
Czy sztuczna inteligencja ma intuicję?

Opowiem Ci dwie ciekawostki, nad którymi ostatnio się zastanawiałem.
Pierwsza, to odczytywanie naszych emocji z twarzy. Mam na myślę zwykłą kamerę, która nagrywa ludzi np. na ulicy czy w tramwaju. Mając zwykłe zdjęcie z twarzą człowieka, przy pomocy uczenia maszynowego, można próbować zgadnąć jak ten człowiek teraz się czuje. Techniczne, jest to możliwe już dzisiaj (i wiem, że podobne rozwiązania są stosowane, np. na konferencjach, ulicach czy w innych miejscach, tu między innymi pojawia się koncepcja “audience measurement” lub “crow measurement”).
Co prawda, na dużą skalę, to wymaga większej próbki danych, ale w naszych czasach mamy tak dużo nagrań z ludźmi, że da się to zrobić. Dlaczego o tym myślałem? Kiedyś, wyczytałem w książkach, że król to była taka osoba, która potrafi odczytać lub wyczuć nastrój ludzi „z powietrza”, i na podstawie tego podejmować te czy inne decyzji. Ten, kto robił to najlepiej, był sławny przez długi czas…
Warto powiedzieć wprost, bo czasem wydaje się, że bycie królem, czy używając bardziej nowoczesnego słowa – prezydentem, jest bardzo łatwe. Zwykle regulacje na takim poziomie muszą być ostrożne, bo nawet minimalne wahnięcie w lewo czy w prawo może doprowadzić do różnych skutków, czyli tak zwanego efektu motyla. Myślałem nad tym, a co jeśli już ktoś pracuje nad rozwiązaniem i mierzy jakie jest napięcie ludzi na dużą skalę? Również próbuje zrozumieć, jak to zmienia się z czasem, od czego to zależy. Jeśli pomyśleć jeszcze szerzej, to w ten sposób, można zbudować narzędzie które może mieć potężną siłę, żeby manipulować ludźmi. Na przykład, stworzyć sztuczną euforię wśród ludzi, wtedy kiedy jest taka potrzeba. Podobnie jak to było w książce braci Strugackich. Oczywiście, możesz powiedzieć, że już teraz sporo jest manipulacji, ale obawiam się, że to z czym mamy do czynienia teraz jest jak zabawka… Ciekawy jestem co o tym myślisz?
Druga historia, też powiązana ze zdjęciami i rozpoznawaniem po twarzy człowieka. Jeśli podróżujesz do większych miast, albo chociażby biorąc pod uwagę pewne dzielnice Warszawy, np. tak zwany Mordor (kto mieszka lub pracuje tam, wie o czym mówię). To pewnie wiesz jak dużo ludzi może pojawić się w jednym miejscu. Teraz jeśli to jest metro, czy inne miejsce, gdzie jest specjalna bramka, w którą trzeba wrzucić monetę czy bilet, to nagle staje się ono wąskim gardłem. Pojawia się gigantyczny korek, złożony tylko z ludzi.
Jak można to rozwiązać? Amerykańska firma Cubic Transportation Systems chce zrobić rewolucję w transporcie w Londynie. Zamiast użycia Oyster Card, będą… skanować twarze. Mówiąc wprost, po twarzy można będzie rozpoznać kto jedzie na gapę i to dosłownie! :). Jako wizja, brzmi to jak najbardziej możliwe. Myślę, że jeszcze będzie trochę wyzwań na poziomie technicznym, żeby osiągnąć skuteczność bliską 100%, a z drugiej strony być może to nie jest takie ważne. Pewnie firmie bardziej będzie się opłacać znacznie zwiększenie przepustowości bramki i incydentalne przepuszczanie ludzi bez biletu, niż zablokowanie tych, którzy mają bilet. Kontynuując tę myśl, po co nam dowód czy paszport w przyszłości? Co o tym sądzisz?

Już nie przedłużam, dzisiejszym gościem jest Łukasz Kuncewicz. Cieszę się, że Łukasz znalazł czas, bo wiem, że jest mocno zapracowany. Ma sporo doświadczenia w IT, pracuje z dużymi danymi, czyli tak zwanym Big Data, jak i uczeniem maszynowym. Jest praktykiem, przez co bardzo z nim sympatyzuję, ale coś innego przykuło moją szczególną uwagę, on lubi myśleć dalej… Wiem, brzmi trochę dziwnie, ale to dość rzadka cecha w naszych czasach. Zastanawiać się nad procesami. Wyciągać z tego samodzielne wnioski.
Czuć, że Łukasz lubi zadawać pytania, przede wszystkim do samego siebie, ale nawet podczas wywiadu, też pytał mnie 🙂 Ciekawy jestem, czy odniesiesz to samo wrażenia. Zapraszam do wysłuchania.
Cześć Łukasz! Przedstaw się, kim jesteś? Co robisz? Gdzie mieszkasz?
Cześć! Nazywam się Łukasz Kuncewicz. Robię różne rzeczy, między innymi, sztuczną inteligencję. A obecnie mieszkam w Łodzi.
Bardzo szybka i sprawna odpowiedź. Ostatnio zwykle zaczynam swoje rozmowy od pytania „Co ostatnio czytałeś?” więc Ciebie też o to pytam. Co ostatnio czytałeś? I dlaczego akurat warto to przeczytać.
Wiesz co, ostatnio to chciałem nadrobić Dukaja. Parę razy już go czytałem i fajnie. Wyszła niedawno jego książka „Król Bólu„, mocna rzecz, opowiadająca o przyszłości, pokazująca różne wizje przyszłości. Polecam, to nie jest prosta rzecz, to się trochę ciężko czyta. Ale każde z tych opowiadań zostaje w Tobie. To znaczy, to nie jest coś co potem odleci, tylko coś co praktycznie jest na całe życie.
Możesz podać jakiś przykład, co tak pamiętasz z tej książki?
Wiesz co, każde z jego opowiadań to jest próba wyłuskania jednego trendu, który teraz widzimy i spróbowania co by było gdyby ta przyszłość właśnie podążyła za tym trendem. Pamiętam dwa takie opowiadania, które najbardziej mi się wryły. Jedno to jest próba odpowiedzi, co się dzieje, kiedy ten nasz świat nierealny, powiedzmy facebookowy, zaczyna dominować nad światem realnym. Jak bardzo jest to dziwne, ale jednocześnie naturalne. I jakby wyglądała przyszłość, w której bardziej jesteśmy w tym świecie wirtualnym niż rzeczywistym.
Drugie opowiadanie, to utwór o tym, co by się stało, gdyby technologicznie była możliwość przepisywania się na coraz lepsze wersje siebie fizycznie. To znaczy, bo by było, gdybyśmy mogli modyfikować swoje DNA. Co by było gdybyśmy mogli modyfikować sposób zapisu informacji o tym, że my to my. Czyli, co by było, gdybyśmy mogli zapisać się w krzemie, jakby to wyglądało i do czego by to prowadziło? Każde z jego opowiadań jest do bólu konkretne i do bólu logiczne. To znaczy, w zasadzie czytasz to i myślisz „no tak, tak to mogłoby być” albo „tak to będzie” bo nie widzisz powodu dla którego tak by to miało nie pójść.
