
Sztuczna inteligencja i bankowość

Robotic process automation zmienia świat! Według KPMG 45% a może nawet i 75% prac w finansowym sektorze będzie wykonywane przez roboty w najbliższe 15 lat. Mówiąc bardziej precyzyjnie, przez tak zwany Robotic Process Automation (RPA). Dzisiaj o tym, ale nie tylko będzie mowa.
Gościem podcastu jest Ernest Wagner, który od 2004 stworzył kilka firm: agencję interaktywną, software house, technologiczny dom doradczy i kilka startupów w modelu SaaS. W 2015 roku stworzył zespół, który uruchomił bank mobile-first o nazwie Loot.io oceniony jako jeden z najgorętszych startupów w UK. Zarządza projektami IT od ponad 16 lat. Od 2014 roku doradza klientom w tematach związanych z danymi i sztuczną inteligencją. Od początku 2017 roku odpowiada za sztuczną inteligencję w ING Banku Śląskim.

Ernest posiada doświadczenie na skrzyżowaniu kilku dziedzin: sztuczna inteligencja, finanse, startupy. Dlatego ta rozmowa czasem była trochę o innych, ale bardzo ciekawych tematach. Na przykład Ernest mówi:
“Bąbel na rynku startupowym niewątpliwie istnieje, może podobny do tego, jak w latach 90-tych, nawet większy, bo jest dużo więcej pieniędzy w tym rynku technologicznym teraz. Wielu mądrych inwestorów, moim zdaniem i których szanuję, przewiduje krach w tym sektorze w najbliższym czasie.”
Również na samym końcu dowiesz się jak dostać bezpłatną godzinną konsultację ze mną.
Już nie przedłużam i zapraszam do wysłuchania.
Cześć Ernest! Przedstaw się kim jesteś, czym się zajmujesz, gdzie pracujesz?
Cześć. Nazywam się Ernest Wagner, jestem odpowiedzialny za rozwój produktów w firmie Hemnes. Obecnie również pracuję dla Banku ING, jako architekt w obszarze sztucznej inteligencji i robotyzacji procesów. Pracuję nad zagadnieniami, związanymi z AI w tym systemami konwersacyjnymi, data miningiem i modelowaniem machine learningowym.
To jak widać wiele rzeczy robisz, o tym będziemy rozmawiać dalej. Dopytam się jeszcze jaką książkę ostatnio czytałeś i czego się nauczyłeś z niej?
Ostatnio najbardziej zwróciła moja uwagę książka Daniela Kahnemana “Pułapki myślenia” i tam kluczową koncepcją jest podział pracy naszego mózgu na dwa systemy. System pierwszy odpowiedzialny jest za bezwiedne ruchy i system drugi – za bardziej złożone myślenie. To są bardzo użyteczne pojęcia, moim zdaniem, dla osób zajmujących się sztuczna inteligencją. To mi trochę pomogło w pracy, oprócz tego że jest ciekawa sama z siebie.
Dodatkowo przeczytałem w parę dni biografie Elona Muska – przedsiębiorcy, który jest moim idolem. Mam równolegle jeszcze dwie inne książki otwarte autorstwa Raymonda Kurzweila.
Singularity?
Dokładnie.
Ta pierwsza książka “Pułapki myślenia”, już była polecana przez dwie osoby przed Tobą, więc widać że w tej chwili bije największe rekordy.



Chciałem ją już dawno przeczytać, ale odkładałem na później. Natomiast jak ją już zaczniesz czytać, to idzie dość szybko, bardzo przyjemna jest ta książka, bardzo fajnie napisana.
Powiedziałeś, że pracujesz teraz dla ING banku, jako architect RPA/AI. Na początek chciałem zapytać, jak wygląda Twój przeciętny dzień pracy, jakie problemy rozwiązujesz, w jaki sposób, może jakich narzędzi używasz?
Mój dzień chyba nie różni się za bardzo od dnia wielu PM’ów czy analityków BI. Odbywam sporo spotkań, jeżdżę na szkolenia i konferencje (zarówno jako uczestnik, tak i prelegent). Bardzo sobie cenię te dni, kiedy mogę spokojnie popracować nad czymś koncepcyjnie, zaprojektować jakiś prototyp, potestować różne narzędzia. Czasami buduje dialogi dla systemów konwersacyjnych oraz zdarza mi się trochę poprogramować. Dzisiaj miałem taki dzień, ale generalnie rzadko to się zdarza. Sporo jest zwykłej koordynacji różnych tematów, czyli tak zwane project management.
To jest ciekawe, że jeszcze programujesz. Rzadko się zdarza, ale jednak się zdarza. Proszę powiedz przykładowe rozwiązania oparte na sztucznej inteligencji które już udało się wdrożyć do ING Banku, a może też zdradzisz takie nad którym pracujecie i już niedługo będą dostępne?
Tu nie wiele mogę powiedzieć bardzo konkretnych rzeczy i pewnie nic, czego samemu można się domyślić, co się w banku robi z AI. Ale spróbuje to skategoryzować. Generalnie, dzielimy działania związane z AI na trzy obszary: data mining albo text mining (czyli wyciąganie encji z dokumentów albo z wiadomości od klientów), systemy konwersacyjne (wewnętrzne i zewnętrzne) oraz najróżniejsze modele analityczne oparte o machine learning w takich obszarach jak ryzyko, sprzedaż i marketing czy KYC & AML.
Zapytam jeszcze coś ogólnego. Czym dla Ciebie jest sztuczna inteligencja?
To jest pytanie, które powraca ostatnio, dość często, w związku z modą. Wydaje mi się, że w związku z takim przełomem w deep learningu, przyjęło się myśl, że prawdziwe AI, to tylko uczące się systemy, albo wręcz wyłącznie tylko sieci neuronowe. Mam podejście troszeczke inne. Dla mnie AI to wszystkie systemy emulujące w jakimś stopniu świadome działanie. Dobrze napisane dialogi chatbotowe w wąskich przypadkach zastosowań tez mogą działać dość inteligentnie.
Podobnie w text miningu, czyli wydobywaniu znaczeń z tekstu, bardzo sprawdzały się bardziej tradycyjne systemy, więc nie skreśliłbym do końca takich mniej spektakularnych rozwiązań. Jestem zwolennikiem dobierania narzędzia do celu, a nie odwrotnie.
A jak w prosty sposób wyjaśnić co to jest chatbot?
Chatbot – to jest system konwersacyjny, czyli program, z którym można odbyć rozmowę. Większośc chatbotów nie stosuje uczenia maszynowego w rzeczywistości, tak naprawde tylko najbardziej zaawansowane systemy, takie jak API.ai czy Watson mają takie moduły.
Wiele polskich chatbotów to są, w szczególności, takie edytory dialogowe gdzie sie panuje “pytanie-odpowiedź, pytanie-odpowiedź” i tak to mniej więcej działa. Więc jeżeli zaliczymy chatboty do sztucznej inteligencji, to wtedy trzeba ją trochę szerzej definiować. Czasami bardzo fajne dialogi można zaprojektować nawet w taki prosty sposób regułowy.
Teraz temat nieco powiązany z chatbotem i zapytam o tym w ten sposób: conversational banking solutions co to jest, jak to działa i co ma wspólnego z chatbotem?
Moim zdaniem, wychodzi na jedno z tą różnica, że do takiego bankowego chatbota dodajemy API czyli interface wymiany danych do usług banku. Czyli umożliwiamy wykonywanie przez rozmówcę różnych czynności typu przelew czy zamówienie karty kredytowej. Ale w swoim podstawowym zakresie czy charakterze, to jest po prostu interface konwersacyjny, taki jak każdy inny chatbot.
Można tak nieco reasumując powiedzieć, że to jest chatbot, który jest zintegrowany z którymś systemem lub systemami.
Tak jest. W ogóle, każdy użyteczny chatbot powinien być z czymś zintegrowany. Jeżeli chatbot jest tylko po to, żeby rozmawiać, to to nie będzie zbyt ciekawa aplikacja, bo w tym momencie nie umiemy jeszcze tworzyć takich turingowych, powiedzmy, systemów, które umiałyby zdać test Turinga w dłuższej rozmowie.
