

Programowanie probabilistyczne

Z tego odcinka dowiesz się:
- Pandemia a media. Zastanowimy się, kto oficjalnie ogłosił pandemię i jak media wpływają na nasze postrzeganie rzeczywistości.
- Probabilistyczne podejście. Dowiesz się, jak probabilistyczne programowanie pomaga lepiej radzić sobie z niepewnością w analizie danych.
- Programowanie probabilistyczne. Adam Goliński, doktorant z Oxfordu, opowie, czym jest probabilistyczne programowanie i jakie ma zastosowania.
- Przykłady praktyczne. Poznasz przykłady zastosowania probabilistycznego programowania w biznesie, finansach i fizyce.
- Kompresja danych. Zrozumiesz, jak nowoczesne metody uczenia maszynowego mogą ulepszyć kompresję obrazów i wideo.
- Kariera naukowa. Adam podzieli się doświadczeniem z doktoratu na Oxfordzie i opowie, jak wygląda jego codzienna praca naukowa.
- Fundacja Polonium. Dowiesz się o działalności Polonium Foundation, która łączy polskich naukowców za granicą z rodzimym środowiskiem naukowym.
Żyjemy w czasach, kiedy prognozowanie jest trudne, a będzie jeszcze ciężej. Mamy dość trudną sytuację związaną z koronawirusem, czasami nazywaną pandemią. Dlaczego ma być trudniej?
Dlaczego też tzw. pandemia? Kto stwierdził, że ta pandemia istnieje? Pomijając tweet z ONZ: „Dokonaliśmy zatem oceny, że COVID-19 można scharakteryzować jako pandemię”, a można tego nie robić. Słowo kluczowe – można. To jest dość ciekawa sytuacja, kiedy słyszysz komunikat również z oficjalnych kanałów, od prezydentów wielu krajów, że jest pandemia, ale nie możesz znaleźć potwierdzenia i źródła.
Jaki organ oficjalnie stwierdził oraz na podstawie czego i wziął za to odpowiedzialność? Być może źle szukałem. Jeżeli masz jakąkolwiek informację na ten temat, to bardzo Cię proszę – podziel się nią. Mam na myśli oficjalne dokumenty – linkowanie do wiadomości czy tweetów to nie jest dokument, ponieważ Twitter nie bierze za to odpowiedzialności.
Oczywiście, nie chodzi teraz o kwestionowanie tego, czy wirus jest, czy go nie ma. Chodzi o odpowiedzialność. Sytuacja, w której teraz się znajdujemy, jest dość wyjątkowa. Kto jest odpowiedzialny za paraliż spowodowany ogłoszeniem pandemii?
Idąc tą drogą, możemy wywnioskować, że światem zaczynają rządzić kanały masowego przekazu. A może nie zaczynają? Być może one już od dawna rządzą? W takiej sytuacji zaczynasz coraz bardziej traktować każdą wypowiedź (nawet na najwyższych szczeblach) jako hipotezę, czyli prawdopodobieństwo. Jest szansa, że to, co słyszysz w tej chwili, od osoby na bardzo wysokim stanowisku w oficjalnej telewizji, może być prawdziwe, ale również może być nieprawdziwe.
Dzisiaj porozmawiamy o probabilistycznym programowaniu. Jak to się łączy z pandemią? Idea jest taka, że w odróżnieniu od tego klasycznego podejścia zamiast operowania pojedynczą liczbą (jako prawda całkowita w ostatniej instancji), to operujemy tzw. rozkładem. Innymi słowy, zamiast powiedzieć, że wynik jest równy 5, mówimy, że wynik charakteryzuje się pewnym rozkładem (podajemy do charakterystyki).
Czyli np. może być 5, może być 10, ale prawdopodobnie jest 7,5 i to prawdopodobieństwo wynosi np. 95%. Takie podejście w obecnym czasie wydaje się być narzędziem powszechnie używanym, żeby przynajmniej w jakiś sposób się odnaleźć w tej rzeczywistości.
Gościem jest Adam Goliński, doktorant na Oxfordzie. Prowadzi ciekawe badania m.in. na temat probabilistycznego programowania. Podzieli się swoim doświadczeniem i powie m.in. o tym, jak zainteresował się na tematem kompresji obrazu czy wideo. Wspomni też o doktoracie w Oxfordzie – czy warto, jak on przebiega.
Cześć Adam. Przedstaw się: kim jesteś, czym się zajmujesz, gdzie mieszkasz?
Nazywam się Adam Goliński. Mieszkam i studiuję w Oxfordzie w Wielkiej Brytanii. Jestem doktorantem, aktualnie zaczynam czwarty rok swojego doktoratu.
Co ostatnio fajnego przeczytałeś?

Zastanawiałem się nad tym pytaniem – wiedziałem, że padnie. Ostatnio przeczytałem „Ali and Nino”. Jest to książka usytuowana zaraz przed wybuchem I wojny światowej na terenach aktualnego Azerbejdżanu. Większość akcji dzieje się w Baku, ale część na terenach Armenii (dzisiejszej Gruzji). Jest to bardzo ciekawa książka, dla wszystkich ludzi ciekawych okolic południowego Kaukazu.
