
Jaki model AI wybrać: wyzwania i rozwiązania?

Praktyczne podejście do oceny modeli LLM
Witam Cię w podcaście „Biznes Myśli”, nazywam się Vladimir Alekseichenko i w tym odcinku skupimy się na praktycznym aspekcie oceny modeli sztucznej inteligencji, ze szczególnym uwzględnieniem dużych modeli językowych (LLM). Przyjrzymy się fundamentom tej dziedziny i zastanowimy się, jak zadawać trafniejsze pytania dotyczące wyboru odpowiedniego modelu.
Często słyszymy pytanie: „Który model jest lepszy?„. Jednak samo to pytanie nie jest do końca właściwe. To trochę tak, jakbyśmy pytali „Który model samochodu jest dla mnie najlepszy?”, nie precyzując, do czego ten samochód ma służyć. Podobnie jest z modelami AI – nie ma jednego uniwersalnego rozwiązania pasującego do wszystkich zastosowań.
Warto pamiętać o słynnym powiedzeniu: „Wszystkie modele są złe, ale niektóre są użyteczne”. W praktyce oznacza to, że każdy model będzie się czasem mylić. Oznacza to, że każdy model będzie popełniał błędy. Tak, każdy model! Kluczowe jest zrozumienie, jak często będą występować błędy i jakie będą ich konsekwencje.

Znaczenie eksperymentowania w uczeniu maszynowym
Uczenie maszynowe to przede wszystkim dziedzina eksperymentowania. Zamiast pytać „czy można sprawdzić to czy coś innego?”, po prostu sprawdzamy różne konfiguracje i porównujemy wyniki. To podejście wymaga odpowiedniej metryki sukcesu, która pozwoli ocenić, który model jest lepszy w danym zastosowaniu.
Wybór właściwej metryki jest kluczowy – to ona decyduje o tym, który model zostanie wybrany. Można to porównać do pilota lądującego w gęstej mgle, który musi polegać na precyzyjnie skalibrowanych przyrządach w kokpicie.
Ewolucja modeli językowych
Przełomowa publikacja „Attention is all you need” zapoczątkowała rozwój transformerów, które z kolei doprowadziły do powstania modeli GPT i innych LLM.

Warto jednak pamiętać, że wcześniejsze prace również przyczyniły się do tego postępu.
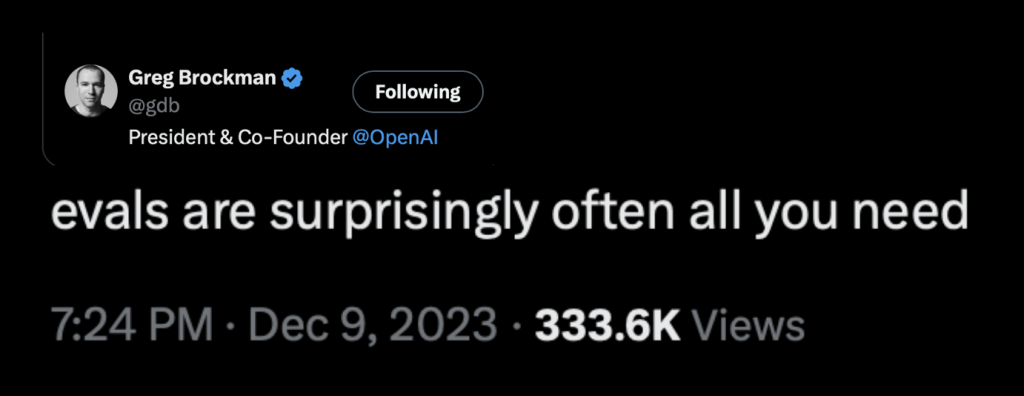
W miarę rozwoju LLM pojawiła się potrzeba ich dokładnej ewaluacji. Stąd wzięło się stwierdzenie „Eval is all you need” (ewaluacja to wszystko, czego potrzebujesz), podkreślające znaczenie oceny modeli (to oczywiście jest gra słów bazując na publikacje powyżej, ale też ważne skierowanie uwagi, na to co się liczy) autorstwa Grega z OpenAI.