Jak to opowiadasz, to brzmi naprawdę bardzo ciekawie, żeby nad tym się zastanowić w wolnej chwili. Na przykład, kiedy masz urlop albo wolny weekend. Takiej książki pewnie nie da się czytać między innymi, pewnie trzeba ją czytać z taką rozwagą i uważnością. Tak to zrozumiałem.
Tak, to nie jest książka, że ją sobie w pociągu przeczytasz i tyle, bo masz akurat czas. To jest raczej taka książka, że kończysz opowiadanie i dwa dni masz przerwy, bo to w Tobie siedzi.
Rozumiem, bardzo ciekawe. A czym dla Ciebie jest sztuczna inteligencja?
To Ty mi powiedz, czym dla Ciebie jest inteligencja?
Właśnie to jest dość trudne pytanie, żeby ją zdefiniować. Wydaje mi się, że inteligencja zwykle kojarzy się, przede wszystkim, z ludźmi. Chociaż niekoniecznie tylko ludzie mają inteligencję, ale takie jest skojarzenie. Drugie skojarzenie to myśli albo rozum albo rzeczy, które mają pewien sens, logikę. Dość ciężko to jednoznacznie zdefiniować. Jakie masz jeszcze inne propozycje?
Powiedziałeś rzeczy, które mają sens, logikę. To chyba gdzieś jest blisko tego, co ja myślę. Dla mnie inteligencja to jest taka zdolność do poradzenia sobie w sytuacji, w której wcześniej nie byłeś. Szczególnie jeśli zawęzimy tę inteligencję do jakiejś niszy.
Teraz jest modnie mówić, że ktoś ma inteligencję matematyczną albo inteligencję językową czy emocjonalną. Jak to tak zawęzimy to ja rozumiem, że ktoś ma inteligencję matematyczną wtedy, kiedy potrafi rozwiązywać zadania, których wcześniej jeszcze nie rozwiązał. Umie znaleźć elementy wspólne, w stosunku do tego co już umiał i stworzyć jakąś nową rzeczy. Jeżeli tak rozumiemy inteligencję to sztuczna inteligencja to będzie taka własność maszyny, że to ona na podstawie swoich wcześniejszych doświadczeń w jakimś temacie, jest w stanie wytworzyć nową wartość. Poradzić sobie w sytuacji, w której jeszcze nie była. Tak rozumiem sztuczną inteligencję.
To jest ciekawe, jak mówiłeś od razu mi przyszło do głowy abstrakcyjne myślenie. Nie chodzi tylko o odkrywanie wzorców, to czym teraz jest uczenie maszynowe. Ale też radzenie sobie z tym, gdzie jeszcze nigdy nie byłeś. Jednak, nie ukrywajmy, ten etap rozwoju, który teraz mamy w uczeniu maszynowym to jest ten czas, kiedy potrafimy przewidzieć tylko te rzeczy, które już wcześniej się wydarzyły. Być może nie identycznie, ale są podobne wzorce. Ale inteligencja jest krok dalej. To jest coś bardziej złożonego.
To tak może być, ale wydaje mi się, że to nie jest taka rzecz, która jest zerojedynkowa. Możemy mówić, że ktoś albo coś jest bardziej lub mniej inteligentne i to uczenie maszynowe jest mniej więcej na poziomie muchy czy mało ogarniętej myszy. To już jest inteligencja, ale to nie jest inteligencja wybitna. Natomiast, jest to spectrum, możemy sobie wyobrażać, że coś lub ktoś jest bardziej inteligentny i to się tak dzieje ewolucyjnie a nie rewolucyjnie.
Kontynuując ten temat z inteligencją, zapytam o coś powiązanego. Zwykle osoba, która w pewnym obszarze pracuje dość długo jest nazywana ekspertem, nabywa pewną umiejętność, która nie do końca wiadomo, jak wpływa na jego decyzje. Mam na myśli taką sytuację, kiedy człowiek podejmuje decyzję, a kiedy ktoś go pyta dlaczego zrobić coś tak a nie inaczej, on mówi „W sumie nie wiem, ale wiem, że to jest prawidłowe”.
Czasem jest to nazywane intuicją. Między innymi gra w Go, była początkowo na tyle złożona, że jak próbowali zrozumieć dlaczego zrobiono ten czy inny krok, to ten gracz nie był w stanie tego jednoznacznie wytłumaczyć. Po prostu, twierdził, że wydaje mu się, że tak jest najlepiej. Jak myślisz, gdy mówimy o sztucznej inteligencji, jaki ma ona związek z intuicją?
Jeżeli rozumiemy intuicję dokładnie tak jak ją zdefiniowałeś. Jako, pewnego rodzaju inteligencję, tylko, że nie uświadamianą sobie przez człowieka to wydaje mi się, że to pytanie nie jest słuszne w stosunku do maszyn. Ono nie ma sensu. To trochę jakbyś się pytał jakiego koloru jest kilogram. To nie ta dziedzina, nie ta domena. Natomiast, jeżeli sobie zdefiniujemy troszkę inaczej to myślę, że będę mógł Ci powiedzieć coś ciekawego. Jeżeli zdefiniujemy intuicję jako umiejętność logicznego albo rozsądnego albo inteligentnego działania w domenie, z którą wcześniej się nie miało styczności.
Na przykład, jesteś w szkole i masz test z języka angielskiego, znasz go trochę i jakoś Ci idzie, no to w porządku. Masz inteligencję języka angielskiego, teraz wyobraź sobie, że dostajesz test z języka hiszpańskiego, którego nie znasz. Po mimo tego, że nie znasz hiszpańskiego to intuicyjnie pewne rzeczy wiesz. Na przykład, pewnie to nie jest tak, że za każdym razem możesz zakreślać pierwszą opcję i, że to jest dobry pomysł. Pewnie intuicyjnie masz jeszcze jakieś heurystyki, które pochodzą z innych testów. Pochodzą one z faktu, że w innych domenach coś tam umiałeś. Jeżeli tak sobie zdefiniujemy intuicję to można pokazać, że nawet w uczeniu maszynowym, szczególnie w sieciach neuronowych, można dokonać takiego transferu inteligencji z jednej domeny na drugą.
Nawet jeżeli maszyna nigdy nie widziała tej drugiej domeny. Takim przykładem mogłoby być… Jeżeli mamy klasyfikowanie zdjęć rentgenowskich i patrzymy czy są tam jakieś niebezpieczne rzeczy czy nie. Patrzymy na klatkę piersiową i maszyna ma stwierdzić czy ktoś ma raka, jakiego jest on typu itd. To okazuje się, że jeżeli najpierw nauczymy taką sieć neuronową rozpoznawać co jest kotem, a co jest psem, a co jest koniem, a co jest chmurą, a co jest samochodem. To te umiejętności są niezwykle przydatne przy ocenie czy na zdjęciu rentgenowskim w płucach mamy raka czy nie. Inaczej mówiąc, jeżeli najpierw nauczymy maszynę czegoś z dziedziny obok to ona jest w stanie te niektóre elementy swojej starej wiedzy wykorzystać w zupełnie nowej dziedzinie. Jeżeli tak rozumiemy intuicję, to maszyny mają intuicję lub mogą ją mieć.
Teraz przechodzimy na inny obszar związany z uczeniem maszynowym, który nazywa się Transfer Learning, zgadza się?
Pewnie tak.
