
Sztuczna inteligencja w Stanford

Inwestycje w sztuczną inteligencją gwałtownie rosną (między innymi Reinforcement Learning). Rynek jest zdominowany przez gigantów informatycznych takich jak Google czy Baidu (chiński analog Google). McKinsey (link do raportu) szacuje, że w roku 2016 zostało zainwestowane ok. 30 miliardów dolarów w sztuczną inteligencję. Z czego 20 miliardów dolarów przez duże firmy takie jak Google.
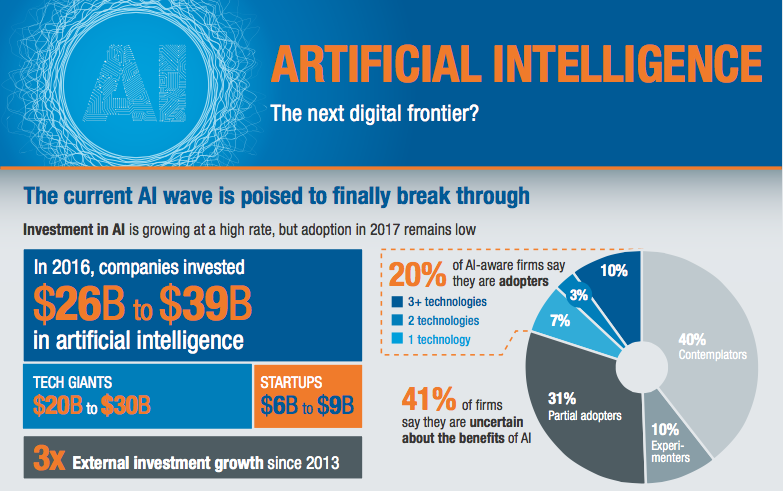
Warto zwrócić uwagę, że 90% wydatków były zainwestowane w tak zwany Research and Development. Tylko 10% na przejęcia innych projektów (tak zwana droga na skróty lub inne rozgrywki biznesowe, mniej technologiczne). Innymi słowa, duże firmy pompują niesamowitą potęgę w postaci zespołów które rozwiją sztuczną intelingencję. Inwestycje wzrosły trzykrotnie w porównaniu do roku 2013 i jak wskazuje trend, będą rozwijać się dalej. Po takich liczbach coraz bardziej rozumiesz, że świat będzie zmieniał się jeszcze szybciej… niż myślisz :).
McKinsey zrobiła wywiad z więcej niż trzema tysiącami tak zwanymi “C-level executives”. Celem było sprawdzić faktyczny stan używania sztucznej inteligencji w życiu realnym. Warto zwrócić uwagę na zróżnicowanie informacji. Wywiady objęły 14 sektorów gospodarki, z 10 krajów w Europie, Ameryce Północnej i Azji. Firmy zatrudniające pracowników od mniej niż 10 do ponad 10 tys.
Jakie są wyniki? Raport jest dość długi (80 stron), który polecam do przeczytania. Swoją drogą, daj mi znać o ile chcesz, żebym robił streszczenia takich raportów jako osobne odcinki. Teraz podam kilka faktów, które najbardziej rzuciły się w oczy:
- Inwestycje w sztuczną inteligencję są zdominowane przez AI gigantów: na dzień dzisiejszy to Google, Amazon, Baidu, Microsoft, Apple itd.
- Najwięcej inwestycji skupiło się w obszarze machine learning (ok. 5-7 mld. dolarów), następnie computer vision (2.5 – 3.5 mld. dolarów), NLP (0.6-0.9 mld.) i inne. Warto zwrócić uwagę, że oderwanie Computer Vision czy NLP od machine learning trochę nie ma sensu, ale z drugiej strony chodzi bardziej o zastosowanie biznesowe, niż rozumienie techniczne. Postaram się w jednym z odcinków bardziej wyjaśnić na przykładach na czym polega różnica i co mają wspólnego.
- Branża HighTech i motoryzacyjna okazały się najbardziej zwinne w adaptacji sztucznej inteligencji, również goni je sektor finansowy. Natomiast w ostatnim wagoniku są branże budowlana i turystyczna. Co mnie osobiście zaskoczyło. Bo ilość tematów które można w tych branżach optymalizować jest ogromna. Zobaczymy jak to zmieni się z czasem.
- Adaptacja sztucznej inteligencji wymaga wysiłku i transformacji firmy. Składa się z kilku warstw i trudno pominąć którąś z nich. Zaczynając do znalezienia tak zwanych “use cases”, ogarnięcie tematów z danymi, zbudowanie odpowiedniej infrastruktury z narzędziami do analizy, połączenie w całość i zbudowanie tak zwany “workflow” i ostatni, najtrudniejszy krok wybudowanie odpowiedniej kultury, otwartość, uczenia się na błędach jak najszybciej, chęć do eksperymentów, mierzenia wszystkiego itd.
- Chiny gonią… inwestują coraz więcej i widać, że mają ambitne plany. Dla przykładu w Azji (głównie Chiny) w roku 2010 zostało zainwestowane 100 mln. dolarów, trzy lata później w roku 2013 – 200 mln dolarów (dwa razy więcej), a jeszcze trzy lata później w roku 2016 – od 1.5 do 2.5 mld. dolarów (ponad 10 razy więcej). Co myślisz, o tym, żeby zrobić osobny odcinek o rozwoju Chin? Mało o tym kraju wiemy, ale to co tam teraz się dzieje, wygląda jak duże “wow”. Pamiętam, że kilka lat temu, było dla mnie trochę żartobliwe, że warto uczyć się chińskiego. Teraz już to brzmi dość pragmatycznie :). Od zawsze było tak, że centrum świata przesuwa się od wschodu do zachodu (kiedyś wcześniej, kilka tysięcy lat temu Indie i kraje obok były takim centrum świata). Pamiętam jak o tym czytałem, myślałem… czy to jest prawda? Jak to jest możliwe, że kiedyś centrum z zachodu przesunie się do Azji. Przecież tam jest bieda… ale chyba na naszych oczach odbywa się kolejne przesunięcie. Czy ma to sens według Ciebie?
