Filip Stachura, CEO Appsilon Data Science, o sztucznej inteligencji
3 lipca, 2017/
13 czerwca odbyła się konferencja Minds + Machines, tym razem Berlinie, zorganizowana przez General Electric. Jeff Immelt, który jest CEO, powiedział: “Europe can lead the digital industrial era”, czyli po polsku
“Europa może prowadzić cyfrową przemysłową erę”
Jeff Immelt | Minds and Machines
Również dodał, już od razu polsku, że „GE inwestuje w technologie, takie jak automatyzacja, zaawansowana produkcja i sztuczna inteligencja czy data science – wraz z nowymi umiejętnościami – które mogą przekształcić przemysł i zwiększyć wydajność. GE od dawna angażuje się w Europę i inwestuje w jej przyszłość”.
W skrócie można powiedzieć, że GE skupia się teraz na trzech kierunkach:
Sztuczna inteligencja i tematy powiązane
3D printing
VR/AR – wirtualna lub rozszerzona rzeczywistość
Warto powiedzieć, General Electric to ogromna firma, w której pracuje ok. 300 tys. ludzi. Również to co jest tworzone, czyli tematy przede wszystkim przemysłowe (takie jak turbiny, silniki i inne), nie są wprost powiązane z IT. Ale jak widać zmiany zwiąny ze sztuczna inteligencją docierają wszędzie. Jako osoba, która pracuje w GE, mogę potwierdzić, że temat zwiazany ze sztuczną inteligencja staje się coraz bardziej aktualny i wiele rzeczy się zmienia. Przede wszystkim w podejściu do myślenia i rozwiązywaniu problemów.
Ciekawy jestem Twojej opinii na ten temat.
W tym czasie przechodzę do dzisiejszego gościa którym jest Filip Stachura. Młody, utalentowany i otwarty na wyzwania człowiek. Niestety (albo stety) zwykle tacy ludzie wyjeżdżają z kraju, Filip też przez jakiś czas pracował w Kalifornii. Ale jednak wrócił do Polski i postanowił tu w Polsce zająć się tematami związanymi z analizą danych.
Filip Stachura | CEO Appsilon Data Science
Jak sam twierdzi:
„Chciałbym doprowadzić do rozkwitu, abyśmy mogli sprawiać, że najlepsi ludzie będą mieli wybór, czy chcą wyjechać zagranicę czy chcą zostać tutaj i pracować nad projektami z Polski.”
O tym i o wielu innych ciekawych rzeczach dowiesz się z dzisiejszej rozmowy.
Również na końcu będzie ogłoszenie, które po raz pierwszy pojawi się w Biznes Myśli (później będzie w innych źródłach). Zapraszam.
Vladimir: Cześć Filip. Twoja misja, cytując Ciebie, brzmi “Live the life to the fullest!”, pewnie po polsku to brzmi jako “Żyj pełnym życiem”. Lubisz się uczyć, podróżować… i komputery. Te wszystkie tematy są bardzo bliskie również dla mnie. Cieszę się, że miałem okazję Cię poznać. A teraz również słuchacze mogą poznać Ciebie… proszę powiedz, więcej o tym kim jesteś, co robisz, co lubisz, gdzie mieszkasz :).
Filip: Cześć. Po pierwsze, bardzo Ci dziękuję że zaprosiłeś mnie do swojego podcastu. Witam wszystkich słuchaczy. Nazywam się Filip Stachura, jestem prezesem firmy Appsilon Data Science. Myślę o sobie, że jestem człowiekiem o otwartej głowie, który lubi świat. Jeżeli chodzi o to kim jestem, to z wykształcenia jestem matematykiem i programistą, studiowałem na Uniwersytecie Warszawskim, to są jednoczesne studia matematyczne i informatyczne.
Jeśli chodzi o to co lubię, to już wymieniłeś kilka rzeczy, które mnie bardzo interesują. Lubię podróżować, poznawać innych ludzi, inne kultury, obyczaje. Lubię też się uczyć, dużo czytam, a moją pasją jest matematyka, programowanie i analiza danych. Stąd kilka lat temu zdecydowałem się z przyjaciółmi założyć firmę w Polsce, skupiającą się na analizie danych, o tym pewnie będę mówił przez cały podcast. Mieszkam w Warszawie, niedaleko stacji metro Służew nad Dolinką, całkiem uroczej okolicy, a gdzieś długofalowo myślę o powrocie do Trójmiasta.
Vladimir: Powiedziałeś że lubisz czytać. Co ostatnio czytałeś i jakie wnioski wyciągnąłeś z tej lektury?
Filip: Kiedy pada to pytanie, to zawsze rozbijam to na dwie osobne sfery. Po pierwsze, prywatnie dużo czytam science fiction, fantastyki, teraz czytam Dzieci Diuny Herberta. Jestem fanem Herberta, bardzo mi się podobały dwa pierwsze tomy, więc trzeci też czytam z zainteresowaniem. A z kolei, jeżeli chodzi o książki samorozwojowe, to czytałem niedawno tę samą książkę, którą czytał Piotr i polecał w ostatnim odcinku – Thinking fast and slow (Pułapki myślenia). Ale książkę wcześniej, która na pewno jest warta polecenia, Bena Horowitza The Hard Thing About Hard Things, z pewnością mogę polecić. Jest to trudna lektura, wniosków z niej mam kilka kartek A4, a książka mówi o różnych trudnościach związanych z prowadzeniem biznesu, biznesu który też szybko rośnie, więc myślę że może być bardzo ciekawa dla odbiorców podcastu.
Vladimir: Basia Fusińska, która była właśnie przed Piotrem, też polecała tą książkę.
Filip: No nie… 🙂 To teraz muszę polecić jeszcze coś innego. W takim razie na pewno mogę polecić, z takich książek, które wywarły duży wpływ na mój rozwój, The power of habit (Siła nawyku), to jest klasyka, ale jeżeli ktoś nie czytał, to na pewno…
Vladimir: Dobrze, myślę że możemy zaliczyć tę trzecią książkę The power of habit. Naprawde jest mocna, też ją polecam. Jeżeli ktoś nie miał okazji jej przeczytać, to bardzo gorąco zachęcamy.
Wiem, że uczestniczyłeś w międzynarodowym konkursie Global Management Challenge. Powiedz słuchaczom więcej, co to jest za konkurs. Kto i w jakiej ilości bierze tam udział. Które miejsce tam zajęliście i jak ten konkurs wpłynął na Twoje życie?
Filip: W tym konkursie braliśmy udział jako zespół, którego kapitanem byłem kilka lat temu. Jest to symulacja biznesowa w której zarządza się spółką na wirtualnym rynku i konkuruje się z innymi firmami, które zaczynają grę w dokładnie takiej samej sytuacji, produkują takie same produkty.
Generalnie co kwartał, podejmuję się bardzo dużo decyzji biznesowych od marketingu, ceny aż po konserwację maszyn czy pensje pracowników. Wszystko to następnie jest przetwarzane i dostaje się raport za kwartał oraz wyniki swojej firmy. Celem gry jest osiągniecie jak największego wyniku giełdowego i pokonanie konkurencji. W konkursie startują pool’y menedżerskie z całego świata, konkurs jest międzynarodowy. W Polsce są to różne firmy od Orange, KGHM, KPMG, lista dokładna jest na stronie konkursu, ale są to duże firmy.