Właśnie się zastanawiam i w pewnym sensie, jeżeli się zastanowimy nad tym głębiej to my jako ludzie wyciągamy tę intuicję faktycznie z doświadczeń. Jeżeli patrzymy na to jak działa Transfer Learning to on też próbuje rozkładać rzeczy na czynniki pierwsze, a później w jakimś stopniu to wykorzystywać, więc w tym stopniu myślę, że ma to jak najbardziej sens.
Może inny przykład Ci podam, bardziej intuicyjny. Uczysz sieć neuronową na przykład czy coś jest napisem w języku angielskim czy jest po prostu zbiorem przypadkowych liter, bądź po prostu językiem nieangielskim. Jeżeli taką sieć, nawet nauczoną języka angielskiego, weźmiesz teraz i powiesz jej „dobra, ale teraz zmieniamy zasady gry i uczymy się francuskiego”. Ta sieć nauczona już języka angielskiego znacznie szybciej będzie się uczyła francuskiego niż sieć, która zaczyna od zera.
Dla mnie to jest wniosek taki, że w tych językach coś siedzi. We francuskim czy angielskim coś ma elementy wspólne i sieć jest w stanie wykorzystać te elementy przy nauce francuskiego. To też dla mnie byłby ten transfer wiedzy czy intuicja.
Zacząłeś mówić o sieci neuronowej, która potrafi wychwytywać pewne wzorce, bądź to angielskie czy francuskie. Ostatnio czytałem o tym, że robiłeś projekt, taki bardziej for fun, pewnie jesteś pasjonatem takiej tematyki, będzie super jeżeli się tym podzielisz. Mam teraz na myśli twój projekt EnigmaCode. Wyjaśnij proszę, najpierw kontekst, o co chodzi z tą Enigmą, a później jak ten problem można rozwiązać dzisiaj.
Musimy się cofnąć do lat 30. poprzedniego wieku. Mamy okres przed II wojną światową, mamy Niemcy, które używają Enigmy, czyli takiej maszyny do kodowania wiadomości. Rozsyłają tą Enigmą informacje o stanie swoich wojsk, o miejscu gdzie się one znajdują, przesyłają raporty przedwojenne itd. Ta maszyna jest tak skomplikowana, że w zasadzie nikt nie chce się podjąć złamania tego szyfru, nawet dowody, że jest to niemożliwe.
Ale na początku Polacy, a potem Anglicy, w końcu łamią ten kod. Łamią go w ten sposób, że używają geniuszy matematycznych, łącznie z Turingiem na czele. Wykorzystują oni swoje niesamowite zdolności matematyczne i logiczne oraz niedużą dawkę maszyn. Są budowane maszyny, takie powiedzmy, pierwowzory komputerów, ale bardzo, bardzo niedoskonałe. Ten tandem, genialny człowiek + bardzo prosta maszyna, jest w stanie złamać kod Enigmy.
I przechodzimy do 2017 roku do projektu Enigma, gdzie chcieliśmy sprawdzić czy jeśli się odwróci te proporcje, jeżeli weźmie się bardzo prostą sztuczną inteligencję, ale za to dołoży do niej ogromną moc obliczeniową, to czy takie połączenie da podobne efekty jak ten tandem człowieka i rachitycznych maszyn jeszcze 80 lat temu. Zbudowaliśmy prostą sztuczną inteligencją, która rozpoznawała czy coś jest językiem niemieckim czy nie. I dopięliśmy do niej projekt, pewnie powinniśmy powiedzieć Big Data, który dystrybuował wszystkie możliwe hasła, pomiędzy tysiąc serwerów.

Te tysiąc serwerów próbowało dekodować wiadomości używają wszystkich możliwych haseł i sprawdzając na wyjściu przez sztuczną inteligencję czy przypadkiem może udało się odkodować bo wyszedł tekst wyglądający na język niemiecki. Okazało się, że tak, jesteśmy w stanie w ten sposób odkodować zaszyfrowane informacje Enigmy. Zatoczyliśmy koło, na początku był geniusz człowieka i bardzo prosta maszyna, a teraz ten tandem wygląda trochę inaczej, czyli bardzo prosta sztuczna inteligencja i ogromna moc obliczeniowa tysiąca komputerów liczących coś tam naraz.
To jest bardzo ciekawa opowieść bo od razu można zauważyć jak szybko zmienia się nasz świat. Ja kiedyś jeszcze na początku tego podcastu, mówiłem, że jeżeli mówimy o sztucznej inteligencji, dlaczego to akurat teraz tak aktywnie zaczęło działać, to wspomniałem o trzech elementach: dane, algorytmy i moc obliczeniowa. Teraz te trzy elementy się połączyły, przy czym moc obliczeniowa naprawdę jest tania. W waszym przypadku, to też można podkreślić, ile kosztowało Was uruchomienie tysiąca serwerów?
Właśnie, dobrze to zauważyłeś. Jest prawo Moore’a, które nie jest łamane przez kilkadziesiąt już lat. Otóż wynajęcie tysiąca serwerów robiących coś dla Ciebie przez godzinę, kosztowało nas 7 dolarów. Dla porównania koszty budowy oryginalnej Enigmy, w zasadzie to się nazywało „bomba kryptologiczna”, tej maszyny, która razem z tymi matematykami 80 lat temu rozgryzła kod Enigmy, wyniosły około pół miliona funtów. Ten przeskok jest ogromny. My teraz dużą ilość problemów, które do tej pory, rozwiązywało się jakoś żmudnie, ewentualnie sprytnie. My teraz rozwiązujemy je czystą siłą obliczeniową, która jest tania jak barszcz.
Dokładnie widać tę moc. Ostatnio czytałem artykuł, był nieco podobny do tego problemu. Chodziło w nim o to, że mało tego, że teraz ludzie zgadują proste hasła, bo jest statystyka jakiego hasła używa przeciętny Kowalski i są najbardziej popularne hasła. W ten sposób, można już wejść na wiele kont na LinkedIn czy w sieciach społecznościowych.
Ostatnio czytałem artykuł, w którym było powiedziane, że w prawie 1/4 profilów na LinkedIn, gdzie są 43 miliony użytkowników, udało się odkryć hasło, używając sztucznej inteligencji. Od razu powiem naszym słuchaczom, żeby zastanowili się jakie mają hasło, nie tylko w LinkedIn, w ogóle w sieciach społecznościowych, w banku przede wszystkim i może zmieńcie je na trudniejsze.
A dla Ciebie pytanie – jak myślisz, na ile już teraz, jest to ryzyko, które naprawdę zmienia lub powinno zmienić myślenie o zabezpieczeniach z punktu widzenia użytkownika. Mam na myśli hasła albo tokeny, które musimy mieć. Jak ty to widzisz?
Podzieliłbym to pytanie na 2 części. Jeżeli chodzi o tokeny czy takie elementy, które nas zabezpieczają mechanicznie, bez udziału naszej woli – to jest w miarę bezpiecznie, że tak powiem. To znaczy, dopóki ja nie muszę wymyślać losowych znaków albo losowych cyfr, a robi to za mnie maszyna, to ja temu bardziej ufam, niż sobie samemu.