Natomiast chatbot, z którym się zagaduje i on od razu serwuje jakieś dane, gdzieś z kimś się kontaktuje, to może być użyteczna aplikacja. Dlatego każdy chatbot powinien być jakimś “conversational coś tam” (conversational banking, conversational insurance czy conversational e-commerce).
Dopytam się teraz o nieco słynnym terminie Robotic Process Automation albo RPA? Co to jest i jakie to ma zastosowanie z punktu widzenia biznesu i proszę podaj jakiś przykład z życia (żeby bardziej było zrozumiałe o czym mówimy).
Oczywiście. W ogóle z nazwy Robotic Process Automation to jest automatyczna robotyzacja procesów czyli termin dosyć szeroki. To o czym dzisiaj mówimy, kiedy mówimy RPA, to zwykle są systemy, które emulują działanie człowieka. Systemy, które pozwalają zaprojektować nam step by step, czyli w zupełnie prosty sposób krok po kroku, działanie pracownika, zastąpić część najprostszych go działań takim systemem.
Mówimy tutaj o takich rzeczach, jak przepisywanie danych z Excela do bazy danych, czy innych tego typu mechanicznych czynnościach. Coś, czego żaden żywy człowiek nie powinien nigdy robić i nie chciałby robić. Nie wyobrażam sobie, jeżeli spytać jakiegokolwiek przedszkolaka na temat “kim chcesz zostać jak dorośniesz”, to żeby powiedział, że chce wklejać dane do Excela w korporacji 🙂 To jest mało ambitna praca i myślę, że w XXI wieku nikt tego nie powinien robić.
RPA jest konsekwencją niedoskonałości systemów, powiązanych częściowo z tym, że są systemy legacy, czyli takie stare systemy w bankach, na przykład. Systemy, które nie mają wsparcia, dla których nie opłaca się już pisać interfacu wymiany danych czyli API. Albo jakieś inne, bardzo złożone infrastruktury i okoliczności, które powodują, że dział IT nie jest w stanie nadążyć pisać tych wszystkich rzeczy.
https://www.youtube.com/watch?v=VZ4oTuQL6ss
Możemy, na przykład, API między jedna bazą danych a drugą, sobie zamówić, ale czekamy na nią rok, bo jest kolejka różnych prac w IT. I takie RPA pozwala nam w szybki sposób, w parę tygodni, zrobić coś innego. Czyli zamiast zrobić to, jak ja to mówię – po Bożemu, po prostu wymianę danych między systemami, żeby serwery gadały między sobą bezpośrednio, to stawiamy RPA, taki programik, na końcówce, na terminalu (to może być laptop albo jakaś stacja robocza).
Używając technik, takich jak screen scraping, będzie otwierał program jednej aplikacji i przeklejał, na przykład, do pola czy jakieś inne akcje wykonywał, w drugiej aplikacji, i taki proces możemy zaprogramować. Są różne systemy, takie pudełkowe, które to oferują. My w banku, to znaczy zespół kolegi, zaprojektował bardzo fajny system, własny, który też sprzedajemy w grupie. I to jest ciekawe w ING, że mamy taką szczególna ekspertyzę, w tych zespołach bankowych.
Natomiast nadal, pojęciowo, RPA, to jest taka anomalia, powiedzmy, taka nieprawidłowość, która występuje przez jakiś czas. Ona, oczywiście, w tym czasie, kiedy jest wdrożona (nawet jeżeli to jest tak zwana prowizorka), może zaoszczędzić w dużych organizacjach miliony euro, to nie znaczy że to jest mniej ważny system czy nie istotny. Tylko jego wdrożenia wynikają z tego, że te systemy działają (zwłaszcza w dużych organizacjach) niedoskonale. Żaden startup raczej nie powinien korzystać z RPA, chyba że w szczególnych okolicznościach. Ale dobrze zaprojektowana firma, dobrze zaprojektowane procesy powinny unikać konieczności stosowania czegoś takiego.
Bardzo fajnie to wyjaśniłeś, bo często to jest pomijane, dlaczego takie rozwiązanie powstało. Załóżmy że teraz nas słucha osoba, która może rozważa użycie RPA i pewnie zastanawia się nad tym, jak drogie jest to rozwiązanie (pod kątem finansowym, pod kątem zasobów, które musi mieć), i jak to wdrożyć? Troszkę wspomniałeś o tym, że są już gotowe rozwiązania, które można kupić, ale czy mógłbyś trochę rozszerzyć, o ile łatwo jest wdrożyć takie rozwiązanie, czy to są dni, miesiące, lata?
Oczywiście. Jeżeli chodzi o wdrożenie czegoś takiego, to tutaj mówimy raczej o przedziałach czasowych do kilku tygodni, do 2 miesięcy. Moim zdaniem, wdrożenie RPA nie powinno trwać dłużej niż miesiąc – półtora. Mają to być rozwiązanie prostsze niż budowa API, dlatego powinne trwać krócej i być tańsze. To zawsze trzeba porównać, co jest lepiej, czy wymienić system albo jakoś go zintegrować, czy zrobić RPA deployment, który powinien być co najmniej o rząd wielkości tańszy, niż to docelowe, prawidłowe rozwiązanie. Jeżeli chodzi o ceny tych narzędzi, to są bardzo zależne, zwłaszcza dla korporacji.
Są różne cenniki w zależności od ilości robotów, których się zamawia. Ciekawą propozycję słyszałem, ale jeszcze nie testowałem i nie wiem czy powinien reklamować… Workfusion wypuściło chyba za darmo swoje narzędzie RPA, bo oni chcą robić upsell komponentów sztucznej inteligencji do swoich rozwiązań, a to takie podstawowe, regułowe RPA mogą udostępnić za darmo. Nie testowałem tego, nie wiem jak to działa, więc ciężko mi dokładniej coś opowiadać, ale myślę że ich ofertę warto rozpatrzyć, zwłaszcza firmom, które chcą spróbować tego na początek i nie chca decydowac od razu na duże budżety. Myślę że to ciekawa strategia, że oni to udostępnili.
Już porozmawialiśmy trochę o chatbotach, co to jest. Przypomniała mi się nasza ostatnia dyskusja, gdzie poruszyłeś ciekawy temat dotyczący analizy tekstu. Ale nie prosto tekstu, a napisanego w języku polskim. Kilka odcinków temu, rozmawiałem z Basia Fusińską z Microsoftu, dwa odcinku temu z Piotrem Pietrzakiem z IBM i generalnie w platformach dostarczanych przez dużych graczy nie ma albo dopiero raczkuje analiza tekstu w języku polskim.
Najpierw może warto określić dlaczego to jest złe i co powinno się stać, żeby pojawiło się rozwiązanie? Z tego co pamiętam, nawet mniej więcej oszacowałeś koszt tego rozwiązania :).
Tak, mogłem Ci wspomnieć o tym. Podczas rozmów z reprezentantami liderów rynku AI, dowiedziałem się, że oni estymują to w przedziałach 30-50 milionów złotych (dla polskiego języka) koszt takiego wdrożenia modułów NLP do systemów konwersacyjnych czy też analizy tekstu ogólnie. Sam tego nie szacowałem, więc zastrzegam że to jest tylko taki estimate, który do mnie dotarł, ale na pierwsze oko brzmi to realistycznie.
Jest to duży problem, ponieważ z jednej strony mamy bardzo skomplikowany język. Język polski jest językiem fleksyjnym, nie pozycyjnym w przeciwieństwie do języka angielskiego, i z różnych względów jest absolutnie koszmarny w takich procesach, jak tokenizacja, gdzie tracimy bardzo dużo znaczeń.
