozwiązany w sensie użytkowym. Też pomyślmy o tym, że jeżeli system ma, powiedzmy, skuteczność 90%, czyli odpowiada na 90% pytań, to to wciąż jest bardzo użyteczny system. W sensie bardzo fajnie coś takiego wdrożyć, nie odpowiemy na wszystkie pytania i w każdym systemie, który jest oparty o uczenie maszynowe, nigdy nie będziemy mieli 100% skuteczności, ale powyżej jakiejś skuteczności ten system już jest użyteczny.
Oczywiście ta proporcja jest różna w zależności od tego, co robimy. Jeżeli gramy w ruletkę i chcemy przewidywać, czy będzie czerwone czy czarne, to nawet jak mamy 55% skuteczności, to już możemy się wzbogacić i wygrywać miliony w kasynie. Ale jakby to było 55% skuteczności w wyszukiwaniu jakiejś informacji, to pewnie nie byłoby to bardzo wysokim wynikiem.
Ja bym powiedział, że to w tej chwili raczej są rzędu właśnie 80-90-90 parę procent. Trochę zależy od tego, jak skomplikowane są te pytania. Trochę zależy, jak bardzo różne są pytania od dokumentów. Znaczy, jeżeli pytanie jest bardzo skomplikowane i ma bardzo dużo szumów i śmieciowych informacji, które nie są istotne, a dokumenty wyglądają zupełnie inaczej, no to wtedy wiadomo, że ten model, jakiś model, system będzie miał trudność, żeby znaleźć dobre dokumenty, żeby generować dobrą odpowiedź. Im prostsze, czystsze, takie sensowniejsze są pytania i im lepszej jakości są dokumenty, to czasami to działa praktycznie zawsze i zawsze dostajemy dobrą odpowiedź.
Użyteczność systemów AI vs ludzie
Vladimir: A fajnie to rozdzieliłeś, bo ja cię zapytałem właśnie o ocenę i to jest blisko idealne, czyli bardzo blisko dziesiątki jesteśmy, ale też fajnie to rozdzieliłeś, że jest jeszcze druga miara – użyteczność. I właściwie, jeżeli chodzi o użyteczność, to jak nie mamy takiej wyszukiwarki wewnętrznej, powiedzmy w większym atelier, no to mamy ludzi. I taka Zuzia albo Jacek to też nie zawsze odpowiada na wszystkie pytania, ale nadal zwykle pytamy kogoś, więc pod tym względem i tak ten problem istnieje, czyli nie mając tych narzędzi też nie mamy zwykle, jeżeli to jest w miarę większa firma, jakieś skomplikowane procedury, rzeczy itd., to zwykle też nie ma pojedynczej osoby, która wie wszystko.
Piotr: Co ciekawe, też istnieje takie routery, że jest ta osoba, która wie, kto może wiedzieć i to też jest taka ciekawa rzecz, którą można stosować technologicznie, że masz takie routery i przekierowujesz się do pojedynczych takich modeli, agentów, jakkolwiek tam je nazwać, a oni się skupiają na którejś tam działce, na przykład ten na HR, ten na marketingu, ten tam jeszcze na urlopach itd.
Udało mi się tak w jednej firmie wpaść w cykl, że spytałem osoby A, jak coś zrobić, zostałem przekierowany do osoby B, osoba B przekierowała mnie do osoby C, osoba C do osoby A i tak naprawdę już ciężko było powiedzieć, co z tym zrobić.
Natomiast co do tej skuteczności ludzi, to też jest coś, co jest w pewnym sensie niesamowite. Czy nie wiem, na ile się zmieniła percepcja ostatnio, ale jeszcze parę lat temu było oczekiwanie takie, że ludzie są bezbłędni, a to uczenie maszynowe czy ta AI, sztuczna inteligencja, no to ona popełnia błędy, ona się myli, ona jest głupia i jest generalnie gorsza od ludzi.
I to naprawdę powodowało duże problemy w rozmowie z klientami, bo robiliśmy badania na zasadzie, trzeba było, nie wiem, klasyfikować teksty, powiedzmy, czy tekst jest z jakiejś tematyki. I wcześniej to robili ludzie, a teraz my to automatyzowaliśmy, robiąc model uczenia maszynowego. I ten model miał skuteczność 80%. No i wtedy klienci mówili: „Nie, no tragedia, 80%, o Panie, to w ogóle nas nie satysfakcjonuje, my nie jesteśmy w stanie przeżyć 20% błędów”. Tak, no tak, ale my daliśmy te same przypadki testowe wam, w sensie waszym pracownikom i oni mieli skuteczność 75%. „Nie, ale to co innego, nie, nie, nie, my nie możemy przeżyć 20% błędów”.
Błędy ludzi vs błędy maszyn
Piotr: Coś w tym jest. Nie wiem, w sensie to nie jest bardzo głupie podejście, bo rzeczywiście ludzie mylą się inaczej niż maszyny. Maszyny często się mylą w dużo głupszy sposób, więc te błędy są inne i być może te błędy są jakby bardziej problematyczne. Natomiast wciąż jest takie przekonanie, że człowiek jest stuprocentowo skuteczny i maszyna też musi być stuprocentowo skuteczna, w szczególności żeby była użyteczna.
A to zupełnie nie jest prawda. Jeżeli nawet mamy taki system do odpowiadania na pytania, który odpowiada tylko w połowie przypadków poprawnie, to to też jest super. Jeżeli wcześniej zajmowało nam na przykład godzinę, żeby znaleźć jakiś akt prawny, który opisuje jakąś sytuację prawną, no i teraz w połowie przypadków ten czas z godziny spada do 5 sekund, to wciąż oszczędzamy mnóstwo czasu. Może tylko w połowie przypadków, ale wciąż oszczędzamy mnóstwo czasu, bo każda ta rozwiązana sprawa to jest godzina do przodu.
Vladimir: Chciałem rzec coś innego, ale jak powiedziałeś, że maszyny się mylą w bardziej głupi sposób, aż się prosi, żeby jakiś leaderboard stworzyć i porównać, kto potrafi się mylić bardziej głupio – maszyny czy ludzie, bo ludzie też czasem robią różne głupie rzeczy.
Piotr: Ludzie, na przykład, jak się mylą, to często się mylą dlatego, że są rozkojarzeni. W sensie raczej nie popełniają głupich pomyłek tak po prostu, w jakiś taki jeden konkretny sposób, tylko na przykład nie chce im się, to klikną coś losowo i też tego typu błędy bardzo łatwo wychwycić.
A jak model się myli, to często się myli w głupi, ale nieoczywisty sposób, taki, że nie jesteśmy w stanie tego łatwo wykryć.

Jak posadzimy dwóch ludzi i każemy im anotować czy patrzeć na ten sam przykład, to nawet jeżeli jedna z tych osób się pomyli, to bardzo łatwo jest wykryć, że się pomyliła. Jak wytrenujemy dwa modele, to już nie jest aż takie oczywiste, że modele będą zazwyczaj w ten sam sposób skrzywione, przynajmniej w podobny sposób skrzywione, i to już wtedy nie jest oczywiste, żeby to naprawić.
Vladimir: O anotacjach gdzieś jeszcze porozmawiamy, temat pewnie rzeka, ale w tym przypadku na pewno Cię podpytam. Ale żeby skończyć tę myśl, którą zacząłem – powiedziałem tak: jaka jest ocena obecnych rozwiązań?
Powiedziałeś, że blisko dziesiątki. A teraz cofniemy się w czasie, powiedzmy 10 lat temu, może 15. I to samo pytanie, czyli jaka była wtedy dostępność rozwiązań, jeśli chodzi o ten problem question answering, od 0 do 10? Jak to oceniałbyś teraz?
Piotr: Powiedziałbym, że było dużo gorzej. Znaczy, trochę rewolucyjnych rzeczy się zmieniło i to jakby w dwóch krokach. Może delikatnie rozbiję, w jaki sposób się w ogóle tego typu systemy buduje.
Dwa kroki w budowaniu systemów question answering
Zazwyczaj składa się to z dwóch kroków. Pierwsza to jest wyszukiwarka, czyli mamy dużo dokumentów, mamy pytanie i chcemy znaleźć dokumenty, które odpowiadają na to pytanie. To jest pierwszy krok – wyszukiwanie dokumentów.
A drugie to, jak już mamy ten dokument, to jak znaleźć odpowiedź w tym dokumencie. I w obu częściach zdarzyła się tak naprawdę rewolucja, przy czym, powiedziałbym, większa rewolucja jest w tej drugiej części, w wyciąganiu informacji z dokumentu.
Tutaj w szczególności modele generatywne, takie jak large language models, czyli LLM, na przykład GPT itd., to jest coś, co zdecydowanie podniosło skuteczność tego typu systemów.
Ale w wyszukiwarkach też się trochę rzeczy zadziało. W szczególności przeszliśmy z używania takich klasycznych wyszukiwarek opartych o słowa kluczowe do wyszukiwarek właśnie opartych o sieci neuronowe. I to było, jest dla mnie cały czas zaskakujące, bo to się wydarzyło dopiero niedawno. To są ostatnie, nie wiem, 2-3 lata.
Mimo że ludzie próbowali już od dawna używać sieci neuronowych do tego, żeby wyszukiwać, to okazuje się, że te wyszukiwarki oparte o słowa kluczowe są po prostu bardzo, bardzo dobre. I one bardzo dobrze działają. Jeżeli dodamy jeszcze jakieś triki na zasadzie lematyzacji tych słów – w języku polskim jest to istotne.

Lematyzacja, czyli sprowadzenie do takiej formy podstawowej, do bezokolicznika czy do mianownika w przypadku rzeczowników. W przypadku języka polskiego jest to problematyczne, dla angielskiego nie ma to dużego znaczenia, bo tam nie ma aż takiej deklinacji.
Tak, jeżeli dodamy jakieś, nie wiem, predefiniowane listy synonimów, to tak naprawdę taka wyszukiwarka oparta o słowa kluczowe działa bardzo dobrze. I w tym sensie te systemy nadal były użyteczne już te 5, 10, 15 lat temu. Google powstał ile, 20 lat temu
Czym jest LLM?