Teraz kilka liczb biznesowych o korzyściach (z wcześniej wspomnianego raportu). Amazon osiągnął niesamowity wynik po wykupieniu firmy o nazwie Kiva w roku 2012, chociaż zaczęły używać pod koniec roku 2014 (to jest też ciekawe, na ile jest ważne firmie dojrzeć, sama technologia to za mało).
Firma Kiva produkuje roboty, które automatyzują proces zbierania i pakowania w dużych magazynach. Inwestycja była warta 775 mln. dolarów. Co udało się osiągnąć? Udało się zredukować czas na tak zwany “click to ship”. To jest czas potrzebny na dostarczenia produktu od momentu zakupu. Przedtem ludzie potrzebowali 60-75 min. gdy pracownicy przeszukują stany, zbierają produkt, pakują i wysyłają, teraz jedynie 15 min (i czas nadal zmniejsza się), chociaż pojemność magazynowa wzrosła o 50%. Mało tego, koszt operacyjny został zredukowany ok. 20% tylko dało zwrot blisko 40% od pierwotnej inwestycji.
Myślę, że warto również zacytować CEO Amazon. Jeff Bezos mówi:
„dwie rzeczy dotyczące wysyłki towarów z magazynu, który nigdy się nie zmieni, to: chęć obniżania cen i szybsza dostawa”.
Kolejny przykład Netflix (który już również jest dostępny na rynku polskim). Dzięki mądrym rekomendacjom filmów, podobnie udało się Netflixowi uniknąć rezygnacji subskrypcji i to zmniejszyłoby przychody o 1 miliard dolarów rocznie!
Trochę długi wyszedł wstęp, a teraz przechodzimy do gościa którym jest Łukasz Kidziński. Cieszę, że miałem okazję go poznać.

To jest człowiek, który rozwija swoją pasję – machine learning. Teraz jest w Stanford gdzie robi bardzo ciekawy projekt. Jest pozytywnym człowiekiem i ma super podejście do życia. Łukasz mówi:
“Wszyscy jesteśmy szczęśliwi, więc dobrze wybierać rzeczy, które dalej będą dla nas wartościowymi. Mamy ogromną liczbę możliwości, to warto podejmować dobre wybory.”
Łukasz przez dłuższy czas mieszka za granicą i trochę wstydził się, że ma akcent. Nawet proponował zrobić to po angielsku :). No właśnie i tutaj pytanie jest do Ciebie, co myślisz o tym, żeby czasem nagrywać odcinek po angielsku? Jest bardzo dużo ciekawych osób które nie mówią po polsku, natomiast waham się na ile to będzie dobrze odebrane przez Ciebie.
Łukasz opowiadał o tym jaka jest różnica życia w Polsce i Dolinie Krzemowej. Poruszyliśmy również tematy etyczne i bezpieczeństwa. Bardzo fajnie to Łukasz ujął:
“… strach przed sztuczną inteligencją może faktycznie wpłynąć na jej rozwój. Mogą pojawić się ustawy, które zupełnie nie mają sensu, więc jest pewne ryzyko na tym poziomie. Ale szczerze, zamiast bać się sztucznej inteligencji, lepiej bać się ludzkiej głupoty.“
W książce “Ja, Robot” (Isaac’a Asimova) było zakazane używać robotów na Ziemi, dlatego wysłali ich w kosmos :). Ciekawa, czy zaboczymy to już niedługo. Jakie masz zdanie?
Już nie przedłużam i zapraszam do wysłuchania.
Cześć Łukaszu… bardzo mi miło, że udało się nam spotkać. Proszę przedstaw się, kim jesteś, czym się zajmujesz, gdzie mieszkasz?
Cześć, nazywam się Łukasz Kidziński, jestem Postdoctoral Researcher czyli naukowcem na Stanfordzie. Zajmuje się biomechaniką i sztucznymi sieciami neuronowymi, zastosowaniami Big Data, data science w medycynie i biomechanice w szczególności. W tym momencie mieszkam w Palo Alto w Kalifornii.
Zgodnie z tradycją, zapytam. Co ostatnio przeczytałeś i czego ciekawego dowiedziałeś?
Ostatnio przeczytałem książkę mocno motywującą pod tytułem “The Subtle Art of Not Giving a Fuck”, napisaną przez Marka Mansona. To jest autor, który jest blogerem i przedstawicielem, w pewnym sensie, mojego pokolenia. Spróbował podejść do kwestii jak żyć, jak funkcjonować w aktualnym społeczeństwie z punktu widzenia millenials, z punktu widzenia człowieka, który dorasta w podobnym środowisku jak ja. Nie byłem trochę pewien czy to jest ciekawa książka czy nie, nie jestem jakimś wielkim fanem tego typu lektury, ale okazało się, że to jest książka, która przemawia do tego co robię teraz i do mojej wartości.

Czego się nauczyłem z tej książki? Tak jak tytuł wskazuje i jego myślą przewodnią jest idea żeby nie przejmować się rzeczami, które tak naprawdę nie mają znaczenia i skupić się nad tym, co ma dla ciebie wartość. Bo jednak mamy ograniczony czas w życiu, jest mnóstwo rzeczy do zrobienia, a w naszym pokoleniu każdy jest podekscytowany milionem rzeczy na raz.
Kiedyś mi się wydawało, że jestem wyjątkowy, że mam miliard projektów i że jestem ciekawym człowiekiem pod tym kątem, ale tak naprawdę wszyscy tak mają (milion rzeczy do zrobienia i którymi się interesujemy). Więc fajnie jest jednak zastanowić się przez chwilę i pomyśleć co tak naprawdę ma dla ciebie wartość i skupić się nad tymi rzeczami.
Fajnie to ująłeś. W ogóle, jak wczoraj szedłem spać i do żony mówiłem, że szkoda że nie mogę siebie sklonować, bo jednego siebie oddałem by do robienia tego, drugiego – do innych rzeczy, a trzeciego – jeszcze gdzieś. Bo faktycznie tych ciekawych rzeczy jest tak dużo, że bardzo trudno jest wybrać. Przynajmniej tak przeżywam.
Dokładnie. Jesteśmy bardzo uprzywilejowanymi ludźmi. Podejrzewam że zarówno Ja jak i Ty, jak i Słuchacze tego podcastu i wszyscy, którzy w tym momencie zajmują się deep learningiem, uczeniem maszynowym są ludźmi na tyle szczęśliwymi, że mają czas, możliwości i zasoby na to, żeby zajmować się takimi rzeczami.