Tokenizacja, to jest proces wprowadzania wyrazu do podstawowej formy. W języku angielskim zwykle tych form nie ma tak dużo pojedynczych wyrazów, poniewaz nie odmiana tam decyduje tylko pozycja w zdaniu. Natomiast u nas są różne piękne dźwięczne końcówki, przekształcenia, tak jak liczebnik “dwa”, na przykład, ma 17, z tego co pamiętam, odmian w języku polskim, a w języku angielskim tylko dwie. Podczas procesu tokenizacji możemy zupełnie stracić sens i kontekst tego o czym mówiliśmy. Więc język polski jest wyjątkowo niewdzięczny dla systemów NLP i w dodatku nie jesteśmy też tak dużym rynkiem.
Jak pytałem o roadmap’ę Google… to oni nie mają sprzedawców, tylko inżynierów sprzedaży. To mi się strasznie podoba, bo tam nie ma takiej tradycji sprzedaży, jakie mają duże firmy software’owe, że oni przesyłają do korporacji sprzedawców, którzy niewiele wiedzą. Tam rzeczywiście przyjeżdża facet, który był inżynierem w Google, wszystko wie i można było z nim pogadać.
Zapytałem go między innymi o strategię dotyczącą NLP w Google i powiedział, że niestety przed językiem polskim jest jeszcze język japoński i jeszcze kilka innych większych rynków, więc nie zanosi się żeby oni bardzo szybko to zrobili. Gdyby znaleźli klienta w Polsce, który by za to zapłacił, to oczywiście bez problemu. I tu jest problem, bo to jest próg wyjścia na tyle duży, że prawdopodobnie żadna firma w Polsce na to się nie zdecyduje, bo te systemy konwersacyjne jeszcze są innowacją. Mają dużo potencjalnych zastosowań, ale nie sądze żeby ktoś był gotów w tym momencie zapłacić takie pieniądze, zobaczymy. Jestem optymistyczny, że to się stanie w ciągu dwóch lat, ale nie jestem w stanie tego teraz ocenić.
Na podstawie twoich słów, dochodzę do takiej konkluzji, że pewnie Rząd miałby wspierać to rozwiązanie, bo jednej firmy na to nie stać, chyba że firmy się połączą, stworzą związek NLP i zrzucą się razem. Co o tym myślisz, czy jest to realistyczne?
Powiedziałbym tak… Mam nieciekawe doświadczenie z grantami rządowymi i różnie to bywa. Czasami to przynosi świetne rezultaty w takich obszarach wokół przemysłowych i takich bardziej tradycyjnych. W przypadku IT bardzo różnie to wychodzi. Nie wiem czy administracja, taka jaką mamy w Polsce, rozumie dobrze innowacje w swojej masie. To znaczy jest bardzo dużo wybitnych osób, które pracują w NCBR, w PARP’ie i przy uczelniach i agendach rządowych.
Natomiast cała polityka finansowania innowacji w Polsce jest bardzo obciążona ograniczeniem biurokracji, takim typowo biurokratycznym, urzędowym, bym powiedział, odziedziczonym jeszcze z tatarskich tradycji, myśleniem. Niestety, to powoduje że projekty, na przykład, mają dużo więcej dokumentacji niż tego meritum. Są to utrudnienia, ale, oczywiście, byłoby to fajnym pomysłem, żeby Rząd coś takiego sfinansował. Po prostu nie wiem, jak by to było z wykonaniem.
Tak się zastanawiam, bo wiem że brałeś udział w takim wydarzeniu, które odbyło się pod koniec maja – FutureTech. Bo dla mnie to było takim sygnałem (ponieważ pomimo przedsiębiorstw, był również Minister), że jednak są ludzie, które dostrzegają w tym potencjał i chcieliby się w to zaangażować.
Może trochę przesadzam i nie chcę teraz wchodzić w tematy polityczne, ale dla mnie to jest ciekawe i po prostu chciałbym usłyszeć, na ile jest realistyczne, że Rząd będzie wspierał takie rozwiązania NLP dla języka angielskiego, bo jednak to jest ważne.
Bo skutki mogą być takie, że fizycznie język polski jest na tyle trudny, że ciężko będzie zbudować wartościowy chatbot. Z tego będą wynikały różne nieprzyjemne historie, które będą spowalniać biznes. Logicznie by było pomóc, ale tak, jak określiłeś, trafnie i pragmatycznie biurokracja może utrudnić takie ciekawe pomysły.
Nie mówię że to nie jest dobry pomysł i nie powiedziałbym że to jest nierealistyczne, że Rząd będzie chciał w to się zaangażować, podejrzewam, że bardzo łatwo by było przekonać obecne osoby odpowiedzialne za różne agencji rządowe, zwłaszcza pod rządami Premiera Morawieckiego.
Można mieć o nim różne opinie, ale na pewno jest to osoba nastawiona na wspieranie innowacji i bardzo aktywnie na tym polu działająca. Problem, moim zdaniem, nie jest w ogóle związany z chęciami, jest związany z umiejętnością finansowania innowacji. Prawda jest prosta, bo to nie same pieniądze są potrzebne, zarówno odpowiedni proces wspierania innowacji, odpowiedni monitoring, odpowiednie zarządzanie projektem, odpowiednie raportowanie, nieprzeciążone biurokratycznymi wymaganiami.
To są wszystko najróżniejsze parametry i w Polsce, uczymy się tego jeszcze. Moje doświadczenie osobiste i kontakty z administracją były bardzo zniechęcające. Nie mówię, że to się nie poprawia, oczywiście. Bardzo bym tego sobie życzył, żeby tak się działo. Na pewno rynki kapitałowe w Polsce są za słabe, żeby finansować w takim stopniu tego typu innowacje.
Rynek VC (venture capital) jest bardzo słaby, mamy mniej funduszy VC w całej Polsce, w Berlinie chyba o rząd wielkości czy dwa. I to jest tego rodzaju problem, że w samym Berlinie jest więcej funduszy venture capital niż w całym kraju u nas. Więc na pewno prywatny sektor nie udźwignie tych wszystkich wyzwań o których mówimy. Rząd mógłby się zaangażować, ale z kolei nie zawsze wie jak. Dylemat jest trudny do rozwiązania, ale może się uda.
Może zadam trochę łatwiejsze pytanie. Jak radzicie z analizą polskiego tekstu w ING Banku?
To jest bardzo duże wyzwanie dla nas i nie powiedziałbym w żadnym stopniu, że to jest problem rozwiązany w całości. Cały czas nad tym intensywnie pracujemy, zarówno testując różne startupy z zewnątrz jak i próbując własnymi siłami różne rzeczy zrobić.
W banku ciekawą rzeczą jest to, że mamy dział IT który liczy ponad 800 osób, więc programistów jest sporo. Dlatego dużo się dzieje w tym obszarze.
Są tu trzy kategorie wyzwań. Pierwsza – to klasyfikacja albo kategoryzacja tekstu czyli przepisywanie różnych tekstów do określonych z góry kategorii. To może być zarówno w obszarze voice of customer czyli głosie klienta, gdzie bank otrzymuje miesięcznie 400 tysięcy komunikatów od klientów różnej treści i różnymi kanałami, takimi jak e-mail, formularze, media społecznościowe. I to wszystko trzeba analizować i klasyfikować bardzo sprawnie, żeby wrzucać to do odpowiednich procesów obsługi klienta i żeby ta obsługa była jak najbardziej sprawna.
Nie tylko musimy klasyfikować tekst, który przychodzi, ale również wyłapywać odpowiedzi i układać to w drabiny dialogowe, czyli jak ta konwersacja przebiegała. Według założeń omnichannel czyli wielokanałowości, tą konwersację powinniśmy podtrzymywać niezależnie od kanału, czyli zarówno może być tak, że klient zacznie rozmowę w social media, później przerzuci się na maila, a potem skończy się w jakiś inny sposób i powinniśmy za nim nadążać.
Dlatego tutaj ta klasyfikacja i kategoryzacja jest bardzo istotna. Dotyczy ona również zeskanowanych dokumentów, na przykład, w obszarze tekst learningowym. Więc pierwszy problem do rozwiązania, z którym radzimy sobie w 70-80% w pierwszej warstwie kategorii, czasami udaje się lepiej, ale to nadal jest trudne.