Vladimir: Dobra, i teraz ta druga część, jeżeli chodzi o poprawę, to między innymi tam pojawi się LLM, tak zwany large language model. Nie będziemy za bardzo się skupiać na definicji, co to jest, ale chciałbym też podpytać, czym dla Ciebie jest LLM i kiedy to jest duży.
Piotr: To może dwa słowa powiem, czym jest LLM, żeby uprościć dyskusję. LLM, czyli large language model, składa się z dwóch części. Language model to jest takie bardzo proste zadanie uczenia maszynowego, gdzie mamy jakiś tekst i chcemy przewidzieć, jakie będzie kolejne słowo w tym tekście. I to jest super zadanie, bo z jednej strony mamy bardzo dużo danych do uczenia. Wystarczy ściągnąć cały internet, wziąć wszystkie możliwe książki na świecie i mamy przygotowane dane, żeby trenować taki model. Po prostu czytamy sobie i przewidujemy kolejne słowo.
A z drugiej strony jest to fajne zadanie, bo to jest takie zadanie, trochę jak właśnie question answering, które enkapsuluje wszystkie inne zadania. Jeżeli mamy zadanie klasyfikacji wydźwięku tweetów, czy tweet jest pozytywny, czy negatywny, to możemy dać tę treść tweeta, a potem napisać „ten tweet jest” i liczymy, że language model nam powie: pozytywny, negatywny, bo musi przewidzieć kolejne słowo. Jakie będzie najbardziej prawdopodobne kolejne słowo? Albo pozytywny, negatywny i która z tych słów raczej ta prawidłowa. Czy question answering też możemy rozwiązać za pomocą language modelingu.
Kiedy model językowy staje się „duży”?
Piotr: Ludzie to robili od lat i zajmowali się tym od lat, i to zawsze było w jakiś tam sposób użyteczne. Natomiast faktycznie zaczęło być super użyteczne od kiedy dodaliśmy to pierwsze „L”, czyli large. To znaczy, ludzie zauważyli, głównie tak naprawdę OpenAI zauważyło, że jeżeli będziemy skalować te modele językowe, czyli te sieci neuronowe, które właśnie przewidują to kolejne słowo, jeżeli będziemy je robić coraz większe i coraz większe, i coraz większe, to te modele będą działać coraz lepiej, coraz lepiej i coraz lepiej.
I to się wydaje banalny wniosek. No wiadomo, jak będzie większe, to będzie lepsze, ale to nie jest oczywisty wniosek. Znaczy, raczej zazwyczaj było tak, że jeżeli mieliśmy więcej danych, no to wiadomo, że model był lepszy, ale w którymś momencie ta skuteczność się wypłaszczała, już nie warto było mieć więcej danych. Albo jeżeli zwiększaliśmy model, to ok, no było lepiej, ale do pewnego momentu, potem już nie było
Skalowanie modeli językowych i ilości danych
Vladimir: Okazało się, że jeśli będziemy skalować obie te rzeczy na raz, czyli wielkość modelu i ilość danych, a obie rzeczy możemy skalować – wielkość modelu, po prostu musimy mieć więcej kart graficznych, więcej GPU, na których trenujemy ten model, no i danych też mamy bardzo dużo, bo możemy brać po prostu strony internetowe, książki itd. I w pewnym sensie mamy tych danych nieograniczenie wiele, chociaż okazuje się, że już dochodzimy do tej granicy.
To okazuje się, że jeżeli będziemy to tak skalować, to się nie wypłaszcza. Znaczy wiadomo, że za każdym razem musimy dawać na przykład 10 razy więcej danych i 10 razy większy model, ale wtedy mamy zawsze stały przyrost skuteczności. No i od pewnego momentu te modele po prostu zaczęły działać bardzo, bardzo dobrze i rzeczywiście zaczęły działać w ten sposób, w jaki zawsze ludzie teoretycznie myśleli, że by było fajnie, gdyby te modele językowe działały.
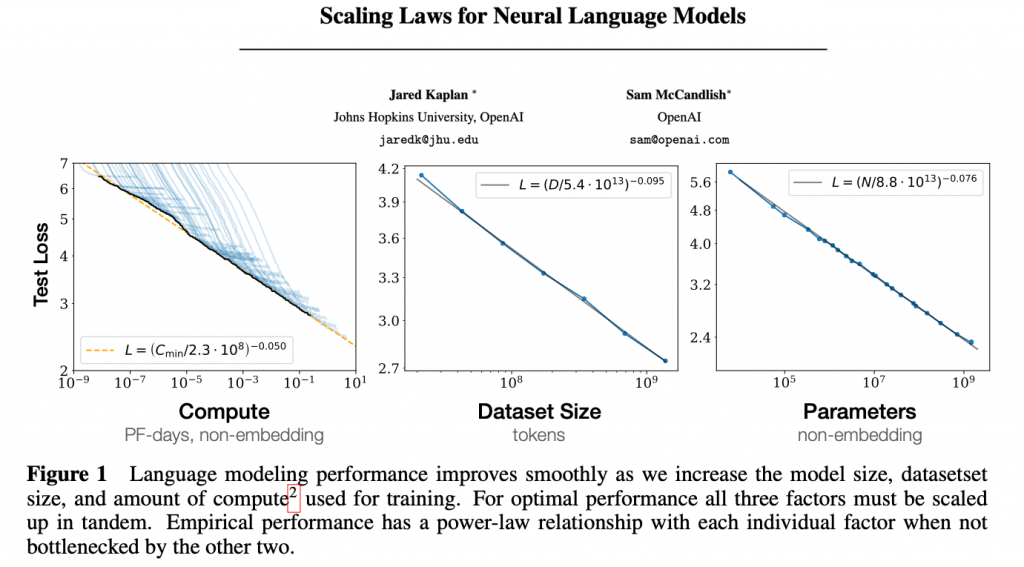
Piotr: Czyli właśnie ten przykład z tweetami, że po prostu dajemy tweet i się pytamy, jaki jest sens tego tweeta. No i to było takie machanie rękami, że to powinno działać, ale od pewnego momentu okazało się, że to faktycznie działa. No i to było w jakimś sensie niesamowite, znaczy mnie to osobiście zaskoczyło, że to faktycznie może tak działać.
Prompt engineering
No i wtedy też pojawił się cały ten nurt promptingu, tak, prompt engineeringu, no bo skoro to w ten sposób działa, no to teraz może ma znaczenie, jaką napiszemy tę początkową sekwencję i włożymy do modelu językowego. Czy najpierw damy treść tweeta, a potem napiszemy: sklasyfikuj ten tweet to…, czy najpierw napiszemy: sklasyfikuj tweet i coś dalej, i tak dalej.
I okazało się, że w tych początkowych modelach językowych ma to bardzo duże znaczenie, bo on jedyne, czego się uczył, to właśnie przewidywać kolejne słowo.
Taki znany przykład jest na przykład ze streszczeniem. Jak się czyta dużo Reddita na przykład, to często posty są pisane w ten sposób, że jest napisany post, a potem tl;dr, czyli „too long; didn’t read”. Ludzie pisali kilkuzdaniowe streszczenie, o co chodzi w tym poście.
I okazało się, że skoro model przeczytał bardzo dużo tego typu tekstów, no to wiedział, że po słówku tl;dr ma napisać streszczenie. Więc jak wzięliśmy taki początkowy language model, GPT-2 czy GPT-3, i daliśmy mu jakiś tekst, a potem daliśmy tl;dr, to on fenomenalnie potrafił generować streszczenie.
No i teraz to jest przydatne, bo te modele są po prostu bardzo zdolne, mają bardzo dużo umiejętności, bardzo dobrze rozumieją tekst i w szczególności nie wymagają bardzo dużo danych treningowych.
Często nie potrzebują w ogóle danych treningowych, tylko wymagają dobrze napisanego promptu, żeby już rozwiązywać jakieś konkretne zadania. Jednym, oczywiście bardzo specyficznym zadaniem, jest właśnie wyciąganie odpowiedzi z dokumentów czy synteza informacji z dokumentów, żeby odpowiedzieć na pytanie.
Vladimir: Bardzo mi się podoba, jeżeli chodzi o ten duży model, że zwrócono uwagę, iż nie chodzi tylko o rozmiar architektury czy liczbę parametrów. Zwykle osoby, które są poza tematem, mierzą się, kto ma tych 13 miliardów parametrów, kto 7 itd. Ale ważne jest też to, że dotyczy to danych. W obecnych czasach, jak już udało się znaleźć pewien poziom, to teraz jest taka walka – co jeżeli zmniejszamy rozmiar modelu, a bardziej pracujemy na jakości i ilości danych, próbując osiągnąć tę samą rzecz.