Wszyscy jesteśmy szczęśliwi, więc dobrze wybierać rzeczy, które dalej będą dla nas wartościowymi. Mamy ogromną liczbę możliwości, to warto podejmować dobre wybory.
Podziel się, jakie ciekawy projekty, związane ze sztuczną inteligencją, zobaczyłeś będąc, jeżeli można tak powiedzieć w jednym z punktu dowodzenia AI – w kampusie Stanforda?
Najbardziej zaskakujące są projekty związane z computer vision. Tak naprawdę, mam wrażenie że AI czy sztuczna inteligencja to przede wszystkim w tym momencie computer vision. Zastosowania są fenomenalne, jak na przykład, wykrywanie raka skóry, samochody autonomiczne czy Deep Art (strona, którą stworzyłem z kolegami). Jest mnóstwo projektów, które naśladują człowieka, w których próbujemy na podstawie danych obrazków, podjąć decyzje takie, jaki bym podejmował człowiek. Sam fakt, że już jesteśmy w stanie dogonić człowieka algorytmem w tych zastosowaniach – jest fenomenalne.

Biorąc pod uwagę to, jak sytuacja szybko się zmieniła w ciągu ostatnich 10-15 lat jest dla mnie niesamowite. Bo jeszcze 10 lat temu nie bylibyśmy w stanie tak dobrze określić czy na obrazku jest pies czy kot, a teraz każdy wie, że to jest trywialny problem uczenia maszynowego i możesz budować taki algorytm w ciągu dwóch – trzech godzin, jeśli masz podstawową znajomość Python.
Zapytam teraz rzeczy takie dość praktyczne. Na ile atmosfera i cały ekosystem Doliny Krzemowej (a w szczególności na Stanfordzie) różni się od Europy i w szczególności od Polski?
Wydaje mi się, że główną różnicą jaką zaobserwowałem pomiędzy Stanfordem a uczelniami w Europie, nawet politechniką w Szwajcarii (która jest jedną z topowych uczelni w Europie), jest impact, jeżeli mówić słowem kluczowym. Czyli twój wpływ na to co się dzieje dookoła, jak duży jest ten wpływ, wyznacza to jak wartościowa jest twoja praca.

Nie twierdzę tutaj, że to jest najważniejsza wartość w tym co ludzie robią, ale tak rzeczywiście jest. Tutaj matematyką teoretyczną, na przykład, zajmuję się mniej ludzi niż w klasycznych uniwersytetach w Europie. Natomiast jest dużo więcej zastosowań, dużo więcej kierunków studiów, które próbują wiązać ze sobą różne domeny, informatykę, biomechanikę (jak jest w moim przypadku), ale też psychologię, socjologię z matematyką i statystyką.
To jest podejście, które nakłania ludzi do wybierania projektów, które są otoczone dużym ryzykiem, ale mogą przynieść duże korzyści dla społeczeństwa i które będą później rozpoznawane. Jeszcze jedna różnica, która zauważyłem, może niekoniecznie na uniwersytecie, ale ogólnie w Dolinie Krzemowej, to jak ludzie podchodzą do pomocy innym ludziom.
Tzn. każdy zakłada że jesteśmy tutaj wszyscy razem, wszyscy walczymy o swoje high impact projekty i każdy stara się pomagać innym, bo wszyscy wiemy, że Silicon Valley idzie do przodu i pojawia się jeszcze więcej możliwości, jeżeli działamy jako drużyna, a nie jako indywidualne osoby. Mimo że każdy ma swój unikalny projekt, to wciąż jest pewien związek ze Stanfordem czy z Doliną Krzemową, który pozwala iść razem do przodu.
Ostatnio uczestniczyłem w takiej dyskusji o Dolinie Krzemowej, która polegała na tym, że to jest takie unikalne miejsce, i nawet w Stanach Zjednoczonych jest bardzo ciężko powtórzyć to samo. Jest MIT (Boston), coś się dzieje w Nowym Jorku, ale nadal zupełnie coś innego niż w Dolinie. To co powiedziałeś o wspieraniu nawzajem, o tym że każdy się koncentruje nad tym, żeby mieć największy wpływ i to są czynniki, które wyróżniają Dolinę Krzemową i też uniemożliwiają to w bardzo prosty sposób skopiować.
To prawda. Jest wiele inicjatyw skopiowania Doliny Krzemowej. Wydaje mi się, że to pomaganie sobie i wiążąca się z tym zaufanie – jest tu faktycznie kluczowe. Jak wiesz, że jesteś w bezpiecznym środowisku, to jesteś w stanie zrobić dużo więcej niż jeżeli boisz się że sąsiad cię oszuka.
A które rozwiązanie ze sztucznej inteligencji najbardziej Cię zaskoczyło?
Ostatnio widziałem dużo projektów związanych z NLP (Natural Language Processing) czyli przetwarzanie języka ludzkiego. O ile 10-15 lat temu uważano, że długo nie będziemy w stanie stworzyć chatbota, który będzie w stanie rozmawiać z drugim człowiekiem na poziomie takim, że ta druga osoba nie rozpozna, że to jest komputer, który z nim rozmawia, to widać że jestesmy coraz bliżej momentu, kiedy te chatboty z ludzką inteligencją się pojawią.
Na razie rozwiązania głównie na poziomie komercyjnym, gdzie duże firmy chcą zastąpić call center przez boty i przesyłać do nich jedynie fragmenty rozmów, które przez algorytm są nierozumiane. Widać że będzie coraz więcej botów, które coraz bliższe ludzkiej inteligencji i w którymś momencie ktoś się nie zorientuje że rozmawia nie z człowiekiem. To było dla mnie najbardziej zaskakujące, że tak szybko zmieniło się przetwarzanie języka ludzkiego.
Jakie są największe wyzwania, na dzień dzisiejszy, związane ze sztuczną inteligencją i tutaj proponuję podzielić na dwa wymiary – techniczne i inne (włączając pytania etyczne, psychologiczne itd)?
Techniczne problemy są dość duże. Z tego co się orientuję, wciąż algorytmy, których używamy nie zmieniają się przez ostanie 20 lat.