Wydobywanie encji z tekstu, to z kolei jest wyzwanie związane ze zlokalizowaniem w komunikatach tekstowych czy w dokumentach zeskanowanych, różnych parametrów. Jeżeli wzięlibyśmy, na przykład, akt notarialny, to musimy zidentyfikować stronę kupującą, sprzedającą, numer księgi wieczystej, jakieś inne jeszcze parametry i je wydobyć z wysoką skutecznością i wprowadzić bezpośrednio do procesów tak, żeby nikt nie musiał tego wklepywać ręcznie do bazy danych.
Ostatnią klasą jest analiza sentymentów (analiza nastroju czy tonu, w jakich komunikat został napisany), co w języku polskim jest trudnym zadaniem. Nasze zwyczaje są dosyć specyficzne, sarkazm jest dosyć popularny, można powiedzieć “świetne usługi” w takim tonie, że jestem nimi zachwycony, a można w tonie sarkastycznym.
Są te same słowa, a musimy je wykryć, bo dla nas to parametry, gdzie między innymi decydują czy coś wpada w kanał reklamacji. Jeżeli klient jest niezadowolony, to dla nas to jest dużo bardziej priorytetowa wiadomość do rozpatrzenia niż pochwała, które też są bardzo mile widziane przez nas, ale wiadomo, jeżeli wszystko jest dobrze, to nie musimy tak szybko reagować. W przypadku negatywnych emocji każda sekunda się liczy, więc jest to wyzwanie.
Myślę że sarkazm w ogóle jest problemem, nie tylko dla języka polskiego, również dla wielu innych i faktycznie jest z tym wyzwanie. Pozwolę sobię trochę zmienić temat.
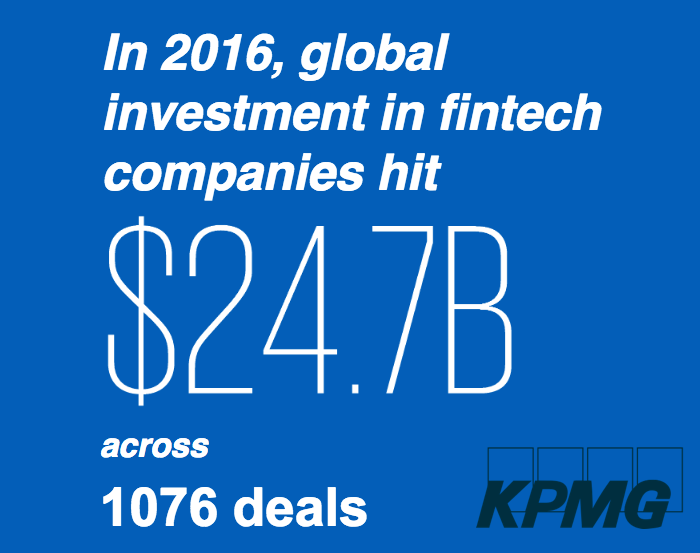
W roku 2016 (zgodnie z raportem KPMG) fintech zebrał 24.7 mld. dolarów inwestycji. To jest całkiem duża kwota. Chciałbym poznać Twoją opinią na temat fintechów, ale najpierw może warto określić czym jest i czym nie jest fintech według Ciebie? Może warto podać przykłady z życia realnego :).
Tutaj, wydaje mi się, definicja jest o tyle prosta, że mianem fintech określa sektor firm technologicznych i jednocześnie zaangażowanych w sektorze finansowym.To będą różnego typu aplikacje bankowe albo wokół bankowe, ubezpieczeniowe, płatnościowe i tego typu, ale też przy fintechu rozszerza się to o firmy, które w jakiś sposób budują funkcjonalności dla tych sektorów. To mogą być narzędzia, które nie obsługują end to end procesu klienta, ale dostarczają jakieś małej wartości, jakiegoś małego elementu w tym procesie.
Widziałem kiedyś, w Wielkiej Brytanii była firma, która umożliwiała klientom robienie zdjęć i filmów nieruchomości swoim telefonem komórkowym, i na tyle dużo informacji zbierała i w taki sposób była skonstruowana, że w półautomatyczny sposób była w stanie ocenić wartości nieruchomości bez wizyty agenta na miejscu. Nie było to całościowym procesem finansowym samo w sobie, ale było to świetną usługa dla firm ubezpieczeniowych. Tego typu różne częściowe rozwiązania też jak najbardziej należałoby do fintechu, moim zdaniem, zaliczyć.
Wspomniałeś tutaj o tym ile fintechy zbierają pieniędzy i oczywiście jest to spora kwota.
Już powiedziałem, że w roku 2016 było zainwestowano ok. 25 mld. dolarów, natomiast rok przed tym, 2015, było ok. 47 mld. dolarów. Wychodzi na to, że prawie dwa razy mniej. Jedynie w Chinach zainwestowali w 2016 więcej niż w 2015. Stany oraz Europa już podeszły z większą ostrożnością.
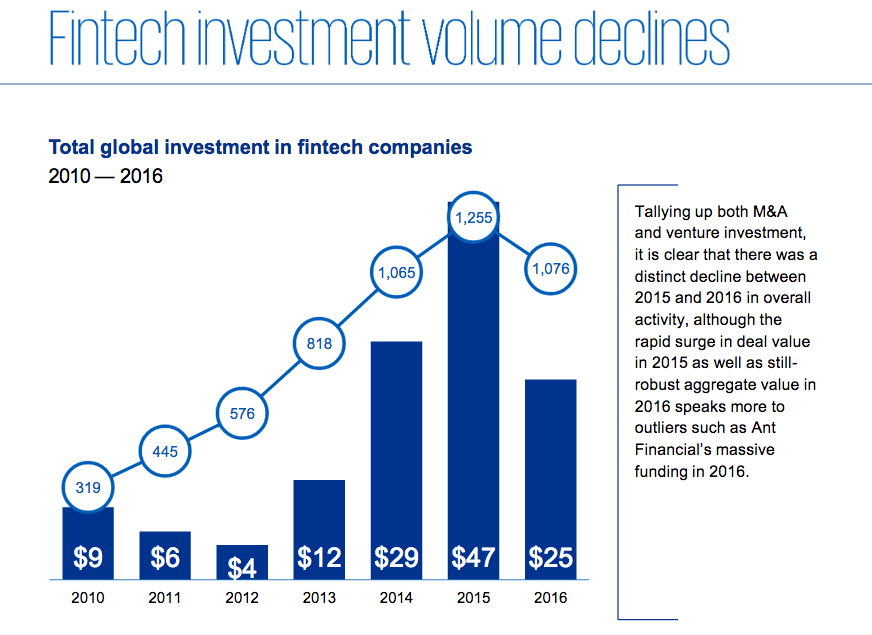
Oczywiście w roku 2016 były takie wydarzenia jak Brexit i to mogło dość negatywnie wpłynąć. Czy fintech to jest jest kolejny bąbel który został rozdmuchany, ale rzeczywistość zweryfikowało i inwestorzy przestali ufać w “obiecanki”. Jaka jest Twoja opinia na ten temat?
Moje spojrzenie na to jest takie, że po pierwsze, banki powoli się budzą i to nie jest tak że na każdej fintech’owej konferencji połowa to nie są ludzie wysłani przez banki, więc banki to bardzo ostrożnie obserwują. Wszystko zależy indywidualnie od banku.
Mogę powiedzieć za bank z którym współpracuje i który obserwuje z bliska, czyli ING. Tutaj bardzo intensywne prace trwają w obszarze fintech. Bank współpracuje z różnymi startupami i je wspiera, jak również produkuje własne startupy. Na przykład, innovation lab’y, zresztą niektóre firmy je również mają. Tam pracownicy, których pomysł zostanie wybrany w trybie konkursowym, są oddelegowani, pracują w trybie Scrum’owym, w trybie Lean Startap’owym, w trybie serwis designu czyli zupełnie poza strukturami tradycyjnej korporacji i budują niesamowite produkty.