Ostatnio prowadziłem wywiad z Adamem Kosiorkiem, który zrobił doktorat w Oxfordzie. Co ciekawego porabiasz w trakcie doktoratu? Jakimi tematami się zajmujesz? Co już udało Ci się osiągnąć?
Moim głównym zainteresowaniem jest dyscyplina probabilistic programming (programowanie probabilistyczne). Jest ona pododdziałem probabilistycznego uczenia maszynowego. To jest mój obszar zainteresowań do tej pory, a aktualnie rozwijam coraz większe zainteresowanie w kierunku kompresji danych, która również bardzo blisko wiąże się z moimi poprzednimi badaniami.
Programowanie probabilistyczne to dzisiejszy temat główny. Pewnie też zahaczymy o tematy kompresji danych. Zacznijmy od podstaw: czym jest programowanie probabilistyczne?
Programowanie probabilistyczne to cały zestaw narzędzi do modelowania statystycznego. Programowanie probabilistyczne to zbiór języków programowania, które zostały zbudowane na bazie istniejących języków programowania, które służą do zaprogramowania każdej funkcji, którą możemy obliczyć komputerowo.
Dodatkowym ich elementem jest to, że skupiają się na wyrażaniu rozkładów prawdopodobieństwa. Te rozkłady prawdopodobieństwa są jednym z fundamentalnych obiektów dostępnych w języku programowania w taki sposób, że możemy je komponować w bardziej złożone modele statystyczne, używając różnego rodzaju obliczeń. Czyli tych właściwości języka, na których zazwyczaj ten język probabilistyczny został zbudowany. Zatem to jest jeden element języków programowania probabilistycznego.
Drugi element, który również występuje w większości z nich, to misja zautomatyzowania procesu tzw. inferencji. Zazwyczaj gdy budujemy model probabilistyczny, naszym celem jest być w stanie odpowiedzieć, jak niektóre zmienne w tym modelu prawdopodobieństwa wpływają na inne zmienne.
Powiedzmy: mam jakiś rozkład prawdopodobieństwa po dwóch lub więcej zmiennych; jeśli zaobserwuję jedną z tych zmiennych, w jaki sposób zmienia to rozkład prawdopodobieństwa po drugiej zmiennej? Na przykład gdy mówimy o jakichś modelach machine learningowych, powiedzmy probabilistycznej regresji liniowej, mam pewien zbiór danych, które są obserwowalnymi zmiennymi w naszym probabilistycznym modelu oraz zbiór parametrów tej krzywej, którą próbujemy „sfitować” do tych danych, które są ukrytymi parametrami.
Pytanie, które byśmy zadali w tym przypadku, to jaki jest rozkład prawdopodobieństwa po tych ukrytych parametrach modelu, znając zaobserwowane wartości tych danych, do których próbujemy dopasować tę krzywą?
Tym drugim elementem języków programowania probabilistycznego jest to, że one próbują automatyzować ten proces inferencji. Proces inferencji probabilistycznej to olbrzymie zagadnienie, wręcz kluczowe w całym dziale statystyki, czy uczenia maszynowego. Również cel tych języków programowania jest bardzo ambitny.
Polega on na tym, że te języki próbują implementować algorytmy, które pozwoliłyby przeprowadzać ten proces inferencji dla dowolnego modelu, który może zostać wyrażony w danym języku programowania. Bardzo często nie jest to możliwe do zrobienia w wydajny sposób, więc w niektórych problemach, modelach będziemy w stanie przeprowadzić ten proces inferencji znacznie szybciej, jeśli ten proces i odpowiedni algorytm inferencji jest dopasowany do modelu.
Kolejnym elementem więc tych probabilistycznych języków programowania jest to, żeby dopasować algorytm inferencji, który zostanie użyty do konkretnego modelu, który użytkownik wyraził w taki sposób, żeby ten algorytm inferencji wykorzystał strukturę owego problemu. To jest, w takim telegraficznym skrócie, czym są probabilistyczne języki programowania.
Podałeś przykład z regresją liniową. Może weźmiemy konkretny przykład, wprowadźmy zmienne i pokażmy, co to znaczy na przykładzie. Wydaje się, że tak będzie to bardziej zrozumiałe.