Mimo że jest bardzo dużo badań prowadzonych w sztucznej inteligencji, w uczeniu maszynowym, to wciąż korzystamy ze schodzenia po gradiencie i z technik, które były używane 20 lat temu, tylko teraz mamy większą moc obliczeniową i więcej zasobów. Jeżeli dalej będziemy szli w tym kierunku zwiększania liczby danych i używania lepszych komputerów do używanie dokładnie tych samych algorytmów, to ten postęp może przestać być tak dramatyczny jak do tej pory.
Mam wrażenie, że jeżeli technicznie uda się znaleźć zupełnie inne podejście do problemów takich jak deep reinforcement learning, który pozwala na rozwiązywanie problemów bez szukania rozwiązania przez człowieka, tylko komputer próbuje sam szukać rozwiązania do problemu. Czy dowolne inne techniki mogą zadecydować o szybszym progresie. Więc, technicznie myślę że problem jest taki, że wciąż bazujemy na starych technologiach, mimo że hardware idzie do przodu.
Natomiast etycznie jest zawsze debata. Po pierwsze, czy powinniśmy się bać sztucznej inteligencji, czy sztuczna inteligencja nie przejmie maszyn i nie zaatakuje ludzi. Myślę, że to jest bardziej prozaiczne podejście do tematu i to jest droga do tego, żeby napisać ciekawy artykuł w prasie, ale im bliżej jesteś tych prawdziwych algorytmów tym bardziej człowiek sobie zdaje sprawę z tego że nie ma tutaj możliwości, żeby w tym momencie algorytmy przejęły władzę nad światem. Natomiast strach przed sztuczną inteligencją może faktycznie wpłynąć na jej rozwój. Mogą pojawić się ustawy, które zupełnie nie mają sensu, więc jest pewne ryzyko na tym poziomie. Ale szczerze, zamiast bać się sztucznej inteligencji, lepiej bać się ludzkiej głupoty.
Tak, to prawda. Jak myślisz, który następny projekt będzie w stanie zrobić kolejne “wow”, podobnie do “AlphaGo”?
Wydaje mi się, że teraz wciąż próbujemy w machine learning naśladować człowieka czyli grać tak dobrze jak człowiek w AlphaGo czy trochę lepiej, albo rozpoznawać na obrazkach to, co rozpoznaje człowiek, ale trochę lepiej. Jak przejdziemy na poziom, kiedy maszyny będą w stanie same wymyślać coś, czego człowiekowi by nawet nie przyszło do głowy, to przyjdzie ten moment kolejnego “wow”.
Trudno mi jest tutaj podać konkretny przykład, ale wyobrażam sobie sytuacje, na przykład, kiedy w healthcare (medycynie), algorytm na podstawie danych z telefonu komórkowego, zegarka i paru innych sensorów będzie w stanie przewidzieć cukrzycę czy coś, czego doktor nie byłby w stanie przewidzieć, bo nie jest w stanie ogarnąć tak dużej ilości danych.
Osobiście mam nadzieje, że te większe kolejne zyski i kolejne benefity ze sztucznej inteligencji pojawią się w medycynie.
Bo póki co sztuczna inteligencja jest stosowana na giełdzie papierów wartościowych, w autonomicznych samochodach czy do gier planszowych, a zastosowań tam, gdzie naprawdę mogłaby się przydać, jeszcze nie ma tak dużo. Dlatego mam nadzieje że ten następny “wow” będzie w medycynie.
Wspomniałeś już o “Reinforcement learning” albo po polsku uczenie ze wzmocnieniem, też w twoim głosie czuć ten potencjał, jeżeli chodzi o to rozwiązanie. Ale najpierw zróbmy takie wprowadzenie – co to jest i jak to działa?
Uczenie ze wzmocnieniem polega na uczeniu algorytmu wewnątrz jakiegoś środowiska, w którym ma podejmować decyzje. To jest tak naprawde nauka o podejmowaniu deyzji z jednej strony, a z drugiej naukowcy starają się naśladować sposób w jaki uczy się dziecko. Wyobraźmy sobie że jesteśmy dzieckiem dwuletnim i staramy się nauczyć chodzić czy wykonywać proste czynności.
W tym momencie na początku poruszamy rękami, nogami, widzimy jak nasi rodzice się poruszają, ale wciąż nie jesteśmy w stanie dokonać tego, co chcemy, wstać i pójść do przodu. Ale powtarzając nasze eksperymenty, zauważyłem jakieś zależności pomiędzy aktywowaniem mięśni w różnych kończynach i z czasem uczymy się jak wstać i jak iść do przodu. I naśladując tą idee naukowcy, które w uczeniu ze wzmocnieniem starają się rozwiązywać inne problemy, jak na przykład, problem które akcje kupić na giełdzie.
Jesteśmy agentem i chcemy kupić/sprzedać akcje na giełdzie i wykonując różne doświadczenia, tak jak dziecko, czyli kupując/sprzedając uczymy się czegoś na temat środowiska, w którym jesteśmy. I z czasem, teoretycznie, może będziemy w stanie podjąć decyzje tak, aby zoptymalizować nasz cel, jak w tym przykładzie – zarobienie jak najwięcej pieniędzy.
Jaki związek Reinforcement Learning ma ze sztuczną inteligencją czy machine learning? I czym dla Ciebie jest sztuczna inteligencja?
Związek jest dość bezpośredni, tzn. próbujemy naśladować ludzki mózg, jak w przypadku tego dziecka, to w pewien sposób modelujemy sztucznie ludzką inteligencję. Dlatego to jest tak naprawde bardzo naturalna gałąź sztucznej inteligencji.
Dla mnie sztuczna inteligencja to jest naśladowanie ludzkich decyzji w danym środowisku, tzn. dla danego środowiska chcemy podjąć decyzje podobną do tej, którą podejmuje człowiek lub lepszą, w kontekście jaki zdefiniujemy. Można życie ludzkie zdefiniować na różne sposoby, mamy swoje codzienne cele i żeby je osiągnąć, podejmujemy różne decyzje. Maszyna, która potrafi podejmować podobne decyzje to dla mnie sztuczna inteligencja.