Benchmarki i ich ograniczenia
Benchmarki to narzędzia pozwalające porównać różne modele na podstawie określonych metryk sukcesu. Jednak warto pamiętać o pewnym ważnym zastrzeżeniu:
Wysoka pozycja modelu w benchmarku nie gwarantuje, że będzie on najlepiej rozwiązywał konkretne problemy biznesowe. Z drugiej strony, model, który wypada słabo w benchmarkach, prawdopodobnie nie sprawdzi się w praktycznych zastosowaniach (po prostu jest „słaby” wszędzie).
Ta subtelna różnica jest często pomijana, gdy ludzie wyciągają wnioski na podstawie pojedynczych benchmarków.
Wniosek: nawet jak model jest bardzo wysoko w benchmarkach, to wcale nie oznacza, że ten model rozwiąże dobrze Twój problem!
W uczeniu maszynowym, w tym w LLM, wyróżniamy dwie fazy testowania:
- Testowanie offline – wykorzystuje dane historyczne do treningu i walidacji modelu.
- Testowanie online – ocenia model w rzeczywistych warunkach, gdy wchodzi w interakcje z użytkownikami.
Choć dobre wyniki w testach offline są ważne, nie gwarantują one sukcesu w środowisku produkcyjnym. Dążymy do tego, aby wyniki z obu faz były porównywalne, choć nie jest to łatwe zadanie.
Wyzwania w ocenie modeli generatywnych
Ocena modeli generatywnych, takich jak LLM, jest znacznie bardziej złożona niż w przypadku klasycznych modeli uczenia maszynowego. W tradycyjnych modelach często mamy do czynienia z pojedynczą wartością wyjściową, którą łatwo porównać z oczekiwanym wynikiem.
W przypadku modeli generatywnych, wyjście może być znacznie bardziej złożone – od pojedynczych zdań po całe paragrafy tekstu (też może być obrazek czy audio). Ocenie podlegają różne aspekty:
- Czy to poprawna odpowiedź, np. gdy pytamy o stolicę kraju.
- Czy odpowiedź jest relewantna – może być poprawna, ale nie na temat.
- Czy styl wypowiedzi pasuje do oczekiwań – zbyt formalny, nieformalny itp.
- Czy zawiera toksyczne elementy, obraźliwe słowa.
- I wiele innych rzeczy, które jeszcze możemy sprawdzić
Co więcej, nie zawsze istnieje jednoznaczna „prawidłowa” odpowiedź, szczególnie w przypadku pytań otwartych lub subiektywnych.
Ocena finalnego produktu
Warto pamiętać, że ocena samego modelu LLM to tylko część procesu. W praktyce biznesowej kluczowe jest ocenianie całego rozwiązania, które wykorzystuje LLM jako jeden z elementów. To właśnie efektywność końcowego produktu ma największe znaczenie z perspektywy biznesowej.
W kolejnych częściach przyjrzymy się, jak podejść do oceny takich złożonych systemów, szczególnie gdy zaczynamy od zera. Zrozumienie tych wyzwań i odpowiednie podejście do ewaluacji pozwoli nam lepiej wykorzystać potencjał modeli językowych w praktycznych zastosowaniach.
Ewolucja metryk oceny modeli językowych
W świecie sztucznej inteligencji i modeli językowych, sposób oceny ich skuteczności przeszedł znaczącą ewolucję. Początkowo, w 2018 roku, pojawiły się metryki takie jak GLUE, SuperGLUE czy BLUE, które koncentrowały się na mierzeniu zdolności modeli do rozumienia tekstu. Jednak szybko okazało się, że te benchmarki były stosunkowo łatwe do pokonania przez coraz bardziej zaawansowane modele.

Gdy modele zaczęły osiągać wyniki bliskie 100% w tych testach, pojawiła się potrzeba stworzenia trudniejszych wyzwań. W odpowiedzi na to powstały nowe metryki, takie jak MMLU (Measuring Massive Multitask Language Understanding), ARK, HellaSwag czy DROP. Miały one stanowić bardziej wymagające testy dla modeli AI.