Jeżeli chodzi o to, czy fintech się kończy, czy te obietnice były puste…Myślę że nie. Myślę że to były fantastyczne narzędzia, natomiast nie należy nigdy zapominać o wadze akwizycji klientów i o ile łatwo jest prowadzić tą akwizycje w tej pierwszej fazie krzywej dyfuzji innowacji czyli tych early adopters, tych wczesnych innowatorów, tych klientów, którzy będą stać w kolejce po nowy Iphone albo tych klientów, którzy mieli płaskie telewizory jak kosztowały po 40 tysięcy.
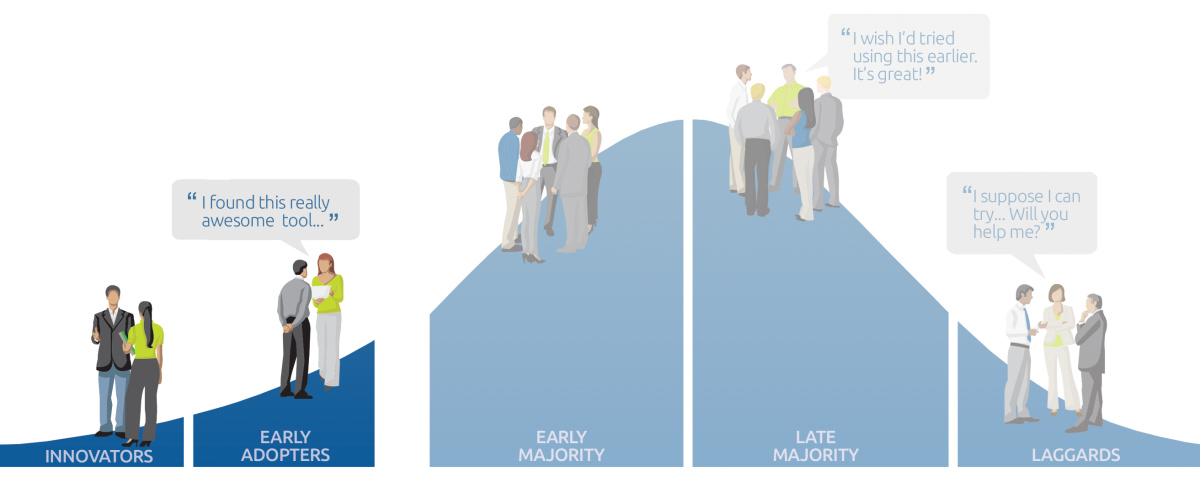
To są tacy ludzie, którzy wydają duże pieniądze, albo dużo poświęca żeby zawsze mieć najnowszą rzeć i ich jest całkiem sporo na różnych rynkach. Im bardziej zaawansowany i rozwinięty jest rynek, tym jest ich więcej.
Ale należy pamiętać, że prawdziwy sukces, to jest przejście z tej grupy klientów na grupę klientów mainstreamowych. Tutaj mi się wydaje, wbrew temu co wielu założycielom startapów się wydaje, ten etap jest nie taki prosty, a dużo trudniejszy. Ponieważ startupowcy, i to też mogę powiedzieć za siebie, bo też byłem w takim stanie często, duszą się we własnym startupowym sosie.
Wszyscy ich znajomi to są power userzy, wykorzystują najróżniejsze aplikacje, interesują się technologiami, więc oni tak rozglądając się dookoła, myślą że świat tak działa, ale trzeba pamiętać że nie tylko w Polsce, no i w Stanach i Wielkiej Brytanii jest cała masa klientów którzy nie korzystają nawet za bardzo z internetu obsługi banków, a co dopiero on-boarding robić poprzez aplikację mobilną, żeby założyć konto.
To są świetne narzędzia i nikt nie może powiedzieć, że one nie są użyteczne i sensowne. Ale nie można zapominać o tym, że ludzka mentalność, a zwłaszcza w tym późnym mainstreamie bardziej tradycyjnych klientów, nie nadąża za tymi wszystkimi innowacjami. Ludzie nie lubią zmian tak bardzo, jakby się wydawało. Niestety ta baza klientów, którą cieszą się banki to jest coś, co dla startupów nie będzie tak łatwo dostępne. Mi się wydaje, że z każdą rewolucją technologiczną idą oczekiwania rewolucji światowej, tak było pod koniec lat 90-tych, tak było w przypadku wielu technologii jak pojawianie się smartphonów i aplikacji mobilnych, gdzie miliony i miliardy zarabiało się na tych aplikacjach.
Ale faktycznie jest tak że “rynek jest rynek jest rynek jest rynek”, jak to mówi Gary Vaynerchuk, a po prostu co mi zrobisz, jak nie kupię, bo mi się nie podoba, bo nie lubię, bo to jest nowe i co z tego że jest lepsze i to nic nie zmienia. Więc trzeba docenić długofalowe plany, trzeba pamiętać że rynki zmieniają się powoli w swojej masie, i to że przekonamy 10% rynku bardzo innowacyjnych ludzi, nie zawsze znaczy że podbiliśmy serca wszystkich potencjalnych klientów.
Myślę że to dotyczy nie tylko fintechu, no i wielu startupów na świecie. Uber, na przykład, jest bardzo mocno przewartościowany.
Bąbel na rynku startapowym niewątpliwie istnieje, może podobny do tego, jak w latach 90-tych, nawet większy, bo jest dużo więcej pieniędzy w tym rynku technologicznym teraz. Wielu mądrych inwestorów, moim zdaniem i których szanuję, przewiduje krach w tym sektorze w najbliższym czasie.
Może tak być, bo za dużo pieniędzy zostało wpompowane w rynki startupowe i trzeba teraz postępować bardzo ostrożnie. To nie znaczy, że każdy startup się nie nadaje i że żaden startup nie ma szans dostarczyć według obietnic, ale na pewno trzeba patrzeć na to ostrożnie, tak jak zaczęli robić to inwestorzy.
Ciekawe to co ująłeś, nawet przestraszyłeś. Myślę, że osoby, które w tych tematach siedzą są na bieżąco. Ale wydaje mi się, że moi słuchacze raczej są mniej zaangażowane w inwestycje, dlatego to jest bardzo ciekawa informacja.
Jak duży potencjał fintech ma w Polsce (według Ciebie)?
Ciężko mi to ocenić kwotowo, bo nie mam w głowie liczb, jak to wygląda dokładnie w Polsce, ale bym powiedział że bardziej systemowo. Bo jak zwykle cyfry cyframi, ale warto rozumieć co się za tym wszystkim kryje. Moje teoria na ten temat, a trochę o tym myślałem, jest taka że w Polsce sektor fintechowy nie będzie tak gorący.
Nie był tak gorący i już nie będzie tak gorący (proporcjonalnie) jak w Wielkiej Brytanii, w Niemczech czy Stanach Zjednoczonych, z tego powodu, że większośc innowacji fintechowych odbywa się w okolicach banków konsumenckich, nie inwestycyjnych. Jeżeli chodzi o bankowość konsumencką, to w Polsce ona jest jedna z najnowocześniejszych na świecie, bo tak się złożyło historycznie, że mamy dosyć młode banki, większość z nich całkowicie się reformowała, albo powstawała w latach 90-tych i zeszłej dekadzie.
Alior Bank – to bardzo młody bank, Mbank powstał pod koniec lat 90-tych i to są banki które były bardzo dobrze przygotowane do rewolucji technologicznych i, powiedzmy, są zapóźnione w stosunku do rynku może o jedną albo o pół generacji, podczas gdy banki w Wielkiej Brytanii czy w Stanach były opóźnione o dwie trzy generacje w stosunku do tego co się dzieje teraz na rynku technologii. W Stanach do dzisiaj ludzie sobie pocztą czeki wysyłają, co u każdego klienta polskich banków budzi histeryczny śmiech, ale taka jest rzeczywistość tamtych rynków. Mimo tego że się mówi, że Anglia jest światową stolicą bankowości i bankowości inwestycyjnej, natomiast bankowość konsumencka tam wygląda jak opowieściach Dickensa.