Już wspomniałeś o tym, że algorytmy, które używamy były znane kilkadziesiąt lat temu. Pytanie jest takie, czemu akurat teraz się stało głośno o sztucznej inteligencji, a w szczególności o Reinforcement Learning (RL). Co się zmineiło tak naprawde?
Jedna z głównych zmian to nasze zasoby. Duże firmy informatyczne takie jak Google są w stanie włączyć tysiące maszyn i szukać rozwiązań do różnych problemów, rozkładając problem na te maszyny.
Problem z uczeniem ze wzmocnieniem do tej pory był taki, że modelowanie środowiska, w którym miał się poruszać nasz agent, jak to dziecko o którym mówiłem, czy agent na giełdzie, wymagało bardzo dużych zasobów, ale też modelowanie całego algorytmu czyli sieci neuronowej, która modelowałą decyzje, też była bardzo duża. Jeżeli chcielibyśmy modelować trudne decyzje, to niezbędne zasoby byłyby ogromne.
Jeżeli chcielibyśmy modelować proste problemy, było to do tej pory możliwe, przy czym proste problemy były naprawdę bardzo proste, czyli granie w kółko i krzyżyk. Może tutaj wyolbrzymiam, dało się też rozwiązywać nieco trudniejsze problemy, ale to nie była ta skala, która jest możliwa w tym momencie.
Drugi powód dlaczego stało się tak głośno to to, że duże firmy faktycznie zaczęły się zajmować RL jako możliwością rozwiązywania problemów, które wcześniej nie były możliwe do rozwiązywania. Tzn. ta metodologia pozwala na podejście do problemów których nie ma konwencjonalnych rozwiązań. Na przykład, można wyobrazić sobie szukanie lekarstwa na raka, w tradycyjnym sensie są naukowcy którzy próbują tworzyć różne nowe leki i starają się wprowadzić te leki na rynek.
Ten proces trwa bardzo długo i tutaj główna nadzieja jest w tym, że będziemy mieli szczęście. Natomiast RL pozwala nam na modelowanie problemów w pamięci komputera, więc nie jesteśmy ograniczeni liczbą ludzi, którzy pracują nad problemem, tylko uruchamiamy komputery, które liczą środowisko i szukają rozwiązań w danym środowisku. Więc jest szansa że będziemy mogli przyspieszyć postęp w niektórych dziedzinach dzięki tej technice.
Pamiętam jak pierwszy raz dowiedziałem się o Reinforcement Learning, byłem bardzo zadowolony i szczęśliwy, że takie rzeczy istnieją i można symulować środowisko. Natomiast pytanie mam dość praktyczne, o ile taka wiedza, którą teraz mamy nie jest tylko wiedzą która ma sens w ośrodkach badawczych i jeszcze nie dojrzała do tego poziomu, żeby zacząć używać to w biznesie.
Oczywiście wspomniałeś już o tych papierach na giełdzie, natomiast wydaje mi się że, w tej chwili przynajmniej, o RL mówią takie firmy jak OpenAI, DeepMind lud Stanford (jako uczelnia) i po przeczytaniu tych papierów i innych materiałów, ciężko zrozumieć jednoznacznie jak można wykorzystać tę wiedzę już teraz w konkretnym biznesie. Jak myślisz, na ile ta wiedza już jest adoptowana czy musimy jeszcze poczekać z 5 lat, żeby te pomysły były używalne w zwykłym biznesie?
Tak, zdecydowanie trzeba jeszcze poczekać żeby to miało praktyczne zastosowanie. Jest duże ryzyko, jak w wielu innych dziedzinach, że jeżeli zainwestujemy w to dużo czasu i pieniędzy, wciąż może to nie dać takich rezultatów jak kiedyś chcieliśmy.
Natomiast ludzie wciąż wierzą, że RL pozwala na podejście do tematu zupełnie inne, niż klasyczne podejście, tzn. ze zwykłym uczeniem maszynowym staramy się naśladować człowieka, natomiast tutaj definiujemy problem i liczymy na to, że algorytm sam znajdzie rozwiązanie, nie mając żadnej ludzkiej wiedzy jako nadzoru. Odpowiadając na Twoje pytanie, faktycznie musimy na to poczekać, ale potencjalna nagroda jest na tyle duża, że wciąż jest warto w to inwestować w tym momencie.
Opowiedz więcej o projekcie OpenSim (github)… Jaki jest cel, jak jest plan go osiągnąć jaki jest postęp?
To jest aplikacja stworzona w laboratorium w którym teraz pracuję. Tworzona przez 10-15 programistów od około 10 lat. Jest to software, który pozwala na modelowanie ludzkiego ruchu, jak również ruchu dowolnych innych zwierząt czy nawet dinozaurów i zwierząt, które nigdy nie istniały czy robotów. Jest to aplikacja do symulacji fizycznych, przy czym w przeciwieństwie do innych istniejących programów, tutaj możemy modelować bardzo efektywnie ludzkie mięśnie. Celem tego projektu jest pomoc w modelowaniu mięśni, w modelowaniu chorób związanych z chodzeniem, z poruszaniem się, chorób neurologicznych.
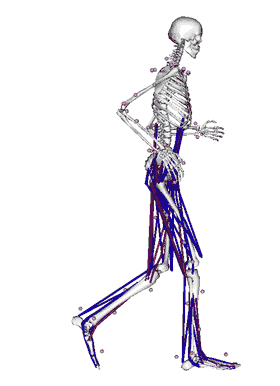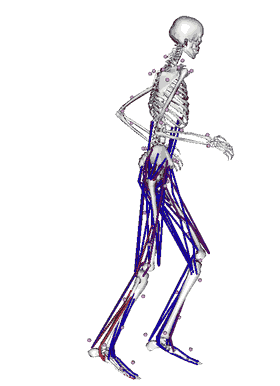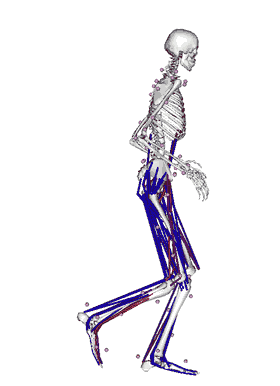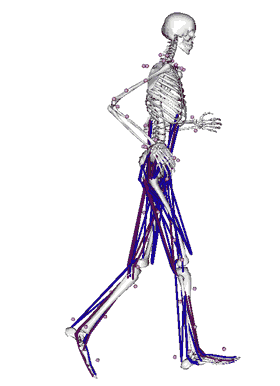
Praca z tym softwarem polega na tym, że przychodzi pacjent do kliniki, gdzie pobierane są różne pomiary tego, jak pacjent się porusza, jak chodzi. Te pomiary są potem transportowane do OpenSim. OpenSim jest w stanie policzyć które mięśnie były aktywowane, które stawy były obciążone, które kości były obciążone i na tej podstawie chirurdzy są w stanie podjąć decyzje na temat tego, jaką interwencje zalecić danemu pacjentowi.