MMLU – nowe wyzwanie dla modeli językowych
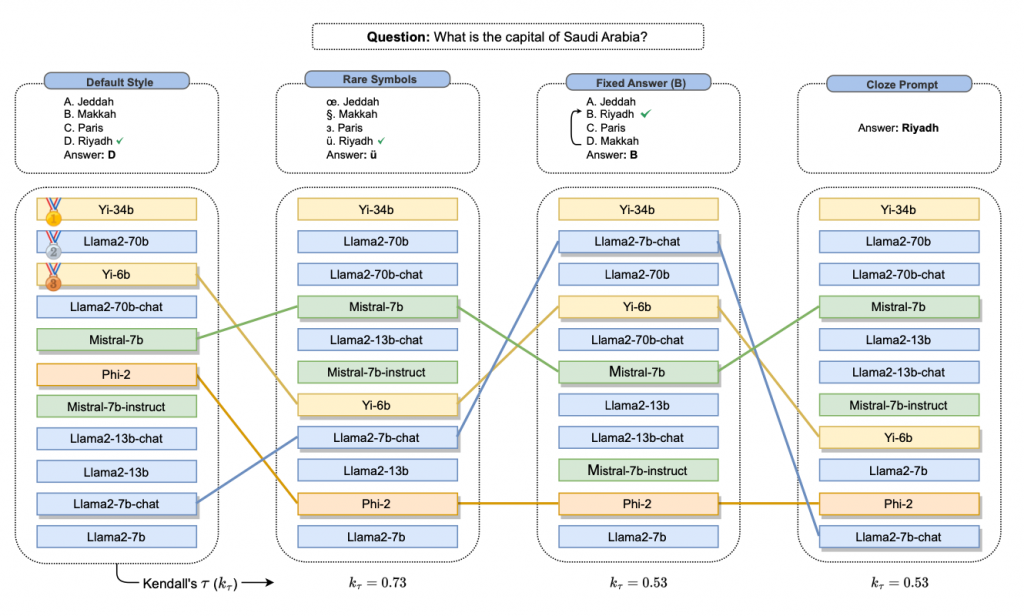
MMLU to szczególnie interesujący benchmark, składający się z 59 różnych zadań obejmujących szeroki zakres dziedzin, od historii po astronomię. Test polega na odpowiadaniu na konkretne pytania, wybierając jedną z czterech opcji. Co ciekawe, pytania te często okazują się trudne nawet dla ludzi, zwłaszcza tych, którzy dawno skończyli edukację formalną.

Początkowo MMLU wydawał się obiecującym narzędziem do oceny modeli AI. Jednak z czasem ujawniły się pewne ograniczenia i problemy związane z tą metryką:
- Modele zaczęły osiągać wyniki bliskie 100%, co ogranicza użyteczność testu.
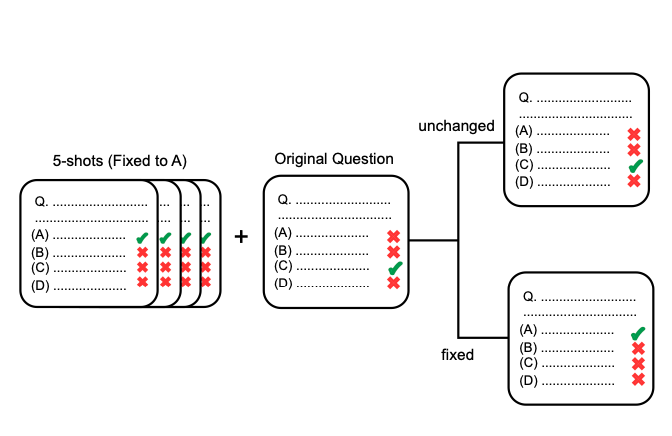
- Odkryto błędy w samym teście, gdzie niektóre pytania miały niepoprawne odpowiedzi lub były źle sformułowane.
- Publiczna dostępność danych MMLU umożliwiła modelom „nauczenie się” odpowiedzi, co podważa wiarygodność wyników.