A dlaczego? Ponieważ, my jesteśmy dosyć łatwi do przewidzenia. Inaczej mówiąc, jeżeli ja bym dostał dane, powiedzmy, miliona osób, informacje kiedy się urodzili, kiedy się urodzili ich współmałżonkowie, dzieci, jak się nazywają, jak się nazywały ich psy itd. Plus miałbym jeszcze informacje jakie ich hasła były, to bardzo łatwo jest zrobić model, który przewidzi i z dobrą skutecznością zaproponuje dla każdej osoby innej, spoza zbioru, takich osób których jeszcze nie widziałem, powiedzmy 20 takich najbardziej rozsądnych haseł i dokładnie to jest ten projekt.
My myślimy, że jak sobe wpisujemy hasła albo wymyślamy losowe numery to, że to jest losowe i tajemnicze i robimy coś, czego nikt nie robi. Ale prawda jest taka, że człowiek jest takim automatem, że większość ludzi dosyć łatwo przewidzieć. Nie mówię, że wszyscy, ale jako masa szczególnie, jesteśmy bardzo przewidywalni.
Ciekawy przykład, gdy to mówiłeś przypomniał mi się generator losowy. On na starcie potrzebuje tak zwane ziarnko albo seed. To co mówisz brzmi tak, że my jako ludzkość też mamy to samo ziarenko i nasza moc losowa jest dość słaba.
Absolutnie! Nie wiem może komuś się będzie chciało. Można sprawdzić na githubie. I popatrzeć jakie ziarna ludzie wsadzają do kodu. Ja bym powiedział, pewnie z 20% to będą ziarna będące jedną cyfrą między 0 a 9, bo nikomu się nie chce. Tacy jesteśmy. Dasz człowiekowi wolność i powiesz mu „weź wpisz dowolną liczbę”, to większość ludzi wpisze 3 albo 2.
Zapytam teraz o taki temat jakim jest uczenie maszynowe. Jest on bardzo gorący. A właściwie na początek nie chodzi tylko o uczenie maszynowe tylko jak coś staje się bardzo popularne, pojawia się wiele osób, które o tym mówią. Niekoniecznie na tym się znają, ale obowiązkowo mówią i jako wynik dostajemy bardzo dużo różnorodnych informacji, które niekoniecznie mają sens. Jak sobie z tym radzić?
Spróbujmy to trochę odczarować. Z Twojego punktu widzenia, jakie rzeczy najbardziej rzucają Ci się w oczy, które nie mają sensu, ale gdzieś non stop się kręcą albo są jakieś stereotypy? Myślę, że nawet po obydwu stronach, po stronie pracowników i po stronie pracodawców. Każda z tych stron coś sobie wyobraża, ale to nie ma powiązania z rzeczywistością. Porozmawiajmy o tym.
Ja bym ten temat podzielił na trzy części. Może zacznijmy od firm. Jest rzeczywiście taki trend pod tytułem wszystkie firmy robią sobie sztuczną inteligencję. Kupują domeny z rozszerzeniem .ai itd. Bardzo dużo mamy zapytań od klientów, którzy chcieliby mieć w firmie sztuczną inteligencję, ponieważ konkurencja ją ma więc oni też muszą. To co najbardziej rzuca się w oczy podczas rozmów z nim to, że nie zdają sobie sprawy, że to oznacza zmianę operacyjną wewnątrz firmy.
To nie jest tak, że oni coś tam robią i Pani Basia czy Pan Sławek, w pewnym momencie decydują o jakiś procesie i teraz wymienimy Pana Sławka czy Panią Basię na sztuczną inteligencję, a w zasadzie dookoła nic się nie zmieni. Tak nie jest. Takim przykładem mógłby być marketing, gdzie nadal duże wolumeny finansów i ruchu przechodzą przez ludzi. To znaczy, że siedzi sobie analityk i mówi „o dobra, jest duża firma, która potrzebuje kampanii reklamowej, to my teraz weźmiemy i pół miliona złotych wrzucimy w telewizję, w taki a nie inny kanał, bo tak mi się wydaję, takie mam przeszłe doświadczenia”.
Można to wymienić na sztuczną inteligencję, ten proces decyzyjny wymienić na sztuczną inteligencję, ale okazuje się, że oznacza to zbieranie dużo większej ilości danych. Po drugie, inną działalność operacyjną, inny sposób kupowania ruchu, inny sposób rozliczenia się za niego i monitorowania go. Nagle się okazuje, że taka duża firma, która chciałaby mieć sztuczną inteligencję, w zasadzie nie może jej mieć, bo to oznacza, że muszą zmienić się tak bardzo, że już przestają być sobą. Paradoksalne znacznie łatwiej jest wprowadzać sztuczną inteligencję w mniejszych firmach, które jeszcze nie nabrały ciała i ta zmiana jest stosunkowo łatwiejsza. Nie mówię, że łatwa, ale łatwiejsza. To byłoby pierwsze moje zdziwienie i odczarowanie sztucznej inteligencji.
Drugie, to czym się zajmuję, to sztuczna inteligencja od strony praktycznej, gdzie tak naprawdę 90% tego co robimy, to jest zabawa z danymi. To nie są te algorytmy, o których się uczymy, ani sieci neuronowe, które trenujemy i one dają wspaniałe wyniki i w ogóle. To jest żmudna, ciężka praca z danymi, które są niekompatybilne, nieznormalizowane, których brakuje albo, które są gdzieś na drugim końcu świata, są ciężkie.
Tak naprawdę tym się zajmujemy. Jeśli ktoś chce się zajmować sztuczną inteligencją i wyobraża sobie, że zbiór danych jest już podany, a on wchodzi ubrany cały na biało i tylko przykłada do niego jakiś algorytm to zupełnie nie tędy droga. To polega na zupełnie czym innym – twardej, konkretnej robocie w danych. Jeżeli ktoś chce być specjalistą od sztucznej inteligencji a nie chce znać SQL albo nie chce się bawić w Big Data to będzie miał trudno. Są takie możliwości, ale jest ich stosunkowo niewiele.
Trzecie, może najważniejsze, takie odczarowanie dotyczące, i teraz uwagę użyję słowa, ludzkości. To mi się wydaje, że ludzie źle oceniają prędkość tego postępu w sztucznej inteligencji. Po pierwsze, przeceniają tę prędkość myśląc, że ta wielka, niedobra sztuczna inteligencja, która zaraz wybije ludzkość co do nogi, to już jest za zakrętem. Jeszcze jej tam nie ma, jeszcze trochę nam brakuje, żeby stworzyć taką generalną sztuczną inteligencję. Natomiast, nie doceniają prędkości konkretnej małej sztucznej inteligencji.
Tej, która odpowiada za samochody, które się same prowadzą, za diagnozy lekarzy, za pracę prawników. Tej sztucznej inteligencji, która zaraz wejdzie na miejsce tych ludzi, którzy przez 8 godzin dziennie siedzą przy komputerach i robią jakieś w miarę proste rzeczy w stylu siedzenia na słuchawce w banku i słuchają klientów albo robią jakieś operacje.