Jeśli chodzi o ekipy studenckie, to one też mogą startować, warunkiem jest to aby znalazły firmę, która wybierze ich zespół i będzie ich sponsorowała. Podeszliśmy do zagadnienia bardziej analitycznie niż biznesowo i skupiliśmy się na modelowaniu rynku, modelowaniu działania naszej firmy na podstawie raportów kwartalnych. W ten sposób budowaliśmy różne modele, od mniejszych modeli dotyczących, na przykład, zapotrzebowania na serwery w internecie czy potrzebnej konserwacji dla maszyn, po bardziej skomplikowane modele popytu i tego jak marketing i nasze ceny będą wpływały na popyt.
Udało nam się na giełdzie papierów wartościowych wygrać polskie finały, a później zdobyć wicemistrzostwo Świata ustępując drużynie Ukrainy, ale pokonując takie zespoły jak Stany Zjednoczone, Rosja, Brazylia, Chiny. Było to bardzo ciekawe doświadczenie. Później odezwały się do nas firmy zarówno z Polski jak i z zagranicy, chcące zoptymalizować swoje procesy biznesowe.
Zespół studencki Piratas del Norte sponsorowany przez Orange Polska – wywalczyła w finale światowym GMC 2012 srebrny medal
Faktycznie, ten konkurs i doświadczenie które tam zbudowaliśmy procentuje do dziś, ponieważ kiedy modelujemy, budujemy modele czy predykcyjne czy nawet jakieś systemy optymalizacyjne, to pozwala nam efektywnie je łączyć w całość i bardziej myśleć o całej firmie jako jednym mechanizmie, którego wynik chcemy poprawić.
Vladimir: Super wynik, nie wiem jak dawno to było, ale teraz już jesteś CEO Appsilon Data Science… mimo tego, że pracujecie z Polski, to nadal jesteście bardziej znane za granicą. Powiedź więcej o firmie, czym się zajmujecie, jak problemy rozwiązujecie i w jaki sposób?
Filip: Jako firma zajmujemy się data science czyli analizą danych, co oczywiście jest bardzo szerokim hasłem. Pomagamy naszym klientom, którzy pochodzą z bardzo wielu branż. Współpracujemy z klientami z branży finansowej, energetycznej, z branży transportowej, liniami lotniczymi, z branżą morską, robiliśmy projekt dla portów, aż po tradycyjne projekty retail czy projekty e-commerce’owe. Jest to bardzo duży przekrój i te zagadnienia też są duże, ale wszystkie orbitują wokół danych. Lubię myśleć o projektach w czterech obszarach, które układają się w chronologicznym porządku.
Pierwszy rodzaj projektów jest związany z tak zwanym data acquisition czyli pozyskaniem danych. Te dane mogą być zarówno u klienta jak i w zewnętrznych systemach. Pomagamy klientom pobrać je i wyczyścić dane z tak zwanego open data, czyli jakichś danych publicznie dostępnych, danych rządowych, używaniu ich później w jakichś ich analizach. Tutaj na pewno jest bardzo ważne zadbanie o wysoką jakość tych danych. Często, niestety, nawet u dużych firm okazuje się że jest potrzebna praca aby jeszcze coś poprawić i aby te dane były takiej jakości jak jest to niezbędne aby budować skuteczne modele.
I tak naturalnym tokiem przechodzimy do drugiej działki czyli budowania modeli. Tutaj stosujemy w pracy bardzo różne modele w zależności od potrzeb klienta, ponieważ czasami nawet model liniowy może przynieść rezultaty. Czasami są to modele bardziej skomplikowane, to mogą być metody uczenia maszynowego aż po uczenie głębokie, które w praktyce jest potrzebne jednak dosyć rzadko, z naszego doświadczenia, ponieważ jest najdroższym sposobem, który faktycznie przynosi bardzo dobre rezultaty, często najlepsze, ale ta różnica i ten tradeoff nie jest aż tak duży aby opłacało się inwestować w takie rozwiązania.
Trzeci rodzaj projektów to jest warstwa platformy i sprawiania aby te projekty były realizowane solidnie, w szególności to znaczy, aby wyniki, które są uzyskiwane były powtarzalne i aby poprawy skuteczności można było obserwować w czasie. Abyśmy mogli łatwo stwierdzić że jakiś model trzy lata temu albo trzy miesiące temu działał o tyle i tyle gorzej niż model który mamy obecnie. Jest to bardzo ważne ponieważ w takich pracach analitycznych często osoby które są w takich zespołach nie mają aż tak solidnego wykształcenia programistycznego i nie przykładają aż tak dużej wagi do powtarzalności przez co do takich projektów może wkradać się chaos. Czasami nie do końca wiadomo na jakich danych model powstał albo dane się zmieniły od tego czasu, a nie wiemy które dane doszły a które zostały usunięte lub nawet z jakimi parametrami model został zbudowany.
Czwarta i ostatnia część to jest warstwa tak zwanego interfejsu, czyli komunikacji pomiędzy tymi elementami analitycznymi a jakimiś innymi systemami. To mogą być systemy komputerowe ale często to też są ludzie. W zależności od tego, to może być API, które jest używane przez aplikację webową czy aplikację mobilną i odpytuje nasz system o jakieś wartości.
Przykładowo, jeżeli to będzie system antyfraudowy, to takie API może spytać – jakie jest prawdopodobieństwo że ta transakcja to fraud. I takie API odpowie – prawdopodobieństwo że jest to fraud wynosi 87%, i ten zewnętrzny system już sobie jakoś tą informacje przetworzy.
Druga rzecz, czyli dashboard’y, a dokładniej – systemy wspierania decyzji, jest czymś w co my w Appsilonie głęboko wierzymy. Jest to bardzo skuteczna metoda wsparcia biznesu, ponieważ jest to krok pośredni pomiędzy manualnym podejmowanie decyzji a pełną automatyzacją. I taki krok jest potrzebny ze względu na to że do decyzji, podejmowanych przez modele czy sugerowanych przez modele, również biznes musi nabrać zaufania, musi zobaczyć że one są skuteczne zanim dojdzie do pełnej automatyzacji. Po za tym, również modele, które są uczone, czasami się mylą i wtedy taki ludzki pierwiastek, który przeanalizuje te informacje z systemu i być może je poprawi, może być bardzo cenny.
Vladimir: Bardzo fajnie że podzieliłeś to na takie cztery kroki i powiedziałeś co robicie w każdym z nich. Będę dopytywać, bo jest wiele ciekawych rzeczy, których pewnie słuchacze chcą się dowiedzieć. Ale najpierw zapytam o takie dość fundamentalne pytanie.
Mimo tego że jesteście w Polsce, jak to doskonale wiesz, jak na razie jeszcze mało firm z Polski dostrzega potencjał w uczeniu maszynowym i tematach powiązanych. Nas słuchają przedsiębiorcy i pewnie większość z Polski. Co możesz powiedzieć przekonującego w kontekście “dlaczego warto”. Ewentualnie co się stanie z firmami za 10 czy nawet za 5 lat jeżeli temat uczenia maszynowego, analizy danych nadal będzie ignorowany?