Wyzwania w ocenie modeli językowych
Badania wykazały, że niektóre modele, zwłaszcza te mniejsze, są podatne na „przeuczenie” się na podstawie publicznie dostępnych danych testowych. Prowadzi to do sytuacji, gdzie model może osiągać wysokie wyniki w teście, nie rozumiejąc faktycznie treści pytań.

Innym problemem jest to, że benchmarki takie jak MMLU są zamknięte i skończone. Oznacza to, że największe firmy technologiczne mogą skupić się na optymalizacji swoich modeli pod kątem konkretnych pytań, co niekoniecznie przekłada się na rzeczywistą użyteczność w zastosowaniach biznesowych.
W poszukiwaniu nowych rozwiązań
Wobec tych wyzwań, branża AI poszukuje alternatywnych metod oceny modeli językowych. Jednym z pomysłów jest włączenie ludzi w proces ewaluacji, co mogłoby zapewnić bardziej kompleksową i realistyczną ocenę możliwości modeli.
Mimo ograniczeń, benchmarki takie jak MMLU wciąż dostarczają cennych informacji. Jeśli model osiąga niskie wyniki w tych testach, prawdopodobnie będzie miał trudności również w rzeczywistych zastosowaniach.
Przyszłość oceny modeli językowych z pewnością będzie wymagała bardziej zaawansowanych i dynamicznych metod, które lepiej odzwierciedlą rzeczywiste wyzwania stojące przed AI w praktycznych zastosowaniach.
Nowe podejście do oceny modeli AI
W obliczu wyzwań związanych z oceną modeli językowych, branża AI poszukuje innowacyjnych rozwiązań. Jednym z nich jest włączenie ludzi w proces ewaluacji, co jednak niesie ze sobą pewne trudności.
Ludzka ocena może być niespójna – ta sama osoba może inaczej ocenić model rano, a inaczej wieczorem. Dlatego eksperci szukają alternatywnych metod. Okazuje się, że ludzie są szczególnie dobrzy w porównywaniu opcji. Podobnie jak w słynnym Pepsi Challenge z 1975 roku, gdzie porównywano Coca-Colę i Pepsi bez pokazywania marek, w ocenie modeli AI również kluczowe jest ukrycie ich nazw.

ChatbotArena – przełom w ocenie modeli
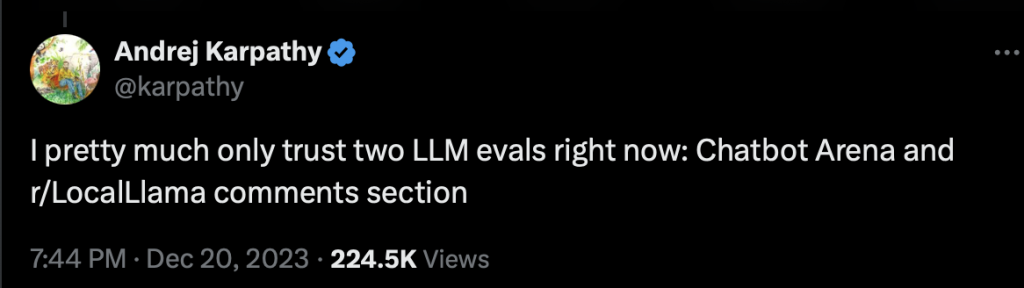
Jednym z najbardziej obiecujących rozwiązań jest ChatbotArena. To platforma, gdzie użytkownicy mogą porównać odpowiedzi dwóch anonimowych modeli na to samo pytanie. Andrzej Karpathy, znany ekspert AI, stwierdził nawet: „Ufam tylko ChatbotArenie”.
Jak to działa? Użytkownik wpisuje zapytanie, np. „5 miejsc, które koniecznie warto odwiedzić w Krakowie” i otrzymuje dwie odpowiedzi – od modelu A i B. Następnie ocenia, która odpowiedź jest lepsza lub czy są równie dobre/złe. To podejście pozwala na bardziej obiektywną ocenę modeli.