Używam tego programu z trochę innej perspektywy, mimo tego że to jest główna motywacja do używania OpenSim. Z kolegami z mojego labu pomyśleliśmy, że można podejść do podobnych problemów od drugiej strony i zamiast pobierać dane od pacjentów, spróbować zrozumieć jak działa ludzki mózg, podejmując decyzje, które mięśnie aktywować, żeby pójść do przodu, na przykład. Stworzyliśmy pewną nakładkę na ten software, który pozwala na modelowanie ludzkiego poruszania się poprzez aktywowanie różnych mięśni. Żeby aktywować te mięśnie, zrobiliśmy środowisko RL, w którym naukowcy mogą stworzyć kontroler czy sztuczną inteligencję, stworzyć mózg dla symulacji w OpenSim.
Zadaniem naukowca czy naszym problemem badawczym jest symulowanie ludzkiego mózgu w środowisku komputerowym (w środowisku OpenSim). Stworzyliśmy środowisko, z którego mogą korzystać naukowcy z całego świata i zrobiliśmy konkurs wokół tego środowiska, w którym ludzie mogą budować swoje własne sztuczne mózgi dla naszego wirtualnego awatara w OpenSim.

Ten konkurs jest jednym z pięciu konkursów na największej konferencji Machine Learning i Neurologii NIPS, która odbędzie się w grudniu w tym roku. Więc zachęcam wszystkich do udziału w tym konkursie. Podstawowa znajomość Python i koncepcji machine learningowych powinny być wystarczające, żeby wystartować i może nawet zająć dobrą pozycję. Konkurs jest o podobnej strukturze, jak konkursy Kaggle, tylko bardziej nastawiony na problemy i pytania naukowe, niż na pytania biznesowe.
Przyznam się, że poruszasz bardzo ciekawe tematy. W ogóle jak zobaczyłem ten projekt, to pomyślałem o czymś innym. Pomyślałem, że chcemy nauczyć robota chodzić po to żeby nauczył się chodzić. Dla nas – ludzi ten problem jest trywialny, po prostu wstajesz i idziesz, nawet nie zastanawiamy się nad tym jakie to jest skomplikowane.
Natomiast osoby, które budowali roboty, wiedzą jak ciężko jest zrobić tak, żeby robot trzymał równowagę. Na przykład, Boston Dynamics robią fajne postępy w tym kierunku, ale to jest jedna z nielicznych firm, która jednak radzi z tym problemem, bo problem jest faktycznie skomplikowany. I pomyślałem właśnie, że w tym kierunku ta wiedza będzie wykorzystana. Ale to, co mówisz, ma znacznie większy cel praktyczny dla ludzi.
W naszym laboratorium staramy się bardziej skupiać się na zastosowaniach medycznych, więc potencjalnym zastosowaniem byłoby bardziej tworzenie tak zwanych assistive devices – urządzeń wspomagających chodzenie.
Gdybyśmy lepiej rozumieli jak człowiek wysyła sygnały do swoich kończyn, będziemy w stanie lepiej kontrolować dodatkowe sygnały, które powinne pochodzić z tych urządzeń wspomagających, więc rzeczywiście bardziej się skupiamy na mięśniach i ludzkiej biomechanice, niż na kontrolowaniu robotów.
Oprócz zastosowań medycznych są zastosowania typowo naukowe i jednym z nich jest zrozumienie jak ludzki mózg działa. Tutaj nie twierdzę że algorytm deep learning będzie w stanie odtworzyć ludzki mózg, mamy nadzieję że pojawią się podobne schematy w wysyłaniu sygnałów. W sztucznym środowisku, jak i w środowisku naturalnym, gdzie możemy mierzyć te sygnały czy używając różnych innych modułów.
Już wspomniałeś że każdy może się dołączyć do tego projektu i zapytam może wprost – jaka jest potrzebna pomoc i jeżeli ktoś się zdecyduje, to jak może to zrobić?
Przede wszystkim zachęcam wszystkich do udziału i tutaj sam udział jest pomocą. Nie jestem ekspertem Deep Reinforcement Learning, a raczej użytkownikiem tych systemów. Stwierdziłem że łatwiej i więcej wartości będzie przez stworzenie środowiska w którym każdy może próbować swoje własne algorytmy, niż jakbym wziął istniejące algorytmy, zamknął się w biurze na parę tygodni i próbował je jeden po drugim.
Zachęcam wszystkich do próbowania i testowania różnych algorytmów. Jest to dobra droga do tego, żeby się nauczyć tego co zmieniło się w RL przez ostatnie lata czy nauczyć się od zera sztucznych sieci neuronowych. To jest dobre środowisko, żeby ucząc się mieć jakąś kontrybucję w nauce i postępie w rozumieniu ludzkiego mózgu.
Trzymam kciuki żeby ta inicjatywa szła do przodu, a teraz zmienię trochę temat. Czym jest DeepArt i proszę wyjaśnij w miarę prostym językiem (z przykładami) jak to działa?
DeepArt to jest strona internetowa i brand, który stworzyliśmy z kolegami z Polski i z Niemiec. Używamy tam algorytmów właśnie stworzonych przez kolegów z Niemiec, które pozwalają na stworzenie obrazów na podstawie zdjęć i stylu wybranego artysty.