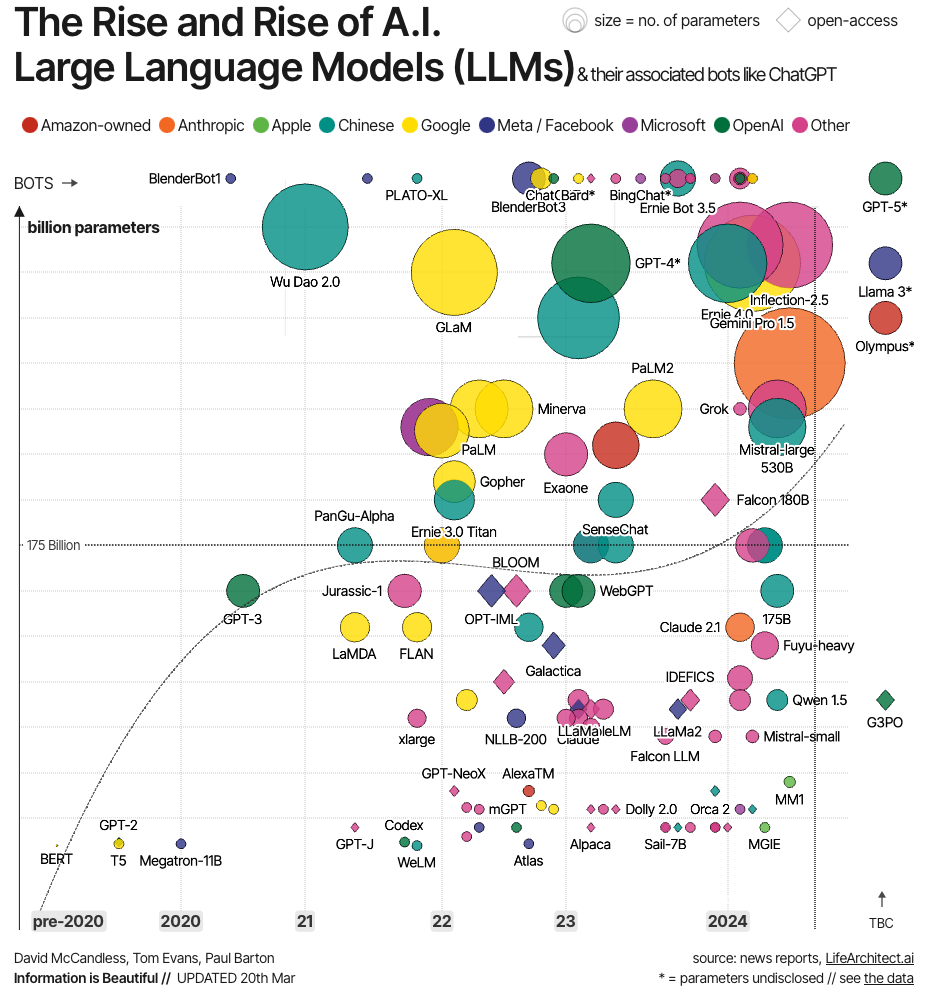
Widać, że dane w tej chwili odgrywają ważną rolę. Był taki moment, pewna iluzja, że wystarczy wrzucić cokolwiek, bo mamy duży model i on sobie jakoś tam poradzi. Jednak po raz kolejny odbiło się to o tę iluzję i znów wraca się do tego, że jakość danych ma sens. Ilość i jakość w tym przypadku odgrywają ważną rolę.
Znaczenie danych w trenowaniu modeli
Piotr: To znaczy, koniec końców, to czego się ten model uczy, to po prostu tych danych. Im więcej tych danych damy, tym więcej informacji się nauczy. Nawet niekoniecznie lepszej jakości, bo bardzo ciężko zdefiniować, co znaczy lepszej jakości dane, ale takich danych, których chcemy, żeby model się nauczył.
Tego się nauczy. Jeżeli damy mu teksty, które są pełne teorii spiskowych i nieprawdziwych faktów, jakichś fake newsów, to model się fenomenalnie tego nauczy, tylko to będzie dla nas mało użyteczne, jeżeli chcemy, żeby odpowiadał prawdziwie na pytania. Ale nie jest powiedziane, że to są wysokiej jakości dane, jeżeli zawierają prawdziwe informacje.
Jeżeli chcemy pisać fake newsy, powiedzmy, że jesteśmy jakąś agencją propagandową i chcemy pisać fałszywe informacje, to akurat tego typu danych chcemy. Chcemy mieć dane z fake newsami i chcemy, żeby on generował nieprawdziwe informacje. Wtedy dla nas wysokiej jakości dane to są te dane, które właśnie zawierają fałszywe informacje.
Vladimir: A w tym przypadku bardziej poszedłeś w kierunku biasu, że może być w ten sposób pisane albo w inny, a ja też, mówiąc o jakości, myślę przede wszystkim, że te dane w ogóle mają sens jako takie.
To znaczy, możesz sobie pozbierać jakieś paskudztwa w internetach, różne rzeczy i tam jest mnóstwo śmieci, które – nawet nie chodzi o to, że to jest prawda czy nieprawda – tylko po prostu to są totalne śmiecie. I trenowanie na takich śmieciach nie daje dużych wartości, bo tam nawet nie ma dobrych zdań, po prostu jakiś spam, niespam, nie wiadomo co.
Problem generowanych tekstów w internecie
Piotr: To w ogóle jest problem, że dużo tekstów w internecie jest generowanych przez jakieś proste modele, w szczególności teraz przy powszechności modeli językowych. Ale też historycznie ludzie tak pisali na potrzeby SEO, czyli optymalizacji wyszukiwarek internetowych, optymalizacji Google’a.
Pisali jakieś fejkowe, automatyczne artykuły na blogach, byle tylko miały odpowiednie słowa kluczowe, żeby Google ich indeksował. Teraz, jeżeli weźmiemy w tym przypadku słabej jakości teksty i nauczymy model, żeby tak generował tekst, to tak będzie generował tekst. Czy to będzie dla nas użyteczne? Zazwyczaj nie, bo chcę mieć taki czysty, ładny, powiedzmy wysokiej jakości, w znaczeniu poprawny gramatycznie.
Reprezentacja dokumentów w wyszukiwarce
Vladimir: Słuchaj, Piotrek, bardzo lubisz klocki LEGO, o tym też dzisiaj porozmawiamy, bo to jest wprost przełożenie, ale teraz chciałem zostać nadal w NLP, ale chciałem, żeby właśnie u słuchaczy była taka fajna analogia, że jak próbujemy rozwiązać konkretny problem, a teraz chciałbym, żebyśmy to zrobili, żeby było zrozumiałe, że ten system, który powstanie, to de facto są klocki LEGO, czyli pewne rzeczy, pewne warstwy, je można wymieniać na różne.
I też te decyzje są o coś, czyli jak zmieniamy A na B, to jest coś lepsze albo coś gorsze i musimy sobie wybrać. I chciałbym, żeby to wybrzmiało, że ten system jako tako to nie jest taka jedna duża bryła, tylko to są pewne warstwy i te warstwy można sobie tak konfigurować na różne sposoby. I też tam język może być inny, też jakby dany wycinek mógł być różny, więc próbujemy zdefiniować zadanie w taki sposób.
Załóżmy, że mamy firmę. Ta firma jest powiedzmy troszkę większa, tysiąc pracowników plus więcej, więc różne materiały tam gdzieś się nagromadziły, i PDF-y, i prezentacje, jakieś tam wewnętrzne serwisy o urlopach i innych i chcielibyśmy zbudować wyszukiwarkę, o której rozmawialiśmy, żeby ten przykład już sobie pociągnąć dalej. I teraz oczekiwanie mnie jako użytkownika jest następujące, że ja mam jakąś stronkę, wchodzę tam, jakiś URL i pytam sobie właśnie takie rzeczy, jak sobie zgłosić urlop, albo ile dni urlopu mi przysługuje.
Jak pracowałem w korporacji to dla mnie było dużym wyzwaniem znaleźć system aby zgłosić np. adres do bazy danych (lub odczytać go stamtąd). Bo właściwe były rzeczy takie prawdziwe do rozwiązania, na których warto było skupiać się i biurokratyczne. I dla mnie faktycznie znalezienie procedury, w jaki sposób ja mogę zgłosić jakiś tam dostęp do bazy danych, albo uzyskać ten dostęp do bazy danych, było super skomplikowane.
I osobiście byłbym mega zadowolony, żeby zapytać powiedzmy: „Proszę, jaki jest adres do bazy + i tam jakiś kontekst”, i on mi od razu zwracał, to ja byłbym bardzo szczęśliwy. Więc takie mam zadanie, ja teraz chciałbym, abyśmy przeszli krok po kroku i rozdzielili to na pierwsze takie warstwy poszczególne i też było zrozumiałe, jakie decyzje powinniśmy podjąć w poszczególnych warstwach. Co myślisz o tym?
Piotr: Teraz skupię się na klockach, ale dam disclaimer na początek, że pierwszą rzeczą, którą w ogóle absolutnie w każdym projekcie, a w szczególności w takim projekcie uczenia maszynowego, to chcemy zdefiniować, co właściwie chcemy zrobić i określić sobie cel. Ten cel powinien być jakoś mierzalny.
Takie wiadomo, że tutaj na potrzeby dyskusji pomachamy rękami, powiemy, że chcemy odpowiadać na takie pytania, tak jak powiedziałeś. Natomiast koniec końców zazwyczaj chcemy zacząć od analizy biznesowej – jakiego typu pytania chcemy odpowiadać, jaki zakres, jakie skomplikowanie, kto ma na nie odpowiadać, znaczy kto ma zadawać te pytania.
Często przygotowanie jakiegoś zbioru testowego, który idealnie, jeżeli reprezentuje dobrze te docelowe pytania i tak dalej, to jest absolutny must have na samym początku. O tym możemy jeszcze potem porozmawiać dalej w kontekście jak się buduje dobre zbiory testowe, jak się anotuje dane itd. Ale załóżmy, że to mamy i teraz już faktycznie budujemy konkretne rozwiązanie.
Ja bym powiedział, że kroków jest kilka i rzeczywiście są to takie klocki, które w miarę łatwo jesteśmy w stanie składać i wymieniać. Pierwszym takim dużym klockiem jest po prostu wyszukiwarka.
Wybór dokumentów do bazy wiedzy
Wyszukiwarka składa się z kilku elementów. Najpierw musimy podjąć decyzję jakie dokumenty w ogóle chcemy wciągać do naszej bazy wiedzy. To już jest taka decyzja mocno biznesowa, na jakie pytania chcemy odpowiadać, w związku z tym wciągamy jakieś konkretne dokumenty.
Często te dokumenty są bardzo różne, to mogą być albo jakieś wewnętrzne strony internetowe, może to być jakaś dokumentacja w Confluence czy czymś innym, mogą to być dokumenty takie wordowe czy w Google Docs czy coś takiego.
Tutaj raczej musimy po prostu zdefiniować, na podstawie czego chcemy odpowiadać i jak. Tu też jest trochę trikowych decyzji, na przykład mogą być problemy z uprawnieniami, z dostępem do informacji. Niektórzy pracownicy powinni mieć dostęp do jakiejś informacji, a niektórzy nie.