Filip: Po pierwsze, mam wrażenie że jednak ta świadomość rośnie. Nawet do nas, gdzie aktywnie nie poszukujemy klientów na polskim rynku, zgłasza się coraz więcej polskich firm z zapytaniami o projekt, więc jest to dosyć optymistyczny sygnał. Ale najlepiej zobrazuje nam spojrzenie na to, co się dzieje na zachodzie. W zeszłym tygodniu wróciłem z San Francisco z konferencji EARL, gdzie miałem okazję być prelegentem i rozmawiałem z różnymi osobami z bardzo wielu firm.
EARL – Enterprise Applications of the R Language
Działy data science, które te firmy posiadają, liczą już po 100-150-200 osób. Są to gigantyczne zespoły czy nawet grupy zespołów, działy w firmie, które analizują dane w celu poprawienia i zoptymalizowania działania tej firmy. Oczywiście, taki dział na ten moment dla firmy musi być bardzo kosztowny, ale to znaczy że optymalizacje, które zespół robi cały czas, i tak dają bardzo pozytywne rezultaty.
Jeśli taka firma na zachodzie optymalizuje swoje działanie w tak szybkim tempie, to z roku na rok będzie zyskiwała przewagę. Gdyby faktycznie na rynku istniały firmy, które nie będą tego robiły wcale albo będą robiły to dużo wolniej, to prawdopodobnie mocno ryzykują tym że ich konkurencja zyska dużą przewagę konkurencyjną. Z każdym rokiem coraz większą.
Vladimir: Zgadzam sie z tym, że w chwili obecnej to nie jest nawet wybór, to nie jest opcjonalne czy firma może się zainteresować tematem data science czy nie, to raczej jest naturalnym krokiem postępu. Jeżeli firma się tym nie zainteresuje – to przegra. To jest coś podobnego jak z komputerami. Teraz nikogo nie dziwi, że raczej każda firma albo większość firm jednak ma komputery, posługuje się bazą danych i podobnymi rzeczami.
Przechodzimy teraz do tych czterech punktów, o których mówiłeś wcześniej, bo są bardzo ciekawe. Pierwszy punkt dotyczył danych, więc porozmawiajmy trochę o tym.
Dane – to surowiec naszego stulecia.
Myślę, że warto podkreślić, że jednak to wymaga dużego wysiłku, żeby faktycznie dane stały się skarbem.
Po pierwsze to dane same w sobie powinny być wartościowe (trzeba przemyśleć jakie dane są potrzebne). Po drugie, załóżmy że mamy przemyślany proces i zbieramy wartościowe dane, to jednak jeszcze trzeba zadbać o ciągłą weryfikację danych. Czym większe człowiek ma doświadczenie praktyczne, tym mniej go dziwią rzeczy które czasem się dzieją dookoła.
Zaczynając od słynnego żartu z panią sprzątaczką… która miała wyłączyć na chwilę maszynę, żeby wytrzeć kurz :). Ciągła weryfikacja prawidłowości danych często nazywają “data healthcheck”. Jesteś praktykiem i miałeś okazję współpracować z różnymi firmami i projektami. Proszę podaj przykład z życia, który jest w stanie pokazać dlaczego weryfikacja danych jest ważnym elementem całego procesu. I co się dzieje, jeżeli to pominąć.
Filip: W najlepszym przypadku projekt znacznie się opóźni, to jest najlepsze co może się wydarzyć. W najgorszym wypadku będą podejmowane złe decyzje, albo co gorsza, stwierdzimy że jakiś model nie działa mimo że tak naprawdę mógł działać. I firma nie wykorzysta przewagi, którą mogła zyskać, gdyby dane które byłyby wprowadzone do modelu były poprawne.
Popełnimy podwójną pomyłkę. Kierunek w którym chcieliśmy pójść był dobry, ale przez to że spojrzeliśmy na zły drogowskaz, stwierdziliśmy że tam nie idziemy. To jest chyba najgorsze co mogę sobie wyobrazić. Oczywiście, mogą się zdarzyć sytuacje przepuszczalne, w których system zostanie przez to źle zaprojektowany i wdrożony na produkcję i firma poniesie przez to jakieś straty, również finansowe. Ale to raczej świadczyłoby o większej ilości problemów, o źle przeprowadzonych testach, o problemach związanych z procesem walidacji danych na różnych krokach, i w praktyce, ciężko mi wyobrazić żeby doszło do takich sytuacji w jakimś projekcie komercyjnym.
Vladimir: Reasumując, dane są bardzo ważnym elementem. Zbieranie danych, przechowanie danych, robienie backupów (kopii zapasowych) i podobnych rzeczy – to jest ważne, ale nie jest wystarczające żeby faktycznie ten projekt zaczął przynosić korzyści, bo jednak po drodze może się coś popsuć, jakieś pole będzie puste, ktoś zapomniał wklepać jakąś wartość. Jak nie ma którejś wartości, to nie wiadomo jak nasz model będzie się zachowywał. Albo jeszcze co gorzej, jak będzie wadliwa wartość, to wtedy samy oszukujemy nasz model, dostajemy zły wynik.
Filip: Dokładnie. Tutaj dodam tylko to, że jeśli faktycznie chcemy do tego doprowadzić to walidacja danych w praktyce (jeśli nie robimy czegoś jednorazowo), powinna dziać się automatycznie. Inaczej, jeżeli będziemy próbować walidować dane manualnie, co z resztą i tak jest możliwe w przypadku jeśli danych jest niewiele, to za każdym razem to będzie zajmować nam czas i w konsekwencji doprowadzi do tego, że przestaniemy to robić.
Dlatego tak ważna jest automatyzacja i robienie healthcheck’ów, po to, abyśmy w sposób automatyczny wiedzieli że wszystko jest OK, albo bardzo szybko dowiadywali się że coś jest nie tak i co dokładnie jest nie tak.
Vladimir: Na jednej ze swoich prezentacji zwróciłeś szczególną uwagę na powtarzalność wyników. Są różne definicję które próbują wyjaśnić co kryje się pod tą frazą. Podziel się swoim doświadczeniem, co to dla Ciebie oznacza i dlaczego to jest tak ważne? Jakie problemy będą, jeżeli pominąć ten ważny aspekt?
Filip: Może zacznę od problemów. Jeżeli nie będziemy w stanie powtarzać wyników, to nie będziemy mieli do nich zaufania. Przykładowo, będziemy na spotkaniu, w firmie lub w jakiejś innej organizacji, zastanawiać się nad wynikami które uzyskiwaliśmy w zeszłych miesiącach.
Ważne jest abyśmy w ogóle wiedzieli jakie to wyniki były miesiąc temu, trzy miesiące temu czy sześć miesięcy temu. Dzięki temu będziemy widzieć czy idziemy do przodu czy nie. Równie ważne jest to abyśmy im ufali, a to oznacza że byśmy mogli je powtórzyć. Jeżeli mamy jakąś metrykę i ktoś nam mówi że ta skuteczność sześć miesięcy temu wynosiła 82%, ale nie jesteśmy w stanie dzisiaj tego powtórzyć, to nie ma to dla nas najmniejszego znaczenia, bo dzisiaj ten model na tych danych i z tymi parametrami osiąga tylko 75%. I to jest problem. Jak osiągnąć taką powtarzalność?! Może jeszcze uzasadnię co dokładnie pod tym rozumiem, tak jak pytałeś.