Jak robiłem przelew, prowadząc interesy w Anglii do Polski, to za ekwiwalentem kilku tysięcy funtów przelewu do Polski, bank chciał pobierać opłatę 50 funtów za każdy taki przelew i to jest jakieś nieporozumienie. Więc nie dziwie że takie fintechowe startupy jak Transferwise zagarnęły praktycznie całkowicie rynek transferów międzynarodowych z Wielkiej Brytanii.
Ale ta łatwość, z jaką fintechy zdobywały rynek, wynikała w bardzo dużym stopniu z cech tego rynku, z zacofania tego rynku i z kompletnej nieudolności tamtejszych banków do tego, żeby się reformować. Podejrzewam, że te sygnały są na tyle bolesne dla nich i na tyle dużo rynku straciły w pewnych sektorach, dla pewnych usług, że teraz będą bardzo intensywnie się reformować, ale może dla nich być za późno.
W Polsce fintechy nigdy nie zagarnęły bardzo dużych części rynku konsumenckiego. Jedynym spektakularnym przykładem fintechowym w mojej głowie jest Cinkciarz i potem jemu pochodne startupy do przewalutowania, właśnie dlatego, że banki konsumenckie były troszeczkę zbyt pazerne przy spreadach i opłatach za przewalutowanie. Natomiast w Anglii, którego tematu w bankowości detalicznej człowiek się nie dotknie, to można zrobić biznes.
Myślę że na tym polega systemowa różnica między tymi rynkami i jeżeli by coś tutaj dodać jeszcze dla polskich fintechów, to bardzo bym sugerował dużą ostrożność, na przykład, w kopiowaniu pomysłów ze Stanów i z Wielkiej Brytanii. Często startupy tak robią i nie zawsze to była zła strategia (wręcz często trafna), natomiast w przypadku fintechów, kopiowanie strategii, patrząc na startup Amerykański czy Brytyjski i przenosząc na polski rynek, można się naciąć. Ponieważ polskie banki są dużo lepiej przygotowane do konkurowania w tych obszarach.
To zapytam jeszcze o polski rynek. Alior Bank w marcu tego roku ogłosił strategię “Cyfrowy Buntownik” i mają zamiar zainwestować 400 mln. złotych na innowacje w najbliższe 4 lata. Warto też wspomnieć o Huge Things wspieraną przez Alior Bank. Jesteś członkiem Związku Banków Polski (ZBP), więc masz szerszy pogląd, ciekawy jestem jak z Twojej perspektywy wygląda wdrożenie sztucznej inteligencji, RPA w polskich bankach?
Ciężko mi powiedzieć co te banki robią u siebie, ale rzeczywiście, gdybym miał się oprzeć o to, co widzę w ZBP (w szczególności należę do grupy Cognitive banking i to nie jest tak, że do końca mam pełny ogląd sytuacji na rynku bankowych innowacji czy też w obszarze RPA), rzeczywiście (w tej grupie) banki zajmują się sztuczną inteligencją. I tu bym powiedział, że niewiele tam słychać. Nie wierze w to, że nie robią nic albo tak mało, jak można się domyśleć z tej debaty. Natomiast nie mam jakichś podstaw, żeby powiedzieć, że jest jakaś niesamowita eksplozja.
Bardzo często reprezentanci z innych banków się nie pojawiają na tych spotkaniach, bardzo aktywnie uczestniczą dostawcy vendorzy (Microsoft, IBM, wiadomo liderzy rynku i kilka mniejszych firm). Staram się być tam za każdym razem. Bardzo fajnie idą prace z partnerami vendorami. Natomiast muszę przyznać, że dla mnie jest trochę dziwne, że moich odpowiedników z innych banków jest niewiele, ale nie chcę tutaj nikogo obrazić, ani powiedzieć że nic się nie dzieje. Ale ciężko mi to ocenić, w związku z tym że bardzo mało sygnałów w ZBP odbieramy.
Brzmi to jako cisza przed burza albo zastanowianie się co z tym zrobić.
Może to jest w trybie tajemnicy.
Zapytam jeszcze o ograniczenia rozwoju, też to jest trochę powiązane z fintechem, sztuczną inteligencją. Chodzi mi teraz o integrację z bankami, żeby robić przelewy w prosty sposób tam i z powrotem.
Na przykład, ktoś chce napisać prostą aplikacją i zintegrować się z bankiem, żeby pobierać opłaty. To dostać się do banku raczej jest dość trudno, przynajmniej wprost. Są pośrednicy, nie będę ich wymieniał nazwę, którzy są pomiędzy bankami i klientami. Ale podobno to ma się zmienić… przynajmniej w teorii.
Teraz mam na myśli Open-API banking lub PSD2. Jaka jest Twoja opinia, z punktu widzenia praktyka. Gdzie jesteśmy teraz, czy to będzie wspólny standard dla całej Europy no i kiedy PSD2 może zacząć działać dla prostego dewelopera? Czy jest realistyczne, że w najbliższym roku – dwa, deweloper będzie w stanie zintegrować się z bankiem, czy jednak to potrwa z dobrych 5 lat.
W ogóle bym powiedział, że to jest świetny rok żeby ten temat podjąć i wszelkie startupy, które tym tematem się zajmują, prawdopodobnie wiedzą o tym i już biegają po bankach. Natomiast osoby, które szykują taki startup i jeszcze nie zaczęły tego robić, to tak, bardzo polecam tym tematem się zająć. Jest to temat gorący, moim zdaniem, w każdym banku, który poważnie traktuje regulacje, a banki – to są takie instytucje, które z definicji ich traktują poważnie. Najbardziej regulowany chyba sektor gospodarki cywilnej.
PSD2 to jest regulacja, która między innymi Open-API narzuca bankom, tzn. konieczność otwarcia ich systemów na rynek startupowy, oraz cała masa drobniejszych regulacji, które pod to wchodzą. W odpowiedź na to polskie banki, w ramach ZBP, budują wspólną platforme, która się nazywa Polish API. Mogę mniej wiedzieć na ten temat, ponieważ tym projektem zajmują się bardziej inne osoby, niż ja.
Natomiast uczestniczę w tych spotkaniach i słyszę, że dużo się dzieje, przynajmniej w ING, gdzie jak najbardziej te rzeczy będą otwarte, moim zdaniem, zgodnie z harmonogramem. Kary są dosyć wymierne dla banków za brak tego otwarcia, więc mi się wydaje, że wszyscy to dosyć poważnie potraktują. Jesteśmy wizytowani przez wiele vendorów, którzy oferują różne narzędzia. Różne startupy, który przygotowywały elementy tej platformy, jakieś aplikacje wspomagające. Oczywiście pojawiają się startupy, które też chcą z tego korzystać. Absolutnie temat bieżący, absolutnie temat poważny.
Myślę, że to super wiadomość dla startupów i osób, które chcą integrować się z bankami. W sumie wszystkie projekty e-commerce w ten czy inny sposób chcą to robić. Ale jedziemy dalej…
Na ostatnim spotkaniu mówiłeś, że istnieje bardzo dużo wyzwań, które mogą być rozwiązane przy pomocy machine learning. I podobnie każdy z nich to może być startup. Również powiedziałeś, że bardzo chętnie podejmiesz współpracy z nimi, pod warunkiem, że faktycznie dostarczą rozwiązanie. Jako przykład pamiętam temat związany z biouwierzytelnieniem (głosem albo odbitkiem palca).
Proszę wymień jeszcze kilka innych aktualnych tematów dla większych firm? Co, na przykład, osobiście możesz kupić albo zacząć rozmawiać o kupowaniu tego produktu.
Nie mogę na pewno czynić deklaracji zakupowych, bo dział zakupu “powiesił by mnie na własnych sznurówkach” :). Mam bardzo twarde procedury w banku, związane z etyką, konfliktami interesów i różnymi takimi rzeczami, dlatego nie mogę powiedzieć co bym kupił. Ale w szerszym i bardzo ogólnym kontekście mogę powiedzieć jakie tematy są aktualnie i jakich poszukujemy na rynku.