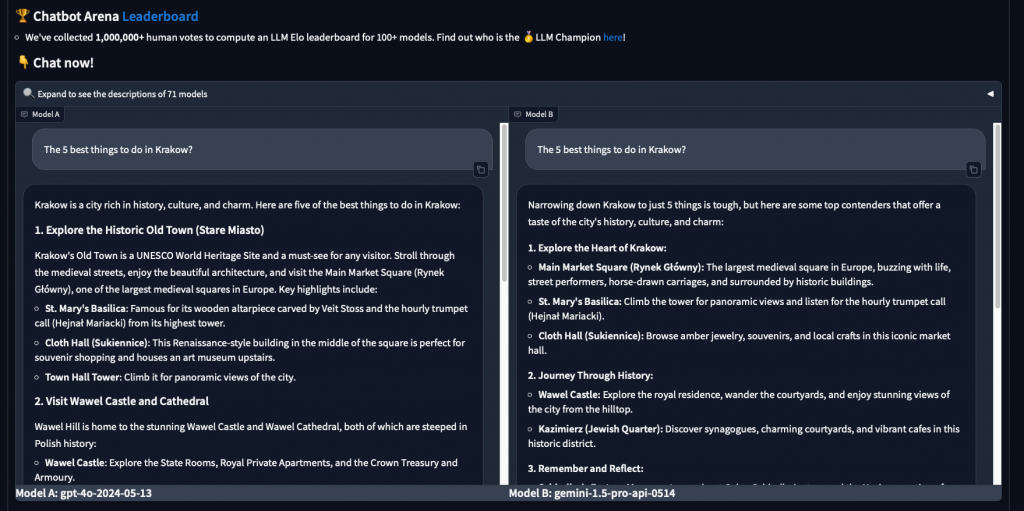
Obecnie w ChatbotArenie oceniono już 115 modeli. Wyzwaniem jest jednak zebranie wystarczającej liczby różnorodnych ocen, co wymaga czasu i zaangażowania wielu użytkowników.
Hard Arena – automatyzacja oceny
Aby przyspieszyć proces oceny, powstała koncepcja Hard Arena. Wykorzystuje ona dane zebrane z ChatbotAreny (1,5 miliona głosów) do stworzenia modelu, który automatycznie ocenia inne modele. Co ciekawe, okazało się, że zaawansowane modele, takie jak GPT-4, potrafią dość dobrze oceniać inne modele.

Hard Arena opiera się na dwóch głównych kryteriach:
- Automatyczny wybór powinien być jak najbardziej zbliżony do ludzkiego.
- Wyniki powinny pozwalać na łatwe rozróżnienie między modelami (większa separowalność niż w tradycyjnych benchmarkach).
Proces oceny w Hard Arena
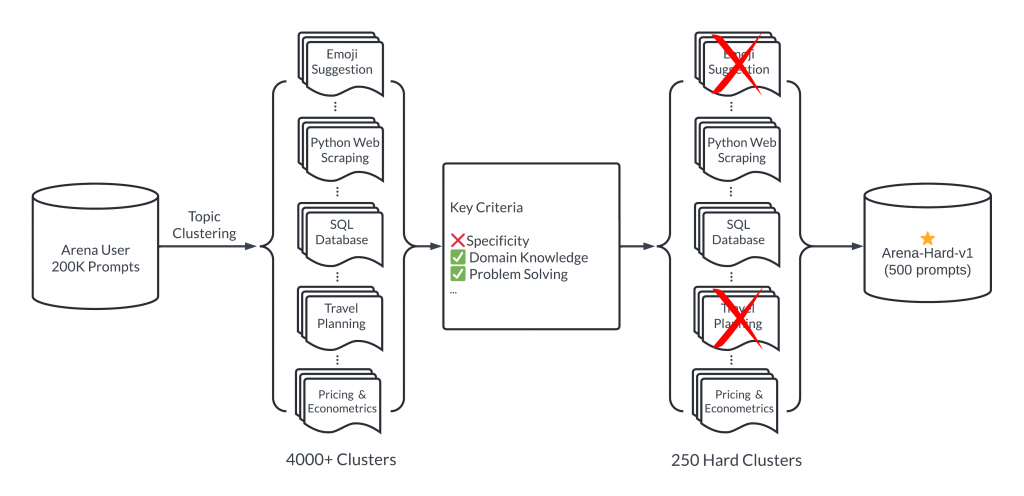
Proces oceny w Hard Arena wygląda następująco:
- Wybór 200 000 promptów od użytkowników
- Grupowanie promptów w 4000 klastrów tematycznych
- Oczyszczanie i selekcja 250 najbardziej odpowiednich klastrów
- Wybór 500 reprezentatywnych promptów do testów
Koszt pojedynczego testu w Hard Arena to około 20-30 dolarów, co jest znacznie tańsze i szybsze niż tradycyjne metody oceny przez ludzi.
