
Fine-tuning LLM: fakty i mity
Witaj w kolejnym odcinku podcastu Biznes Myśli, Twoim zaufanym źródle informacji o sztucznej inteligencji. Jestem Vladimir Alekseichenko, praktykiem AI i od 2017 roku wraz z moimi gośćmi mówimy tu o potencjalnej wartości i ryzykach związanych z tą technologią. Zaufało nam już tysiące osób i wielu liderów rynku, takich jak Orange, Leroy czy mBank.
Świat zmienia się szybciej niż myślisz, a my pomożemy Ci zrozumieć, o co chodzi w świecie AI i jak możesz to zastosować w praktyce. Jeśli masz pomysł związany z ML/AI, skontaktuj się z nami w DataWorkshop – przeprowadzimy konsultacje, wytrenujemy Ciebie, Twój zespół lub całą firmę.

Fine-tuning, czyli dostrajanie modeli LLM
W dzisiejszym odcinku gościem jest Remigiusz Kinas, ekspert w temacie dostrajania dużych modeli językowych (LLM). Remek jest podwójnym Grand Masterem na platformie Kaggle, ambasadorem marki HP i członkiem core teamu projektu SpeakLeash, polskiego modelu LLM. Zajmuje się rozwojem sztucznej inteligencji zawodowo w grupie NEUCA, a także poświęca temu czas po godzinach pracy.
Porozmawiamy dziś o poszczególnych etapach trenowania modeli LLM, skupiając się na fine-tuningu. Dowiemy się, jakie są jego rodzaje, formaty danych i ile danych potrzeba na poszczególnych etapach. Poruszymy też kwestie kosztów – okazuje się, że jedna z faz może kosztować tyle, co nieruchomość w Warszawie! Na koniec Remek uchyli rąbka tajemnicy na temat nowinek, których można spodziewać się w drugiej wersji Bilika.
Co to jest fine-tuning modeli AI?
Fine-tuning, czyli dostrajanie modeli AI, to technika znana od kilku lat, wywodząca się z dziedziny computer vision. Polega ona na wzięciu wstępnie wytrenowanego modelu (np. na zbiorze danych ImageNet) i douczeniu go na mniejszym, specyficznym dla danego zadania zbiorze.

Modele AI można postrzegać jako matematyczne funkcje – coś wchodzi na wejście i chcemy zrealizować pewne zadanie. Początkowo model jest „głupi”, zainicjalizowany losowymi wartościami. Dopiero trening na dużych zbiorach danych, takich jak korpusy tekstowe w przypadku LLM, pozwala mu nabrać „rozumu”. Po wstępnym treningu model potrafi już wykonywać proste zadania, np. Przewidywać następne słowo w zdaniu.
Jednak aby model radził sobie z konkretnymi, specjalistycznymi zadaniami, potrzebny jest dodatkowy etap dostrajania. I właśnie tym zagadnieniem zajmiemy się w dzisiejszym odcinku.
Fine-tuning – dostrajanie modeli AI do konkretnych zadań
Po wstępnym treningu modelu (pre-training) na ogromnym zbiorze danych, kolejnym etapem jest fine-tuning, czyli dostosowanie modelu do bardzo konkretnego zadania. W przypadku wizji komputerowej może to być klasyfikacja obiektów na zdjęciach, np. rozpoznawanie kotów i psów, czy detekcja samochodów, ludzi itp.
Fine-tuning polega na ograniczeniu liczby klas do predykcji i dostrojeniu modelu. Okazuje się, że takie dostrajanie znacząco poprawia jakość modeli, niezależnie od zadania. Te zadania mogą być bardzo różnorodne – klasyfikacja, detekcja, segmentacja w przypadku wizji komputerowej, a w przypadku modeli językowych (LLM) np. wykonywanie instrukcji, konwersacje czy klasyfikacje tekstu.
W LLM proces fine-tuningu jest jeszcze bardziej złożony. Po dostrojeniu modelu instrukcyjnego, wykonuje się jeszcze tzw. alignment, czyli dopasowanie modelu do określonego stylu i „wygładzenie” odpowiedzi. Tak dostrojony model radzi sobie znacznie lepiej z konkretnymi zadaniami.
Model bazowy a instrukcyjny – jak je odróżnić?
Osoby z biznesu czy decydenci często gubią się w gąszczu nazw i skrótów związanych z różnymi rodzajami modeli AI. Mamy model bazowy (pre-trained), instrukcyjny (Instruct) i jeszcze fine-tuning. O co w tym wszystkim chodzi?
Pierwszy model w LLM to model bazowy, trenowany od zera na ogromnym zbiorze danych tekstowych. Taki model uczy się jedynie przewidywać kolejne słowo i generować tekst w nieskończoność. Jest to fundament, na którym buduje się kolejne warstwy.
Jednak model bazowy można dalej trenować, np. na konkretnym języku. Mamy wtedy do czynienia z kontynuowanym pre-trainingiem. Przykładowo, model LLM trenowany głównie na angielskich danych (np. 15 bilionów tokenów) może być dalej uczony na polskim korpusie językowym. Dane z oryginalnego zbioru są uzupełniane o te z danego języka.
Tak przygotowane modele bazowe mogą być już użyteczne, ale wyzwaniem jest zatrzymanie generowania tekstu w odpowiednim momencie. Tutaj z pomocą przychodzi pre-training instrukcyjny (Instruct).
W treningu instrukcyjnym mamy dwa główne typy poleceń:
- Proste instrukcje, np. „napisz wierszyk o żurku i ogórku”.
- Trening konwersacyjny, uczący model prowadzenia dialogu z uwzględnieniem kontekstu.
Jest jeszcze trzeci typ – function calling, gdzie model zwraca odpowiedź w ustrukturyzowanym formacie.