Tutaj jest ogromne niedocenienie tego, że to nie będzie trwało 20 lat, tylko parę i nagle się okaże, że umiejętności dużej części ludzi są nieduże. Może to inaczej powiem. My się teraz fascynujemy tym, że sztuczna inteligencja wygrała w Go, wygrała w pokera, w szachy z człowiekiem. Nie doceniamy faktu, że ta sztuczna inteligencja wygrała i stoi w miejscu, zdecydowanie nie, ona idzie do przodu. Za chwilę będziemy musieli się nauczyć współpracować z pracować z partnerem, który jest inteligentniejszy od nas. Musimy się nauczyć co to oznacza, mieć w firmie prawnika, który jest lepszy od nas. Myślę, że totalnie jesteśmy nieprzygotowani na to. To jest coś co bardzo mocno zaskoczy dużą część ludzi.
Myślę, że to są trzy wartościowe punkty, wskazówki. Trochę się odniosę do ostatniego. Dzisiaj czytałem artykuł, bodajże, był to wywiad z Head of Research w Google Brain albo kimś innym na wysokim stanowisku. Powiedział on, że za dużo przejmujemy się tym, że roboty zaczną rządzić tym światem, zamiast tego jak sobie radzić z “Bajesami”. Te algorytmy, które teraz mamy uczą się na danych, które mamy i w zasadzie też nie są obiektywne.
Chociaż chcielibyśmy, aby taka maszyna była obiektywna. Czytałem też w kilku różnych źródłach, że ktoś pokazywał, że przez to, że algorytm uczy się na tych samych danych to przewiduje on…, prawdopodobnie chodziło wtedy o pensje. Jeżeli dotyczy on kobiety, to prawdopodobnie będzie ona od razu zarabiać mniej przez swoją płeć. Dzieje się tak nie dlatego, że ten algorytm nie lubi kobiet, tylko jest to sytuacja, którą w tej chwili mamy. On się nauczył, że tak to jest, dla niego jest to wzorzec. To jest ciekawe, jak zarządzać tymi sytuacjami?
Ja bym powiedział, że sztuczna inteligencja to nie tylko nadzorowane uczenie maszynowe, czyli te algorytmy, o których mówiłeś. Jest jeszcze duża część sztucznej inteligencja, która polega na uczeniu nienadzorowanym. To, że teraz mamy, algorytmy, które powielają błędy człowieka, bo od niego się uczą, to nie jest według mnie jedyna możliwa sytuacja.
Coraz częściej będziemy mieli sytuacje, w których algorytmy będą się same uczyły i same będa znajdowały co jest dobre a co nie, co działa a co nie. Ta wiedza człowieka nie będzie już potrzebna. Albo będziemy wykorzystywali transfer wiedzy, czyli algorytm, który będzie znajdował taką zmianę w płucach, nie będzie tak samo dobry jak najlepszy lekarz na świecie, od którego będzie się uczył, tylko będzie znacznie lepszy bo będzie miał wiedzę z jeszcze innych domen, których ten lekarz nie posiada. To się nie boję. Te algorytmy przeskoczą człowieka, w ogromnej ilości dziedzin.
To jest bardzo ciekawe. Jeżeli dochodzimy do sytuacji, kiedy algorytm jest w pewnej dziedzinie lepszy niż człowiek w tej dziedzinie, mówimy o obszarach finansów, banków, medycyny itd. My jako ludzie chcielibyśmy rozumieć jak ta decyzja została podjęta. Jeżeli zaufanym, że to czarne pudło same podejmuje decyzje to my nie mamy nad tym kontroli. Nie wiemy czy możemy mu zaufać czy nie.
Tutaj jest pytanie: jak sobie radzić z takimi czarnymi pudłami? I druga rzecz, czy myślisz, że w najbliższej przyszłości… Teraz gdy mówimy o bankach, to oni nie mają wyboru, dość często wybierają prostsze, liniowe modele, dlatego, że mogą to interpretować, ale tracą na jakości, więc mają ten wybór. Moje pytanie jest takie: czy w tej przyszłości, za kilka lat taki, bank będzie miał ten wybór?
Jeżeli wybierze prostszy model to straci na jakości, na przykład będzie dawać kredyt osobom, które nie powinny go dostać i będzie na tym tracić. A jakiś konkurent będzie miał bardziej zaawansowany model, jakiś FinTech Startup i będzie skuteczniejszy. Jak to widzisz ze swojej perspektywy?
W zasadzie odpowiedziałeś sobie na pytanie. Inaczej, jako klient banku, w którym banku chciałbyś mieć konto? W takim, w którym opłaty są wyższe bo bank się częściej myli? Czy w takim, w którym opłaty są niższe bo bank ma lepszy algorytm przyznawania kredytów? Jeszcze inaczej się zapytam, gdzie chciałbyś być leczony? U takiego lekarza, który jest w stanie wytłumaczyć dlaczego uważa, że masz katar albo anginę, ale częściej się myli?
Czy u takiego, u którego nie wiadomo dlaczego twierdzi, że masz zapalenie płuc, ale on się nie myli? Dla mnie odpowiedź jest prosta. Powiedzmy, my teraz w Europie będziemy mieli problem bo wchodzi RODO i nie wiadomo jeszcze do końca jak to ma być. Ten problem wytłumaczalności decyzji, które podejmuje algorytm, bądź instytucja jest ważnym elementem, ale to znowu będą, według mnie, budowane jakieś atrapy bo Europejczycy też chcą być dobrze leczeni. Jeżeli onkolodzy w Stanach Zjednoczonych będą korzystali z lepszego sprzętu, algorytmów bo nie będą się musieli tłumaczyć dlaczego uważają, że ktoś ma jakiś cień na płucach, to Europejczycy będą wysyłali swoje zdjęcia do Ameryki i koniec. Nie jesteś w stanie tego zablokować, można próbować, ale ludzie będą chcieli lepszej jakości leczenia, usług, nawet kosztem tego, że nie będą rozumieli dlaczego lekarz, bankier czy ubezpieczyciel podejmuje jakąś tam decyzję.
Ten temat poruszam, bo dosłownie kilka dni temu byłem na spotkaniu FinTech w Warszawie, gdzie przyszli ludzie z branży bankowej, finansowej, pewnie też ubezpieczeniowej. Mój punkt widzenia był taki, że nie da się uniknąć blackboxa, musimy tylko wymyślić jak sobie z tym radzić. Natomiast, było to odmienne spojrzenie na to, że jednak chcę mieć nad tym kontrolę. Tutaj jak zapytałeś mnie co ja wolę mieć: rozwiązanie, które jest gorsze lub lepsze, ale dla mnie niezrozumiałe, to odpowiedź jest oczywista. Zwykle to pytanie jest podawane inaczej.
Zazwyczaj brzmi ono: w tej chwili nam wydaje się, że blackbox działa lepiej, ale nie jesteśmy pewni. Żeby to zweryfikować potrzebujemy czasu. Jeżeli mówimy o credit score to ten czas zwykle wynosi 5-10-20 lat. Teraz pytanie, jak podjąć takie ryzyko, bo co się stanie jeżeli to była błędna decyzja? Rozumiesz o co mi teraz chodzi?
Wydaje mi się, że brakuje jeszcze tego zaufania, być może chodzi o czas, żeby było więcej potwierdzeń, że to działa. Być może chodzi o popularyzację? Gdy powiedziałeś, że gdy zaczną tego używać z Stanach to Europa nie będzie miała wyboru. To jest ciekawy moment do dyskusji.