Nowe podejścia do ewaluacji modeli językowych, takie jak ChatbotArena i Hard Arena, otwierają fascynujące możliwości. Pozwalają na bardziej obiektywną, szybszą i tańszą ocenę, co z pewnością przyczyni się do dalszego rozwoju sztucznej inteligencji.
Arena Learning i automatyzacja oceny modeli AI
Arena Learning to podobne podejście do oceny modeli językowych, które ma na celu przyspieszenie procesu weryfikacji wprowadzanych zmian. Metoda ta wykorzystuje prompty i automatyczne ocenianie, co pozwala na szybsze sprawdzenie, czy modyfikacje faktycznie przyniosły pożądane efekty.
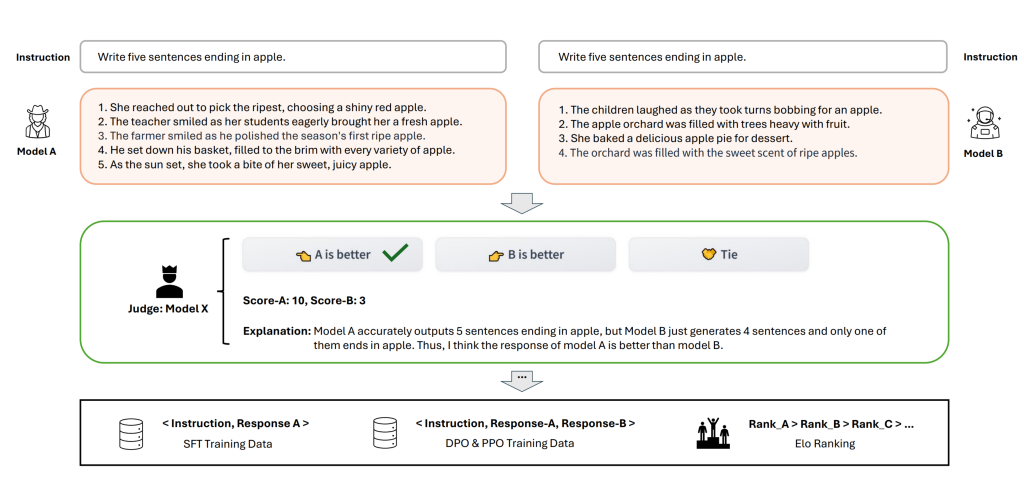
Konkurs Kaggle – nowe spojrzenie na ocenę modeli
Aktualnie trwa konkurs na platformie Kaggle, który wykorzystuje prompty z Areny oraz odpowiedzi modeli A i B. Celem uczestników jest stworzenie modelu, który najlepiej przewidzi zwycięzcę w pojedynku między dwoma modelami AI.
Analiza danych z konkursu ujawniła interesujące zależności:
- Dłuższe odpowiedzi miały większą szansę na zwycięstwo
- Przy porównywalnej długości odpowiedzi, szanse na wygraną były zbliżone dla obu modeli
- Gdy odpowiedź modelu A była krótsza, model B miał około 60% szans na zwycięstwo
Te obserwacje pokazują, że nawet najbardziej wiarygodne rankingi, takie jak Arena Leaderboard, mogą mieć pewne słabe punkty prowadzące do błędnych interpretacji.
Praktyczne podejście do wdrażania modeli językowych
Choć benchmarki i rankingi są pomocne, w rzeczywistości liczy się rozwiązanie konkretnego problemu biznesowego. Dlatego kluczowe jest stworzenie własnego leaderboardu, który uwzględnia specyfikę danego przedsięwzięcia.