Tak wytrenowany model instrukcyjny ma już konkretne kompetencje – potrafi wykonywać polecenia, generować sensowne odpowiedzi i zatrzymać się we właściwym momencie. To właśnie te modele widzimy jako użytkownicy w takich produktach jak ChatGPT, Anthropic, Bard czy Bing.
Ostatnim, niewidocznym dla użytkownika etapem, jest alignment czyli „wygładzanie” modelu przez mentora, który podpowiada jak najlepiej odpowiadać.
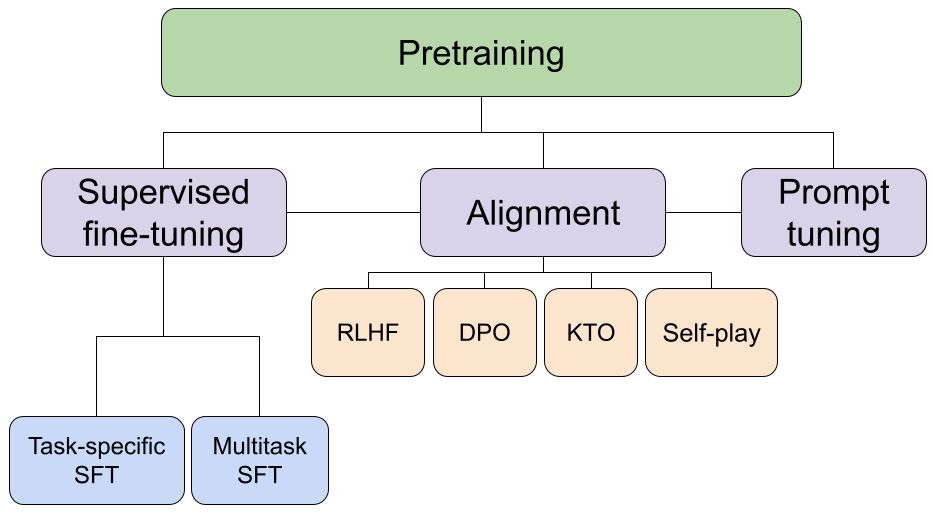
To stąd mamy:
- Model bazowy to student, który przeczytał mnóstwo książek, ale nie umie jeszcze wykorzystać tej wiedzy.
- Model instrukcyjny to student, który potrafi już rozwiązywać konkretne zadania.
- Model po alignmencie to student pod okiem mentora, dbającego o jakość i styl odpowiedzi.
Dane do treningu – dużo danych
W treningu modeli AI kluczowe znaczenie mają dane. W fazie pre-trainingu obowiązuje zasada „im więcej, tym lepiej” – wygrywają firmy z największymi zasobami danych. Przykładowo polska wersja modelu Bielik była trenowana na ogromnym, największym jak dotąd korpusie polskich danych tekstowych (1,5 TB).
Jednak ważna jest nie tylko ilość, ale i jakość danych. Nawet w fazie instrukcyjnej i alignmentu, gdzie zbiory danych są dużo mniejsze, model nadal chłonie wiedzę i może uczyć się błędów. Dbałość o jakość instrukcji i danych na każdym etapie to klucz do stworzenia wartościowego i użytecznego modelu AI.
Jakość danych kluczem do stworzenia wartościowego modelu AI
Kolejnym istotnym aspektem po ilości danych jest ich jakość. W SpeakLeash powstały klasyfikatory jakości, które dzielą dokumenty na trzy kategorie: high, medium i low. Do treningu modeli wykorzystywane są tylko dane z kategorii high, określanej na skali procentowej. Próg odcięcia wynosi zazwyczaj 95-98%, co gwarantuje bardzo dobrą jakość danych.
Przygotowanie danych to wieloetapowy proces. Po pozyskaniu ich z różnych źródeł, należy je odpowiednio sklasyfikować, usunąć duplikaty i ewentualnie skorygować. Szczególną uwagę trzeba zwrócić na etap korekcji, ponieważ modele mogą wprowadzić własne błędy poznawcze, tzw. bias, które później zostaną powielone w modelu wynikowym.
Instrukcje i ich formaty
Kolejnym etapem po pre-trainingu jest fine-tuning, gdzie wykorzystuje się instrukcje. Instrukcja to po prostu polecenie, np. „napisz wierszyk”, wraz z przykładową odpowiedzią. Istnieje ponad 30 zarejestrowanych formatów instrukcji, które są obsługiwane automatycznie przez frameworki. Wyróżniamy trzy główne typy: zwykłe instrukcje, instrukcje konwersacyjne i function calling.

W Bieliku 2 obecnie znajduje się pięć milionów instrukcji, co stanowi bardzo duży zbiór. Instrukcje tworzone są ręcznie lub generowane syntetycznie przez inne modele. Obecny trend wskazuje na coraz częstsze wykorzystanie syntetycznych danych, ze względu na wzrost jakości modeli je generujących. Człowiek nie jest w stanie stworzyć tak dużej ilości zróżnicowanych instrukcji, pokrywających szeroką tematykę i wariacje.
Balansowanie i dostosowywanie modeli
W Bieliku i SpeakLeashu, oprócz klasyfikatora jakości, stosowany jest również klasyfikator tematyczny ze 120 klasami. Jego zadaniem jest zbalansowanie zbioru danych, aby model nie skupiał się za bardzo na jednym temacie, np. polityce czy matematyce.
Ostatnim etapem jest przygotowanie zbioru do uczenia wzmacnianego. W najprostszym rozwiązaniu generuje się pary odpowiedzi – akceptowane i odrzucane. Model może też generować odpowiedzi na bieżąco w trakcie treningu, a drugi model je modyfikuje.
Dane mają kluczowy wpływ na zachowanie modelu. Nawet styl i format danych przekłada się później na sposób odpowiadania przez AI. Dlatego tak ważne jest przemyślenie, jak mają wyglądać odpowiedzi – czy powinny zawierać Markdown, być wytłuszczone, wypunktowane, mieć otwarcie i zakończenie. To wiele decyzji do podjęcia w procesie tworzenia modelu.