To jest ciekawy temat. Jeszcze jest pytanie, kto odpowiada za decyzje algorytmu? Wyobraźmy sobie taką sytuację, algorytm mówi, że dana osoba powinna być leczona jakąś tam metodą, bo wychodzi z modelu, że tak powinna. Ta osoba, na przykład nie przeżywa kuracji, i kto teraz bierze odpowiedzialność za to, że leczono osobę taką a nie inną metodą?
Ja myślę, że nie uciekniemy, myślę, że będziemy się bardzo barowali z tym tematem. Po czym technologia pójdzie do przodu, będziemy mieli coraz więcej danych i już nikt nie będzie sobie zaprzątał głowy tym, że nie do końca wiemy dlaczego coś działa albo dlaczego są podejmowane takie decyzje. Czytałem taką książkę, apropo hamowania postępu, gdzie autor pokazywał fajnie jak coraz mniejszy jest czas utrzymywania się jakiegoś banu technologicznego.
Podano przykład kuszy, która była zabroniona, i bodajże 200 lat w niektórych miejscach ten ban technologiczny się utrzymywał. To znaczy, że nie korzystali z kusz, choć wiedzieli jak je robić. Pokazuje autor, jak ze stulecia na stulecie ten czas jest coraz mniejszy. Sam pamiętam, kilka lat temu dyskusję czy można dokonywać zmian DNA w płodach i tak dalej. Po czym się okazuje, że Chiny już się w ogóle nie szczypią i nie zdziwię się, jeżeli w ciągu 10 lat też to się przyjmie.
Czy my to lubimy, czy nie, czy uważamy to za ludzkie czy nie, to jest to inna kwestia. To jest jak dryf kontynentalny, nie jesteś w stanie tego powstrzymać. To się po prostu stanie. To co my będziemy obserwowali, w Europie w szczególności, to taka walka pomiędzy tymi, którzy są ostrożni a tymi którzy chcą efektów. Wygrają ci drudzy.
Jakby to podsumować, to mogę powiedzieć, że świat zmienia się szybciej niż myślisz.
Teraz zadam bardziej biznesowe pytanie bo myślę, że warto takie tematy jak najbardziej poruszyć. Podaj, proszę, kilka przykładów z biznesu, kiedy uczenie maszynowe dostarcza wartość. Bardziej mi chodzi o jakieś niebanalne przykłady, może takie, które sam przerabiałeś albo są mniej oczywiste. To pomoże lepiej zrozumieć albo zacząć myśleć inaczej.
Dosyć sporo projektów przeszło przez moje ręce. Większość była projektami biznesowymi, gdzie albo generowaliśmy większe oszczędności albo większe zyski – jedno z tym dwóch. To oczywiście można robić na wiele sposób.
Mieliśmy, na przykład projekt, gdzie jest portal z ogłoszeniami o pracę i osoby, które wstawiają ogłoszenia to mogą być osoby także prywatne. W związku z tym, jakość tych ogłoszeń jest różna, a czasami nawet niektóre ogłoszenia zawierają elementy niezgodne z regulaminem lub nawet z prawem. Takie ogłoszenie musi być sprawdzone, to jest dobry moment, żeby wprowadzić sztuczną inteligencję bo firma ma cały proces ogarnięty. Te ogłoszenia gdzieś trafiają, siedzi sobie Pan Sławek i klika, że ogłoszenie jest dobre bądź nie, potem coś się dzieje z tym ogłoszeniem.
W takim momencie, wyjęcie Pana Sławka i wrzucenie tam sztucznej inteligencji jest dosyć proste. Wszystkie dane już są, proces technologiczny, co się dzieje z tymi danymi już jest zrobiony. Taki projekt zrobiliśmy i z tego co pamiętam ilość czasu przeznaczona na sprawdzanie tych ogłoszeń spadła ze 100% do 7%. Ta sztuczna inteligencja była w stanie znakomitą większość ogłoszeń zaklasyfikować w jedną lub drugą stronę. Dużo robimy też projektów marketingowych. Takich gdzie klient wydaje pieniądze na różne kampanie reklamowe w różnych mediach i magiczne pytanie brzmi czy gdyby wydał je trochę inaczej to czy byłoby lepiej?
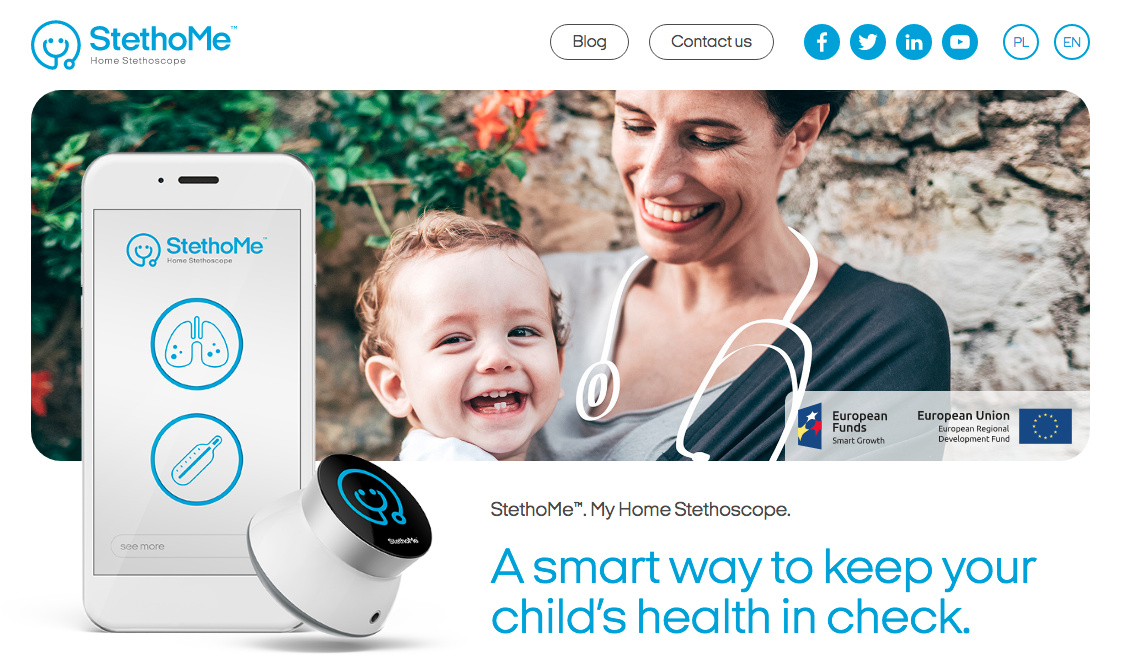
Co to znaczy lepiej, to już zależy od klienta. Ale takie modelowanie. To też robimy i to się sprawdza. Myślę, że najciekawszym projektem to było pół roku, które spędziłem w StethoMe, gdzie chłopaki ze StethoMe, których bardzo serdecznie pozdrawiam, budują sztuczną inteligencję w stetoskopie. Pomysł jest taki, że masz urządzenie wielkości paczki zapałek, przykładasz je w różne miejsca na klatce piersiowej swojej lub swojego dziecka, i to urządzenie analizuje mikrofonem oddech i mówi, że jest ok albo nie, masz zapalenia opłucnej.