Oto trzy kroki, które pomogą w stworzeniu własnego systemu oceny:
- Przygotowanie danych:
- Zbierz 50-100 przykładowych pytań od klientów
- Przygotuj wzorcowe odpowiedzi z pomocą ekspertów
- Określenie metryk:
- Zdefiniuj kryteria oceny odpowiedzi (np. poprawność, relewantność, styl)
- Dostosuj metryki do celów biznesowych
- Stworzenie leaderboardu:
- Połącz zebrane dane i wybrane metryki
- Regularnie aktualizuj i weryfikuj skuteczność systemu
Ciągłe doskonalenie procesu oceny
Pamiętaj, że tworzenie benchmarków to proces ciągły. Regularne przeglądy (np. co miesiąc lub kwartał) pomogą utrzymać aktualność danych i metryk. Warto również nadawać wersje lub nazwy kolejnym iteracjom leaderboardu, aby uniknąć nieporozumień przy porównywaniu wyników.
Takie podejście pozwoli na bardziej świadome i efektywne wdrażanie modeli LLM w biznesie, minimalizując ryzyko i maksymalizując korzyści płynące z wykorzystania sztucznej inteligencji.
Zbieranie informacji zwrotnej – klucz do sukcesu
OpenAI, lider w dziedzinie modeli językowych, wyróżnia się nie tylko jakością swoich produktów, ale także umiejętnością zbierania cennych informacji zwrotnych. Ich podejście do analizy zachowań użytkowników jest godne naśladowania.
Zwróć uwagę na to, jak OpenAI obserwuje interakcje z ich systemem. Możliwość postawienia „lajka”, skopiowania odpowiedzi czy wygenerowania jej ponownie to nie tylko udogodnienia dla użytkownika. To przede wszystkim narzędzia do zbierania bezcennych danych o satysfakcji i użyteczności generowanych treści.
Kopiowanie odpowiedzi sugeruje, że treść była wartościowa. Z kolei prośba o ponowne wygenerowanie może wskazywać na niezadowalający rezultat. Te automatyczne mechanizmy zbierania feedbacku są często bardziej wartościowe niż bezpośrednie pytania zadawane użytkownikom po zakończeniu interakcji.
Projektowanie interfejsu z myślą o danych
Projektując własny interfejs, warto zainspirować się tym podejściem. Oprócz podstawowej funkcjonalności, jak możliwość wpisania zapytania, rozważ dodanie opcji:
- Kopiowania odpowiedzi
- Oceny (np. poprzez „lajki”)
- Ponownego generowania treści
Zastanów się, jakie jeszcze działania użytkownika mogłyby dostarczyć ci cennych informacji o jakości i przydatności generowanych odpowiedzi.
Struktura danych do oceny modeli LLM
Tworząc własny zestaw danych do oceny modeli LLM, warto uwzględnić następujące elementy:
- Prompt (zapytanie użytkownika)
- Oczekiwany output (wzorcowa odpowiedź)
- Kontekst pomocniczy dla modelu
- Wygenerowana odpowiedź
- Wyciągnięty przez model kontekst (jeśli dotyczy)
Taka struktura pozwoli na wielowymiarową ocenę działania modelu, uwzględniającą nie tylko jakość samej odpowiedzi, ale także trafność doboru kontekstu czy zgodność ze stylem i wartościami firmy.
Znaczenie własnych benchmarków
Pamiętaj, że popularne benchmarki, takie jak te dostępne na Arena, mierzą jedynie ogólną jakość modeli LLM. Nie uwzględniają one specyfiki Twojego biznesu i konkretnych zastosowań.
Wysoka pozycja modelu w ogólnym rankingu nie gwarantuje, że sprawdzi się on równie dobrze w Twoim przypadku. Z drugiej strony, niska pozycja w rankingu może sugerować, że model raczej nie będzie odpowiedni dla Twoich potrzeb.