Jeżeli na przykład mamy dokumenty w Google Docs, to w oczywisty sposób nie możemy wziąć po prostu wszystkich dokumentów w Google Docs całej naszej korporacji, bo tam będą jakieś mniej lub bardziej tajne rzeczy, gdzie konkretne zespoły nie powinny mieć do tego dostępu. Więc jak w ogóle filtrować te dokumenty, skąd brać te dokumenty itd.
To jest taki może mały klocek, ale część polegająca na tym, że musimy te dokumenty, to źródło danych, wybrać.
Reprezentacja dokumentów
Jak mamy już te dokumenty, to pierwszy taki realny klocek to jest to, jak chcemy te dokumenty reprezentować.
Możemy albo je reprezentować i używać wyszukiwarki właśnie takiej klasycznej, opartej o słowa kluczowe. Wtedy jest to względnie proste – bierzemy dokument i wrzucamy cały, reprezentujemy jako słowa kluczowe, czyli dzielimy po prostu na słowa. Być może musimy podjąć tę decyzję, czy chcemy lematyzować te dokumenty, czy nie, ale w końcu jest to względnie proste, gdzie nie ma tutaj dużo decyzji.
Większy problem jest, kiedy chcemy używać tych bardziej współczesnych metod wyszukiwania, czyli tzw. embeddingów albo semantic search, albo ma wiele różnych nazw, ale chodzi o to, żeby reprezentować dokumenty jako jakiś wektor i generujemy ten wektor za pomocą sieci neuronowej, czyli modelu uczenia maszynowego.
Tutaj okazuje się, że ma bardzo duże znaczenie, jak ten dokument podzielimy na kawałki. Możemy oczywiście wziąć cały dokument i wrzucić do takiej sieci neuronowej, i dostać jakiś wektor, ale możemy też ten dokument podzielić na paragrafy i każdy paragraf wrzucić. Możemy też podzielić na zdania i wrzucić każde zdanie, i mieć tak tysiąc wektorów z jednego dokumentu.
Możemy zrobić bardziej trikowe rzeczy, np. użyć LLM-a, żeby napisał nam streszczenie tego dokumentu, czyli co w tym dokumencie jest, i zareprezentować, zaembedować tylko to streszczenie i wrzucić do bazy danych.
Podział dokumentów na fragmenty
Vladimir: Tutaj to są decyzje, które nie powodują dodatkowych problemów technicznych. Często są po prostu gotowe biblioteki, które to robią i każda z tych metod jest równie prosta, i każdą możemy bezpośrednio użyć. Natomiast jest to decyzja trudna produktowo, bo nie jest oczywiste, która z nich jest najlepsza i która w której sytuacji się sprawdzi.
Może podam dwa przykłady na to. Jeden przykład – załóżmy, że mamy system do odpowiadania na pytania o grach planszowych. Czyli chcemy zadać pytanie, nie wiem, czy mogę się ruszyć tym pionkiem tutaj albo o co chodzi w tej karcie, gram w jakąś grę karcianą.
I to jest sytuacja, w której tak naprawdę nie musimy robić wyszukiwania, bo jeżeli jesteśmy w kontekście danej gry planszowej, to źródłem prawdy do tej gry planszowej jest instrukcja tej gry. Instrukcja do gry planszowej zazwyczaj ma najwyżej kilka stron i to jest dostatecznie mało, żeby kolejny krok, jakiś LLM, był w stanie przeczytać całą instrukcję na raz. Więc tak naprawdę nie musimy robić wyszukiwania.
Ale możemy mieć skrajnie inny przykład – projekt, nad którym pracowałem, gdzie trzeba było odpowiadać na pytania dotyczące hoteli, a dla hoteli mieliśmy opinie. Dla danego hotelu mieliśmy tysiące opinii i tam ludzie pytali, czy woda w basenie jest ciepła.
Reprezentacja dokumentów w bazie danych
No i teraz, jak sobie o tym pomyślimy, to w jaki sposób możemy reprezentować te nasze dokumenty? W znaczeniu – każdy dokument to jest opinia.
Tak możemy całą opinię traktować jako taki jeden tzw. chunk i coś takiego wrzucać do bazy danych, ale w przypadku takich pytań o fakty, o jakieś cechy produktu, usługi, czegokolwiek, przez to jest za dużo.
W tej opinii ludzie wymienią 20 różnych cech. No, że woda była ciepła, ale szkoda, że ta plaża była daleko, a drinki to w ogóle były beznadziejne, ale przynajmniej było czysto w hotelu i tak dalej, i tak dalej.
Nie potrzebujemy kontekstu całej opinii, żeby zrozumieć, że woda była ciepła. Wystarczy, że podzielimy sobie tę całą opinię na takie króciutkie frazy rzeczownikowe – po prostu „woda była ciepła”, na pojedyncze zdania czy nawet mniej i coś takiego będziemy enkodować i wrzucać do bazy danych.
Generalnie, im – nazwijmy to – czystsze, czyli im mniej informacji będzie w tych pojedynczych chunkach, tym lepiej, tym łatwiej będzie je wyszukać. No bo jeżeli widzimy całą opinię, to będziemy mieli tak z 20 różnych informacji.
Trudniej jest wyszukać coś, co ma 20 informacji, versus coś, co ma jedną informację, takie to the point. Więc w zależności od problemu – czasami musimy robić wyszukiwanie, czasem to wyszukiwanie jest proste, właśnie po jakichś metadanych, jaka to jest gra planszowa i tyle, a czasami możemy sobie dzielić bardzo drobno, czasami nie możemy dzielić bardzo drobno.
Tak, jeżeli mamy jakiś akt prawny i chcemy wyszukać akt prawny, no to raczej jeżeli wyszukamy po jakimś drobnym detalu, po jakimś pojedynczym zdaniu, to zgubimy cały kontekst dokumentu i to nic nam nie będzie mówić. Więc w zależności od problemu jakoś musimy dzielić te dokumenty na kawałki.
Jak podzielić dokumenty na fragmenty?
Vladimir: Czekaj, ja cię troszkę przepytam, bo tutaj też chciałem podpytać – powiedziałeś, że „woda ciepła”, a potem ta cała reszta – plaża i tak dalej – będzie niepotrzebna w tym kontekście. Super, brzmi fajnie, tylko jak to podzielić? Bo to nie jest podział per kropka, per spacja, tylko taki bardziej semantyczny sposób, żeby to podzielić. I tutaj na pewno trzeba coś zatrudnić bardziej mądrego niż tylko takie regexpy. I jak to zrobić?
Piotr: Znaczy, te pomysły są dwa albo trzy. Znaczy, ja szczerze mówiąc po prostu dzieliłem, w cudzysłowie, „po kropce”, w sensie dzieliłem po pełnych zdaniach i to było dostatecznie dobre przybliżenie.
Można używać czegoś, co się nazywa parsowanie zależnościowe, to jest taki lingwistyczny termin. Znaczy, można – nie wiem, czy pamiętasz – w podstawówce rysowało się drzewka gramatyczne zdań.
No i coś takiego też można robić automatycznie za pomocą uczenia maszynowego. To było popularne 15-20 lat temu w przetwarzaniu języka naturalnego, ale nadal się to czasami wykorzystuje właśnie po to, żeby automatycznie podzielić to zdanie, że tu są frazy rzeczownikowe i te frazy rzeczownikowe są osobne, a pomiędzy nimi jest koordynacja, czyli a, b i c.
To są trzy osobne komponenty i okazuje się, że względnie łatwo jesteśmy w stanie automatycznie to podzielić na kawałki, więc jakby to jest drugi pomysł, jak można do tego podejść.
A trzeci pomysł to po prostu użycie LLMów znowu, właśnie na etapie takiego preprocesingu, na zasadzie: „Tak, wylistuj mi wszystkie cechy tego hotelu”.
No i on wypisze, jeżeli napiszemy dobry prompt, no to wypisze, że woda jest ciepła, pokój jest czysty i tak dalej. To notabene, to może już uprzedzając i wyprzedzając, w przypadku tego projektu o hotelach to może mieć fundamentalne znaczenie, jeżeli o tym pomyślimy.
Problem z wyszukiwaniem fragmentów
Jeżeli mamy 1000 opinii i 900 osób napisało, że woda jest ciepła, a 100 osób napisało, że woda jest zimna, to chcielibyśmy wiedzieć, że faktycznie 90% osób napisało, że woda jest ciepła.
Ale jeżeli wyszukamy sobie kilka tak najbardziej podobnych zdań w tym przypadku, które opisują ciepłotę wody, no to w szczególności jak ktoś zapyta, czy woda jest ciepła, to semantycznie bardziej podobne będą zdania „woda jest ciepła” niż że „woda jest zimna”.
Jak ktoś zapyta, czy woda jest zimna, to bardziej podobne będą te zdania „woda jest zimna”. No i teraz będzie bardzo duży problem, jeżeli ktoś zapyta, czy woda jest ciepła, znajdziemy powiedzmy 10 zdań, gdzie ludzie piszą, że woda jest ciepła i damy odpowiedź: „Tak, woda jest ciepła”.
Jak ktoś zapyta, czy woda jest zimna, znajdziemy 10 zdań, gdzie ktoś napisał, że woda jest zimna i odpowiemy: „Tak, woda jest zimna”. Widzisz, to jest absurdalne, bo model nam odpowie w zupełnie inny sposób, zależnie od tego, jak zadamy pytanie.
Wybór modelu do tworzenia embeddingów
Piotr: Kolejna ważna decyzja to czym tworzymy te embeddingi. To nie jest oczywisty wybór. Mogliśmy w ogóle ominąć ten krok i używać słów kluczowych, ale zazwyczaj w dzisiejszych czasach chcemy używać metod semantycznych, czyli sieci neuronowych, które przetwarzają teksty w konkretne wektory.
Wybór modelu jest bardzo istotny, bo te modele różnią się jakością. Często ludzie sięgają po popularne rozwiązania, jak np. embeddingi od OpenAI. Ich nowsza, trzecia wersja jest już w porządku, ale poprzednia była po prostu tragiczna, szczególnie dla języka polskiego. Trzecia też nie jest najlepsza, ale wystarczająco dobra.