Przez styl rozumiem styl malarski. Możemy sobie wyobrazić, na przykład, Van Gogha, który ma bardzo charakterystyczny styl malowania, charakterystyczne krawędzie obiektów, które umieszcza na swoich obrazach. DeepArt pozwala na przeniesienie tych charakterystyk na dowolne zdjęcie, które wrzucimy do algorytmu. Czyli algorytm jest w stanie, powtarzając pewną procedurę kilkaset razy, stworzyć zdjęcie które odpowiada treścią zdjęciu, które do algorytmu podaliśmy, tylko ma zupełnie inną formę co do wybranego stylu.
Możemy o tym myśleć jako oddzielenie formy od treści w takim”witkiewiczowym” stylu, tzn. formą jest styl artysty, który chcemy zastosować, a treścią są obiekty, które znajdują się na fotografii, którą chcemy przetworzyć.
Jakie widzisz zastosowanie praktyczne podobnych rozwiązań?
Zależy od tego, jak zdefiniujemy praktykę. W pewnym sensie, jednym z zastosowań jest zastosowanie rekreacyjne. Każdy cieszy się jak ma ładny obraz na ścianie. Kupujemy czasami obrazy od pań malujących pejzaże na ulicach czy inne droższe dzieła sztuki. To samo w sobie jest w pewnym sensie zastosowaniem.
Innym zastosowaniem tej konkretnej technologii mogłoby być próbowanie odnawiania dzieł sztuki. Moglibyśmy wziąć jako zdjęcie – zdjęcie istniejącego obrazu, ale może nieco zniszczonego, a jako styl – styl danego artysty i w taki sposób uzupełnić brakujące części obrazu przez części, które wynikają naturalnie ze stylu danego artysty.
Kolejne zastosowanie, któremu blisko bardziej rozrywki, mogłoby być zastosowanie podobnych koncepcji w literaturze czy w muzyce. W literaturze też możemy oddzielić formę od treści. Jak myślimy o Panu Tadeuszu, jest tam konkretny styl, jak został napisany, ale też jest konkretna treść. Jak weźmiemy treść i zmienimy styl na styl hip-hopowy, to powstanie zupełnie inny utwór wciąż o tej samej treści. I teoretycznie to samo można zrobić w muzyce. Mam nadzieje że w przeciągu kilku lat pojawią się takie zastosowania.
Wydaje mi się, że tak, takie rzeczy już pomału się dzieją, być może jeszcze nie tak dynamicznie jak z obrazkami, ale DeepBach i podobne przykłady…
Tak, zgadza się, jest parę projektów w których próbują tworzyć muzykę i tworzyć literaturę. Oddzielenia form od treści w tak jasny sposób, jak to zrobione w DeepArt jeszcze nie widziałem, ale to jest kwestia czasu.
W DeepArcie motywacją tego algorytmu było to jak człowiek jest w stanie oddzielić formę od treści i naukowcy w Tubingen pracowali nad reprezentacją elementów obrazu. Jednym z elementów jest forma, drugim – treść, można rozbić te elementy jeszcze bardziej. Mam wrażenie że w różnych innych dziedzinach rozdzielenie dużych całości na mniejsze części i potem rekombinacja tych części może być zastosowana. Jeżeli spojrzymy na to z bardzo dalekiej perspektywy, to zastosowań jest bardzo dużo.
Teraz pracujesz w na uczelni, robisz fajny projekt. Ale warto powiedzieć, że masz umysł przedsiębiorcy. Założyłeś pierwszą firmę, tuż po pierwszym roku studiów, zrealizowałeś kilka projektów. Co możesz doradzić przedsiębiorcom, które chcą zacząć używać uczenia maszynowego. Czego należy unikać, a gdzie odwrotnie pozwolić sobie popełniać własne błędy? Podziel się swoją opinią?
Z tego co widzę w Dolinie Krzemowej, uczenie maszynowe już nie jest wartością samą w sobie. Startupy, które tworzy się tylko dlatego, że jest tam machine learning, i dostają pieniądze, tylko dlatego że są związane ze sztuczną inteligencją, wciąż powstają. Ale to jest kwestia krótkiego czasu, kiedy to przestanie być wartością samą w sobie i wszyscy będą zakładać, że jeżeli twoje rozwiązanie może korzystać z uczenia maszynowego, to będzie korzystać z uczenia maszynowego.
To jest w pewnym sensie tak, jak 20 lat temu było z tworzeniem stron internetowych. Jeszcze niedawno wiedza na temat tego jak zarządzać cloudem, dużą liczbą serwerów, jak przetwarzać dane w Hadoopie też było bardzo wartościowe. Taki machine learning teraz jest bardzo wartościowy, ale ten trend powoli zanika. Jeżeli miałbym dać poradę, jak budować firmę dookoła machine learningu, to przede wszystkim warto pomyśleć, jaka jest wartość dodana, a nie liczyć na to, że technologia sama się sprzeda, bo niestety lub stety coraz więcej osób ma te podstawowe zasoby machine learningowe.
Dlatego zalecałbym szukania pomysłów, które wykraczają dwa-trzy kroki do przodu. Zaryzykowania w tym kierunku, zamiast skupiać się na, na przykład, konsultacji data science czy machine learningu i budowania prostych narzędzi dookoła tego. Jest dużo startupów, które się tym zajmują i jeżeli wymyślą super narzędzia, to też jak najbardziej to działa, bo też nie chcę ujmować takim podejściu. Takie firmy, które powstały w ten sposób 5 lat temu, mają całkowicie prawo bytu, ale nie zalecałbym startowanie takich pomysłów dzisiaj, na przykład.
Jeżeli ktoś myśli o zrobieniu dużej firmy, startując z czegoś bardzo małego i chcę pójść szybko do przodu w stylu Doliny Krzemowej to zdecydowanie polecam przyjechać do Doliny i spędzić tutaj trochę czasu.
To jak tutaj podchodzi się do rozwiązywania problemów, do zakładania firm i do szukania partnerów, finansów na te przedsięwzięcia wygląda zupełnie inaczej niż w Europie, przynajmniej z mojego doświadczenia.
Ostatnio czytałem artykuł, który miał dość kontrowersyjną nazwę, a mianowicie “Najbliższe kilka lata inwestorzy nie będą inwestować w rozwiązania ze sztuczną inteligencją“ i później to było rozwinięte i właśnie mniej więcej chodziło o to, co powiedziałeś. Bo tak naprawdę w najbliższe 2 lata każdy projekt będzie miał pewne algorytmy uczenia maszynowego i same w sobie użycie to nie będzie wiele warto. Tak samo jak ktoś teraz powie że używa jakiś język programowania, a to już jest oczywiste.