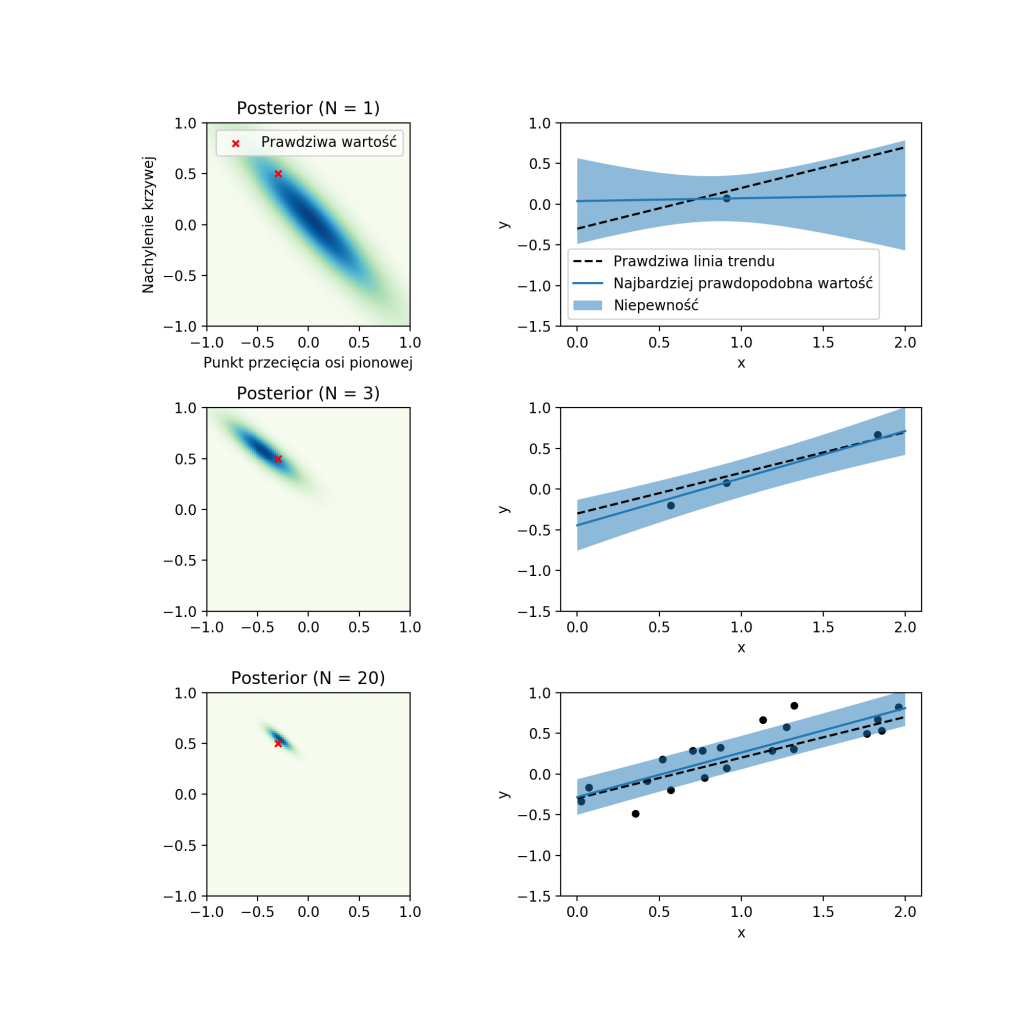
Powiedzmy, że chcielibyśmy przeprowadzić regresję pensji w stosunku do stażu pracy. Mamy staż pracy na osi poziomej oraz pensję na osi pionowej. Zbieramy dane, prawdopodobnie w konkretnej firmie. Oczywiście, moglibyśmy chcieć zebrać znacznie więcej zmiennych, natomiast w tym przypadku powiedzmy, że myślimy tylko o tej jednej zmiennej, jaką jest staż pracy danego pracownika versus jego pensja.
Chcielibyśmy zamodelować to modelem liniowym, czyli mamy dwa parametry takiego modelu: slope – nachylenie krzywej oraz punkt, w którym ta krzywa przekracza linię 0 (czyli początkowa pensja dla pracownika z zerowym stażem pracy). Taki model jest bardzo prosty do wyrażenia w probabilistycznym języku programowania.
W momencie, gdy wprowadzimy do systemu dane, które zebraliśmy w naszej firmie, silnik używanego języka programowania probabilistycznego będzie w stanie określić rozkład prawdopodobieństwa po tych dwóch parametrach (po nachyleniu krzywej oraz punktu przecięcia z osią 0).
Dlaczego jesteśmy zainteresowani rozkładem prawdopodobieństwa, a nie punktowym szacunkiem? Standardowa regresja liniowa w takiej sytuacji zwróciłaby nam tylko i wyłącznie najbardziej trafną wartość tego nachylenia i punktu przecięcia z osią 0.
Natomiast w przypadku użycia probabilistycznej czy bayesowskiej regresji liniowej (w takim języku programowania probabilistycznego) otrzymamy pełen rozkład prawdopodobieństwa, który również daje nam możliwość oceny niepewności tej estymacji. Znając niepewność naszego szacunku, jesteśmy w stanie zdecydować, czy w takim razie może chcemy zebrać więcej danych, ponieważ w tego rodzaju sytuacjach, dzięki większej ilości danych ta niepewność w szacunku będzie zmniejszona.