Skala danych na różnych etapach
Skala danych różni się znacząco w zależności od etapu. W pre-trainingu operuje się na teratokenach, czyli ogromnych ilościach. W porównaniu do Lamy 3, korpusy danych używane w polskich modelach, np. Bieliku, są stosunkowo małe. Dlatego trenuje się je zazwyczaj metodą kontynuowanego pre-trainingu.
W fine-tuningu liczba instrukcji waha się od 10 tysięcy dla specyficznych zadań, do milionów dla modeli ogólnych. Bielik 2 posiada obecnie 5 milionów instrukcji, co jest bardzo dużą liczbą.
Podsumowując, dane stanowią kluczowy element w procesie tworzenia modeli AI. Ich ilość, jakość, zróżnicowanie i dostosowanie mają ogromny wpływ na końcowy efekt. Warto poświęcić im dużo uwagi, przemyśleć każdy aspekt i zadbać o jak najlepsze zbiory treningowe. Bo to, co włożymy do danych, otrzymamy później na wyjściu.
Optymalizacja danych treningowych w modelach językowych AI
Nasze badania wskazują, że nawet dla dużego modelu językowego AI 10 tysięcy instrukcji już robi robotę. Ten dataset jest bardzo mały w stosunku do poprzednich zbiorów danych. Oznacza to, że jesteśmy w stanie zmienić sposób odpowiedzi modelu, np. z bardzo krótkich na bardziej rozbudowane, jak w przypadku ChatGPT. Możemy całkowicie odwrócić działanie modelu za pomocą odpowiednio dobranych instrukcji.
W procesie treningu modeli AI wyróżniamy trzy fazy:
- Pre-training – tutaj liczy się przede wszystkim masa danych, im więcej tym lepiej.
- Pośredni fine-tuning – w tej fazie wykorzystuje się zdecydowanie mniej danych.
- Alignment – ostatni etap, gdzie używa się już naprawdę niewielkiej liczby dokumentów.
Obecnie prowadzimy badania nad wykorzystaniem uczenia wzmacnianego w ostatniej fazie alignmentu. Chcemy, aby nasz model Bielik 2, którego premiera planowana jest na lipiec, przechodził przez wszystkie trzy etapy: pre-training, fine-tuning i uczenie wzmacniane. Ma to na celu dalszą poprawę jakości działania AI. Wstępne wyniki są bardzo obiecujące – obserwujemy znaczny przyrost jakości po fine-tuningu i kolejny po zastosowaniu uczenia wzmacnianego. To potwierdza słuszność podejścia stosowanego m.in. przez OpenAI.
Ogromna skala danych treningowych
Aby lepiej zrozumieć skalę danych używanych do treningu modeli AI, przytoczę taki obrazowy przykład. Popularna książka „Harry Potter i Kamień Filozoficzny” ma około 100 tysięcy tokenów. Oznaczenia literowe ilości tokenów to K (tysiące), M (miliony), B (miliardy) i T (biliony). Żeby dojść do skali T, potrzeba aż 10 milionów takich książek jak Harry Potter! Model Llama 3 trenowano na 15 bilionach tokenów, to naprawdę ogromna ilość danych.
Kiedyś w świecie AI panowało podejście „im więcej danych, tym lepiej”. Wrzucano ogromne ilości treści licząc, że model jakoś sobie z tym poradzi. Jednak w ciągu ostatniego roku trend się odwrócił. Coraz więcej osób zwraca uwagę na kluczowe znaczenie jakości danych treningowych. Twórcy modelu Llama 3 chwalili się, że mocno popracowali nad tym aspektem, wprowadzając m.in. klasyfikatory poprawiające jakość datasetu.

Potencjał współpracy nad polskim modelem językowym
Kiedy odwiedzam targi książki na Stadionie Narodowym, patrząc na ogrom zgromadzonych tam publikacji, od razu myślę o potencjale tych treści dla polskich modeli językowych AI. Oczywiście rozumiem obawy wydawców i autorów o ochronę ich pracy. Nie chodzi o to, by nagle uwolnić wszystkie książki do modeli. Jednak na pewno są takie dane, które za zgodą twórców mogłyby wejść do narodowego modelu językowego, bardzo go wzmacniając.
W Polsce mamy obecnie problem z dostępem do danych, by móc konkurować z gigantami jak OpenAI czy Anthropic. Jednak w kontekście modeli Mistrala, twierdzę, że w ciągu roku będziemy mieli lepsze rozwiązania dla języka polskiego. Już teraz w benchmarkach widać, że model Bielik 2.0 przebija modele Mistrala 7B w kontekście polszczyzny.
Jestem wielkim fanem wszystkich organizacji pracujących nad modelami językowymi w Polsce. Martwi mnie jednak pewne konkurowanie i ściganie się zamiast współpracy. Mamy w kraju bardzo niewiele osób z doświadczeniem w tym obszarze. Dlatego marzę o tym, by kiedyś usiedli oni razem i stworzyli naprawdę potężny polski model językowy. Taki, który mógłby konkurować na arenie międzynarodowej, np. z rozwiązaniami Mistrala.
Koszty trenowania modeli językowych
Trenowanie modeli AI na ogromnych zbiorach danych wymaga bardzo dużej mocy obliczeniowej, a co za tym idzie, generuje spore koszty. Wielkość modelu wpływa bezpośrednio na czas i zasoby potrzebne do jego wytrenowania.
By zobrazować skalę – model o wielkości 10 miliardów parametrów (10B) wymaga już bardzo dużo godzin pracy kart graficznych (GPU). A modele 100B to jeszcze wyższy poziom. Wszystko zależy też od wybranego podejścia – można kupić własny sprzęt, wynająć zasoby obliczeniowe w chmurze albo zbudować partnerstwo jak w przypadku Bielika.