Dla mnie powtarzalność oznacza, że dla każdego modelu, który trenujemy, wiemy na jakim zbiorze danych został wytrenowany, jakie parametry zostały użyte, jaki kod źródłowy jaki system operacyjny został użyty czyli jaka infrastruktura została użyta. Te wszystkie rzeczy mogą mieć wpływ na finalny wynik tego modelu. Jeżeli dane się zmienią, to oczywiście wynik może się zmienić, jeżeli kod źródłowy się zmienił, jeżeli parametry się zmienią, to oczywiście wynik może się zmienić.
Co więcej, jeżeli wersje bibliotek, pakietów czy nawet jakichś zależności systemowych się zmienią, to również wynik może się zmienić. Zarówno we wszystkich językach programowania, służących do analizy danych, zdarzają się przypadki, że API jakiejś biblioteki czy pakietu zostaje zmienione i logika pod spodem jest inna. Dlatego tak ważne jest, abyśmy mogli dokładnie odtworzyć identyczny stan wszystkich parametrów, które mają znaczenie, jeśli chodzi o to, jak ten model później działa.
Jak to uzyskać? Na pewno jest kilka sposobów. Używamy w Appsilonie tak zwane kontenery, to jest bardzo ważny składnik. W takim kontenerze mamy zapisaną informację o tym pełnym systemie, o wszystkich pakietach, które zostały użyte. Wiemy dokładnie na jakiej rewizji kodu taki model zostaje wytrenowany. Dużo większym problemem czasami bywają dane. Tutaj z pomocą przychodzi, w szczególności w przypadku dużych zbiorów danych, hash’owanie. Wtedy, w szczególności czasami, możemy nie wiedzieć co dokładnie się zmieniło, ale przynajmniej możemy wiedzieć że coś się zmieniło, jeżeli chodzi o zbiór danych wejściowych.
Druga rzecz, która jest bardzo ważna, to tak zwane immutable data sets czyli niezmienne zbiory danych. To oznacza, że jeżeli coś trafia do naszej bazy danych czy HDFSa big data, jakkolwiek dane przechowujemy, do naszego zbioru, to już stamtąd nigdy nie wylatuje. To jest innowacja wdrożona między innymi przez Airbnb, ale również przez wiele innych firm, i jest skuteczną metodą na zachowanie powtarzalności eksperymentów analitycznych.
Vladimir: Bardzo fajnie to ująłeś. Cieszę że o tym mówisz, ponieważ to bardzo praktyczna i pragmatyczna wiedza. Z mojego doświadczenia, z tego co obserwuje co się dzieje na rynku, fajnie że ludzie już wiedzą, że powtarzalność to jest coś, co powinno być. Natomiast często są w błędzie, czym jest ta powtarzalność.
Z tego co obserwuję – widzę, że powtarzalność, to jest zbiór bibliotek, a nawet nie bibliotek, tylko kod źródłowy, który buduje ten model. I to jest pierwszy poziom powtarzalności. Ewentualnie ktoś pamięta wersje bibliotek na których to było uruchamiane. Ale bardzo rzadko widziałem, żeby ktoś się martwił o wersjonowanie danych, żeby faktycznie mógł powtórzyć ten sam eksperyment na tych samych danych, a to jest bardzo ważne.
Tak jak powiedziałeś, jeżeli nie mamy tej powtarzalności, to mamy takiego “kota w worku”, odpalamy model i mamy zupełnie inny wyniki. Czy to jest dobrze czy źle? Nie wiadomo jak to traktować :).
Filip: Oczywiście, to co wytłumaczyłem, jest podejściem bardzo skomplikowanym, też wierzę że najbardziej profesjonalnym. Nie zawsze aż taką maszynerię trzeba wyciągać do prostego projektu. Mogą się zdarzyć projekty, gdzie wersjonowanie kodu, parametrów, wersji bibliotek będzie w zupełności wystarczające. Chcemy zapewniać najwyższy poziom dokładności i pełna wiedze o tym, co się wydarzyło w takim eksperymencie.
Vladimir: Przechodzimy teraz do kolejnego tematu, właściwie o czwartym obszarze, o którym wspomniałeś. Jednym z podpunktów tego obszaru były dashboardy. Nie wiem, czy wszyscy wiedzą czym jest dashboard. Bardzo proszę, na początek, wyjaśnij co to jest i jakie są korzyści dla biznesu? Jakiego rodzaju problemy może rozwiązywać?
Filip: Tak, niestety to jest też słowo, które ulega pewnym hype’om, jest wykorzystywane przez bardzo różne osoby, podmioty i tak dalej, więc nie jest to jasne. Istnieje bardzo wiele dashboardów analitycznych i pierwszy, który przychodzi mi do głowy, to pewnie Google Analytics, który pokazuje nam jakieś informacje, w miare przystępnej formie i pozwala nam coś przeanalizować.
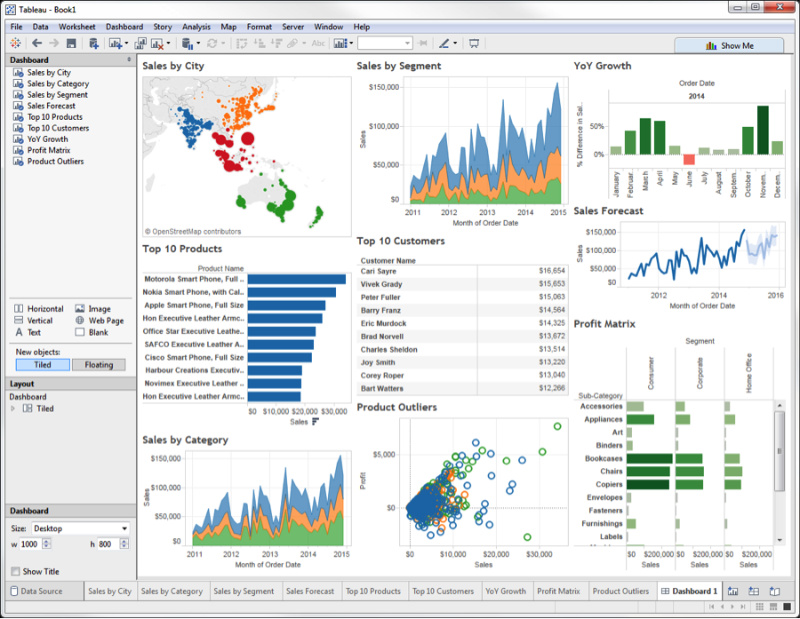
Tableau
Istnieją narzędzia klasy business intelligence, które pozwalają nam takie dashboardy tworzyć i tutaj oczywiście jest Tableau, QlikView, Power BI i szereg innych narzędzi. One są świetnymi narzędziami analitycznymi dla niektórych rodzajów problemów, ale nie są to dashboardy o których mówię. Ponieważ te, o których mówię ja, bardziej przypominają pełne aplikacje webowe, które mają zasady nie tylko prezentować dane, tak jak w przypadku wcześniejszych, ale również, na przykład, je pobierać.