Teraz użycie deep learningu nawet jest już bardzo bardzo proste. Zbudowanie modeli deep learningowych to jest kwestia 30 linii kodu i dużej liczby obrazków, więc te state of the art algorytmy są na wyciągnięciu ręki. A skoro jest tak, to nie można już zakładać że skoro je znam, to nikt inny nie zna, bo tak nie jest.
Zapytam teraz może dość prywatne pytanie. Jakie masz plan na najbliższe 5 lat? Co chcesz osiągnąć, zwłaszcza w tematach związanych z AI?
Osobiście bardzo się cieszę że jestem w Dolinie Krzemowej na Stanfordzie i chcę jak najbardziej skorzystać z tego, co ta Dolina oferuje. Wciąż z żoną chcemy wrócić do Europy, jak tylko skorzystamy z tego, co Dolina Krzemowa dla nas oferuje.
Popatrzymy jak tutaj się podchodzi do biznesu, do nauki i może nie będziemy próbować tego replikować w Europie. Przynajmniej przywieziemy to doświadczenie i spróbujemy motywować młodych i motywować ludzi dookoła siebie iść do przodu szybciej i podejmować decyzje tak jak podejmuje się tutaj.
Zgodnie ze swoim systemem wartości, ale też próbować postawić impact jako słowo kluczowe w wielu przedsięwzięciach. Myślę że to główna rzecz, z których tutaj nauczyliśmy i z chęcią przywieźli byśmy do Europy.
Jak można Ciebie znaleźć w sieci?
W sieci zacząłem udzielać na Twitterze pod nickiem @kidzik. Można mnie znaleźć na mojej stronie internetowej i tam są linki zarówno do Twittera, Facebooka, Linkedina i mój email. Zachęcam jak najbardziej do kontaktu, bardzo chętnie włączam się w różne projekty i chętnie pomogę w kontakcie z Doliną Krzemową lub jako konsultant w projektach w Polsce. Jestem otwarty na wszelkie przedsięwzięcia.
Dziękuję Ci bardzo za Twój czas, że znalazłeś możliwość porozmawiać, mimo tego, że strefy czasowe są różne (u Ciebie jest prawie noc, u mnie rano). Dzięki jeszcze raz.
Też bardzo dziękuję i się podziwiam że wstałeś o 6 rano, żeby ze mna porozmawiać. Rzadko się spotykam z takim zawzięciem, więc bardzo się cieszę.
Myślę że było warto. Dziękuję.
Jakie masz wrażeniu po wywiadzie?
Mnie bardzo spodobało się, miałem również sporo motywacji już po spotkaniu. Bardzo mnie motywują ludzie które robią to co lubią, cieszą się z życia, robią tu i teraz ale też mają plany na przyszłość.. Wiadomo, zawsze są trudności, ale chodzi o to, na co zwracamy uwagę i jak je pokonujemy. Jest to inspirujące dla mnie.
Dziękuję wszystkim za udostępnianie informacji o Biznes Myśli na Facebook’u, Twitterze.
Tomasz Pluszczyk dziękuję Ci za twój retweet. Krzysztof Raczyński dziękuję Ci za motywację przygotowania słowniczka pojęć (pokazując, że jest taka potrzeba). Jest wiele rzeczy które wspominam, które warto wg mnie zrobić. Ale jeżeli nie dostaje informacji zwrotnej, to nagle priorytet się zmniejsza.
Tak jak mówiliśmy z Łukaszem, jest tak dużo ciekawych rzeczy, że ciężko wybrać. Dlatego mam również taki filtr. Innymi słowy, jak jest potrzeba, to się zrobi :). Proszę daj mi znać, jak jeszcze Ci mogę pomóc w tematach związanych ze sztuczną inteligencją. Tak jak już mówiłem, bardzo mnie to cieszy możliwość pomagać w tematach które są moją pasją.
Do mnie napisało kilka osób z pomysłami o czym warto jeszcze nagrać. To jest super! Bardzo to doceniam i pomaga mi to nadać priorytety kolejnym odcinkom. Ilość tematów o których można nagrywać – jest bardzo duża. Ale każdy odcinek potrzebuję sporo czasu (być może mój perfekcjonista ciąglę coś próbuję ulepszyć) i dodatkowych wydatków. Zależy mi na tym, żeby poruszać tematy które są wartością dla Ciebie. Możesz do mnie pisać w dowolny wygodny dla Ciebie sposób: facebook, twitter, linkedin, mail czy forma kontaktu na BiznesMyśli.
Mam dobrą nowość dla Ciebie. Pewnie jak już słyszałeś, pracuję teraz nad warsztatem w ramach DataWorkshop. Który będzie dostępny przez internet, i mam nadzieje, że pomoże Ci zacząć używać uczenie maszynowe. Warsztat potrwa prawdopodobnie około 8 tygodni i rozpocznie się z dużym prawdopodobieństwem w październiku (szczegóły będą trochę później).
Łukasz wspominał o projekcie OpenSim i Reinforcement Learning który jest tam używany. Czasem wydaje się, że to jest zbyt skomplikowany temat i tylko naukowcy na Stanford mogą tym się zajmować. Właśnie chcemy wspólnie z Łukaszem obalić ten mit. Zapraszam do udziału w warsztacie gdzie między innymi dowiesz się co to jest i jak możesz pomóc OpenSim (nie mając doktora czy nawet magistra).
Dziękuję Ci bardzo za Twój czas i życzę wszystkiego dobrego. Do usłyszenia.
Książka polecana przez gościa
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.

2 komentarze
Dokato
Bardzo ciekawy i profesjonalnie przygotowany odcinek. Jestem za i streszczeniami ciekawych artykułów i raportów, ale też za odcinkami po angielsku. To drugie z pewnością zwiększy liczbę ciekawych rozmówców.
Vladimir
Dziękuję Ci bardzo Dokato :). Już dostaję pozytywne odzew o nagranie po angielsku, więc pewnie będę eksperymentował w najbliższej przyszłości.