Trendy w ocenie modeli LLM
Warto zwrócić uwagę na pojawiające się Enterprise Leaderboards – prywatne rankingi tworzone przez firmy, które przygotowują zestawy pytań i odpowiedzi z różnych dziedzin, np. finansów czy prawa. Choć mogą one być bliższe realnym zastosowaniom biznesowym niż ogólne benchmarki, nadal należy podchodzić do nich z ostrożnością. Brak transparentności co do metodologii i danych użytych do oceny może stanowić istotne ograniczenie.
Narzędzia i zasoby
Dla osób zainteresowanych automatyzacją procesu oceny modeli LLM, warto zapoznać się z takimi narzędziami jak:
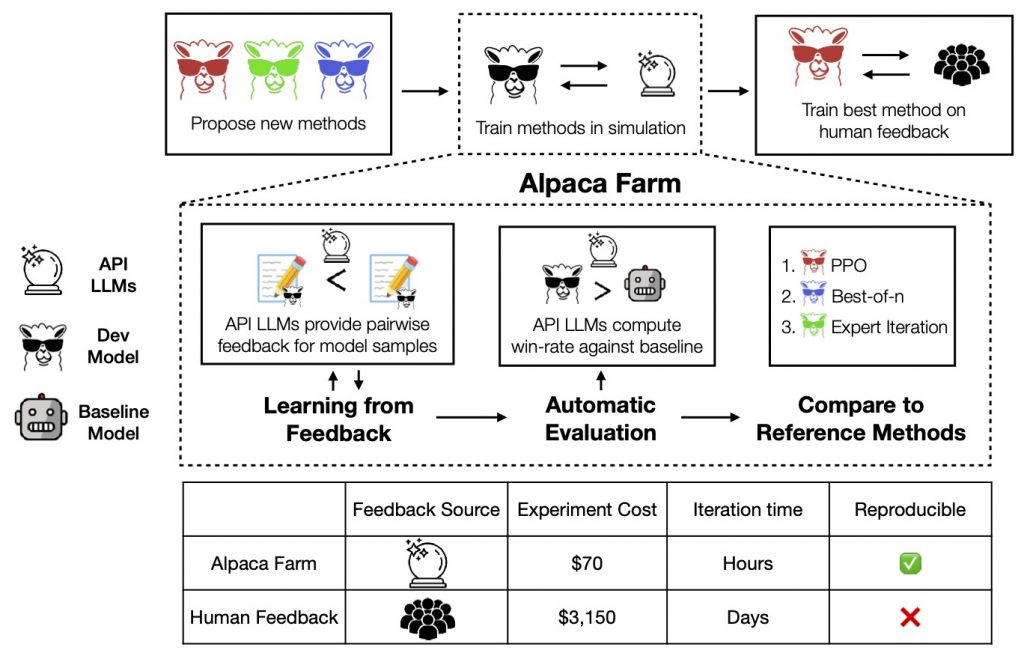
- Alpaca Farm – framework do automatyzacji oceny
- DeepEval – biblioteka zawierająca przydatne zestawy narzędzi
Istnieją również specjalistyczne benchmarki dla konkretnych zastosowań, np.:
- TTS Arena dla konwersji tekstu na mowę
- Long Code Arena i Live Code Bench dla oceny modeli w kontekście programowania
Podsumowanie
- W uczeniu maszynowym kluczowe jest eksperymentowanie i weryfikacja wyników.
- Nie istnieją idealne modele ani metryki – ważne jest znalezienie tych, które są najbardziej przydatne w konkretnym przypadku.
- Statyczne benchmarki mają ograniczoną wartość w ocenie najnowszych modeli LLM.
- Arena Leaderboard i podobne inicjatywy próbują rozwiązać problem oceny poprzez zaangażowanie ludzi.
- Dla firm wdrażających LLM kluczowe jest stworzenie własnego, dostosowanego do potrzeb biznesowych systemu oceny.
Nie ma uniwersalnego rozwiązania – najlepszym podejściem jest stworzenie własnego systemu oceny, który będzie odpowiadał specyficznym potrzebom i celom Twojego biznesu.
P.S. Poleć przynajmniej jednej osobie ten odcinek i też subskrybuj nas na YouTube.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