To było coś prostego w użyciu, ale bardzo słabego. Wyszukiwaliśmy w jakimś sensie podobne teksty do naszego pytania, podobne dokumenty czy chunki, ale one były podobne tylko według OpenAI, a nie według tego, jak my na to patrzymy. Widzieliśmy, że to jest totalnie od czapy.
Wybór modelu wpływa na to, czy rozwiązanie będzie działać, czy nie. Wracając do twojego pytania, co się zmieniło w ciągu ostatnich 10 lat – to zmieniło się bardzo mocno. Jeszcze 5 lat temu, jeśli mieliśmy model do wyszukiwania informacji, potrafił on działać sensownie tylko w jednej domenie.
Jeśli mieliśmy problem wyszukiwania opinii o hotelach i model wytrenowany pod kątem opinii hotelowych, to użycie go dla danych prawniczych skończyłoby się totalną porażką. W danych hotelowych działałby może trochę lepiej niż wyszukiwanie po słowach kluczowych, ale po przejściu do innej domeny, innego typu tekstu, działałby już praktycznie losowo.
Postęp w dziedzinie modeli językowych
Piotr: Tak, bo to, teraz kolejna decyzja to jest, ale właściwie czym embedujemy, tak, czym tworzymy te embeddingi. I to też nie jest oczywista decyzja, tak, w sensie mogliśmy w ogóle ominąć ten krok i używać słów kluczowych, ale zazwyczaj w dzisiejszych czasach chcemy używać takich metod, tak zwanych semantycznych, czyli właśnie sieci neuronowych, które przetwarzają te teksty w konkretne wektory.
No i to jest bardzo nieoczywista decyzja, którego modelu użyjemy. I to jest bardzo ważna decyzja, bo te modele są lepsze albo gorsze. Często ludzie używają jakichś popularnych modeli, na przykład tak, postulant embeddingów od OpenAI i ta nowsza wersja, wersja trzecia, już jest okej, ale ta poprzednia wersja była po prostu tragiczna, przynajmniej dla języka polskiego. Ta trzecia też nie najlepsza, ale good enough może.
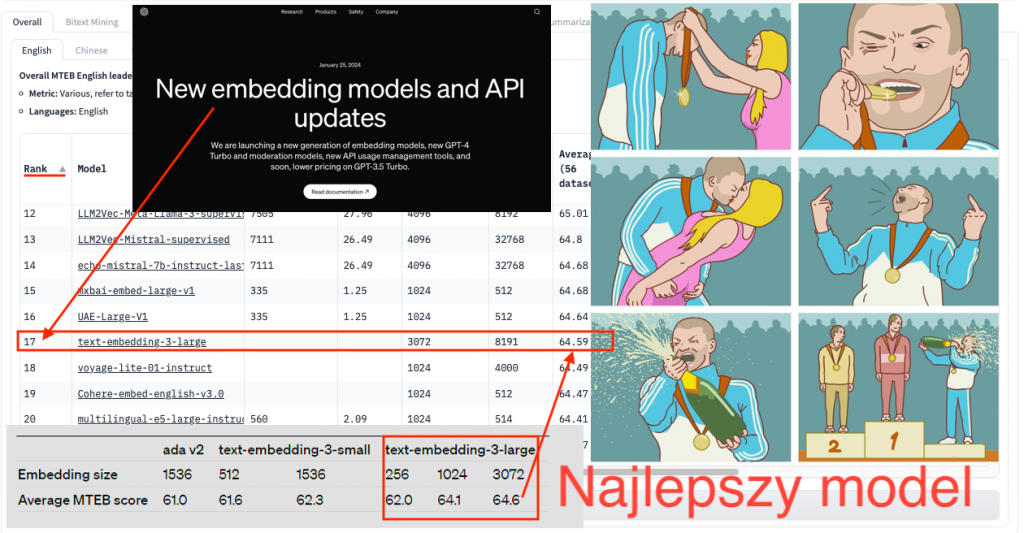
To było coś, co jest bardzo proste do użycia, ale ono było bardzo słabe i okej, wyszukiwaliśmy w jakimś sensie podobne teksty do tego naszego pytania, podobne dokumenty, podobne te chunki, ale one były tylko podobne według OpenAI, a nie według nas, jak na to patrzymy, bo widzimy, że to jest totalnie od czapy.
No i tutaj to, jak wybierzemy ten model, właśnie wpływa na to, czy to będzie działać, czy nie. I trochę wracając do tego pytania twojego, co się zmieniło w ciągu ostatnich 10 lat, to to się bardzo mocno zmieniło, w sensie jeszcze 5 lat temu nawet, jeżeli mieliśmy taki model do wyszukiwania informacji, to on potrafił działać tylko i wyłącznie w jednej domenie sensownie, znaczy jak mieliśmy ten problem, powiedzmy, wyszukiwania opinii o hotelach i mieliśmy wytrenowany model pod opinie dla hoteli i byśmy użyli go dla danych prawniczych, to on totalnie by nie działał.
W sensie w tych danych hotelowych on pewnie działałby trochę lepiej niż wyszukiwanie po słowach kluczowych, ale jak byśmy musieli przejść do innej domeny, do innego typu tekstu, to on by już działał praktycznie losowo.
Generowanie syntetycznych danych treningowych
PIotr: I okazało się, że to było bardzo trudne, żeby przeskoczyć to i żeby mieć model, który faktycznie daje uniwersalnie dobre embeddingi. To się udało dosłownie 2-3 lata temu, głównie w ten sposób, że po prostu wzięliśmy bardzo, bardzo dużo danych i wytrenowaliśmy model na wszystkich domenach naraz. W jaki sposób jest to oszustwo? Nadal nie potrafimy generalizować, czyli dobrze działać na nieznanych domenach.
Tak poradziliśmy sobie z tym w ten sposób, że wytrenowaliśmy model na wszystkich możliwych domenach, co jest w pewnym sensie oszustwem, ale dopóki działa praktycznie, to w sumie czemu nie. I rzeczywiście są takie modele, które teraz działają sensownie dla wielu różnych domen, i to dla angielskiego, i też dla polskiego takie modele się pojawiają.
Natomiast wciąż te modele nie są zazwyczaj idealne. One są generyczne, uniwersalne i działają ok, ale jeżeli chcemy mieć naprawdę super dobrą skuteczność, to wciąż bardzo wartościowe jest, żeby wytrenować ten model specjalnie dla siebie, w twojej konkretnej niszy. To daje bardzo duże zyski.
Trenowanie własnego modelu
Piotr: Więc ja zazwyczaj to, co rekomenduję, to w pierwszym kroku użyć takiego modelu uniwersalnego i sprawdzić, jak on będzie działać, sprawdzić na naszym zbiorze testowym, czy on faktycznie zwraca dobre dokumenty, dobre w znaczeniu zawierające odpowiedź. Często zwraca dostatecznie dobre.
Powiedzmy, że zwraca dobry dokument w 90% przypadków i to jest użyteczne, ale czasami dla nas ma znaczenie, czy to będzie 90 czy 95%, czy tak może się zdarzyć, że to jest 60 vs 90%. I wtedy jest inny klocek, kolejny klocek na zasadzie – wytrenujmy swój własny model do tego celu.
I to też jest coś, co się radykalnie zmieniło w ciągu tych ostatnich paru lat, bo kiedyś, żeby wytrenować taki model, trzeba było mieć dane, no ale żeby mieć dane, to trzeba zatrudnić ludzi, którzy będą anotować dane. To było zaskakująco trudne w znaczeniu, że tych danych, żeby wytrenować taki model do embeddingu, potrzebujemy dosyć dużo, w sensie to są raczej dziesiątki tysięcy takich par – pytanie, dokument.
W związku z tym trzeba jakoś te pary napisać, trzeba albo mieć pytania skądś, na przykład historyczne pytania od użytkowników i dla tych pytań znaleźć dokumenty w naszej bazie danych, albo nie mamy historycznych pytań od użytkowników, więc trzeba sobie jakoś radzić i albo wymyślać te pytania, i potem znajdować dokumenty, albo brać te dokumenty i do nich pisać pytania. No ale dość, że to było bardzo czasochłonne i jakby koniec końców kosztowało dużo pieniędzy i nie zawsze warto było to robić.
To, co się stało niesamowitego w ostatnich czasach przez LLM-y, to że możemy użyć po prostu LLM-ów, żeby te pytania wygenerować automatycznie. Czyli bierzemy sobie nasze dokumenty, które mamy w bazie danych, i pytamy tak ChatGPT: „Wygeneruj mi pięć pytań do tego dokumentu”. I on generuje pytania, a te pytania są zaskakująco sensowne.
Czasem warto coś tam pofiltrować, poczyścić te rzeczy, ale możemy to robić automatycznie. I teraz nagle wygenerowanie dziesięciu tysięcy pytań czy pięćdziesięciu tysięcy pytań to koszt pięćdziesięciu dolarów – absolutnie zerowy w skali jakiejś korporacji.
I mając te pięćdziesiąt tysięcy pytań, jesteśmy w stanie już dotrenować jakiś taki uniwersalny model do embeddingów pod nasze potrzeby, ponieważ jest to dotrenowanie. Dotrenowanie zazwyczaj jest jakby mało zasobochłonne, często zajmuje po prostu godzinę czasu na jednej karcie graficznej i już wtedy ten model jest dużo, dużo lepszy.
Więc też właśnie to, co się zmieniło, to możliwość szybkiego dostosowania tych modeli dzięki temu, że możemy łatwo wygenerować sobie syntetyczne dane treningowe.
Wiadomo, że te dane treningowe nie są super jakości, one będą miały błędy, nie mają tych wszystkich subtelności, które powinny tam być, ale jesteśmy w stanie szybko dojść do sensownego poziomu. A potem, jeżeli nadal chcemy mieć lepszą skuteczność, to już nie uciekniemy od tego, że ktoś musi usiąść, zanotować te dane i stworzyć dane wysokiej jakości.