W bardzo świadomy sposób możemy tu operować wiedzą o niepewności naszej estymacji. Tego rodzaju rozważania są jeszcze ważniejsze w wielu przypadkach biznesowych.
Powiedzmy, że mamy do czynienia ze znacznie bardziej skomplikowanym modelem finansów, czy cashflow w pewnej firmie. Przekręcając tę korbę do silnika programowania probabilistycznego, dostarczamy mu danych, włączamy silnik inferencji i on zwraca nam rozkład prawdopodobieństwa po możliwym cashflow danej firmy. Tak się składa, że duża część tej krzywej (przyjmijmy, że jest to krzywa gausjańska) jest dodatnia, ale jest jakaś część tego ogona po lewej stronie poniżej 0 (oznacza to, że tracimy płynność finansową).
Posiadając tego rodzaju szacunki z niepewnością, jesteśmy w stanie dokładnie policzyć, jakie jest całkowite prawdopodobieństwo, czyli pole pod wykresem poniżej tego punktu 0. Pozwala nam to testować założenia naszego modelu biznesowego w taki sposób, że będziemy w stanie podjąć decyzje, żeby przy pewnym określonym czy akceptowanym poziomie ryzyka, policzalnym dzięki tej niepewności w naszych szacunkach.
Dodajmy do tego kwoty. Jak pojawiają się pieniądze, od razu jakoś lepiej tłumaczą się rzeczy. Załóżmy takie scenariusze, że jak dopiero zaczynasz, czyli doświadczenie jest 0 to zarabiasz powiedzmy 2 000 zł. Jak masz 10 lat doświadczenia, to niech to będzie 22 000 zł.
Czyli tam gdzie będzie 5 lat doświadczenia to będzie ok. 12 000 zł. Prawda? Tak w sposób liniowy spróbujmy to oszacować. W normalnej regresji liniowej pytasz: ile będę zarabiać, gdy będę miał 5 lat doświadczenia? Ona powie, że ok. 12 000 zł. Nie dodajesz żadnej informacji na temat tego, na ile to jest niepewna informacja.
Jest taka strategia lisa i jeża. Nie wiem, czy kiedyś o tym słyszałeś. Strategia jeża polega na tym, że jest on pewny jednej rzeczy i przyjmuje, że to jest prawda i tyle. Strategia lisa polega na tym, że on cały czas się waha, próbuje się kalibrować do nowych informacji, które uzyska i tak cały czas znajduje się w pewnej niepewności.

To, co teraz się nawiązało to to, że ta regresja liniowa klasyczna to jest taka strategia jeża, która zawsze jest pewna jednej rzeczy – jak masz 5 lat doświadczenia to ok. 12 000 zł masz zarabiać. W przypadku strategii lisa to będzie tak, że będzie jakiś rozkład. Ten rozkład będzie bardziej pokazywał tę rzeczywistość. Co o tym myślisz?
Nie słyszałem wcześniej tej analogii, ale wydaje mi się ona dość trafiona. Jeśli faktycznie tak ludzie mówią, to zdecydowanie się zgadzam.
Wiemy już, czym jest programowanie probabilistyczne. Jakie ma praktyczne zastosowanie? Czy masz jakieś przykłady?
Tak, oczywiście. Programowanie probabilistyczne ma co najmniej kilka dużych zakresów zastosowań. Pierwsze to są zastosowania w data analytics i data science do budowania średniego stopnia złożoności modeli, które pozwalają analizować dane zebrane przez użytkowników. Jednym z przykładów, który chciałbym podać, jest firma taka jak YouGov, która zajmuje się zbieraniem i sondażowaniem populacji na temat różnych wydarzeń, np. wyborów.
Te języki programowania probabilistycznego są dość często używane w tego rodzaju sytuacjach do określenia tego, w jaki sposób zebrane dane odzwierciedlają możliwe wyniki wyborów oraz udzielają tych odpowiedzi w postaci prawdopodobieństwa (bardziej niż tylko pojedynczych, punktowych szacunków otrzymanych z danych).
Te modele prawdopodobieństwa pozwalają nam również łączyć różne zmienne. Możemy w ten sposób wykorzystać dane, założenia czy różnego rodzaju korelacje pomiędzy odpowiedziami ludzi na różnego rodzaju pytania czy sondaże, które zebraliśmy w przeszłości, a które bezpośrednio nie dotykały tematu np. nadchodzących wyborów, z ich preferencjami politycznymi albo z podobnymi pytaniami.
W ten sposób pozwalają nam korzystać z przeszłych sondaży, żeby odpowiadać na nowe pytania, ale które w pewien sposób są skorelowane z tymi poprzednimi. Jesteśmy w stanie, tego rodzaju korelacje samemu stwierdzić i umieścić tę informację w systemie.
Natomiast całość dalszego określania, dokładnego rozkładu tego prawdopodobieństwa w stosunku do pytań, które chcemy zadać temu systemowi czy pytań, na które chcemy sobie odpowiedzieć, używając tych danych, jest już przeprowadzana automatycznie przez te języki programowania probabilistycznego. To jest jeden z dużych przykładów zastosowań tego rodzaju języka programowania.