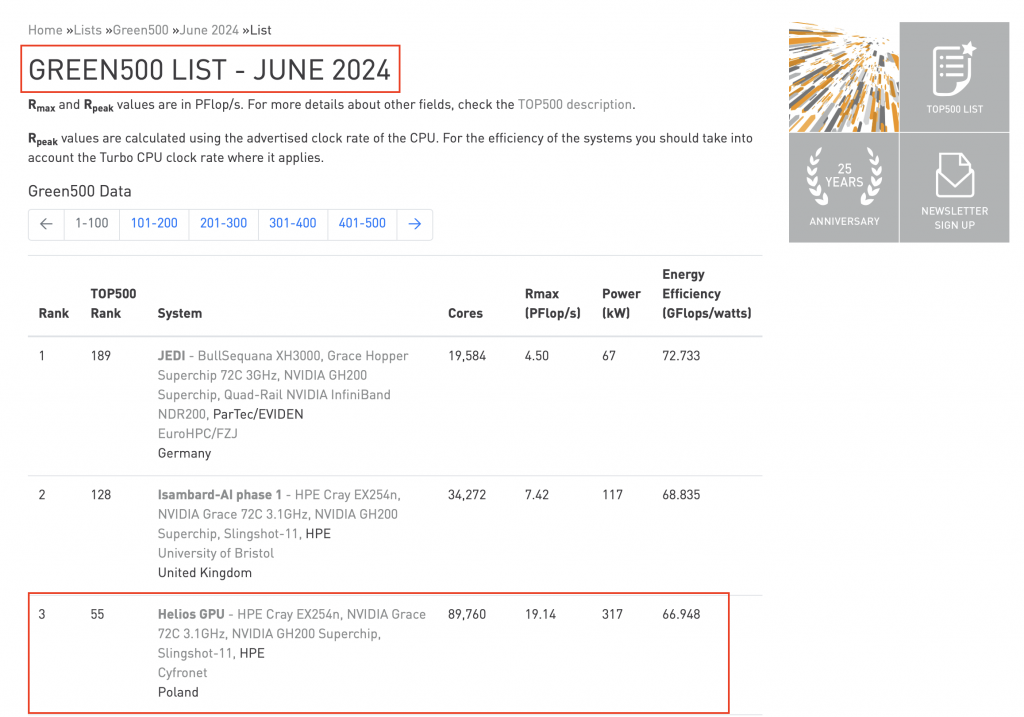
Projekt Bielik miał to szczęście, że nawiązał współpracę z Cyfronetem, który dysponuje najpotężniejszym superkomputerem w Polsce. Maszyna HPE Cray o nazwie Prometheus jest 55. najpotężniejszym komputerem na świecie i 3. pod względem ekologiczności. Cyfronet udostępnił te zasoby, aby przetestować i „wygrzać” maszynę, a jednocześnie umożliwił trening polskiego modelu AI.
To pokazuje, jak owocna może być współpraca nauki i biznesu w tym obszarze. Cyfronet dysponuje unikalną wiedzą na światowym poziomie, a jednocześnie potrzebuje ambitnych zadań, by w pełni wykorzystać potencjał superkomputerów. Z kolei twórcy SpeakLeash początkowo planowali tylko stworzyć zbiór danych, ale dzięki dostępowi do takich zasobów obliczeniowych, mogli pokusić się o wytrenowanie całego modelu.

Warto aby w przyszłości będziemy obserwować w Polsce więcej tego typu partnerstw. To da szansę stworzenia modeli językowych AI, które nie tylko doskonale rozumieją polszczyznę, ale też osiągają najwyższą jakość w skali globalnej. Wymaga to przekroczenia wcześniejszych podziałów i wspólnego działania osób, firm i instytucji, które mają odpowiednią wiedzę i zasoby. Wierzę, że stać nas na to, by kiedyś obok OpenAI, Anthropic i Mistrala wymieniano także polski model jako czołowe osiągnięcie w dziedzinie AI.
Moc obliczeniowa przeznaczona na trening modeli AI w Cyfronecie
Cyfronet, największy superkomputer w Polsce, dysponuje imponującą mocą obliczeniową. Maszyna składa się z 75 tysięcy rdzeni CPU i aż 196 terabajtów pamięci RAM. Dodatkowo, posiada 110 węzłów, z których każdy wyposażony jest w cztery jednostki GPU. Łącznie daje to 440 kart graficznych GH200 – obecnie najsilniejszych procesorów dostępnych na rynku. Jeden taki procesor jest nawet 8-10 razy szybszy od silnego A100.