Embeddingi – konwertowanie tekstu na reprezentację numeryczną
Vladimir: To teraz ja już spróbuję tak podsumować to, co wybrzmiało i idziemy dalej.
Czyli kiedy jesteśmy na etapie embeddingu, czyli chcemy skonwertować nasz tekst w reprezentację numeryczną, to pierwsza rzecz: nie chcemy używać jakiejś znanej nazwy jak OpenAI ot tak domyślnie bez rozważenia, bo zwykle to nie działało w tej poprzedniej wersji. I mimo że GPT jest super, to nie znaczy, że embeddingi też będą super, tym bardziej dla nas, więc to jest do rozważenia.
Druga rzecz to trzeba rozważyć, jak nie to, to co wtedy. I to jest super, że w ogóle te pytania się pojawiają, bo można zacząć wybierać. Warto podpowiedzieć, że są na przykład takie leaderboardy MTEB albo jakieś tam inne, gdzie można sobie wybrać takich fajnych kandydatów, których można byłoby rozważyć.
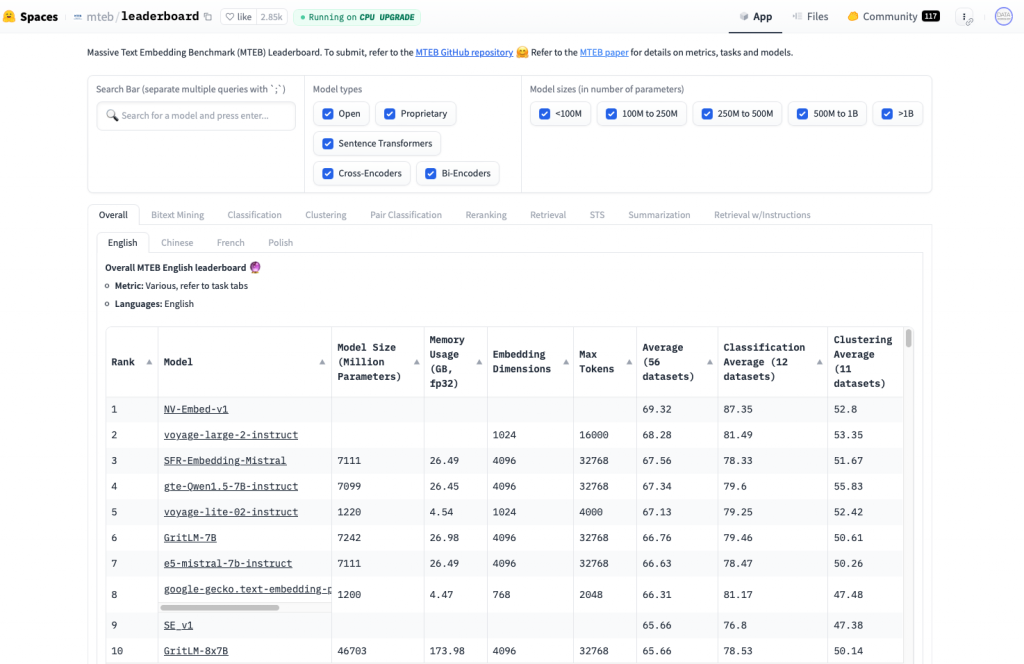
I też, co fajnie powiedziałaś, że owszem, teraz są bardziej takie ogólne rozwiązania, ale też może tak się zdarzyć, że mamy jakąś bardziej konkretną potrzebę i wtedy może być lepiej, żebyśmy my dotrenowali to do siebie, ale też żeby to było obiektywne, to weźmiemy coś bardziej ogólnego.
Mamy wynik, potem bierzemy coś bardziej konkretnego pod nas, czyli dotrenujemy pod naszą domenę. Też na przykład język polski już sam w sobie jest domeną, bo też te wyrazy itd. już też to komplikują. I wtedy dostajemy rozwiązanie, które będzie de facto lepiej reprezentować te semantyczne zależności, jeżeli chodzi o dane na wejściu, czyli dane w postaci tekstu, i na wyjściu to będą wartości numeryczne.
Dobra, mamy to. Idziemy dalej, co tam dalej nas czeka?
Reranking – ulepszanie wyników wyszukiwania
Piotr: Mamy to. Dobra, to teraz ostatni krok wyszukiwania, bo jak robimy to wyszukiwanie, zazwyczaj znajdujemy dla danego pytania 10, 20 albo 100 najbardziej podobnych dokumentów. Te dokumenty będą rzeczywiście podobne, ale nie będą łapać tych wszystkich subtelności, bo one będą podobne, ale niekoniecznie będą odpowiadały na pytanie.
To z różnych względów technicznych jest trudne do uzyskania, żeby te zwrócone dokumenty były faktycznie świetnej jakości. I teraz dochodzi nam kolejny klocek, czyli tzw. reranking. Znaczy, jak mamy te 100 zwróconych dokumentów, to czy możemy bardziej złożonym, bardziej skomplikowanym, lepszym modelem maszynowym przesortować te dokumenty tak, że jeżeli ten poprawny dokument był na 90. pozycji, to żeby wynieść go na pierwszą pozycję.
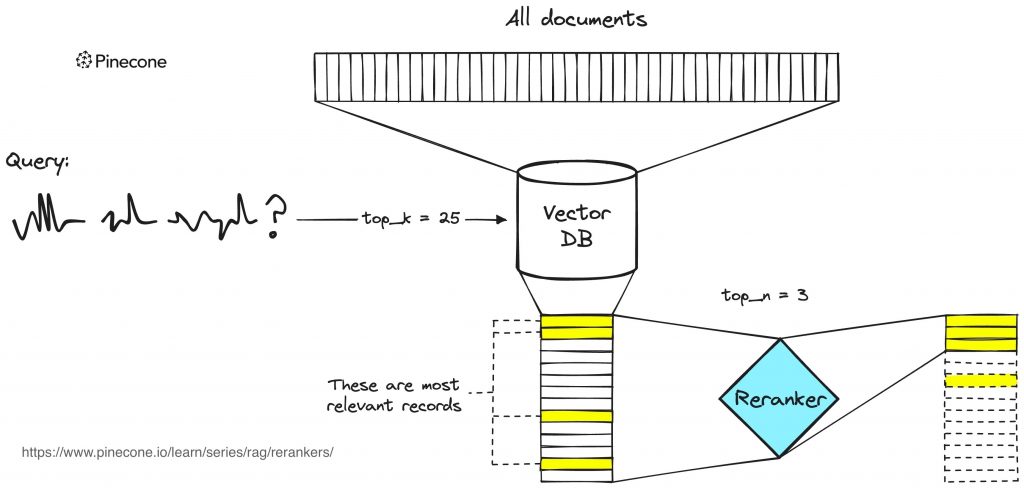
Tutaj oczywiście też jest dużo podejść, możemy używać LLMów do tego, zrobić zapytanie do OpenAI, czy ten dokument odpowiada na to pytanie – tak, nie.
Generowanie odpowiedzi
Piotr: Możemy użyć opensource’owych modeli, możemy też trenować swoje modele do tego zadania i to często też pomaga, żeby jeszcze bardziej poprawić te wyniki wyszukiwania. Oczywiście wiąże się to z kosztem finansowym, bo musimy zrobić np. odpytania do OpenAI, ale też kosztem jeżeli chodzi o czas odpowiedzi, bo wkładamy kolejny klocek i on zajmuje jakiś czas. To czasami jest potrzebne, czasami nie. Tak naprawdę znowu, to jest zależne od konkretnego wdrożenia, od konkretnego produktu.
Czasami te wyniki z tego pierwszego wyszukiwania są na tyle dobre, że nie musimy tego poprawiać. A czasami niestety tak nie jest i musimy dołożyć kolejny klocek.
Vladimir: Ja chciałem tylko tak dopowiedzieć, że na początek mamy powiedzmy 100 tysięcy albo 10 tysięcy dokumentów, więc „pierwsze wyszukiwanie” robi takie szybsze, ale mniej precyzyjne wyszukiwanie i z tych 100 tysięcy dostarczy nam np. 100 dokumentów.
Ale żeby faktycznie znaleźć najbardziej trafny dokument, to czasem może nam się opłacać zatrudnić troszkę bardziej skomplikowany mechanizm, co zwykle nam powiększa czas, bo nic nie ma za darmo, no i też jakieś pieniądze prawdopodobnie będą za tym. Ale dzięki temu możemy liczyć na to, że znajdziemy faktycznie bardziej konkretniejsze, też możemy się mylić, ale tak z punktu widzenia tego mechanizmu, bardziej trafny dokument i mamy w ten sposób wybrany ten dokument numer jeden.
Piotr: Dokładnie tak. Zazwyczaj nie dokument numer jeden, tylko wciąż kilka dokumentów, pięć najlepszych dokumentów, kilka najlepszych dokumentów.
Tak i to zakończyliśmy ten etap wyszukiwania i teraz zazwyczaj jest ten etap generowania odpowiedzi i on często, przynajmniej w takim najprostszym wariancie, jest w sumie prosty. Znaczy bierzemy to pytanie, bierzemy te pięć dokumentów i współcześnie po prostu wysyłamy to do OpenAI, do ChatGPT i prosimy o odpowiedź na pytanie. I ChatGPT odpowiada na to bardzo dobrze zazwyczaj. To jest też fajne, bo on wtedy raczej nie halucynuje, co się zdarza później wiadomo, ale raczej korzysta z tych informacji, które były w znalezionych dokumentach, żeby odpowiedzieć na pytanie.
Trenowanie własnych modeli
Piotr: Oczywiście to jest coś, co się tak pojawiło te dwa lata temu razem z popularyzacją ChatGPT. Wcześniej trenowaliśmy też specyficzne modele, które właśnie te informacje, te odpowiedzi wyciągały.