Innym dużym zakresem zastosowania są symulatory, czyli wszelkiego rodzaju inżynieria. Jednym z pierwszych przykładów, który nasuwa mi się na myśl, jest aplikacja języka programowania probabilistycznego pyprob do analizy danych, zbieranych w CERNie.
CERN to duża instytucja zajmująca się badaniami fizyki fundamentalnej. Ośrodek naukowy znajduje się pod Genewą, na granicy szwajcarsko-francuskiej, gdzie również znajduje się największy fizyczny eksperyment na świecie, czyli Large Hadron Collider. W tym eksperymencie LHC zbierane są olbrzymie ilości danych. Tak duże, że nie jesteśmy w stanie na bieżąco ich przetwarzać.
Na czym polega przetwarzanie tych danych? W fizyce znamy bardzo dobry opis tego, jaki jest ciąg przyczynowo-skutkowy, tego, jak rzeczy się dzieją. Z reguły, jeśli mamy dobry opis systemu w danym momencie w czasie t=0, wiemy, jakie cząsteczki mamy w systemie, wiemy z jaką prędkością one się poruszają, jaka jest ich masa.
Jesteśmy w stanie przewidywać, co się będzie działo w przyszłości (przynajmniej na małych skalach czasowych). Natomiast mimo tego, że mamy tak dobrą znajomość praw fizyki, która pozwala nam symulować rozwój sytuacji w przyszłości, jeśli zaobserwujemy jakiś stan systemu (powiedzmy – 5 sekund później), dalej bardzo trudnym problemem jest odpowiedzenie na pytanie, w jaki sposób ten system znalazł się w tym stanie i w jakim stanie był kilka mikrosekund wcześniej.
Czyli w jaki sposób to się odbywa w praktyce? Szczególnie jeśli pomiary nie są w 100% dokładne, tylko mierzymy pozycję cząsteczki z jakąś niepewnością, co absolutnie ma miejsce, jeśli chodzi o badania cząsteczek fundamentalnych. Mamy tylko bardzo niebezpośrednie informacje. Mamy cząsteczki, które zderzają się w tym tunelu LHC, one zachodzą ze sobą w interakcje i powodują powstanie innych cząsteczek, z jakimiś właściwościami fizycznymi rodzaju masa czy pęd i energia kinetyczna, które w jakiś sposób zależą od tego, jakie cząsteczki zderzyły się na początku.
To też nie są procesy deterministyczne, tylko stochastyczne. Za każdym razem, nawet jeśli zderzą się dwie takie same cząsteczki, z takimi samymi własnościami, nie wiemy do końca, jakie nowe cząsteczki powstaną. Możliwych jest kilka różnych przebiegów przyszłości. Następnie te cząsteczki uderzają w ścianę tunelu. To wszystko jesteśmy w stanie zasymulować, m.in. używając programowania probabilistycznego.
W tym momencie wprowadzając te dane do naszego systemu i używając tego procesu inferencji, który jest wbudowany w silniki programowania probabilistycznego, jesteśmy w stanie odpowiedzieć sobie na pytanie, jaki był rozkład prawdopodobieństwa, jakie cząsteczki się zderzyły i jakie były ich właściwości rodzaju masa, pęd czy energia kinetyczna.
Kolejne fundamentalne pytanie – po co potrzebujemy tych informacji?
Ponieważ tylko bardzo mała część zdarzeń w tym eksperymencie jest tak naprawdę interesująca, nowa i ciekawa dla naukowców. Nie chcemy zbierać informacji o wszystkich zdarzeniach, które się dzieją w tych eksperymentach.
Chcemy zbierać tylko informacje o tych nowych, które jeszcze nie są dobrze znane i zbadane. Posiadanie dobrego opisu (rozkładu prawdopodobieństwa, po tym co się zdarzyło, co dokładnie zaszło), pozwala nam wybierać i zapisywać tylko te najbardziej ciekawe.
Również kluczem jest to, że dzieje się ich olbrzymia ilość i w związku z tym, ten proces odpowiadania sobie na pytanie, co dokładnie zdarzyło się w tym tunelu, jakie zdarzenie miało miejsce, jakie cząsteczki zostały wygenerowane po tym zdarzeniu – musi odbywać się bardzo szybko.
To jest motywacja do części z badań, które ja sam prowadzę i które być może kiedyś znajdą zastosowanie w tego rodzaju sytuacjach. Czyli moje własne badania polegają w dużej mierze na tym, jak przyspieszyć ten proces inferencji, w momencie gdy obserwowalne dane zostały już zaobserwowane.
Bardzo fajnie brzmi w teorii to, co się dzieje w CERNie. Powiedz, na ile to w praktyce jest stosowane codziennie? Czy to jest na razie tylko taki eksperyment teoretyczny?