W niektórych systemach wspierania decyzji, które budujemy, osoba, która współpracuje z dashboardem, podejmuje finalną decyzje i ta decyzja gdzieś jest zapisywana. Co więcej, później ona może zostać użyta do przeuczenia modelu i poprawienia skuteczności tego modelu. W takich dashboardach analitycznych też możemy pozwolić na, na przykład, kolaboracje i tego, aby kilka osób analizowało jakieś zjawisko jednocześnie lub widziało, że ktoś inny otagował już jakieś transakcje lub inne elementy.
To jest podstawowa różnica pomiędzy dashboardem a systemem wspierania decyzji, który jest bardziej skomplikowany, czyli ten odczyt, zapis i większa siła wyrazu. To znaczy że, taki dashboard, stworzony, na przykład, w Shiny w R, pozwala używać wszystkich rzeczy, które są dostępne w językach programowania. Czyli w szczególności bardzo łatwo możemy dodać jakiś całkowicie wyjątkowy wykres, który nie pojawiał się nigdzie indziej czy zbudować workflow (tł. przepływ danych), w którym przechodzi się przez pewien proces w wielu krokach i podejmuje jakieś decyzje.
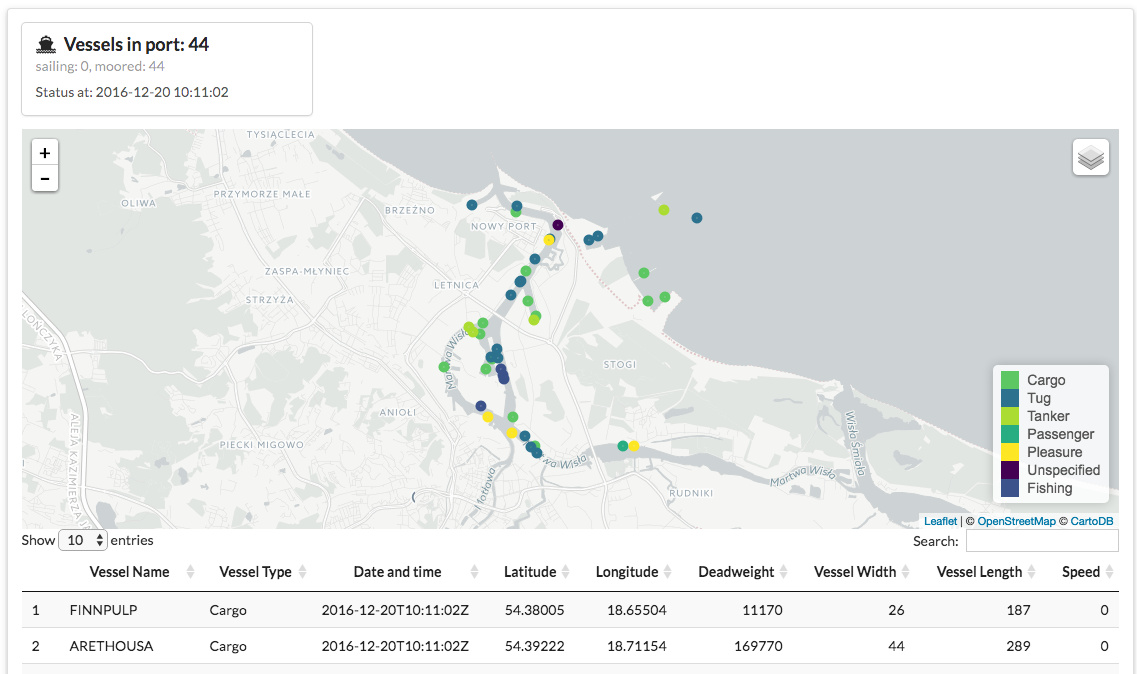
Ports Analytics | Dashboard | Shiny
W takich narzędziach BI’owych będzie to trudne albo wręcz niemożliwe. Oni też nie mają kodu źródłowego i to jest chyba najważniejsza różnica. Można w nich osadzać kawałki kodu, ale ten kod, który tam osadzamy, nie może być w repozytorium, nie może podlegać kontroli wersji, nie będzie przechodził procesu code review (tł. przegląd kodu), nie będzie testowany automatycznie, więc istnieją liczne problemy, które z takim kodem źródłowym osadzonym w takiej aplikacji te problemy będą nam doskwierać.
Vladimir: Myślę że teraz już wchodzisz trochę w szczegóły techniczne i nie wiem czy wszyscy to zrozumieją. Natomiast, wydaje mi się że bardzo istotnym i ważnym będzie powiedzieć jak wygląda proces przygotowania tego dashboardu. Załóżmy że jest firma, która chce zamówić taki dashboard, co ona powinna mieć, jakie są wymogi.
Filip: Jeżeli firma chce stworzyć taki dashboard, to bardzo często istnieją jakieś narzędzia, które były używane do zaspokojenia tej potrzeby biznesowej wcześniej. Nierzadko są to, stety niestety, arkusze excelowe. Takie arkusze oczywiście mają liczne problemy, są wysyłane mailami, w dziesiątkach wersji, które zaczynają wyglądać kompletnie inaczej, mają inne dane w środku i nie wiadomo który został ostatecznie użyty do podjęcia decyzji. W praktyce bardzo często spotykamy się z tym, że firmy toną w arkuszach.
Pierwszym krokiem jest zrozumienie tego, jak ten arkusz jest używany, kto finalnie podejmuje jakieś decyzje, jakie dane powinien on widzieć, aby jak najszybciej podejmować decyzje, które ma podjąć. I kiedy zostanie stworzony taki zbiór wymagań można pomyśleć nad tym, jak zbudować interface. On może być przeniesiony w miarę podobnie do tego, co istniało w arkuszu albo może być kompletnie inny.
Z naszego doświadczenia, spotykaliśmy oba przypadki, też z tego powodu, że w arkuszu niektóre komponenty jest trudno osadzać, a niektóre rzeczy można mocno uprościć w aplikacji, ponieważ nie wszyscy w firmach są świetnymi programistami VBA, czasami te arkusze muszą korzystać z pewnych uproszczeń. Więc wtedy w takich dashboardach można to faktycznie fajnie rozwinąć i pokazać, na przykład, informacje na mapie, pozwolić wybrać coś na mapie i dla tego obszaru wyświetlić wykres. Następnie wprowadzić jakieś dane, na przykład, o proponowanych cenach lub o proponowanych nakładach na marketing, co więcej, te dane mogą zostać zapisane w bazie danych pod spodem i wyświetlone w zupełnie innym miejscu, nawet, być może, w zupełnie innym dashboardzie dla osoby z działu produkcji, która dzięki temu będzie wiedziała ile jakiegoś produktu należy stworzyć.
Vladimir: Jak zacząłeś mówić o arkuszach, od razu mi się przypomina nazwa pliku “final final FINAL wersja 10” i myślę, że każda osoba, która pracowała w nieco większej firmie i używała takiego procesu, widziała to na własne oczy, a to jest bardzo męczące.
Zapytam Cię jeszcze o taką dość ciekawą i ważną rzecz, na jak dużych zasobach danych takie dashboardy potrafią pracować? Również wspomniałeś, że kilka osób może mieć dostęp do takich dashboardów, stąd pytanie czy to jest kilka osób, kilkaset, kilka tysięcy, jak to się skaluje?