I to albo na takiej zasadzie, jakby początkowo to było, żeby zaznaczyć fragment dokumentu, który zawiera odpowiedź. Czyli jak powiedzmy to pytanie o urlop, ile mam dni urlopu, to gdzieś tam pewnie była rozpiska, że w zależności od stażu to ma się tyle i tyle dni urlopu i wtedy byśmy dostali odpowiedź jako zaznaczony fragment tego oryginalnego dokumentu.
No ale to jest mega ograniczone podejście. Jeżeli sobie pomyślimy o pytaniach typu „tak, nie”, no to nie możemy w dokumencie zaznaczyć „tak, nie”, czyli „czy mam 26 dni urlopu” i możemy zaznaczyć tylko „26 dni urlopu przysługuje osobie, która coś tam coś tam”. Tak, ale nie dostaniemy odpowiedzi „tak”, bo tego „tak” nie ma w dokumencie.
Potem pojawiły się modele właśnie takie generatywne, które były specjalnie trenowane do tego, żeby wziąć pytanie, wziąć te dokumenty i wygenerować faktyczną odpowiedź. Do tego często potrzebowaliśmy przygotować sobie jakieś dane treningowe, zazwyczaj parę, paręnaście, parędziesiąt tysięcy takich przykładów, wytrenować model i mogliśmy go użyć, żeby odpowiadać na pytania. Natomiast te LLM-y obecnie używane są super dlatego, że nie musimy mieć danych treningowych i one działają dostatecznie dobrze.
Oczywiście, jeżeli zależy nam na tym, żeby model odpowiadał w jakimś konkretnym stylu albo żeby po prostu odpowiadał lepiej, to wciąż możemy ten model dotrenować. To też może nie wszyscy wiedzą, ale modele od OpenAI, w sensie Chata GPT, też można w ich interfejsie sobie dotrenować, jeżeli mamy jakieś dane i tak dostosować do naszych potrzeb.
To jest powiedziałbym dziedzinowo proste, wystarczy dać takie pary: pytanie, dokumenty i oczekiwana odpowiedź. Nawet jak przygotujemy 100 takich przykładów, to już ten model będzie działał dużo, dużo lepiej. Wtedy odpytywanie Chata GPT będzie trochę droższe, ale często jakość będzie istotnie lepsza i te odpowiedzi będą bardziej dostosowane do tego, czego oczekujemy.
Natomiast zazwyczaj po prostu korzystamy z Chata GPT, Anthropic czy z jakichś oczywiście innych konkurencyjnych rozwiązań – Gemini, Claude i tak dalej. One wszystkie działają bardzo fajnie.
Wielkość kontekstu w modelach językowych
Vladimir: Jaka jest obecnie typowa wielkość dokumentu, który można przesłać do modelu językowego w jednym zapytaniu? Fajnie byłoby to przedstawić w liczbie stron, aby ludzie mogli to sobie lepiej wyobrazić. I druga kwestia – jakie są dobre praktyki w tym zakresie? Bo nie wszystko co się da, warto robić, prawda?
Piotr: To ważna kwestia, którą poruszyłeś. W standardowym, najprostszym setupie, o którym mówiłem, nawet nie wyciągamy całych dokumentów, tylko tzw. chunki, czyli fragmenty. Zazwyczaj będzie to jedno zdanie, maksymalnie parę zdań. Więc nawet jak wyciągniemy pięć takich chunków, to nie będzie tego dużo – maksymalnie jedna strona tekstu. To jest coś, co bez problemu każdy model językowy przetworzy.
Natomiast rzeczywiście, w zależności od problemu, taki chunk może nie zawierać wszystkich potrzebnych informacji. Czasem potrzebujemy szerszego kontekstu, na przykład całego dokumentu. Tutaj jest kilka różnych trików, które można zastosować.
Jeden standardowy trik polega na tym, że skoro mamy jakiś chunk, ale chcemy mieć większy kontekst, to bierzemy jeszcze dwa chunki poprzedzające ten główny i dwa następujące po nim. Wtedy takie pięć chunków wrzucamy. To daje nam dwadzieścia pięć bazowych chunków, czyli już około pięć stron tekstu. Ale czasami nawet to może być za mało i musimy znać cały dokument.
Sposobów radzenia sobie z dużymi dokumentami jest wiele. Na szczęście w dzisiejszych czasach okno kontekstowe (context window) różnych modeli językowych jest na tyle duże, że nie musimy się tym aż tak bardzo przejmować. To są raczej dziesiątki tysięcy tokenów, a nawet setki tysięcy. Gemini od Google obsługuje nawet milion tokenów. Więc to są absurdalne ilości, których nigdy nie wykorzystamy w takim setupie odpowiadania na pytania. W innych zastosowaniach oczywiście możemy je wykorzystać.

Jednym z rozwiązań jest takie, że jak mieliśmy tych pięć oryginalnych chunków, to tak naprawdę robimy pięć odpytań do modelu językowego. Pytanie plus pierwszy chunk – chcemy dostać odpowiedź, pytanie plus drugi chunk – chcemy dostać odpowiedź, i tak dalej. Wysyłamy więc pięć różnych zapytań i dostajemy pięć różnych odpowiedzi.
Możemy też zrobić dodatkowy krok, że nie tyle generujemy odpowiedź, co wyciągamy istotne informacje. Czyli bierzemy pytanie, pierwszy cały dokument i prosimy model o wyciągnięcie kluczowych informacji z tego dokumentu.
Wyciąganie kluczowych informacji z dokumentów
Zazwyczaj tych kluczowych informacji nie będzie aż tak dużo, żeby odpowiedzieć na pytanie. One będą po prostu rozsiane w różnych miejscach po tym dokumencie. Powtarzamy to pięć razy dla każdego z tych pięciu dokumentów, więc zbieramy koniec końców dosyć małą ilość danych i wrzucamy do finalnego promptu do LLM-a. Wygeneruje on odpowiedź na podstawie tych wyciągniętych cytatów i dzięki temu możemy sobie radzić z tym ograniczonym kontekstem.
To też ma znaczenie o tyle, że jeżeli zrobimy pięć takich odpytań równolegle w tym samym czasie, to będzie to szybsze niż jedno odpytanie z bardzo długim dokumentem.
Vladimir: Wydaje mi się, że w miarę pokryliśmy temat, przynajmniej tak high level, żeby mniej więcej było zrozumiałe, jakie są warstwy i jakie decyzje należy podejmować. Temat rzeka. Ja też nie stawiałem aż tak ambitnego celu, żeby omówić wszystkie szczegóły, bo tego jest wiele.
Triki i detale w budowaniu chatbotów
Piotr: Tak, tego jest bardzo, bardzo dużo i generalnie takich trików – ludzie wymyślają bardzo dużo tych trików i to na każdym z tych etapów. Ja też przedstawiłem taką ścieżkę dosyć podstawową. Mimo że już wchodziliśmy w jakieś detale, to tych detali może być bardzo, bardzo dużo.
Problem jest taki, że wybór tych detali bardzo mocno zależy od konkretnego projektu i nie jest tak, że któreś z tych rozwiązań są dobre. One bywają dobre, ale często bywają złe. Często też na przykład ta sama konstrukcja naszego chatbota czy systemu odpowiadania na pytania wymaga czegoś więcej, jakichś dodatkowych funkcjonalności.
Na przykład, jeżeli mamy asystenta prawniczego i chcemy odpowiadać na pytania prawnicze, to nie jest tak, że jedyne kryterium to czy ten dokument będzie pasujący do pytania, ale też czy będzie aktualny. Tak więc możemy na przykład sortować jeszcze te dokumenty po tym, jak one są aktualne, z którego są roku. Możliwe, że powinniśmy filtrować po jakichś metadanych i tak dalej. Więc tych detali jest jeszcze bardzo, bardzo dużo, ale to jest taki najprostszy możliwy przepływ.
Rozwiązania szyte na miarę
Vladimir: Fajnie, że to wybrzmiało, bo mimo tego, że istnieje ta cała magia, jeżeli chodzi o LLM, który faktycznie zaskoczył wszystkich osób technicznych możliwością porozmawiania i tak dalej, to nadal rozwiązanie jako takie musi być szyte na miarę. Tutaj właśnie zdefiniowanie, co potrzebuje biznes, jaka jest metryka sukcesu, jakie błędy są dopuszczalne, jakie są niedopuszczalne, jaki jest koszt takich błędów. W zależności od tych wszystkich wytycznych pojawia się to finalne rozwiązanie i stąd właśnie musi być ono szyte na miarę, a te warstwy są dość elastyczne w zależności od potrzeb. Bywa różnie.
Kluczowe kompetencje w budowaniu projektów ML
Piotr: Wracając jeszcze raz do tego pytania, co się zmieniło w przeciągu ostatnich 10 lat. W tym sensie nic się w świecie nie zmieniło. Dostaliśmy nowe zabawki, nowe narzędzia, one działają dużo lepiej niż działały kiedyś, ale te kluczowe kompetencje – kiedyś to byli statystycy, potem data scientiści, potem ML inżynierowie, teraz AI inżynierowie – te nazwy stanowisk, nazwa dziedziny się co chwilę zmienia, narzędzia się zmieniają.
Ale te kluczowe kompetencje są dokładnie takie same cały czas i te problemy są też dokładnie takie same. Chcemy wiedzieć, co musimy budować, jak dobrać odpowiednie klocki, żeby zrealizować cele biznesowe, gdzie popełniamy błędy, jaki jest kompromis między skutecznością a kosztami itd.
I jasne, że mamy zupełnie inne klocki do dyspozycji dzisiaj niż 10 lat temu, ale sam proces budowania projektu machine learningowego tak naprawdę nie zmienił się – powiedziałbym, że prawie w ogóle. Może trochę, rzadko już teraz pisze się sieci neuronowe np. od zera w PyTorchu, raczej się wykorzystuje jakieś gotowe klocki, ale nigdy to pisanie sieci neuronowych w PyTorchu, czy wcześniej w TensorFlow, czy w Theano, to nigdy nie było clou problemu.
Narzędzia do adnotacji danych
Vladimir: Powiedz kilka rzeczy na temat narzędzi, których używasz w kontekście tekstu, obrazków. Jakie rzeczy są dla ciebie przydatne? Chcielibyśmy, żeby inni też to usłyszeli. No i jak sobie to układasz mentalnie, motywacyjnie, że chce ci się to robić?