Nie jest to już tylko eksperymentem teoretycznym. To nie jest tylko przykład tego, co mogłoby się dziać. To też nie jest dokładnie to, co już się dzieje. Aktualnie niektórzy z moich kolegów z grupy badawczej w Oxfordzie pracują właśnie nad tym problemem, czyli modelowaniem konkretnych zjawisk, które następują w obiekcie LHC przy pomocy programowania probabilistycznego.
Faktycznie, współpracują oni z fizykami z CERN-u tak, żeby zoperacjonalizować tego rodzaju narzędzia z dyscypliny programowania probabilistycznego z nadzieją na to, że prędzej czy później, wejdą one do praktycznego użycia. Natomiast nie jest to jeszcze domyślny sposób prowadzenia tych analiz.
Przyszła do głowy kolejna analogia – naukowcy, którzy używają mikroskopów do badania różnych rzeczy, których oko nie potrafi zobaczyć. Podobnie tutaj probabilistyczne programowanie staje się narzędziem, które umożliwia robić rzeczy, które inaczej ciężko byłoby zmierzyć.

Mamy dużą niepewność, jeśli chodzi o te cząsteczki, nie jesteśmy w stanie opisać tego w jednoznaczny sposób. Taka teoria, elementy probabilistyczne umożliwiają nam mierzyć rzeczy, które bez tych założeń, było by ciężko zmierzyć.
Tak, zdecydowanie. Większość rzeczy, o których mówimy w tym momencie w kontekście programowania probabilistycznego, odnosi się do modelowania probabilistycznego w ogóle, bardziej niż tylko języków programowania probabilistycznego. Języki programowania probabilistycznego są narzędziem do modelowania statystycznego.
Jednym z głównych zastosowań modelowania probabilistycznego jest to, żeby być w stanie korzystać z danych, które są zmierzone w sposób zawierający jakieś zniekształcenie. Najlepiej w sytuacjach, kiedy wiemy, w jaki sposób to zniekształcenie powstaje i jesteśmy w stanie wykorzystać tę wiedzę tak, żeby później zebrać jakąś większą ilość tych danych i odpowiedzieć sobie na pytania, które nas nurtują w ich kontekście.
Fajnie byłoby teraz podpowiedzieć, jak w łatwy sposób można zacząć działać w tym obszarze – możesz podać kilka nazw bibliotek w Pythonie czy innych dostępnych? Jakie pierwsze kroki wykonać, żeby osiągnąć namacalny wynik?
Wydaje mi się (z mojego własnego doświadczenia), że jednym z najlepszych miejsc, gdzie można zacząć, jest dość znany kurs Bayesian Methods for Hackers. To jest książka dostępna w całości na GitHubie, razem z zestawem jupyter notebooków.
Przeprowadza ona czytelnika przez początki teorii (czym jest statystyka bayesowska, czym jest programowanie probabilistyczne) oraz zaznajamia czytelnika z jedną z najbardziej popularnych bibliotek programowania probabilistycznego w Pythonie, która nazywa się PyMC3. Gorąco polecam, jest to tak jak nazwa wskazuje – bardzo pragmatycznie zorientowany kurs. Ma 6 części i wydaje mi się, że jest to zajęcie na kilka weekendów.
Teraz pozwolę sobie zmienić temat. Na początku wspomniałeś, że interesuje Cię również kompresja obrazu i wideo. Jaki tutaj mamy problem? Jak klasycznie był rozwiązywany? Później przejdźmy do uczenia maszynowego.
Prawdopodobnie większość z nas zna lub słyszała o standardowych rozszerzeniach plików z obrazami na komputerze. Te z najbardziej znanych to *jpg, *png, *tiff, *bmp. Każde z tych rozszerzeń odpowiada jakiemuś sposobowi kompresji czy też opisania obrazu. Ogólnie metody kompresji rozwijają się na dwie duże podgrupy, czyli kompresja ze stratą i kompresja bez straty.
Kompresja bez straty, tak jak wskazuje nazwa, upewnia się, że odbiorca skompresowanego obrazu, otrzyma dokładnie ten sam obraz jak osoba, która go skompresowała. Podczas gdy kompresja ze stratą, np. standard *jpg, wprowadza zniekształcenie do tego obrazu. W taki sposób, że w momencie gdy rozpakujemy ten obraz i wyświetlimy go na ekranie, nie będzie on dokładnie taki sam, jak spakowany plik źródłowy.
Te tradycyjne metody zostały zaprojektowane ręcznie, tak jak większość oprogramowania, z którego korzystamy i odzwierciedlają w tym momencie już długie dekady pracy nad kompresją obrazów w świecie cyfrowym.
Wcześniej kompresja była robiona manualnie. Teraz posługując się tymi narzędziami (sieć neuronowa), możemy podejść do tego problemu nieco inaczej i jak pokazują publikacje w tych obszarach, daje to całkiem fajny wynik. Powiedz proszę teraz trochę więcej na ten temat. Jakie są osiągnięcia w tym momencie?