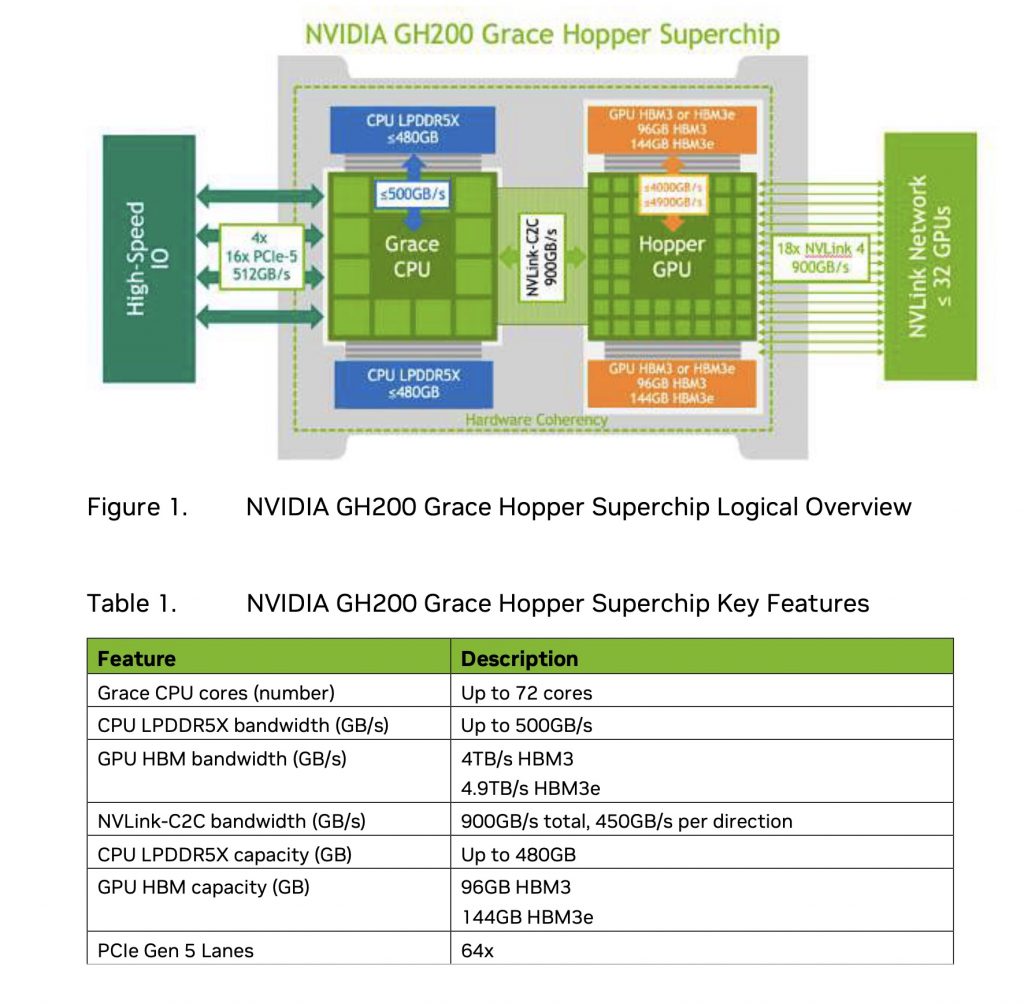
Wszystkie te jednostki są połączone bardzo szybką siecią, co umożliwia synchronizację stanów podczas treningu rozproszonych modeli AI. Chłodzenie zapewnia zaawansowany system przepływu wody przez bloki chłodzące. To prawdziwy majstersztyk inżynieryjny.
Bielik, jeden z polskich modeli językowych, był pretrenowany na 256 kartach GPU w Cyfronecie. Był to największy do tej pory trening przeprowadzony w Polsce. Dla porównania, Meta dysponuje aż 330 tysiącami kart A100, co daje im nieporównywalnie większe możliwości.
Optymalizacja wykorzystania zasobów
W Cyfronecie pracują specjaliści, którzy dbają o maksymalne wykorzystanie mocy obliczeniowej podczas treningów. Monitorują metryki wydajności, optymalizują frameworki i dbają, by maszyna pracowała na krawędzi możliwości bez ryzyka awarii. Krzysiek Ociepa, lider strumienia pre-treningu i fine-tuningu, stworzył autorski framework pozwalający wycisnąć z maszyny jak najwięcej.
Dzięki temu, nawet krótkie kilkunastogodzinne treningi pozwalają uzyskiwać wysokiej jakości modele przy optymalnym zużyciu zasobów. Kolejne etapy jak fine-tuning czy preference optimization wymagają już znacznie mniejszej mocy obliczeniowej i mogą być realizowane nawet na pojedynczych węzłach czy maszynach lokalnych.
Koszty trenowania modeli językowych
Choć dokładne kwoty nie są ujawniane, wiadomo, że pre-training to bardzo kosztowny etap. Dla modelu wielkości 7-10B parametrów koszt może sięgać 100-150 tysięcy dolarów. Modele 70-100B to już wydatek rzędu milionów dolarów. Kolejne etapy jak fine-tuning są już znacznie tańsze.
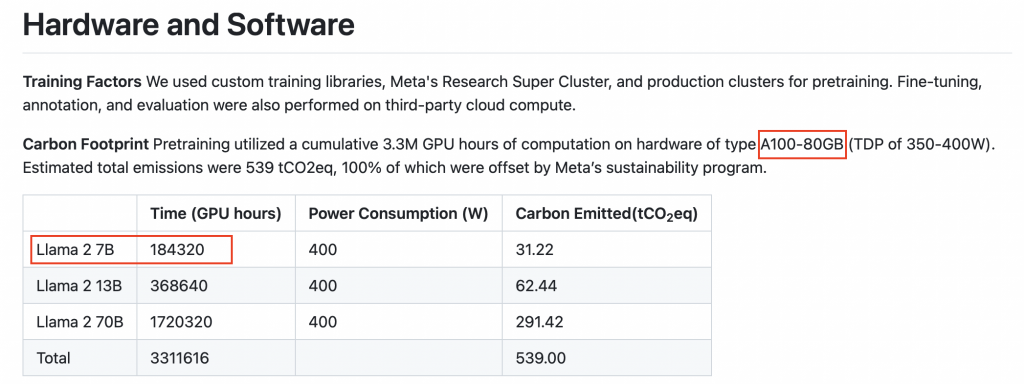
Tak wysokie koszty wynikają z ogromnego zapotrzebowania na moc obliczeniową. Dla przykładu model Llama 2 o wielkości 7B trenowany był przez 100-180 tysięcy godzin GPU na kartach A100. Wynajęcie takiej mocy to wydatek rzędu 1-2 dolarów za godzinę GPU.