Filip: Dla naszych klientów komercyjnych tworzymy dashboardy do których mają dostęp setki, a nawet potencjalnie tysiące ludzi. Nie zawsze to jest potrzebne, bo nie są to aplikacje, które są dawane, na przykład, konsumentom końcowych, w tym nie tworzy się Facebooka. Ale, na przykład, działy sprzedaży w filiach na całym świecie korzystają z takiego dashboardu i on działa bez zarzutu. Więc jest możliwość skalowania i one skalują się dobrze.
Oczywiście, istnieje też możliwość przepisania je na jeszcze inne technologie, które skalowały by się jeszcze lepiej, tak jak Facebook. I to też jest możliwe, tylko wymagałoby istotnie więcej pracy. Ponieważ to, co jest ważne – te dashboardy, które tworzymy, powstają bardzo, bardzo szybko. W niektórych przypadkach dostarczamy coś w miesiąc, bardziej skomplikowany dashboard w dwa miesiące, może trzy, ale to i tak jest dużo szybciej, niż tradycyjne aplikacje webowe. Biorąc pod uwagę to, jak bardzo skomplikowany jest taki dashboard i jak wiele rzeczy w trakcie jeszcze jest dostosowywanych.
Jeśli chodzi o ilość danych, to tutaj największa zagwozdka jest po stronie serwera, który przetwarza te dane. Na pewno możemy w dashboardzie zlecić wykonanie jakichś obliczeń przez jakieś zaprzyjaźnione API, które świetnie nam przeskaluje obliczenia na jakiejś architekturze i dostarczy te wyniki albo zapisze je w bazie danych. Wtedy, tak naprawdę, dane nie stanowią większego problemu. Jeżeli skupimy się na takim przykładzie jak Shiny, to tutaj w praktyce, aby taki dashboard powstał tak szybko jak mówię, to te dane będą musiały się zmieścić w pamięci RAM, co na pierwszy rzut oka może się wydawać problemem, ale obecnie bez problemu możemy uruchomić na chmurze Amazona maszynę, która ma 2 terabajty (TB).
W mojej karierze zawodowej, ilość projektów, które przekraczały rozmiar 2 TB, stanowiły bardzo niewielki procent wszystkich projektów. Więc dla drastycznej ilości firm, taka maszyna z 2 TB RAMu w zupełności wystarczy aby coś w pamięci działało. Oczywiście, to może być i tak za drogie i tak może opłacać się przeliczenie tego równolegle i zapisanie do bazy danych, co w większości przypadków jest najlepszym rozwiązaniem.
Vladimir: Bardzo fajnie, że wspomniałeś o tej maszynę z 2 TB. Wydaje mi się, że jeszcze często ludzie mylą, że jeśli danych jest więcej niż, załóżmy, 50 GB, to już jest „big data”. Ale teraz już w pamięci potrafimy trzymać 2 TB danych, przy czym każdy może taką maszynę sobie wykupić. Może nie jest to do końca różowe, bo dostępnych takich maszyn raczej jest niedużo i może też być za drogo, ale ciekawostką jest to, że technicznie to jest już możliwe.
Przejdziemy teraz trochę do innego tematu… Jakie są największe wyzwania lub trudności które spotkałeś na swojej drodze w tematach związanych z uczeniem maszynowym, data science, analizą danych?
Filip: Obawiam się, że o tych najciekawszych wyzwaniach nie mogę za dużo mówić obecnie. Na pewno bardzo dużym wyzwaniem jest zarządzanie zespołem w takich projektach, zarządzanie również oczekiwaniami klienta, ponieważ te projekty często mają charakter researchowy.
My w przeciwieństwie do firm, które tworzą, na przykład, bardziej tradycyjne oprogramowanie, jak strony internetowe czy aplikacje mobilne, czasami nie możemy zagwarantować efektu końcowego. Możemy powiedzieć, że spróbujemy metod, które stanowią state of the art, czyli są najlepszymi metodami, które ogólnie wiadomo, że możemy zastosować do tej klasy problemów. Ale to może być na tyle innowacyjne, że nie możemy zagwarantować, że projekt się powiedzie. I to na pewno jest wyzwanie.
Jeśli chodzi o wyzwania intelektualne, to wydaje mi się, że w branży uczenia maszynowego, obecnie, najciekawszą działką są zagadnienia związane z Reinforcement Learning.
To są wszelkie zagadnienia, obecnie popychane do przodu przez zespół Open AI Elona Muska. Miałem okazje, podczas mojego wizytu w San Francisco, odwiedzić ich siedzibę, zobaczyć prototypy nad którymi pracują. Jest to na pewno niezwykle interesujący element, związany ze sztuczną inteligencją.
Vladimir: Elon Musk stworzył wiele ciekawych firm, o których mówi się bardzo dużo, między innymi Neuralink, ale Open AI, o której wspomniałeś, faktycznie, prawie co tydzień coś publikują na swoim blogu, jakieś kolejne rozwiązania, których każdy może użyć. Niesamowite jest to, że ta wiedza nie jest zamykana w pudełku, tylko każdy może przeczytać blog, znaleźć kod i odpalić to samodzielnie.
Oczywiście, to wymaga pewnego rozumienia co robisz, natomiast nie jest ta wiedza chowana. Dla mnie to jest bardzo fajne podejście.
Filip: Tak, aczkolwiek to jest taki czysty research. Wydaje się, że jeżeli chodzi o biznes, to te rzeczy, którymi, między innymi, my się zajmujemy, ale też w wielu firmach są używane, to są bardziej tradycyjne metody uczenia maszynowego, które po prostu szybko przenoszą bardzo dobre rezultaty.
Vladimir: Teraz zmienię temat w trochę innym kierunku. Jak myślisz dokąd dąży rozwój technologiczny i czego, my jako ludzkość możemy się spodziewać za jakieś 10-20 lat?
Filip: To jest bardzo ciekawe pytanie. Wydaje mi się, że przyszłość będzie dosyć niespodziewana. Kiedy myślę o tym, co się wydarzyło przez ostatnie 15 lat, to w niektórych obszarach wydarzyły się rzeczy całkowicie niespodziewane, a w innych ta innowacja idzie stosunkowo powoli do przodu. To znaczy, ciągle nie mieszkamy w szklanych domach, ale chodzimy z telefonami i mamy dostęp do dowolnej informacji, która chcemy pozyskać w dowolnym miejscu na świecie. I to jest coś niesamowitego. Na pewno nie jestem jedną z osób, która wierzy, że postęp pozyskania ogólnej sztucznej inteligencji czy AGI nastąpi niebawem.
Raczej skłaniam się ku temu, że obecnie jesteśmy, pod względem myślenia o sztucznej inteligencji, w podobnym hypie, który istniał, kiedy naukowcy pracowali nad prologiem. Ponieważ różne struktury, które powstają, są bardziej skomplikowane, mamy mocniejsze komputery, mamy trochę lepsze modele abstrakcji analizy tych danych, ale brakuje, przynajmniej moim zdaniem, jeszcze kilku ważnych elementów, być może związanych z reprezentacją wiedzy, bardziej w obszarze, być może, ontologii, to są tylko jakieś intuicje, nic sprecyzowanego.