Obserwujemy w tym momencie coraz większe zainteresowanie, żeby zastąpić część algorytmów do tej pory były programowanych ręczne, używając różnego rodzaju doświadczeń i heurystyk – elementami uczonymi, czyli elementami uczenia maszynowego, które byłyby w stanie do pewnego stopnia wykorzystać te heurystyki, które były używane do tej pory, ale faktycznie nauczyć się wartości algorytmów, które są wykonywane z danych, tak bardzo efektywnie, jak to możliwe.
Zainteresowanie tym tematem istniało prawdopodobnie już od lat 90, natomiast praktyczne sukcesy zaczęły pojawiać się dopiero od czasów rewolucji deep learningu. Pierwsze publikacje nowoczesne na temat kompresji obrazu i wideo zaczęły powstawać około 2013-2014 r. Większość z tych prac korzysta z metod unsupervised learning i z modeli rodzaju autoencoderów.
Obraz jest konsumowany przez taki autoencoder, który znajduje jakąś skompresowaną reprezentację obrazu, a następnie dekoder próbuje odtworzyć ten oryginalny obraz do jak najlepszego stopnia wierności. To jest metoda na tzw. kompresje ze stratą.
Druga odmiana, kompresja bez straty, jest w znacznym stopniu poprawiana. Elementem machine learningu, który tam znajduje zastosowanie, są właśnie modele probabilistyczne, które pozwalają nam określić jakie jest prawdopodobieństwo, że kolejny piksel będzie miał taką, czy inną wartość na podstawie pozostałych pikseli w obrazie.
Dzięki możliwości tych modeli uczenia maszynowego, żeby lepiej zamodelować ten rozkład prawdopodobieństwa, możemy opisać ten oryginalny obraz, używając mniejszej ilości danych, bez utraty jakichkolwiek informacji z obrazu wejściowego. To są dwie duże kategorie modeli uczenia maszynowego, które aktualnie znajdują zastosowanie w kompresji obrazów i wideo.
Jeśli chcecie nauczyć się więcej o tego rodzaju metodach Adam poleca 1-5 tygodnie kursu „Deep Unsupervised Learning” z University of California, Berkeley.
To naprawdę fascynujące jak technologia się rozwija, jak znajduje różnego rodzaju zastosowania. W odcinku 79. rozmawiałem z Adamem Kosiorkiem na temat uczenia nienadzorowanego. Można tam ten wątek zgłębić.
Przejdę teraz do innego tematu. Jesteś zaangażowany w Fundację Polonium Foundation. Czym zajmuje się fundacja? Jaki ma cel? Czym się w niej zajmujesz?
Fundacja Polonium zajmuje się łączeniem naukowców zainteresowanych Polską w jakikolwiek sposób, którzy przebywają lub są z zagranicy ze środowiskiem polonijnym za granicą oraz z możliwościami rozwoju kariery naukowej w Polsce.
Fundacja wyrosła z konferencji Science: Polish Perspectives, która była i jest dalej organizowana i w której organizację ja byłem zaangażowany w latach 2014-2016. Aktualnie moja rola jest już znacznie mniejsza i zajmuję się tylko częścią administracji IT tej organizacji.
Trzymam kciuki, żeby to się rozwijało. Obserwuję, że część osób wyjeżdża z Polski i kończy takie fajne uczelnie jak Oxford, ale część z nich potem wraca. Ta fizyczna lokalizacja w tej chwili nie jest aż taka ważna, ale fajnie, że ta więź jest utrzymywana, bo takie kontakty dają fajne owoce.
Jak duża jest społeczność polskich naukowców zajmujących się uczeniem maszynowym w znaczących ośrodkach zagranicznych (np. w Oxfordzie, w Niemczech, w Stanach)? Jak to możesz oszacować?
Mówisz o środowisku polonijnym?
Tak.
Przede wszystkim powinienem powiedzieć, że to środowisko rośnie. Jeśli chodzi o rząd wielkości powiedziałbym, że to jest w okolicach około 100 w Wielkiej Brytanii. Nie jest mi łatwo oszacować rozmiar tej społeczności w Stanach.
Wiem, że gdy próbowaliśmy spotykać się na konferencjach, zazwyczaj udawało nam się zebrać około 20 do 40 osób, które byłyby zainteresowane takim spotkaniem. W dużej mierze pochodzą one z różnych europejskich ośrodków – z Wielkiej Brytanii, także z Polski.
Oprócz tego, wiem o ludziach, którzy pracują w Holandii, Szwajcarii, część w Szwecji, w Niemczech. To są główne ośrodki, gdzie spotykam się z Polonią, która działa w obszarze machine learning.
Na początku wspomniałeś, że robisz doktorat na Oxfordzie. Wyjaśnij dokładnie jak długo ten program trwa. Jak to funkcjonuje? Miałeś półroczne praktyki w firmie w Qualcomm. Jak to się nakłada z tym programem? Jesteś zadowolony z uczelni? Czy rozwija Twoje pasje?