Cały obszar NLP, to jest coś co nadal nie jest rozwiązane (o tym rozmawialiśmy wcześniej), ale nie tylko. Nawet bym powiedział platformy chatbotowe, takie zwykłe, są mile widziane w bankach i mi się wydaje, że warto chodzić na spotkania i pokazywać swoje rozwiązania. Ale tak jak powiedziałeś, to wszystko musi działać. I te firmy, które dostarczają produkty do banków, muszą być dobrze przygotowane, mieć produkt który działa i jest stabilny.
Warto pomyśleć żeby działał on nie w chmurze. Ponieważ banki mają bardzo duży problem z wyrzucaniem danych na zewnątrz. Ta kultura się powoli zmienia i myślę, że za parę lat banki będą pracować w chmurze publicznej częściowo, ale będzie to droga przez mękę i na tym etapie są bardzo duże opory. Nawet jeżeli prawnie to jest teoretycznie dozwolone, to warto się nastawić też na taką opcje, gdzie jesteśmy w stanie postawić serwer czy wstawić oprogramowanie on premise.
Wiele startupów, które do nas przychodzą nie zdają z tego sobie sprawę, jak trudne jest dla nas proceduralnie i prawnie wrzucanie danych klientów na zewnątrz. Ponieważ jesteśmy tylko administratorem danych, takim jak inne firmy, ale jesteśmy bardzo regulowanym, bardzo podświetlaną instytucją jako bank i nie możemy sobie tymi danymi tak szastać.
Zresztą, każdy kto daje dane do banku swoje transakcyjne, swoje bardziej wrażliwe, zakłada, że w banku jak w banku, bezpiecznie. Mamy bardzo duże opory, żeby te dane na zewnątrz eksportować, ale myślę, że w obszarze KYC & AML, bioauthentication też to wchodzi.
Ale widzę sporo dobrych rozwiązań na rynku w tym momencie, więc mi się wydaje, że jeżeli ktoś nie ma takiego rozwiązania już od jakiegoś czasu, to bym się skupił chyba nad czymś innym, jeżeli chcemy startupować.
Nawet obszar NLP, który ma wiele dziedzin, które ma tu dostarczyć, niekoniecznie cały system, który jest olbrzymi, ale pewne jego składowe elementy, może elementy morfologii albo elementy słowników ontologicznych, może słownik pojęć finansowych.
Najróżniejsze rzeczy mogłyby się przydać, tylko trzeba, po pierwsze, dobrze znać swoją branżę, po drugie mieć zespół, który pozwala na ciągłą dostępność. Jeżeli to są dwie osoby startupujące, to dla dużej instytucji, to bardzo szybko się okazuję, że nie są w stanie dostarczać na czas.
Polecałbym za banki się brać, jak się ma zespół co najmniej 5-osobowy i raczej bardzo dyspozycyjny. Bo jak trzeba coś zmodyfikować, coś dopisać trochę kodu i nie ma kim to zrobić, to trwa całe miesiące, a bank nie ma czasu. Jeżeli to jest dynamiczna instytucja, taka jak ING, to ma dużą niecierpliwość i frustracje, w związku z takimi rzeczami. Mi się wydaję, że to są takie trudności w obsłudze banków.
Oprócz tego zauważyłem, że większe sukcesy odnoszą startupy prowadzone czy zakładane przez byłych pracowników banków, ponieważ ci ludzi bardzo płynnie się poruszają po realiach banku. Jeżeli takiego doświadczenia nie mamy, jako startup, to warto z kimś takim być w kontakcie albo zatrudnić jako konsultanta, albo inna firmę która ma z bankami doświadczenia. Bo można się wywalić na wielu bardzo oczywistych rzeczach bankowości, a kompletnie niedostępnych dla kogoś, kto tej branży nie zna dobrze. Więc to takie moje rady.
Jeżeli chodzi o mechanizmy, to nieskończoność różnych rozwiązań od prognostycznych modeli, modeli propensity różnego typu, bardziej zaawansowanych machine learningowych adaptywnych algorytmów, ryzyka na różne sposoby, w bankowości jest bardzo dużo takich przykładów. Myślę że jak ktoś już działa w tym obszarze, to będzie wiedział co takiego może się przydać.
Na dzień dzisiejszy sztuczna inteligencja jest jak poszukiwanie złota, wiele firm o tym słyszało, próbując biec gdzieś… bo już świadomość rośnie i wiedzą, że raczej muszą. No właśnie… Jako osoba (praktyk), na co dzień kierujesz strategiami związanymi z projektowaniem, implementacją oraz wdrażaniem projektów sztucznej inteligencji w dużym banku (TOP 5).
Co możesz doradzić osobom które dopiero chcą zacząć używać uczenia maszynowego, sztucznej inteligencji czy RPA. Na co należy zwracać szczególną uwagę i jakie klasyczne błędy popełniają początkujący?
Na początek warto zaprosić bardziej doświadczonych, firm konsultingowych, zewnętrznych, które takie projekty robiły. Bo samemu eksperymentować ze sztuczną inteligencją – to jest bardzo długa krzywa uczenia się. Tutaj naprawdę trzeba mieć dużo doświadczenia. Ale zanim tam dojdziemy, powiedziałbym że dla wielu firm AI nie będzie miało zastosowania z kilku powodów…
Po pierwsze, że nie mają dość dobrej jakości danych albo w ogóle mają za mało danych. Jednak wiele mechanizmów jest związane z dostępnością Big Data. Często, jak rozmawiam z klientami, to mówię, że jeżeli nie odrobiliście pracy domowej przy poprzednim hypie czyli Big Data (parę lat temu), to teraz będzie trudno wam załapać się na hype typu sztuczna inteligencja.
Wynika to z tego, że większośc modeli czy rozwiązań sztucznej inteligencji opiera się o Big Data, jeżeli nie „big”, to przynajmniej średnie data. Muszą to być nie tylko w miare duże zbiory danych, ale również zbiory danych, które w jakiś sposób dobrze przygotowane, posortowane. Nie zawsze muszą być strukturyzowane, ale muszą być w odpowiedni sposób przygotowane do odpowiednich modeli.
Warto pamiętać że nie zawsze trzeba mieć Data Lake. To często się manifestuje w postaci Apache Hadoop Stack, czyli takich rozwiązań jeziora danych, głównie opartych o Hadoop, Spark. Często na zwykłym serwerze SQL’owym można bardzo dużo ciekawych analiz i modeli zbudować. Wszystko zależy od tego, w jakiej skali funkcjonujemy.
Ostatnia rada to taka, że podejdźmy do tego bardzo pragmatycznie. Nie róbmy SI czy AI dla AI, bo to jest hype i cudowna technologia, ostatni ludzki wynalazek i wszystko prawda. Ale ten olbrzymi wpływ jaki technologie AI będą mieć niestety, i to może jest trochę niesprawiedliwe, ale będzie największy dla największych firm. Takie firmy jak Facebook, Google mają największe zbiory danych i będa miały największe korzyści z AI. Wiele średnich firm i niektóre nawet duże, które nie zbierają dane, po prostu dla AI nie będą miały zastosowania.
RPA – zupełnie inna sprawa. Dla RPA, zwłaszcza w polskich firmach, będzie sporo takich bardzo prostych prac, związanych z przepisywaniem czegoś. Pracowałem na rynku IT w charakterze konsultanta wiele lat i widziałem w różnych firmach różne dziwne rzeczy. I jest trochę takiej kultury, jak “brak automatyzacji pracy”, brak takiego podejścia, że zanim się coś zdeleguje najpierw powinno się to zautomatyzować, powinno się upewnić czy to nie jest głupia robota.
Tutaj trochę okazji do zastosowania RPA będzie, żeby tę prostą, nieproduktywną pracę zautomatyzować, a tych pracowników oczywiście nie zwalniać, tylko wyszkolić w taki sposób, żeby mogli robić rzeczy bardziej ciekawe i budować więcej wartości dla firmy. Bo to zawsze jest tak, że można dostarczyć trochę więcej tych usług, trochę więcej wartości, nie zawsze warto konkurować ceną i cięciem kosztów tylko.
Jakie największe wyzwanie miałeś do rozwiązywania związane ze sztuczną inteligencją?