Ale mam wrażenie, że jednak ta innowacja w zakresie AI, będzie postępować bardziej wertykalnie, niż horyzontalnie i będziemy widzieć wiele automatyzacji następujących w bardzo wyspecjalizowanych zadaniach. Być może z czasem coraz mniej, ale jednak wyspecjalizowanych, gdzie maszyny będą lepsze od ludzi.
W związku z tym, zresztą podobnie jak słyszałem w poprzednim odcinku, będzie dochodziło do mechanizmów, związanych z rewolucją przemysłową. Czyli niektóre zawody prawdopodobnie będą wypierane przez technologie. I wtedy mogą się wydarzyć różne ciekawe rzeczy. Oczywiście, mogą się wydarzyć protesty, ale prawdopodobnie będą się pojawiały nowe zawody.
Podejrzewam, że 20 lat temu nikt nie myślało tym, że powstanie taki zawód jak osoba projektująca interface’y i zajmująca się user experience na cały etat. A obecnie, dzięki temu, że tak bardzo rozwinęły się technologie związane z rozwojem internetu, te zawody powstały. Dlatego wydaje mi się, że w przyszłości powstaną jeszcze kolejne zawody o których teraz nawet nie możemy pomyśleć. I być może, nawet nie będzie potrzeby tworzenia podstawowego wynagrodzenia bazowego, o którym też chyba rozmawialiście ostatnio.
Vladimir: Próbuje zrozumieć czy jesteś bardziej optymista czy pesymistą, jeśli chodzi o te postępy rozwoju? Czy jednak widzisz w tym korzyść, że ludzkość ma takie narzędzie jak uczenie maszynowe i coraz bardziej sprawnie potrafi to używać?
Filip: Tak, absolutnie. Jeśli chodzi o ten aspekt, to jestem optymistą. Uważam że to jest wspaniałe, że są takie metody i pozwalają nam różne rzeczy robić szybciej i sprawniej, być może taniej, to stworzy też nowe możliwości, które będą musiały zostać w odpowiedni sposób wykorzystane. I być może, właśnie, powstaną nowe zawody, ludzie będą mogli się rozwijać.
To będzie też bardzo duża odpowiedzialność społeczeństwa na to, aby pomóc niektórym ludziom się przekwalifikować i zdobyć nowe umiejętności. To może też wiązać się z tym, że będą potrzebne bardziej drastyczne kroki związane z edukacją. Więc dużo rzeczy może zadziać się bardzo szybko.
A jeśli jestem pesymista, to tylko w obszarze tego, jak szybko będziemy reagować na zmiany, które mogą się pojawiać. Mam nadzieję że nie będziemy reagować za wolno. Jestem pesymistą odnośnie tego, jak szybko pojawi się AGI czyli ta ogólna sztuczna inteligencja porównywalna lub lepsza od człowieka. Wydaje mi się że to zajmie jeszcze dużo czasu.
Vladimir: Teraz pozwól zapytać o przyszłość, którą chciałbyś osiągnąć. Podziel się swoimi planami na przyszłość? Co chciałbyś osiągnąć w najbliższe kilka czy nawet 5 lat?
Filip: Oczywiście. Pierwsza rzecz, nad którą pracujemy, to to, aby stworzyć w Polsce jedną, mam nadzieje, z wielu firm, w których będziemy mogli z Polski rozwiązywać bardzo ciekawe problemy analityczne. To jest rzecz, w którą wkładam olbrzymi wysiłek i którą z roku na rok realizujemy i, mam nadzieję, że będziemy realizować je nadal. Kolejna rzecz którą realizujemy, to poznawanie świata i uczenie się o bardzo wielu firmach, ponieważ jest to niesamowicie ciekawe.
Myślę że z samego tego faktu będę to robił dalej, a jednocześnie, zachowując przy tym zdrowy balan, udowadniamy sobie, że jesteśmy w stanie pracować z Polski, zdalnie, z zagranicznymi klientami.
Chciałbym doprowadzić do rozkwitu, chciałbym abyśmy mogli sprawiać że najlepsi ludzie będą mieli wybór, czy chcą wyjechać zagranicę czy chcą zostać tutaj i pracować nad projektami z Polski.
Vladimir: Masz bardzo ambitne i wspaniałe plany, więc trzymam kciuki, żeby Ci faktycznie to się udało.
Już ostatnie pytanie na dzisiaj, jeżeli ktoś będzie chciał się z tobą skontaktować, to jak to można zrobić?
Filip: Tutaj bez problemu. Generalnie, jeżeli ktoś odezwie się do mnie na LinkedIn i napiszę miarę sensowną wiadomość, to zawsze staram się zaakceptować, porozmawiać. Też, na ile pozwala mi kalendarz, możemy umówić się na spotkanie, więc to nie powinno stanowić problemu.
Vladimir: Bardzo dziękuję Ci, Filip, za rozmowę, za twój czas.
Filip: Dzięki serdecznie i wszystkiego dobrego.
Co myślisz o tym co powiedział Filip? Proszę podziel się swoją opinią w najbardziej wygodny sposób dla Ciebie.
Podziękowania
Na itunes już pojawiło się 7 głosów i każdy ma pięć gwiazdek oraz nowa opinia. Mariusz Stachowisz napisał:
Opinie w itunes
Bardzo dziękuję Mariuszu i będę dalej starał się mówić językiem prostym o trudnych rzeczach.
Pojawiło się sporo nowych komentarzy na stronie biznesmysli.pl. Pozwolę sobie przeczytać osobę którę znalezli chwilę i podzielili się swoją opinią, to jest Patryk Wójcik, Adam, Rafał Bieleniewicz, Bogusz Pękalski. W szczególności Kamila Szafrańska, która napisała wiele komentarzy, a jeden z nich naprawdę był wielkością porównywalny do artykułu. Dziękuję Wam za wyrażanie swoich opinii, to dla mnie jest cenne i motywujące.
Również zapraszam Ciebie do podzielenia się swoją opinią. Dla Ciebie to chwila czasu. Tym samym możesz wpłynąć na to co będzie dalej się pojawiać, sprostować któryś temat lub po prostu wyrazić swoją opinię.
Ogłoszenie
Oprócz podcastu Biznes Myśli, prowadzę warsztaty dla osób technicznych pod nazwą DataWorkshop.eu.
Data Workshop
Na dzień dzisiejszy udało się już zorganizować 9 warsztatów w których uczestniczyło ponad 250 osób. Jest sporo pozytywnych informacji od uczestników – co mnie bardzo cieszy.
Paweł Lorek – jeden z komentarzy z ostatniego warsztatu
Prawdopodobnie nadal będę organizować warsztaty na żywo, ale to podejście bardzo trudno skaluje się (maksymalnie 30 osób) i raczej jest dość drogie dla uczestników. Bo są spore opłaty logistyczne.
Tak pojawił się pomysł uruchomić warsztaty przez internet. Już zacząłem nad tym aktywnie pracować i mam plan uruchomić go na jesień tego roku.