Program, na którym jestem, nazywa się Centre for Doctoral Training. To, co warto o nim wspomnieć to to, że różni się nieco od tradycyjnych programów doktoranckich w Wielkiej Brytanii. Po pierwsze jest to bardziej zorganizowany program aniżeli standardowy doktorat w Wielkiej Brytanii. Pierwszy rok tego doktoratu składa się z trzech etapów.
Przez pierwsze pół roku uczęszczasz na obowiązkowe kursy, a następne pół roku to dwa trzymiesięczne projekty badawcze z różnymi grupami badawczymi, które pozwalają Ci zobaczyć, w jaki sposób współpracuje się z naukowcami, którymi jesteś zainteresowany. Różni się to od standardowego programu doktoranckiego tym, że w standardowym programie doktoranckim zazwyczaj trzeba mieć dość ściśle określone zainteresowania badawcze już od punktu aplikacji.
Jednym z elementów aplikacji jest research statement, w którym opisujesz to, jakimi rodzaju badaniami jesteś zainteresowany, a bardzo często piszesz również research proposal, gdzie sugerujesz, w jakim kierunku Twoje badania poszłyby przynajmniej na początku doktoratu, a możliwe również, że przez cały doktorat, jeśli ktoś ma taką wizję.
W przypadku programu, na którym ja jestem, jest to bardziej program skierowany do ludzi, którzy przechodzą z innych, sąsiednich dyscyplin (ja przechodziłem po licencjacie i magisterce z fizyki) i chciałyby zmienić trochę kierunek, zacząć wchodzić w machine learning. Z tego powodu proces aplikacji jest nieco inny i w moim przypadku nie wymagał sformułowania aż tak szczegółowego planu badań, a bardziej opisania dyscyplin, którymi jestem zainteresowany.
Być może jest to ciekawa opcja dla osób, które nie mają jeszcze formalnego wykształcenia w uczeniu maszynowym, ale wiedzą, że są zainteresowane prowadzeniem badań i są przekonane co do tego, że chciałyby robić doktorat. Tego rodzaju program z racji połączenia tego elementu nauczanego, podobnego do tego, jak wyglądają doktoraty w Stanach Zjednoczonych, pozwala na nieco łagodniejsze wejście w tę trochę inną dyscyplinę nauki.
Jedną z największych zalet tego programu, w porównaniu do takiego niezależnego doktoratu jest to, że przez pierwsze pół roku odbywasz kursy w grupie innych doktorantów z tego samego programu, zazwyczaj jest to grupa pomiędzy 10 a 15 osobami. Jest to grupa, która potem rozchodzi się do różnych grup badawczych, ale z racji tego, jak dużo kontaktu mieliśmy w pierwszym roku, pozostajemy w bliskim kontakcie (aż do tego momentu, 2,5 roku później).
Znacząco ułatwia to nawiązywanie kontaktów pomiędzy różnymi grupami badawczymi, wewnątrz tej samej instytucji, co wcale nie jest takie łatwe, jak mogłoby się zdawać, ponieważ grupy badawcze w temacie uczenia maszynowego są rozsiane po różnych departamentach w Oxfordzie. Bardzo często nawet nie znasz innych ludzi, którzy prowadzą wcale nie aż tak różne badania w tej samej dyscyplinie.
Posiadanie kogoś, z kim jest się w dobrej komitywie w innych grupach badawczych, znacząco ułatwia nawiązywanie tych relacji z innymi grupami badawczymi i poznanie szerszego środowiska, nawet na tej samej uczelni.
Dzięki za to wyjaśnienie. Brzmi jak zachęta, żeby przynajmniej spróbować i poznać ludzi. Chciałbym Ci podziękować za Twój czas i zaangażowanie, żeby wyjaśnić, czym jest probabilistyczne programowanie i spróbować to zrobić w taki sposób, żeby to nie było zbyt skomplikowane.
Życzę Ci samych sukcesów i rozwijaj się w tym kierunku, w którym najbardziej chcesz. Z tego co zrozumiałem, w tej chwili najbardziej Cię kręci kompresja wideo.
Zdecydowanie. Dzięki wielkie Vladimir i również jak najwięcej sukcesów. Trzymaj się w tych dziwnych czasach.
Zacząłem ten tekst zadając pytanie, w jaki sposób analizować docierające do nas informacje. Z jednej strony tych informacji jest dużo w porównaniu z tym, co było 50 czy 100 lat temu.
Teraz wydaje się, że wszystko stało się bardziej transparentne, ale z drugiej strony, jak zaczynasz się zagłębiać w pewne rzeczy, analizować komunikaty pod kątem odpowiedzialności (kto bierze odpowiedzialność za tę czy inną decyzję), to pojawia się bardzo dużo pytań.
Życzę Ci, żebyś zadawał/-a właściwe pytania i próbował/-a dowiedzieć się, co oznacza ten czy inny komunikat. Również życzę Ci bardzo dużo zdrowia, żeby móc to wszystko przeanalizować.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.