Myślę, że takim największym rozwiązaniem nadal są wszelkie zagadnienia związane z procesowaniem tekstu. I to zarówno w obszarze tekst miningowym, learningowym trochę, ale jeszcze bardziej w obszarze konwersacyjnym. To są problemy trudne do rozwiązania, nie trywialne.
Jeżeli chodzi o modelowanie i zastosowanie machine learningu, to są rzeczy, które często jednak się replikuje na gotowych modelach, jakichś dobrych praktykach, tu przygotowanie danych zwykle jest trudne. Jeżeli chodzi o NLP, to w wymiarze języka polskiego, nadal problem jest nierozwiązany.
Jaki projekt lub konkretne rozwiązanie sztucznej inteligencji najbardziej Cię zaskoczyło?
Najbardziej mnie zaskoczyła sytuacja z zeszłego tygodnia, kiedy się okazało, że w takim projekcie proof of concept, bardziej eksperymencie tekst miningowym, przy dokumentach nieustrukturyzowanych (czyli robiliśmy to dla umów czy aktów notarialnych), kiedy próbowaliśmy wydobywać encje (czyli konkretne jednostki danych, jednostki tekstowe), i się okazało że bardzo niewiele będziemy stosować w tym machine learningu czy deep learningu, a bardzo dużo rzeczy udało się obsłużyć regexp’em czyli takimi regularnymi wyrażeniami.
W języku potocznym można powiedzieć zwykłymi warunkowymi, regułowymi stwierdzeniami programistycznymi. I tak naprawde w tym całym AI się okazało, że będzie dużo mniej AI niż wszyscy się spodziewaliśmy. Czyli jak wcześniej mówiłem, warto się upewnić że na pewno to AI jest potrzebne. Bo bardzo wiele problemów, jak do nich podejdziemy na spokojnie i bez tej całej otoczki hypowej AI, można rozwiązać często w prosty sposób, czyli jak mawiał Konfucjusz:
“Nie wytaczaj armaty na komara”.
Dokładnie. Bardzo cieszę się że to powiedziałeś, bo to jest super pragmatyczna rzecz. Najpierw trzeba sprawdzić najprostszą metodę, którą posiadamy, jak powiedziałeś, na przykład, regex’a czyli wyrażenia regularne, albo jakieś zestaw reguł.
Miałem rozmowę o sztucznej inteligencji w księgowości, rozmawiałem z Dimą, i on powiedział coś podobnego. Oni nie używają za bardzo deep learningu, natomiast napisali swoją własna implementacje (trochę machine learningu, trochę statystyki) i ten model jest najlepszy, który bije wszystko, co mieli dotychczas.
I to jest złota reguła, że Deep Learning, to nie jest pierwsza rzecz, którą chcesz sprawdzić, tylko coś bardziej prostszego, jeżeli to nie działo, to wtedy może używać bardziej złożone rozwiazane (takie jak deep learning).
Zresztą, podczas rozwiązywania tych problemów, często podczas dekompozycji wychodzi, że różne metody stosujemy do różnych elementów czyli coś, co się wydaje całością (czyli taki tekst mining), wygląda na jeden temat i jego zdekomponujemy na pojedyncze części, to nagle się okazuje, że tych różnych czynności tam się wykonuje kilkanaście, kilkadziesiąt i każdą można robić trochę na inny sposób. I to jest tak naprawdę cała rodzina rozwiązań.
Taką dobrą analogią jest Watson, który też nie jest jednym algorytmem czy jedną siecią neuronową, ale całą rodziną najróżniejszych rozwiązań od bardziej tradycyjnych poprzez najróżniejsze odmiany machine learningu. To wszystko zależy. Trzeba dobrać młotek do gwoździa.
Pytanie już bardziej prywatne. Czy możesz trochę zdradzić trochę swoich planów na przyszłość w szczególności zwiażanych ze stuczną inteligencja oraz RPA?
Szczerze mówiąc, to co teraz robię, pochłania mnie bardzo mocno i na pewno do dwóch lat będę chciał się skupić na tym projekcie ING, bo tam jest kilka długofalowych projektów, które trzeba dociągnąć do końca. I jednocześnie, równolegle, staram się jak najwięcej uczyć się, studiować, staram się po godzinach budować jakieś prototypy w domu, eksperymentować trochę. Jak najbardziej się rozwijać w tym kierunku. I to chyba na taką dającą się przewidzieć przyszłość, to by było to.
Wiadomo że takim długofalowym marzeniem to było by pracować dla jednego z liderów tych obszarów, takich jak Google. Dla każdej osoby, która pracuje z tego typu technologiami, chciałoby się pracować w tych wiodących zespołach, żeby mieć dostęp do najnowszych rozwiązań, ale to są na razie bardzo dalekosiężne jakieś aspiracje, nawet można powiedzieć plany.
Życzę żeby się udały tak krótkotrwałe plany jak i długotrwałe. Już ostatnie pytanie na dzisiaj, jak można Cię znaleźć w sieci?
Jestem na LinkedIn’ie, jestem na Facebooku. Można też zajrzeć, do czego zachęcam, na stronę mojej macierzystej firmy Hemnes.
Dziękuję bardzo za twój czas.
Również Ci dziękuję i mam nadzieję, do zobaczenia niedługo na jednym z meetupów startupowych.
Trochę nam rozmowa przeciągnęła się, ale myślę, że było warto :). A jaka jest Twoja opinia?
Zapraszam do pozostawienia swojego komentarza na itunes, na stronie biznesmysli.pl czy siecach społecznościowych. Dla Ciebie to dosłownie kilka minut a tym samym możesz uczynić kilka dobrych rzeczy na raz:
- Dodać mi motywacji do kontynuacji tego co robię
- Poruszyć temat czy nawet dyskusję, która może ulepszyć podcast
- Umożliwić innym znaleźć podcast (tak działa algorytm w itunes)
Również proszę o podzielenie się treścią na Facebook. W grupie Biznes Myśli, będzie link i opis tego odcinka. Jeżeli spodobał się ten podcast, podziel się z innymi. Być może ktoś poszukuję tej informacji. Z góry bardzo Ci dziękuję.
Dziękuję również osobom, które do mnie piszą, pytają o porady. Z chęcią staram się pomóc, jeżeli mogę. Zauważyłem, że czasem jest niepewność, a czy warto pisać, a czy odpiszę itd? Oczywiście różne rzeczy dzieją się w życiu, ale na dzień dzisiejszy odpowiedziałem wszystkim osobom które mnie napisały. Dlatego zapraszam. Dla mnie jest cała przyjemność pomóc komuś, jeżeli to jest w moich siłach :).
Tak jak już zapowiedziałem w poprzednim odcinku. Teraz pracuję nad warsztatem o nazwie Data Workshop.

Data Workshop | Poznaj czym jest sztuczna intelingencja ze strony praktycznejKtóry ma pomóc (już na poziomie implementacji) w nauce używania machine learning w praktyce. Osoby które są zapisane na newsletter mogą liczyć na zniżkę, ale teraz chcę powiedzieć o czymś innym… Bardzo mi zależy na tym, żeby warsztat był skupiony na rozwiązaniu praktycznych problemów. To jest bardzo pragmatyczne podejście. Już wspomniałem o możliwości bezpłatnej konsultacji ze mną na samym początku, a teraz szczegóły.
Proszę wypełnić prostą ankietę z 5-cioma pytaniami o problemach biznesowych które chcesz rozwiązać. Jeśli to zrobisz, wtedy możesz liczyć na bezpłatną godzinną konsultację ze mną na temat uczenia maszynowego. Oferta jest aktualna do końca sierpnia 2017.
W następnym odcinku będzie gość który teraz robi badania na jednej z najbardziej znanych uczelni w świecie, zwłaszcza w tematach sztucznej inteligencji. Podzieli się swoim doświadczeniem, powie co tam działa inaczej niż w Polsce i jeszcze sporo innych ciekawych tematów.
To już tyle na dzisiaj. Dziękuję Ci bardzo za poświęcony Twój czas, Twoją energię i chęć do rozwoju.
Cześć i wszystkiego dobrego!
Książki polecane przez gościa
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