Dobra nowość dla Ciebie, że koszt warsztatu przez internet będzie znacznie tańszy (niż spotkanie na żywo), bardziej elastyczny (po Twojej stronie jest decyzja o której godziny w ciągu tygodnia chcesz się uczyć) i rozciągnięty w czasie (żeby mieć czas na przyswojenia wiedzy). Kolejna dobra nowość dla Ciebie to możliwość uzyskania 10% zniżki, która będzie dostępna dla słuchaczy podcastu Biznes Myśli. Dlatego gorąco polecam zapisać się na newsletter.
Warsztat jest skierowany dla osób technicznych które mają chociażby minimalne doświadczenie w programowaniu. Dlatego jeżeli chcesz przeszkolić swój zespół lub wybranych osób z IT, myślę, że warto wziąć udział. Podczas warsztatu, duży nacisk będzie kładziony na rozwiązywanie realnych problemów, niż bawienia się w technologię.
Szczerze mówiąc, pięć lata temu sam borykałem się ze zrozumieniem wielu tematów związanych z uczeniem maszynowym, a potem okazało się, że teoria dość często mało skupia się na tym, jak rozwiązać realny problem. Dlatego, ten kurs kupiłbym osobiście, kilka lat temu i tym samym zaoszczędziłbym sporo swego czasu.
W najbliższym miesiącu będzie więcej informacji na ten temat. Gorąca Cię zachęcam podzielić się swoją opinią na ten temat oraz jakiego typu problemy warto było rozwiązać podczas szkolenia.
Tyle na dzisiaj. Dziękuję za poświęcony czas i Twoją energię. Życzę dobrego samopuczucia i do usłyszenia w kolejnym odcinku.
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.
Dzięki za bardzo dobry odcinek podcastu, świetnie jest dowiedzieć się że na Polskim rynku wśród firm są takie perełki jak Appsilon.
Dodatkowo, chciałbym doprecyzować jedną rzecz, nie zgodzę się z Twoim gościem – Panie Filipie przepraszam 🙂 – w kwestii może delikatnego szufladkowania rozwiązań BI.
Na przykładzie Qlik-a (jako że z tym mam największe doświadczenie):
* Pełen język skryptowy w oparciu o autorski silnik QIX
* Wersjonowanie kodu – jak najbardziej zarówno dla skryptu (trywialna sprawa jako że jest to plik tekstowy) jak i dla dashboard-u (wystarczy zapisać front w XML-u lub JSON-ie)
* Zarówno Qlik View jak i Qlik Sense umożliwiają współpracę wielu użytkowników, komenatrze write back (jako dodatkowa funkcjonalność – nie jest to out of the box w narzędziu)
* Otwarte API (dla Qlik Sense-a) można skorzystać tylko z możliwości silnika a cały front end napisać samemu: http://help.qlik.com/en-US/sense-developer/3.2/Content/APIs-and-SDKs.htm
* Mnogość otwartych JavaScriptowych bibliotek (Enigma.JS, Halyard.JS itp.)
* Integracja z R / Python i innymi (Spark , Matlab) (natywne skrypty R i Python wysyłane do przetworzenia na serwerach zewnętrznych) – https://www.youtube.com/watch?v=7dEm_EOzrtY
* Predictive analytics i Augmented Intelligence (świeżynka w Qlik Senie – to be in the future) – https://www.youtube.com/watch?v=DpSnTEd88E4
Mógłbym wymieniać jeszcze wiele dodatkowych funkcjonalności, ale zależało mi w zasadzie tylko na tym żeby podkreślić trafną definicję „dashboardu” Pana Filipa z którą się zgadzam w 100%, jak również to że jest ona jak najbardziej adekwatna do rozwiązań klasy BI, można pisać custom build za każdym razem ale jak Klient ma fundusze na rozwiązania takie jak Qlik może lepiej z nich skorzystać?
Vladimir,
świetny odcinek i i na prawdę mocny zawodnik w tym podcascie, pan Filip.
Idę dalej z odcinkami i nie mogę się doczekać co planujesz w kolejnych. Pewnie jeszcze mi zejdzie zanim dotrę do 2021 🙂
BTW
miałem okazję całkiem niedawno rozmawiać z panem Filipem w sprawie biznesowej. Firma Appsilon została mi polecona przez jednego z wykładowców z Akademii im. Leona Koźmińskiego jako jedna z najlepszych w Polsce
Panie Filipie, jeszcze wrócimy do tematu tylko uporządkuję sprawy w firmie












2 komentarze
Krzysztof Bury
Cześć Vladimir,
Dzięki za bardzo dobry odcinek podcastu, świetnie jest dowiedzieć się że na Polskim rynku wśród firm są takie perełki jak Appsilon.
Dodatkowo, chciałbym doprecyzować jedną rzecz, nie zgodzę się z Twoim gościem – Panie Filipie przepraszam 🙂 – w kwestii może delikatnego szufladkowania rozwiązań BI.
Na przykładzie Qlik-a (jako że z tym mam największe doświadczenie):
* Pełen język skryptowy w oparciu o autorski silnik QIX
* Wersjonowanie kodu – jak najbardziej zarówno dla skryptu (trywialna sprawa jako że jest to plik tekstowy) jak i dla dashboard-u (wystarczy zapisać front w XML-u lub JSON-ie)
* Zarówno Qlik View jak i Qlik Sense umożliwiają współpracę wielu użytkowników, komenatrze write back (jako dodatkowa funkcjonalność – nie jest to out of the box w narzędziu)
* Otwarte API (dla Qlik Sense-a) można skorzystać tylko z możliwości silnika a cały front end napisać samemu: http://help.qlik.com/en-US/sense-developer/3.2/Content/APIs-and-SDKs.htm
* Mnogość otwartych JavaScriptowych bibliotek (Enigma.JS, Halyard.JS itp.)
* Integracja z R / Python i innymi (Spark , Matlab) (natywne skrypty R i Python wysyłane do przetworzenia na serwerach zewnętrznych) – https://www.youtube.com/watch?v=7dEm_EOzrtY
* Predictive analytics i Augmented Intelligence (świeżynka w Qlik Senie – to be in the future) – https://www.youtube.com/watch?v=DpSnTEd88E4
Mógłbym wymieniać jeszcze wiele dodatkowych funkcjonalności, ale zależało mi w zasadzie tylko na tym żeby podkreślić trafną definicję „dashboardu” Pana Filipa z którą się zgadzam w 100%, jak również to że jest ona jak najbardziej adekwatna do rozwiązań klasy BI, można pisać custom build za każdym razem ale jak Klient ma fundusze na rozwiązania takie jak Qlik może lepiej z nich skorzystać?
Pozdrawiam,
Krzysiek
MARIUSZ
Vladimir,
świetny odcinek i i na prawdę mocny zawodnik w tym podcascie, pan Filip.
Idę dalej z odcinkami i nie mogę się doczekać co planujesz w kolejnych. Pewnie jeszcze mi zejdzie zanim dotrę do 2021 🙂
BTW
miałem okazję całkiem niedawno rozmawiać z panem Filipem w sprawie biznesowej. Firma Appsilon została mi polecona przez jednego z wykładowców z Akademii im. Leona Koźmińskiego jako jedna z najlepszych w Polsce
Panie Filipie, jeszcze wrócimy do tematu tylko uporządkuję sprawy w firmie
Mariusz