To chyba był najciekawszy, może niekoniecznie stricte biznesowy, chociaż z tego będzie poważny biznes. To jest coś co zarówno rodzice czy osoby starsze chcą mieć w domu. Jest to też dobre narzędzie dla lekarzy. Zwykle mają oni pod sobą kilkadziesiąt osób na sali, czy na oddziale. Zamiast chodzić i sprawdzać każdego pacjenta, może on wysłać z takim urządzeniem pielęgniarkę i wskaże ono tylko pacjentów, u których prawdopodobieństwo, że coś się dzieje jest największe. To chyba ten inteligentny stetoskop to taki najfajniejszy projekt.
Bardzo ciekawy projekt. Jak słyszę o takich rozwiązaniach to najbardziej mi się podoba w nich fakt, że one są powtarzalne. Nie ma na nie wpływu zły humor, za dużo pracy, padający deszcz, coś co się dzieje w rodzinie. To urządzenie działa identycznie cały czas. Na pewno są jakieś zakłócenia, ale jest ono zdecydowanie bardziej odporne niż człowiek, jeżeli chodzi o zmiany w czasie i percepcję świata.
Ja bym dodał, bo o tym się często zapomina, że jest ogromna różnica, pomiędzy inteligentnym stetoskopem a inteligentnym lekarzem. Już mówię o co mi chodzi. Bardzo dobry lekarz, mający bardzo duże doświadczenie to jest ktoś na wagę złota. Ale ten lekarz kiedyś przestanie być lekarzem, odejdzie na emeryturę i ta jego wiedza zniknie.
Kolejny lekarz, który przyjdzie na jego miejsce, będzie musiał się znowu uczyć kilkadziesiąt lat, żeby osiągnąć podobny rezultat. W sztucznej inteligencji te dane nie giną, można nawet powiedzieć, że im dłużej ona działa tym lepiej, bo kumuluje więcej danych. To nawet nie jest kwestia tego, że dany lekarz w ciągu swojego życia przebada, powiedzmy 20 tysięcy osób, a sztuczna inteligencja ma natychmiastowy dostęp do zbioru miliona osób. Jest w stanie się uczyć na przebiegu ich choroby.
Różnica polega na tym, że ta wiedza nie ginie tylko jest coraz bardziej polerowana, coraz lepiej dostrajana do nowych sytuacji. Jest to przykład, że to nie jest tak, że sztuczna inteligencja dojdzie do poziomu człowieka i się zatrzyma, musimy się nauczyć żyć w świecie gdzie sztuczna inteligencja będzie lepsza od ludzi.
Bardzo fajna uwaga do tego co powiedziałeś przedtem. Faktycznie to cały czas się rozwija i też warto zauważyć, że ta prędkość rozwoju tylko wzrasta. Zapytam teraz o coś z trochę innej strony. Jeżeli słucha nas teraz ktoś, kto chce zacząć budować takie modele, wejść do tego świata, być osobą, która konfiguruje tę sztuczną inteligencję, zbiera dane, trenuje modele. Jakie cenne wskazówki z twojego doświadczenia możesz przekazać takiej osobie?
Wydaje mi się, że powiedziałbym tak. Najważniejsza jest praktyka. Jeśli tylko interesujesz się sztuczną inteligencją i zastanawiasz się czy to jest fajne czy nie, wejdź sobie na udemy czy na corserze są darmowe, dobre kursy i zacznij je robić. Nawet jeżeli będziesz już umiał, czy umiała, trochę będzie ogarniać, niech to będzie dygresja liniowa czy prosty klasyfikator logiczny, naprawdę początki początków.
Natychmiast siadaj do Excela, czy jakiegokolwiek innego narzędzia, i przygotuj sobie dane. Jest bardzo dużo ogólnodostępnych danych przygotowanych już pod sztuczną inteligencję. Porób sobie parę modeli, poczuj tę fajność lub znużenie. Natomiast, nie siedź pół roku czy dwa lata w temacie zanim ruszysz z pierwszym projektem. Jeżeli tylko mogę coś doradzić, to jak najszybciej sprawdzaj się.
Wybierz taki kurs, zarówno na Udemy jak na Courserze są takie kursy, których nie da się przejść jeżeli nie zaczniesz programować, robić modeli. Takie kursy są dobre, one wyrabiają taki nawyk, że ta sztuczna inteligencja to nie jest magia, teoria, tylko to realnie da się zrobić na laptopie i jest fajnie. Tutaj chciałbym bardzo serdecznie pozdrowić mojego kolegę Pawła Kaczyńskiego, który właśnie 3 dni temu skończył taki kurs na courserze i już robi pierwszy projekt.
Posiadasz bardzo ogromne doświadczenie jeżeli chodzi o uczenie maszynowe, pewnie już 10+ lat i jesteś samoukiem. Dla mnie też jest to bardzo bliskie, bo mam podobną ścieżkę. Z Twojego punktu widzenia, to że nie masz zrobionego doktoratu, czy to Ci jakoś przeszkadza? Czy są takie sytuacje, w których czujesz się mniej komfortowo? Albo to jest tak, że zdobyłeś tę wiedzę tylko w inny sposób i jest ona bardzo praktyczna?
Odczarujmy parę rzeczy. Zacznijmy od tego, że nie mam 10-letniego doświadczenia w machine learning tylko w Big Data. Machine learning jest takim dodatkiem, który pojawił się dosyć niedawno. Natomiast, odpowiadając na twoje pytanie o doktoraty. Musisz brać pod uwagę, że odpowiedź będzie pochodziła od kogoś, kto zrobił coś własnymi rękami, praktycznie i jest z tego dumny. Mając to na uwadze, moja odpowiedź będzie taka, że doktorat nie jest strasznie potrzebny.
To znaczy, ja bym powiedział, że to czym się zajmuje przypomina bardziej pracę dentysty. Ok, masz wiedzę medyczną, ale sam musisz borować, się schylać. Bardzo mało jest dentystów teoretyków, pewnie jacyś są, ktoś wymyśla metody leczenia, ale ogromna większość to są praktycy, ludzie, którzy robią konkretną robotę. Tak samo postrzegałbym branżę sztucznej inteligencji. Tak naprawdę, statystycznie niedużo jest osób, które zajmują sią tak zwanym researchem i pchają tę dziedzinę do przodu.
Natomiast, jest ogromne zapotrzebowanie na ludzi, którzy przyjdą do firmy albo są konsultantami i zrobią konkretną robotę. Powiedzą, ok, ja umiem się podłączyć do waszego systemu, pobrać dane, zamodelować je i wystawić wam rezultaty w taki sposób, żeby to działało. Mam paru kolegów, którzy są doktorami sztucznej inteligencji – których serdecznie też pozdrawiam – mam nadzieję, że się na mnie strasznie nie obrażą jeśli powiem, że ta część związana z danymi, przyłączeniem ich jest żmudną robotą, to nie jest to czego uczą na uniwersytetach czy politechnikach.
Raczej oni zajmują się częścią teoretyczną, związaną z algorytmami i w tym się doktoryzują. Podczas gdy takiego realnego klienta nie interesuje tak bardzo czy algorytm będzie miał skuteczność przewidywania 83% czy 83,5%. Ich interesuje to, żeby ten algorytm był dobrze podpięty, żeby dane dobrze hulały i miało to sens. Interesuje ich ktoś, kto przyjdzie i powie „dobra rozwiąże wam problem wykrywania nieścisłości w jakimś elemencie waszego procesu”. Nie wiem czy Ci odpowiedziałem na to pytanie.