Optymalizacja wykorzystania zasobów jest więc kluczowa dla uzyskania jak najlepszych rezultatów przy ograniczonym budżecie. W Cyfronecie udaje się uzyskiwać ponad 95% utylizacji mocy obliczeniowej podczas treningów.
Narzędzia wykorzystywane w treningu modeli językowych
W Bieliku 1 wykorzystywaliśmy Ollama Krzyśka, a w Bieliku 2 sięgnęliśmy po Megatrona od NVIDIA. Bielik 2 to model o innych parametrach – ma 11 miliardów parametrów, czyli jest większy od poprzednika. Ponadto, rozszerzyliśmy kontekst wejściowy do 32 tysięcy znaków, czyli znacznie więcej niż standardowe 4 tysiące znaków w modelu Mistral.
Społeczność odebrała Bielika bardzo pozytywnie. Pierwsze głosy, które do nas dotarły, mówiły: „Dajcie większy kontekst”. Słuchamy opinii osób, które do nas przychodzą. Bielik i SpeakLeash to otwarte społeczności, skupiające obecnie najlepszych w Polsce specjalistów wymieniających się doświadczeniami z zakresu LLM. Wsłuchujemy się w ich potrzeby.
Zwiększenie kontekstu do 32 tysięcy znaków spowodowało problemy z wepchnięciem modelu do treningu nawet na dużej maszynie. Im więcej danych wchodzi, tym bardziej rozszerzają się wewnętrzne stany modelu i potrzeba znacznie więcej pamięci. Musieliśmy sięgnąć po dodatkowe techniki rozpraszające pewne rzeczy na maszynach i node’ach. Tu z pomocą przyszedł nam Megatron.
W fine-tuningu używamy dwóch narzędzi. Pierwsze to Ollama Krzyśka, napisane w czystym PyTorch przez Metę. Nie wykorzystuje ono dodatkowych bibliotek jak Transformers, przez co jest bardziej wydajne przy trenowaniu na dużych maszynach.
Transformers od Hugging Face świetnie sprawdza się w szybkim prototypowaniu rozwiązań, jednak nie jest optymalne wydajnościowo przy trenowaniu na dużych maszynach. Prędkość jest wtedy mniejsza, a wykorzystanie sprzętu gorsze.

Drugim frameworkiem, z którego korzystamy, jest LLaMA-Factory. Próbowaliśmy też Axolotla, ale oba te narzędzia bazują na bibliotece Transformers. Ku naszemu zdziwieniu, wydajność Axolotla jest zdecydowanie niższa niż LLaMA-Factory. Być może to kwestia konfiguracji środowiska, ale jak dotąd nie udało nam się ustawić Axolotla tak efektywnie. Dlatego do ostatniego etapu używamy LLaMA-Factory.
Kiedy warto sięgnąć po fine-tuning modeli językowych?
Wśród niektórych osób pokutuje mit, że fine-tuning to rozwiązanie na wszystko. Mamy dane, więc trzeba model dotrenować. Osoby bardziej techniczne również podchodzą do tego zbyt lekko – dotrenowują mały wycinek, aby lepiej radzić sobie z danymi. Jednak to nie wszystko. Taki zabieg może zepsuć cały dotychczasowy model i więcej stracić niż zyskać.
Osobiście jestem przeciwnikiem nadużywania fine-tuningu. Istnieją lepsze metody korzystania z modeli językowych. Pierwszą z nich jest prompt engineering. Widzimy w Bieliku, jak ludzie czatują i jakich promptów używają. Najczęściej są to proste konstrukcje, bez zaawansowanych technik. Tymczasem istnieje ponad 58 sprawdzonych sposobów na poprawę odpowiedzi modelu poprzez odpowiednie promptowanie.
W 90% przypadków promptowanie w zupełności wystarczy do osiągnięcia bardzo dobrych wyników, bez konieczności kosztownego obliczeniowo fine-tuningu. Zachęcam do nauki zaawansowanych technik promptowania, a nie tylko bazowego „napisz coś tam”.
Drugim ważnym elementem jest kontekst, czyli wiedza modelu. Szeroki kontekst zdecydowanie rozszerza możliwości modeli typu GPT. Jednak tu również dominuje naiwne podejście. Największym wyzwaniem jest odpowiednie przygotowanie danych do wyszukiwania (retrieval), aby później zasilić nimi model językowy (LLM). To bardzo szeroki i skomplikowany temat, wymagający specjalizacji.
Dopiero na samym końcu jest miejsce na fine-tuning. Promptowanie nie zepsuje modelu, retrieval-augmented generation (RAG) może, jeśli źle używamy retrievalu, ale sam model pozostanie nietknięty. Natomiast fine-tuning najczęściej od razu psuje model. Dotyczy bardzo wąskich zastosowań.
Dlatego sugeruję następującą kolejność działań:
- Promptowanie z odpowiednimi parametrami zapytania (temperatura, top-p, top-k itp.)
- RAG, jeśli potrzebujemy szerszego kontekstu
- Fine-tuning, ale tylko w uzasadnionych przypadkach
Trzeba przekonać siebie i innych, że fine-tuning jest naprawdę potrzebny. Osoby niezajmujące się nim na co dzień bardzo go chcą, a specjaliści podchodzą do tematu z dużą ostrożnością, wiedząc z czym to się wiąże.
Oczywiście są sytuacje, gdy fine-tuning jest wskazany. Inaczej wygląda to w przypadku modeli wizyjnych czy klasycznego uczenia maszynowego. Tam często tworzy się modele od zera lub fine-tunuje generyczne rozwiązania. Natomiast w przypadku modeli językowych mamy już wiele sprawnych rozwiązań po fine-tuningu, zarówno zamkniętych, jak i open-source’owych.
Fine-tuning warto rozważyć, gdy mamy do czynienia z bardzo wąską domeną dziedzinową, np. chcemy dostosować model ogólny do zastosowań medycznych. Wtedy może to przynieść korzyści.## Kiedy warto rozważyć fine-tuning modelu językowego?