Piotr: Jeśli chodzi o narzędzia do adnotacji danych, to jest bardzo trudne pytanie, bo różnie. W swoim życiu napisałem pewnie z 10 różnych narzędzi do adnotacji danych, tak po prostu dla siebie, w zależności od projektu. Często to jest najlepsze rozwiązanie, bo te adnotacje danych bywają na tyle specyficzne, że warto napisać coś swojego.
Mogą to być bardzo proste rzeczy, na przykład Google Sheets, gdzie po prostu robimy sobie arkusz, w jaki sposób go filtrujemy, sortujemy i tam piszemy adnotacje. Klocki Lego anotuję głównie w Jupyter Notebooku. Mam po prostu taką prostą aplikację w Jupyter Notebooku napisaną do adnotacji danych, bo tam robię bardzo dużo filtrowania tego, jakie dokładnie dane chcę zaadnotować. To filtrowanie tak po prostu robię w Pythonie.

Motywacja do żmudnej pracy
Piotr: Mnie zawsze najbardziej napędza zrobienie projektu. Najważniejsze dla mnie jest to, że chcę po prostu zbudować jakiś model, produkt, coś stworzyć. Tak naprawdę, co dokładnie robię, nie ma aż tak dużego znaczenia.
Może adnotacja danych jest nudna, powtarzalna i człowiekowi się nie chce tego robić. Ja też nie jestem w stanie wytrzymać dłużej niż pół godziny czy godzinę, siedząc i adnotując te dane. Po prostu wiem, że jest to konieczne, potrzebne i wartościowe, więc samo to mnie motywuje.
Pisanie kodu też nie zawsze jest super miłe i przyjemne, jest męczące, uciążliwe, trzeba myśleć i też się nie chce. Wyskakują jakieś błędy. W pewnym sensie wolę adnotować dane, bo tam przynajmniej klikam ten klocek, ten klocek, ten klocek i jest to przynajmniej bezstresowe. Więc motywuje mnie efekt końcowy, tak w skrócie.
Natomiast rzeczywiście dzielę sobie też często tę adnotację tak, żeby po prostu robić po trochu. Staram się mieć zawsze gotową jakąś adnotację danych, w sensie jakoś ustawiony proces adnotacji danych. Także jak mam przerwę pomiędzy spotkaniami 15 minut, to mogę sobie otworzyć to narzędzie do adnotacji danych i trochę poklikać. Albo jem obiad i nic mi się innego nie chce robić, to sobie poklikam. Czy jest wieczór i już jestem zmęczony, i nie chce mi się pracować, a trochę sobie poklikam.
Tak jak powiedziałeś, że robię to bardzo regularnie, to też nie do końca prawda. Są takie miesiące dwa, trzy, że na przykład anotuję codziennie dane, a potem mam już tak bardzo dosyć, że przez kolejne dwa miesiące w ogóle na to nie mogę patrzeć.
Vladimir: Trochę mnie uspokajasz, bo to brzmi jak szaleniec już wreszcie.
Piotr: Nie, nie, nie, to znaczy jestem szalony, ale nie aż tak szalony.
Narzędzia do anotacji danych
Piotr: Nie byłbym w stanie tego robić sensownie w jakimś gotowym narzędziu, w szczególności, że to często jest mniej lub bardziej dynamiczne, więc nie mogę wrzucać jakichś batchy. Wygodnie jest mi to anotować w Jupyter Notebooku.
Natomiast z takich narzędzi, z których faktycznie korzystam regularnie, to jest na pewno Label Studio. To jest takie narzędzie open source’owe, bardzo elastyczne, można odpalić lokalnie lub na serwerze w chmurze. Jest to narzędzie w miarę uniwersalne – i do tekstu, i do obrazków, i do bardzo wielu różnych typów danych.
Oni mają w miarę elastyczny system definiowania interfejsu, czyli co chcemy wyświetlać i w jaki sposób. To działa ok. Na pewno nie jest to świetne narzędzie, ale działa dostatecznie dobrze, więc jak jest coś bardziej standardowego, to po prostu używam tego.
Albo jeżeli jest coś, co jest trudne do zaimplementowania samemu, np. rysowanie bounding boxów czy prostokątów, żeby zaznaczyć gdzie klocek Lego znajduje się na zdjęciu, to napisanie czegoś takiego byłoby odrobinę bardziej skomplikowane. Więc warto użyć czegoś gotowego, jak Label Studio.
Jest trochę komercyjnych rozwiązań, które też są spoko, ale one w dużej mierze wszystkie są w miarę podobne, więc czego nie użyjemy, to będzie ok.
UX narzędzia do anotacji
Piotr: Dla mnie ważne jest to, żeby UX rozwiązania był dobry. To narzędzie powinno nam pomagać anotować dane, a nie przeszkadzać. Nie powinniśmy robić 10 kliknięć, żeby zrobić jedną anotację, tylko jedno kliknięcie i już.
Istotniejsze od tego, jakiego używamy narzędzia, jest to, w jaki sposób w ogóle przedstawimy problem anotacji danych. Przykładowo klocki Lego. Jest 80 tysięcy klocków Lego i mam jakieś zdjęcia od użytkowników, które muszę przypisać, jaki klocek jest na danym zdjęciu.
Oczywiście mógłbym to robić naiwnie, na zasadzie mieć zdjęcie i 80 tysięcy klas, i teraz przeglądać te klasy. Ale to byłoby nierealne, bo nie przeskrolowałbym tych 80 tysięcy klas, plus nie znam wszystkich tych klas. Więc wiadomo, że tutaj anotacja musi działać w taki sposób, że mam oryginalne zdjęcie i np. 5 predykcji modelu, co to jest za klocek.
Wtedy wybieram najbardziej prawdopodobny klocek. Muszę mieć też np. link do jakiejś „Wikipedii klockowej” dla każdego z tych polecanych klocków, żebym mógł wejść i poczytać, czy to jest na pewno ten klocek, zobaczyć więcej zdjęć.
Więc to za-setupowanie sobie, jak dokładnie anotujemy dane, wpływa na to, czy robimy to szybko czy wolno i czy robimy to poprawnie czy nie.
Eksperyment z klasyfikacją tekstu
Piotr: Pamiętam, jak jeszcze pracowałem w Allegro, robiliśmy taki eksperyment. Robiliśmy klasyfikację tekstu i albo klasyfikowaliśmy tekst na zasadzie: tu jest tekst i mamy 100 labelek, i wybierz poprawną labelkę, albo: tu jest tekst i wydaje nam się, że to jest ta labelka, i potwierdź albo nie. Powiedz, czy to jest poprawna labelka, czy nie.
Okazało się, że w takim set-upie binarnym, gdzie tylko potwierdzasz tak/nie, uzyskaliśmy dużo szybsze anotacje. Człowiek był w stanie zaanotować dużo więcej danych i te dane były dużo lepszej jakości. Bo człowiek nie musiał w głowie trzymać tych 100 labelek i zastanawiać się, która z nich będzie poprawna.
Tylko widział wiadomość, widział labelkę, widział klasę, mówił: „A, no tak, to pasuje” i ok, i lecimy dalej. I to ma naprawdę bardzo duże znaczenie.
Podsumowanie
Vladimir: Chciałem podsumować to, co usłyszałem. Czyli tak naprawdę anotacja sama w sobie to też wymaga podejścia produktowego. Nie wystarczy tylko pobrać któreś, nawet modne czy płatne, narzędzie, bo to jest jeden z możliwych klocków, który ma tam powstać. Liczy się to, co pojawia się jako wynik, też jaki czas potrzeba spędzić, aby ten wynik osiągnąć.
Ta łatwość musi być jak największa i często może być taka sytuacja, że proste narzędzia, jak arkusz czy coś takiego, nadal wchodzą w grę. Bo czemu nie? Spełniają podstawowe warunki i pomagają dostarczyć to, co jest potrzebne na koniec.
Piotr: Jasne, taki arkusz, jak w Google Docs, jest super do anotacji tekstu. Mamy jakąś wiadomość i chcemy sprawdzić, w jaki sposób anotowałem poprzednie tego typu wiadomości.
Mogę zrobić Ctrl+F i szybko mam znalezione inne podobne wiadomości, i widzę: „A, dobra, anotowałem to w taki sposób”. Jakbym miał jakieś zewnętrzne narzędzie, to pewnie mógłbym się cofnąć z widoku anotacji, przejść do widoku wszystkich tekstów, potem mieć jakieś wyszukiwanie, coś wyszukać, wejść w te wiadomości i zajęłoby mi to dużo więcej czasu.
Czasami nie warto, czasami takie proste narzędzia są po prostu dużo lepsze, dużo szybsze. Na przykład takim innym trikiem, którego często używam do klasyfikacji obrazów, i to w ogóle jest taki absurdalny trik.
Jeżeli mamy klasyfikację obrazków i mamy, nie wiem, kilka klas generalnie, pięć, dziesięć, to jak ja anotuję te dane, to otwieram sobie te wszystkie zdjęcia, wrzucam do jednego katalogu i robię sobie miniaturki tych obrazków. I teraz przelatuję i po prostu z Commandem zaznaczam obrazki jednej klasy, i jak zaznaczę sobie z 50 takich, to po prostu przenoszę do katalogu „klasa pierwsza” i zaczynam od początku tego katalogu.
Zaznaczam tę klasę, tę samą klasę, pewnie jakąś inną, generalnie tę klasę, którą widzę, że jest najpopularniejsza aktualnie, i po prostu klikam, zaznaczam z 50 przypadków i przenoszę do innego katalogu.
I skupiam się mocno na precision, a nie na recall, czyli nie zależy mi, żeby znaleźć wszystkie zdjęcia tej klasy, którą akurat mam w głowie, bo to nie ma znaczenia. Po prostu robię bardzo wiele takich przejść, bardzo dużo takich baczy i to działa niesamowicie szybko.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.