Bardzo mi się podoba ta analogia z dentystą. Nie słyszałem jej wcześniej, ale jeśli nie masz nic przeciwko będę ją czasem używać, tłumacząc jaka jest różnica. Bardzo fajnie się z Tobą rozmawia, ale widzę, że czas nam bardzo szybko mija. Mam jeszcze takie pytanie, już na koniec. Bardziej o przyszłość, którą zawsze jest ciężko przewidzieć. Jak myślisz, czego możemy się spodziewać za 5-10 lat? W kwestiach ogólnych albo związanych ze sztuczną inteligencją.
Ja nie mam jasnych myśli, raczej są one dosyć ciemne. To znaczy, zauważam coraz większą przepaść pomiędzy poszczególnymi ludźmi. Myślę, że technologia nas oddala, ale nie tylko w takim znaczeniu, że mamy mniej przyjaciół czy kontaktów międzyludzkich. Oddala nas też ze względu na to jak bardzo różne technicznie rzeczy wykorzystujemy. Ta przepaść będzie coraz bardziej rosła aż do momentu, w którym duża część ludzi znajdzie się poza techniczną częścią.
Widzę wielką migrację ludzi i podzielenie ich na tych, dla których sztuczna inteligencja to szansa, zysk i nowe możliwości i tych, dla których sztuczna inteligencja to zmniejszanie możliwości. Ja się tak realnie boję rewolucji, rozumianej jako mocne, socjalne tąpnięcie, które spowoduje, że będziemy mieli rewolucję techniczną, którą mieliśmy w XIX wieku. Ale zamiast przeżywać ją w 100 lat, będziemy mieli na to 10 lat. Myśli mam raczej czarne, ale może to tak dzisiaj, miejmy nadzieję.
Jak się do tego przygotować, czy masz jakieś porady? Czy jest coś, żeby można było na to jakoś pozytywnie wpłynąć?
Trzeba na pewno przygotować się na to, brutalnie mówiąc, jeżeli twoja praca polega na czymś co sztuczna inteligencja może szybko zastąpić. Jeżeli jedyną twoją umiejętnością jest jeżdżenie samochodem albo siedzenie na telefonie i odpowiadanie na pytania klientów lub klient przychodzi daje Ci rzeczy na taśmę, a ty je skanujesz i bierzesz od niego pieniądze, mówiąc tak dosyć brutalnie.
Trzeba się zastanowić czy to nie jest ostatni moment na to, żeby zmienić to co robisz. Proste czynności, które są już zapakowane w proces wewnątrz firm, są pierwsze do zastąpienia. Trudno, taki mamy czas. Był taki czas, że drukarze składali ręcznie czcionki, a potem weszły inne technologie i to już nie działało. Tylko, że był bardzo długi czas, żeby się do tego przystosować. My nie będziemy mieli go aż tyle. Przemyśl co umiesz i jak szybko da się to zastąpić sztuczną inteligencją. Jeżeli niezbyt szybko, bo jesteś hydraulikiem to spoko. Ale jeżeli twoją wartością jest to, że przepisujesz z jednych dokumentów dane do drugich dokumentów, no to bym się zastanowił.
Mam nadzieję, że tę cenną wskazówkę usłyszała osoba, która najbardziej tego potrzebuje. Nie ukrywam, że mam podobne zmartwienie. Między innymi podcast ma poszerzyć tę edukację, na tyle ile jest to możliwe w mojej skali. Trzymam kciuki, żeby przynajmniej odrobinę udało się złagodzić ten proces. Ostatnie pytanie dzisiaj – jak można się z Tobą skontaktować, jeśli ktoś będzie miał taką ochotę?
Jeszcze raz, ja się nazywam Łukasz Kuncewicz, bardzo łatwo się ze mną skontaktować na LikedIn, na Facebooku. Jeżeli ktoś tylko będzie miał ochotę, zapraszam do kontaktu.
Dziękuję bardzo Łukaszu za Twój czas, za chęć podzielenia się wiedzą i naprawdę bardzo cenne porady i wskazówki.
Cała przyjemność po mojej stronie.
Chcę podzielić się z Tobą jeszcze jedną myślą. Pewnie jak wiesz, uruchomiłem kurs „Praktyczne uczenie maszynowe„. To jest pierwsza edycja, która jest w 100% online. Uświadomiłem sobie jedną rzecz, po raz kolejny, są pewne rzeczy które jedynie można doświadczyć poprzez cierpliwość i duży wysiłek.
Do stworzenienia tego kursu dążyłem już od dawna. Wiele rzeczy musiało się wydarzyć pomiędzy, ale zaufanie, że to ma sens bardzo mi pomogło. Mówię to dlatego, jeśli masz jakiś pomysł, który wydaje się na początku dziwny albo myślisz, że nie dasz rady, to posłuchaj tego co jest wewnątrz Ciebie (jakie masz odczucia?). Jeśli wierzysz, że to ma sens – to po prostu rób to. Dopiero z czasem to się okaże jak dojść do mety.
Życie jest niespodzianką i dość często działa totalnie inaczej, niż myślimy. To co wydaje się trudne, okazuję się łatwe, a rzeczach, o których w ogóle nie myślimy lub wydawały się one nam proste, okazują się bardzo trudne. Życie zawsze potrafi zaskoczyć.
Życzę Tobie, po pierwsze posiadania marzeń, mniejszych lub większych, a po drugie abyś ciągle dążył do ich realizacji. To jest super frajda, kiedy Twoje starania zaczynają się przekładać na konkretne wyniki i wtedy dopiero jesteś w stanie to docenić. To jest uczucie, które można zdobyć przez wysiłek i pokorę, ale czujesz się wtedy bardzo szczęśliwy.
Kurs potrwa 2 miesiące, więc jestem również otwarty na naukę… tylko w moim przypadku bardziej będzie to „nauka o ludziach”. Bardzo lubię pomagać i zastanawiać się nad różnymi procesami, które dzieją się w głowach ludzi. Czasem z tym przesadzam, bo pochłania to moją ciekawość i mogę nad tym spędzić za dużo czasu. Gdy skończy się kurs, myślę nad tym, żeby zrobić podsumowanie i podzielić się moimi przemyśleniami. Proszę daj znać, czy to będzie dla Ciebie ciekawe?
Chciałem jeszcze podziękować za kilka kolejnych 5-cio gwiazdkowych ocen na Itunes i za te wszystkie maile, które dostaję. To daje mi dużo motywacji.
Następnym razem, będziemy rozmawiać o dźwięku. Czy wiesz, że teraz firmy zwracają coraz większą uwagę na dźwięk przy budowaniu marki? Oczywiście, uczenie maszynowe w tym może pomóc. Zapraszam.
Vladimir
Od 2013 roku zacząłem pracować z uczeniem maszynowym (od strony praktycznej). W 2015 założyłem inicjatywę DataWorkshop. Pomagać ludziom zaczać stosować uczenie maszynow w praktyce. W 2017 zacząłem nagrywać podcast BiznesMyśli. Jestem perfekcjonistą w sercu i pragmatykiem z nawyku. Lubię podróżować.

Jeden Komentarz
Mariusz
Świetny odcinek, dzięki bardzo fajnemu gościowi podcastu, który niewątpliwie wie o czym mówi!