Fine-tuning warto rozważyć, gdy mamy do czynienia z bardzo wąską domeną dziedzinową, np. chcemy dostosować model ogólny do zastosowań medycznych. Wtedy może to przynieść korzyści.
Kolejna sytuacja, w której fine-tuning może być dobrym rozwiązaniem, to gdy techniki promptowania są uciążliwe. Jeśli za każdym razem model odpowiada nie do końca tak, jak byśmy chcieli, a zależy nam na ustalonym formacie odpowiedzi, np. zawsze w formacie JSON z czterema polami, to nie ma potrzeby ciągle rozbudowywać promptu i dodawać skomplikowanych instrukcji. Lepiej wtedy postawić na fine-tuning.
Fine-tuning sprawdzi się też, gdy zależy nam na bardzo szybkim modelu, który moglibyśmy hostować samodzielnie. Tutaj w grę wchodzą takie elementy jak szybkość, bezpieczeństwo, hostowanie wewnętrzne i koszty. Tworząc model specyficzny dla swojej branży, mamy swój własny model, który możemy uruchomić na własnej infrastrukturze. Taki model jest bezpieczny – wrażliwe dane, np. medyczne, nie wychodzą nawet do chronionej chmury.
Ostatnim przypadkiem, w którym warto rozważyć fine-tuning, jest sytuacja, gdy chcemy nadać modelowi jakiś ogólny kontekst, np. związany z konkretnym językiem. Jeśli zależy nam, aby model wiedział, co to jest żurek, parówka czy rozumiał idiomy, to fine-tuning może okazać się dobrym rozwiązaniem.
Warto jednak pamiętać, że w zdecydowanej większości przypadków (ponad 99%) fine-tuning nie jest potrzebny. Zanim zdecydujemy się na ten krok, warto znaleźć przekonujące argumenty.
Co nowego w Bieliku 2?
Bielik to model językowy dostępny w wersji pierwszej, nad którym obecnie trwają prace nad ulepszeniem. Wersja druga, choć jeszcze nie jest publicznie dostępna, wprowadza wiele usprawnień.
Przede wszystkim Bielik 2 bazuje na znacznie większym korpusie danych. To model 11B (11 miliardów parametrów), czyli większy niż pierwsza wersja. Została też zmieniona architektura modelu poprzez zwiększenie liczby warstw atencji. Kontekst wejściowy został rozszerzony do 32 tysięcy tokenów, co pozwala na przetwarzanie o wiele dłuższych tekstów.
W Bieliku 2 dodano wstępne wsparcie dla Function Calling, choć nie będzie to jeszcze finalny produkt w tej wersji. Przygotowano również odpowiednie tokenizacje i template chata pod Function Calling. W pełni będzie on dostępny prawdopodobnie w Bieliku 3.
Bielik 2 zostanie wytrenowany na konwersacjach (ponad 5 milionów instrukcji), a nie tylko prostych poleceniach. Wprowadzone zostanie też uczenie wzmacniane (Preferences Optimization) służące do dostrajania i dostosowywania modelu.
Dostępne będą wszystkie wersje kwantyzacyjne, co pozwoli na uruchomienie modelu na mocniejszych maszynach, laptopach, a nawet w trybie offline. Przygotowane zostaną też specjalne wersje zoptymalizowane pod kątem sprzętu NVIDIA (TensorRT) oraz środowiska VLLM dla jeszcze szybszej generacji odpowiedzi.
Bielik 2 w testach wypada znacznie lepiej niż pierwsza wersja we wszystkich benchmarkach. Trwają jeszcze prace nad poprawkami zgłaszanymi przez testerów, ale już teraz widać, że będzie to model o bardzo wysokiej jakości.
W stronę multimodalności
W planach rozwoju Bielika jest też stworzenie modelu multimodalnego, który zostanie wydany prawdopodobnie w trzecim lub czwartym kwartale tego roku. Trening takiego modelu jest prostszy niż trenowanie samego LLM.
Bielik 2 posłuży jako podstawa modelu multimodalnego – będzie pełnił rolę enkodera językowego. Zostanie on połączony ze standardowym modelem wizyjnym. Do przygotowania datasetu treningowego również planowane jest wykorzystanie Bielika 2, aby automatycznie wygenerować opisy dużej liczby zdjęć.
Cały projekt Bielika stawia na niezależność i wykorzystanie własnych narzędzi. Twórcy chcą podążać tą czystą ścieżką, unikając używania modeli innych firm do generowania treści treningowych.## Dążenie do niezależności i użyteczności
Cały projekt Bielika stawia na niezależność i wykorzystanie własnych narzędzi. Twórcy chcą podążać tą czystą ścieżką, unikając używania modeli innych firm do generowania treści treningowych.
Zespół SpeakLeash jest bardzo ukierunkowany na użyteczność. Przeprowadzili dodatkowe badania ankietowe, aby sprawdzić, do czego ludzie i firmy wykorzystują duże modele językowe (LLM). Zebrano kilkaset odpowiedzi, które pozwoliły lepiej zrozumieć potrzeby użytkowników. Celem jest tworzenie modeli, które będą miały realne zastosowanie biznesowe.
Co więcej, SpeakLeash chce umożliwić firmom instalację modeli na własnej infrastrukturze. Poza ewentualnym udostępnieniem API, główną ideą jest to, aby modele były jak najbardziej użyteczne i dostępne dla biznesu. Chodzi o to, żeby dać narzędzia w ręce firm i uniezależnić je od SpeakLeash.
Kwantyzacja modeli ma na celu demokratyzację polskich LLM. Celem jest dotarcie z rodzimymi produktami do jak najszerszego grona odbiorców. Bielik 2 ma przynieść kolejne ulepszenia, w tym adaptacje pod VLLM, aby jeszcze lepiej wykorzystać potencjał modeli w praktyce.
Otwartość i zaangażowanie społeczności
Jednym z wyzwań przy pierwszej wersji Bielika była licencja non-commercial, która mogła ograniczać wykorzystanie modelu przez biznes. Wynikało to z warunków licencji danych użytych do trenowania. Jednak już model bazowy i instrukcyjny w drugiej wersji mają być otwarte i umożliwiać komercyjne zastosowania. Fundacja SpeakLeash podjęła kroki prawne, aby to osiągnąć.
Warto podkreślić, że cały projekt SpeakLeash opiera się na wolontariacie i pasji. Ludzie pracują nad nim po godzinach, bez wynagrodzenia, dzieląc się efektami swojej pracy ze światem. Przekształcenie inicjatywy w fundację pozwoliło zyskać osobowość prawną i być poważniej postrzeganym przez firmy i inne organizacje.
Otwartość przejawia się też w udostępnianiu modeli. Każdy może je pobrać np. z Hugging Face i uruchomić lokalnie, nawet bez dostępu do internetu. To sprawia, że polska AI staje się dostępna dla szerokiego grona odbiorców.
Podsumujmy
Trenowanie modeli od zera składa się z wielu etapów. Pierwszym z nich jest pre-trenowanie, którego wynikiem jest model bazowy (pre-trained). Pre-trenowanie może startować od losowych parametrów lub kontynuować pracę rozpoczętą przez kogoś innego. Na przykład Bielik bazuje na wagach z modelu Mistral.
Faza pre-trenowania jest najtrudniejsza i wymaga ogromnych ilości danych. Liczba tokenów idzie w biliony, a czasem nawet cały internet to za mało. Firmy jak OpenAI sięgają po dodatkowe źródła, np. transkrypcje z YouTube. Sam proces trwa bardzo długo i generuje wysokie koszty – setki tysięcy dolarów, porównywalne z ceną mieszkania.
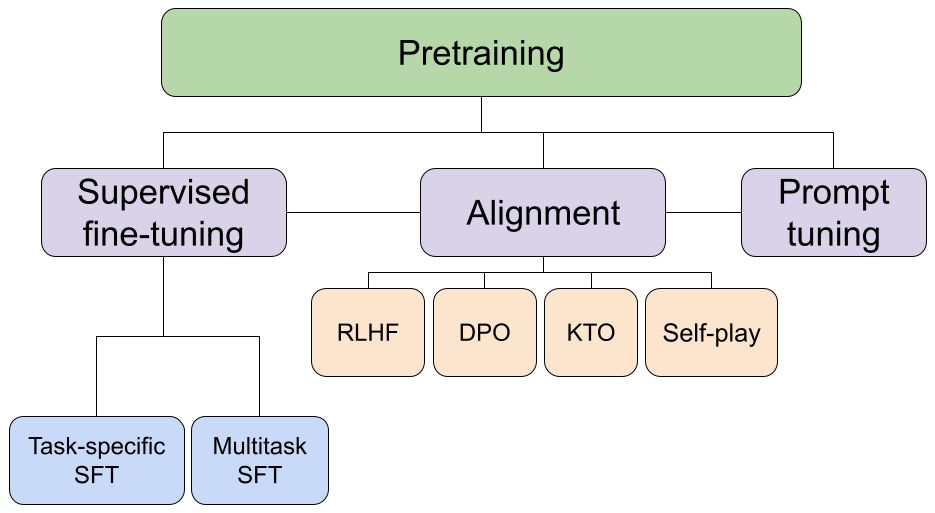
Po pre-treningu otrzymujemy model bazowy, który posiada wiedzę, ale nie potrafi jeszcze rozmawiać z ludźmi. Potrzebny jest kolejny etap – fine-tuning, dzielący się na kilka rodzajów. Pierwszy z nich to dostrojenie nadzorowane Supervised Fine Tuning (SFT), gdzie modelowi wskazuje się odpowiedzi na konkretne prompty. Uczy się go, jak reagować na pytania i polecenia użytkowników.
Część tego procesu można później zautomatyzować, ale trzeba uważać – jeśli instrukcje pochodzą z modeli zabraniających komercyjnego użycia (np. niektóre wersje GPT czy Llama), to wytrenowany na nich model również staje się niekomercyjny.
Po SFT model potrafi już prowadzić rozmowę, ale mogą pojawiać się różne problemy, np. generowanie wielu alternatywnych odpowiedzi bez oceny, która jest najlepsza. Tutaj z pomocą przychodzi Reinforcement Learning from Human Feedback (RLHF). Człowiek ocenia nieliczne odpowiedzi modelu, ustalając ranking od najlepszej do najgorszej. Następnie za pomocą technik Reinforcement Learning te ludzkie preferencje są wychwytywane i proces oceny jest automatyzowany. Dzięki temu model „uczy się myśleć” jak człowiek.
Kolejnym wyzwaniem jest radzenie sobie z nieetycznymi pytaniami użytkowników. Model musi rozpoznać takie zapytania i grzecznie odmówić odpowiedzi. Najnowsze rozwiązania, np. od firmy Anthropic, wplatają te zabezpieczenia bardzo głęboko w architekturę modelu.
Podsumowując, tworzenie modeli AI to wieloetapowy, zrównoważony proces. Trzeba uważać, aby późniejsze modyfikacje (np. fine-tuning) nie zaburzyły tej delikatnej struktury. Wymaga to dużej wiedzy i ostrożności – jak przebudowa domu przez doświadczonego inżyniera. W większości przypadków nie ma takiej potrzeby, a z pomocą przychodzą zaawansowane techniki promptowania. Temat będę poszerzał w kolejnych wątkach, obserwuj mnie :).
Na koniec. Poleć ten odcinek co najmniej jednej osobie, której warto go posłuchać.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
